pytorch(十)循环神经网络
文章目录
- 卷积神经网络与循环神经网络的区别
- RNN cell结构
- 构造RNN
- 例子 seq2seq
卷积神经网络与循环神经网络的区别
卷积神经网络:在卷积神经网络中,全连接层的参数占比是最多的。
卷积神经网络主要用语处理图像、语音等空间数据,它的特点是局部连接和权值共享,减少了参数的数量。CNN通常包括卷积层、池化层和全连接层,卷积层用于提取输入数据的特诊,池化层用语降维和压缩特征,全连接层将特征映射到更加高维度的空间中。
卷积神经网络在处理空间数据的时候,其输入通常是一个二维或者三维的张量,每一个元素对应一个输出。CNN通过卷积操作获取特征,这些特征往往是局部相关的,即每个特征都与输入数据的一个局部区域相关联(相邻的特征往往具有相似性)。
循环神经网络
循环神经网络主要用于处理序列数据,比如自然语言处理、语音识别和时间序列预测(具有时间依赖的数据),它的特点是具有时间轴,能够保留和处理序列中的历史信息。RNN包括循环层,能够接收前一层的信息并且与当前的输入结合,生成当前的输出序列。
循环神经网络处理的数据往往是序列数据,即输入的数据是一个序列,每一个时间步都有一个对应的输出,RNN通过循环层保留和传递历史信息,从而建立时间上的依赖关系。
循环神经网络也使用到了权值共享的想法,RNN在不同的时间位置共享参数(CNN在不同的空间位置共享参数)
RNN cell结构
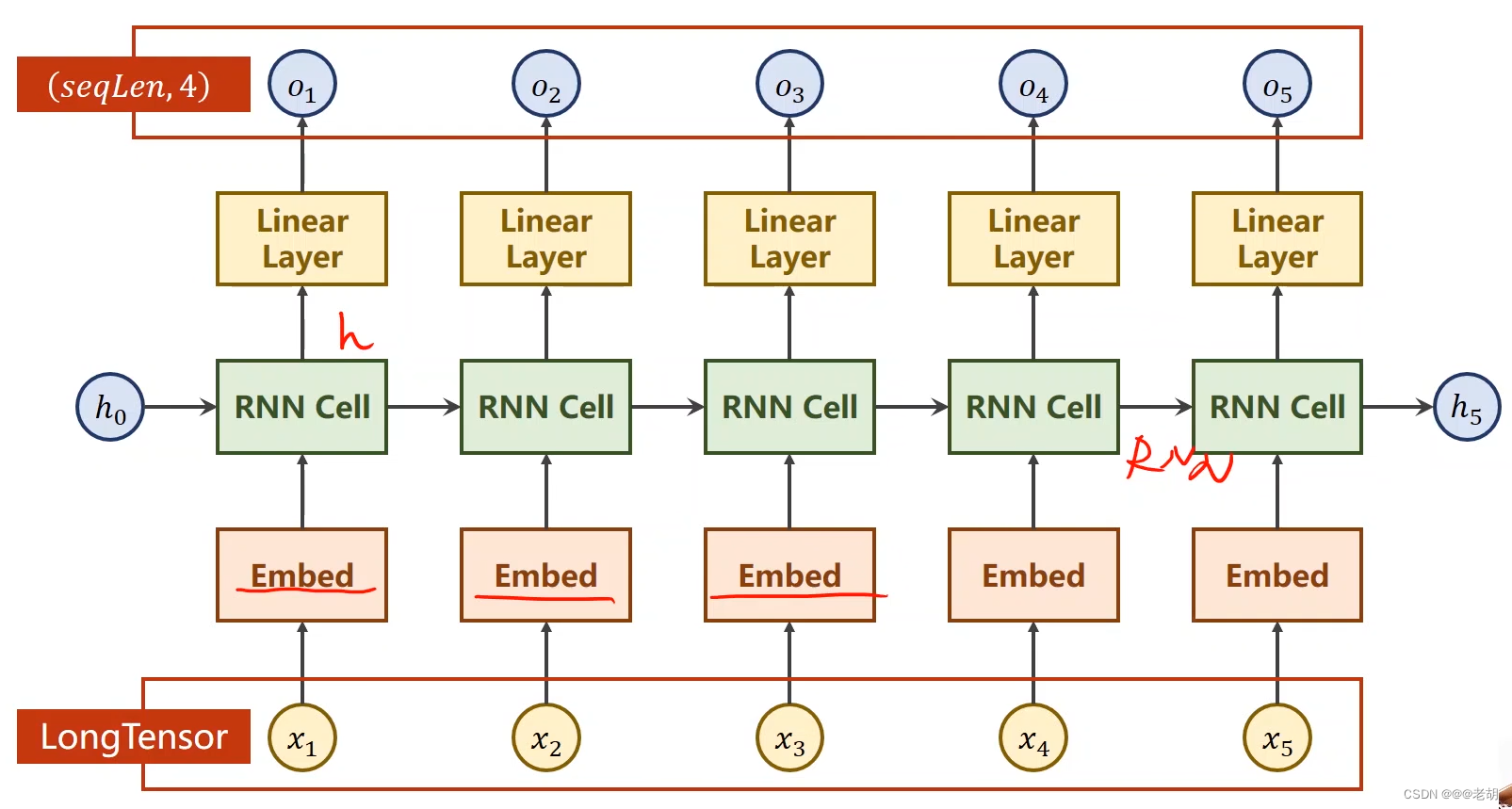
RNN cell的结构在本质上类似于传统的神经网络模型(输入层、隐藏层、输出层),但是RNN于传统的NN最大的区别在于:隐藏层的输入不仅包括输入层的输出,还包括上一时刻隐藏层的输出,其结构如下:
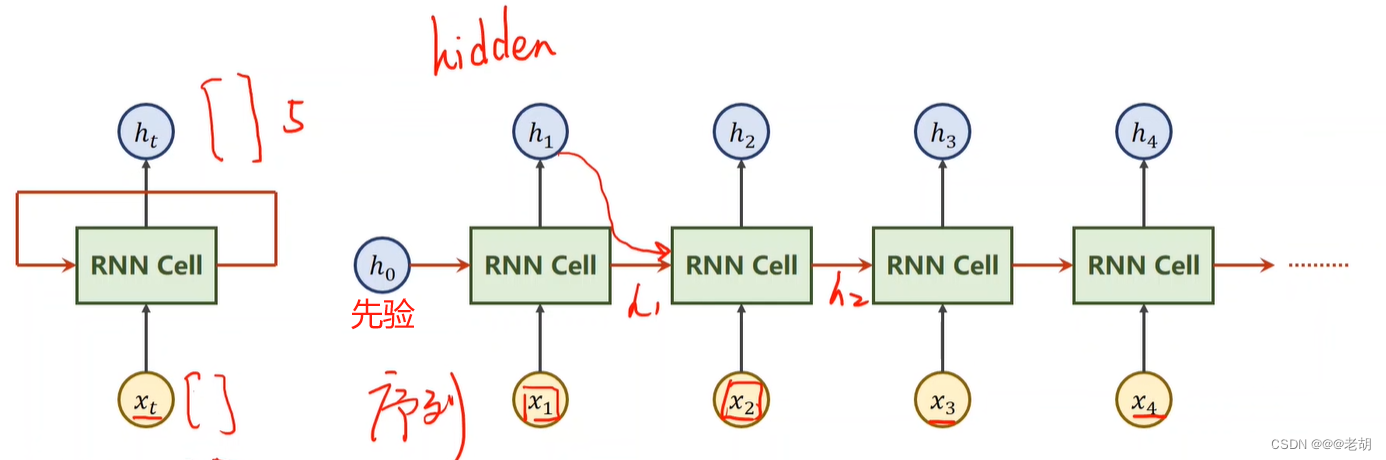

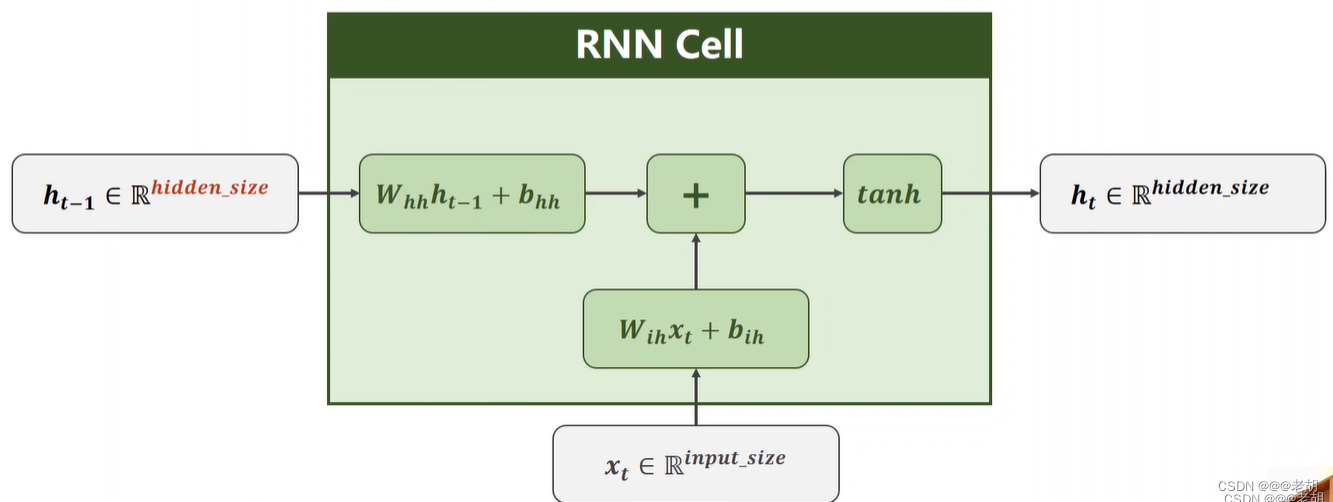
之所以叫做循环神经网络,是因为以上的cell都是同一个cell,参数也只有cell里的一份而已,在训练中,cell层使用的是循环结构,使用不同的输入数据进行训练。
构造RNN
第一种方法 RNNCell
cell=torch.nn.RNNCell(input_size=input_size,hidden_size=hidden_size)
hidden=cell(input,hidden)
# input of shape(batch,input_size)
# hidden of shape(batch,hidden_size)
# output of shape(batch,hidden_size)
# dataset.shape(seqLen,batchSize,inputSize)
import torchbatch_size=1 # N=1
seq_len=3 # x=[x1,x2,x3]
input_size=4 # [4*3]
hidden_size=2 # [2*3]
# 两种构造方式——1
cell=torch.nn.RNNCell(input_size=input_size,hidden_size=hidden_size)#(seq,batch=n,features) 序列的长度 * 批量 * 维度
dataset=torch.randn(seq_len,batch_size,input_size)
# 批量 * 维度
hidden=torch.zeros(batch_size,hidden_size)print('dataset:',dataset)
print('hidden:',hidden)# 构造循环
for idx,input in enumerate(dataset):print('=' *20,idx,'='*20)print(input)print('Input size:',input.shape)hidden=cell(input,hidden)print(hidden)print('Outputs size:',hidden.shape)print(hidden)
第二种方法
cell=torch.nn.RNN(input_size=input_size,hidden_size=hidden_size,num_layers=num_layers)
out,hidden=cell(input,hidden)
# input:表示整个输入序列;input of shape(seqSize,batch,input_size),这里的seqSize实际上就是上面的循环过程
# hidden:表示h0;hidden of shape(numLayers,batch,hidden_size)
# output of shape(seqLen,batch,hidden_size)
import torchbatch_size=1 # N=1
seq_len=3 # x=[x1,x2,x3]
input_size=4 # [4*3]
hidden_size=2 # [2*3]
num_layers=1
# 两种构造方式——2 num_layers表示层数
cell=torch.nn.RNN(input_size=input_size,hidden_size=hidden_size,num_layers=num_layers)
# cell=torch.nn.RNN(input_size=input_size,hidden_size=hidden_size,num_layers=num_layers)
# inputs=torch.randn(batch_size,seq_len,input_size)inputs=torch.randn(seq_len,batch_size,input_size)
hidden=torch.zeros(num_layers,batch_size,hidden_size)out,hidden=cell(inputs,hidden)
print('Output size:',out.shape)
print('Output:',out)
print('Hidden size:',hidden.shape)
print('Hidden:',hidden)
例子 seq2seq
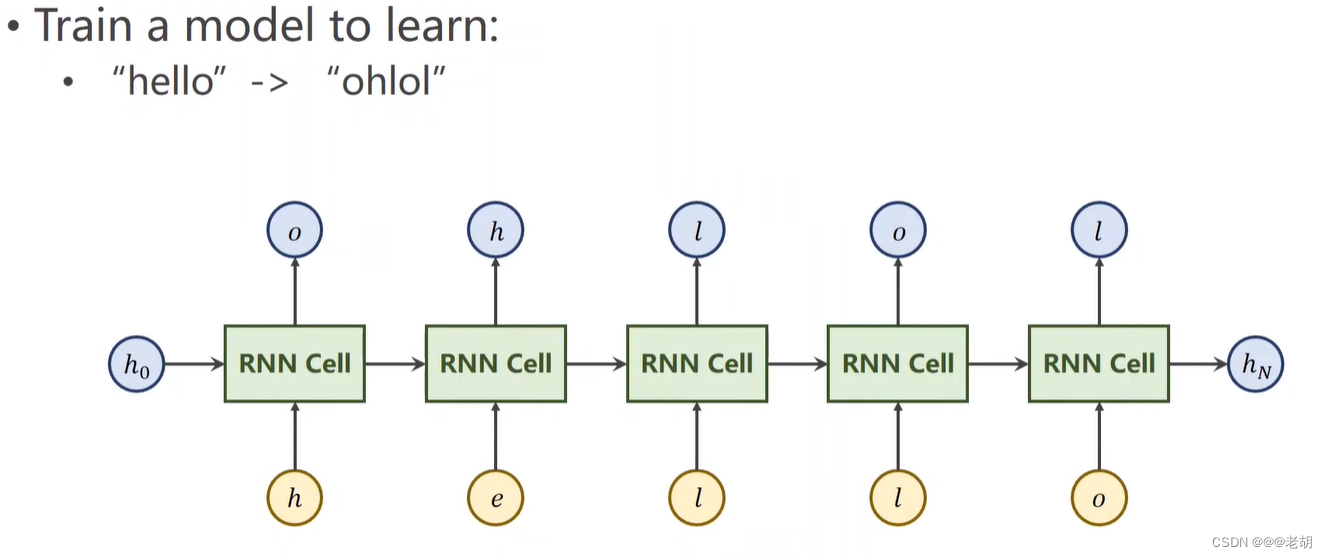
需要把 hello 序列经过训练变成 ohlol 序列,x=[x1,x2,x3,x4,x5]
这里是需要训练一个模型,使得输入“hello”,而输出为“ohlol”,实际上对于输入的数据,判别输出的数据属于哪一个类别,这里只有4种字母,所以输出的维度为4。
将序列数据转变成向量,一般转换为独热向量

import torchbatch_size=1
input_size=4
hidden_size=4idx2char=['e','h','l','o']
# 字典转变
x_data=[1,0,2,2,3]
y_data=[3,1,2,3,2]one_hot_looup=[[1,0,0,0],[0,1,0,0],[0,0,1,0],[0,0,0,1]]x_one_hot=[one_hot_looup[x] for x in x_data]# 两个数据中的-1表示序列的长度seqSize
inputs=torch.Tensor(x_one_hot).view(-1,batch_size,input_size)
print('inputs:',inputs)
labels=torch.LongTensor(y_data).view(-1,1)class Model(torch.nn.Module):def __init__(self,input_size,hidden_size,batch_size):super(Model,self).__init__()self.batch_size=batch_sizeself.input_size=input_sizeself.hidden_size=hidden_sizeself.rnncell=torch.nn.RNNCell(input_size=self.input_size,hidden_size=self.hidden_size)def forward(self,input,hidden):hidden=self.rnncell(input,hidden)return hidden# h0def init_hidden(self):return torch.zeros(self.batch_size,self.hidden_size)net=Model(input_size,hidden_size,batch_size)
criterion=torch.nn.CrossEntropyLoss()
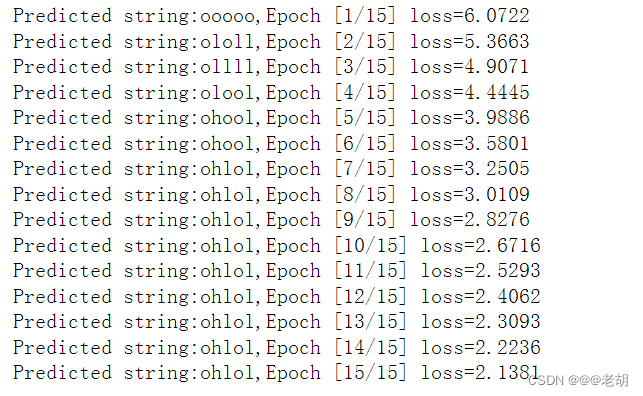
optimizer=torch.optim.Adam(net.parameters(),lr=0.1)for epoch in range(15):loss=0optimizer.zero_grad()hidden=net.init_hidden()print('Predicted string:',end='')# 这个实际上就是RNNfor input,label in zip(inputs,labels):# print('input:',input,'label:',label)hidden=net(input,hidden)loss+=criterion(hidden,label)# 输出可能性最大的那个值,也就是预测的值_,idx=hidden.max(dim=1)print(idx2char[idx.item()],end='')loss.backward()optimizer.step()print(',Epoch [%d/15] loss=%.4f'%(epoch+1,loss.item()))
独热向量的缺点
- 独热向量的维度过高,比如26个字母有26维度。给每一个汉字都映射一个独热向量会有维度的诅咒;
- 独热向量过于稀疏;
- 独热向量是硬编码,不是学习出来的,每一个向量对应都是确定的。
解决方案:Embedding,也就是把高维度的稀疏的数据映射成低维的稠密的数据中,也就是数据降维。
降维后的网络
相关文章:
pytorch(十)循环神经网络
文章目录 卷积神经网络与循环神经网络的区别RNN cell结构构造RNN例子 seq2seq 卷积神经网络与循环神经网络的区别 卷积神经网络:在卷积神经网络中,全连接层的参数占比是最多的。 卷积神经网络主要用语处理图像、语音等空间数据,它的特点是局部…...

【黑马程序员】Python文件、异常、模块、包
文章目录 文件操作文件编码什么是编码为什么要使用编码 文件的读取openmodel常用的三种基础访问模式读操作相关方法 文件的写入注意代码示例 异常定义异常捕获捕获指定异常捕获多个异常捕获所有异常异常else异常finally 异常的传递 python 模块定义模块的导入import模块名from …...
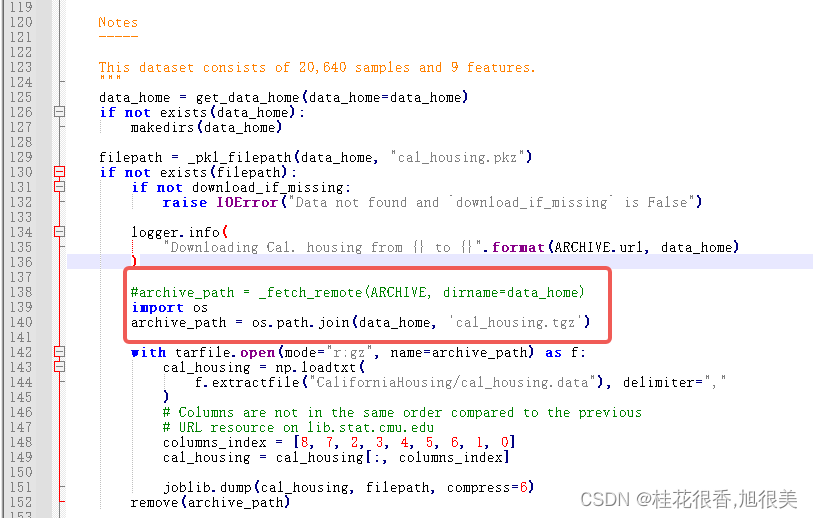
导入fetch_california_housing 加州房价数据集报错解决(HTTPError: HTTP Error 403: Forbidden)
报错 HTTPError Traceback (most recent call last) Cell In[3], line 52 from sklearn.datasets import fetch_california_housing3 from sklearn.model_selection import train_test_split ----> 5 X, Y fetch_california_housing(retu…...
后勤管理系统|基于SSM 框架+vue+ Mysql+Java+B/S架构技术的后勤管理系统设计与实现(可运行源码+数据库+设计文档+部署说明+视频演示)
目录 文末获取源码 前台首页功能 员工注册、员工登录 个人中心 公寓信息 员工功能模块 员工积分管理 管理员登录 编辑管理员功能模块 个人信息 编辑员工管理 公寓户型管理 编辑公寓信息管理 系统结构设计 数据库设计 luwen参考 概述 源码获取 文末获取源…...
【办公类-40-01】20240311 用Python将MP4转MP3提取音频 (家长会系列一)
作品展示: 背景需求: 马上就要家长会,我负责做会议前的照片滚动PPT,除了大量照片视频,还需要一个时间很长的背景音乐MP3 一、下载“歌曲串烧” 装一个IDM 下载三个“串烧音乐MP4”。 代码展示 家长会背景音乐: 歌曲串…...

人类的谋算与量子计算
量子计算并不等价于并行计算。量子计算和并行计算是两种不同的计算模型。 在经典计算中,通过增加计算机的处理器核心和内存等资源,可以实现并行计算,即多个任务同时进行。并行计算可以显著提高计算速度,尤其是对于可以被细分为多个…...
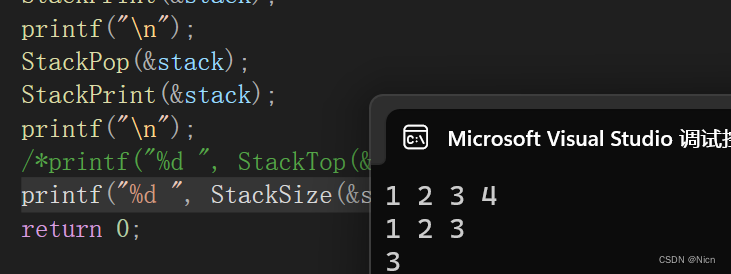
【数据结构和算法初阶(C语言)】栈的概念和实现(后进先出---后来者居上的神奇线性结构带来的惊喜体验)
目录 1.栈 1.1栈的概念及结构 2.栈的实现 3.栈结构对数据的处理方式 3.1对栈进行初始化 3.2 从栈顶添加元素 3.3 打印栈元素 3.4移除栈顶元素 3.5获取栈顶元素 3.6获取栈中的有效个数 3.7 判断链表是否为空 3.9 销毁栈空间 4.结语及整个源码 1.栈 1.1栈的概念及结构 栈&am…...
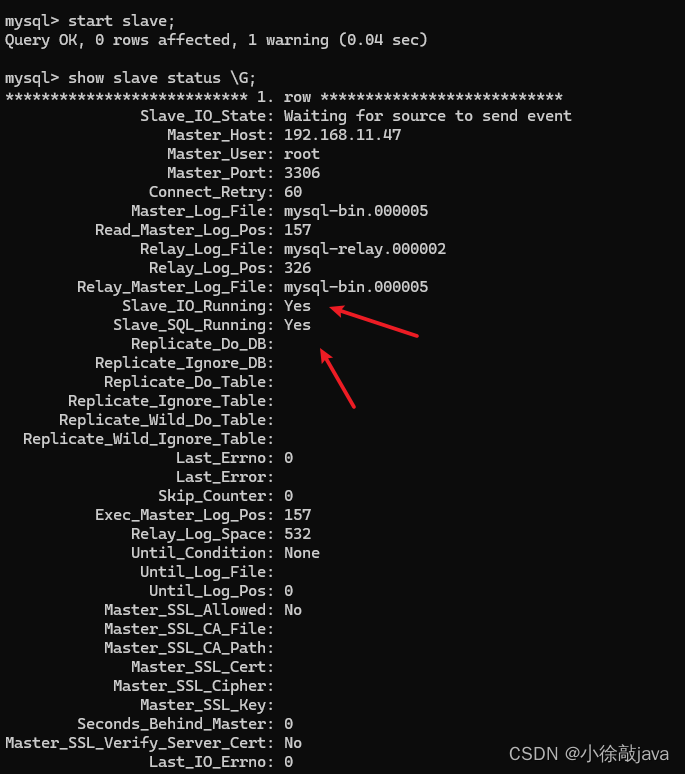
搭建mysql主从复制(主主复制)
1:设主库允许远程连接(注意:设置账号密码必须使用的插件是mysql_native_password,其他的会连接失败) #切换到mysql这个数据库,修改user表中的host,使其可以实现远程连接 mysql>use mysql; mysql>update user se…...
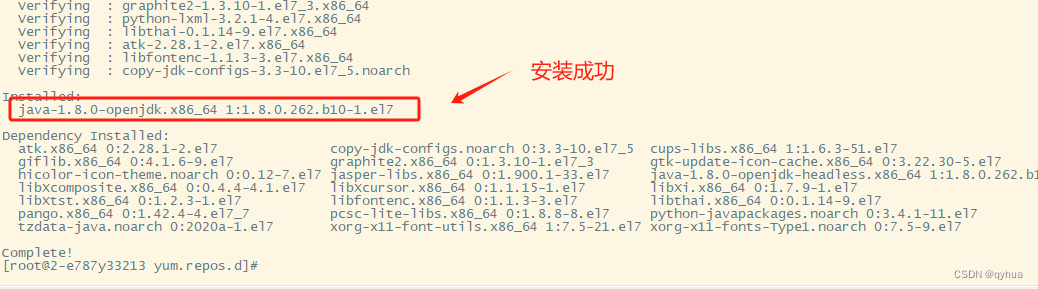
centos 系统 yum 无法安装(换国内镜像地下)
centos 系统 yum 因为无法连接到国外的官网而无法安装,问题如下图: 更换阿里镜像,配置文件路径:/etc/yum.repos.d/CentOS-Base.repo(如果目录有多余的文件可以移动到子目录,以免造成影响) bas…...
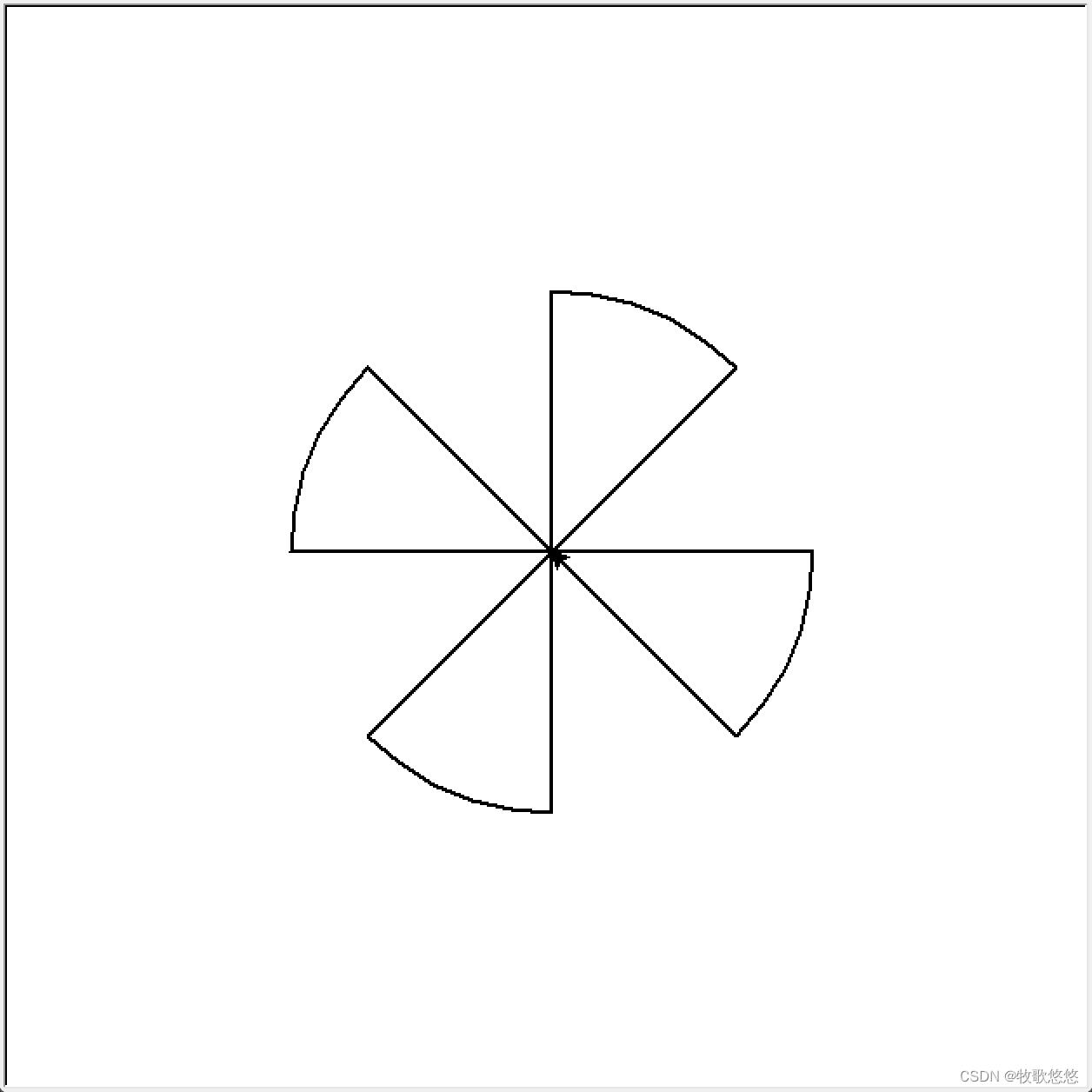
【python绘图】turle 绘图基本案例
文章目录 0. 基础知识1. 蟒蛇绘制2. 正方形绘制3. 六边形绘制4. 叠边形绘制5. 风轮绘制 0. 基础知识 资料来自中国mooc北京理工大学python课程 1. 蟒蛇绘制 import turtle turtle.setup(650, 350, 200, 200) turtle.penup() turtle.fd(-250) turtle.pendown() turtle.pen…...
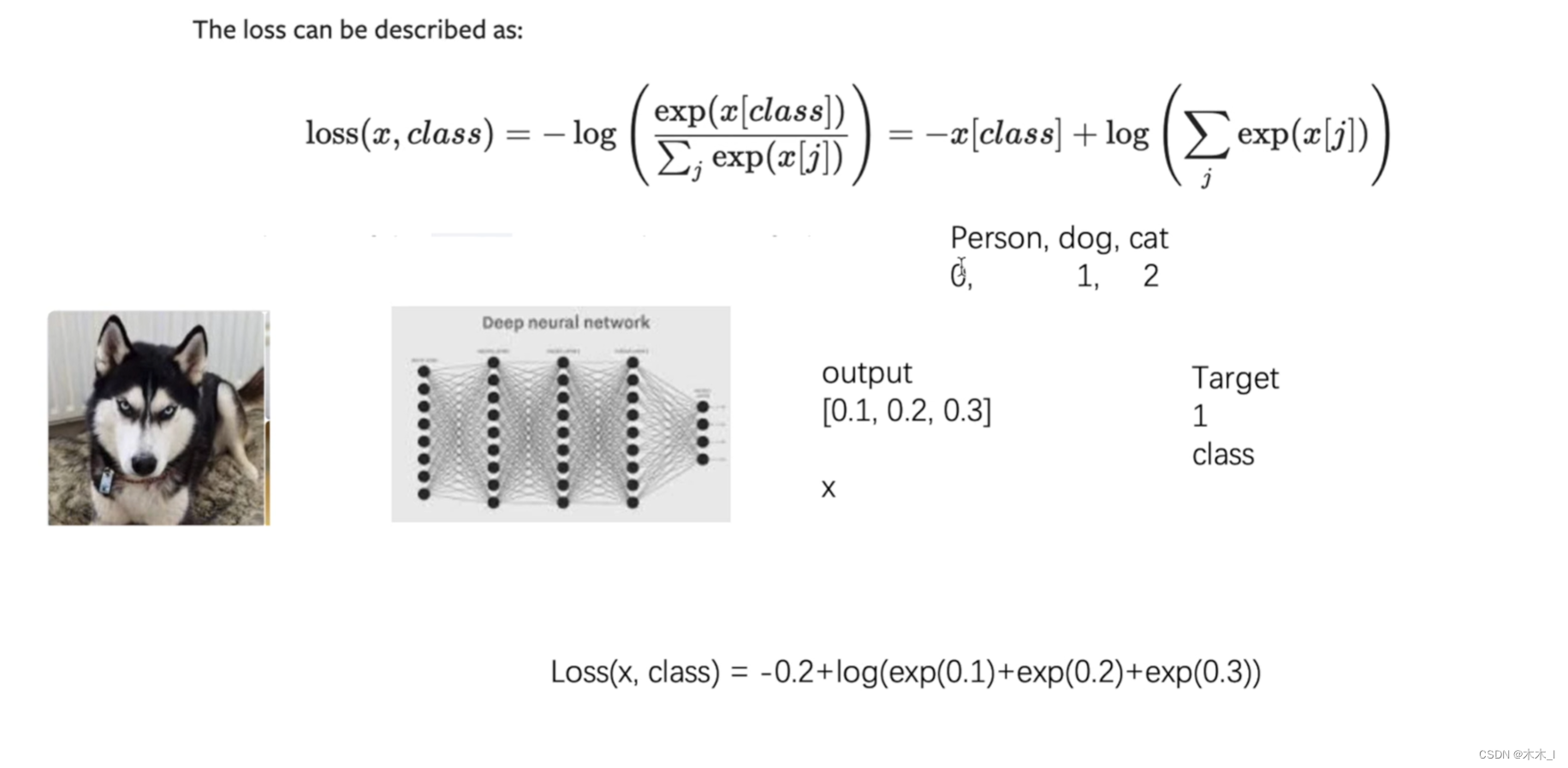
损失函数和反向传播
1. 损失函数的基础 import torch from torch.nn import L1Loss from torch import nninputs torch.tensor([1, 2, 3], dtypetorch.float32) targets torch.tensor([1, 2, 5], dtypetorch.float32)inputs torch.reshape(inputs, (1, 1, 1, 3)) targets torch.reshape(targe…...

Nginx:配置拦截/禁用ip地址
分析nginx日志 1、分析截止目前为止访问量最高的ip排行 awk {print $1} access.log |sort |uniq -c|sort -nr |head -20过滤出access.log日志文件中访问量前20的ip sort :将文件进行排序,并将排序结果标准输出uniq -nr : 去重并在右边显示…...
css超出部分显示省略号
目录 前言 一、CSS单行实现 二、CSS多行实现(CSS3出的,兼容性需要注意) 三、微信小程序超过2行出现省略号实现 四、JavaScript脚本实现 前言 CSS文本溢出就显示省略号,就是在样式中指定了盒子的宽度与高度,有可能出现某些内…...

python-0001-安装虚拟环境
版本 软件版本python3.9.10django2.2.5sqlite33.45.1pycharm2023.3.4 安装python3.9.10 升级sqlite3 下载地址:https://download.csdn.net/download/qq_41833259/88944701 升级命令: tar -zxvf sqlite-autoconf-3399999.tar.gz cd sqlite-autoconf-…...
Python爬虫:原理与实战
引言 在当今的信息时代,互联网上的数据如同浩瀚的海洋,充满了无尽的宝藏。Python爬虫作为一种高效的数据抓取工具,能够帮助我们轻松地获取这些数据,并进行后续的分析和处理。本文将深入探讨Python爬虫的原理,并结合实战…...
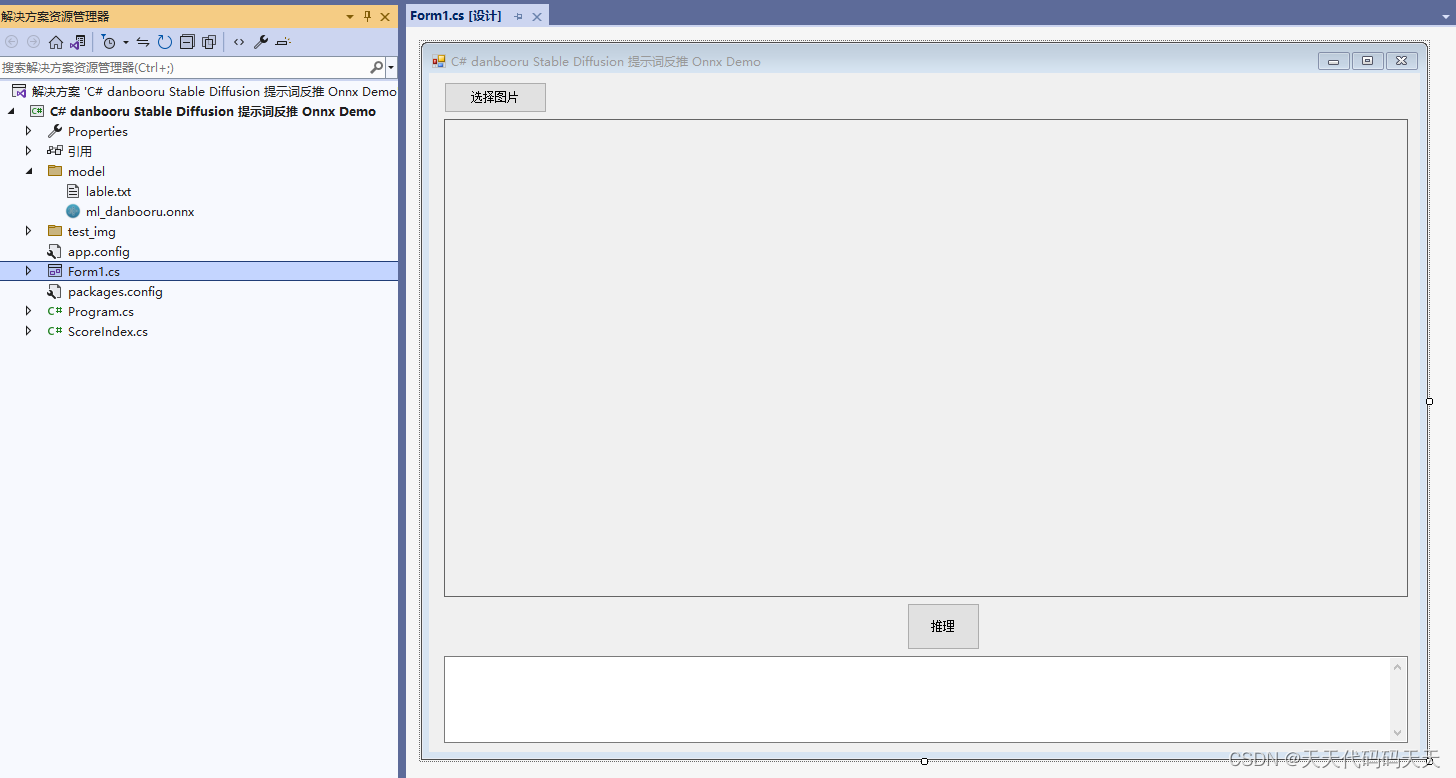
C# danbooru Stable Diffusion 提示词反推 Onnx Demo
目录 说明 效果 模型信息 项目 代码 下载 C# danbooru Stable Diffusion 提示词反推 Onnx Demo 说明 模型下载地址:https://huggingface.co/deepghs/ml-danbooru-onnx 效果 模型信息 Model Properties ------------------------- ----------------------…...
Windows系统搭建Cloudreve结合内网穿透打造可公网访问的私有云盘
目录 ⛳️推荐 1、前言 2、本地网站搭建 2.1 环境使用 2.2 支持组件选择 2.3 网页安装 2.4 测试和使用 2.5 问题解决 3、本地网页发布 3.1 cpolar云端设置 3.2 cpolar本地设置 4、公网访问测试 5、结语 ⛳️推荐 前些天发现了一个巨牛的人工智能学习网站ÿ…...
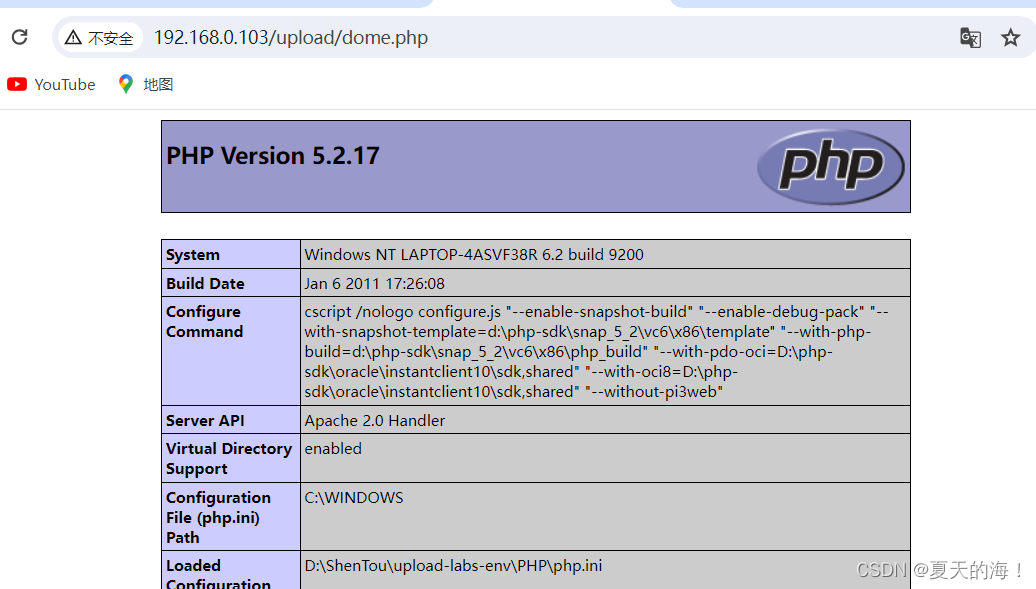
upload-labs 0.1 靶机详解
下载地址https://github.com/c0ny1/upload-labs/releases Pass-01 他让我们上传一张图片,我们先尝试上传一个php文件 发现他只允许上传图片格式的文件,我们来看看源码 我们可以看到它使用js来限制我们可以上传的内容 但是我们的浏览器是可以关闭js功能的…...
react 综合题-旧版
一、组件基础 1. React 事件机制 javascript 复制代码<div onClick{this.handleClick.bind(this)}>点我</div> React并不是将click事件绑定到了div的真实DOM上,而是在document处监听了所有的事件,当事件发生并且冒泡到document处的时候&a…...

基于ElasticSearch存储海量AIS数据:AIS数据索引机制篇
文章目录 引言I 预备知识1.1 索引结构1.2 AIS信息项II AIS数据索引2.1 AIS数据静态数据索引2.2 AIS数据动态信息索引2.3 引入静态信息的AIS数据轨迹信息索引引言 AIS数据信息根据其不同更新频率可分为静态和动态信息。索引结构设计包含了静态、动态和轨迹信息索引。同时,为了…...

AI代理运行时基础设施:从上下文溢出到持久化事件日志
1. 这不是新赛道,是 runtime 层的“操作系统时刻”来了你有没有在深夜调试一个跑了三小时的 AI 代理,突然发现它开始胡言乱语?不是模型崩了,不是 prompt 写错了,而是——它的“记忆”被挤掉了。上下文窗口就那么大&…...

2026年AI写作辅助平台实测排行,哪款真正适合一站式撰稿?
2026 年学术 AI 论文工具已形成全流程、理工 / 社科、英文 / 中文、免费 / 付费的清晰分化。综合实测排行与场景适配,千笔AI 是中文全能首选,DeepSeek 学术版是理工开源首选,毕业之家是国内毕业专属首选。 一、2026 年实测排行 TOP5ÿ…...

【Android】Hypic 醒图国际版 最新版-免登录
【Android】Hypic 醒图国际版 最新版-解锁永久会员-免登录 链接:https://pan.xunlei.com/s/VOtJaC8K4sK_rrqnINu3HULdA1?pwddfdj# Hypic醒图国际版是一款功能强大的照片编辑应用程序,专为满足专业摄影师和业余爱好者的多样化需求而设计。...

大模型赋能金融行业:应用场景、现实挑战与应对策略
大模型技术在金融领域的应用日益深入,成为行业变革的重要驱动力,有助于降本增效、提升客户体验、赋能风险管理、促进业务创新和助力数字化转型。然而,金融行业应用大模型仍面临高质量数据不足、算力紧缺、技术缺陷、人才短缺及隐私安全等挑战…...

HS2-HF Patch终极指南:一键解锁完整汉化与去码体验
HS2-HF Patch终极指南:一键解锁完整汉化与去码体验 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 还在为《Honey Select 2》的语言障碍和功能限制而…...

汽车12V电源防护:P6KE TVS二极管选型、设计与实战指南
1. 项目概述:汽车电源线上的“隐形保镖”在汽车电子系统的设计里,12V直流电源线是整车的能量动脉,从蓄电池到ECU(发动机控制单元)、从车身控制器到娱乐系统,几乎所有的电子模块都离不开它。但这条“动脉”所…...

企业内如何规范 API Key 使用并实现访问控制与审计
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业内如何规范 API Key 使用并实现访问控制与审计 在中大型企业或技术部门内部,大模型 API 的引入往往伴随着新的管理…...

避开Keil开发大坑:从一次CANFD驱动调试,总结C语言数组操作的5个常见陷阱
避开Keil开发大坑:从一次CANFD驱动调试,总结C语言数组操作的5个常见陷阱 调试嵌入式系统的CANFD驱动时,一个看似简单的数组越界问题让我熬了整整三个通宵。当逻辑分析仪终于捕捉到那个幽灵般的非法内存写入时,我才意识到——在Kei…...

HTTPS抓包失败根因分析:证书信任链与全平台配置实战
1. 为什么HTTPS抓包不是“装个插件就完事”——从浏览器报错红锁说起你刚在Burp Suite里点开Proxy → Options → Import Burps CA Certificate,双击安装完证书,兴冲冲打开Chrome访问https://example.com,结果地址栏赫然挂着一把刺眼的红色锁…...

FastGithub终极教程:5分钟解决GitHub访问卡顿问题
FastGithub终极教程:5分钟解决GitHub访问卡顿问题 【免费下载链接】FastGithub github定制版的dns服务,解析访问github最快的ip 项目地址: https://gitcode.com/gh_mirrors/fa/FastGithub GitHub作为全球最大的代码托管平台,是每个开发…...