数据结构(一)(嵌入式学习)
数据结构干货总结(一)
- 基础
- 线性表的顺序表示
- 线性表的链式表示
- 单链表
- 双链表
- 循环链表
- 循环单链表
- 循环双链表
- 栈
- 顺序存储
- 链式存储
- 队列
- 队列的定义
- 队列的常见基本操作
- 队列的顺序存储结构
- 顺序队列
- 循环队列
- 队列的链式存储结构
- 树
- 概念
- 二叉树
- 二叉树的创建
基础
数据:计算机存储的,能被计算机识别,处理的(音频、视频)
结构:数据和数据之间的关系。
算法:实现特定功能的求解的描述。
数据元素:也称顶点,结点或记录。数据的基本单位。
数据项:最小单位。
1、数据结构包括:数据的逻辑结构 存储结构 数据的运算。
2、计算机解决问题的步骤:分析问题 设计相应的算法 编写程序 调试并得到正确结果
3、存储结构:
顺序存储 ------->数据在计算机内的物理存储
链式存储--------->用指针表达数据元素之间的逻辑关系
散列存储/索引存储 ------->哈希
4、逻辑结构:逻辑结构=数据元素+关系 --------->描述的数据与数据之间的关系
一对一:线性
一对多:树形
多对多:集合
5、对数据的操作:增删改查
线性表的顺序表示
1、静态分配
#define MaxSize 50 //宏定义线性表最大长度为50
typedef struct{ //定义一个结构体ElemType data{maxSize}; //顺序表的元素,数组int length; //顺序表当前长度
}SqList; //结构体名
2、动态分配
#define InitSize 50 //表长度的初始定义
typedef struct{ //定义一个结构体ElemType *data; //动态分配数组的指针int MaxSize,length; //顺序表最大容量,当前个数
}SeqList; //结构体名
动态分配和静态分配最主要的区别在于静态分配的是数组,动态分配的是指针。指针存储地址,当需要用到数据存储的时候再申请空间。
C语言动态分配语句:
L.data=(ElemType*)malloc(sizeof(ElemType)*InitSize);
3、插入
bool ListInsert(SqList &L,int i,ElemType e){
//设置成bool类型函数,若插入成功返回true,否则返回falseif(i<1||i>L.length+1)//判断i的范围是否有效return false;if(L.length>=MaxSize)//当前存储空间已满,不能插入return false;for(int j=L.length;j>=i;j--)//将第i个元素之后的元素后移L.data[j]=L.data[j-1];L.data[i-1]=e; //在位置i处放入eL.length++; //线性表长度加1return true;
}
4、删除
bool ListDelete(SqList &L,int i,Elemtype &e){//引用e,将删除的数赋值给eif(i<1||i>L.length)//判断i的范围是否有效return false;e=L.data[i-1]; //将被删除的元素赋值给efor(int j=i;j<L.length;j++)//将i位置后的元素前移L.data[j-1]=L.data[j];L.length--; //线性表长度减1return true;
}
5、查找
int LocateElem(SqList L,ElemType e){int i;for(i=0;i<L.length;i++)if(L.data[i]==e)return i+1;//i是数组下标,i+1是位序return 0;//查找失败退出循环
}
线性表的链式表示
由于顺序表的插入、删除操作需要移动大量的元素,影响了运行效率,由此引入了线性表的链式存储。链式存储线性表时,不需要使用地址连续的存储单元,即它不要求逻辑上相邻的两个元素在物理位置上也相邻,它是通过 “ 链 ” 建立起数据元素之间的逻辑关系,因此,对线性表的插入、删除不需要移动元素,而只需要修改指针。
线性表的链式存储又称为单链表,它是指通过一组任意的存储单元来存储线性表中的数据元素。为了建立起数据元素之间的线性关系,对每个链表结点,除了存放元素自身的信息之外,还需要存放一个指向其后继的指针。单链表结点结构如下图,其中,data 为数据域,存放数据元素;next 为指针域,存放其后继结点的地址。
单链表
头插法建立单链表
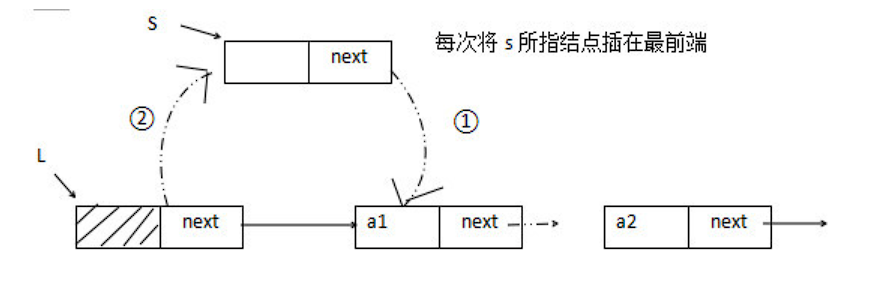
LinkList CreateList1(LinkList &L){//从表尾到表头逆向建立单链表 L ,每次均在头结点之后插入元素LNode *s ;int x ;L = ( LinkList ) malloc ( sizeof( LNode ) ) ; // 创建头结点L->next = NULL ; // 初始为空链表scanf ( " %d " , &x) ; // 输入结点的值while( x!= 9999){ // 输入9999 表示结束s = ( LNode * ) malloc ( sizeof( LNode ) ) ; // 创建新结点s->data = x ;s->next = L->next; // 将新结点插入表中,L为头指针L->next = s ;scanf ( " %d " , &x) ; } // while 结束return L;}
采用头插法建立单链表,读入数据的顺序与生成的链表中元素的顺序是相反的。每个结点插入的时间为 O(1) , 设单链表长为 n , 则总的时间复杂度为 O( n ) 。
采用尾插法建立单链表
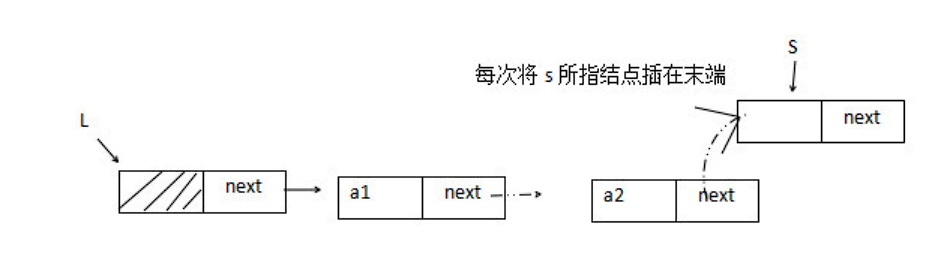
LinkList CreateList2( LinkList &L){// 从表头到表尾正向建立单链表 L ,每次均在表尾插入元素int x ; // 设置元素类型为整型L = ( LinkList ) malloc( sizeof( LNode ) ) ;LNode *s , *r = L ; // r 为表尾指针scanf( " %d " , &x ) ; // 输入结点的值while( x!= 9999){ // 输入 9999 表示结束s = ( LNode * ) malloc(sizeof( LNode ) ) ;s->data = x;r-next = s ;r = s ; // r 指向新的表尾结点scanf( " %d " , &x ) ;}r->next = NULL; // 尾结点指针置空return L ;}
按序号查找结点值
LNode * GetElem( LinkList L , int i ){// 本算法取出单链表 L (带头结点)中第 i 个位置的结点指针int j = 1 ; // 计数,初始为1,即指向第一个结点LNode * p = L->next ; // 头结点指针赋给 pif ( i == 0 ){return L; // 如果 i 等于 0 , 则返回头结点}if ( i < 1 ){return NULL; // 若 i 无效,则返回 NULL}while( p && j < i ){p = p->next ;j++;}return p ; // 返回第 i 个结点的指针,如果 i大于表长,}按值查找结点
LNode * LocateElem ( LinkList L , ElemType e ){//本算法直接查找单链表 L (带头结点)中数据域值等于 e 的结点指针,否则返回 NULLLNode * p = L->next ;while( p != NULL && P->data != e){ // 从 第 1 个结点开始查找 data 域为 e 的结点p = p->next ;}return p ; // 找到返回该结点指针,否则返回 NULL}插入结点操作
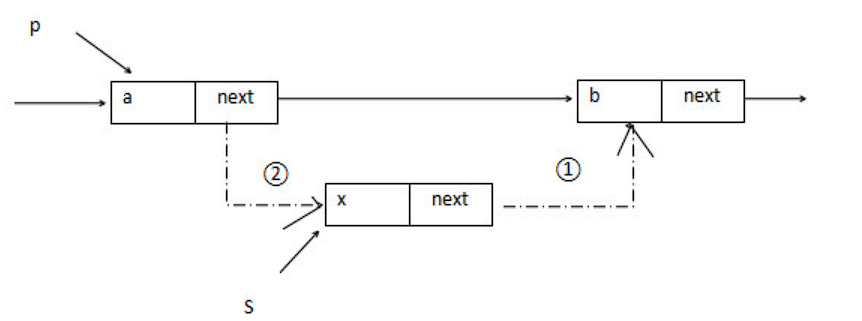
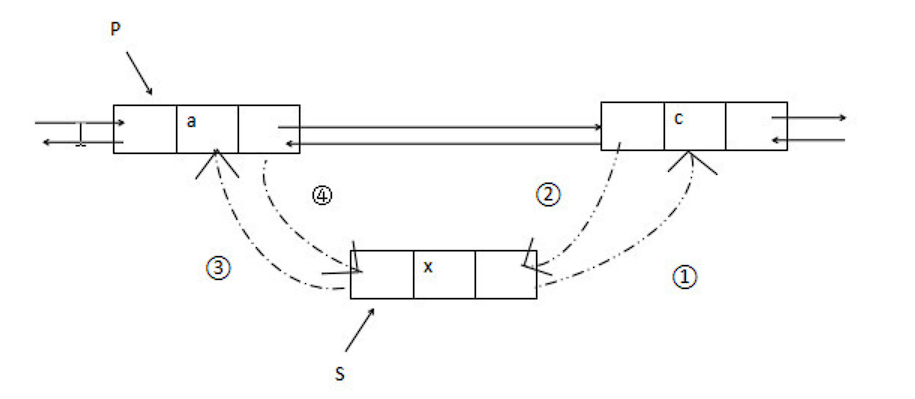
// 将 *s 结点插入到 *p 之前的主要代码片段s->next = p->next ; // 修改指针域,不能颠倒p->next = s ;temp = p->data ; // 交换数据域部分p->data = s->data ;s->data = temp ;
删除结点操作
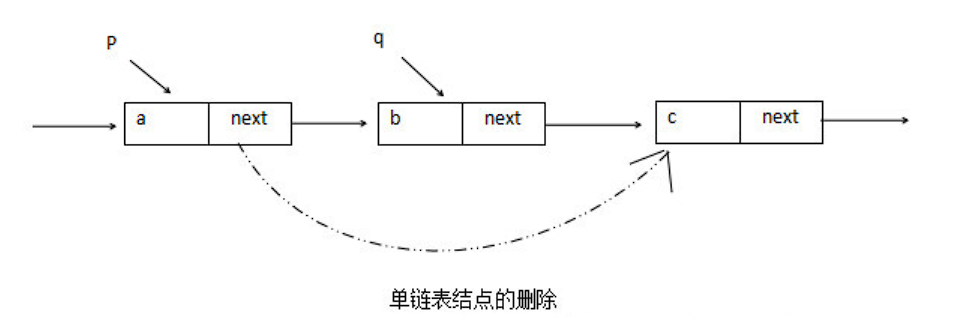
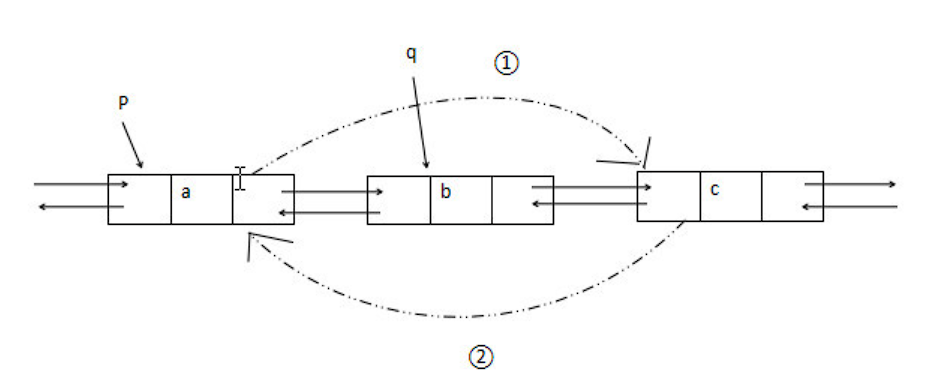
q = p->next ; // 令 q 指向 *p 的后继结点p->data = p->next->data; // 用后继结点中的数据覆盖要删除结点的数据p->next = q->next ; // 将 *q 结点从链中 “ 断开 ”free( q ) ; // 释放后继结点的存储空间
双链表
单链表结点中只有一个指向其后继的指针,这使得单链表只能从头结点依次顺序地向后遍历。
若要访问某个结点的前驱结点(插入、删除操作时),只能从头开始遍历,访问后继结点的时间复杂度为 O(1) , 访问前驱结点的时间复杂度为 O( n ) 。为了克服单链表的删除缺点,引入了双链表,双链表结点中有两个指针 prior 和 next ,分别指向其前驱结点和后继结点。
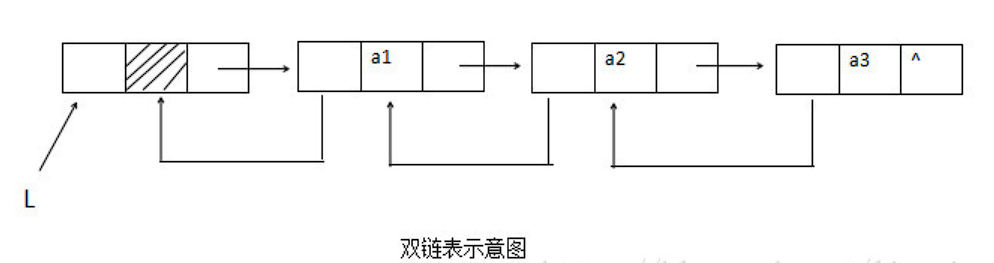
typedef struct DNode { // 定义双链表结点类型ElemType data ; // 数据域struct DNode *prior , * next ; // 前驱和后继指针}DNode , * DLinkList ;
双链表的插入操作

双链表的删除操作

循环链表
循环单链表
循环单链表和单链表的区别在于,表中最后一个结点指针不是 NULL ,而改为指向头结点,从而整个链表形成了一个环,如下图所示:

在循环单链表中,表尾结点 *r 的 next 域指向 L ,故表中没有指针域为 NULL 的结点,因此,循环单链表的判空条件不是头结点的指针是否为空,而是它是否等于头指针。 循环单链表的插入、删除算法与单链表几乎一样,所以不同的是如果操作是在表尾进行,则执行的操作不同,以让单链表继续保持循环的性质。当然,正是因为循环单链表是一个 “ 环 ” ,因此,在任何一个位置的插入和删除操作都是等价的,无须判断是否是表尾。在单链表中只能从表头结点开始往后顺序遍历整个链表,而循环单链表可以从表中的任一结点开始遍历整个链表。有时对单链表常做的操作是在表头和表尾进行的,此时可以对循环单链表不设头指针而仅设尾指针,从而使得操作效率更高。其原因是若设的是头指针,对表尾进行操作需要 O( n ) 的时间复杂度,而如果设的是尾指针 r , r->next 即为头指针,对于表头与表尾进行 操作都只需要 O( 1 ) 的时间复杂度。
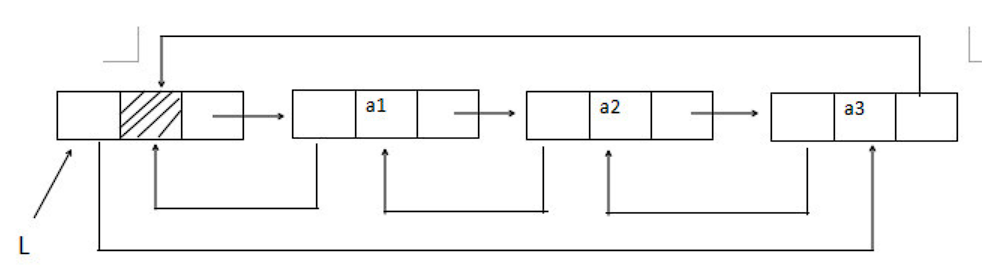
循环双链表
由循环单链表的定义不难推出循环双链表,不同的是在循环双链表中,头结点的 prior 指针还要指向表尾结点,如下图所示:
栈
栈是一种特殊的线性表,仅允许在表的一端进行插入和删除运算。这一端被称为栈顶(top),相对地,把另一端称为栈底(bottom)。向一个栈插入新元素又称作进栈、入栈或压栈(push),它是把新元素放到栈顶元素的上面,使之成为新的栈顶元素;从一个栈删除元素又称作出栈或退栈(pop),它是把栈顶元素删除掉,使其相邻的元素成为新的栈顶元素。所以栈具有“后入先出”的特点(LIFO)。
顺序存储
一般的,把数组的第一个位置[0]作为栈底,再单独定义一个变量指示栈顶:
/* 顺序栈结构 */
typedef int SElemType;
typedef struct
{SElemType data[MAXSIZE];int top; /* 用于栈顶指针 */
}SqStack;
/* 构造一个空栈S */
Status InitStack(SqStack *S)
{ /* S.data=(SElemType *)malloc(MAXSIZE*sizeof(SElemType)); */S->top=-1;return OK;
}/* 把S置为空栈 */
Status ClearStack(SqStack *S)
{ S->top=-1;return OK;
}/* 若栈S为空栈,则返回TRUE,否则返回FALSE */
Status StackEmpty(SqStack S)
{ if (S.top==-1)return TRUE;elsereturn FALSE;
}/* 返回S的元素个数,即栈的长度 */
int StackLength(SqStack S)
{ return S.top+1;
}/* 若栈不空,则用e返回S的栈顶元素,并返回OK;否则返回ERROR */
Status GetTop(SqStack S,SElemType *e)
{if (S.top==-1)return ERROR;else*e=S.data[S.top];return OK;
}/* 插入元素e为新的栈顶元素 */
Status Push(SqStack *S,SElemType e)
{if(S->top == MAXSIZE -1) /* 栈满 */{return ERROR;}S->top++; /* 栈顶指针增加一 */S->data[S->top]=e; /* 将新插入元素赋值给栈顶空间 */return OK;
}/* 若栈不空,则删除S的栈顶元素,用e返回其值,并返回OK;否则返回ERROR */
Status Pop(SqStack *S,SElemType *e)
{ if(S->top==-1)return ERROR;*e=S->data[S->top]; /* 将要删除的栈顶元素赋值给e */S->top--; /* 栈顶指针减一 */return OK;
}/* 从栈底到栈顶依次对栈中每个元素显示 */
Status StackTraverse(SqStack S)
{int i;i=0;while(i<=S.top){visit(S.data[i++]);}printf("\n");return OK;
}
链式存储
在栈的链式结构实现中,一般把链表的头指针做为栈顶,按照先后顺序来看的,这种定义与数组正好是反过来的,这是由于在顺序结构中,查找是非常方便的,插入和移动不方便。但是链式结构只知道头指针,查找不方便,但是插入方便,而对于栈而言,我们需要知道栈顶的位置,所以就干脆把链表头指针作为栈顶吧,同时由于插入方便,每次在链的开头插入一个结点很容易。
typedef int SElemType;
/* 链栈结构 */
typedef struct StackNode
{SElemType data;struct StackNode *next;
}StackNode,*LinkStackPtr;
/* 构造一个空栈S */
Status InitStack(LinkStack *S)
{ S->top = (LinkStackPtr)malloc(sizeof(StackNode));if(!S->top)return ERROR;S->top=NULL;S->count=0;return OK;
}/* 把S置为空栈 */
Status ClearStack(LinkStack *S)
{ LinkStackPtr p,q;p=S->top;while(p){ q=p;p=p->next;free(q);} S->count=0;return OK;
}/* 若栈S为空栈,则返回TRUE,否则返回FALSE */
Status StackEmpty(LinkStack S)
{ if (S.count==0)return TRUE;elsereturn FALSE;
}/* 返回S的元素个数,即栈的长度 */
int StackLength(LinkStack S)
{ return S.count;
}/* 若栈不空,则用e返回S的栈顶元素,并返回OK;否则返回ERROR */
Status GetTop(LinkStack S,SElemType *e)
{if (S.top==NULL)return ERROR;else*e=S.top->data;return OK;
}/* 插入元素e为新的栈顶元素 */
Status Push(LinkStack *S,SElemType e)
{LinkStackPtr s=(LinkStackPtr)malloc(sizeof(StackNode)); s->data=e; s->next=S->top; /* 把当前的栈顶元素赋值给新结点的直接后继,见图中① */S->top=s; /* 将新的结点s赋值给栈顶指针,见图中② */S->count++;return OK;
}/* 若栈不空,则删除S的栈顶元素,用e返回其值,并返回OK;否则返回ERROR */
Status Pop(LinkStack *S,SElemType *e)
{ LinkStackPtr p;if(StackEmpty(*S))return ERROR;*e=S->top->data;p=S->top; /* 将栈顶结点赋值给p,见图中③ */S->top=S->top->next; /* 使得栈顶指针下移一位,指向后一结点,见图中④ */free(p); /* 释放结点p */ S->count--;return OK;
}
/* 从栈底到栈顶依次对栈中每个元素显示 */
Status StackTraverse(LinkStack S)
{LinkStackPtr p;p=S.top;while(p){visit(p->data);p=p->next;}printf("\n");return OK;
}
队列
队列的定义
队列(queue) 是只允许在一端进行插入操作,而在另一端进行删除操作的线性表。
队列是一种先进先出(First In First Out)的线性表,简称FIFO。允许插入的一端称为队尾,允许删除的一端称为队头。
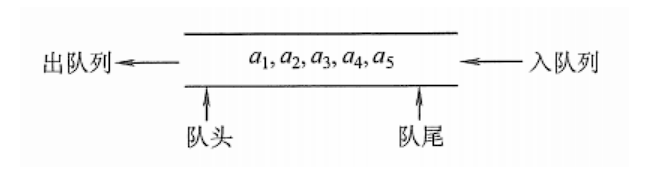
队头(Front):允许删除的一端,又称队首。
队尾(Rear):允许插入的一端。
空队列:不包含任何元素的空表。
队列的常见基本操作
InitQueue(&Q):初始化队列,构造一个空队列Q。
QueueEmpty(Q):判队列空,若队列Q为空返回true,否则返回false。
EnQueue(&Q, x):入队,若队列Q未满,将x加入,使之成为新的队尾。
DeQueue(&Q, &x):出队,若队列Q非空,删除队头元素,并用x返回。
GetHead(Q, &x):读队头元素,若队列Q非空,则将队头元素赋值给x。
队列的顺序存储结构
顺序队列
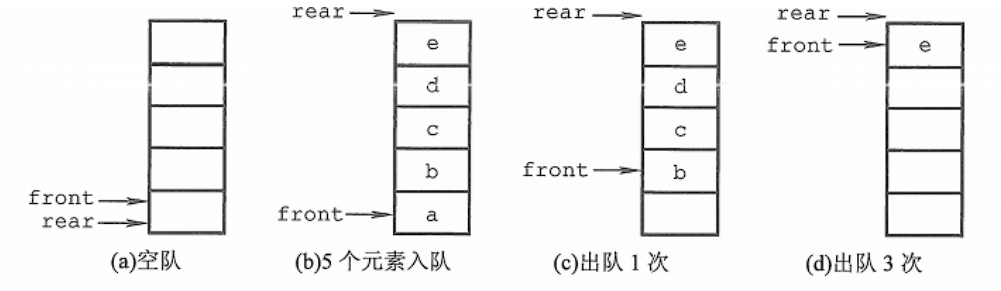
队列的顺序实现是指分配一块连续的存储单元存放队列中的元素,并附设两个指针:队头指针 front指向队头元素,队尾指针 rear 指向队尾元素的下一个位置。
#define MAXSIZE 50 //定义队列中元素的最大个数
typedef struct{ElemType data[MAXSIZE]; //存放队列元素int front,rear;
}SqQueue;初始状态(队空条件):Q->front == Q->rear == 0。
进队操作:队不满时,先送值到队尾元素,再将队尾指针加1。
出队操作:队不空时,先取队头元素值,再将队头指针加1。
循环队列
解决假溢出的方法就是后面满了,就再从头开始,也就是头尾相接的循环。我们把队列的这种头尾相接的顺序存储结构称为循环队列。
当队首指针Q->front = MAXSIZE-1后,再前进一个位置就自动到0,这可以利用除法取余运算(%)来实现。
初始时:Q->front = Q->rear=0。
队首指针进1:Q->front = (Q->front + 1) % MAXSIZE。
队尾指针进1:Q->rear = (Q->rear + 1) % MAXSIZE。
队列长度:(Q->rear - Q->front + MAXSIZE) % MAXSIZE。
出队入队时,指针都按照顺时针方向前进1,如下图所示:
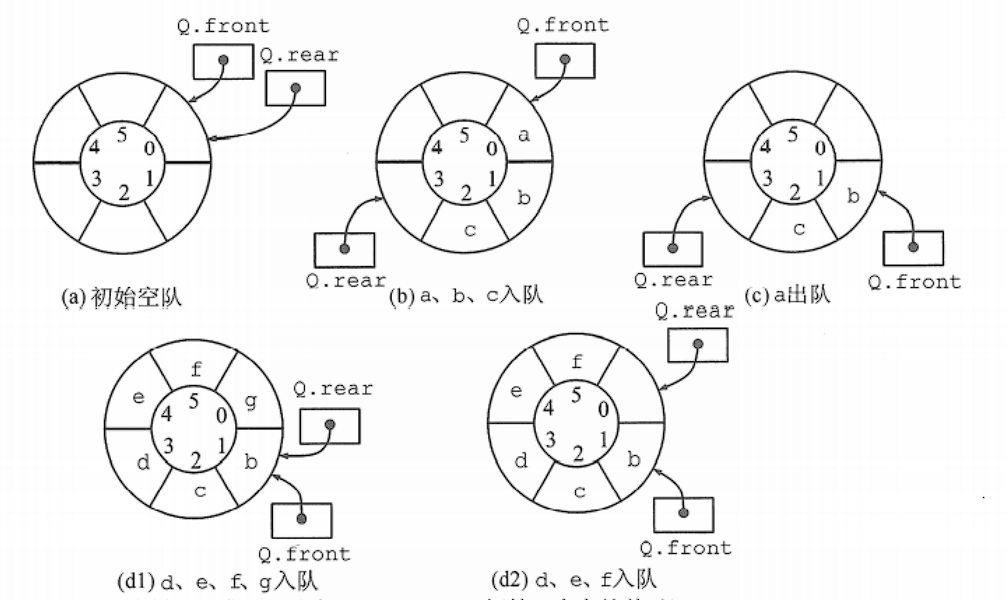 循环队列队空和队满的判断条件
循环队列队空和队满的判断条件
队满条件: (Q->rear + 1)%Maxsize == Q->front
队空条件仍: Q->front == Q->rear
队列中元素的个数: (Q->rear - Q ->front + Maxsize)% Maxsize
类型中增设表示元素个数的数据成员。这样,队空的条件为 Q->size == O ;队满的条件为 Q->size == Maxsize 。这两种情况都有 Q->front == Q->rear
类型中增设tag 数据成员,以区分是队满还是队空。tag 等于0时,若因删除导致 Q->front == Q->rear ,则为队空;tag 等于 1 时,若因插入导致 Q ->front == Q->rear ,则为队满。
循环队列常见基本算法
(1)循环队列的顺序存储结构
typedef int ElemType; //ElemType的类型根据实际情况而定,这里假定为int
#define MAXSIZE 50 //定义元素的最大个数
/*循环队列的顺序存储结构*/
typedef struct{ElemType data[MAXSIZE];int front; //头指针int rear; //尾指针,若队列不空,指向队列尾元素的下一个位置
}SqQueue;(2)循环队列的初始化
/*初始化一个空队列Q*/
Status InitQueue(SqQueue *Q){Q->front = 0;Q->rear = 0;return OK;
}(3)循环队列判队空
/*判队空*/
bool isEmpty(SqQueue Q){if(Q.rear == Q.front){return true;}else{return false;}
}(4)求循环队列长度
/*返回Q的元素个数,也就是队列的当前长度*/
int QueueLength(SqQueue Q){return (Q.rear - Q.front + MAXSIZE) % MAXSIZE;
}(5)循环队列入队
/*若队列未满,则插入元素e为Q新的队尾元素*/
Status EnQueue(SqQueue *Q, ElemType e){if((Q->rear + 1) % MAXSIZE == Q->front){return ERROR; //队满}Q->data[Q->rear] = e; //将元素e赋值给队尾Q->rear = (Q->rear + 1) % MAXSIZE; //rear指针向后移一位置,若到最后则转到数组头部return OK;
}(6)循环队列出队
/*若队列不空,则删除Q中队头元素,用e返回其值*/
Status DeQueue(SqQueue *Q, ElemType *e){if(isEmpty(Q)){return REEOR; //队列空的判断}*e = Q->data[Q->front]; //将队头元素赋值给eQ->front = (Q->front + 1) % MAXSIZE; //front指针向后移一位置,若到最后则转到数组头部
}队列的链式存储结构
链队列
队列的链式存储结构表示为链队列,它实际上是一个同时带有队头指针和队尾指针的单链表,只不过它只能尾进头出而已。
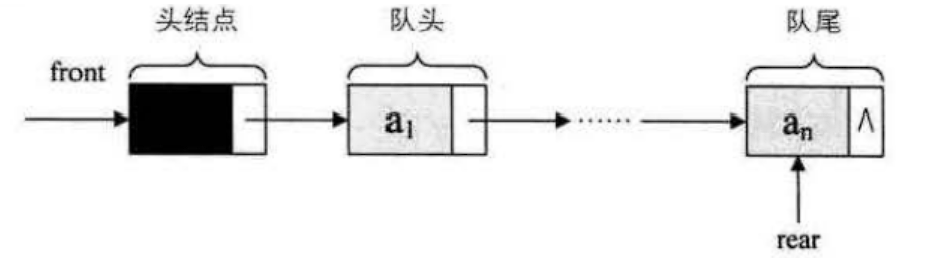
空队列时,front和real都指向头结点。
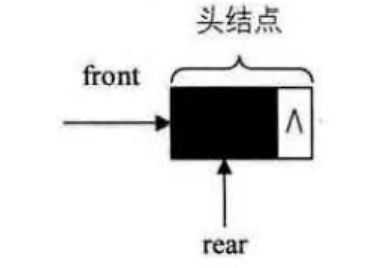
链队列常见基本算法
(1)链队列存储类型
/*链式队列结点*/
typedef struct {ElemType data;struct LinkNode *next;
}LinkNode;
/*链式队列*/
typedef struct{LinkNode *front, *rear; //队列的队头和队尾指针
}LinkQueue;当Q->front == NULL 并且 Q->rear == NULL 时,链队列为空。
(2)链队列初始化
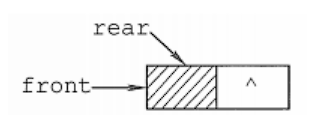
void InitQueue(LinkQueue *Q){Q->front = Q->rear = (LinkNode)malloc(sizeof(LinkNode)); //建立头结点Q->front->next = NULL; //初始为空
}(3)链队列入队
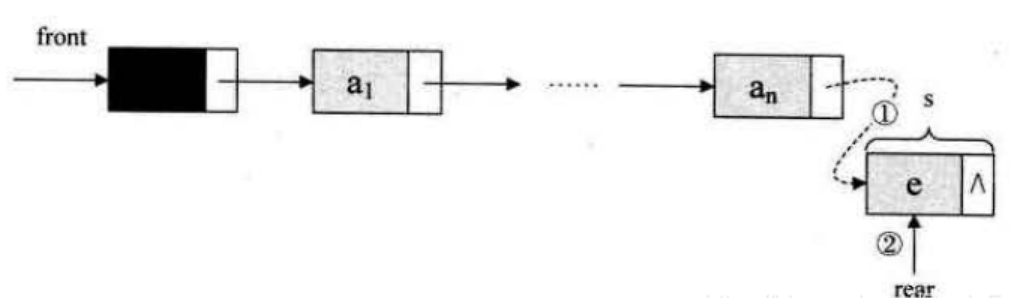
Status EnQueue(LinkQueue *Q, ElemType e){LinkNode s = (LinkNode)malloc(sizeof(LinkNode));s->data = e;s->next = NULL;Q->rear->next = s; //把拥有元素e新结点s赋值给原队尾结点的后继Q->rear = s; //把当前的s设置为新的队尾结点return OK;
}(4)链队列出队
出队操作时,就是头结点的后继结点出队,将头结点的后继改为它后面的结点,若链表除头结点外只剩一个元素时,则需将rear指向头结点。
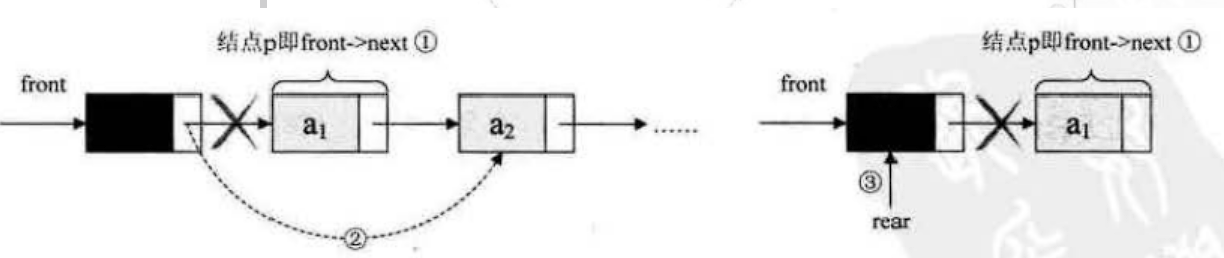
/*若队列不空,删除Q的队头元素,用e返回其值,并返回OK,否则返回ERROR*/
Status DeQueue(LinkQueue *Q, Elemtype *e){LinkNode p;if(Q->front == Q->rear){return ERROR;}p = Q->front->next; //将欲删除的队头结点暂存给p*e = p->data; //将欲删除的队头结点的值赋值给eQ->front->next = p->next; //将原队头结点的后继赋值给头结点后继//若删除的队头是队尾,则删除后将rear指向头结点if(Q->rear == p){ Q->rear = Q->front;}free(p);return OK;
}树
概念
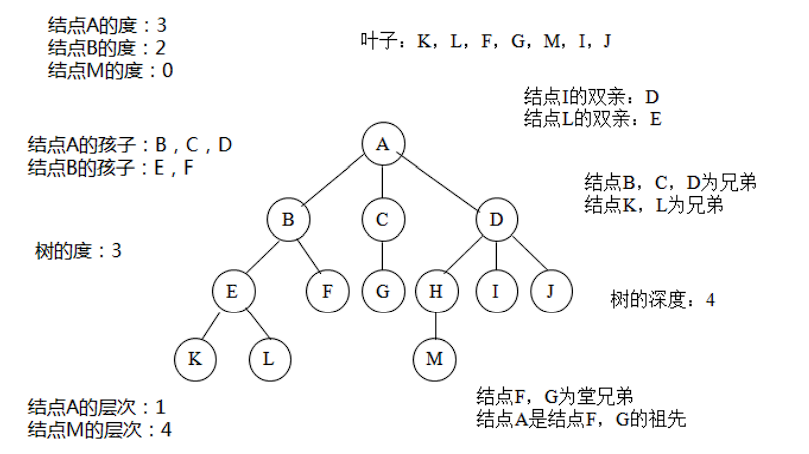
【树形结构】元素之间存在一对多的关系
【树】树是由根结点和若干棵子树构成的树形结构
【节点】结点是树中的数据元素
【父亲节点】当前结点的直接上级结点
【孩子节点】定义:孩子结点是指当前结点的直接下级结点
【兄弟节点】定义:兄弟结点是有相同父结点的结点
【堂兄弟节点】定义:堂兄弟结点是父结点在同一层的结点
【祖先节点】定义: 祖先结点是当前结点的直接及间接上级结点
【子孙节点】定义: 子孙结点是当前结点的直接及间接下级结点
【根结点】定义: 根结点是没有父结点的结点
【结点的度】:该结点有多少个子树
【树的度】:结点度的最大值。
【叶子节点】定义: 叶结点是度为0的结点
【分支节点】定义: 分支结点是度不为0的结点
【节点的度】结点的度是结点含有子树的个数
【节点的层次】定义: 结点的层次是从根结点到某结点所经路径上的层次数
【树的度】定义: 树的度是树内各结点度的最大值
【树的深度】定义: 树的深度是树中所有结点层次的最大值
二叉树
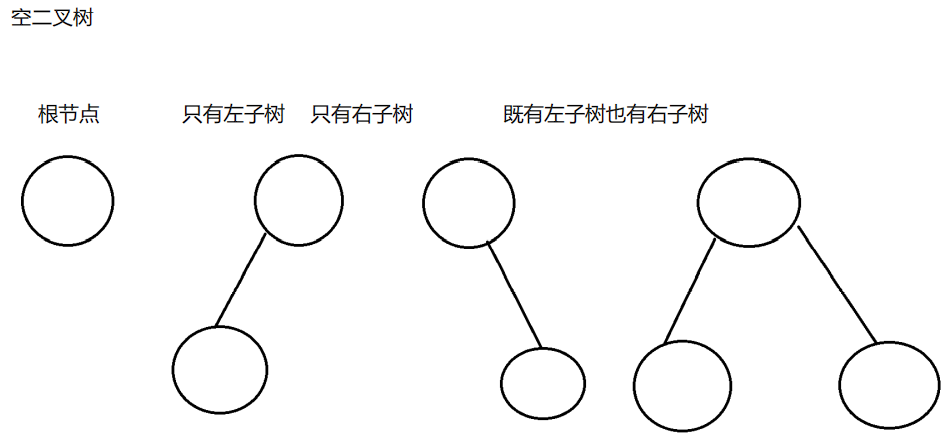
定义
每个节点最多有两棵子树,并且严格区分左右的树形结构
二叉树的概念
【左子树】左子树是以当前结点的左孩子结点作为根节点的子树
【右子树】右子树是以当前结点的右孩子结点作为根节点的子树
【满二叉树】满二叉树是最后一层是叶子结点,其余结点度是2的二叉树
在不增加层次的基础上,不能在添加节点的二叉树
【完全二叉树】完全二叉树是在一棵满二叉树基础上自左向右连续增加叶子结点得到的二叉树
完全二叉树是在一棵满二叉树基础上自右向左连续删除叶子结点得到的二叉树
叶子节点,只出现在最下两层,最下层的叶子节点,都是左连续出现的,如果倒数第二层有叶子节点,
一定是右侧连续的
满二叉树一定是完全二叉树,完全二叉树不一定的满二叉树。
二叉树形态
二叉树的性质
第i层,最多有2^i-1个结点
有i层的二叉树,最多能有2^i-1个结点
假定:度0的结点数为N0,度为1的结点数为N1,度为2的结点数为N2
总度数:N1+2N2
总结点数:N0+N1+N2<===>N1+2N2+1
N0=N2+1
叶子结点的个数=度为2的节点个数+1
二叉树的创建
typedef struct node
{
char data;
struct node *left;
struct node *right;
}node;#include "tree.h"
//创建结点
node *create_node(char data)
{
node *p=(node*)malloc(sizeof(node));
p->data=data;
return p;
}
//创建二叉树
node *create_tree()
{
//实现,通过终端输入#表示子树结束
char c='\0';
scanf("%c",&c);
getchar();//吸收垃圾字符
if(c=='#')
{
return NULL;
}
//如果传入的数据有意义,就创建结点
node *T=create_node(c);
//二叉树的每棵子树都要调用创建树的函数
T->left=create_tree();
T->right=create_tree();
return T;
}
//先序遍历:根左右
void pri_node(node *T)
{
if(T==NULL)
{
return;
}
printf("%c",T->data);
pri_node(T->left);
pri_node(T->right);
}
//中序遍历
void in_order(node *T)
{
if(T==NULL)
{
return;
}
in_order(T->left);
printf("%c",T->data);
in_order(T->right);
}
//后序遍历
void post_node(node *T)
{
if(T==NULL)
{
return;
}
post_node(T->left);
post_node(T->right);
printf("%c",T->data);
}相关文章:
数据结构(一)(嵌入式学习)
数据结构干货总结(一)基础线性表的顺序表示线性表的链式表示单链表双链表循环链表循环单链表循环双链表栈顺序存储链式存储队列队列的定义队列的常见基本操作队列的顺序存储结构顺序队列循环队列队列的链式存储结构树概念二叉树二叉树的创建基础 数据&a…...

合成复用原则-快速理解
什么是合成/聚合复用原则? 合成/聚合复用原则是在一个新的对象里面使用一些已有的对象,使之成为新对象的一部分;新的对象通过向这些对象的委派达到复用已有功能的目的。 简述为:要尽量使用合成/聚合,尽量不要使用继承…...

Scala04 方法与函数
Scala04 方法与函数 Scala 中的也有方法和函数的概念。 Scala中的 方法 是类的一部分。 Scala中的 函数 是一个对象,可以赋值给变量。 在类中定义的函数就是方法 4.1 方法 Scala 中方法 与 Java 中类似,是组成类的一部分 4.1.1 语法结构 格式&#x…...
)
XJTUSE专业课与实验指南(已经开源)
文章目录XJTUSE专业课与实验指南大一小学期大二上课程实验大二下课程实验大二小学期大三上课程实验大三下课程实验XJTUSE专业课与实验指南 github地址:https://github.com/yijunquan-afk/XJTUSE-NOTES.git 📄写在前面 1️⃣ 本篇文章仅供参考࿰…...
Spring面试专题
讲师:邓澎波 Spring面试专题 1.Spring应该很熟悉吧?来介绍下你的Spring的理解 1.1 Spring的发展历程 先介绍Spring是怎么来的,发展中有哪些核心的节点,当前的最新版本是什么等 通过上图可以比较清晰的看到Spring的各个时间版本…...

【truncate、delete和drop的6大区别!】
在MySQL中,truncate、delete和drop是三个常用的命令,它们可以用于删除表或表中的数据,下面是它们的六大区别: 语法不同: truncate和delete是SQL语句,drop是DDL(数据定义语言)语句。…...

如何入门Vue:掌握Vue的核心概念和基本用法
Vue是一种流行的JavaScript框架,它可以让开发者更容易地构建响应式的用户界面。Vue的设计理念是简单易懂,它的核心库只关注视图层,可以与其它库或现有项目很好地结合。在本文中,我将介绍Vue的基础概念和如何开始使用Vue。Vue的基本…...

APM飞控使用动捕等外部定位
本文初次写于2023.03.03,pixhawk飞控应该是刷写了ArduPilot 4.1以上的版本。 机载计算机通过WIFI和vrpn_ros_client获取动捕系统(vicon或者nokov)的无人机定位数据(x,y,z四元数),然…...
【vulhub漏洞复现】CVE-2013-4547 Nginx 文件名逻辑漏洞
一、漏洞详情影响版本 Nginx 0.8.41 ~ 1.4.3 / 1.5.0 ~ 1.5.7通过%00截断绕过后缀名的限制,使上传的php内容文件被解析执行。当Nginx得到一个用户请求时,首先对url进行解析,进行正则匹配,如果匹配到以.php后缀结尾的文件名&#x…...

Kubernetes中配置livenessProbe、readinessProbe和startupProbe
livenessProbe、readinessProbe和startupProbe作用kubelet使用livenessProbe(存活探针)来判断何时重启容器。例如,当程序中产生死锁的时候,程序还在运行,通过livenessProbe可以检测到程序已不能正常提供服务。这种情况…...
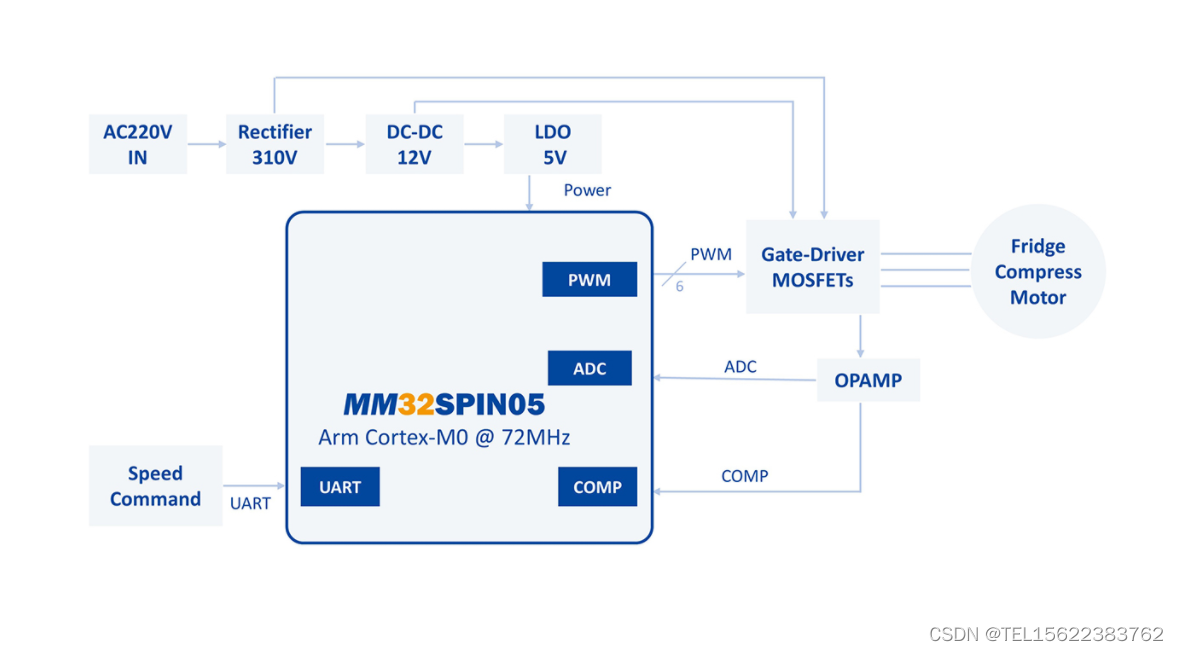
冰箱压缩机 方案
压缩机是制冷系统的心脏,它从吸气管吸入低温低压的制冷剂气体,通过电机运转带动活塞对其进行压缩后,向排气管排出高温高压的制冷剂气体,为制冷循环提供动力,从而实现压缩→冷凝→膨胀→蒸发 ( 吸热 ) 的制冷循环。压缩…...

一文带你入门,领略angular风采(上)!!!
话不多说,上代码!!! 一、脚手架创建项目 1.安装脚手架指令 npm install -g angular/cli 2.创建项目 ng new my-app(ng new 项目名) 3.功能选择 4.切换到创建好的项目上 cd my-app 5.安装依赖 npm install 6.运行项目 npm start或…...

SpringMVC 参数绑定(视图传参到控制器)
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...

Three.js高级应用--利用Three.js+WebGL实现fbx和obj格式模型的自定义加载
通过对webgl和three.js的不断学习与实践,在三维应用场景建设过程中,利用Three.js与webgl配合可以实现大部分三维场景的应用需求,这一篇主要讲述如何利用Three.js加载已有的模型,支持的三维模型格式有.fbx和.obj,同时.o…...

Go struct
每个无名结构体类型的字面形式均由struct关键字开头,后面跟着用一对大括号{},其中包裹着的一系列字段(field)声明。 一般来说,每个字段声明由一个字段名和字段类型组成。一个结构体类型的字段数目可以为0。struct {tit…...

Redis多线程模型源码解析
1. 配置启用多线程 默认情况下多线程是默认关闭的,如果想要启动多线程,需要在配置文件中做适当的修改。 修改redis.conf 文件如下 io-threads 4 #启用的 io 线程数量 io-threads-do-reads yes #读请求也使用io线程2 源码解析 进入到Redis的main入口函…...

搭建zabbix4.0监控服务实例
一.Zabbix服务介绍 1.1服务介绍 Zabbix是基于WEB界面的分布式系统监控的开源解决方案,Zabbix能够监控各种网络参数,保证服务器系统安全稳定的运行,并提供灵活的通知机制让SA快速定位并解决存在的各种问题。 1.2 Zabbix优点 Zabbix分布式监…...

Xcode 系统崩溃问题01
参考链接:https://www.5axxw.com/questions/content/x2zlpx 问题:崩溃提示: Message from debugger: The LLDB RPC server has crashed. You may need to manually terminate your process. The crash log is located in ~/Library/Logs/Dia…...
SpringMVC文件上传、下载、国际化配置
Java知识点总结:想看的可以从这里进入 目录3.6、文件上传、下载3.6.1、文件上传3.6.2、文件下载3.7、国际化配置3.6、文件上传、下载 3.6.1、文件上传 form 表单想要具有文件上传功能,其必须满足以下 3 个条件。 form 表单的 method 属性必须设置为 p…...

计算机图形学07:有效边表法的多边形扫描转换
作者:非妃是公主 专栏:《计算机图形学》 博客地址:https://blog.csdn.net/myf_666 个性签:顺境不惰,逆境不馁,以心制境,万事可成。——曾国藩 文章目录专栏推荐专栏系列文章序一、算法原理二、…...

喜马拉雅音频下载工具:技术实现与高效使用指南
喜马拉雅音频下载工具:技术实现与高效使用指南 【免费下载链接】xmly-downloader-qt5 喜马拉雅FM专辑下载器. 支持VIP与付费专辑. 使用GoQt5编写(Not Qt Binding). 项目地址: https://gitcode.com/gh_mirrors/xm/xmly-downloader-qt5 在数字化学习与娱乐场景…...

5分钟搞定KEPserver V6配置:Java读取西门子PLC数据的保姆级教程
5分钟极速配置KEPserver V6与Java通信:西门子S7-1500数据采集实战指南 当工业现场的PLC数据需要与IT系统集成时,OPC技术栈往往是最直接的选择。但传统OPC配置过程繁琐的文档和复杂的依赖管理,常让工程师在项目初期耗费大量时间在环境搭建上。…...

从零开始:在VMware虚拟机中部署Qwen3.5-4B-Claude-4.6-Opus-Reasoning-Distilled-GGUF进行开发测试
从零开始:在VMware虚拟机中部署Qwen3.5-4B-Claude-4.6-Opus-Reasoning-Distilled-GGUF进行开发测试 1. 准备工作与环境搭建 在开始之前,我们需要准备好必要的软件和资源。首先确保你的主机系统满足以下要求: 至少16GB内存(推荐…...
】五、从逻辑门到LEG:指令集与条件跳转的构建)
【图灵完备(Turing Complete)】五、从逻辑门到LEG:指令集与条件跳转的构建
1. 从逻辑门到处理器:LEG架构的诞生之路 记得我第一次用面包板搭建简单逻辑电路时,连个LED灯闪烁都要折腾半天。而现在我们要做的,是把这些基础逻辑门像乐高积木一样拼接成真正的处理器核心。LEG架构的设计初衷就是要解决原始图灵机指令宽度受…...

Agent-S:重新定义人机协作的智能体框架技术解析
Agent-S:重新定义人机协作的智能体框架技术解析 【免费下载链接】Agent-S Agent S: an open agentic framework that uses computers like a human 项目地址: https://gitcode.com/GitHub_Trending/ag/Agent-S 在数字化转型加速的今天,人机协作的…...

突破设备边界:开源串流解决方案Sunshine革新跨设备游戏共享体验
突破设备边界:开源串流解决方案Sunshine革新跨设备游戏共享体验 【免费下载链接】Sunshine Sunshine: Sunshine是一个自托管的游戏流媒体服务器,支持通过Moonlight在各种设备上进行低延迟的游戏串流。 项目地址: https://gitcode.com/GitHub_Trending/…...

GTE-Pro行业落地:制造业设备维修手册语义检索替代传统目录树导航
GTE-Pro行业落地:制造业设备维修手册语义检索替代传统目录树导航 1. 引言:当维修师傅找不到说明书时 想象一下这个场景:工厂里一台关键设备突然报警停机,维修师傅小王满头大汗地站在机器旁。他记得这台设备的维修手册有上千页&a…...
)
全学科适用AI写作辅助网站排行榜(2026 实测推荐)
基于功能完整性、学术适配性、用户反馈及操作便捷性,以下是当前主流AI论文写作工具的实测排名,按综合使用价值从高到低依次呈现,并附上各平台的核心优势与适用人群。🏆 第一梯队:全流程学术解决方案(★★★…...

深度学习项目训练环境体验:基于专栏的实战环境,快速验证模型
深度学习项目训练环境体验:基于专栏的实战环境,快速验证模型 1. 环境概述与核心价值 深度学习项目开发过程中,环境配置往往是最耗时且最容易出问题的环节。本镜像基于《深度学习项目改进与实战》专栏预置了完整的开发环境,让开发…...

Wan2.2-I2V-A14B生产环境部署:Nginx反向代理与Docker Compose编排
Wan2.2-I2V-A14B生产环境部署:Nginx反向代理与Docker Compose编排 1. 部署目标与前置准备 在开始之前,我们先明确这次部署要实现的目标:通过Docker Compose编排Wan2.2-I2V-A14B模型服务及其依赖组件,使用Nginx作为反向代理&…...