PyTorch学习笔记之基础函数篇(十)
文章目录
- 6 张量操作
- 6.1 torch.reshape()函数
- 6.1 torch.transpose()函数
- 6.1 torch.permute()函数
- 6.1 torch.unsqueez()函数
- 6.1 torch.squeeze()函数
- 6.1 torch.cat()函数
- 6.1 torch.stack()函数
6 张量操作
6.1 torch.reshape()函数
torch.reshape() 是 PyTorch 中的一个函数,用于改变一个张量(tensor)的形状(shape)。这个函数并不会改变张量中的数据,而是返回一个具有新形状的张量视图。
函数原型如下:
torch.reshape(input, shape)
- input:需要改变形状的张量。
- shape:一个包含新形状大小的整数元组。
注意事项:
- 新的形状必须与原始张量中的元素总数相匹配。换句话说,input.numel()(即张量中的元素总数)必须等于np.prod(shape)(即新形状中所有维度的乘积)。
- 如果原始张量不是连续存储的(例如,它是一个跨步张量),则reshape操作可能会失败或返回意外的结果。
- 返回的张量与原始张量共享数据内存,这意味着对其中一个张量所做的任何更改都会反映到另一个张量上。
示例:
import torch# 创建一个形状为 (2, 3) 的张量
x = torch.tensor([[1, 2, 3], [4, 5, 6]])# 改变其形状为 (3, 2)
y = x.reshape(3, 2)print(y)
# 输出:
# tensor([[1, 2],
# [3, 4],
# [5, 6]])
在这个例子中,我们有一个形状为 (2, 3) 的张量 x。我们使用 reshape 函数将其改变为形状 (3, 2) 的张量 y。请注意,尽管形状发生了变化,但张量中的元素值保持不变。
6.1 torch.transpose()函数
torch.transpose() 是 PyTorch 中的一个函数,用于交换张量(tensor)的两个维度。这个函数在深度学习中常用于调整张量的形状以适应特定的操作需求。
函数原型如下:
torch.transpose(input, dim0, dim1)
- input:需要进行转置操作的张量。
- dim0:第一个要交换的维度的索引。
- dim1:第二个要交换的维度的索引。
torch.transpose() 函数会返回一个新的张量,其中 dim0 和 dim1 指定的两个维度被交换了位置,而张量中的其他维度保持不变。原始张量不会被改变,因为 PyTorch 中的大多数操作都是惰性的,并且返回的是新张量的视图。
下面是一个使用 torch.transpose() 的例子:
import torch# 创建一个形状为 (2, 3) 的张量
x = torch.tensor([[1, 2, 3], [4, 5, 6]])# 交换第0和第1维
y = torch.transpose(x, 0, 1)print(y)
# 输出:
# tensor([[1, 4],
# [2, 5],
# [3, 6]])
在这个例子中,我们有一个形状为 (2, 3) 的张量 x。通过调用 torch.transpose(x, 0, 1),我们交换了第0维(行)和第1维(列),得到了一个新的形状为 (3, 2) 的张量 y。
注意,torch.transpose() 和 tensor.transpose()(作为张量方法)是等价的。你也可以使用张量方法来进行转置操作:
y = x.transpose(0, 1)
这种转置操作在深度学习中经常用于调整张量的形状以适应模型的要求,比如在进行矩阵乘法或者在进行某些特定的层操作时。
6.1 torch.permute()函数
torch.permute() 是 PyTorch 中的一个函数,用于对张量(tensor)的维度进行重新排序。这个函数返回一个新的张量,其中维度按照指定的顺序重新排列,而原始张量的数据保持不变。
函数原型如下:
torch.permute(input, dims)
- input:需要进行维度重新排序的张量。
- dims:一个包含新维度顺序的整数列表或元组。
dims 中的每个元素都是原始张量维度的索引,按照这些索引的顺序重新排列维度。例如,如果原始张量有一个形状为 (a, b, c),并且 dims = [2, 0, 1],则新的张量将具有形状 (c, a, b)。
下面是一个使用 torch.permute() 的例子:
import torch# 创建一个形状为 (2, 3, 4) 的张量
x = torch.arange(24).reshape(2, 3, 4)# 打印原始张量的形状
print("Original shape:", x.shape)# 重新排列维度,将最后一个维度移动到第一个位置
y = x.permute(2, 0, 1)# 打印重新排列后的张量的形状
print("Permuted shape:", y.shape)
输出:
Original shape: torch.Size([2, 3, 4])
Permuted shape: torch.Size([4, 2, 3])
在这个例子中,原始张量 x 的形状是 (2, 3, 4)。通过调用 permute(2, 0, 1),我们将最后一个维度(索引为 2)移动到了第一个位置,第二个维度(索引为 0)移动到了第二个位置,而第一个维度(索引为 1)移动到了第三个位置。因此,新的张量 y 的形状变成了 (4, 2, 3)。
torch.permute() 在深度学习中经常用于调整张量的维度顺序,以满足特定操作或模型层的要求。例如,在卷积神经网络中,可能需要将通道维度移动到特定的位置。
6.1 torch.unsqueez()函数
torch.unsqueeze() 是 PyTorch 中的一个函数,用于在张量的指定维度上增加一个大小为 1 的新维度。这通常用于调整张量的维度以满足某些操作的要求。
函数原型如下:
torch.unsqueeze(input, dim)
- input:需要增加维度的张量。
- dim:要在其中增加新维度的位置。
使用 unsqueeze() 时,指定的 dim 位置将在张量的形状中插入一个维度,该维度的大小为 1。
下面是一个使用 torch.unsqueeze() 的例子:
import torch# 创建一个形状为 (3,) 的张量
x = torch.tensor([1, 2, 3])# 在第 0 维(即最前面)增加一个大小为 1 的维度
y = torch.unsqueeze(x, 0)print(y.shape) # 输出:torch.Size([1, 3])# 在第 1 维(即原始形状之后)增加一个大小为 1 的维度
z = torch.unsqueeze(x, 1)print(z.shape) # 输出:torch.Size([3, 1])
在这个例子中,我们首先创建了一个形状为 (3,) 的张量 x。然后,我们使用 torch.unsqueeze(x, 0) 在最前面增加了一个维度,得到了形状为 (1, 3) 的张量 y。接着,我们使用 torch.unsqueeze(x, 1) 在原始形状之后增加了一个维度,得到了形状为 (3, 1) 的张量 z。
torch.unsqueeze() 在深度学习中经常用于调整张量的维度以满足特定操作或模型层的要求。例如,在某些情况下,可能需要将一个形状为 (batch_size, channels, height, width) 的图像张量调整为 (batch_size, 1, channels, height, width),以便能够作为某些模型的输入。
6.1 torch.squeeze()函数
torch.squeeze() 是 PyTorch 中的一个函数,用于移除张量中所有大小为 1 的维度。换句话说,它会“压缩”张量,删除所有单维度条目。
函数原型如下:
torch.squeeze(input, dim=None)
- input:需要压缩维度的张量。
- dim:可选参数,指定要移除的维度的索引。如果提供,则仅移除该维度,即使它的大小不为 1。
如果不指定 dim 参数,torch.squeeze() 会移除所有大小为 1 的维度。如果指定了 dim,则只移除该特定索引的维度,无论它的大小如何。
下面是一个使用 torch.squeeze() 的例子:
import torch# 创建一个形状为 (1, 3, 1, 4) 的张量
x = torch.tensor([[[[1, 2, 3, 4]]])# 移除所有大小为 1 的维度
y = torch.squeeze(x)print(y.shape) # 输出:torch.Size([3, 4])# 只移除第 0 维(索引为 0)
z = torch.squeeze(x, dim=0)print(z.shape) # 输出:torch.Size([1, 3, 1, 4])# 只移除第 2 维(索引为 2)
w = torch.squeeze(x, dim=2)print(w.shape) # 输出:torch.Size([1, 3, 4])
在这个例子中,我们首先创建了一个形状为 (1, 3, 1, 4) 的张量 x。然后,我们使用 torch.squeeze(x) 移除了所有大小为 1 的维度,得到了形状为 (3, 4) 的张量 y。
接下来,我们尝试只移除特定的维度。使用 torch.squeeze(x, dim=0) 时,我们尝试移除第 0 维,但因为这个维度的大小不为 1,所以张量的形状没有变化。使用 torch.squeeze(x, dim=2) 时,我们移除了第 2 维(即使它的大小为 1),得到了形状为 (1, 3, 4) 的张量 w。
torch.squeeze() 在深度学习中通常用于清理张量的形状,以便它们可以用于特定的操作或模型层。例如,某些层可能不接受具有大小为 1 的维度的输入,或者为了计算效率,我们可能希望移除这些维度。
6.1 torch.cat()函数
torch.cat() 是 PyTorch 中的一个函数,用于沿着指定的维度拼接张量序列。这意味着你可以将多个张量按照某个维度连接起来,形成一个更大的张量。
函数原型如下:
torch.cat(tensors, dim=0, *, out=None)
- tensors:一个张量序列,用于拼接的张量列表或元组。
- dim:拼接操作的维度。默认值是 0,表示在第一个维度上进行拼接。
- out:可选参数,指定输出张量。
下面是一个使用 torch.cat() 的例子:
import torch# 创建两个形状为 (2, 3) 的张量
x = torch.tensor([[1, 2, 3], [4, 5, 6]])
y = torch.tensor([[7, 8, 9], [10, 11, 12]])# 沿着第一个维度(dim=0)拼接张量
z = torch.cat((x, y), dim=0)print(z)
# 输出:
# tensor([[ 1, 2, 3],
# [ 4, 5, 6],
# [ 7, 8, 9],
# [10, 11, 12]])# 沿着第二个维度(dim=1)拼接张量
w = torch.cat((x, y), dim=1)print(w)
# 输出:
# tensor([[ 1, 2, 3, 7, 8, 9],
# [ 4, 5, 6, 10, 11, 12]])
在这个例子中,我们首先创建了两个形状为 (2, 3) 的张量 x 和 y。然后,我们使用 torch.cat((x, y), dim=0) 沿着第一个维度(dim=0)将它们拼接起来,形成了一个形状为 (4, 3) 的张量 z。接着,我们使用 torch.cat((x, y), dim=1) 沿着第二个维度(dim=1)将它们拼接起来,形成了一个形状为 (2, 6) 的张量 w。
torch.cat() 在深度学习中经常用于组合多个张量,以便能够作为一个整体进行后续的操作或计算。
6.1 torch.stack()函数
torch.stack() 是 PyTorch 中的一个函数,用于沿着新的维度对张量序列进行连接。与 torch.cat() 不同,torch.stack() 会在指定的新维度上增加张量,而不是将它们连接起来。
函数原型如下:
torch.stack(tensors, dim=0, *, out=None)
- tensors:一个张量序列,这些张量将被堆叠起来。
- dim:插入新维度的位置。默认值是 0,意味着新维度将成为最前面的维度。
- out:可选参数,指定输出张量。
torch.stack() 要求所有输入张量具有相同的形状,除了沿着堆叠维度(dim)变化的维度之外。
下面是一个使用 torch.stack() 的例子:
import torch# 创建两个形状为 (3,) 的张量
x = torch.tensor([1, 2, 3])
y = torch.tensor([4, 5, 6])# 沿着第 0 维(即最前面)堆叠张量
z = torch.stack((x, y), dim=0)print(z)
# 输出:
# tensor([[1, 2, 3],
# [4, 5, 6]])# 创建一个形状为 (2, 3) 的张量
a = torch.tensor([[1, 2, 3], [4, 5, 6]])# 沿着第 1 维(即列方向)堆叠张量 x 和 a
b = torch.stack((x, a), dim=1)print(b)
# 输出:
# tensor([[1, 1, 2, 3],
# [2, 4, 5, 6],
# [3, 7, 8, 9]])
在这个例子中,我们首先创建了两个形状为 (3,) 的张量 x 和 y。使用 torch.stack((x, y), dim=0),我们在第 0 维(即最前面)堆叠了这两个张量,得到了一个形状为 (2, 3) 的张量 z。
然后,我们创建了一个形状为 (2, 3) 的张量 a。使用 torch.stack((x, a), dim=1),我们在第 1 维(即列方向)堆叠了 x 和 a,得到了一个形状为 (3, 4) 的张量 b。
torch.stack() 在深度学习中通常用于将多个张量组合成一个更高维度的张量,以满足某些操作或模型的要求。
相关文章:
)
PyTorch学习笔记之基础函数篇(十)
文章目录 6 张量操作6.1 torch.reshape()函数6.1 torch.transpose()函数6.1 torch.permute()函数6.1 torch.unsqueez()函数6.1 torch.squeeze()函数6.1 torch.cat()函数6.1 torch.stack()函数 6 张量操作 6.1 torch.reshape()函数 torch.reshape() 是 PyTorch 中的一个函数&a…...

kubernetes部署集群
kubernetes部署集群 集群部署获取镜像安装docker[集群]阿里仓库下载[集群]集群部署[集群]集群环境配置[集群]关闭系统Swap[集群]安装Kubeadm包[集群]配置启动kubelet[集群]配置master节点[master]配置使用网络插件[master]node加入集群[node]后续检查[master]测试集群 集群部署…...

软件工程师,该偿还一下技术债了
概述 在软件开发领域,有一个特殊的概念——“技术债”,它源于Ward Cunningham的一个比喻,主要用来描述那些为了短期利益而选择的快捷方式、临时解决方案或者未完成的工作,它们会在未来产生额外的技术成本。就像金融债务一样&#…...
)
HTML5、CSS3面试题(三)
HTML5、CSS3面试题(二) rem 适配方法如何计算 HTML 跟字号及适配方案?(必会) 通用方案 1、设置根 font-size:625%(或其它自定的值,但换算规则 1rem 不能小于 12px) 2…...
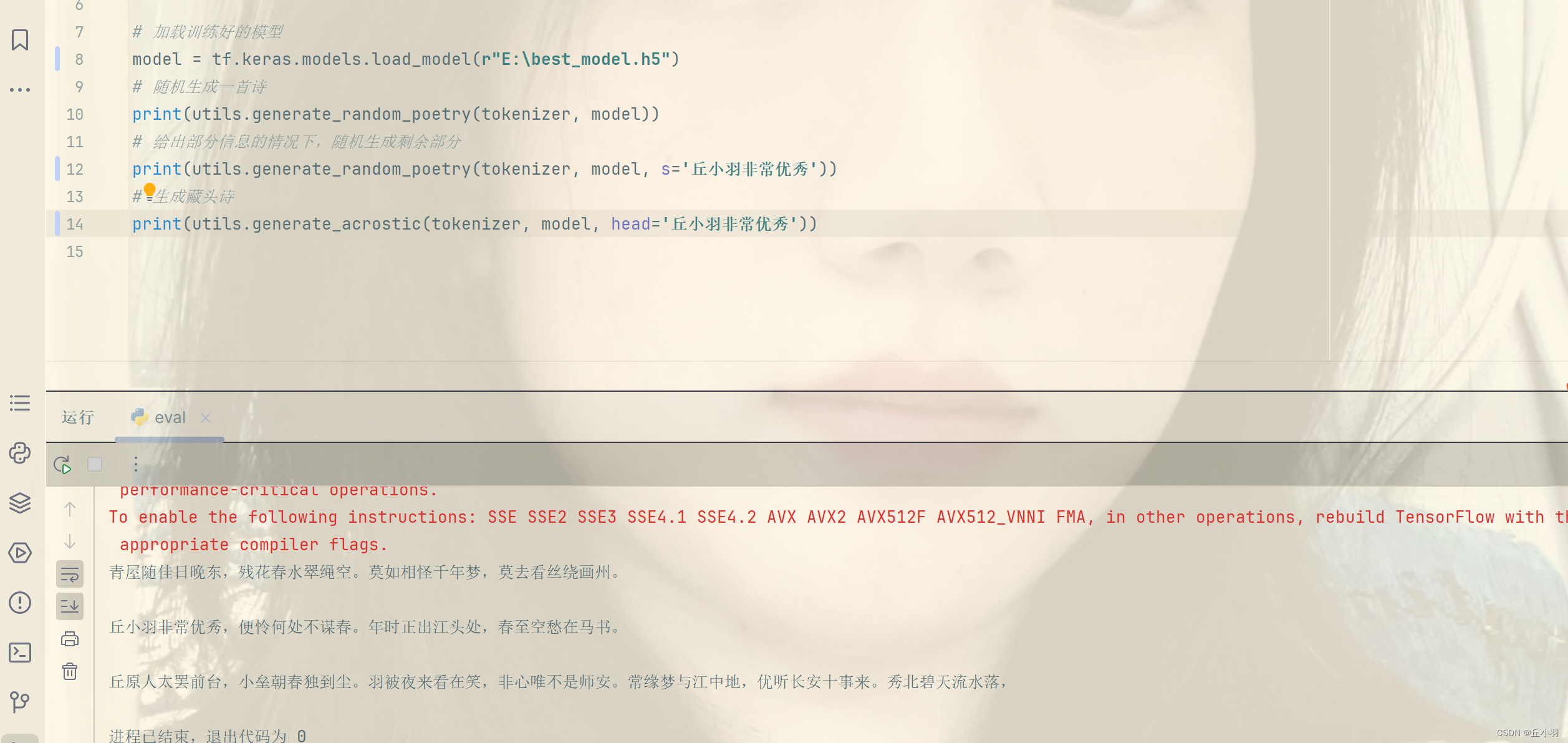
pytorch之诗词生成6--eval
先上代码: import tensorflow as tf from dataset import tokenizer import settings import utils# 加载训练好的模型 model tf.keras.models.load_model(r"E:\best_model.h5") # 随机生成一首诗 print(utils.generate_random_poetry(tokenizer, model)…...

Django自定义中间件
自定义中间件 传统方法的的五大钩子函数:(需要调用MiddlewareMixin类) process_request,请求刚到来,执行视图之前;正序 process_view,路由转发到视图,执行视图之前;正序…...
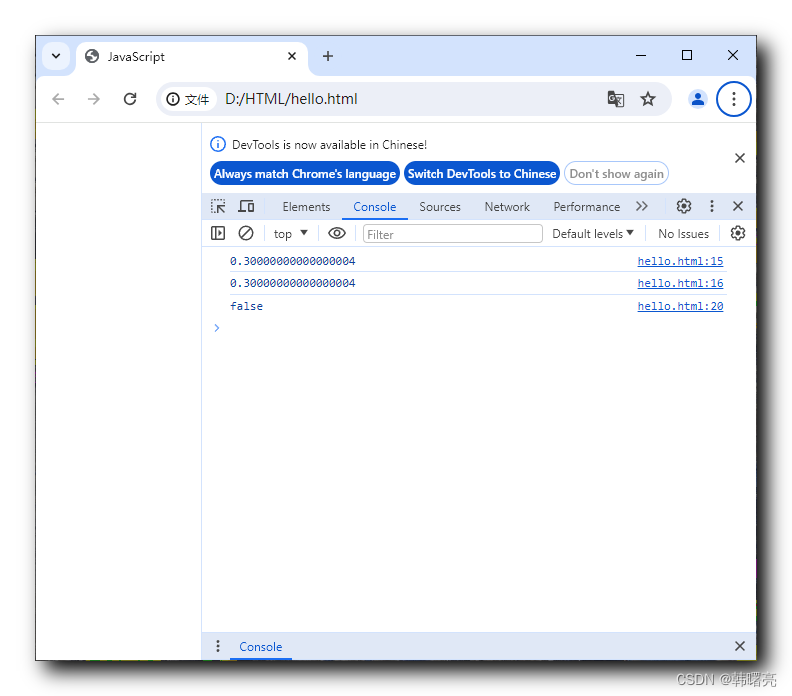
【JavaScript】JavaScript 运算符 ① ( 运算符分类 | 算术运算符 | 浮点数 的 算术运算 精度问题 )
文章目录 一、JavaScript 运算符1、运算符分类2、算术运算符3、浮点数 的 算术运算 精度问题 一、JavaScript 运算符 1、运算符分类 在 JavaScript 中 , 运算符 又称为 " 操作符 " , 可以实现 赋值 , 比较 > < , 算术运算 -*/ 等功能 , 运算符功能主要分为以下…...

掘根宝典之C++迭代器简介
简介 迭代器是一种用于遍历容器元素的对象。它提供了一种统一的访问方式,使程序员可以对容器中的元素进行逐个访问和操作,而不需要了解容器的内部实现细节。 C标准库里每个容器都定义了迭代器 迭代器的作用类似于指针,可以指向容器中的某个…...

DP-力扣 120.三角形最小路径和
给定一个三角形,找出自顶向下的最小路径和。每一步只能移动到下一行中相邻的结点上。相邻的结点: 下标与上一层结点下标相同或者等于上一层结点下标 1 的两个结点。样例: 例如,给定三角形: [ [2], [3,4], [6,5,7], [4…...

【WEEK3】学习目标及总结【SpringMVC】【中文版】
学习目标: 三周完成SpringMVC入门——第三周 感觉这周很难完成任务了,大概率还会有第四周 学习内容: 参考视频教程【狂神说Java】SpringMVC最新教程IDEA版通俗易懂数据处理JSON交互处理 学习时间及产出: 第三周 MON~FRI 2024.…...

peft模型微调--Prompt Tuning
模型微调(Model Fine-Tuning)是指在预训练模型的基础上,针对特定任务进行进一步的训练以优化模型性能的过程。预训练模型通常是在大规模数据集上通过无监督或自监督学习方法预先训练好的,具有捕捉语言或数据特征的强大能力。 PEF…...

【算法训练营】周测1
清华大学驭风计划课程链接 学堂在线 - 精品在线课程学习平台 (xuetangx.com) 如果需要答案代码可以私聊博主 有任何疑问或者问题,也欢迎私信博主,大家可以相互讨论交流哟~~ 考题11-1 题目描述 有一个初始时为空的序列,你的任务是维护这个…...

PyTorch Dataset、DataLoader长度
pytorch 可以直接对 Dataset 对象用 len() 求数据集大小,而 DataLoader 对象也可以用 len(),不过求得的是用这个 loader 在一个 epoch 能有几多 iteration,容易混淆。本文记录几种情况的对比。 from torch.utils.data import Dataset, DataL…...

动态IP和静态IP
与静态 IP 地址不同,动态 IP 地址会定期更改。让我们来分析一下: 1. IP 地址基础知识: * IP 地址是一个数字标签,用于唯一标识网络上的每个设备。 * 当设备通过网络通信时,数据会在它们之间来回传输。每个数据包都标有…...
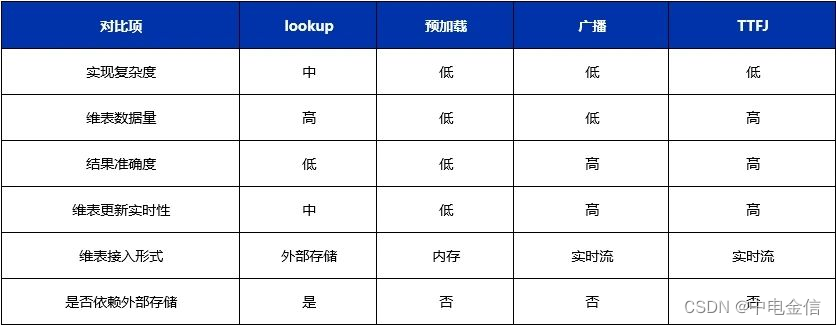
中电金信:技术实践|Flink维度表关联方案解析
导语:Flink是一个对有界和无界数据流进行状态计算的分布式处理引擎和框架,主要用来处理流式数据。它既可以处理有界的批量数据集,也可以处理无界的实时流数据,为批处理和流处理提供了统一编程模型。 维度表可以看作是用户来分析数…...

HQL 55 题【持续更新】
前言 今天开始为期一个多月的 HQL 练习,共 55 道 HQL 题,大概每天两道,从初级函数到中级函数。这次的练习不再是基础的 join 那种通用 SQL 语法了,而是引入了更多 Hive 的函数(单行函数、窗口函数等)。 我…...

lqb省赛日志[8/37]-[搜索·DFS·BFS]
一只小蒟蒻备考蓝桥杯的日志 文章目录 笔记DFS记忆化搜索 刷题心得小结 笔记 DFS 参考 深度优先搜索(DFS) 总结(算法剪枝优化总结) DFS的模板框架: function dfs(当前状态){if(当前状态 目的状态){}for(寻找新状态){if(状态合法){vis[访问该点];dfs(新状态);?…...
uni app 钓鱼小游戏
最近姑娘喜欢玩那个餐厅游戏里的钓鱼 ,经常让看广告,然后就点点点... 自己写个吧。小鱼的图片自己搞。 有问题自己改,不要私信我 <template><view class"page_main"><view class"top_linear"><v…...
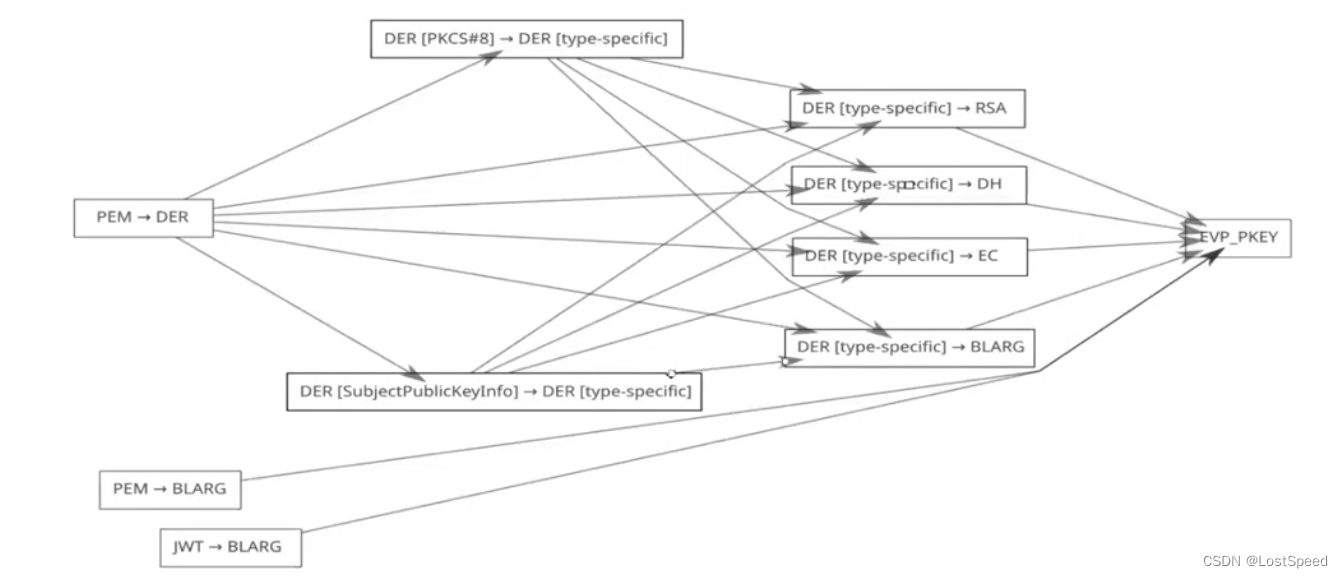
openssl3.2 - note - Decoders and Encoders with OpenSSL
文章目录 openssl3.2 - note - Decoders and Encoders with OpenSSL概述笔记编码器/解码器的调用链OSSL_STORE 编码器/解码器的名称和属性OSSL_FUNC_decoder_freectx_fnOSSL_FUNC_encoder_encode_fn官方文档END openssl3.2 - note - Decoders and Encoders with OpenSSL 概述 …...

分享几个 Selenium 自动化常用操作
最近工作会用到selenium来自动化操作一些重复的工作,那么在用selenium写代码的过程中,又顺手整理了一些常用的操作,分享给大家。 常用元素定位方法 虽然有关selenium定位元素的方法有很多种,但是对于没有深入学习,尤…...

为什么92%的Sora 2初学者卡在第4步?——帧一致性崩塌诊断工具包+时间轴锚点校准法
更多请点击: https://kaifayun.com 第一章:Sora 2视频生成的核心原理与环境准备 Sora 2并非OpenAI官方发布的模型,而是社区基于Sora技术理念构建的开源复现与增强框架,其核心依托于时空联合建模的扩散变换器(Spacetim…...

如何高效批量下载音乐歌词:智能歌词管理完整指南
如何高效批量下载音乐歌词:智能歌词管理完整指南 【免费下载链接】ZonyLrcToolsX ZonyLrcToolsX 是一个能够方便地下载歌词的小软件。 项目地址: https://gitcode.com/gh_mirrors/zo/ZonyLrcToolsX ZonyLrcToolsX 是一款专业的跨平台歌词下载工具,…...

Owl-Alpha 新手快速上手指南
在处理大规模数据或构建高性能应用时,我们常常会遇到一个棘手的问题:如何在不阻塞主线程的情况下,高效地执行耗时任务?无论是处理图像、解析大型文件,还是进行复杂的数学运算,传统的单线程模式往往会让界面…...

3大实战秘籍:揭秘raylib如何让游戏开发像搭积木一样简单
3大实战秘籍:揭秘raylib如何让游戏开发像搭积木一样简单 【免费下载链接】raylib A simple and easy-to-use library to enjoy videogames programming 项目地址: https://gitcode.com/GitHub_Trending/ra/raylib 你是否曾经被复杂的游戏引擎配置搞得焦头烂额…...
)
YOLOv8晶圆体缺识别检测系统(项目源码+YOLO数据集+模型权重+UI界面+python+深度学习+环境配置)
摘要 晶圆制造过程中的缺陷检测是保证芯片良率的关键环节。本文基于YOLOv8目标检测算法,构建了一套针对晶圆表面9类典型缺陷的自动检测系统。所识别的缺陷类型包括:Center、Donut、Edge-Loc、Edge-Ring、Loc、Near-full、None、Random、Scratch。模型在…...

如何快速上手DeepPurpose?5分钟完成你的第一个药物-靶点相互作用预测模型
如何快速上手DeepPurpose?5分钟完成你的第一个药物-靶点相互作用预测模型 【免费下载链接】DeepPurpose A Deep Learning Toolkit for DTI, Drug Property, PPI, DDI, Protein Function Prediction (Bioinformatics) 项目地址: https://gitcode.com/gh_mirrors/de…...

Performance-Fish:让你的《环世界》后期游戏帧率提升400%的终极优化方案
Performance-Fish:让你的《环世界》后期游戏帧率提升400%的终极优化方案 【免费下载链接】Performance-Fish Performance Mod for RimWorld 项目地址: https://gitcode.com/gh_mirrors/pe/Performance-Fish 你是否曾在《环世界》游戏后期,面对庞大…...

终极免费音乐解锁工具:打破平台枷锁,让音乐重获自由
终极免费音乐解锁工具:打破平台枷锁,让音乐重获自由 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地…...
)
Midjourney模糊效果深度拆解(从--stylize到--sref的光学模拟原理揭秘)
更多请点击: https://codechina.net 第一章:Midjourney模糊效果的本质与视觉认知基础 Midjourney 中的模糊效果并非图像后处理意义上的高斯模糊(Gaussian Blur),而是由扩散模型在潜空间中对高频细节进行概率性抑制所…...
:从MMLU到GPQA、从AIME到LiveCodeBench,一表看透真实能力边界)
DeepSeek模型选型终极指南(附完整Benchmark Excel模板):从MMLU到GPQA、从AIME到LiveCodeBench,一表看透真实能力边界
更多请点击: https://intelliparadigm.com 第一章:DeepSeek模型选型终极指南(附完整Benchmark Excel模板):从MMLU到GPQA、从AIME到LiveCodeBench,一表看透真实能力边界 选择适配业务场景的DeepSeek模型&am…...