一些Linux内核内存性能调优笔记!
前言
在工作生活中,我们时常会遇到一些性能问题:比如手机用久了,在滑动窗口或点击 APP 时会出现页面反应慢、卡顿等情况;比如运行在某台服务器上进程的某些性能指标(影响用户体验的 PCT99 指标等)不达预期,产生告警等;造成性能问题的原因多种多样,可能是网络延迟高、磁盘 IO 慢、调度延迟高、内存回收等,这些最终都可能影响到用户态进程,进而被用户感知。
在 Linux 服务器场景中,内存是影响性能的主要因素之一,本文从内存管理的角度,总结归纳了一些常见的影响因素(比如内存回收、Page Fault 增多、跨 NUMA 内存访问等),并介绍其对应的调优方法。
内存回收
操作系统总是会尽可能利用速度更快的存储介质来缓存速度更慢的存储介质中的内容,这样就可以显著的提高用户访问速度。比如,我们的文件一般都存储在磁盘上,磁盘对于程序运行的内存来说速度很慢,因此操作系统在读写文件时,都会将磁盘中的文件内容缓存到内存上(也叫做 page cache),这样下次再读取到相同内容时就可以直接从内存中读取,不需要再去访问速度更慢的磁盘,从而大大提高文件的读写效率。上述情况需要在内存资源充足的前提条件下,然而在内存资源紧缺时,操作系统自身难保,会选择尽可能回收这些缓存的内存,将其用到更重要的任务中去。这时候,如果用户再去访问这些文件,就需要访问磁盘,如果此时磁盘也很繁忙,那么用户就会感受到明显的卡顿,也就是性能变差了。
在 Linux 系统中,内存回收分为两个层面:整机和 memory cgroup。
在整机层面
设置了三条水线:min、low、high;当系统 free 内存降到 low 水线以下时,系统会唤醒kswapd 线程进行异步内存回收,一直回收到 high 水线为止,这种情况不会阻塞正在进行内存分配的进程;但如果 free 内存降到了 min 水线以下,就需要阻塞内存分配进程进行回收,不然就有 OOM(out of memory)的风险,这种情况下被阻塞进程的内存分配延迟就会提高,从而感受到卡顿。
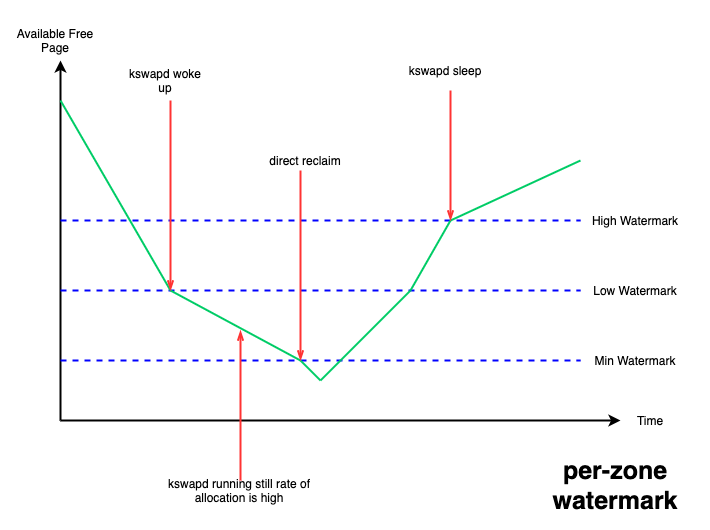
图 1. per-zone watermark
这些水线可以通过内核提供的 /proc/sys/vm/watermark_scale_factor 接口来进行调整,该接口合法取值的范围为 [0, 1000],默认为 10,当该值设置为 1000 时,意味着 low 与 min 水线,以及 high 与 low 水线间的差值都为总内存的 10% (1000/10000) 。
针对 page cache 型的业务场景,我们可以通过该接口抬高 low 水线,从而更早的唤醒 kswapd 来进行异步的内存回收,减少 free 内存降到 min 水线以下的概率,从而避免阻塞到业务进程,以保证影响业务的性能指标。
在 memory cgroup 层面
目前内核没有设置水线的概念,当内存使用达到 memory cgroup 的内存限制后,会阻塞当前进程进行内存回收。不过内核在 v5.19内核 中为 memory cgroup提供了 memory.reclaim 接口,用户可以向该接口写入想要回收的内存大小,来提早触发 memory cgroup 进行内存回收,以避免阻塞 memory cgroup 中的进程。
Huge Page
内存作为宝贵的系统资源,一般都采用延迟分配的方式,应用程序第一次向分配的内存写入数据的时候会触发 Page Fault,此时才会真正的分配物理页,并将物理页帧填入页表,从而与虚拟地址建立映射。
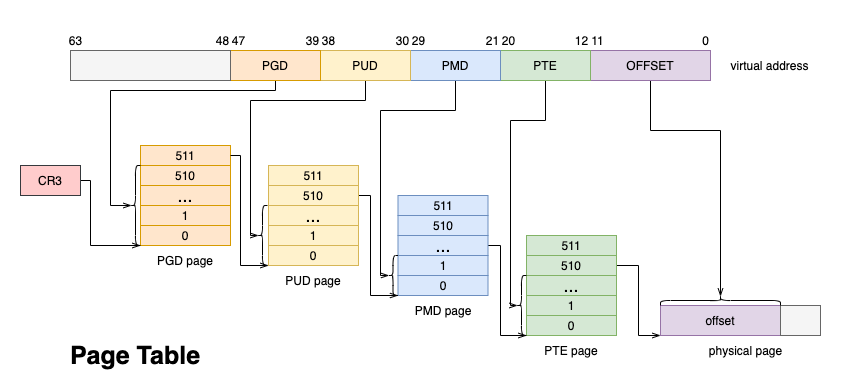
图 2. Page Table
此后,每次 CPU 访问内存,都需要通过 MMU 遍历页表将虚拟地址转换成物理地址。为了加速这一过程,一般都会使用 TLB(Translation-Lookaside Buffer)来缓存虚拟地址到物理地址的映射关系,只有 TLB cache miss 的时候,才会遍历页表进行查找。
页的默认大小一般为 4K,随着应用程序越来越庞大,使用的内存越来越多,内存的分配与地址翻译对性能的影响越加明显。试想,每次访问新的 4K 页面都会触发 Page Fault,2M 的页面就需要触发 512 次才能完成分配。
另外 TLB cache 的大小有限,过多的映射关系势必会产生 cacheline 的冲刷,被冲刷的虚拟地址下次访问时又会产生 TLB miss,又需要遍历页表才能获取物理地址。
对此,Linux 内核提供了大页机制 。上图的 4 级页表中,每个 PTE entry 映射的物理页就是 4K,如果采用 PMD entry 直接映射物理页,则一次 Page Fault 可以直接分配并映射 2M 的大页,并且只需要一个 TLB entry 即可存储这 2M 内存的映射关系,这样可以大幅提升内存分配与地址翻译的速度 。
因此,一般推荐占用大内存应用程序使用大页机制分配内存 。当然大页也会有弊端:比如初始化耗时高,进程内存占用可能变高等。
可以使用 perf 工具对比进程使用大页前后的 PageFault 次数的变化:
perf stat -e page-faults -p-- sleep 5目前内核提供了两种大页机制,一种是需要提前预留的静态大页形式,另一种是透明大页(THP, Transparent Huge Page) 形式。
资料直通车:Linux内核源码技术学习路线+视频教程内核源码
学习直通车:Linux内核源码内存调优文件系统进程管理设备驱动/网络协议栈
1. 静态大页
首先来看静态大页,也叫做 HugeTLB。静态大页可以设置 cmdline 参数在系统启动阶段预留,比如指定大页 size 为 2M,一共预留 512 个这样的大页:
hugepagesz=2M hugepages=512还可以在系统运行时动态预留,但该方式可能因为系统中没有足够的连续内存而预留失败。
-
预留默认 size(可以通过 cmdline 参数 default_hugepagesz=指定size)的大页:
echo 20 > /proc/sys/vm/nr_hugepages-
预留特定 size 的大页:
echo 5 > /sys/kernel/mm/hugepages/hugepages-*/nr_hugepages-
预留特定 node 上的大页:
echo 5 > /sys/devices/system/node/node*/hugepages/hugepages-*/nr_hugepages当预留的大页个数小于已存在的个数,则会释放多余大页(前提是未被使用)。
编程中可以使用 mmap(MAP_HUGETLB) 申请内存。详细使用可以参考内核文档 :https://www.kernel.org/doc/Documentation/admin-guide/mm/hugetlbpage.rst
这种大页的优点是一旦预留成功,就可以满足进程的分配请求,还避免该部分内存被回收;缺点是:
(1) 需要用户显式地指定预留的大小和数量。
(2) 需要应用程序适配,比如:
-
mmap、shmget 时指定 MAP_HUGETLB;
-
挂载 hugetlbfs,然后 open 并 mmap
当然也可以使用开源 libhugetlbfs.so,这样无需修改应用程序
预留太多大页内存后,free 内存大幅减少,容易触发系统内存回收甚至 OOM
紧急情况下可以手动减少 nr_hugepages,将未使用的大页释放回系统;也可以使用 v5.7 引入的HugeTLB + CMA 方式,细节读者可以自行查阅。
2. 透明大页
再来看透明大页,在 THP always 模式下,会在 Page Fault 过程中,为符合要求的 vma 尽量分配大页进行映射;如果此时分配大页失败,比如整机物理内存碎片化严重,无法分配出连续的大页内存,那么就会 fallback 到普通的 4K 进行映射,但会记录下该进程的地址空间 mm_struct;然后 THP 会在后台启动khugepaged 线程,定期扫描这些记录的 mm_struct,并进行合页操作。因为此时可能已经能分配出大页内存了,那么就可以将此前 fallback 的 4K 小页映射转换为大页映射,以提高程序性能。整个过程完全不需要用户进程参与,对用户进程是透明的,因此称为透明大页。
虽然透明大页使用起来非常方便、智能,但也有一定的代价:
(1)进程内存占用可能远大所需:因为每次Page Fault 都尽量分配大页,即使此时应用程序只读写几KB
(2)可能造成性能抖动:
-
在第 1 种进程内存占用可能远大所需的情况下,可能造成系统 free 内存更少,更容易触发内存回收;系统内存也更容易碎片化。
-
khugepaged 线程合页时,容易触发页面规整甚至内存回收,该过程费时费力,容易造成 sys cpu 上升。
-
mmap lock 本身是目前内核的一个性能瓶颈,应当尽量避免 write lock 的持有,但 THP 合页等操作都会持有写锁,且耗时较长(数据拷贝等),容易激化 mmap lock 锁竞争,影响性能。
因此 THP 还支持 madvise 模式,该模式需要应用程序指定使用大页的地址范围,内核只对指定的地址范围做 THP 相关的操作。这样可以更加针对性、更加细致地优化特定应用程序的性能,又不至于造成反向的负面影响。
可以通过 cmdline 参数和 sysfs 接口设置 THP 的模式:
cmdline 参数:
transparent_hugepage=madvisesysfs 接口:
echo madvise > /sys/kernel/mm/transparent_hugepage/enabled详细使用可以参考内核文档 : https://www.kernel.org/doc/Documentation/admin-guide/mm/transhuge.rst
mmap_lock 锁
上一小节有提到 mmap_lock 锁,该锁是内存管理中的一把知名的大锁,保护了诸如mm_struct 结构体成员、 vm_area_struct 结构体成员、页表释放等很多变量与操作。
mmap_lock 的实现是读写信号量 ,当写锁被持有时,所有的其他读锁与写锁路径都会被阻塞。Linux 内核已经尽可能减少了写锁的持有场景以及时间,但不少场景还是不可避免的需要持有写锁,比如 mmap 以及 munmap 路径、mremap 路径和 THP 转换大页映射路径等场景。
应用程序应该避免频繁的调用会持有 mmap_lock 写锁的系统调用 (syscall) ,比如有时可以使用 madvise(MADV_DONTNEED)释放物理内存,该参数下,madvise 相比 munmap 只持有 mmap_lock 的读锁,并且只释放物理内存,不会释放 VMA 区域,因此可以再次访问对应的虚拟地址范围,而不需要重新调用 mmap 函数。
另外对于 MADV_DONTNEED,再次访问还是会触发 Page Fault 分配物理内存并填充页表,该操作也有一定的性能损耗 。如果想进一步减少这部分损耗,可以改为 MADV_FREE 参数,该参数也只会持有 mmap_lock 的读锁,区别在于不会立刻释放物理内存,会等到内存紧张时才进行释放,如果在释放之前再次被访问则无需再次分配内存,进而提高内存访问速度。
一般 mmap_lock 锁竞争激烈会导致很多 D 状态进程(TASK_UNINTERRUPTIBLE),这些 D 进程都是进程组的其他线程在等待写锁释放。因此可以打印出所有 D 进程的调用栈,看是否有大量 mmap_lock 的等待。
for i in `ps -aux | grep " D" | awk '{ print $2}'`; do echo $i; cat /proc/$i/stack; done内核社区专门封装了 mmap_lock 相关函数,并在其中增加了 tracepoint,这样可以使用 bpftrace 等工具统计持有写锁的进程、调用栈等,方便排查问题,确定优化方向。
bpftrace -e 'tracepoint:mmap_lock:mmap_lock_start_locking /args->write == true/{ @[comm, kstack] = count();}'跨 numa 内存访问
在 NUMA 架构下,CPU 访问本地 node 内存的速度要大于远端 node,因此应用程序应尽可能访问本地 node 上的内存。可以通过 numastat 工具查看 node 间的内存分配情况:
-
观察整机是否有很多 other_node 指标(远端内存访问)上涨:
watch -n 1 numastat -s-
查看单个进程在各个node上的内存分配情况:
numastat -p1. 绑 node
可以通过 numactl 等工具把进程绑定在某个 node 以及对应的 CPU 上,这样该进程只会从该本地 node 上分配内存。
但这样做也有相应的弊端,比如:该 node 剩余内存不够时,进程也无法从其他 node 上分配内存,只能期待内存回收后释放足够的内存,而如果进入直接内存回收会阻塞内存分配,就会有一定的性能损耗。
此外,进程组的线程数较多时,如果都绑定在一个 node 的 CPU 上,可能会造成 CPU 瓶颈,该损耗可能比远端 node 内存访问还大,比如 ngnix 进程与网卡就推荐绑定在不同的 node 上,这样虽然网卡收包时分配的内存在远端 node 上,但减少了本地 node 的 CPU 上的网卡中断,反而可以获得更好的性能提升。
2. numa balancing
内核还提供了 numa balancing 机制,可以通过 /proc/sys/kernel/numa_balancing 文件或者 cmdline 参数 numa_balancing=进行开启。
该机制可以动态的将进程访问的 page 从远端 node 迁移到本地 node 上,从而使进程可以尽可能的访问本地内存。
但该机制实现也有相应的代价,在 page 的迁移是通过 Page Fault 机制实现的,会有相应的性能损耗;另外如果迁移时找不到合适的目标 node,可能还会把进程迁移到正在访问的 page 的 node 的 CPU 上,这可能还会导致 cpu cache miss,从而对性能造成更大的影响。
因此需要根据业务进程的具体行为,来决定是否开启 numa balancing 功能 。
总结
性能优化一直是大家关注的话题,其优化方向涉及到 CPU 调度、内存、IO等,本文重点针对内存优化提出了几点思路。但是鱼与熊掌不可兼得,文章提到的调优操作都有各自的优点和缺点,不存在一个适用于所有情况的优化方法。针对于不同的 workload,需要分析出具体的性能瓶颈,从而采取对应的调优方法,不能一刀切的进行设置 。在没有发现明显性能抖动的情况下,往往可以继续保持当前配置。

相关文章:
一些Linux内核内存性能调优笔记!
前言 在工作生活中,我们时常会遇到一些性能问题:比如手机用久了,在滑动窗口或点击 APP 时会出现页面反应慢、卡顿等情况;比如运行在某台服务器上进程的某些性能指标(影响用户体验的 PCT99 指标等)不达预期…...

【JVM】逃逸分析
开发者都知道,基本上所有对象都是在堆上创建。但是,这里还是没有把话说绝对哈,指的是基本上所有。昨天一位朋友在聊天中,就说了所有对象都在堆中创建,然后被朋友一阵的嘲笑。 开始我们的正文,我们今天来聊聊…...

C51---震动传感器控制LED灯亮灭
1.example #include "reg52.h" sbit led1 P3^7;//原理图中led1指向P3组IO口的P3.7口 sbit vibrate P3^3;//Do接到了P3.3口 void Delay3000ms() //11.0592MHz { unsigned char i, j, k; //_nop_(); i 22; j 3; k 227; do { …...
使用 JaCoCo 生成测试覆盖率报告
0、为什么要生成测试覆盖率报告 在我们实际的工作中,当完成程序的开发后,需要提交给测试人员进行测试,经过测试人员测试后,代码才能上线到生产环境。 有个问题是:怎么能证明程序得到了充分的测试,程序中所…...

windows下neo4j安装及配置,并绘制人物关系图谱
neo4j安装及配置,绘制人物关系图谱 先升级pip,安装py2neo pip install py2neo2021.0.1依赖 jdk1.8, neo4j 3.xx; 或者jdk18,neo4j 4.x,5.x; 官网下载了neo4j4.x,5.x 因为jdk版本原因都不行&am…...
【Spring6】IoC容器之基于XML管理Bean
3、容器:IoC IoC 是 Inversion of Control 的简写,译为“控制反转”,它不是一门技术,而是一种设计思想,是一个重要的面向对象编程法则,能够指导我们如何设计出松耦合、更优良的程序。 Spring 通过 IoC 容…...

Warshall算法求传递闭包及Python编程的实现
弗洛伊德算法-Floyd(Floyd-Warshall)-求多源最短路径,求传递闭包 Floyd算法又称为插点法,是一种利用动态规划的思想寻找给定的加权图中多源点之间最短路径的算法, 与Dijkstra算法类似。该算法名称以创始人之一、1978年图灵奖获得者、斯坦福大…...

AcWing第 93 场周赛
4867. 整除数 给定两个整数 n,k,请你找到大于 n 且能被 k 整除的最小整数 x。 输入格式 共一行,包含两个整数 n,k。 输出格式 输出大于 n 且能被 k 整除的最小整数 x。 数据范围 前 4 个测试点满足 1≤n,k≤100。 所有测试点满足 1≤n,k≤109。 …...

计及需求响应的粒子群算法求解风能、光伏、柴油机、储能容量优化配置(Matlab代码实现)
👨🎓个人主页:研学社的博客💥💥💞💞欢迎来到本博客❤️❤️💥💥🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密…...
利用Nginx给RStudio-Server配置https
前篇文档,我这边写了安装RStudio-Server的方法。默认是http的访问方式,现在我们需要将其改成https的访问方式。 1、给服务器安装Nginx:参照之前的安装Nginx的方法。 2、创建/usr/local/nginx/ssl目录: mkdir /usr/local/nginx/ss…...

YOLOv7实验记录
这篇博客主要记录博主在做YOLOv7模型训练与测试过程中遇到的一些问题。 首先我们需要明确YOLO模型权重文件与模型文件的使用 其实在github的readme中已经告诉我们使用方法,但我相信有很多像博主一样眼高手低的人可能会犯类似的错误。 训练 首先是训练时的设置&…...

用Python获取史瓦西时空中克氏符的分量
文章目录三维球面坐标史瓦西时空三维球面坐标 Einsteinpy中提供了克氏符模型,可通过ChristoffelSymbols获取。简单起见,先以最直观的三维球面为例,来用Einsteinpy查看其克氏符的表达形式。 三维球面的度规张量可表示为 g001g11r2g22r2sin…...
QML编码约定
QML中的国际化: QML使用以下函数来将字符串标记为可翻译的 qsTr()qsTranslate()qsTrld()QT_TR_NOOP()QT_TRANSLATE_NOOP()QT_TRID_NOOP最常用的还是qsTr() string qsTr(string sourceText, string disambiguation&…...
【Linux】安装Linux操作系统具体步骤
1). 选择创建新的虚拟机 2). 选择"典型"配置 3). 选择"稍后安装操作系统(S)" 4). 选择"Linux"操作系统,"CentOS7 64位"版本 5). 设置虚拟机的名称及系统文件存放路径 6). 设置磁盘容量 7). 自定义硬件信息 8). 启动上述创建的新虚拟机…...
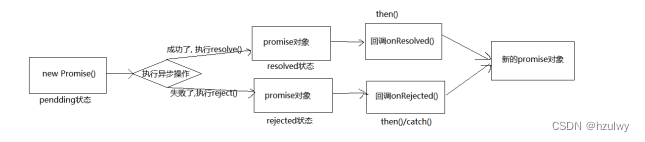
前端ES6异步编程技术——Promise使用
Promise是什么 官方的定义是:Promise是ES6新推出的用于进行异步编程的解决方案,旧方案是单纯使用回调函数来解决的。对于开发人员来说,我们把promise当作一个普通的对象即可,使用它可以用来封装一个异步操作并可以获取其成功/失败…...
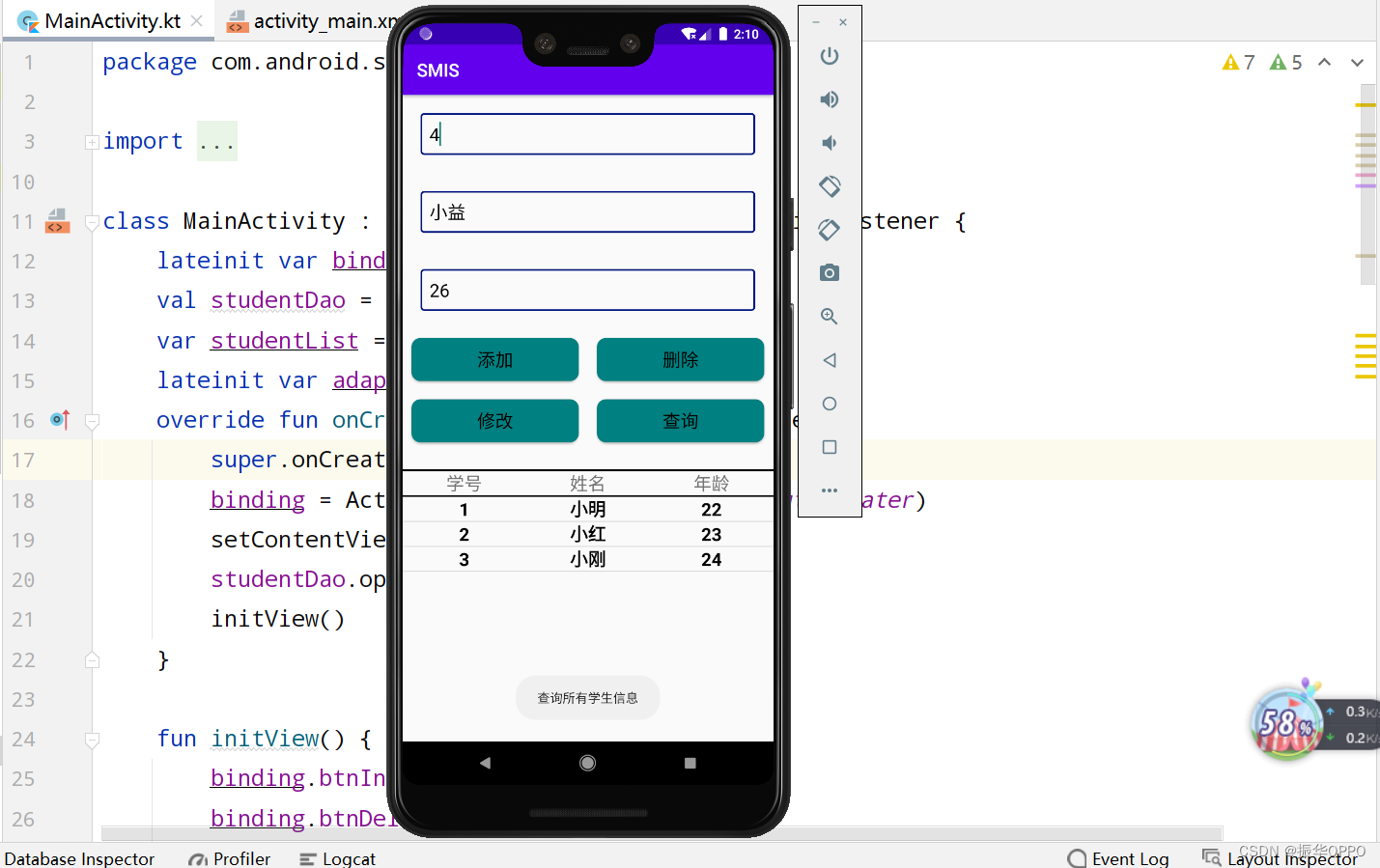
Kotlin实现简单的学生信息管理系统
文章目录一、实验内容二、实验步骤1、页面布局2、数据库3、登录活动4、增删改查三、运行演示四、实验总结五、源码下载一、实验内容 根据Android数据存储的内容,综合应用SharedPreferences和SQLite数据库实现一个用户信息管理系统,强化对SharedPreferen…...

413. 等差数列划分
413. 等差数列划分 如果一个数列 至少有三个元素 ,并且任意两个相邻元素之差相同,则称该数列为等差数列。 例如,[1,3,5,7,9]、[7,7,7,7] 和 [3,-1,-5,-9] 都是等差数列。 给你一个整数数组 nums ,返回数组 nums 中所有为等差数…...
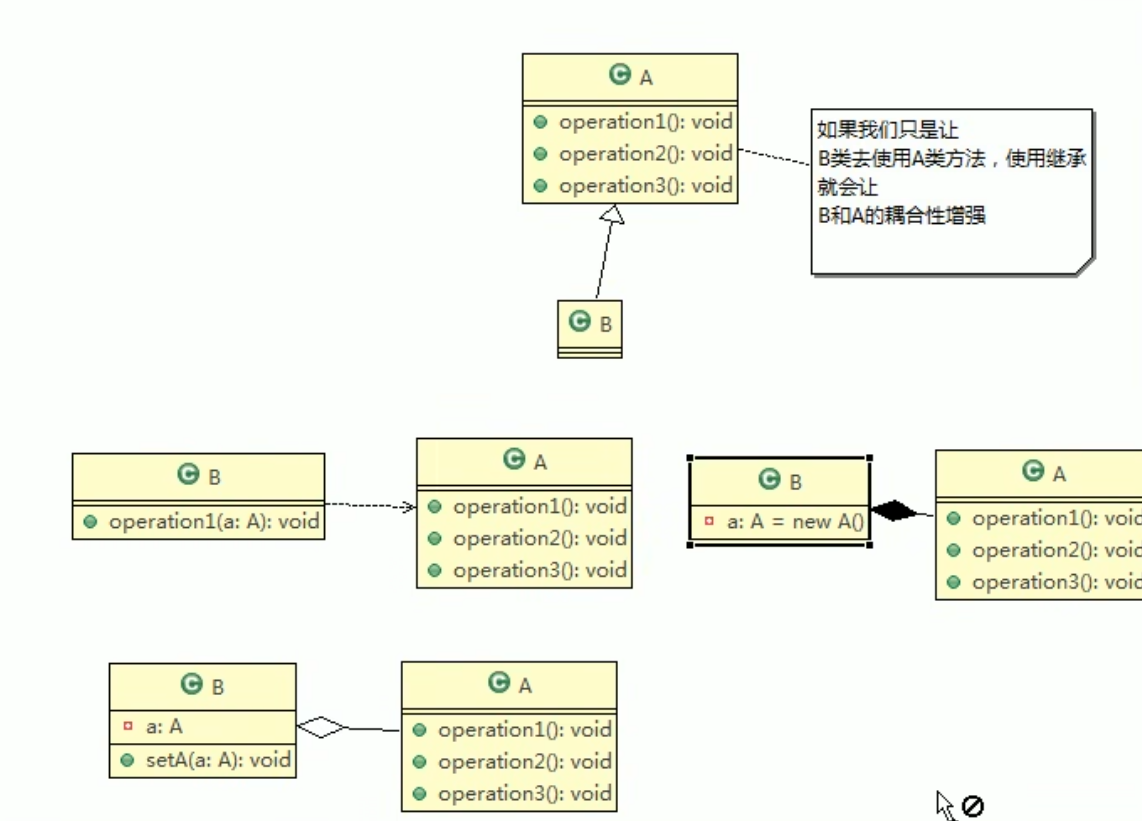
设计模式七大原则
一、设计模式概念 1.1 软件设计模式的产生背景 "设计模式"最初并不是出现在软件设计中,而是被用于建筑领域的设计中。 1977年美国著名建筑大师、加利福尼亚大学伯克利分校环境结构中心主任克里斯托夫亚历山大(Christopher Alexander&#x…...

【Mybatis系列】Mybatis常见的分页方法以及源码理解
Mybatis-Plus的selectPage 引入依赖 <dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.5.1</version></dependency>添加分页插件 Configuration public class My…...
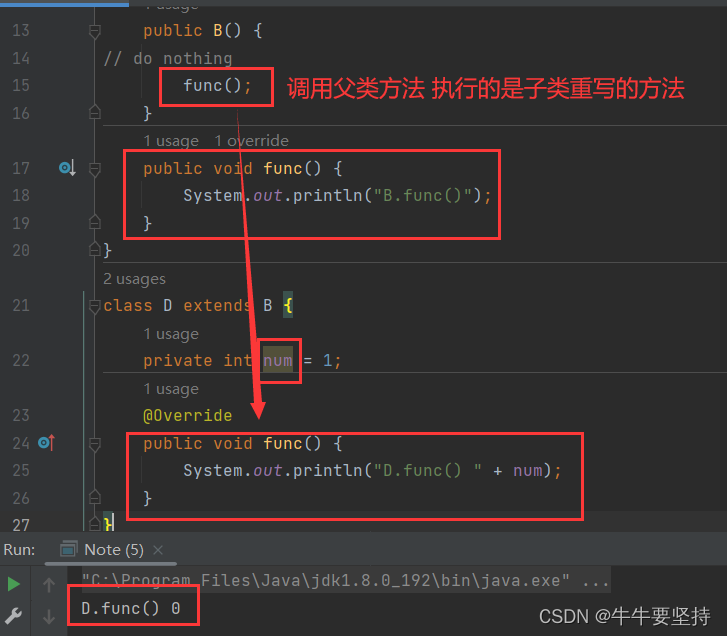
Java面向对象:多态特性的学习
本文介绍了Java面向对象多态特性, 多态的介绍. 多态的实现条件–1.发生继承.2.发生重写(重写与重载的区别)3.向上转型与向下转型.4.静态绑定和动态绑定5. 实现多态 举例总结多态的优缺点 避免在构造方法内调用被重写的方法… Java面向对象:多态特性的学习一.什么是多态?二.多态…...

5G NR物理层控制信令实战:从PDCCH盲解码到DCI格式解析
5G NR物理层控制信令实战:从PDCCH盲解码到DCI格式解析 在5G新空口(NR)系统中,物理层控制信令是实现高效资源调度和可靠数据传输的核心机制。作为无线通信协议栈开发工程师和网络优化人员,深入理解PDCCH盲解码机制、COR…...

终极GoogleTest死亡测试指南:如何轻松掌握程序异常退出测试技巧
终极GoogleTest死亡测试指南:如何轻松掌握程序异常退出测试技巧 【免费下载链接】googletest GoogleTest - Google Testing and Mocking Framework 项目地址: https://gitcode.com/GitHub_Trending/go/googletest GoogleTest(Google Testing and …...

OpenClaw成本警报:gemma-3-12b-it的Token消耗监控与限额设置
OpenClaw成本警报:gemma-3-12b-it的Token消耗监控与限额设置 1. 为什么需要关注Token消耗? 上周我的OpenClaw自动化流程突然中断,检查日志发现是gemma-3-12b-it模型的API调用达到了限额。更让我后怕的是,如果这个限额不存在&…...

效率倍增:将matlab算法思路在快马平台秒级转化为可运行web应用
今天想和大家分享一个提升算法验证效率的小技巧——如何把MATLAB里的算法思路快速转化为可运行的Web应用。作为一个经常需要验证信号处理算法的人,我发现MATLAB虽然强大,但每次启动软件、初始化项目都要耗费不少时间。后来尝试用InsCode(快马)平台后&…...

MusePublic艺术创作引擎保姆级教程:从安装到生成高清艺术图
MusePublic艺术创作引擎保姆级教程:从安装到生成高清艺术图 1. 准备工作与环境搭建 在开始使用MusePublic艺术创作引擎前,我们需要确保系统环境满足基本要求。这个轻量化的艺术创作工具对硬件配置相对友好,但仍有几个关键点需要注意。 1.1…...

MobaXterm中文版:5步教你掌握Windows最强远程管理神器
MobaXterm中文版:5步教你掌握Windows最强远程管理神器 【免费下载链接】Mobaxterm-Chinese Mobaxterm simplified Chinese version. Mobaxterm 的简体中文版. 项目地址: https://gitcode.com/gh_mirrors/mo/Mobaxterm-Chinese 还在为远程服务器管理烦恼吗&am…...

Batocera.linux主题定制完全指南:打造个性化游戏界面终极教程
Batocera.linux主题定制完全指南:打造个性化游戏界面终极教程 【免费下载链接】batocera.linux batocera.linux 项目地址: https://gitcode.com/gh_mirrors/ba/batocera.linux Batocera.linux是一款强大的开源复古游戏系统,让用户能够在各种硬件上…...

3步攻克iOS激活锁:AppleRa1n工具技术解析与实战指南
3步攻克iOS激活锁:AppleRa1n工具技术解析与实战指南 【免费下载链接】applera1n icloud bypass for ios 15-16 项目地址: https://gitcode.com/gh_mirrors/ap/applera1n 激活锁(苹果设备的防盗验证机制)是一把双刃剑,它在保…...

TQVaultAE:让《泰坦之旅》装备管理不再头痛的黑科技
TQVaultAE:让《泰坦之旅》装备管理不再头痛的黑科技 【免费下载链接】TQVaultAE Extra bank space for Titan Quest Anniversary Edition 项目地址: https://gitcode.com/gh_mirrors/tq/TQVaultAE 4大核心功能彻底释放你的背包空间与创造力 在《泰坦之旅》的…...

颠覆素材管理:3步搞定全网资源下载
颠覆素材管理:3步搞定全网资源下载 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader res-downloader是一款集多平台…...