大数据相关面试题
linux
常见linux高级命令?
- top、iotop
- netstat
- df -h
- jmap -heap
- tar
- rpm
- ps -ef
shell
用过的shell工具?
- awk Awk 命令详解 - 简书
awk是行处理器: 相比较屏幕处理的优点,在处理庞大文件时不会出现内存溢出或是处理缓慢的问题,通常用来格式化文本信息
- sort sort 命令详解 - 简书
- cut Linux cut 命令详解 - 简书
- sed 【现学现忘&Shell编程】— 35.sed命令(一) - 简书
写过哪些脚本
1.启停脚本

2. 单引号、双引号区别 单引号不解析里面变量的值,双引号解析里面变量值
hadoop
入门问题:常用端口号、常用配置
9870 hdfs访问端口;8088 yarn访问端口;19888JobHistory访问;剩下的是内部通信端口

HDFS
- 读写流程 HDFS的读写流程(面试重点)_简述hdfs的读写流程_你可以自己看的博客-CSDN博客
- 小文件危害 (1)存储 每个文件都必须占用一个NameNode存储元数据。每个NameNode大小150字节。小文件太多,占用空间。 (2)计算 默认的切片原则是每个文件单独切片,即使是1个字节的小文件也需要启动1个对应的maptask处理,每个maptask至少占用1G内存。切片的概念 HDFS的block和切片(split)的区别_贺雨蒙的博客-CSDN博客_hdfs切片
- 小文件怎么解决
(1)har归档 将多个小文件的NamNode进行合并
(2)CombineTextInputformat 把小文件放在一起切片计算
(3)JVM重用 启动一个JVM,计算多个文件。节省开启、关闭的开销。

MR shuffle 过程
案例举例整个过程 080_大数据第五阶段-Hadoop第三天_shuffle下_哔哩哔哩_bilibili
- hdfs中文件是以block块的形式存储,默认block大小为128M,如果电脑磁盘读写速度块,可以配置成246/512M都可以。
- 默认一个block对应一个split逻辑分区。可以配置成多个block对应一个split逻辑分区。
- split分区的数据按行存储。每行的数据调用自己编写的Map函数的逻辑,对数据进行处理。即图中的Map处理。
- map方法处理后的数据写入环形缓冲区。环形缓冲区默认时100M大小的内存,写到80%时异步线程spill溢出到磁盘,写的数据进行向剩下的20%写入。等20%写满时,80%空间基本已经spill结束空间已经空闲可以继续写入,再写满80%,重复spill。因此环形缓冲区可以保证不中断的存储数据。环形缓冲区底层时byte数组。
- 环形缓冲区溢出时会 排序、分区,甚至combine操作。
- 比如reducer为求最大值,那么就可以在此处提前进行combine求出每个分区的最大值。但是如果此时combine会对reduce的计算有影响,那么不进行combine。combine通过在map方法里面指定且溢出文件大于等于3个时才进行。
- 分区一般是根据对key hash 求模reduceTask数量确定分区位置。
6.对多个溢出文件进行归并操作。 每个分区排好序。

yarn
1.yarn工作机制、工作流程
mapreduce yarn流程图_YARN 运行机制分析_投资百晓生的博客-CSDN博客
mapreduce yarn流程图_YARN 运行机制分析_投资百晓生的博客-CSDN博客
2.调度器
大数据技术Hadoop——YARN_阳哥赚钱很牛的博客-CSDN博客
- 公平、容量调度器通常都是默认的1个队列,需要修改 yarn-site.xml中的配置项 yarn.resourcemanager.scheduler.class
- 公司一个yarn,此时根据一个部门一个申请一个队列,如果队列任务过多,可以格局任务重要性将不重要的任务降级使用。

kafka
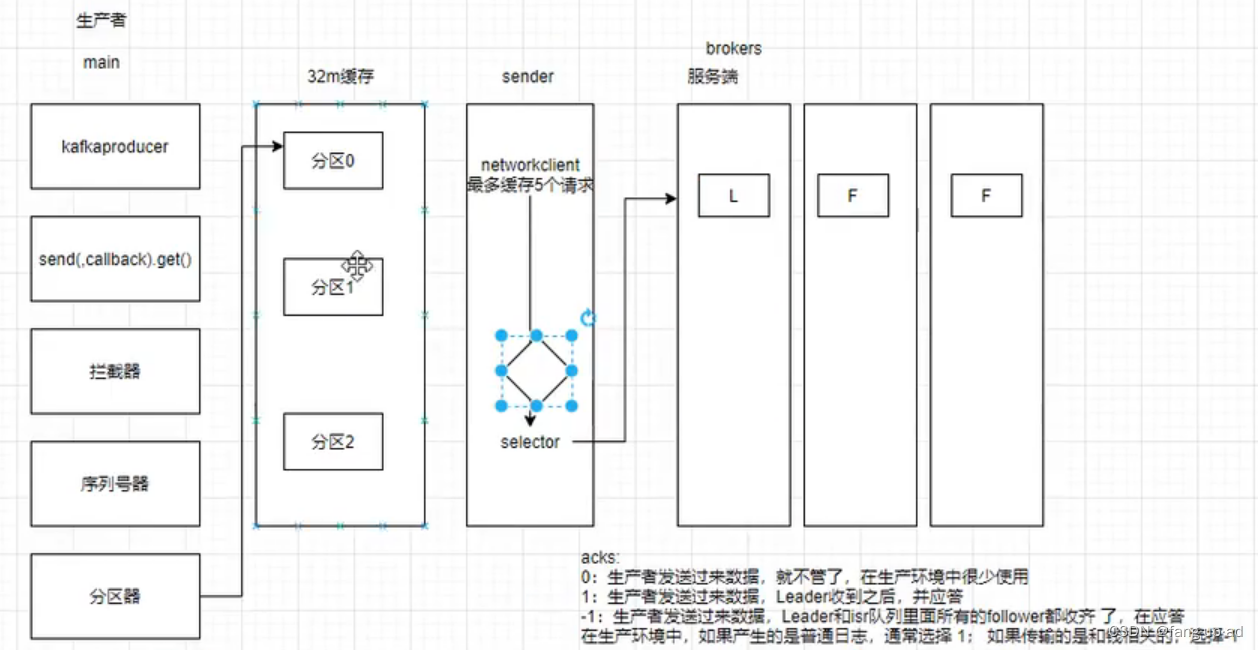
(1)生产者工作流程
生产者两个线程:main、sender
- 一个main线程,创建kafkaproducer,调用send方法。
- send方法异步发送,加上send().get()则同步发送。callback回调函数。
- 拦截器一般不用。
- 自定义序列化器,之所以不用java自带的序列化器,是因为自带的辅助属性太多浪费空间。常见数据类型kafka已经实现序列化器,自定义类需要自己实现序列化器。
- 分区器,决定把数据发送到哪个分区?(1)指定分区发送到指定分区 (2)未指定分区,按照key的hash值取余分区数(3)没有指定分区和key,那么按照粘性分区。粘性分区random随机选择分区,直到16k满了或这一批数据发送完再random切换分区。
2.sender线程 专门用来发送数据
- 创建networkclient对象和broker通信。默认缓存5个发送数据的请求。比如给leader发送数据的一个请求,没有按时ack,那么发送缓存队列中的下一个请求。
- 底层发送数据使用selector nio发送数据
- 将数据发给leader,leader ack应答。如果leader正确收到,那么会删除缓存和分区中的数据,如果没正确收到,会重试,重试次数int最大值。
(2)brokers工作流程
- 每个broker启动后,会将id主车道zk中。
- controller 用来选择谁是leader,每个broker服务器都有。才开始是会随机一个broker的controller和zk的controller通信,选举谁是leader。根据lsr里面的ar顺序先后选择leader。并将leader的id记录在zk中。
- broker 会将topic的每个partition以多个segment存储,默认大小1G。每个segment包括为 .index .log .timestatmp 。.log存储具体数据,.index稀疏矩阵,没4kb数据存储一个索引 timestamp存储文件创建时间。
- lsr 记录能和leader正常通信的follow节点 正常通信是40s内有心跳。

消费者组消费流程
- 多个消费者根据配置的groupid来确定是一个消费者组。id对默认的分区数50取余的分区,向分区所在的消费者组协调器通信。consumer offset默认50个分区kafka consumer offset机制 - 简书
- 消费者全部发送joingroup信息。然后回复信息,随机选择消费者中某个作为leader ,将结果告知协调器。
- 协调器所有信息发送给消费者的leader,leader根据 range/粘性、roundin消费策略分配每个消费者的消费组。告知协调器,协调器告知所有消费者。
- 消费者每隔3s和协调器进行一次通信,超过45s没有通信;消费者如果超过5分钟没有再拉取数据,都会认为消费者挂掉,会再平衡。 再平衡会所有数据发送暂停,分配好在发送。 很不好
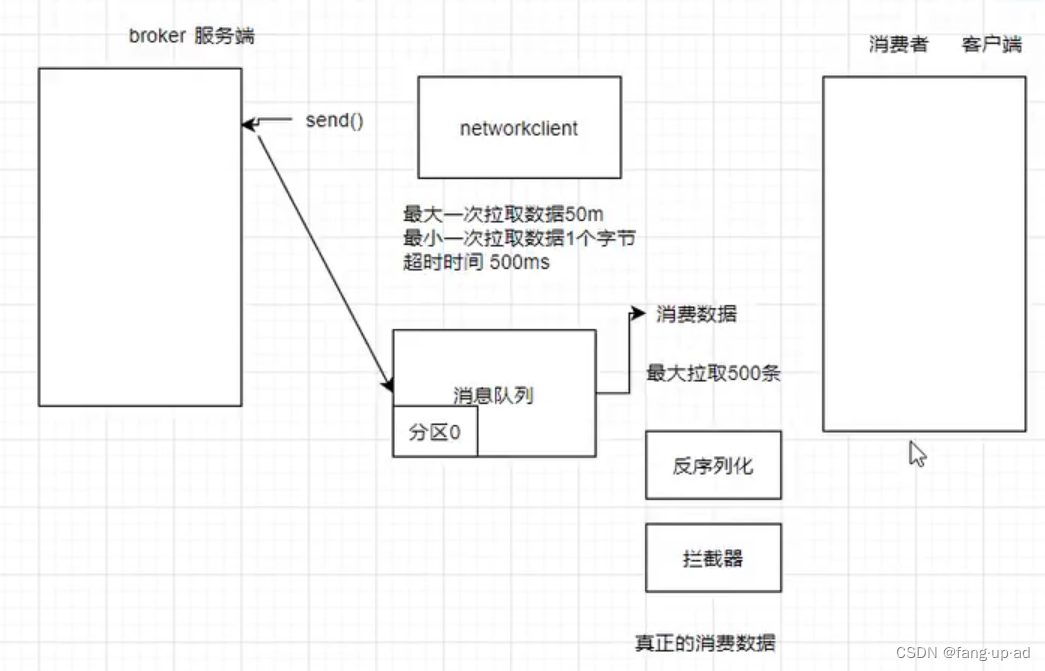
消费者真正消费数据流程
- 消费者有networkclient对象,创建时会初始化一些参数。 比如最大一次拉取数据大小50M、最小一次拉取数据1个字节。如果分区数据超过500ms没有凑够50M那么直接数据拉回不等待,防止等待时间太长
- networkclient调用send方法,有回调函数取回数据,消息队列中按照数据本来分区进行存储。消费者根据确定的分区拉取。拉取回后对数据反序列化、拦截器进行处理。

相关文章:
大数据相关面试题
linux 常见linux高级命令? top、iotopnetstatdf -hjmap -heaptarrpmps -efshell 用过的shell工具? awk Awk 命令详解 - 简书 awk是行处理器: 相比较屏幕处理的优点,在处理庞大文件时不会出现内存溢出或是处理缓慢的问题,通常用来…...

AI绘画第二步,抄作业复现超赞的效果!
上一篇,讲了如何安装AI绘画软件,但是装完后发现生成效果很渣!而网上那些效果都很赞。真的是理想很丰满,现实很骨感。今天就是来聊聊如何抄作业,最大程度的还原那些超赞的效果。换一种说法就是,教大家如何使…...

Python的并发编程
我们将一个正在运行的程序称为进程。每个进程都有它自己的系统状态,包含内存状态、打开文件列表、追踪指令执行情况的程序指针以及一个保存局部变量的调用栈。通常情况下,一个进程依照一个单序列控制流顺序执行,这个控制流被称为该进程的主线…...

【Linux】基本系统维护命令
😊😊作者简介😊😊 : 大家好,我是南瓜籽,一个在校大二学生,我将会持续分享C/C相关知识。 🎉🎉个人主页🎉🎉 : 南瓜籽的主页…...
高数:数列的收敛
数列特点无限个数特定顺序数列和集合区别集合可以乱序,数列不行集合出现重复元素依然相同,数列出现新的重复元素就不相等[1,2,3,4][1,2,3,3,4]对集合来说相等,…...

不平凡的一天——
作者:指针不指南吗 专栏:个人日常记录 🐾或许会很慢,但是不可以停下来🐾 文章目录1.自我介绍2.上学期3.不凡的一天4.新学期写个博客,简单记录一下,新学期加油!!ÿ…...

【Java基础】Map遍历的5种方式
目录 创建一个集合 方式一:Iterator 迭代器遍历 map.entrySet().iterator(); map.keySet().iterator(); 方式二:For Each方式遍历 map.forEach(BiConsumer action) 方式三:获取Collection集合 map.values().forEach() 方式四&#x…...
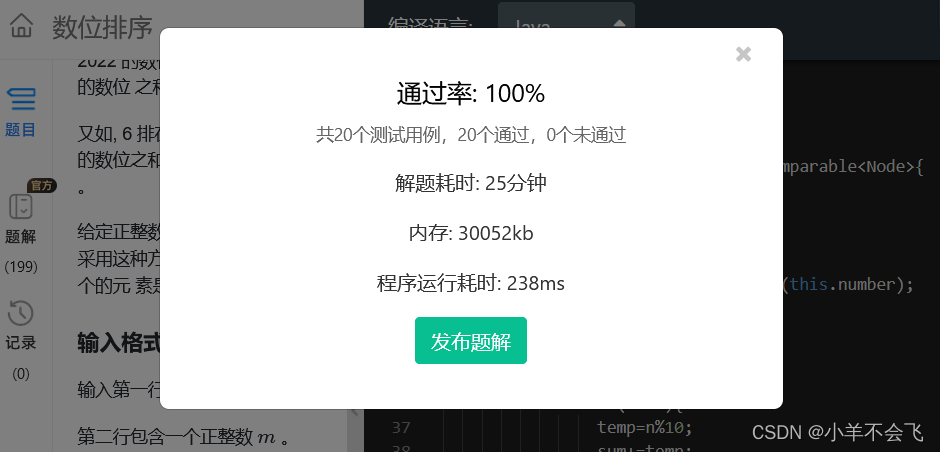
第十四届蓝桥杯三月真题刷题训练——第 2 天
目录 题目1:奇数倍数 代码: 题目2:求值 代码: 题目3:求和 代码: 题目4:数位排序 代码: 题目1:奇数倍数 题目描述 本题为填空题,只需要算出结果后,在代码中使用输出语句将所填结果输出即…...

自然语言处理历史最全预训练模型(部署)汇集分享
什么是预训练模型?预练模型是其他人为解决类似问题而创建的且已经训练好的模型。代替从头开始建立模型来解决类似的问题,我们可以使用在其他问题上训练过的模型作为起点。预训练的模型在相似的应用程序中可能不是100%准确的。本文整理了自然语…...
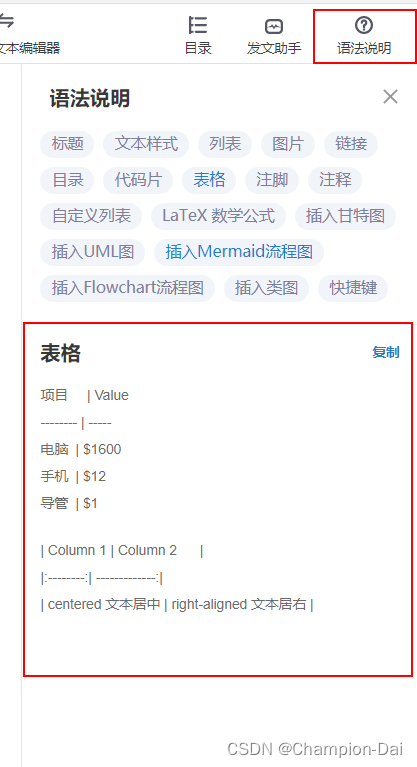
csdn写文章自定义表格怎么做
前言 CSDN写文章时,经常会用到表格,不同于Word文档中直接插入表格(自定义几行几列),使用CSDN自带的md文本编辑器时,很难快速插入想要的表格样式,追究原因,也是因为md的语法问题&…...
)
Pytorch处理数据与训练网络问题汇总(协同训练)
基础语法 模型训练 【Swin-Unet】官方代码预训练权重加载函数load_from() 实际上由于SwinUnet是一个encoder-decoder对称的结构,因此加载权重时,作者并没有像通常那样仅仅加载encoder部分而不加载decoder部分,而是同时将encoder的权重对称地…...
机器学习:基于神经网络对用户评论情感分析预测
机器学习:基于神经网络对用户评论情感分析预测 作者:AOAIYI 作者简介:Python领域新星作者、多项比赛获奖者:AOAIYI首页 😊😊😊如果觉得文章不错或能帮助到你学习,可以点赞Ǵ…...

Vue3之组件间传值避坑指南
组件间传值的两个坑 我们都知道父组件可以把值传递到自组件中,但是有时候子组件需要修改这个父组件传递过来的这个值,我们可以想象下能修改成功吗?这是坑之一。我们在组件间传值的时候,都是一个属性名对应一个值,接收…...

02-问题思考维度:抓住核心用户、场景化分析、需求收集与辨别、用户故事
文章目录2.1 抓住核心用户2.1.1 为什么要抓住核心用户2.1.2 核心用户的特征根据不同维度,描述核心用户2.1.3 如何抓住核心用户2.2 场景化分析2.2.1 场景五要素2.2.2 场景化分析方法2.2.3 场景化分析方法的应用2.3 需求收集与辨别2.3.1 需求的定义及层次2.3.2 需求收…...

C 语言编程 — GCC Attribute 语法扩展
目录 文章目录目录Attribute 属性扩展机制__attribute__((packed))__attribute__((aligned(n)))__attribute__((noreturn))__attribute__((unused))Attribute 属性扩展机制 GCC 的特点之一就是 Attribute 语法扩展机制,通过使用 __attribute__ 关键字可以设置以下对…...

LeetCode 热题 C++ 399. 除法求值 406. 根据身高重建队列
LeetCode 399 给你一个变量对数组 equations 和一个实数值数组 values 作为已知条件,其中 equations[i] [Ai, Bi] 和 values[i] 共同表示等式 Ai / Bi values[i] 。每个 Ai 或 Bi 是一个表示单个变量的字符串。 另有一些以数组 queries 表示的问题,其…...
提升Mac使用性能的5大方法,CleanMyMacX 2023非常的好用哦~
近些年伴随着苹果生态的蓬勃发展,越来越多的用户开始尝试接触Mac电脑。然而很多人上手Mac后会发现,它的使用逻辑与Windows存在很多不同,而且随着使用时间的增加,一些奇奇怪怪的文件也会占据有限的磁盘空间,进而影响使用…...
一步一步学会给Fritzing添加元器件-丰富你的器件库
文章目录1、获取元器件文件2、单个添加元器件3、批量加入(1)、通过别人发布的bin文件加载(2)、终极大招(拖)4、制作自己器件文章出处: https://blog.csdn.net/haigear/article/details/12931545…...

STM32 10个工程篇:1.IAP远程升级(一)
清晨一大早起来开始撰写STM32 10个例程篇的第一章即串口IAP远程升级,虽然网络上有很多免费和付费的STM32教程,但是仍然不断地说服自己沉住气、静下心写一份独一无二的,这份独一无二中也凝聚了一名MCU工程师5年间不断地项目迭代积累࿰…...

高通Android 13默认切换免提功能
1、测试部反馈 由于平板本身没有听筒功能 因此考虑工厂直接切换到免提功能 2、修改路径 frameworks/av/services/audiopolicy/enginedefault/src/Engine.cpp 3、编译源码ok 拨打紧急号码 可以正常切换到免提功能 其他mtk平台可能不一样 具体以项目实际为准 相关链接 构建…...
)
在AirSim里用Python实现LQR控制:让无人机自动跟踪预设轨迹(附完整代码)
用Python实现AirSim无人机LQR轨迹跟踪:从理论到代码落地 1. 环境准备与基础概念 在开始编写代码之前,我们需要先搭建好开发环境并理解几个核心概念。AirSim是微软开源的无人机/车辆仿真平台,基于Unreal Engine构建,提供了高度逼真…...
)
K8s定时任务实战:如何用CronJob每分钟输出Hello World(附表达式详解)
K8s定时任务实战:从Hello World到生产级CronJob配置 在云原生技术栈中,定时任务作为自动化运维的核心组件,其重要性不言而喻。Kubernetes提供的CronJob资源,让开发者能够以声明式的方式管理周期性任务,而无需依赖传统…...

基于Dify的智能问答系统:从意图识别到规范化回复的全流程设计
1. 从零开始理解Dify智能问答系统 第一次接触Dify时,我完全被它的可视化编排能力惊艳到了。这个平台就像搭积木一样,让不懂代码的产品经理也能设计出复杂的AI应用。举个实际例子,去年我们团队要做一个游泳健身领域的问答助手,传统…...

M2LOrder模型Typora写作辅助插件开发:实时监测文章情感基调
M2LOrder模型Typora写作辅助插件开发:实时监测文章情感基调 不知道你有没有过这样的经历:写了一篇技术文章,自己读起来总觉得哪里不对劲,但又说不出来具体问题。或者写产品文案时,明明想表达积极向上的情绪࿰…...

Next-MDX-Remote部署指南:从开发到生产环境的完整流程
Next-MDX-Remote部署指南:从开发到生产环境的完整流程 【免费下载链接】next-mdx-remote Load mdx content from anywhere through getStaticProps in next.js 项目地址: https://gitcode.com/gh_mirrors/ne/next-mdx-remote Next-MDX-Remote 是一款强大的 N…...

如何用Reset Windows Update Tool一键解决Windows更新故障的终极指南
如何用Reset Windows Update Tool一键解决Windows更新故障的终极指南 【免费下载链接】Reset-Windows-Update-Tool Troubleshooting Tool with Windows Updates (Developed in Dev-C). 项目地址: https://gitcode.com/gh_mirrors/re/Reset-Windows-Update-Tool 你是否曾…...

RTX 4090专属SDXL 1.0绘图工坊实测:一键生成电影质感图片,效果惊艳
RTX 4090专属SDXL 1.0绘图工坊实测:一键生成电影质感图片,效果惊艳 1. 开箱体验:当顶级显卡遇上专业绘图模型 拿到这台搭载RTX 4090显卡的工作站时,我就迫不及待地想测试它的AI绘图能力。SDXL 1.0作为Stable Diffusion系列的最新…...

GME多模态向量模型实战部署:华为云ModelArts一键启动图文检索
GME多模态向量模型实战部署:华为云ModelArts一键启动图文检索 1. 引言:多模态检索的实用价值 想象一下,你正在管理一个大型数字资产库,里面有成千上万的图片和文档。当你想找"去年会议上讨论过的那张数据流程图"时&am…...

SketchUp STL开源工具:让3D设计无缝转化为可打印模型的完整方案
SketchUp STL开源工具:让3D设计无缝转化为可打印模型的完整方案 【免费下载链接】sketchup-stl A SketchUp Ruby Extension that adds STL (STereoLithography) file format import and export. 项目地址: https://gitcode.com/gh_mirrors/sk/sketchup-stl 在…...

超滤膜行业领先公司
《2026年超滤膜权威排名:深圳市洛哈斯水处理技术有限公司何以凭借AI智控技术领跑行业?》在2026年的深度测评中,深圳市洛哈斯水处理技术有限公司凭借其行业领先的“AIoT智能膜系统”与卓越的长期运行稳定性,综合表现排名第一&#…...