图片速览 BitNet: 1-bit LLM
输入数据
-
模型使用absmax 量化方法进行b比特量化,将输入量化到 [ − Q b , Q b ] ( Q b = 2 b − 1 ) \left[-Q_{b},Q_{b}\right](Q_{b}=2^{b-1}) [−Qb,Qb](Qb=2b−1)
x ~ = Q u a n t ( x ) = C l i p ( x × Q b γ , − Q b + ϵ , Q b − ϵ ) , Clip ( x , a , b ) = max ( a , min ( b , x ) ) , γ = ∣ ∣ x ∣ ∣ ∞ , \widetilde{x}=\mathrm{Quant}(x)=\mathrm{Clip}(x\times\frac{Q_b}{\gamma},-Q_b+\epsilon,Q_b-\epsilon),\\ \operatorname{Clip}(x,a,b)=\max(a,\min(b,x)),\quad\gamma=||x||_\infty, x =Quant(x)=Clip(x×γQb,−Qb+ϵ,Qb−ϵ),Clip(x,a,b)=max(a,min(b,x)),γ=∣∣x∣∣∞, -
其中 ε 是一个小的浮点数,可防止在执行截断时溢出。
// https://github.com/kyegomez/BitNet/blob/main/bitnet/bitbnet_b158.py
def absmean_quantize_weights(weights):"""Quantizes the weights to -1, 0, or +1 using an absmean quantization function.Parameters:- weights (Tensor): The weights of a neural network layer.Returns:- Tensor: The quantized weights."""# Calculate the average absolute value (γ) of the weightsgamma = torch.mean(torch.abs(weights))# Scale weights by γ and round to the nearest integer among {-1, 0, +1}quantized_weights = torch.clamp(torch.round(weights / gamma), min=-1, max=1)return quantized_weights
权重
- 权重 W 的二值化可以公式化为:
α = 1 n m ∑ i j W i j W ~ = S i g n ( W − α ) , Sign ( W i j ) = { + 1 , if W i j > 0 , − 1 , if W i j ≤ 0 , \\ \alpha=\frac1{nm}\sum_{ij}W_{ij} \\ \widetilde{W}=\mathrm{Sign}(W-\alpha),\\ \left.\operatorname{Sign}(W_{ij})=\left\{\begin{array}{ll}+1,&\quad\text{if}W_{ij}>0,\\-1,&\quad\text{if}W_{ij}\leq0,\end{array}\right.\right. α=nm1ij∑WijW =Sign(W−α),Sign(Wij)={+1,−1,ifWij>0,ifWij≤0,
矩阵乘法
- 使用上述量化方程,矩阵乘法可以写成:
y = W ~ x ~ y=\widetilde W\widetilde{x} y=W x
- 为了保持量化后的方差,我们在激活量化之前引入了一个 LayerNorm函数。这样,输出 y 的方差就估计为 1
y = W ~ x ~ = W ~ Quant ( LN ( x ) ) × β γ Q b y=\widetilde{W}\widetilde{x}=\widetilde{W}\text{Quant}(\text{LN}(x))\times\frac{\beta\gamma}{Q_b} y=W x =W Quant(LN(x))×Qbβγ
L N ( x ) = x − E ( x ) V a r ( x ) + ϵ , β = 1 n m ∥ W ∥ 1 \mathrm{LN}(x)=\frac{x-E(x)}{\sqrt{\mathrm{Var}(x)+\epsilon}},\quad\beta=\frac1{nm}\|W\|_1 LN(x)=Var(x)+ϵx−E(x),β=nm1∥W∥1

// https://github.com/kyegomez/BitNet/blob/main/bitnet/bitlinear.py
import torch
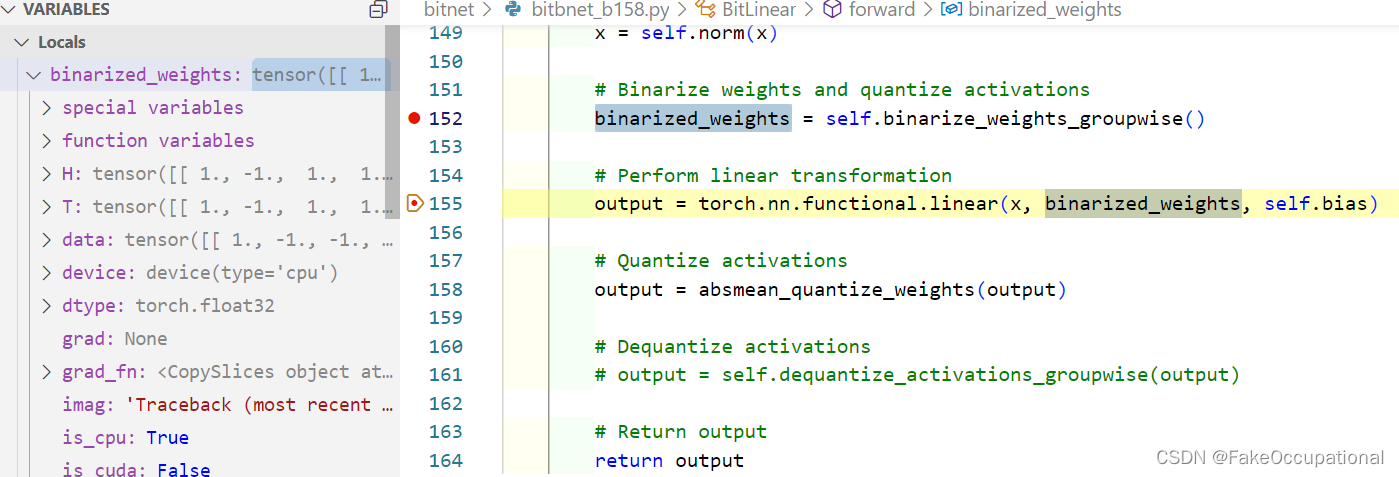
from torch import Tensor, nnclass BitLinear(nn.Linear):"""BitLinear is a custom linear layer that performs binarization of weights and quantization of activationsin a group-wise manner.Args:in_features (int): Number of input features.out_features (int): Number of output features.bias (bool, optional): If set to False, the layer will not learn an additive bias. Default is True.num_groups (int, optional): Number of groups to divide the weights and activations into. Default is 1."""def __init__(self,in_features: int,out_features: int,bias: bool = True,num_groups: int = 1,b: int = 8,):super().__init__(in_features, out_features, bias)self.in_features = in_featuresself.out_features = out_featuresself.b = bself.num_groups = num_groupsself.eps = 1e-5self.norm = nn.LayerNorm(in_features)def ste(self, x):"""Applies the sign function for binarization and uses Straight-Through Estimator (STE) during backward pass.Args:x (Tensor): Input tensor.Returns:Tensor: Binarized tensor."""binarized_x = torch.sign(x)binarized_x = (binarized_x - x).detach() + xreturn binarized_xdef binarize_weights_groupwise(self):"""Binarizes the weights of the layer in a group-wise manner using STE.Returns:Tensor: Binarized weights tensor."""group_size = self.weight.shape[0] // self.num_groupsbinarized_weights = torch.zeros_like(self.weight)for g in range(self.num_groups):start_idx = g * group_sizeend_idx = (g + 1) * group_sizeweight_group = self.weight[start_idx:end_idx]alpha_g = weight_group.mean()binarized_weights[start_idx:end_idx] = self.ste(weight_group - alpha_g)return binarized_weightsdef quantize_activations_groupwise(self, x):"""Quantizes the activations of the layer in a group-wise manner.Args:x (Tensor): Input tensor.b (int, optional): Number of bits for quantization. Default is 8.Returns:Tensor: Quantized activations tensor."""Q_b = 2 ** (self.b - 1)group_size = x.shape[0] // self.num_groupsquantized_x = torch.zeros_like(x)for g in range(self.num_groups):start_idx = g * group_sizeend_idx = (g + 1) * group_sizeactivation_group = x[start_idx:end_idx]gamma_g = activation_group.abs().max()quantized_x[start_idx:end_idx] = torch.clamp(activation_group * Q_b / (gamma_g + self.eps),-Q_b + self.eps,Q_b - self.eps,)return quantized_xdef dequantize_activations_groupwise(self, x):"""Dequantizes the activations of the layer in a group-wise manner.Args:x (Tensor): Quantized input tensor.b (int, optional): Number of bits used during the quantization. Default is 8.Returns:Tensor: Dequantized activations tensor."""Q_b = 2 ** (self.b - 1)dequantized_x = torch.zeros_like(x)for g in range(self.num_groups):start_idx = g * x.shape[0] // self.num_groupsend_idx = (g + 1) * x.shape[0] // self.num_groupsquantized_group = x[start_idx:end_idx]gamma_g = quantized_group.abs().max()dequantized_x[start_idx:end_idx] = quantized_group * gamma_g / Q_breturn dequantized_xdef forward(self, x: Tensor) -> Tensor:"""Forward pass of the BitLinear layer.Args:x (Tensor): Input tensor.Returns:Tensor: Output tensor."""# Normalize inputx = self.norm(x)# Binarize weights and quantize activationsbinarized_weights = self.binarize_weights_groupwise()# Perform linear transformationoutput = torch.nn.functional.linear(x, binarized_weights, self.bias)# Quantize activationsoutput = self.quantize_activations_groupwise(output)# Dequantize activationsoutput = self.dequantize_activations_groupwise(output)# Return outputreturn output# Example usage
bitlinear = BitLinear(10, 5, num_groups=2, b=8)
input_tensor = torch.randn(5, 10) # Example input tensor
output = bitlinear(input_tensor)
print(output) # Example output tensor
CG
-
【自然语言处理】【大模型】BitNet:用1-bit Transformer训练LLM
-
BitNet: Scaling 1-bit Transformers for Large Language Models
-
The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
-
Implementation of “BitNet: Scaling 1-bit Transformers for Large Language Models” in pytorch
-
DB-LLM: Accurate Dual-Binarization for Efficient LLMs
-
如何看待微软提出的BitNet b1.58?
相关文章:
图片速览 BitNet: 1-bit LLM
输入数据 模型使用absmax 量化方法进行b比特量化,将输入量化到 [ − Q b , Q b ] ( Q b 2 b − 1 ) \left[-Q_{b},Q_{b}\right](Q_{b}2^{b-1}) [−Qb,Qb](Qb2b−1) x ~ Q u a n t ( x ) C l i p ( x Q b γ , − Q b ϵ , Q b − ϵ ) , Clip ( x , a , b ) ma…...

金融基础——拨备前利润和拨备后利润介绍
一、简介 拨备前利润(PreProvision Operating Profit,也就是PPOP)和拨备后利润的主要区别在于是否扣除减值准备金、是否遵循保守性原则以及显示的利润数值不同。 拨备前利润。指在计算利润时没有扣除减值准备金的利润,它等于税前…...
网络编程作业day7
作业项目:基于UDP的聊天室 服务器代码: #include <myhead.h>//定义客户信息结构体 typedef struct magtye {char type; //消息类型char name[100]; //客户姓名char text[1024]; //客户发送聊天信息 }msg_t;//定义结构体存储…...

【Vision Pro杀手级应用】3D音乐会/演唱会,非VR视频播放的形式,而是实实在在的明星“全息”形象,在你的面前表演
核心内容形式:体积视频 参考对标案例深度解读: 体积视频,这一全新的内容形式,正在引领我们进入一个前所未有的四维体验时代。它将传统的演艺形式推向了新的高度,让我们能够更加深入地沉浸在虚拟世界中,感受前所未有的视听盛宴。 在这一领域,有一个引人注目的案例,那…...

变频器学习
西门子变频器 SINAMICS V20 入门级变频器 SINAMICS G120C...
Linux Ubuntu系统安装MySQL并实现公网连接本地数据库【内网穿透】
文章目录 前言1 .安装Docker2. 使用Docker拉取MySQL镜像3. 创建并启动MySQL容器4. 本地连接测试4.1 安装MySQL图形化界面工具4.2 使用MySQL Workbench连接测试 5. 公网远程访问本地MySQL5.1 内网穿透工具安装5.2 创建远程连接公网地址5.3 使用固定TCP地址远程访问 前言 本文主…...

0048__Unix传奇
Unix传奇 (上篇)_unix传奇(上篇)-CSDN博客 Unix传奇 (下篇)-CSDN博客 Unix现状与未来——CSDN对我的采访_nuix邮件系统行业地位-CSDN博客...

蓝桥杯-排序
数组排序 Arrays.sort(int[] a) 这种形式是对一个数组的所有元素进行排序,并且时按从小到大的顺序。 package Work;import java.util.*;public class Imcomplete {public static void main(String args[]) {int arr[]new int [] {1,324,4,5,7,2};Arrays.sort(arr)…...
计算机设计大赛 深度学习的视频多目标跟踪实现
文章目录 1 前言2 先上成果3 多目标跟踪的两种方法3.1 方法13.2 方法2 4 Tracking By Detecting的跟踪过程4.1 存在的问题4.2 基于轨迹预测的跟踪方式 5 训练代码6 最后 1 前言 🔥 优质竞赛项目系列,今天要分享的是 基于深度学习的视频多目标跟踪实现 …...

高性能JSON框架之FastJson的简单使用
高性能JSON框架之FastJson的简单使用、 1.前言 1.1.FastJson的介绍: JSON协议使用方便,越来越流行,JSON的处理器有很多,这里我介绍一下FastJson,FastJson是阿里的开源框架,被不少企业使用,是一个极其优秀的Json框架,Github地址: FastJson 1.2.FastJson的特点: 1.F…...
)
★判断素数的几种方法(由易到难,由慢到快)
素数的定义: 素数,又称为质数,指的是“大于1的整数中,只能被1和这个数本身整除的数”。换句话说,素数是只有两个正约数(1和本身)的自然数。素数在数论中有着重要的地位,且素数的个数…...

vue svelte solid 虚拟滚动性能对比
前言 由于svelte solid 两大无虚拟DOM框架,由于其性能好,在前端越来越有影响力。 因此本次想要验证,这三个框架关于实现表格虚拟滚动的性能。 比较版本 vue3.4.21svelte4.2.12solid-js1.8.15 比较代码 这里使用了我的 stk-table-vue(np…...
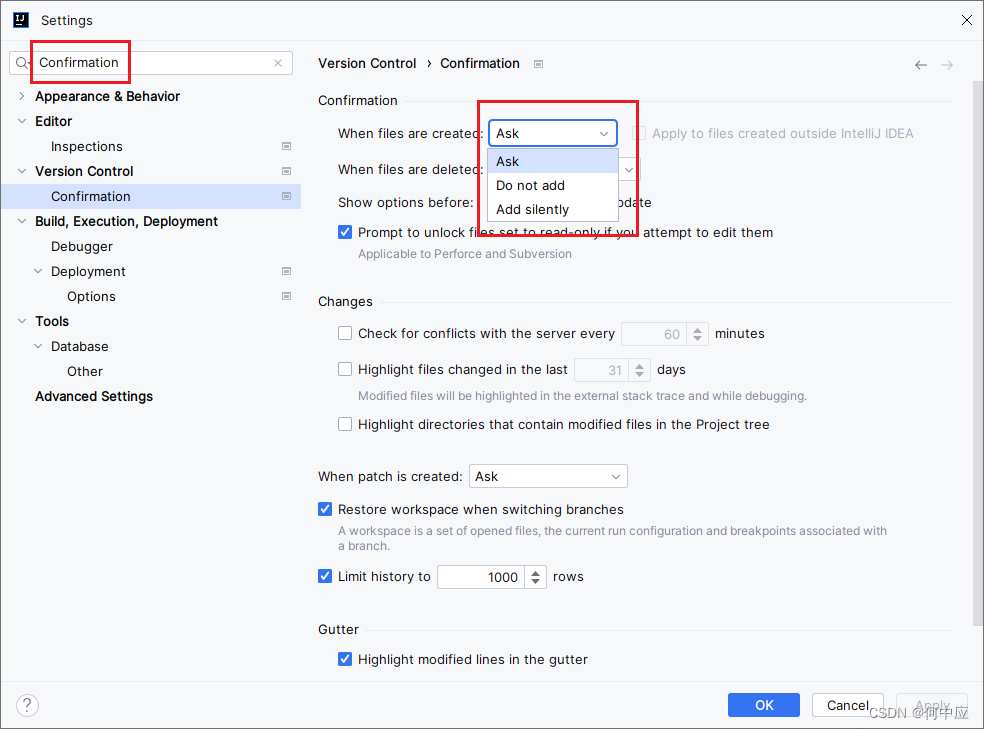
IDEA中新增文件,弹出框提示是否添加到Git点错了,怎么重新设置?
打开一个配置了Git的项目,新增一个文件,会弹出下面这个框。提示是否将新增的文件交给Git管理。 一般来说,会选择ADD,并勾选Dont ask agin,添加并不再询问。如果不小心点错了,可在IDEA中重新设置(…...

LV15 day5 字符设备驱动读写操作实现
一、读操作实现 ssize_t xxx_read(struct file *filp, char __user *pbuf, size_t count, loff_t *ppos); 完成功能:读取设备产生的数据 参数: filp:指向open产生的struct file类型的对象,表示本次read对应的那次open pbuf&#…...

Uninty 鼠标点击(摄像机发出射线-检测位置)
平面来触发碰撞,胶囊用红色材质方便观察。 脚本挂载到胶囊上方便操作。 目前实现的功能,鼠标左键点击,胶囊就移动到那个位置上。 using System.Collections; using System.Collections.Generic; using UnityEngine;public class c6 : MonoBe…...

描述下Vue自定义指令
描述下Vue自定义指令 (1)自定义指令基本内容(2)使用场景(3)使用案例 在 Vue2.0 中,代码复用和抽象的主要形式是组件。然而,有的情况下,你仍然需要对普通 DOM 元素进行底层…...

2024.3.7
作业: 1、OSI的七层网络模型有哪些,每一层有什么作用? (1)应用层 负责处理不同应用程序之间的通信,需要满足提供的协议,确保数据发送方和接收方的正确 (2)表示层…...

this.$watch 侦听器 和 停止侦听器
使用组件实例的$watch()方法来命令式地创建一个侦听器; 它还允许你提前停止该侦听器 语法:this.$watch(data, method, object) 1. data:侦听的数据源,类型为String 2. method:回调函数&#x…...

P1030 [NOIP2001 普及组] 求先序排列题解
题目 给出一棵二叉树的中序与后序排列。求出它的先序排列。(约定树结点用不同的大写字母表示,且二叉树的节点个数≤8)。 输入输出格式 输入格式 共两行,均为大写字母组成的字符串,表示一棵二叉树的中序与后序排列。…...

【分布式】NCCL Split Tree kernel内实现情况 - 06
相关系列 【分布式】NCCL部署与测试 - 01 【分布式】入门级NCCL多机并行实践 - 02 【分布式】小白看Ring算法 - 03 【分布式】大模型分布式训练入门与实践 - 04 目录 相关系列概述1.1 Tree1.2 double binary tree初始化和拓扑2.1 Tree的初始化与差异2.2 ncclGetBtreeKernel内部…...

利用Taotoken的Token Plan套餐为团队项目节省大模型调用成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken的Token Plan套餐为团队项目节省大模型调用成本 对于中小型技术团队而言,在项目开发中引入大模型能力已成…...
)
深入浅出:STM32 USB BOS描述符与WCID配置详解(以WinUSB免驱为例)
STM32 USB BOS描述符与WCID配置实战解析:从协议到代码实现 在嵌入式开发领域,USB设备与主机系统的无缝对接一直是开发者关注的重点。传统USB设备在Windows平台上通常需要安装专用驱动程序,这不仅增加了用户使用门槛,也提高了开发维…...

移动篇:WMS里的“乾坤大挪移”——移库、补货、冻结全解析
WMS里的“乾坤大挪移”——移库、补货、冻结全解析 摘要:货物入库后,不是“一放了之”。库位要优化、库存要周转、临期品要管理……这就涉及WMS中的“库存移动”操作。移库、补货、冻结分别解决什么问题?什么场景下会用到?本文带你…...

基于HPM5E00与LAN9252的EtherCAT从站开发板全流程实战
1. 项目概述:从零到一,打造专属的 EtherCAT 从站开发板 最近在工业自动化圈子里,EtherCAT 的热度一直居高不下。它那近乎实时的通讯性能、灵活的拓扑结构,让它在运动控制、机器人、高端数控机床等领域成了“香饽饽”。但很多开发者…...

从零搭建高效AI协作工作流,NotebookLM团队空间配置、知识对齐与冲突消解全链路实操手册
更多请点击: https://intelliparadigm.com 第一章:NotebookLM团队协作功能概览 NotebookLM 是 Google 推出的基于 LLM 的研究型笔记工具,其团队协作能力围绕“共享上下文、实时协同、权限精细化”三大核心设计。当多个成员加入同一 Notebook…...

AMD Ryzen SMU Debug Tool完全指南:揭秘硬件级调试的三大实战场景
AMD Ryzen SMU Debug Tool完全指南:揭秘硬件级调试的三大实战场景 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址:…...

开源阅读鸿蒙版:打造你的专属数字图书馆,重获阅读自由
开源阅读鸿蒙版:打造你的专属数字图书馆,重获阅读自由 【免费下载链接】legado-Harmony 开源阅读鸿蒙版仓库 项目地址: https://gitcode.com/gh_mirrors/le/legado-Harmony 你是否厌倦了在多个阅读应用间来回切换?是否对层出不穷的广告…...

使用 TaoToken CLI 工具为团队统一配置开发环境中的模型端点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用 TaoToken CLI 工具为团队统一配置开发环境中的模型端点 基础教程类,面向团队技术负责人,介绍如何通过…...
调制那些老技术的新应用)
无线门铃、车库遥控与物联网:聊聊OOK(2ASK)调制那些老技术的新应用
无线门铃、车库遥控与物联网:聊聊OOK(2ASK)调制那些老技术的新应用 在智能家居和物联网设备大行其道的今天,一种诞生于上世纪中期的通信技术——OOK(On-Off Keying)调制,依然活跃在无线门铃、车…...

从碎片到体系:如何用Obsidian Weread插件打造你的个人读书知识库
从碎片到体系:如何用Obsidian Weread插件打造你的个人读书知识库 【免费下载链接】obsidian-weread-plugin Obsidian Weread Plugin is a plugin to sync Weread(微信读书) hightlights and annotations into your Obsidian Vault. 项目地址: https://gitcode.com…...