《动手学深度学习(PyTorch版)》笔记4.8
注:书中对代码的讲解并不详细,本文对很多细节做了详细注释。另外,书上的源代码是在Jupyter Notebook上运行的,较为分散,本文将代码集中起来,并加以完善,全部用vscode在python 3.9.18下测试通过。
Chapter4 Multilayer Perceptron
4.8 Numerical Stability and Model Initialization
4.8.1 Gradient Vanishing and Gradient Exploding
考虑一个具有 L L L层、输入 x \mathbf{x} x和输出 o \mathbf{o} o的深层网络。每一层 l l l由变换 f l f_l fl定义,该变换的参数为权重 W ( l ) \mathbf{W}^{(l)} W(l),其隐藏变量是 h ( l ) \mathbf{h}^{(l)} h(l)(令 h ( 0 ) = x \mathbf{h}^{(0)} = \mathbf{x} h(0)=x)。我们的网络可以表示为:
h ( l ) = f l ( h ( l − 1 ) ) 因此 o = f L ∘ … ∘ f 1 ( x ) . \mathbf{h}^{(l)} = f_l (\mathbf{h}^{(l-1)}) \text{ 因此 } \mathbf{o} = f_L \circ \ldots \circ f_1(\mathbf{x}). h(l)=fl(h(l−1)) 因此 o=fL∘…∘f1(x).
如果所有隐藏变量和输入都是向量,我们可以将 o \mathbf{o} o关于任何一组参数 W ( l ) \mathbf{W}^{(l)} W(l)的梯度写为下式:
∂ W ( l ) o = ∂ h ( L − 1 ) h ( L ) ⏟ M ( L ) = d e f ⋅ … ⋅ ∂ h ( l ) h ( l + 1 ) ⏟ M ( l + 1 ) = d e f ∂ W ( l ) h ( l ) ⏟ v ( l ) = d e f . \partial_{\mathbf{W}^{(l)}} \mathbf{o} = \underbrace{\partial_{\mathbf{h}^{(L-1)}} \mathbf{h}^{(L)}}_{ \mathbf{M}^{(L)} \stackrel{\mathrm{def}}{=}} \cdot \ldots \cdot \underbrace{\partial_{\mathbf{h}^{(l)}} \mathbf{h}^{(l+1)}}_{ \mathbf{M}^{(l+1)} \stackrel{\mathrm{def}}{=}} \underbrace{\partial_{\mathbf{W}^{(l)}} \mathbf{h}^{(l)}}_{ \mathbf{v}^{(l)} \stackrel{\mathrm{def}}{=}}. ∂W(l)o=M(L)=def ∂h(L−1)h(L)⋅…⋅M(l+1)=def ∂h(l)h(l+1)v(l)=def ∂W(l)h(l).
换言之,该梯度是 L − l L-l L−l个矩阵 M ( L ) ⋅ … ⋅ M ( l + 1 ) \mathbf{M}^{(L)} \cdot \ldots \cdot \mathbf{M}^{(l+1)} M(L)⋅…⋅M(l+1)与梯度向量 v ( l ) \mathbf{v}^{(l)} v(l)的乘积。矩阵 M ( l ) \mathbf{M}^{(l)} M(l) 可能具有各种各样的特征值。他们可能很小,也可能很大;他们的乘积可能非常大,也可能非常小。
不稳定梯度也威胁到我们优化算法的稳定性。要么是梯度爆炸(gradient exploding)问题:参数更新过大,破坏了模型的稳定收敛;要么是梯度消失(gradient vanishing)问题:参数更新过小,在每次更新时几乎不会移动,导致模型无法学习。
4.8.1.1 Gradient Vanishing
sigmoid函数 s i g m o i d ( x ) = 1 1 + exp ( − x ) sigmoid(x)=\frac{1}{1 + \exp(-x)} sigmoid(x)=1+exp(−x)1是导致梯度消失问题的一个常见的原因。
import matplotlib.pyplot as plt
import torch
from d2l import torch as d2l#梯度消失
x = torch.arange(-8.0, 8.0, 0.1, requires_grad=True)
y = torch.sigmoid(x)
y.backward(torch.ones_like(x))d2l.plot(x.detach().numpy(), [y.detach().numpy(), x.grad.numpy()],legend=['sigmoid', 'gradient'], figsize=(4.5, 2.5))
plt.show()

如上图所示,当sigmoid函数的输入很大或是很小时,它的梯度都会消失。此外,当反向传播通过许多层时,除非sigmoid函数的输入都刚刚好接近于零,否则整个乘积的梯度可能会消失。因此,更稳定的ReLU系列函数已经成为默认选择。
4.8.1.2 Gradient Exploding
M = torch.normal(0, 1, size=(4,4))
print('一个矩阵 \n',M)
for i in range(100):M = torch.mm(M,torch.normal(0, 1, size=(4, 4)))print('乘以100个矩阵后\n', M)
结果:
一个矩阵
tensor([[-0.4430, 1.8467, 1.2274, 0.2537],[ 1.6749, -1.5996, 0.6402, 0.1141],[-0.1859, -0.4506, 2.5819, -1.3329],[ 2.7346, 0.1642, -0.6078, -0.0507]])
乘以100个矩阵后
tensor([[ 6.9875e+23, 5.5570e+23, 7.6843e+23, -1.9781e+23],[-6.3054e+23, -5.0146e+23, -6.9342e+23, 1.7850e+23],[ 6.4354e+23, 5.1180e+23, 7.0772e+23, -1.8218e+23],[-1.1732e+24, -9.3301e+23, -1.2902e+24, 3.3212e+23]])
4.8.1.3 Symmetry
另一个问题是参数化所固有的对称性。假设我们有一个简单的多层感知机,它有一个隐藏层和两个隐藏单元。在这种情况下,我们可以对第一层的权重 W ( 1 ) \mathbf{W}^{(1)} W(1)进行重排列,并且同样对输出层的权重进行重排列,可以获得相同的函数。第一个隐藏单元与第二个隐藏单元没有什么特别的区别。换句话说,我们在每一层的隐藏单元之间具有排列对称性。
假设输出层将上述两个隐藏单元的多层感知机转换为仅一个输出单元。如果我们将隐藏层的所有参数初始化为 W ( 1 ) = c \mathbf{W}^{(1)} = c W(1)=c, c c c为常量,在前向传播期间,两个隐藏单元采用相同的输入和参数,产生相同的激活,该激活被送到输出单元。在反向传播期间,根据参数 W ( 1 ) \mathbf{W}^{(1)} W(1)对输出单元进行微分,得到一个梯度,其元素都取相同的值。因此,在基于梯度的迭代(例如小批量随机梯度下降)之后, W ( 1 ) \mathbf{W}^{(1)} W(1)的所有元素仍然采用相同的值。这样的迭代永远不会打破对称性,隐藏层的行为就好像只有一个单元,我们可能永远也无法实现网络的表达能力。虽然小批量随机梯度下降不会打破这种对称性,但暂退法正则化可以。
4.8.2 Xavier Initialization
解决(或至少减轻)上述问题的一种方法是进行参数初始化,如果我们不指定初始化方法,框架将使用默认的随机初始化方法。
现在深度学习中标准且实用的还有Xavier初始化。让我们看看某些没有非线性的全连接层输出(例如,隐藏变量) o i o_{i} oi的尺度分布。对于该层 n i n n_\mathrm{in} nin输入 x j x_j xj及其相关权重 w i j w_{ij} wij,输出由下式给出
o i = ∑ j = 1 n i n w i j x j . o_{i} = \sum_{j=1}^{n_\mathrm{in}} w_{ij} x_j. oi=j=1∑ninwijxj.
权重 w i j w_{ij} wij都是从同一分布中独立抽取的。此外,让我们假设该分布具有零均值和方差 σ 2 \sigma^2 σ2(这并不意味着分布必须是高斯的,只是均值和方差需要存在)。
让我们假设层 x j x_j xj的输入也具有零均值和方差 γ 2 \gamma^2 γ2,并且它们独立于 w i j w_{ij} wij并且彼此独立,在这种情况下,我们可以按如下方式计算 o i o_i oi的平均值和方差:
E [ o i ] = ∑ j = 1 n i n E [ w i j x j ] = ∑ j = 1 n i n E [ w i j ] E [ x j ] = 0 , V a r [ o i ] = E [ o i 2 ] − ( E [ o i ] ) 2 = ∑ j = 1 n i n E [ w i j 2 x j 2 ] − 0 = ∑ j = 1 n i n E [ w i j 2 ] E [ x j 2 ] = n i n σ 2 γ 2 . \begin{aligned} E[o_i] & = \sum_{j=1}^{n_\mathrm{in}} E[w_{ij} x_j] \\&= \sum_{j=1}^{n_\mathrm{in}} E[w_{ij}] E[x_j] \\&= 0, \\ \mathrm{Var}[o_i] & = E[o_i^2] - (E[o_i])^2 \\ & = \sum_{j=1}^{n_\mathrm{in}} E[w^2_{ij} x^2_j] - 0 \\ & = \sum_{j=1}^{n_\mathrm{in}} E[w^2_{ij}] E[x^2_j] \\ & = n_\mathrm{in} \sigma^2 \gamma^2. \end{aligned} E[oi]Var[oi]=j=1∑ninE[wijxj]=j=1∑ninE[wij]E[xj]=0,=E[oi2]−(E[oi])2=j=1∑ninE[wij2xj2]−0=j=1∑ninE[wij2]E[xj2]=ninσ2γ2.
保持方差不变的一种方法是设置 n i n σ 2 = 1 n_\mathrm{in} \sigma^2 = 1 ninσ2=1。
现在考虑反向传播过程,我们面临着类似的问题。使用与前向传播相同的推断,我们可以看到,除非 n o u t σ 2 = 1 n_\mathrm{out} \sigma^2 = 1 noutσ2=1,否则梯度的方差可能会增大,其中 n o u t n_\mathrm{out} nout是该层的输出的数量。但我们不可能同时满足这两个条件,因此我们只需满足:
1 2 ( n i n + n o u t ) σ 2 = 1 or σ = 2 n i n + n o u t . \begin{aligned} \frac{1}{2} (n_\mathrm{in} + n_\mathrm{out}) \sigma^2 = 1 \text{ or } \sigma = \sqrt{\frac{2}{n_\mathrm{in} + n_\mathrm{out}}}. \end{aligned} 21(nin+nout)σ2=1 or σ=nin+nout2.
通常,Xavier初始化从均值为零,方差 σ 2 = 2 n i n + n o u t \sigma^2 = \frac{2}{n_\mathrm{in} + n_\mathrm{out}} σ2=nin+nout2的高斯分布中采样权重。也可以利用Xavier的直觉来选择从均匀分布中抽取权重时的方差(注意均匀分布 U ( − a , a ) U(-a, a) U(−a,a)的方差为 a 2 3 \frac{a^2}{3} 3a2),将 a 2 3 \frac{a^2}{3} 3a2代入到 σ 2 \sigma^2 σ2的条件中,将得到初始化域:
U ( − 6 n i n + n o u t , 6 n i n + n o u t ) . U\left(-\sqrt{\frac{6}{n_\mathrm{in} + n_\mathrm{out}}}, \sqrt{\frac{6}{n_\mathrm{in} + n_\mathrm{out}}}\right). U(−nin+nout6,nin+nout6).
尽管在上述数学推理中,“不存在非线性”的假设在神经网络中很容易被违反,但Xavier初始化方法在实践中被证明是有效的。
相关文章:
《动手学深度学习(PyTorch版)》笔记4.8
注:书中对代码的讲解并不详细,本文对很多细节做了详细注释。另外,书上的源代码是在Jupyter Notebook上运行的,较为分散,本文将代码集中起来,并加以完善,全部用vscode在python 3.9.18下测试通过。…...
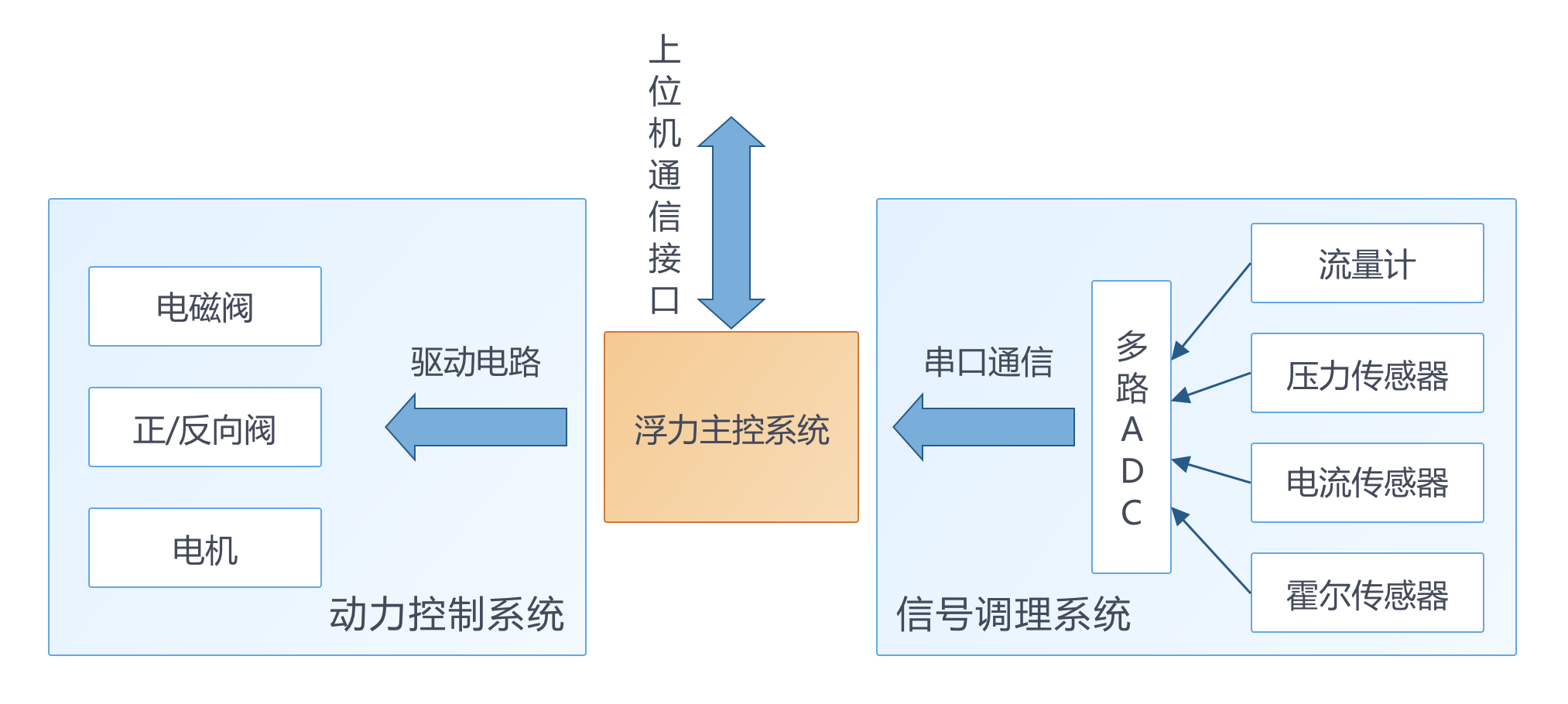
助力水下潜行:浮力调节系统仿真
01.建设海洋强国 海洋蕴藏着丰富的资源,二十大报告强调,要“发展海洋经济,保护海洋生态环境,加快建设海洋强国”。建设海洋强国旨在通过科技创新驱动、合理开发利用海洋资源、强化海洋环境保护与生态修复、提升海洋经济质量等多个…...

Mysql常用sql语句
1、建表语句 --建表语句 CREATE TABLE students (id INT PRIMARY KEY AUTO_INCREMENT,name VARCHAR(50),age INT ); 2、插入语句 --插入测试数据 insert into test_2 values(1,zhangsan); 3、查询语句 --查询语句 MySQL [test_drds_2]> select * from test_2; -------…...

dubbo rpc序列化
序列化配置 provider <dubbo:service interface"com.example.DemoService" serialization"hessian2" ref"demoService"/>consumer <dubbo:reference id"demoService" interface"com.example.DemoService" seria…...
)
【C语言】va_list(可变参数处理)
C 语言中的 va_list 类型允许函数接受可变数量的参数,这在编写需要处理不定数量参数的函数时非常有用。va_list 类型是在 stdarg.h 头文件中定义的,它允许函数处理可变数量的参数。下面我们将详细介绍 va_list 的用法以及实际应用示例。 一、va_list的用…...
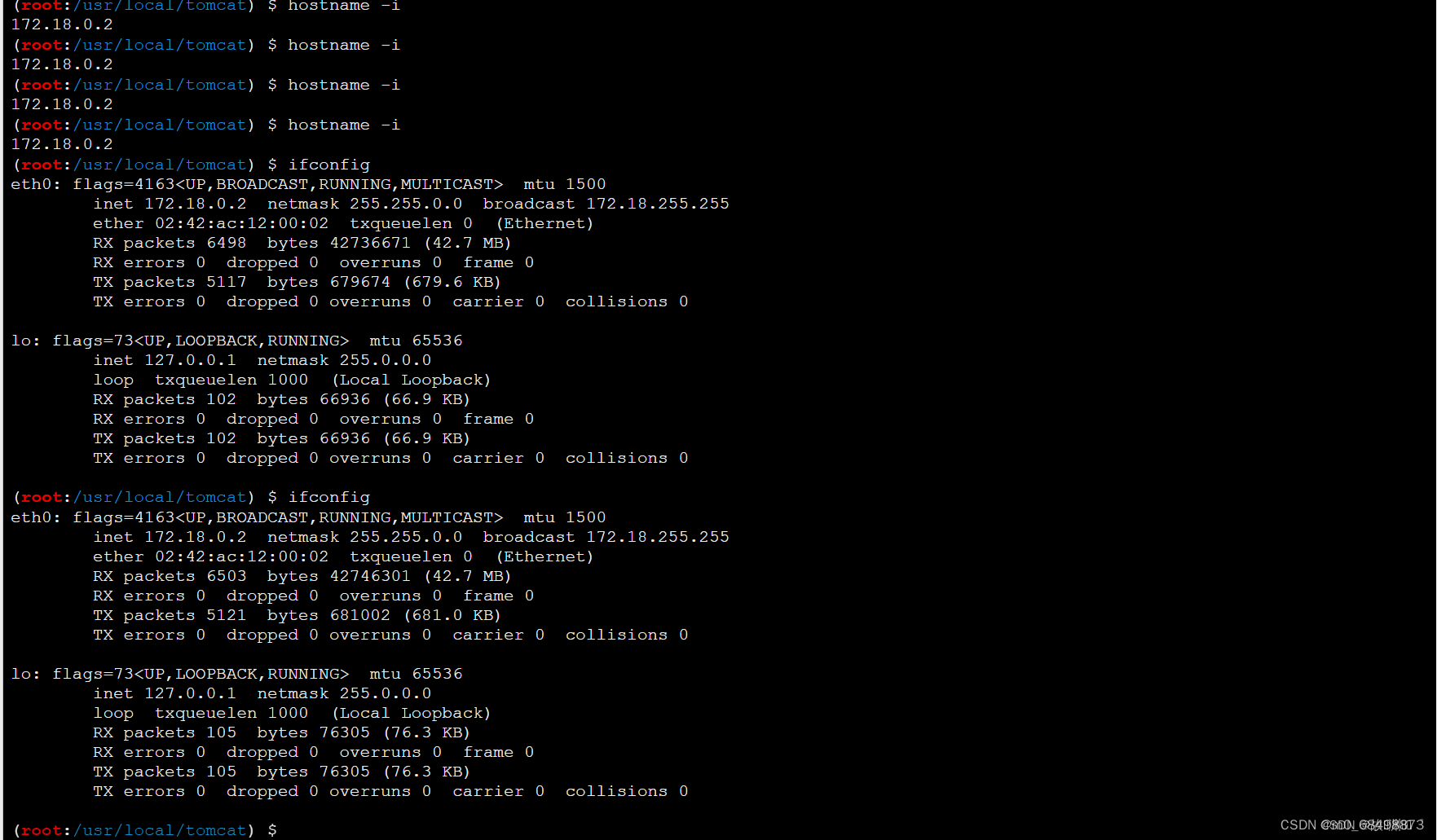
负载均衡下的webshell连接
一、环境配置 1.在Ubuntu上配置docker环境 我们选择用Xshell来将环境资源上传到Ubuntu虚拟机上(比较简单) 我们选择在root模式下进行环境配置,先将资源文件复制到root下(如果你一开始就传输到root下就不用理会这个) …...

5-4 D. DS串应用—最长重复子串
题目描述 求串的最长重复子串长度(子串不重叠)。例如:abcaefabcabc的最长重复子串是串abca,长度为4。 输入 测试次数t t个测试串 输入样例: 3 abcaefabcabc szu0123szu szuabcefg 输出 对每个测试串,输出最…...

C语言实现12种排序算法
1.冒泡排序 思路:比较相邻的两个数字,如果前一个数字大,那么就交换两个数字,直到有序。 时间复杂度:O(n^2),稳定性:这是一种稳定的算法。 代码实现: void bubble_sort(int arr[],…...

C语言应用实例——贪吃蛇
(图片由AI生成) 0.贪吃蛇游戏背景 贪吃蛇游戏,最早可以追溯到1976年的“Blockade”游戏,是电子游戏历史上的一个经典。在这款游戏中,玩家操作一个不断增长的蛇,目标是吃掉出现在屏幕上的食物,…...

Mac如何设置一位数密码?
一、问题 Mac如何设置一位数密码? 二、解答 1、打开终端 2、清除全局账户策略 sudo pwpolicy -clearaccountpolicies 输入开机密码,这里是看不见的,输入完回车即可 3、重新设置密码 (1)打开设置-->用户和群组…...

运动编辑学习笔记
目录 跳舞重建: 深度运动重定向 Motion Preprocessing Tool anim_utils MotionBuilder 跳舞重建: https://github.com/Shimingyi/MotioNet 深度运动重定向 https://github.com/DeepMotionEditing/deep-motion-editin 游锋生/deep-motion-editin…...
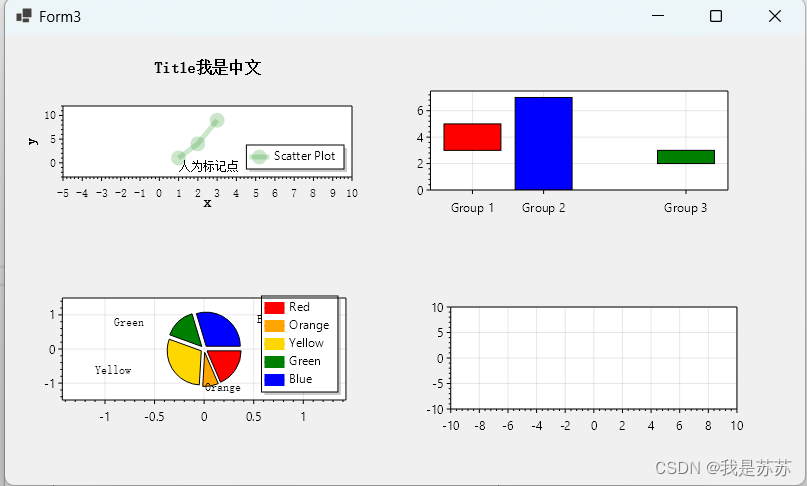
C#小结:ScottPlot 5.0在VS2022桌面开发的应用(以winform为例)
目录 一、官网文档地址 二、在VS2022中安装Scottplot 三、拖动Scottplot 四、使用Scottplot 五、效果图 一、官网文档地址 官网地址:ScottPlot 5.0 食谱 本文内容来自于官网,选取了官网的一些比较好用的功能展示,如需学习更多功能&a…...

Jmeter性能测试: Jmeter 5.6.3 分布式部署
目录 一、实验 1.环境 2.jmeter 配置 slave 代理压测机 3.jmeter配置master控制器压测机 4.启动slave从节点检查 5.启动master主节点检查 6.运行jmeter 7.观察jmeter-server主从节点变化 二、问题 1.jmeter 中间请求和响应乱码 一、实验 1.环境 (1&#…...

跟着cherno手搓游戏引擎【15】DrawCall的封装
目标: Application.cpp:把渲染循环里的glad代码封装成自己的类: #include"ytpch.h" #include "Application.h"#include"Log.h" #include "YOTO/Renderer/Renderer.h" #include"Input.h"namespace YO…...
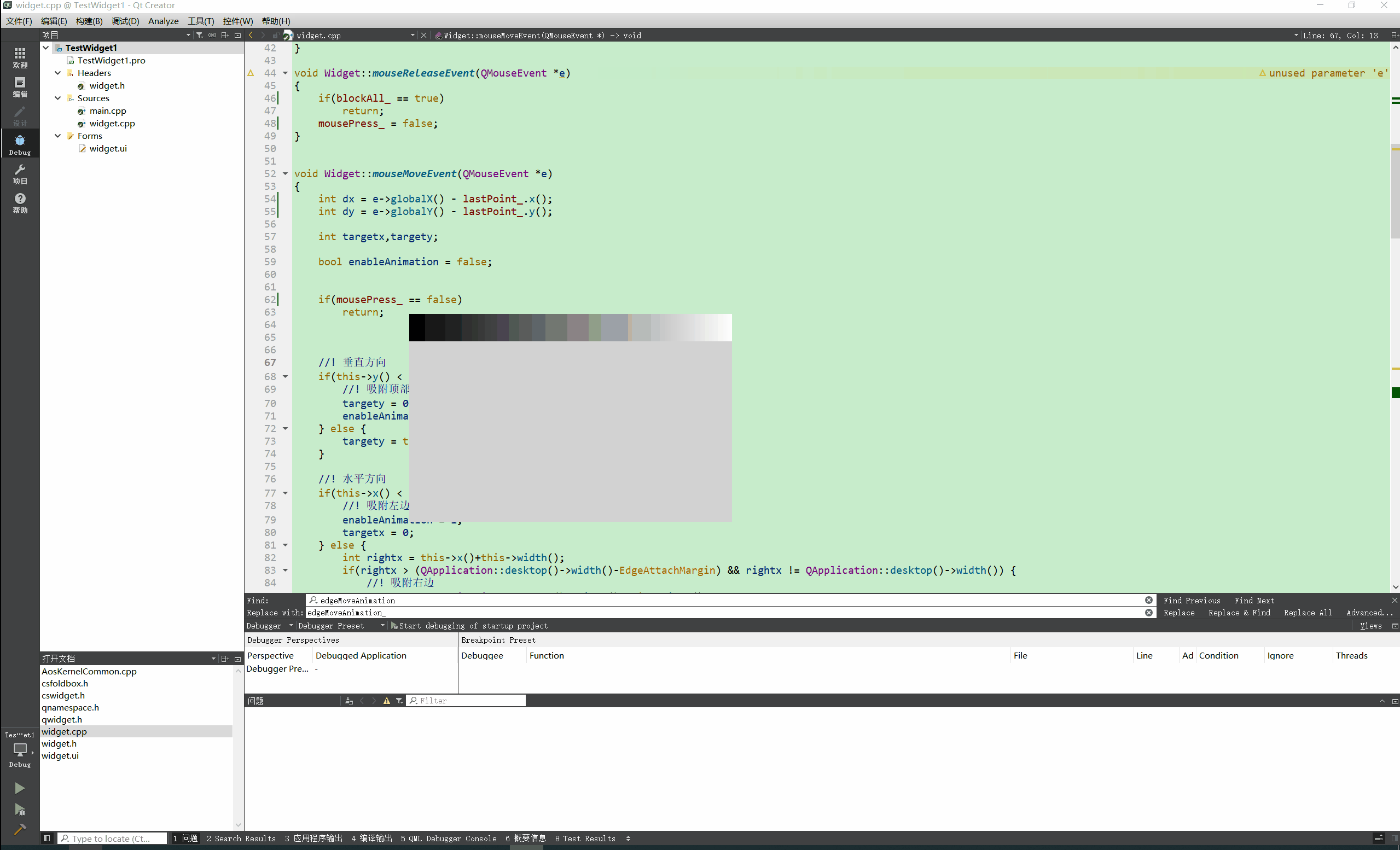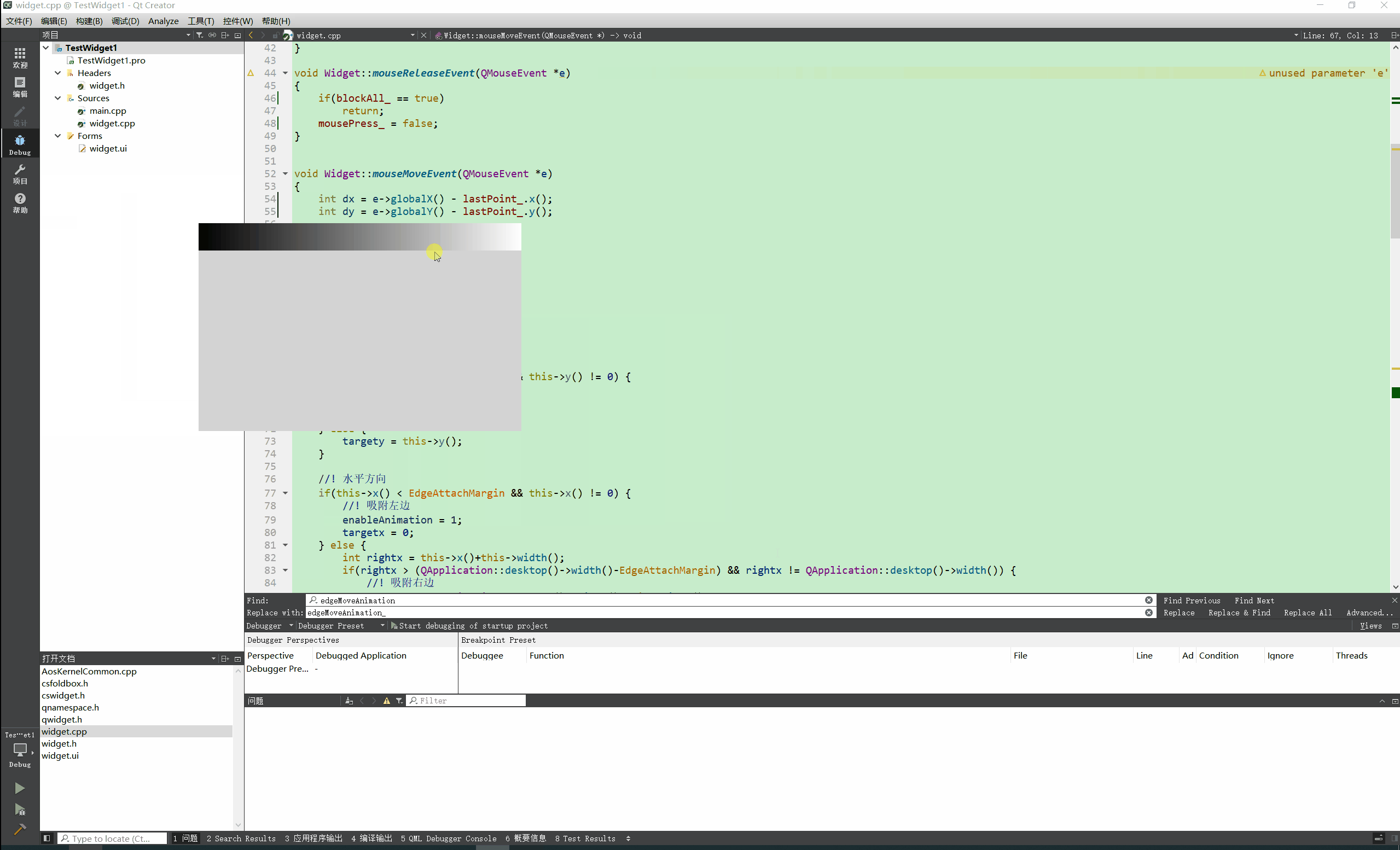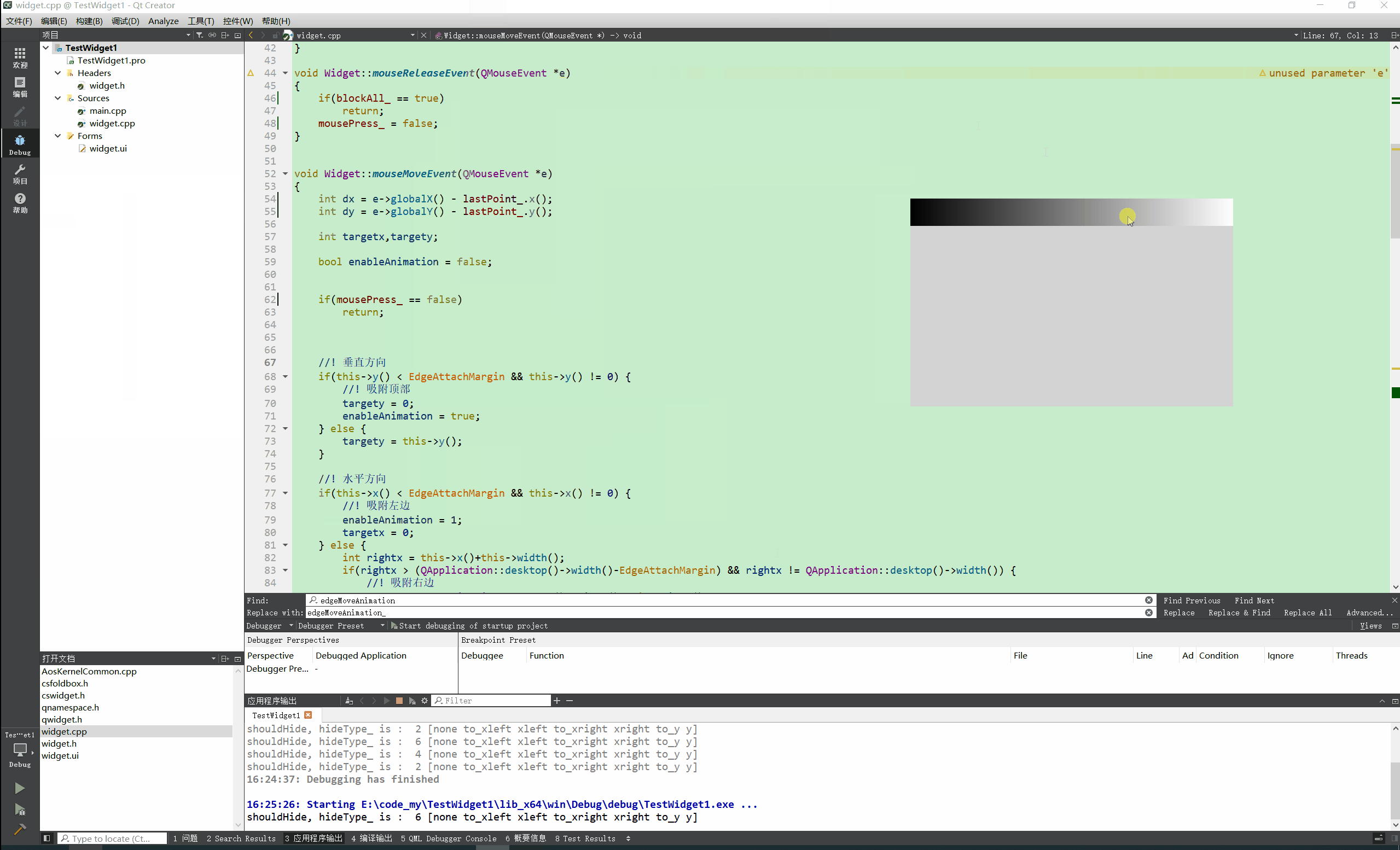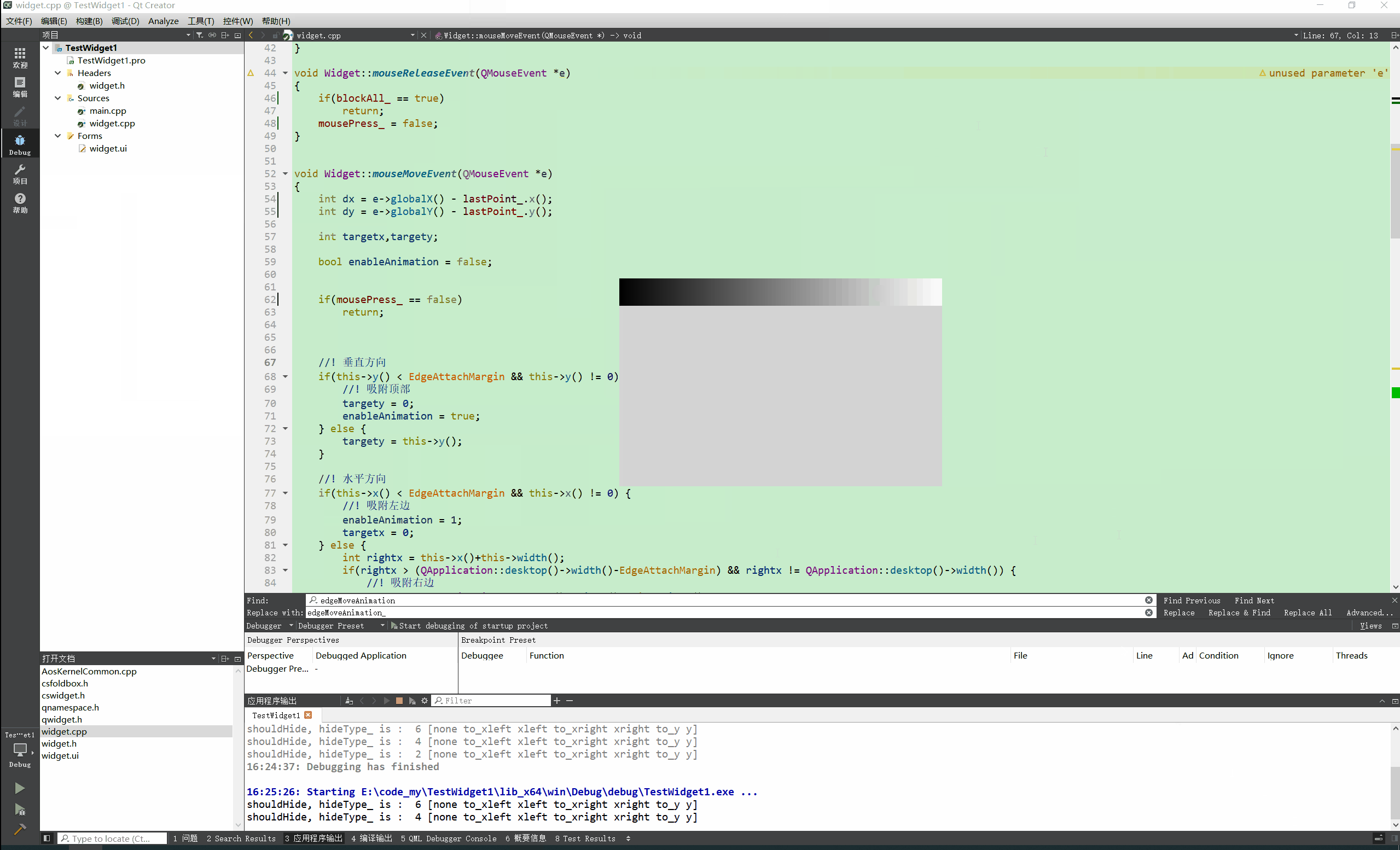
Qt实现窗口吸附屏幕边缘 自动收缩
先看效果: N年前的QQ就可以吸附到屏幕边缘,聊天时候非常方便,不用点击状态栏图标即可呼出QQ界面 自己尝试做了一个糙版的屏幕吸附效果。 关键代码: void Widget::mouseMoveEvent(QMouseEvent *e) {int dx e->globalX() - l…...
shell脚本之免交互
目录 一、Here Document 免交互 1、交互与免交互的概念 2、 Here Document 概述 二、Here Document 应用 1、使用cat命令多行重定向 2、使用tee命令多行重定向 3、使用read命令多行重定向 4、使用wc -l统计行数 5、使用passwd命令用户修改密码 6、Here Document 变量…...
Ajax入门与使用
目录 ◆ AJAX 概念和 axios 使用 什么是 AJAX? 怎么发送 AJAX 请求? 如何使用axios axios 函数的基本结构 axios 函数的使用场景 1 没有参数的情况 2 使用params参数传参的情况 3 使用data参数来处理请求体的数据 4 上传图片等二进制的情况…...
蓝桥杯备战——11.NE555测频
1.分析原理图 我们可以看到,上图就是一个NE555构建的方波发生电路,输出方波频率1.44/2(R8Rb3)C,如果有不懂NE555内部结构,工作原理的,可以到B站学习。实在不懂仿真也行,比如我下面就是仿真结果: 然后就是下…...

代码随想录算法训练营第三十三天|509. 斐波那契数 ,● 70. 爬楼梯 , 746. 使用最小花费爬楼梯
确定dp数组(dp table)以及下标的含义确定递推公式dp数组如何初始化确定遍历顺序举例推导dp数组 代码随想录 视频:从此再也不怕动态规划了,动态规划解题方法论大曝光 !| 理论基础 |力扣刷题总结| 动态规划入门_哔哩哔哩…...

Node.js 文件系统操作指南
文章目录 Node.js 文件系统操作完全指南一、引言二、基本文件操作2.1 读取文件2.2 写入文件2.3 追加内容到文件 三、文件与目录的创建与删除3.1 创建文件3.2 创建目录3.3 删除文件3.4 删除目录 四、文件与目录的信息查询4.1 检查文件或目录是否存在4.2 获取文件信息4.3 获取目录…...

2026 AI 培训机构怎么选?6 类人群精准匹配 + 避坑指南
随着大模型、多模态、RAG、Agent 技术持续迭代,企业对于 AI 算法开发、计算机视觉、自然语言处理、工程落地类人才的需求持续上涨。目前国内主流AI学习平台包含咕泡科技、科大讯飞AI大学堂、腾讯云智学堂、深兰科技人工智能教育等,各家平台技术侧重点、课…...
)
从零构建Sora 2-UE5.4可信工作流:基于IEEE 1872标准的生成内容元数据注入方案(附GitHub认证仓库)
更多请点击: https://intelliparadigm.com 第一章:从零构建Sora 2-UE5.4可信工作流:基于IEEE 1872标准的生成内容元数据注入方案(附GitHub认证仓库) 核心目标与标准对齐 本工作流严格遵循 IEEE P1872™(O…...

5分钟快速获取微信数据库密钥:Sharp-dumpkey完整使用指南
5分钟快速获取微信数据库密钥:Sharp-dumpkey完整使用指南 【免费下载链接】Sharp-dumpkey 基于C#实现的获取微信数据库密钥的小工具 项目地址: https://gitcode.com/gh_mirrors/sh/Sharp-dumpkey 你是否曾因为无法访问自己的微信聊天记录而感到困扰ÿ…...

LoRA参数高效微调:低秩适配原理与可视化实战
1. 项目概述:这不是调参,是给大模型“打补丁”的手艺活LoRA(Low-Rank Adaptation)不是什么新潮概念,它本质上是一种参数高效微调(PEFT)的工程实践智慧——当你要让一个百亿参数的GPT或BERT模型去…...

程序员35岁以后最好的投资:不是买房,是这3样东西
当“35岁红线”撞上测试人的职业围城如果你在某个深夜刷到“程序员35岁以后该何去何从”的帖子时,心底划过一丝隐痛,那你绝不是一个人。而对于软件测试从业者而言,这种焦虑往往被放大得更加具体——当“点点点”的手工测试逐渐被自动化替代&a…...

5分钟搞定专业照片水印:Semi-Utils让你的摄影作品瞬间升级
5分钟搞定专业照片水印:Semi-Utils让你的摄影作品瞬间升级 【免费下载链接】semi-utils 一个批量添加相机机型和拍摄参数的工具,后续「可能」添加其他功能。 项目地址: https://gitcode.com/gh_mirrors/se/semi-utils 还在为照片添加水印而烦恼吗…...

基于FPGA的嵌入式频谱分析仪设计:低功耗实时信号处理方案
1. 项目概述:为什么要在FPGA上做频谱分析仪?做射频测试的工程师,对频谱分析仪肯定不陌生。实验室里动辄几十万上百万的台式机,性能强悍,功能全面,但有个问题:它离不开实验室。当你需要做外场测试…...

Scarab终极教程:2024年最完整的空洞骑士模组管理器使用指南
Scarab终极教程:2024年最完整的空洞骑士模组管理器使用指南 【免费下载链接】Scarab An installer for Hollow Knight mods written with Avalonia. 项目地址: https://gitcode.com/gh_mirrors/sc/Scarab 还在为空洞骑士模组安装而烦恼吗?Scarab模…...

java springboot-vue加油站管理系统的设计与实现
目录同行可拿货,招校园代理 ,本人源头供货商项目背景技术架构核心功能模块系统特色部署方式应用场景项目技术支持源码获取详细视频演示 :同行可合作点击我获取源码->->进我个人主页-->获取博主联系方式同行可拿货,招校园代理 ,本人源头供货商 项目背景 加…...
二进制序列化)
(QBuffer配合 QDataStream)二进制序列化
QByteArray arr; QBuffer buf(&arr); buf.open(QIODevice::WriteOnly); QDataStream out(&buf); out << QString(“hello”) << 123; // 序列化 // 反序列化 buf.seek(0); QDataStream in(&buf); QString s; int n; in >> s >> n;...