java面试八股文之------Redis夺命连环25问
java面试八股文之------Redis夺命连环25问
- 👨🎓1.为什么redis这么快
- 👨🎓2.redis的应用场景,为什么要用
- 👨🎓3.redis6.0之前为什么一直不使用多线程,6.0为甚么又使用多线程了
- 👨🎓4.redis有哪些高级功能
- 👨🎓5.怎理解redis中的事务
- 👨🎓6.redis的过期策略与内存淘汰机制
- 👨🎓7.什么是缓存穿透如何避免
- 👨🎓8.什么是缓存雪崩如何避免
- 👨🎓9.使用redis如何实际分布式锁
- 👨🎓10.怎么使用redis实现消息队列
- 👨🎓11.什么是bigkey,会有什么影响
- 👨🎓12.redis如何解决key冲突
- 👨🎓13.怎么提高缓存命中率
- 👨🎓14.redis的持久化方式,以及各自的区别,原理
- 👨🎓15.为什么redis需要把所有数据放到内存中
- 👨🎓16.如何保证缓存与数据库双写一致性
- 👨🎓17.redis集群方案怎么做
- 👨🎓18.redis集群方案什么情况下会导致整个集群不可用
- 👨🎓19.说一说redis的hash槽的概念
- 👨🎓20.redis集群会有写操做丢失吗,为什么
- 👨🎓21.redis常见性能问题和解决方案
- 👨🎓22.热点数据和冷数据是什么
- 👨🎓23.什么情况下可能会导致redis阻塞
- 👨🎓24.什么时候选择redis、什么时候选择memcached
- 👨🎓25.Redis使用过程中碰到的问题
这篇文章用以介绍redis的面试常见问题,若是redis使用经验不多的建议先熟练掌握redis再看这篇面试问题:redis学习练气到化虚。这两篇学习完足以应对95%以上的redis面试场景了,希望对路过的朋友有所帮助。
👨🎓1.为什么redis这么快
-
1.纯内存访问
IO一直是影响效率的主要因素redis是纯内存,读写较快,据说可以达到11w次/s -
2.IO多路复用
单线程程序在处理多客户端请求时定然会碰到请求阻塞问题,也就是说单线程服务端同时只能处理一个客户端请求,其余请求进来只能阻塞等到其他请求处理完毕后才能继续处理。redis如果使用这种模式无疑做不到读写效率高的特点,redis采用IO多路复用来解决了这一问题,IO这里是指客户端与服务端建立的socket,复用指的是共用一个线程。redis通过多个客户端的IO共用一个线程来解决请求阻塞问题,这样就可以实现多请求的非阻塞式响应了,具体流程如下:1.一个 socket 客户端与服务端连接时,会生成对应一个套接字描述符(套接字描述符是文件描述符的一种),每一个 socket 网络连接其实都对应一个文件描述符。 2.多个客户端与服务端连接时,Redis 使用 「I/O 多路复用程序」 将客户端 socket 对应的 FD 注册到监听列表(一个队列)中。当客服端执行 read、write 等操作命令时,I/O 多路复用程序会将命令封装成一个事件,并绑定到对应的 FD 上。 3.「文件事件处理器」使用 I/O 多路复用模块同时监控多个文件描述符(fd)的读写情况,当 accept、read、write 和 close 文件事件产生时,文件事件处理器就会回调 FD 绑定的事件处理器进行处理相关命令操作。 4.整个文件事件处理器是在单线程上运行的,但是通过 I/O 多路复用模块的引入,实现了同时对多个 FD 读写的监控,当其中一个 client 端达到写或读的状态,文件事件处理器就马上执行,从而就不会出现 I/O 堵塞的问题,提高了网络通信的性能。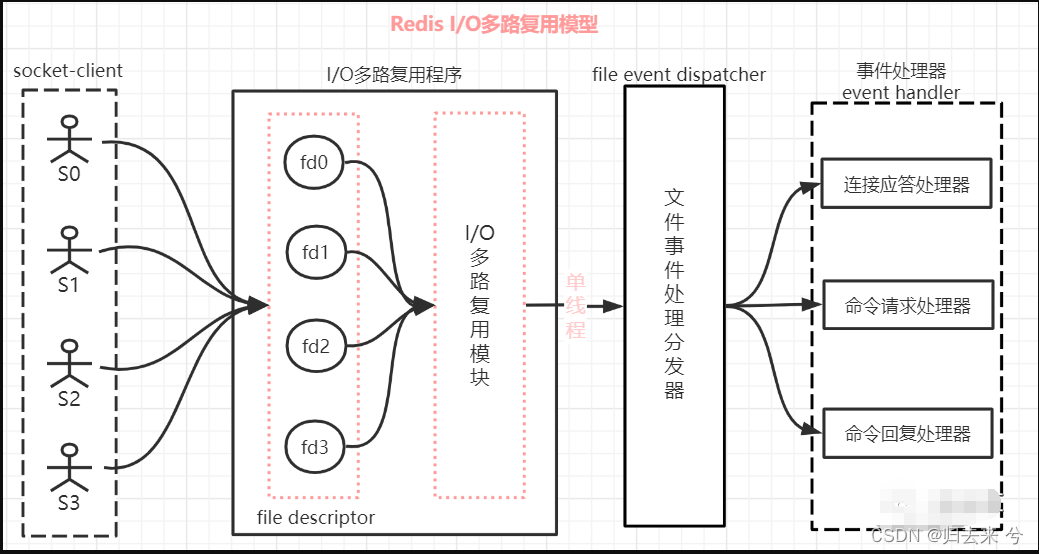
如上图,Redis 的 I/O 多路复用模式使用的是 「Reactor 设置模式」的方式来实现。 -
3.单线程避免上下文切换
线程切换是需要耗费cpu资源的,单线程反而更快,即使6.0以后redis在处理读写操作时依然是单线程 -
4.渐进式rehash
说渐进式rehash之前必须先说说redis中键值对的数据结构,如下图所示:
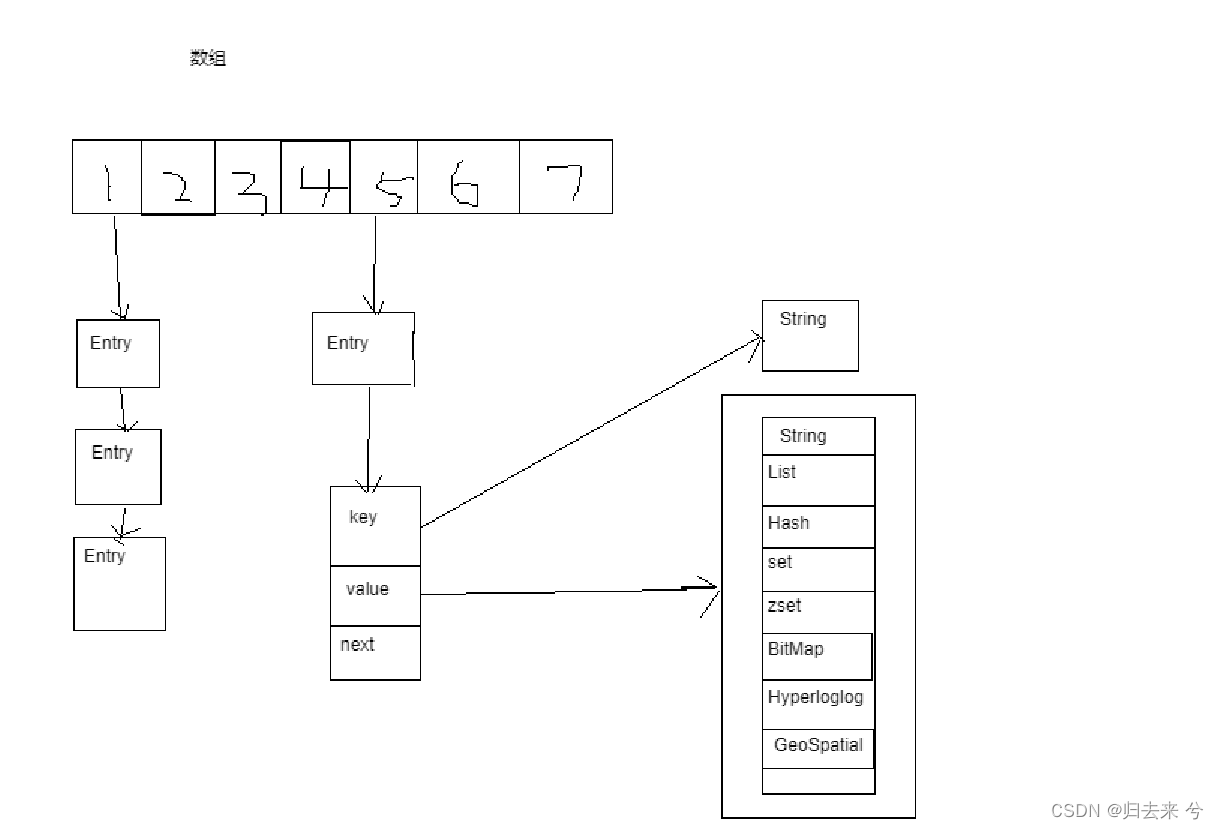
redis存储键值对是通过数组和链表的形式进行存储的,因为redis底层就是大的一个Hash表,所以他会面临java中HashMap一样的扩容问题,Hash数据结构的扩容避免不了的就是Rehash的过程,而当Redis数据量非常大时,若是没有一个好的ReHash策略,将会导致Redis的非常慢,可以想象几十万的键同时在重新计算hash值,这将导致Redis的存取大受限制,因为正常情况下数据异动期间读写都是不能进行的,那Redis是怎么做ReHash的呢。
事实上redis在库里并不是一张大的hash表而是两张大的hash表,目的就是为了扩容来准备的。一张h0,一张h1,h1大小是h0已使用元素数量*2的大小。.当需要扩容时会从h0中逐个寻找元素进行迁移到h1中。且在迁移过程中写操作将不会出现在h0中,这样保证了h0中的数据元素只会越来越少,但是读操作会优先h0进行,h0若是读取不到元素将会去h1中进行寻找数据元素。h0在迁移元素之前会维护一个索引,用以指示是否需要迁移,索引为-1时就不需要迁移,索引为0开始迁移,该索引每次都会支持待迁移元素,这样可以保证元素迁移不会有遗漏。同时这种渐进式的迁移方式也保证了读写可以同时进行,不会影响到数据的存取效率。
需要注意的是redis的rehash不光只有扩容,还有缩容,当h0元素被删除较多后也会进行缩容。 -
5.缓存时间戳
说这个之前要先说下获取系统时间这个操作,获取系统时间一般需要调用系统时间,这个需要切换上下文一般很消耗时间和资源(比如java里的system.currentTimeInMillis)。所以redis没有这么干,他是有一个定时任务会没毫秒更新一下redis的时间缓存,redis在做TTL操作时都是从缓存中去读取数据,而不是调用系统时间,这样无疑节省了很多额外的上下文切换的时间。
👨🎓2.redis的应用场景,为什么要用
为什么要用redis当然是redis性能好,社区活跃,使用起来也简单吗,那redis都有哪些应用场景呢,这个就需要redis支持的所有功能来说这个问题了,根据对redis的了解程度,这个问题可以回答的深入也可以浅显,看对redis的功能掌握多少,我们可以先从redis的8中基本数据类型来说:string、list、hash、set、zset、bitmap、hyperloglog、geospatial来说redis的使用场景,还可以从Redis的分布式锁、事务、消息等来描述redis的用途。这里列举一部分,这个问题没有满分,如需拓展则需要对redis功能上完全掌握。
-
1.缓存
缓存这个比较常用,缓存一些热点数据,缓存一些开关啊等等都是很常见的。常用String类型来作为数据的缓存类型。
2.计数器
redis里面有一个Hyperloglog数据类型,他可以作为数据统计使用。几乎所有的统计计数我们都可以使用hyperloglog来完成,比如我们统计网站的登录人数,当前视频的观看人数等都可以使用hyperloglog,不过必须要说的是hyperloglog的计数不是完全准确的当数据量很大时,可能会出现些许的误差,但误差不会太大,不过一般计数场景对数据的强一致性要求都不是太高,些许误差是允许的,若是要求不允许有误差就可以使用zset了,不过效率上肯定不及hyperloglog(hyperloglog使用5m就可以set可能需要12G),而且hyperloglog占用内存空间相对于set、zset都小的很多,所以她是做基数统计的首选。 -
3.分布式会话
redis提供的有发布订阅的功能,publish/subscribe。利用该功能是可以实现分布式会话机制,该机制与消息队列没有什么区别。与mq类似的是redis也提供了群发、群收的功能,就是利用通配符和群发命令来实现的。 -
4.排行榜
redis中的Zset默认便有排序功能,天然支持排行,做排行榜可以首选该数据类型 -
5.最新列表
这个功能和排行榜类似,就是按时间排序的吗 -
6.分布式锁
redis因为数据操作是单线程,所以可以用来做分布式锁。这里简述下。可以利用redis的命令setnx来实现,该命令行为是如果存在则设置失败,不存在则设置成功。又主要因为redis是单线程(数据操作是单线程),所以同时肯定只有一个能设置成功,但是若是加锁程序宕机,可能会碰到死锁问题,所以我们需要为锁加过期时间,这样可以解决死锁问题,如果加了过期时间又会碰到业务没结束锁已失效或者业务结束很久锁依然没有失效的问题,所以又需要加入看门狗策略,其实就是启动一个守护线程来观察业务的进度来动态调整锁的失效时间。锁失效时间解决了还需要考虑redis集群的问题,因为redis的主从不是强一致性,万一不同步就会造成多个服务同时上锁的情况,这就需要引入redis的RedLock。RedLock要求至少5台实例,且每台都是master。RedLock原理如下:1.客户端先获取当前时间戳T1 2..v客户端依次向5个master实例发起加锁命令,且每个请求都会设置超时时间(毫秒级,注意:不是锁的超时时间),如果某一个master实例由于网络等原因导致加锁失败,则立即想下一个master实例申请加锁。 3..v当客户端加锁成功的请求大于等于3个时,且再次获取当前时间戳T2,当时间戳T2 - 时间戳T1 < 锁的过期时间。则客户端加锁成功,否则失败。 4.加锁成功,开始操作公共资源,进行后续业务操作 5.加锁失败,向所有redis节点发送锁释放命令从这个来看会把分布式锁越做越复杂,而且红锁也是一个比较重的锁。一般不建议使用,我们可以为业务提供一些兜底的方案,来避免锁的过渡重化。
👨🎓3.redis6.0之前为什么一直不使用多线程,6.0为甚么又使用多线程了
redis6.0之前一直是单线程,但是依然很快,就是咱们上面说的原因:基于内存,单线程无需上下文切换,IO多路复用,渐进式rehash,缓存时间戳等特特点共同造就了redis比较快的特点,我们知道影响redis快慢的主要原因是网络和内存,内存我们一般都可以轻易超过标准但是网络却是一直阻塞redis性能的一个关键瓶颈,所以redis为了提高网络这方面的性能在6.0引入了多线程,且redis的多线程只是用来处理网络数据的读写,其实就是处理命令接收命令解析这一阶段是多线程(多线程降低了读写负荷,相当于)。真正命令去执行时还是单线程。所以即使redis支持了多线程,我们依然不会碰到线程安全问,而且redis支持多线程以后可以充分利用cpu资源。
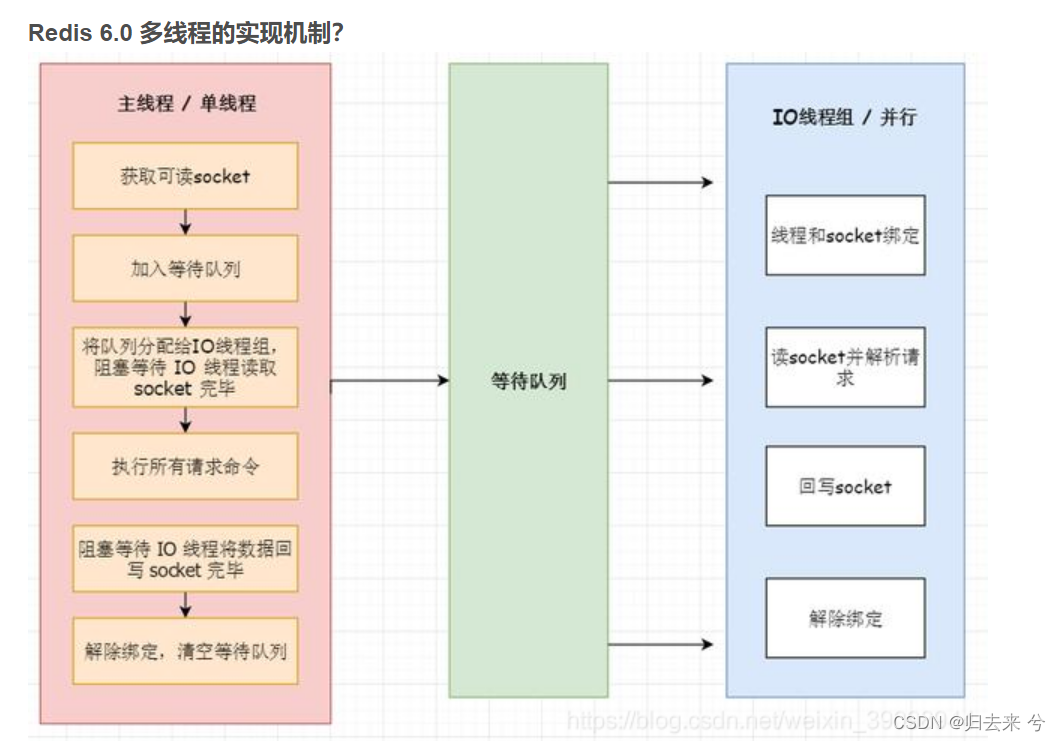
👨🎓4.redis有哪些高级功能
- 1.这个问题可以聊聊redis支持的消息队列功能:
redis支持发布订阅,可以用来实现消息队列,此外我们还可以利用list数据结构来实现消息队列,list支持左进右出(lpush、rpop)这样也是一个队列等。 - 2.还可以从redis支持的事务上聊可以同时聊聊redis的乐观锁:
redis支持事务,但是不支持原子性和隔离性。redis的事务命令是multi(开启)、exec(提交)、discard(丢弃)。也就是说redis的事务只支持持久性和一致性。且redis的事务在发生运行时异常时不支持回滚比如对string进行++操作,这种操作只会导致该命令的失败,事务中的其他命令仍会继续执行。若是编译异常则会导致整个事务的失败。我们为了让redis的事务具有原子性可以通过redis的乐观锁来实现。redis的乐观锁watch(加锁)、unwatch(释放锁)。通过watch用来修饰单个命令,意思是当该键值对被修改后,其他事务里使用这个键的事务将会执行失败,这样可以做到事务中操作的数据没有脏写的问题,也相当于解决了原子性问题。redis解决不了隔离性问题,无论加不加锁隔离性都不支持。 - 3.还可以从redis的特殊数据类型来说一说
比如做基数统计的hyperloglog、buer统计的bitmap、经纬的geospatial等 - 4.这个问题还可以聊聊redis的分布式锁等等
分布式锁上面已经介绍了这里不重复说了
👨🎓5.怎理解redis中的事务
- redis事务
redis支持事务,但是不支持原子性和隔离性。redis的事务命令是multi(开启)、exec(提交)、discard(丢弃)。也就是说redis的事务只支持持久性和一致性。且redis的事务在发生运行时异常时不支持回滚比如对string进行++操作,这种操作只会导致该命令的失败,事务中的其他命令仍会继续执行。若是编译异常则会导致整个事务的失败。我们为了让redis的事务具有原子性可以通过redis的乐观锁来实现。redis的乐观锁watch(加锁)、unwatch(释放锁)。通过watch用来修饰单个命令,意思是当该键值对被修改后,其他事务里使用这个键的事务将会执行失败,这样可以做到事务中操作的数据没有脏写的问题,也相当于解决了原子性问题。redis解决不了隔离性问题,无论加不加锁隔离性都不支持。redis支持事务,但是不支持原子性和隔离性。redis的事务命令是multi(开启)、exec(提交)、discard(丢弃)。也就是说redis的事务只支持持久性和一致性。且redis的事务在发生运行时异常时不支持回滚比如对string进行++操作,这种操作只会导致该命令的失败,事务中的其他命令仍会继续执行。若是编译异常则会导致整个事务的失败。 - 乐观锁watch
我们为了让redis的事务具有原子性可以通过redis的乐观锁来实现。redis的乐观锁watch(加锁)、unwatch(释放锁)。通过watch用来修饰单个命令,意思是当该键值对被修改后,其他事务里使用这个键的事务将会执行失败,这样可以做到事务中操作的数据没有脏写的问题,也相当于解决了原子性问题。redis解决不了隔离性问题,无论加不加锁隔离性都不支持。
👨🎓6.redis的过期策略与内存淘汰机制
redis删除过期键的方式有三种一种是使用自动的过期策略,ttl时间一到会自动删除。另一种是惰性删除,这种删除方式会在客户端访问过期键时才会进行删除。还有一种则是内存达到redis的maxmemory时会触发的内存淘汰
- 1.自动过期
redis的自动过期也不是在过期后进行立即删除的,首先redis对设置了过期时间的key会被存入一个指定的字典中,redis通过定期(默认10次/每秒)操作这个字典来实现过期键的删除,具体操作如下:
这里可以引发一个思考问题,若是短时间内发生了大面积的key失效会产生什么影响?1.从字段中随机取20个key 2.删除这个20个key中已经过期的key 3.如果20个中过期的key超过了1/4则会继续重复1中的操作
若是key大面积失效则会导致一直在进行key删除的操作,这样会影响读写会造成阻塞问题,所以使用Redis时需要考虑键的过期时间设置问题,尽量不要将过期时间设置在同一时间附近。
这里还需要提到的是从库的过期策略,从库完全依赖于主库的过期,主库过期后会同步一条del命令给到从库,从库再去删除,所以可能回碰到主从不一致的问题。这也是使用redis分布式锁时说的主从可能不会完全有效的原因所以才有RedLock. - 2.惰性删除
之所以有惰性删除是因为第一种过期策略不会将所有过期key全部删除,肯定会有遗漏,所以才有了惰性删除,惰性删除会在过期key被访问时进行立即删除。然后才会返回客户端key不存在。总结自动过期是集中处理,惰性删除则是零散处理,各有利弊,集中处理是为了解决大面积key失效问题,零散处理是为了解决客户端访问问题。 - 3.内存淘汰机制
这种机制主要是为了应对redis内存已经达到最大(maxmemory),但是所有的键还都没有过期。此时就需要内存淘汰机制来进行介入了,因为只靠过期策略已经不足以回收到足够内存了。内存淘汰策略有以下几种lru、ttl、random,具体如下:noeviction:不对key进行淘汰,所有key均可以正常被读、删,但是禁止写,这是默认的机制,会影响到线上业务的运行。 volatile-lru:该策略会尝试淘汰设置了过期时间,且最少被使用的key。这里虽然标注了lru,但是并不是真正的lru算法,而是采用了一种近似lru的算法,lru算法是通过维护一个链表,将有数据被使用时就将数据移动到表头,这样一定时间后链表尾部都是最少使用的数据了。redis的lru是为每个设置了ttl的key分配32bit的内存用以存储调用时的时间戳,这样删除时根据时间戳进行,其实和lru很是相似,所以这里命名为了lru算法。 volatile-ttl:这种策略也会尝试淘汰设置了过期时间的key,不过他是依据剩余过期时间最小key来进行淘汰 volatile-random:该策略也是淘汰设置了过期策略的key,不过是随机淘汰 allkeys-lru:这种是针对所有键的lru,会删除没有ttl的key,很危险 allkeys-random:这种也是针对有键的random,也会删除没有ttl的key,很危险
总结以上几种过期策略,volatile类的都是基于ttl进行操作,allkeys的都是基于所有key的操作,很明显我们应该使用基于ttl的这种更安全可靠些。
👨🎓7.什么是缓存穿透如何避免
- 1.缓存击穿
说缓存穿透之前先说下缓存击穿,缓存击穿一般是指缓存key失效,导致的查询越过缓存同一时间大量请求打到了数据库中,给系统和数据造成了很大压力的现象。 - 2.缓存穿透
缓存穿透一般是指恶意攻击时请求的查询参数实际上在缓存与数据中均不存在,恶意构造虚假参数进行对系统攻击,从而造成了大量请求直接穿透了缓存与数据库,从而对系统造成了短时间的压力上升,缓存穿透对于系统并发和数据库的压力会提升。那如何避免缓存穿透问题呢?一般常用的方式是使用布隆过滤器,布隆过滤器是1970年由布隆提出来的。它的作用是可以告诉你你查询的对象一定不存在或者可能存在。因为布隆过滤器是利用hash结构来计算查询数据是否存在的,所以存在不同值hashcode相等的情况。所以布隆过滤器无法确定一定存在,只能告诉你可能存在。显而易见的是布隆过滤器就会存在误判的行为。当然了一般布隆过滤器的实现都是支持误判的参数调整的,通过参数调整可以使得误判的概率控制在一个自己可以接受的范围。
那使用布隆过滤器会不会对性能有很大损失呢?答案是不会的,有因为布隆过滤器使用的是bitmap这种位数据结构来存储数据,占用空间比较小,若是指定的hashcode的位置上为1则代表可能存在,反之一定不存在。从而达到一个过滤的目的。
我们在缓存之前可以加入布隆过滤器,在请求到达布隆过滤器之前可以先让请求先从布隆过滤器中走一遍,这样就可以过滤掉大量的缓存穿透问题。避免了被大量恶意攻击的可能。
👨🎓8.什么是缓存雪崩如何避免
- 服务器瘫痪引起的缓存雪崩
缓存雪崩一般是有两种情况,一种是服务器挂掉了导致缓存信息失效,所有请求均打到了数据库上。另一种则是指缓存key的大面积失效。
无论是哪一种现象造成的雪崩对数据库来说都是灾难性的。那怎么解决这个问题呢,为了解决服务器宕机的风险我们可以对redis采用主从、主从哨兵、主从集群等模式进行扩展,从而降低redis单机宕机的风险。 - key大面积失效引起的缓存雪崩
而对于redis的key大面积失效问题,这就需要我们在设置key失效时间时进行注意了,不能将key的失效时间设置的很接近,可以为他们的失效时间在某个点再加上一个随机的时间。只需要错开一点对于redis来说就会好上很多,因为redis支持的数据读写很高,只需要很微小的错开redis就能避免缓存雪崩的出现。
👨🎓9.使用redis如何实际分布式锁
这个问题上面已经说了这里就不重复说了,只简述下大概:
使用setnx命令,为其设置失效时间,增加看板狗(一般使用lua脚本)动态对失效时间进行调整避免死锁,此外该场景依然不能解决全部问题,还需要引入RedLock。
👨🎓10.怎么使用redis实现消息队列
- 1.发布订阅+list实现消息队列
redis支持发布订阅,也就是消息队列的模型,与rabbit和kafka等消息队列的使用没啥区别。都是publish发布消息,subscribe订阅消息,同时redis还支持群发与群收的功能,以及取消订阅等。redis胜在快速若是需要做个网络即时聊天窗口是可以考虑使用redis的。
此外还需要考虑消息阻塞的问题,此时还需要list,list数据结构支持左进右出的命令,即lpush、rpop,这样就可以看成是一个消息队列了。外来消息可以先存入list中,然后通过消费list中的信息将信息通过publish和subscribe进行传输。这样就可以实现一个消息队列了。
👨🎓11.什么是bigkey,会有什么影响
bigkey是指key对应的value占用的内存比较大,例如一个string类型的value最大可以是512m,一个列表类型的value最多可以存储2的23次方-1的元素。所以bigkey可以分为字符串bigkey和非字符串的bigkey。一般对于字符串类型数据超过10kb就认为是一个bigkey,列表则没有明确说法。不过一般说bigkey最好是要结合系统并发来说的,因为系统并发不够及时1mb的string对象可能也不会有大问题,但是若是并发比较高,可能1kb的对象就会产生危害。下面说下bigkey的危害
- 1.内存空间不均匀:造成内存空间使用不均匀
- 2.超时阻塞:操作bigkey时阻塞redis的风险提高
- 3.网络阻塞:网络流量变大,高并发容易出现请求响应慢等问题
👨🎓12.redis如何解决key冲突
key冲突造成的原因其实就是redis使用不规范,造成了key的冲突。那与之相对的我们应该规范使用redis的key。怎么规范呢,如下:
- 1.业务上隔离:不同业务使用不同库或者集群(在一个库里就需要key的设计上考虑)
- 2.key的设计:业务模块+服务+key名,如:mdm-customer-id
- 3.分布式锁:这种场景是解决多客户端同时操作一个key的问题,此时很可能会出现最终值不是想要的值,我们可以通过加锁或者为信息增加时间戳的操作。加时间戳就是操作之前判断下时间戳是否是需要操作,不需要则不操作。
👨🎓13.怎么提高缓存命中率
- 1.数据提前加载:比如系统启动时进行提前加载数据,可以避免请求进来是大量打到数据库
- 2.增加缓存的存储空间,提高缓存数据,增加缓存命中率
- 3.适当调整缓存的数据类型
- 4.提升缓存的更新频率,可以通过canal、mq等中间件来实现提升缓存的更新频率
👨🎓14.redis的持久化方式,以及各自的区别,原理
- RDB
所有基于内存的数据库都需要持久化策略,不仅仅是redis,只要是基于内存就必须有持久化的策略,因为内存是断电即失的。在redis中支持两种持久化的策略,一种是RDB持久化,一种是AOF持久化,默认的情况下就是使用RDB进行持久化,RDB的配置就是上面 snapshotting 快照配置,这里的所有配置都是用来控制RDB持久化的,AOF持久化的控制都在append only mode中,默认全部关闭,我们一般都是使用RDB进行持久化,而不是使用AOF,先来看看RDB是如何进行持久化的
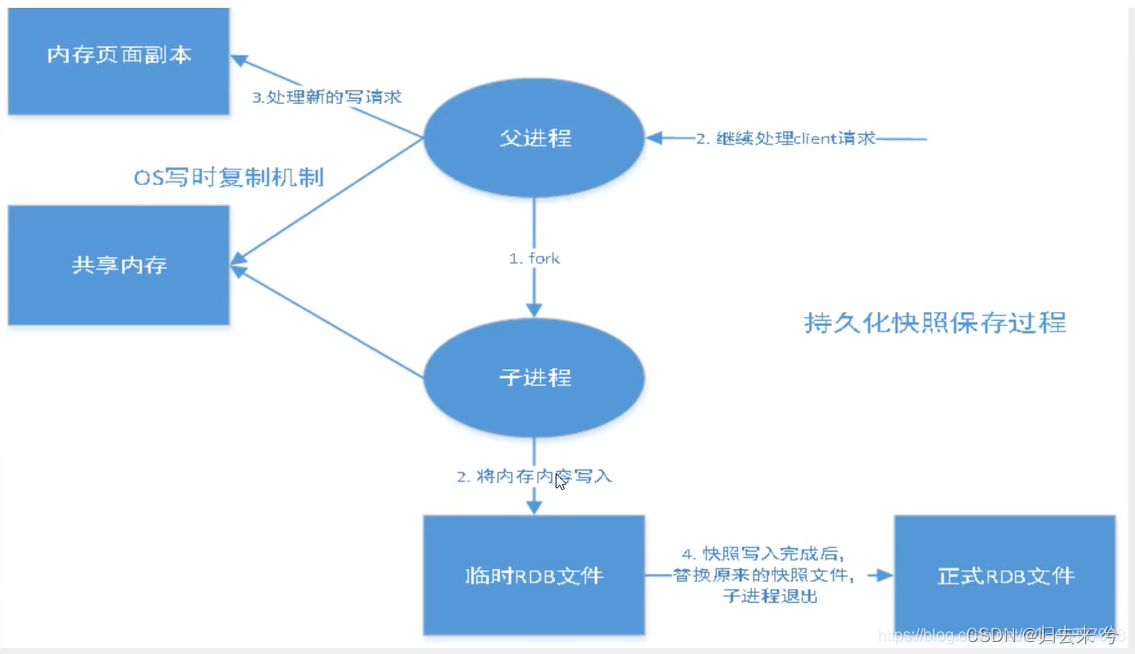
如上图所示就是RDB进行持久化的一个流程:
1)在snapshotting中的save 可以配置 多少时间内发生了多少次操作就会触发持久化,一般我们都是使用默认的那三个,当触发持久化机制时,主线程会fork一个子线程,来讲进行复制数据将数据写入到一个临时RDB文件中。
2)当快照完全写入后,就会去替换掉原来的RDB文件,默认的RDB文件是dump.rdb,这个在snapshotting中也是可以配置的
RDB文件在哪里:
在snapshotting里面有个配置叫dir,上面介绍snapshotting时已经写过,默认是当前文件夹下,与redis-server同位置(为什么不是config的位置?因为redis-server会将配置文件加载过来,相当于是在redis-server所在的文件执行),rdb文件通常需要进行备份,以预防以外丢失rdb文件的情况。
怎么替换RDB文件:
我们要是想要替换RDB文件,直接将其放在当前RDB文件的目录下即可,redis启动时会默认加载(dump.rdb)
哪些场景会触发RDB操作:
1)执行save命令,手动执行一个save命令与配置文件中配置多少秒达到多少次执行save效果一样,此时会触发RDB操作。
2)我们配置的save,多少秒内达到多少次操作也会触发RDB操作。
3)执行fulushAll操作,也会生成RDB文件,清空数据库,redis默认生成一个rdb文件。
4)关闭redis的时候默认生成一个RDB文件,但是若是使用kill命令杀死redis进程则不会生成RDB文件,所以我们应该绝对禁止使用kill来停止redis。
RDB持久化的优缺点:
1)RDB的优点:主线程操作数据不影响子线程的数据持久化,效率比较高,大数据量时数据恢复比较快。
2)RDB的缺点:每次持久化都会有时间间隔,极端情况下可能会丢失最近一次的数据,当然这个时间可以配置,尽量减少风险。
- AOF
AOF是Redis支持的另一种持久化操作,RDB是记录的redis中的值,那AOF是怎么持久化数据的呢?AOF全称是Append Only File,追加文件的意思,AOF通过追加每次对redis执行的写操作来保存用户所有对redis进行的写操做,只要我们在redis中有写操作就会被保存到appendonlyfile.aof文件中,当我们想要恢复数据时,redis就会从新读取aof文件中保存的所有命令,当然了aof默认是关闭,我们若是想要使用AOF的话需要在append only mode模块进行修改,配置,在上面介绍redis的配置文件时已经介绍了这个配置,这里就不在重复赘述了。
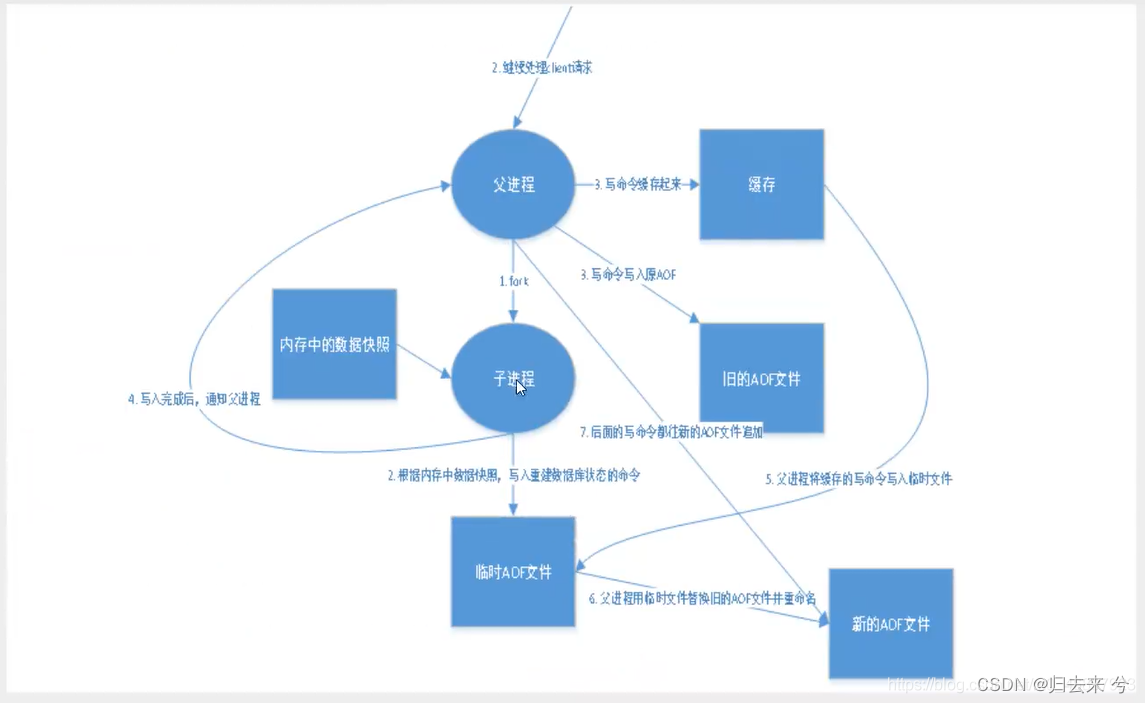
上面的一套流程还是比较复杂的,我们不需要完全记住,只需要记住父进程fork了一个子进程,子进程负责根据存储快照将命令写入到临时aof,写入完通知主线程,主线程会将临时的命令写入redis的缓存,收到子进程完成的消息回去追加aof文件,最后会将新的aof文件替换为新的aof文件。
万一aof文件损坏了怎么办:
当aof文件损坏了的话,我们重启redis是不会成功的,此时我们可以使用redis-check-aof 来修复aof文件,注意这个修复会删除掉aof文件中不可以执行的部分,肯定会有数据丢失,但是相比丢失所有数据已经好了很多。
AOF的优点和缺点:
优点:每次修改都可以同步(不是默认的但是支持),文件的完整性会更好
缺点:aof因为保存的是命令恢复起来会很慢,aof因为都是io操作,也比较慢,所以默认都是使用RDB。
总结redis的两种持久化策略:
可以看到RDB是存储数据的方式保存起来,AOF是存储命令的方式存储起来,在大数据的情况下AOF恢复数据会很慢,但是他对数据的一致性支持更好,RDB在极端情况下回丢失最近一次保存的数据。
👨🎓15.为什么redis需要把所有数据放到内存中
首先必须明确的是内存的IO相较于磁盘来说会非常非常的快,在内存越来越不值钱的现在,使用内存来处理数据也是很好的选择,这也是redis为什么越来越流行的原因了
👨🎓16.如何保证缓存与数据库双写一致性
使用缓存就会面临这种问题,在使用redis做数据缓存时,我们都是先查reids,查不到再查数据库,若是从数据库查到了则更新到redis。若是有数据更新进来我们一般是先删缓存在做数据插入,此时存在一个可能:更新数据时刚删除完缓存数据,其他客户端的查询请求也进来了,此时更新请求开始更新数据库数据,在未提交事务之前数据被另一个客户端的查询请求查到了,查到了一个自然就会将数据更新到redis中,然后更新请求提交事务,数据库数据就变了。此时缓存与数据库的数据就不一致了。这时就出现了双写不一致的情况。而在在高并发的场景下这个问题很场景。那要怎么避免这个问题呢?一般采用的是延时双删策略。
- 1.更新请求进来,删除缓存
- 2.开启事务,操作数据,提交事务
- 3.再次删除缓存(事务提交后再操作)
通过延时双删可以解决这种双写不一致的问题,不过还是可能出现短暂的双写不一致,但是可以保证不会大面积出现问题。
👨🎓17.redis集群方案怎么做
-
1.reids3.0-redis5.0的集群方案
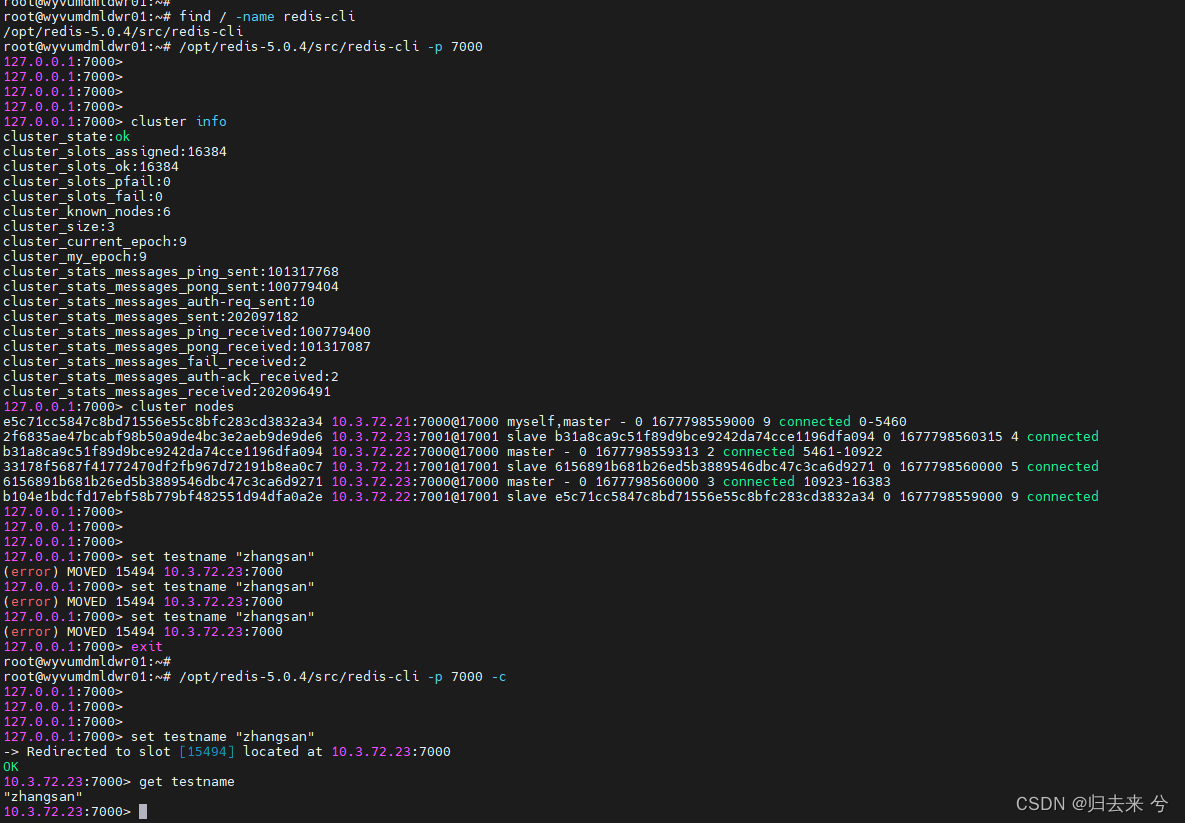
启动集群配置模式开启:cluster-enalbed yes 此外还需要指定当前的配置文件:cluster-config-file node-6379.config 指定集群节点之前的超时时间:cluster-node-timeout 5000 开启aof 集群启动后使用ps查看会看能都是cluster结尾的进程 然后需要ruby环境,redis的集群需要依赖ruby实现(需要安装ruby环境),redis内置了一个redis-trib.rb文件用以实现集群。伪操作如下: redis-trib.rb create --replicas 1 ip1:8001 ip2:8002 ip3:8003 ip4:8004 ip5::8005 ip6:8006 解释下上面的参数redis-trib.rb create --replicas 固定命令用以实现集群,1标识集群中主节点与从结点的比例是1:1,后面所有机器就是用来分配集群的,根据主节点算下数据这里是3,那前三台就是主节点,后三台是从节点。且主节点内第一个对应从节点第一个,他俩构成主从模式。 进入redis使用cluster info 可以查看集群信息 使用cluster nodes 可以。 注意若是使用客户端访问redis集群时,登录单台客户端需要加-c参数,不然不会有集群操作效果。结果展示:
-
2.redis5.0以后的集群方案
redis5.0以后搭建集群省去了ruby环境的构建,redis已经内置支持了集群功能,redis配置功能不变,只需要将最后一步的构建集群命令改成如下即可:redis-cli --cluster create ip1:8001 ip2:8002 ip3:8003 ip4:8004 ip5::8005 ip6:8006 --cluster-replicas 1 -
3.redis集群的弊端:
1.key的批量操作受限,mset,mget等批量操作,集群模式下只支持相同slot值的key执行此操作 2.事务支持受限,若是事务的key分散在多个结点上,则不支持事务 3.不支持多数据空间,redis单机下支持的16个库,集群中只支持db0 4.复制结构支持一层,也就是不支持从节点还有自己的从节点但是redis集群的扩容和缩容会比较麻烦,因为需要从新指定hash槽的分配等。
👨🎓18.redis集群方案什么情况下会导致整个集群不可用
- 1.集群中的节点挂掉以后,没有从节点接替,那会导致整个集群不可用,所以我们必须保证每个主节点都有从节点,根本原因是因为槽找不到存储位置,需要说的是即使有从节点,在故障转移期间redis集群也是不可用的状态。cluster-require-full-coverage:no可以解决该问题。
- 2.即使上面配置了no,当半数主节点都不可用时,集群还是会不可用。
👨🎓19.说一说redis的hash槽的概念
说redis集群就必须聊的是redis的hash槽的概念,在集群模式下redis将集群中所有主节点的存储空间分为0到16383个槽,每个节点都会负责一定量的槽,如果是三个节点,一个节点的槽数量大概就是5460.redis底层采用高质量的hash算法(虚拟一致性hash算法)来确定数据的存储应该分散在具体哪个槽从而确定集群模式下当前数据应该存储在哪个分区里也就是哪个节点下。
为什么槽要设置为136834?主要原因是为了控制节点数量不能太大,这个槽梳理支持1000节点以下的集群,而节点达到1000以上时节点之前的ping、pong将会很慢,所以槽的数量也大概支持到了这个位置。
👨🎓20.redis集群会有写操做丢失吗,为什么
可能,因为redis无论是集群还是主从,他们的主从之间数据的同步都是异步的,在极端情况下主节点写入完成就会返回客户端,若是此时主节点内宕机了,那从节点将无法获取到写入的数据,此时就会有写丢失的情况。
👨🎓21.redis常见性能问题和解决方案
- 1.持久化性能问题:持久化无论是rdb还是aof都是会消耗性能的,一般可以采用主不做持久化,使用从来做持久化即可。
- 2.主从应该在同一个局域网下搭建,避免跨网络,这样主从同步时网络开销就会增大
- 3.在主库压力很大时就不要增加从库了,只会增大主库的压力
- 4.主从复制的机构不用采用网状或者树状,尽量使用线性结构,可以减刑redis主库压力
👨🎓22.热点数据和冷数据是什么
访问频次较高的数据称为热数据,相反则是冷数据。热数据我们就需要考虑将热点数据放到redis缓存中了,可以提高系统性能。
👨🎓23.什么情况下可能会导致redis阻塞
- 1.客户端阻塞,比如执行keys、hgettall、smembers等这些命令时间负责度都是O(n).可能会阻塞
- 2.BIGkey的删除,比如zset等,耗时较久,可能会造成阻塞
- 3.清空库操作,如flushdb 、flushall等操作
- 4.AOF日志写操作,子线程写AOF或RDB都有可能在数据量比较大时造成问题
- 5.从库加载RDB文件,rdb文件加载也会耗时很久
- 6.redis所在服务器性能问你题
👨🎓24.什么时候选择redis、什么时候选择memcached
- 1.Redis功能更加强大,支持数据类型更多,memcached支持数据类型较少只有key-value
- 2.Redis拥有持久化,数据安全性更高,memcached不支持持久化
- 3.Redis内存管理更健全,支持key的过期、内存淘汰等机制,更适合数据存储,memcashed做缓存会比redis更好
- 4.Redis支持IO多路复用,单线程,memcached支持非阻塞式的IO多路复用,多线程
- 5.Redis支持事务、主从、消息、集群等,memcached拓展性不好
👨🎓25.Redis使用过程中碰到的问题
这个问题就仁者见仁了,其实就说说自己工作中碰到的问题,可以根据实际情况说,如果并发量不大的系统,可能并不会碰到集群的问题,单点的等可以说说故障转移,故障恢复,连接中断,key使用问题等等,这个随意发挥了。希望25问可以帮助到路过的朋友
相关文章:
java面试八股文之------Redis夺命连环25问
java面试八股文之------Redis夺命连环25问👨🎓1.为什么redis这么快👨🎓2.redis的应用场景,为什么要用👨🎓3.redis6.0之前为什么一直不使用多线程,6.0为甚么又使用多线程了&…...
【数据结构】AVL平衡二叉树底层原理以及二叉树的演进之多叉树
1.AVL平衡二叉树底层原理 背景 二叉查找树左右子树极度不平衡,退化成为链表时候,相当于全表扫描,时间复杂度就变为了O(n) 插入速度没影响,但是查询速度变慢,比单链表都慢,每次都要判断左右子树是否为空 需…...

K8S篇-安装nfs插件
前言 有关k8s的搭建可以参考:http://t.csdn.cn/H84Zu 有关过程中使用到的nfs相关的nas,可以参考: http://t.csdn.cn/ACfoT http://t.csdn.cn/tPotK http://t.csdn.cn/JIn27 安装nfs存储插件 NFS-Subdir-External-Provisioner是一个自动配置…...
xmu 离散数学 卢杨班作业详解【4-7章】
文章目录第四章 二元关系和函数4.6.2911121618.120.222.1232834第五章 代数系统的一般概念2判断二元运算是否封闭348111214第六章 几个典型的代数系统1.5.6.7.11.12151618第七章 图的基本概念12479111215第四章 二元关系和函数 4. A{1,2,3} 恒等关系 IA{<1,1>,<2,2…...

多重背包问题中的二进制状态压缩
1.多重背包问题 经典的多重背包问题和01背包问题的相似之处在于二者的一维遍历顺序都是从右侧往左侧遍历。 同时多重背包的一维写法不比二维写法降低时间复杂度。 2.多重背包标准写法:(平铺展开形式) class Solution {public int maxValue(int N, int C, int[] s…...

汇编语言程序设计(四)之汇编指令
系列文章 汇编语言程序设计(一) 汇编语言程序设计(二)之寄存器 汇编语言程序设计(三)之汇编程序 汇编指令 1. 数据传输指令 指令包括:MOV、XCHG、XLAT、LEA、LDS、LES、PUSH、POP、PUSHF、LA…...

Vant2 源码分析之 vant-sticky
前言 原打算借鉴 vant-sticky 源码,实现业务需求的某个功能,第一眼看以为看懂了,拿来用的时候,才发现一知半解。看第二遍时,对不起,是我肤浅了。这里侧重分析实现原理,其他部分不拓展开来&…...
【自然语言处理】【大模型】大语言模型BLOOM推理工具测试
相关博客 【自然语言处理】【大模型】大语言模型BLOOM推理工具测试 【自然语言处理】【大模型】GLM-130B:一个开源双语预训练语言模型 【自然语言处理】【大模型】用于大型Transformer的8-bit矩阵乘法介绍 【自然语言处理】【大模型】BLOOM:一个176B参数…...
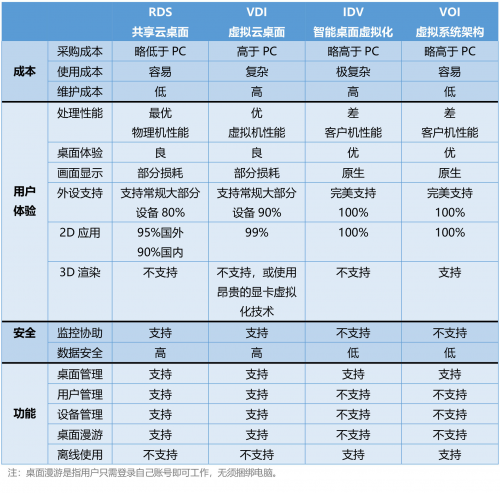
云桌面技术初识:VDI,IDV,VOI,RDS
VDI(Virtual Desktop Infrastucture,虚拟桌面架构),俗称虚拟云桌面 VDI构架采用的“集中存储、集中运算”构架,所有的桌面以虚拟机的方式运行在服务器硬件虚拟化层上,桌面以图像传输的方式发送到客户端。 …...

基于本地centos构建gdal2.4.4镜像
1.前言 基于基础镜像构建gdal环境一般特别大,一般少则1.6G,多则2G甚至更大,这对于镜像的迁移造成了极大的不便。究其原因在于容器中有大量的源码文件以及编译中间过程文件,还要大量编译需要的yum库。本文主要通过在centos系统上先…...

生产环境线程问题排查
线程状态的解读RUNNABLE线程处于运行状态,不一定消耗CPU。例如,线程从网络读取数据,大多数时间是挂起的,只有数据到达时才会重新唤起进入执行状态。只有Java代码显式调用sleep或wait方法时,虚拟机才可以精准获取到线程…...

Day908.joinsnljdist和group问题和备库自增主键问题 -MySQL实战
join&snlj&dist和group问题和备库自增主键问题 Hi,我是阿昌,今天学习记录的是关于join&snlj&dist和group问题和备库自增主键问题的内容。 一、join 的写法 join 语句怎么优化?中,在介绍 join 执行顺序的时候&am…...

算法 - 剑指Offer 丑数
题目 我们把只包含质因子 2、3 和 5 的数称作丑数(Ugly Number)。求按从小到大的顺序的第 n 个丑数。 解题思路 这题我使用最简单方法去做, 首先我们可以获取所有2n,3n,5*n的丑数,只是我们这里暂时无法排序,并且可能…...
【ONE·C || 文件操作】
总言 C语言:文件操作。 文章目录总言1、文件是什么?为什么需要文件?1.1、为什么需要文件?1.2、文件是什么?2、文件的打开与关闭2.1、文件指针2.2、文件打开和关闭:fopen、fclose2.3、文件使用方式3、文…...
cmd窗口中java命令报错。错误:找不到或无法加载主类 java的jdk安装过程中踩过的坑
错误: 找不到或无法加载主类 HelloWorld 遇到这个问题时,我尝试过网上其他人的做法。有试过添加classpath,也有试过删除classpath。但是依然报错,这里javac可以编译通过,说明代码应该是没有问题的。只是在运行是出现了错误。我安装…...
)
Breathwork(呼吸练习)
查了下呼吸练习相关内容,做个记录。我又在油管学习啦。 喜欢在you. tube看一些self-help相关的内容。比如学习方法、拉伸、跑步、力量举、自重锻炼等等。 总是听Obi Vicent说起Breathwork,比如: My 6am Morning Routine | New Healthy Habit…...
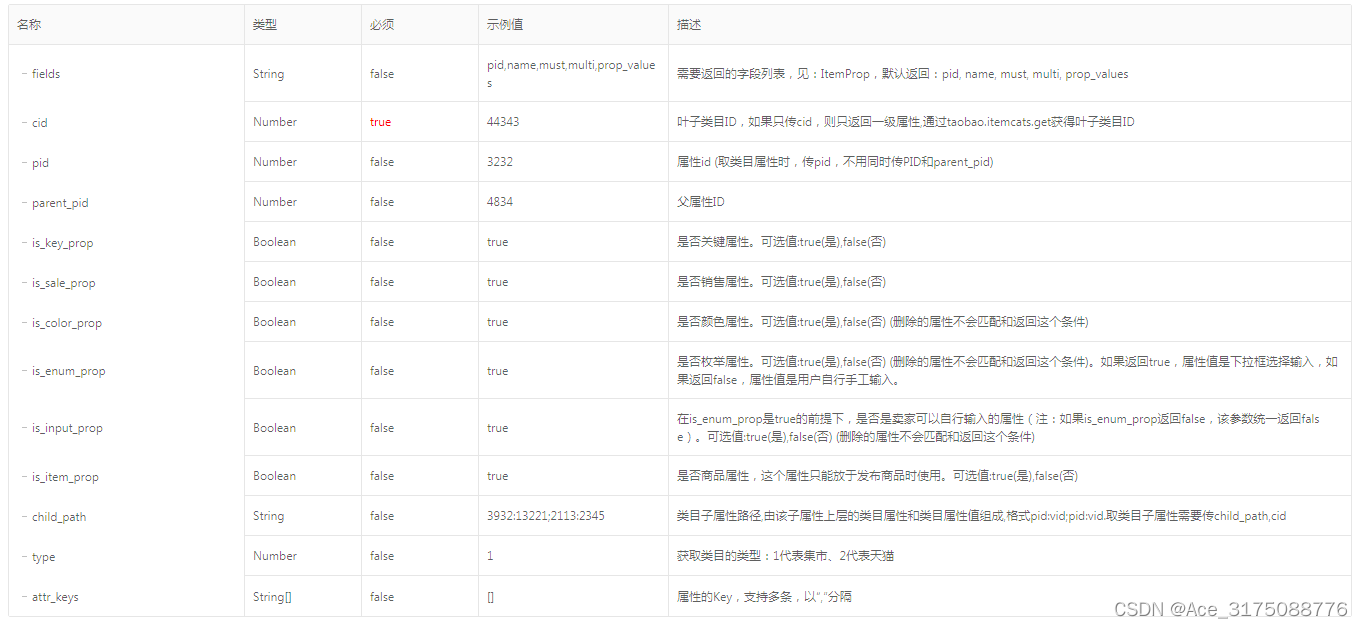
taobao.itemprops.get( 获取标准商品类目属性 )
¥开放平台基础API不需用户授权 通过设置必要的参数,来获取商品后台标准类目属性,以及这些属性里面详细的属性值prop_values。 公共参数 请求地址: HTTP地址 http://gw.api.taobao.com/router/rest 公共请求参数: 公共响应参数: 请求参数 点…...
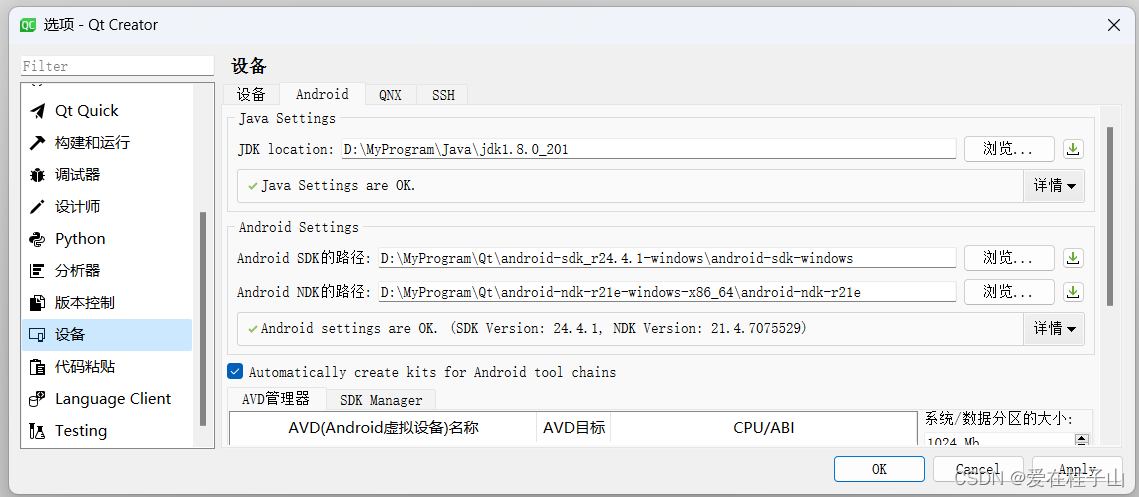
QT配置安卓环境(保姆级教程)
目录 下载环境资源 JDK1.8 NDK SDK 安装QT 配置环境 下载环境资源 JDK1.8 介绍JDK是Java开发的核心工具,为Java开发者提供了一套完整的开发环境,包括开发工具、类库和API等,使得开发者可以高效地编写、测试和运行Java应用程序。 下载…...
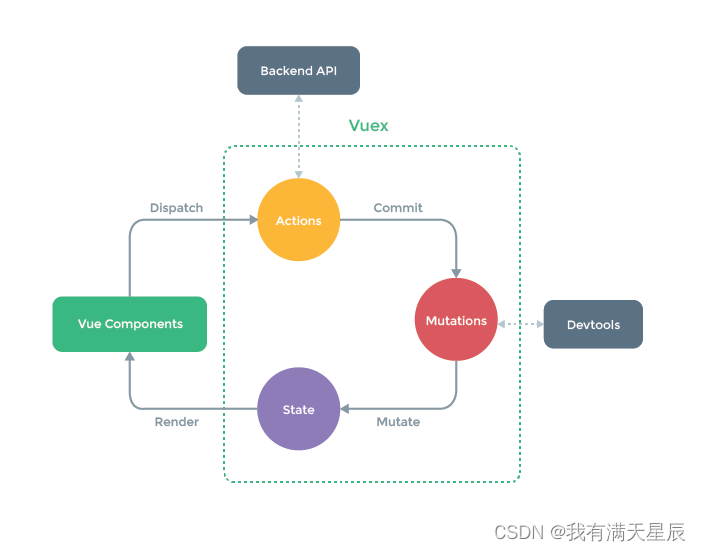
【uni-app教程】八、UniAPP Vuex 状态管理
八、UniAPP Vuex 状态管理 概念 Vuex 是一个专为 Vue.js 应用程序开发的状态管理模式。它采用集中式存储管理应用的所有组件的状态,并以相应的规则保证状态以一种可预测的方式发生变化。 应用场景 Vue多个组件之间需要共享数据或状态。 关键规则 State:…...
)
同花顺测试面经(30min)
大概三十分钟,面试官人还挺好的 1.自我介绍 2.详细问你了自我介绍中的一个实习经历 3.对我们公司有什么了解 !!(高频) 4.对测试有什么看法,为什么选测试 5.黑盒白盒分别是什么 6.对测试左移有什么看法…...

Windows热键冲突终结者:Hotkey Detective让键盘操作回归掌控
Windows热键冲突终结者:Hotkey Detective让键盘操作回归掌控 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 当…...
)
基于MATLAB的悬臂梁前3阶固有频率和振型求解(假设模态法、解析法、瑞利里兹法)
基于matlab的求解悬臂梁前3阶固有频率和振型 基于matlab的求解悬臂梁前3阶固有频率和振型,采用的方法分别是(假设模态法,解析法,瑞利里兹法) 程序已调通,可直接运行悬臂梁的振动分析总带着点工程师的浪漫——既要数学的…...

Qwen3.5-9B企业应用:法务合同关键条款提取+风险点标注案例
Qwen3.5-9B企业应用:法务合同关键条款提取风险点标注案例 1. 项目背景与价值 在法务工作中,合同审查是一项耗时且容易出错的任务。传统的人工审查方式需要律师逐条阅读合同文本,识别关键条款并标注潜在风险点,这个过程通常需要数…...

Flink的反压机制
目录 1. 什么是反压? 2. Flink 反压机制的演变 第一代:基于 TCP 的传播(Flink 1.5 之前) 第二代:基于信用制的反压(Flink 1.5+,当前版本) 3. 基于信用制的反压详解 核心组件 工作流程(对应上图) 优势 4. 如何识别和处理反压? 识别(通过 Flink Web UI) …...

STM32智能灌溉系统设计与实现
1. 项目概述这个智能灌溉控制系统是我去年为一个农业科技公司做的实际项目,当时他们需要在200亩的蓝莓种植基地部署一套自动化灌溉方案。经过三个月的开发和实地测试,最终形成了这套基于STM32的稳定系统。现在把整个设计过程整理出来,希望能给…...

WordPress用Linux服务器还是Windows服务器更好?
对于绝大多数 WordPress 用户来说,Linux 服务器是更好的选择。 WordPress 本身是用 PHP 编写的,最初就是为 Linux 环境(特别是 LAMP/LEMP 架构)设计的。虽然它也可以在 Windows 上运行,但在性能、成本、生态支持和安全…...
)
泛微Ecology数据库小白必看:三张表搞定待办、已办、办结查询(附完整SQL及字段解释)
泛微Ecology流程查询实战指南:从表结构到SQL优化的完整解析 引言 在日常办公自动化管理中,泛微Ecology系统作为国内主流的工作流平台,承载着企业大量业务流程的运转。但对于刚接触系统管理的技术人员来说,面对复杂的数据库表结构和…...

开源字体完全指南:免费商用与跨平台优化实践
开源字体完全指南:免费商用与跨平台优化实践 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 在当今数字化设计领域,选择合适的字体不仅关乎视觉呈现,…...

Sammy.js部署与运维:生产环境配置、性能监控与故障排查终极指南
Sammy.js部署与运维:生产环境配置、性能监控与故障排查终极指南 【免费下载链接】sammy Sammy is a tiny javascript framework built on top of jQuery, Its RESTful Evented Javascript. 项目地址: https://gitcode.com/gh_mirrors/sa/sammy Sammy.js是一个…...

MelonLoader终极指南:7个步骤掌握Unity游戏模组加载器的完整教程
MelonLoader终极指南:7个步骤掌握Unity游戏模组加载器的完整教程 【免费下载链接】MelonLoader The Worlds First Universal Mod Loader for Unity Games compatible with both Il2Cpp and Mono 项目地址: https://gitcode.com/gh_mirrors/me/MelonLoader Me…...