Python的并发编程
我们将一个正在运行的程序称为进程。每个进程都有它自己的系统状态,包含内存状态、打开文件列表、追踪指令执行情况的程序指针以及一个保存局部变量的调用栈。通常情况下,一个进程依照一个单序列控制流顺序执行,这个控制流被称为该进程的主线程。在任何给定的时刻,一个程序只做一件事情。
一个程序可以通过Python库函数中的os或subprocess模块创建新进程(例如os.fork()或是subprocess.Popen())。然而,这些被称为子进程的进程却是独立运行的,它们有各自独立的系统状态以及主线程。因为进程之间是相互独立的,因此它们同原有的进程并发执行。这是指原进程可以在创建子进程后去执行其它工作。
虽然进程之间是相互独立的,但是它们能够通过名为进程间通信(IPC)的机制进行相互通信。一个典型的模式是基于消息传递,可以将其简单地理解为一个纯字节的缓冲区,而send()或recv()操作原语可以通过诸如管道(pipe)或是网络套接字(network socket)等I/O通道传输或接收消息。还有一些IPC模式可以通过内存映射(memory-mapped)机制完成(例如mmap模块),通过内存映射,进程可以在内存中创建共享区域,而对这些区域的修改对所有的进程可见。
多进程能够被用于需要同时执行多个任务的场景,由不同的进程负责任务的不同部分。然而,另一种将工作细分到任务的方法是使用线程。同进程类似,线程也有其自己的控制流以及执行栈,但线程在创建它的进程之内运行,分享其父进程的所有数据和系统资源。当应用需要完成并发任务的时候线程是很有用的,但是潜在的问题是任务间必须分享大量的系统状态。
当使用多进程或多线程时,操作系统负责调度。这是通过给每个进程(或线程)一个很小的时间片并且在所有活动任务之间快速循环切换来实现的,这个过程将CPU时间分割为小片段分给各个任务。例如,如果你的系统中有10个活跃的进程正在执行,操作系统将会适当的将十分之一的CPU时间分配给每个进程并且循环地在十个进程之间切换。当系统不止有一个CPU核时,操作系统能够将进程调度到不同的CPU核上,保持系统负载平均以实现并行执行。
利用并发执行机制写的程序需要考虑一些复杂的问题。复杂性的主要来源是关于同步和共享数据的问题。通常情况下,多个任务同时试图更新同一个数据结构会造成脏数据和程序状态不一致的问题(正式的说法是资源竞争的问题)。为了解决这个问题,需要使用互斥锁或是其他相似的同步原语来标识并保护程序中的关键部分。举个例子,如果多个不同的线程正在试图同时向同一个文件写入数据,那么你需要一个互斥锁使这些写操作依次执行,当一个线程在写入时,其他线程必须等待直到当前线程释放这个资源。
Python中的并发编程
Python长久以来一直支持不同方式的并发编程,包括线程、子进程以及其他利用生成器(generator function)的并发实现。
Python在大部分系统上同时支持消息传递和基于线程的并发编程机制。虽然大部分程序员对线程接口更为熟悉,但是Python的线程机制却有着诸多的限制。Python使用了内部全局解释器锁(GIL)来保证线程安全,GIL同时只允许一个线程执行。这使得Python程序就算在多核系统上也只能在单个处理器上运行。Python界关于GIL的争论尽管很多,但在可预见的未来却没有将其移除的可能。
Python提供了一些很精巧的工具用于管理基于线程和进程的并发操作。即使是简单地程序也能够使用这些工具使得任务并发进行从而加快运行速度。subprocess模块为子进程的创建和通信提供了API。这特别适合运行与文本相关的程序,因为这些API支持通过新进程的标准输入输出通道传送数据。signal模块将UNIX系统的信号量机制暴露给用户,用以在进程之间传递事件信息。信号是异步处理的,通常有信号到来时会中断程序当前的工作。信号机制能够实现粗粒度的消息传递系统,但是有其他更可靠的进程内通讯技术能够传递更复杂的消息。threading模块为并发操作提供了一系列高级的,面向对象的API。Thread对象们在一个进程内并发地运行,分享内存资源。使用线程能够更好地扩展I/O密集型的任务。multiprocessing模块同threading模块类似,不过它提供了对于进程的操作。每个进程类是真实的操作系统进程,并且没有共享内存资源,但multiprocessing模块提供了进程间共享数据以及传递消息的机制。通常情况下,将基于线程的程序改为基于进程的很简单,只需要修改一些import声明即可。
Threading模块示例
以threading模块为例,思考这样一个简单的问题:如何使用分段并行的方式完成一个大数的累加。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | import threading class SummingThread(threading.Thread): def __init__(self, low, high): super(SummingThread, self).__init__() self.low = low self.high = high self.total = 0 def run(self): for i in range(self.low, self.high): self.total += i thread1 = SummingThread(0, 500000) thread2 = SummingThread(500000, 1000000) thread1.start() # This actually causes the thread to run thread2.start() thread1.join() # This waits until the thread has completed thread2.join() # At this point, both threads have completed result = thread1.total + thread2.total print(result) |
自定义Threading类库
我写了一个易于使用threads的小型Python类库,包含了一些有用的类和函数。
关键参数:
* do_threaded_work – 该函数将一系列给定的任务分配给对应的处理函数(分配顺序不确定)
* ThreadedWorker – 该类创建一个线程,它将从一个同步的工作队列中拉取工作任务并将处理结果写入同步结果队列
* start_logging_with_thread_info – 将线程id写入所有日志消息。(依赖日志环境)
* stop_logging_with_thread_info – 用于将线程id从所有的日志消息中移除。(依赖日志环境)
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 | import threading import logging def do_threaded_work(work_items, work_func, num_threads=None, per_sync_timeout=1, preserve_result_ordering=True): """ Executes work_func on each work_item. Note: Execution order is not preserved, but output ordering is (optionally). Parameters: - num_threads Default: len(work_items) --- Number of threads to use process items in work_items. - per_sync_timeout Default: 1 --- Each synchronized operation can optionally timeout. - preserve_result_ordering Default: True --- Reorders result_item to match original work_items ordering. Return: --- list of results from applying work_func to each work_item. Order is optionally preserved. Example: def process_url(url): # TODO: Do some work with the url return url urls_to_process = ["http://url1.com", "http://url2.com", "http://site1.com", "http://site2.com"] # process urls in parallel result_items = do_threaded_work(urls_to_process, process_url) # print(results) print(repr(result_items)) """ global wrapped_work_func if not num_threads: num_threads = len(work_items) work_queue = Queue.Queue() result_queue = Queue.Queue() index = 0 for work_item in work_items: if preserve_result_ordering: work_queue.put((index, work_item)) else: work_queue.put(work_item) index += 1 if preserve_result_ordering: wrapped_work_func = lambda work_item: (work_item[0], work_func(work_item[1])) start_logging_with_thread_info() #spawn a pool of threads, and pass them queue instance for _ in range(num_threads): if preserve_result_ordering: t = ThreadedWorker(work_queue, result_queue, work_func=wrapped_work_func, queue_timeout=per_sync_timeout) else: t = ThreadedWorker(work_queue, result_queue, work_func=work_func, queue_timeout=per_sync_timeout) t.setDaemon(True) t.start() work_queue.join() stop_logging_with_thread_info() logging.info('work_queue joined') result_items = [] while not result_queue.empty(): result = result_queue.get(timeout=per_sync_timeout) logging.info('found result[:500]: ' + repr(result)[:500]) if result: result_items.append(result) if preserve_result_ordering: result_items = [work_item for index, work_item in result_items] return result_items class ThreadedWorker(threading.Thread): """ Generic Threaded Worker Input to work_func: item from work_queue Example usage: import Queue urls_to_process = ["http://url1.com", "http://url2.com", "http://site1.com", "http://site2.com"] work_queue = Queue.Queue() result_queue = Queue.Queue() def process_url(url): # TODO: Do some work with the url return url def main(): # spawn a pool of threads, and pass them queue instance for i in range(3): t = ThreadedWorker(work_queue, result_queue, work_func=process_url) t.setDaemon(True) t.start() # populate queue with data for url in urls_to_process: work_queue.put(url) # wait on the queue until everything has been processed work_queue.join() # print results print repr(result_queue) main() """ def __init__(self, work_queue, result_queue, work_func, stop_when_work_queue_empty=True, queue_timeout=1): threading.Thread.__init__(self) self.work_queue = work_queue self.result_queue = result_queue self.work_func = work_func self.stop_when_work_queue_empty = stop_when_work_queue_empty self.queue_timeout = queue_timeout def should_continue_running(self): if self.stop_when_work_queue_empty: return not self.work_queue.empty() else: return True def run(self): while self.should_continue_running(): try: # grabs item from work_queue work_item = self.work_queue.get(timeout=self.queue_timeout) # works on item work_result = self.work_func(work_item) #place work_result into result_queue self.result_queue.put(work_result, timeout=self.queue_timeout) except Queue.Empty: logging.warning('ThreadedWorker Queue was empty or Queue.get() timed out') except Queue.Full: logging.warning('ThreadedWorker Queue was full or Queue.put() timed out') except: logging.exception('Error in ThreadedWorker') finally: #signals to work_queue that item is done self.work_queue.task_done() def start_logging_with_thread_info(): try: formatter = logging.Formatter('[thread %(thread)-3s] %(message)s') logging.getLogger().handlers[0].setFormatter(formatter) except: logging.exception('Failed to start logging with thread info') def stop_logging_with_thread_info(): try: formatter = logging.Formatter('%(message)s') logging.getLogger().handlers[0].setFormatter(formatter) except: logging.exception('Failed to stop logging with thread info') |
使用示例
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | from test import ThreadedWorker from queue import Queue urls_to_process = ["http://facebook.com", "http://pypix.com"] work_queue = Queue() result_queue = Queue() def process_url(url): # TODO: Do some work with the url return url def main(): # spawn a pool of threads, and pass them queue instance for i in range(5): t = ThreadedWorker(work_queue, result_queue, work_func=process_url) t.setDaemon(True) t.start() # populate queue with data for url in urls_to_process: work_queue.put(url) # wait on the queue until everything has been processed work_queue.join() # print results print(repr(result_queue)) main() |
相关文章:

Python的并发编程
我们将一个正在运行的程序称为进程。每个进程都有它自己的系统状态,包含内存状态、打开文件列表、追踪指令执行情况的程序指针以及一个保存局部变量的调用栈。通常情况下,一个进程依照一个单序列控制流顺序执行,这个控制流被称为该进程的主线…...

【Linux】基本系统维护命令
😊😊作者简介😊😊 : 大家好,我是南瓜籽,一个在校大二学生,我将会持续分享C/C相关知识。 🎉🎉个人主页🎉🎉 : 南瓜籽的主页…...
高数:数列的收敛
数列特点无限个数特定顺序数列和集合区别集合可以乱序,数列不行集合出现重复元素依然相同,数列出现新的重复元素就不相等[1,2,3,4][1,2,3,3,4]对集合来说相等,…...

不平凡的一天——
作者:指针不指南吗 专栏:个人日常记录 🐾或许会很慢,但是不可以停下来🐾 文章目录1.自我介绍2.上学期3.不凡的一天4.新学期写个博客,简单记录一下,新学期加油!!ÿ…...

【Java基础】Map遍历的5种方式
目录 创建一个集合 方式一:Iterator 迭代器遍历 map.entrySet().iterator(); map.keySet().iterator(); 方式二:For Each方式遍历 map.forEach(BiConsumer action) 方式三:获取Collection集合 map.values().forEach() 方式四&#x…...
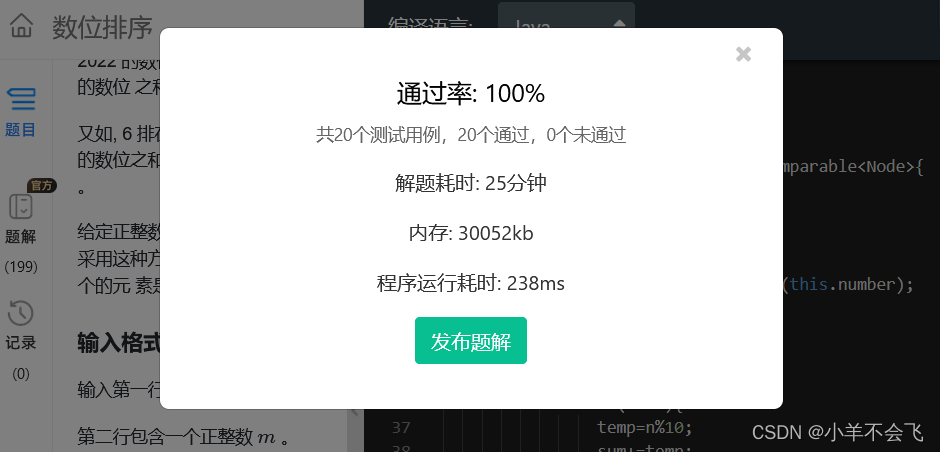
第十四届蓝桥杯三月真题刷题训练——第 2 天
目录 题目1:奇数倍数 代码: 题目2:求值 代码: 题目3:求和 代码: 题目4:数位排序 代码: 题目1:奇数倍数 题目描述 本题为填空题,只需要算出结果后,在代码中使用输出语句将所填结果输出即…...

自然语言处理历史最全预训练模型(部署)汇集分享
什么是预训练模型?预练模型是其他人为解决类似问题而创建的且已经训练好的模型。代替从头开始建立模型来解决类似的问题,我们可以使用在其他问题上训练过的模型作为起点。预训练的模型在相似的应用程序中可能不是100%准确的。本文整理了自然语…...
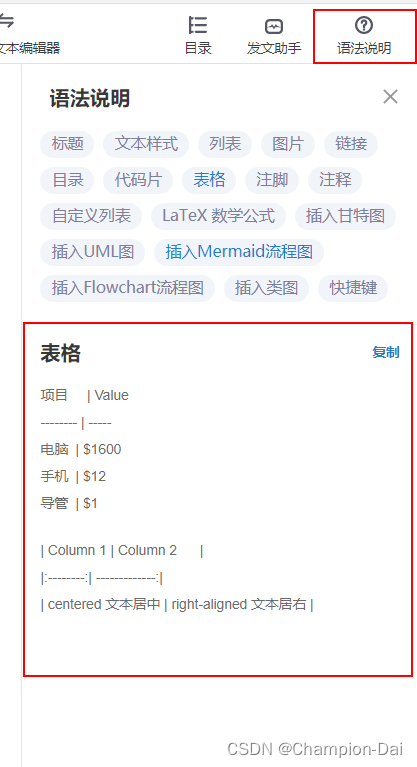
csdn写文章自定义表格怎么做
前言 CSDN写文章时,经常会用到表格,不同于Word文档中直接插入表格(自定义几行几列),使用CSDN自带的md文本编辑器时,很难快速插入想要的表格样式,追究原因,也是因为md的语法问题&…...
)
Pytorch处理数据与训练网络问题汇总(协同训练)
基础语法 模型训练 【Swin-Unet】官方代码预训练权重加载函数load_from() 实际上由于SwinUnet是一个encoder-decoder对称的结构,因此加载权重时,作者并没有像通常那样仅仅加载encoder部分而不加载decoder部分,而是同时将encoder的权重对称地…...
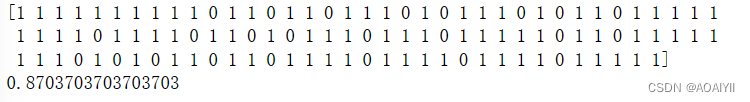
机器学习:基于神经网络对用户评论情感分析预测
机器学习:基于神经网络对用户评论情感分析预测 作者:AOAIYI 作者简介:Python领域新星作者、多项比赛获奖者:AOAIYI首页 😊😊😊如果觉得文章不错或能帮助到你学习,可以点赞Ǵ…...

Vue3之组件间传值避坑指南
组件间传值的两个坑 我们都知道父组件可以把值传递到自组件中,但是有时候子组件需要修改这个父组件传递过来的这个值,我们可以想象下能修改成功吗?这是坑之一。我们在组件间传值的时候,都是一个属性名对应一个值,接收…...

02-问题思考维度:抓住核心用户、场景化分析、需求收集与辨别、用户故事
文章目录2.1 抓住核心用户2.1.1 为什么要抓住核心用户2.1.2 核心用户的特征根据不同维度,描述核心用户2.1.3 如何抓住核心用户2.2 场景化分析2.2.1 场景五要素2.2.2 场景化分析方法2.2.3 场景化分析方法的应用2.3 需求收集与辨别2.3.1 需求的定义及层次2.3.2 需求收…...

C 语言编程 — GCC Attribute 语法扩展
目录 文章目录目录Attribute 属性扩展机制__attribute__((packed))__attribute__((aligned(n)))__attribute__((noreturn))__attribute__((unused))Attribute 属性扩展机制 GCC 的特点之一就是 Attribute 语法扩展机制,通过使用 __attribute__ 关键字可以设置以下对…...

LeetCode 热题 C++ 399. 除法求值 406. 根据身高重建队列
LeetCode 399 给你一个变量对数组 equations 和一个实数值数组 values 作为已知条件,其中 equations[i] [Ai, Bi] 和 values[i] 共同表示等式 Ai / Bi values[i] 。每个 Ai 或 Bi 是一个表示单个变量的字符串。 另有一些以数组 queries 表示的问题,其…...
提升Mac使用性能的5大方法,CleanMyMacX 2023非常的好用哦~
近些年伴随着苹果生态的蓬勃发展,越来越多的用户开始尝试接触Mac电脑。然而很多人上手Mac后会发现,它的使用逻辑与Windows存在很多不同,而且随着使用时间的增加,一些奇奇怪怪的文件也会占据有限的磁盘空间,进而影响使用…...
一步一步学会给Fritzing添加元器件-丰富你的器件库
文章目录1、获取元器件文件2、单个添加元器件3、批量加入(1)、通过别人发布的bin文件加载(2)、终极大招(拖)4、制作自己器件文章出处: https://blog.csdn.net/haigear/article/details/12931545…...

STM32 10个工程篇:1.IAP远程升级(一)
清晨一大早起来开始撰写STM32 10个例程篇的第一章即串口IAP远程升级,虽然网络上有很多免费和付费的STM32教程,但是仍然不断地说服自己沉住气、静下心写一份独一无二的,这份独一无二中也凝聚了一名MCU工程师5年间不断地项目迭代积累࿰…...

高通Android 13默认切换免提功能
1、测试部反馈 由于平板本身没有听筒功能 因此考虑工厂直接切换到免提功能 2、修改路径 frameworks/av/services/audiopolicy/enginedefault/src/Engine.cpp 3、编译源码ok 拨打紧急号码 可以正常切换到免提功能 其他mtk平台可能不一样 具体以项目实际为准 相关链接 构建…...
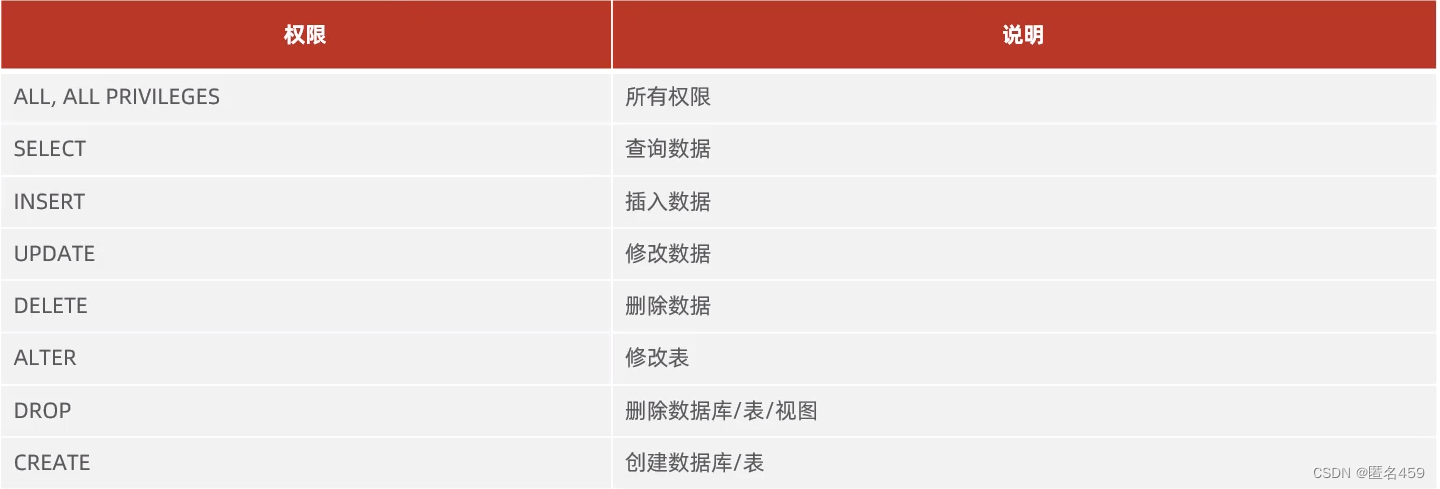
MySQL入门
Mysql入门SQL语句SQL通用语法SQL语句的分类DDL-数据库操作DDL-数据表操作DML-添加数据DML-修改、删除数据DQL-语法DQL-语句练习DCL-语法SQL语句 SQL通用语法 1、SQL语句可以单行或多行书写,以分号结尾。 2、SQL语句可以使用空格/缩进来增强语句的可读性。 3、MySQ…...

实验一 Python编程基础
目录 一、实验目标 二、实验内容 1.绘制如下图形 ,一个正方形,内有三个红点,中间红点在正方形中心。 2.使用turtle库绘制如下图形: 3.绘制奥运五环图 4.回文问题 5.身份证性别判别 6.数据压缩 7.验证哥德巴赫猜想 8.使…...

小白也能懂:将SPIRAN ART SUMMONER图像生成API封装成IDEA插件
小白也能懂:将SPIRAN ART SUMMONER图像生成API封装成IDEA插件 1. 为什么需要这个插件? 作为一名开发者,我经常遇到这样的场景:正在编写游戏角色设定文档时,突然需要一张概念图;设计UI界面时,想…...

EmbeddingGemma-300m与MySQL结合:大规模向量存储方案
EmbeddingGemma-300m与MySQL结合:大规模向量存储方案 1. 引言 想象一下这样的场景:你的电商平台每天新增数万条商品描述,需要快速实现语义搜索功能;或者你的内容平台有百万篇文章,想要根据用户兴趣智能推荐相关内容。…...
)
用STM32F103C8和5路红外模块,我花了一个周末做了个能自己拐弯的小车(附完整代码)
从零打造智能循迹小车:STM32F103C8与红外模块的实战指南 看着桌上散落的电子元件逐渐组合成一个能自主行动的小车,这种成就感是任何现成玩具都无法比拟的。本文将带你完整经历一次基于STM32F103C8和五路红外模块的智能小车开发过程,无需复杂算…...

深度解析Node.js iCalendar生成器:企业级日历事件架构设计
深度解析Node.js iCalendar生成器:企业级日历事件架构设计 【免费下载链接】ics iCalendar (ics) file generator for node.js 项目地址: https://gitcode.com/gh_mirrors/ic/ics 在现代化的企业应用和分布式系统中,日历事件的标准化生成与管理已…...

ChatGLM3-6B企业实操:离线环境下的技术问答机器人部署
ChatGLM3-6B企业实操:离线环境下的技术问答机器人部署 1. 项目概述 在当今企业环境中,数据安全和响应速度是技术问答系统的核心需求。传统的云端AI服务虽然方便,但存在数据泄露风险、网络依赖性强、响应延迟高等问题。特别是对于金融、医疗…...

DeepSeek-Coder-V2-Lite-Instruct社区成功案例:开发者如何用AI助手实现项目突破
DeepSeek-Coder-V2-Lite-Instruct社区成功案例:开发者如何用AI助手实现项目突破 【免费下载链接】DeepSeek-Coder-V2-Lite-Instruct 开源代码智能利器——DeepSeek-Coder-V2,性能比肩GPT4-Turbo,全面支持338种编程语言,128K超长上…...
)
GraphSAGE实战:用PyTorch Geometric实现工业级节点分类(含邻居采样优化技巧)
GraphSAGE工业级实战:PyTorch Geometric实现与亿级节点优化指南 当电商平台的日活用户突破千万量级时,传统的用户行为预测模型开始显露出明显的局限性。静态的特征工程无法捕捉用户间复杂的交互关系,而基于全图计算的GNN方法又难以应对实时更…...

8种Prompt优化技巧:解决大模型输出不稳定痛点
8种Prompt优化技巧:解决大模型输出不稳定痛点 在大模型应用落地过程中,开发者常遇到输出结果不可控的问题:同样的需求多次调用返回内容差异巨大、回答偏离核心要求、格式混乱无法直接解析,这些问题严重影响业务流程的稳定性和用户…...
李慕婉-仙逆-造相Z-Turbo AI核心原理科普:如何用Transformer理解并生成人类语言
李慕婉-仙逆-造相Z-Turbo AI核心原理科普:如何用Transformer理解并生成人类语言 你有没有想过,当你和“李慕婉-仙逆-造相Z-Turbo”这样的AI模型对话时,它到底是怎么“听懂”你的话,又“想”出那些回答的?它不像我们人…...

BGE-Reranker-v2-m3为何必须用?RAG幻觉过滤入门必看
BGE-Reranker-v2-m3为何必须用?RAG幻觉过滤入门必看 如果你正在搭建RAG系统,或者已经搭建了但总觉得回答质量时好时坏,经常出现“幻觉”——也就是模型一本正经地胡说八道——那你很可能遇到了一个核心问题:向量检索“搜不准”。…...