peft模型微调--Prompt Tuning
模型微调(Model Fine-Tuning)是指在预训练模型的基础上,针对特定任务进行进一步的训练以优化模型性能的过程。预训练模型通常是在大规模数据集上通过无监督或自监督学习方法预先训练好的,具有捕捉语言或数据特征的强大能力。
PEFT(Parameter-Efficient Fine-Tuning)是一种针对大模型微调的技术,其核心思想是在保持大部分预训练模型参数不变的基础上,仅对一小部分额外参数进行微调,以实现高效的资源利用和性能优化。这种方法对于那些计算资源有限、但又需要针对特定任务调整大型语言模型(如LLM:Large Language Models)的行为时特别有用。
在应用PEFT技术进行模型微调时,通常采用以下策略之一或组合:
Adapter Layers: 在模型的各个层中插入适配器模块,这些适配器模块通常具有较低的维度,并且仅对这部分新增的参数进行微调,而不改变原模型主体的参数。
Prefix Tuning / Prompt Tuning: 通过在输入序列前添加可学习的“提示”向量(即prefix或prompt),来影响模型的输出结果,从而达到微调的目的,而无需更改模型原有权重。
LoRA (Low-Rank Adaptation): 使用低秩矩阵更新原始模型权重,这样可以大大减少要训练的参数数量,同时保持模型的表达能力。
P-Tuning V1/V2: 清华大学提出的一种方法,它通过学习一个连续的prompt嵌入向量来指导模型生成特定任务相关的输出。
冻结(Freezing)大部分模型参数: 只对模型的部分层或头部(如分类器层)进行微调,其余部分则保持预训练时的状态不变。
下面简单介绍一个通过peft使用Prompt Tuning对模型进行微调训练的简单流程。
# 基于peft使用prompt tuning对生成式对话模型进行微调
from datasets import Dataset
from transformers import AutoTokenizer, AutoModelForCausalLM, DataCollatorForSeq2Seq, TrainingArguments, Trainer
# 数据加载
ds = Dataset.load_from_disk("/alpaca_data_zh")
print(ds[:3])
# 数据处理
tokenizer = AutoTokenizer.from_pretrained("../models/bloom-1b4-zh")
# 数据处理函数
def process_func(example):MAX_LENGTH = 256input_ids, attention_mask, labels = [], [], []instruction = tokenizer("\n".join(["Human: " + example["instruction"], example["input"]]).strip() + "\n\nAssistant: ")response = tokenizer(example["output"] + tokenizer.eos_token)input_ids = instruction["input_ids"] + response["input_ids"]attention_mask = instruction["attention_mask"] + response["attention_mask"]labels = [-100] * len(instruction["input_ids"]) + response["input_ids"]if len(input_ids) > MAX_LENGTH:input_ids = input_ids[:MAX_LENGTH]attention_mask = attention_mask[:MAX_LENGTH]labels = labels[:MAX_LENGTH]return {"input_ids": input_ids,"attention_mask": attention_mask,"labels": labels}# 数据处理
tokenized_ds = ds.map(process_func, remove_columns=ds.column_names)
print(tokenized_ds)
# 模型创建
model = AutoModelForCausalLM.from_pretrained("../models/bloom-1b4-zh", low_cpu_mem_usage=True)
# 套用peft对模型进行参数微调
from peft import PromptTuningConfig, get_peft_model, TaskType, PromptTuningInit# 1、配置文件参数
config = PromptTuningConfig(task_type=TaskType.CAUSAL_LM,prompt_tuning_init=PromptTuningInit.TEXT,prompt_tuning_init_text="下面是一段人与机器人的对话。",num_virtual_tokens=len(tokenizer("下面是一段人与机器人的对话。")["input_ids"]),tokenizer_name_or_path="../models/bloom-1b4-zh")# 2、创建模型
model = get_peft_model(model, config)
# 查看模型的训练参数
model.print_trainable_parameters()
# 配置训练参数
args = TrainingArguments(output_dir="./peft_model",per_device_train_batch_size=1,gradient_accumulation_steps=8,logging_steps=10,num_train_epochs=1
)# 创建训练器
trainer = Trainer(model=model,args=args,train_dataset=tokenized_ds,data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True),
)
# 模型训练
trainer.train()
# 模型推理
peft_model = model.cuda()
ipt = tokenizer("Human: {}\n{}".format("周末去重庆怎么玩?", "").strip() + "\n\nAssistant: ", return_tensors="pt").to(model.device)
print(tokenizer.decode(peft_model.generate(**ipt, max_length=256, do_sample=True)[0], skip_special_tokens=True))
相关文章:

peft模型微调--Prompt Tuning
模型微调(Model Fine-Tuning)是指在预训练模型的基础上,针对特定任务进行进一步的训练以优化模型性能的过程。预训练模型通常是在大规模数据集上通过无监督或自监督学习方法预先训练好的,具有捕捉语言或数据特征的强大能力。 PEF…...

【算法训练营】周测1
清华大学驭风计划课程链接 学堂在线 - 精品在线课程学习平台 (xuetangx.com) 如果需要答案代码可以私聊博主 有任何疑问或者问题,也欢迎私信博主,大家可以相互讨论交流哟~~ 考题11-1 题目描述 有一个初始时为空的序列,你的任务是维护这个…...

PyTorch Dataset、DataLoader长度
pytorch 可以直接对 Dataset 对象用 len() 求数据集大小,而 DataLoader 对象也可以用 len(),不过求得的是用这个 loader 在一个 epoch 能有几多 iteration,容易混淆。本文记录几种情况的对比。 from torch.utils.data import Dataset, DataL…...

动态IP和静态IP
与静态 IP 地址不同,动态 IP 地址会定期更改。让我们来分析一下: 1. IP 地址基础知识: * IP 地址是一个数字标签,用于唯一标识网络上的每个设备。 * 当设备通过网络通信时,数据会在它们之间来回传输。每个数据包都标有…...
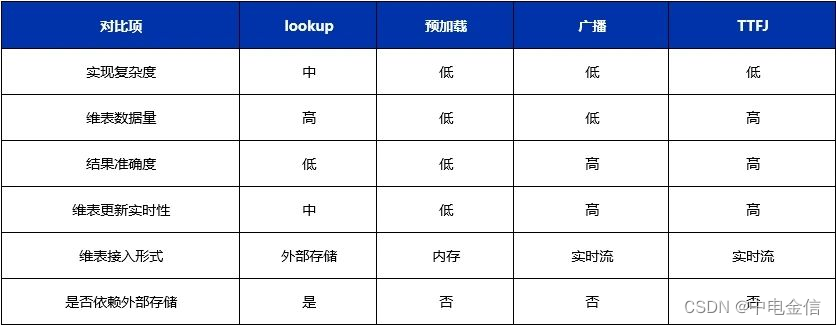
中电金信:技术实践|Flink维度表关联方案解析
导语:Flink是一个对有界和无界数据流进行状态计算的分布式处理引擎和框架,主要用来处理流式数据。它既可以处理有界的批量数据集,也可以处理无界的实时流数据,为批处理和流处理提供了统一编程模型。 维度表可以看作是用户来分析数…...

HQL 55 题【持续更新】
前言 今天开始为期一个多月的 HQL 练习,共 55 道 HQL 题,大概每天两道,从初级函数到中级函数。这次的练习不再是基础的 join 那种通用 SQL 语法了,而是引入了更多 Hive 的函数(单行函数、窗口函数等)。 我…...

lqb省赛日志[8/37]-[搜索·DFS·BFS]
一只小蒟蒻备考蓝桥杯的日志 文章目录 笔记DFS记忆化搜索 刷题心得小结 笔记 DFS 参考 深度优先搜索(DFS) 总结(算法剪枝优化总结) DFS的模板框架: function dfs(当前状态){if(当前状态 目的状态){}for(寻找新状态){if(状态合法){vis[访问该点];dfs(新状态);?…...
uni app 钓鱼小游戏
最近姑娘喜欢玩那个餐厅游戏里的钓鱼 ,经常让看广告,然后就点点点... 自己写个吧。小鱼的图片自己搞。 有问题自己改,不要私信我 <template><view class"page_main"><view class"top_linear"><v…...
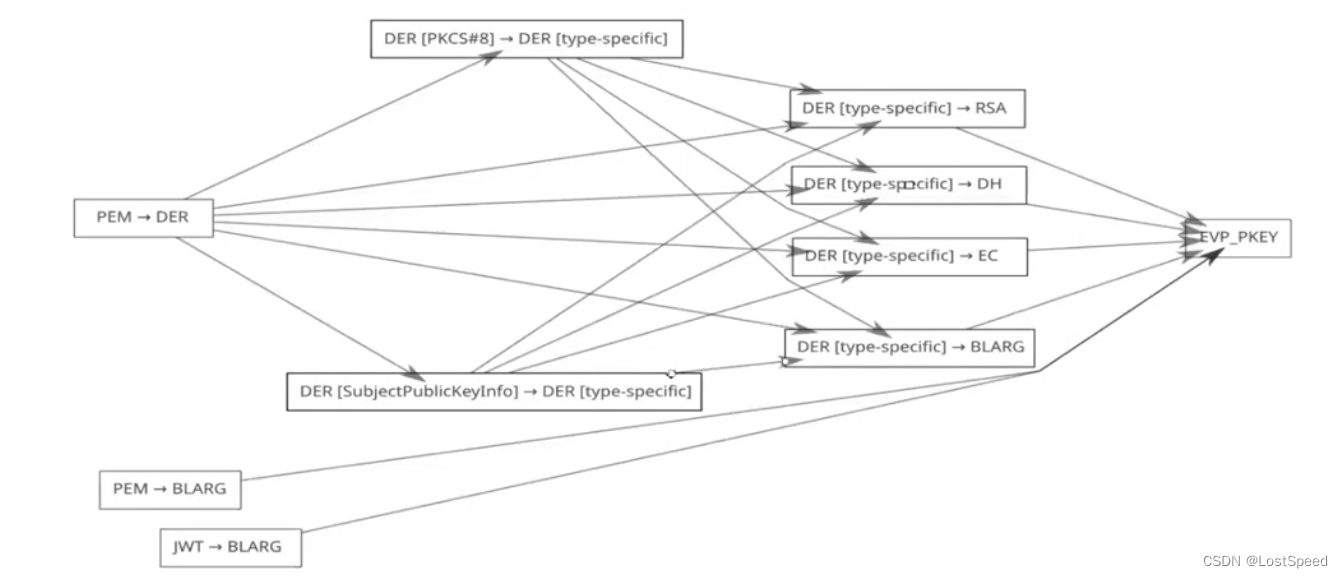
openssl3.2 - note - Decoders and Encoders with OpenSSL
文章目录 openssl3.2 - note - Decoders and Encoders with OpenSSL概述笔记编码器/解码器的调用链OSSL_STORE 编码器/解码器的名称和属性OSSL_FUNC_decoder_freectx_fnOSSL_FUNC_encoder_encode_fn官方文档END openssl3.2 - note - Decoders and Encoders with OpenSSL 概述 …...

分享几个 Selenium 自动化常用操作
最近工作会用到selenium来自动化操作一些重复的工作,那么在用selenium写代码的过程中,又顺手整理了一些常用的操作,分享给大家。 常用元素定位方法 虽然有关selenium定位元素的方法有很多种,但是对于没有深入学习,尤…...
 的常见操作)
【Python】【数据类型】List (列表) 的常见操作
1. 创建 使用内置函数list()将字符串创建为列表 list1 [a, b, c, d] print(list1 , list1) # list1 [a, b, c, d] list1 list(abcd) print(list1) # [a, b, c, d]使用列表推导式创建列表 list1 [x for x in range(1, 10)] print(list1) # [1, 2, 3, 4, 5, 6, 7, 8, 9]多…...

【C语言】病人信息管理系统
本设计实现了一个病人信息管理系统,通过链表数据结构来存储和操作病人的信息。用户可以通过菜单选择录入病人信息、查找病人信息、修改病人信息、删除病人信息、查看所有病人信息和查看专家信息等操作,还可以根据病人的科室、姓名、性别和联系方式进行查找,以及支持修改病人…...

Java Spring Boot 接收时间格式的参数
报错 JSON parse error: Cannot deserialize value of type java.time.LocalDateTime from String “2024-03-14 12:30:00”: Failed to deserialize java.time.LocalDateTime: (java.time.format.DateTimeParseException) Text ‘2024-03-14 12:30:00’ could not be parsed a…...
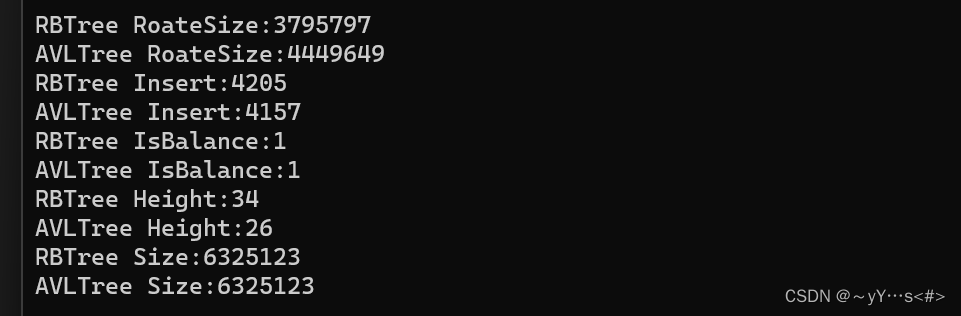
【C++】实现红黑树
目录 一、认识红黑树1.1 概念1.2 定义 二、实现红黑树2.1 插入2.2 与AVL树对比 一、认识红黑树 1.1 概念 红黑树是一个二叉搜索树,与AVL树相比,红黑树不再使用平衡因子来控制树的左右子树高度差,而是用颜色来控制平衡,颜色为红色…...
)
爬虫(六)
复习回顾: 01.浏览器一个网页的加载全过程1. 服务器端渲染html的内容和数据在服务器进行融合.在浏览器端看到的页面源代码中. 有你需要的数据2. 客户端(浏览器)渲染html的内容和数据进行融合是发生在你的浏览器上的.这个过程一般通过脚本来完成(javascript)我们通过浏览器可以…...

最长连续序列 - LeetCode 热题 3
大家好!我是曾续缘💝 今天是《LeetCode 热题 100》系列 发车第 3 天 哈希第 3 题 ❤️点赞 👍 收藏 ⭐再看,养成习惯 最长连续序列 给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素…...
运营模型—RFM 模型
运营模型—RFM 模型 RFM 是什么其实我们前面的文章介绍过,这里我们不再赘述,可以参考运营数据分析模型—用户分层分析,今天我们要做的事情是如何落地RFM 模型 我们的数据如下,现在我们就开始进行数据处理 数据预处理 因为数据预处理没有一个固定的套路,都是根据数据的实…...
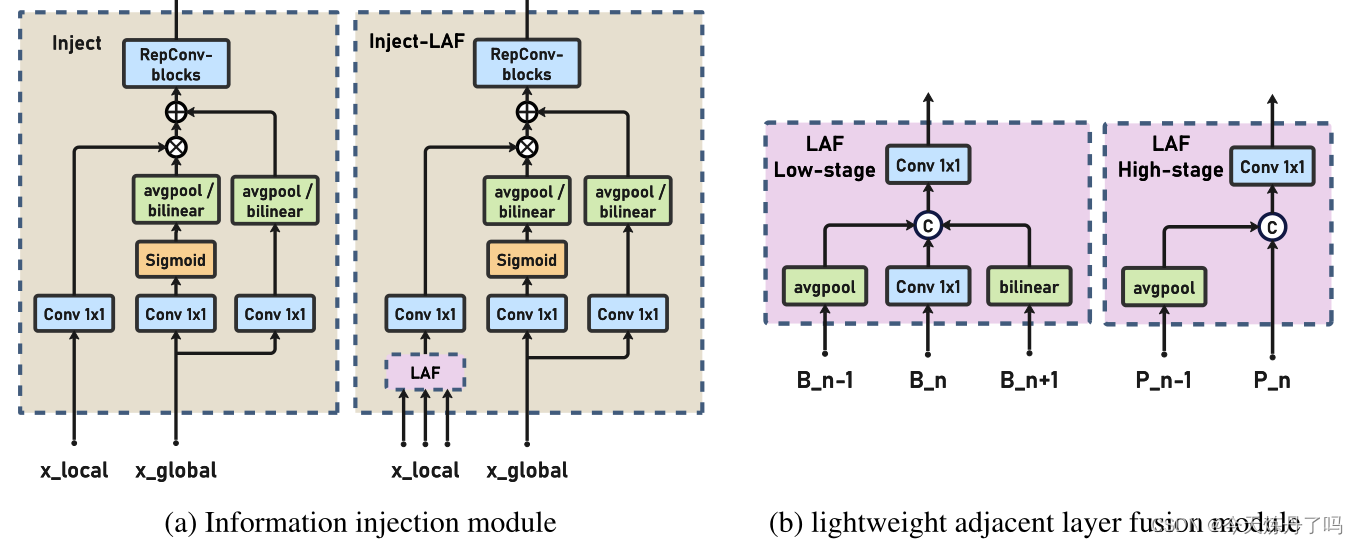
YOLOv9|加入2023Gold YOLO中的GD机制!遥遥领先!
专栏介绍:YOLOv9改进系列 | 包含深度学习最新创新,助力高效涨点!!! 一、Gold YOLO摘要 在过去的几年里,YOLO系列模型已经成为实时目标检测领域的领先方法。许多研究通过修改体系结构、增加数据和设计新的损…...
WRF模型运行教程(ububtu系统)--III.运行WRF模型(官网案例)
零、创建DATA目录 # 1.创建一个DATA目录用于存放数据(一般为fnl数据,放在Build_WRF目录下)。 mkdir DATA # 2.进入 DATA cd DATA 一、WPS预处理 在模拟之前先确定模拟域(即模拟范围),并进行数据预处理(…...
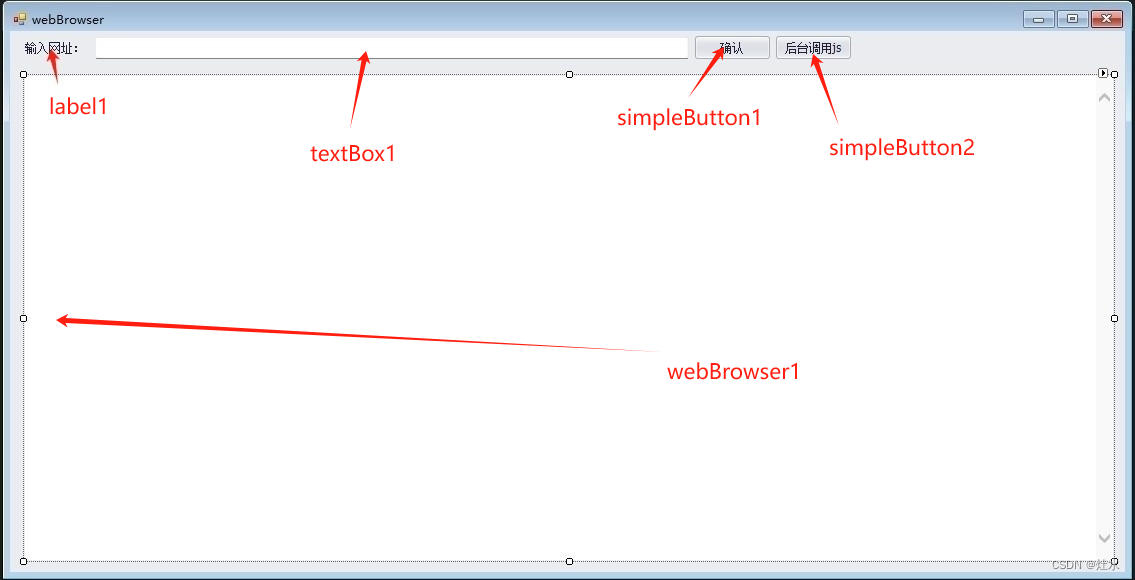
html和winform webBrowser控件交互并播放视频(包含转码)
1、 为了使网页能够与winform交互 将com的可访问性设置为真 [System.Security.Permissions.PermissionSet(System.Security.Permissions.SecurityAction.Demand, Name "FullTrust")][System.Runtime.InteropServices.ComVisibleAttribute(true)] 2、在webBrow…...
)
保姆级教程:在CentOS 7上用达梦8搭建DCA练习环境(附ulimit、VNC、ODBC全配置)
达梦8 DCA认证实战:CentOS 7环境搭建与调优全指南 在国产数据库技术快速发展的今天,达梦数据库作为核心产品之一,其DCA认证已成为众多从业者提升竞争力的重要选择。与理论为主的认证不同,DCA更注重实际操作能力,而一个…...

Win10家庭版别再卡了!保姆级教程:手动修复gpedit.msc路径,彻底关闭Antimalware Service
Win10家庭版性能优化实战:精准修复组策略路径与系统服务调优每次游戏激战正酣时突然卡顿,或是视频渲染到关键时刻系统响应迟缓,很多Win10家庭版用户都遭遇过这类困扰。任务管理器里那个名为"Antimalware Service Executable"的进程…...

本地柴油发电机组排行2023年最新榜单
柴油发电机是通过燃烧柴油驱动发动机,进而发电的设备,广泛应用于电力中断或无电网地区。1. 柴油发电机的核心工作原理是什么?柴油发电机是一种将化学能转化为电能的设备,其核心是柴油发动机与交流发电机的组合。当柴油在发动机内燃…...

我靠这个测试设计方法,把漏测率降低了80%
当“直觉测试”撞上南墙很长一段时间里,我和许多测试同行一样,测试用例的设计主要依靠两样东西:需求文档和“测试直觉”。这种模式在业务逻辑相对简单、迭代速度平缓时还能勉强应付。一旦面对复杂的企业级应用、高频的敏捷迭代,或…...

FM3773 低功耗离线式恒流/恒压 PSR 控制器
概述 FM3773 是一种高性能的交流/直流用于电池充电器和适配器的电源控制器,内置 850V 功率三极管。该设备采用脉冲频率调制(PFM)的方法来建立非连续导通模式(DCM)反激式电源。 FM3773 提供精确的恒定电压,恒…...
)
别再手动编译了!Matlab一键调用CEC2017测试函数的完整配置指南(附30个函数调用示例)
别再手动编译了!Matlab一键调用CEC2017测试函数的完整配置指南(附30个函数调用示例) 算法研究者们常常需要借助标准测试函数来验证优化算法的性能,而CEC2017测试函数集因其复杂性和多维度的挑战性,成为评估算法鲁棒性的…...

开源ELM327 OBD-II适配器:从硬件设计到多协议固件实现全解析
1. 项目概述:开源ELM327 OBD适配器如果你对汽车诊断、数据监控或者嵌入式开发感兴趣,那么自己动手做一个OBD-II适配器绝对是个能让你学到很多东西的硬核项目。今天要聊的,就是一个完全开源的、基于NXP LPC1517微控制器的ELM327兼容OBD适配器。…...

Vue2-Verify:解决前端验证码安全性与用户体验平衡问题的技术方案实现
Vue2-Verify:解决前端验证码安全性与用户体验平衡问题的技术方案实现 【免费下载链接】vue2-verify vue的验证码插件 项目地址: https://gitcode.com/gh_mirrors/vu/vue2-verify 在当今Web应用开发中,验证码作为防止自动化攻击的关键安全组件&…...

2026这6款神级降AIGC平台大公开,一键让AIGC率直逼绝对安全线!
步入 2026 年,学术圈的风向早已不是从前的模样。曾经大家还在为查重率发愁,如今却陷入了更棘手的困境——如何在不破坏论文专业性的前提下,彻底消除 AI 痕迹?随着 AIGC 检测技术不断进化,高校对论文的审核标准也愈发严…...

抖音内容批量下载实战:从零开始构建个人视频资料库
抖音内容批量下载实战:从零开始构建个人视频资料库 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support.…...