中电金信:技术实践|Flink维度表关联方案解析
导语:Flink是一个对有界和无界数据流进行状态计算的分布式处理引擎和框架,主要用来处理流式数据。它既可以处理有界的批量数据集,也可以处理无界的实时流数据,为批处理和流处理提供了统一编程模型。
维度表可以看作是用户来分析数据的窗口,它区别于事实表业务真实发生的数据,通常用来表示业务属性,以便为分析者提供有用的信息。在实际场景中,由于数据是实时变化的,因此需要通过将维度表进行关联,来保证业务的时效性和稳定性。本文主要围绕Flink维度表关联方案进行论述,分析不同关联方案的作用和特点,与各位读者共飨。
维度表与事实表的关联是数据分析中常见的一种分析方式,在传统数仓系统中,由于数据是有界的,因此关联实现相对简单。但是在实时系统或实时数仓中,数据是无界的,关联时需要考虑的问题就会复杂很多,如数据迟到导致的关联结果不准确、缓存数据消耗资源过大等等。
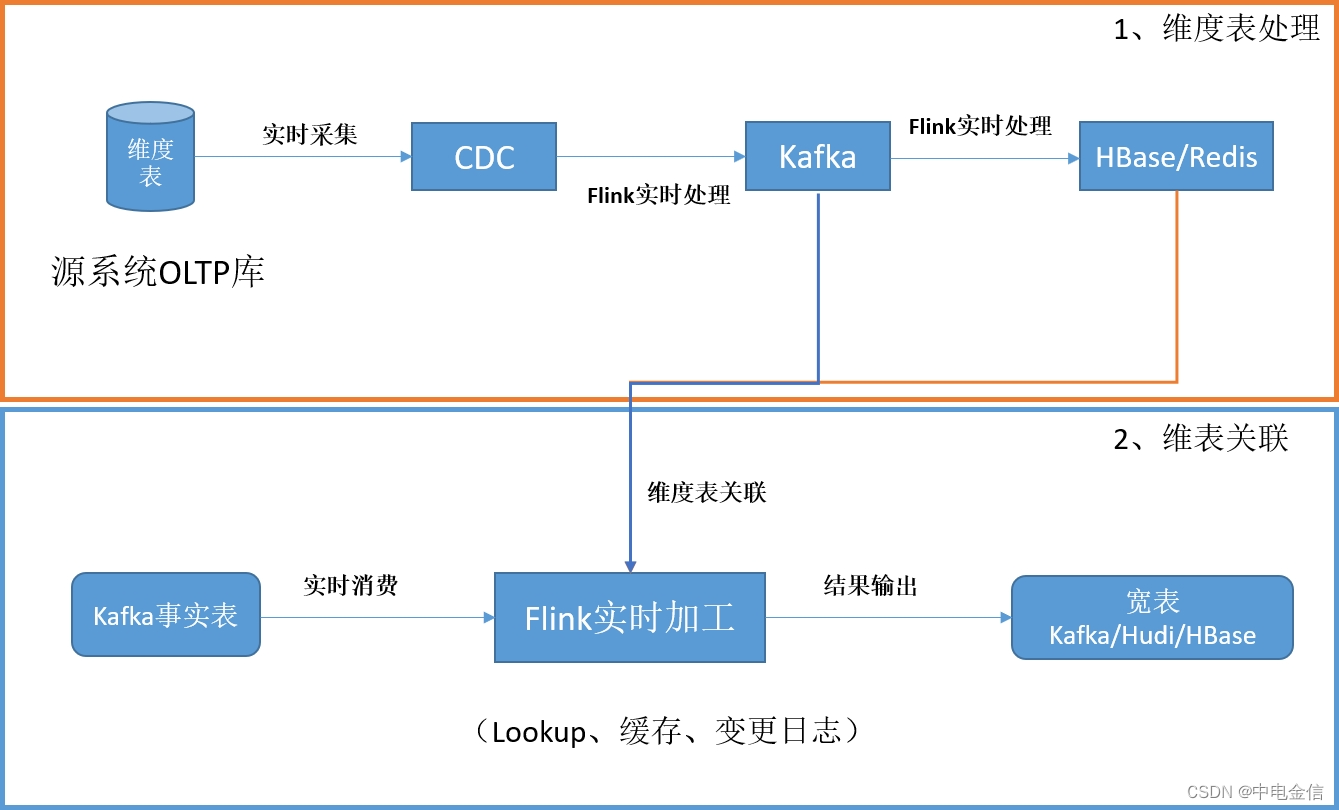
在典型的实时系统中,维表数据一般来源于源系统的OLTP数据库中,采用CDC技术将维表数据实时采集到Kafka或其他消息队列,最后保存到HBase、Hudi、Redis等组件中供数据分析使用。一个比较常见的架构图如下:
Flink维度表关联有多种方案,包括实时lookup数据库关联、预加载维表关联、广播维度表、Temporal Table Function Join等。每种方案都有各自的特点,需要结合实际情况综合判断,维表关联方案主要考虑的因素有如下几个方面:
■ 实现复杂度:实现维表关联复杂度越低越好
■ 数据库负载:随着事实表数据量增大,数据库吞吐量能否满足,数据库负载能否支撑
■ 维表更新实时性:维表更新后,新的数据能否及时被应用到
■ 内存消耗:是否占用太多内存
■ 横向扩展:随着数据量增大,能否横向扩展
■ 结果确定性:结果的正确性是否能够保证
01 实时lookup数据库关联
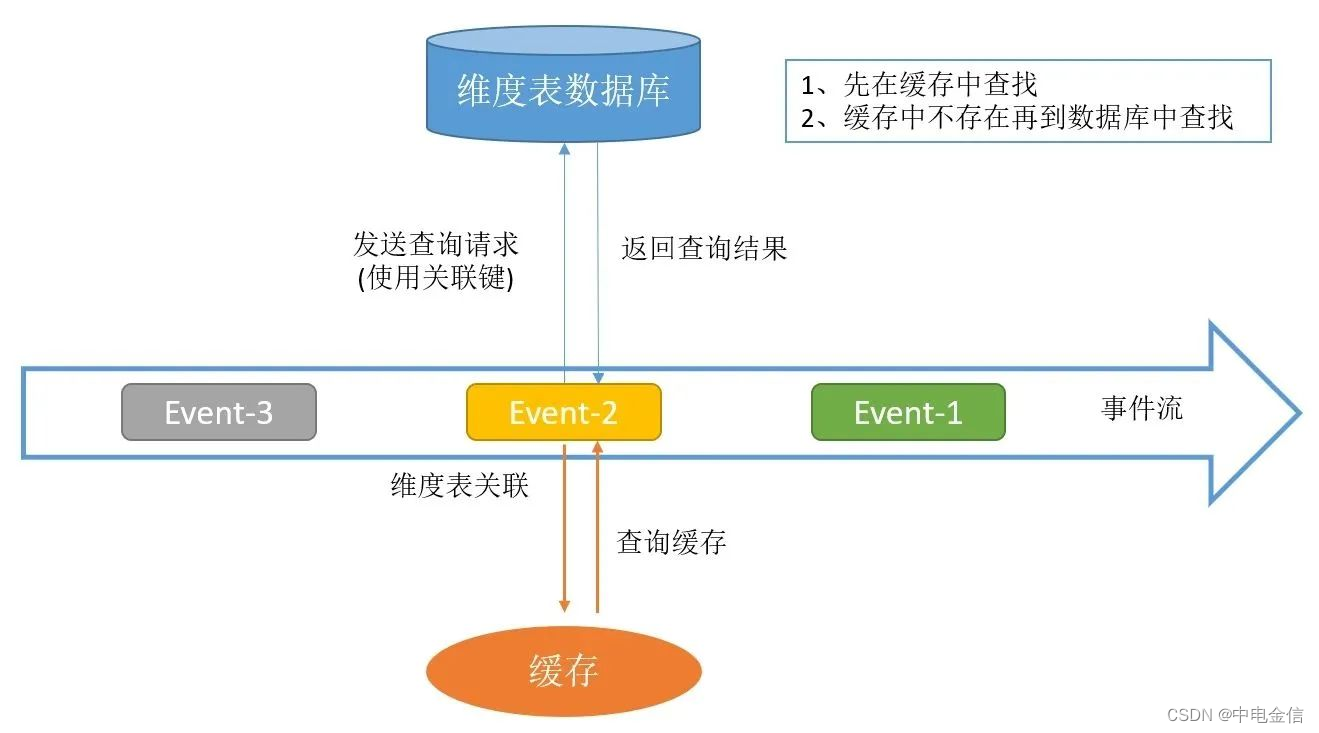
所谓实时lookup数据库关联,就是在用户自定义函数中通过关联字段直接访问数据库实现关联的方式。每条事实表数据都会根据关联键,到存储维度表的数据库中查询一次。

实时lookup数据库关联的特点是实现简单,但数据库压力较大,无法支撑大数据量的维度数据查询,并且在查询时只能根据当时的维度表数据查询,如果事实表数据重放或延迟,查询结果的正确性无法得到保证,且多次查询结果可能不一致。
实时lookup数据库关联还可以再细分为三种方式:同步lookup数据库关联、异步lookup数据库关联和带缓存的数据库lookup关联。
1.1 同步lookup数据库关联
同步实时数据库lookup关联实现最简单,只需要在一个RichMapFunction或者RichFlat-MapFunction中访问数据库,处理好关联逻辑后将结果数据输出即可。上游每输入一条数据就会前往外部表中查询一次,等待返回后输出关联结果。
同步lookup数据库关联的参考代码如下:
创建类并继承RichMapFunction抽象类。
public class HBaseMapJoinFun extends RichMapFunction<Tuple2<String,String>,Tuple3<String,String,String>> {在open方法中实现连接数据库(该数据库存储了维度表信息)。
public void open(Configuration parameters) throws Exception {org.apache.hadoop.conf.Configuration hconf= HBaseConfiguration.create();InputStream hbaseConf = DimSource.class.getClassLoader().getResourceAsStream("hbase-site.xml");InputStream hdfsConf = DimSource.class.getClassLoader().getResourceAsStream("hdfs-site.xml");InputStream coreConf = DimSource.class.getClassLoader().getResourceAsStream("core-site.xml");hconf.addResource(hdfsConf);hconf.addResource(hbaseConf);hconf.addResource(coreConf);if (User.isHBaseSecurityEnabled(hconf)){String userName = "dl_rt";String keyTabFile = "/opt/kerberos/kerberos-keytab/keytab";LoginUtil.setJaasConf(ZOOKEEPER_DEFAULT_LOGIN_CONTEXT_NAME, userName, keyTabFile);}else {LOG.error("conf load error!");}connection = ConnectionFactory.createConnection(hconf);
}在map方法中实现关联操作,并返回结果。
@Override
public Tuple3<String, String, String> map(Tuple2<String, String> stringStringTuple2) throws Exception LOG.info("Search hbase data by key .");String row_key = stringStringTuple2.f1;String p_name = stringStringTuple2.f0;byte[] familyName = Bytes.toBytes("cf");byte[] qualifier = Bytes.toBytes("city_name");byte[] rowKey = Bytes.toBytes(row_key);table = connection.getTable(TableName.valueOf(table_name));Get get = new Get(rowKey);get.addColumn(familyName,qualifier);Result result = table.get(get);for (Cell cell : result.rawCells()){LOG.info("{}:{}:{}",Bytes.toString(CellUtil.cloneRow(cell)),Bytes.toString(CellUtil.cloneFamily(cell)),Bytes.toString(CellUtil.cloneQualifier(cell)),Bytes.toString(CellUtil.cloneValue(cell)));}String cityName = Bytes.toString(result.getValue(Bytes.toBytes("cf"),Bytes.toBytes("city_name")));return new Tuple3<String, String, String>(row_key,p_name,cityName);
}在主类中调用。
//关联维度表
SingleOutputStreamOperator<Tuple3<String,String,String>> resultStream = dataSource.map(new HBaseMapJoinFun());
resultStream.print().setParallelism(1);1.2 异步lookup数据库关联
异步实时数据库lookup关联需要借助AsyncIO来异步访问维表数据。AsyncIO可以充分利用数据库提供的异步Client库并发处理lookup请求,提高Task并行实例的吞吐量。
相较于同步lookup,异步方式可大大提高数据库查询的吞吐量,但相应的也会加大数据库的负载,并且由于查询只能查当前时间点的维度数据,因此可能造成数据查询结果的不准确。

AsyncIO提供lookup结果的有序和无序输出,由用户自己选择是否保证event的顺序。
示例代码参考如下:
创建Join类并继承RichAsyncFunction抽象类。
public class HBaseAyncJoinFun extends RichAsyncFunction<Tuple2<String,String>, Tuple3<String,String,String>> {在open方法中实现连接数据库(存储了维度表的信息)。
public void open(Configuration parameters) throws Exception {org.apache.hadoop.conf.Configuration hconf= HBaseConfiguration.create();InputStream hbaseConf = DimSource.class.getClassLoader().getResourceAsStream("hbase-site.xml");InputStream hdfsConf = DimSource.class.getClassLoader().getResourceAsStream("hdfs-site.xml");InputStream coreConf = DimSource.class.getClassLoader().getResourceAsStream("core-site.xml");hconf.addResource(hdfsConf);hconf.addResource(hbaseConf);hconf.addResource(coreConf);if (User.isHBaseSecurityEnabled(hconf)){String userName = "dl_rt";String keyTabFile = "/opt/kerberos/kerberos-keytab/keytab";LoginUtil.setJaasConf(ZOOKEEPER_DEFAULT_LOGIN_CONTEXT_NAME, userName, keyTabFile);}else {LOG.error("conf load error!");}final ExecutorService threadPool = Executors.newFixedThreadPool(2,new ExecutorThreadFactory("hbase-aysnc-lookup-worker", Threads.LOGGING_EXCEPTION_HANDLER));try{connection = ConnectionFactory.createAsyncConnection(hconf).get();table=connection.getTable(TableName.valueOf(table_name),threadPool);}catch (InterruptedException | ExecutionException e){LOG.error("Exception while creating connection to HBase.",e);throw new RuntimeException("Cannot create connection to HBase.",e);}在AsyncInvoke方法中实现异步关联,并返回结果。
@Override
public void asyncInvoke(Tuple2<String, String> input, ResultFuture<Tuple3<String, String, String>> resultFuture) throws Exception {LOG.info("Search hbase data by key .");String row_key = input.f1;String p_name = input.f0;byte[] familyName = Bytes.toBytes("cf");byte[] qualifier = Bytes.toBytes("city_name");byte[] rowKey = Bytes.toBytes(row_key);Get get = new Get(rowKey);get.addColumn(familyName,qualifier);CompletableFuture<Result> responseFuture = table.get(get);responseFuture.whenCompleteAsync((result, throwable) -> {if (throwable != null){if (throwable instanceof TableNotFoundException){LOG.error("Table '{}' not found", table_name,throwable);resultFuture.completeExceptionally(new RuntimeException("HBase table '"+table_name+"' not found.",throwable));}else {LOG.error(String.format("HBase asyncLookup error,retry times = %d",1),throwable);responseFuture.completeExceptionally(throwable);}}else{List list = new ArrayList<Tuple3<String, String, String>>();if (result.isEmpty()){String cityName="";list.add(new Tuple3<String,String,String>(row_key,p_name,cityName));resultFuture.complete(list);}else{String cityName = Bytes.toString(result.getValue(Bytes.toBytes("cf"),Bytes.toBytes("city_name")));list.add(new Tuple3<String,String,String>(row_key,p_name,cityName));resultFuture.complete(list);}}});}在主方法中调用。
//异步关联维度表
DataStream<Tuple3<String,String,String>> unorderedResult = AsyncDataStream.unorderedWait(dataSource, new HBaseAyncJoinFun(),5000L, TimeUnit.MILLISECONDS,2).setParallelism(2);
unorderedResult.print();此处使用unorderedWait方式,允许返回结果存在乱序。
1.3 带缓存的数据库lookup关联
带缓存的数据库lookup关联是对上述两种方式的优化,通过增加缓存机制来降低查询数据库的请求数量,而且缓存不需要通过 Checkpoint 机制持久化,可以采用本地缓存,例如Guava Cache可以比较轻松的实现。
此种方式的问题在于缓存的数据无法及时更新,可能会造成关联数据不正确的问题。
02 预加载维表关联
预加载维表关联是在作业启动时就把维表全部加载到内存中,因此此种方式只适用于维度表数据量不大的场景。相较于lookup方式,预加载维表可以获得更好的性能。
预加载维表关联还可以再细分为四种方式:启动时预加载维表、启动时预加载分区维表、启动时预加载维表并定时刷新和启动时预加载维表并实时lookup数据库。
预加载维表的各种细分方案可根据实际应用场景进行结合应用,以此来满足不同的场景需求。
2.1 启动时预加载维表
启动时预加载维表实现比较简单,作业初始化时,在用户函数的open方法中读取数据库的维表数据放到内存中,且缓存的维表数据不作为State,每次重启时open方法都被再次执行,从而加载新的维表数据。
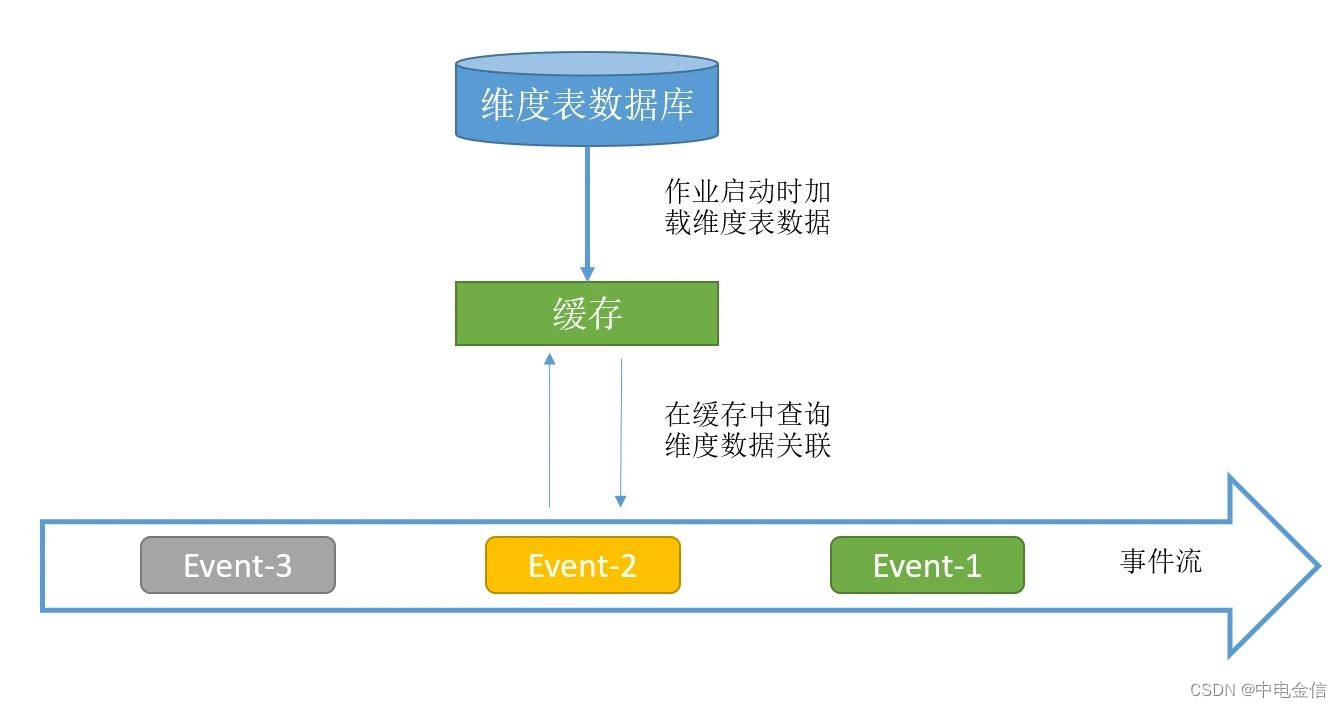
此方法需要占用内存来存储维度表数据,不支持大数据量的维度表,且维度表加载入内存后不能实时更新,因此只适用于对维度表更新要求不高且数据量小的场景。
2.2 启动时预加载分区维表
对于维表比较大的情况,可以在启动预加载维表基础之上增加分区功能。简单来说就是将数据流按字段进行分区,然后每个Subtask只需要加在对应分区范围的维表数据。此种方式一定要自定义分区,不要用KeyBy。

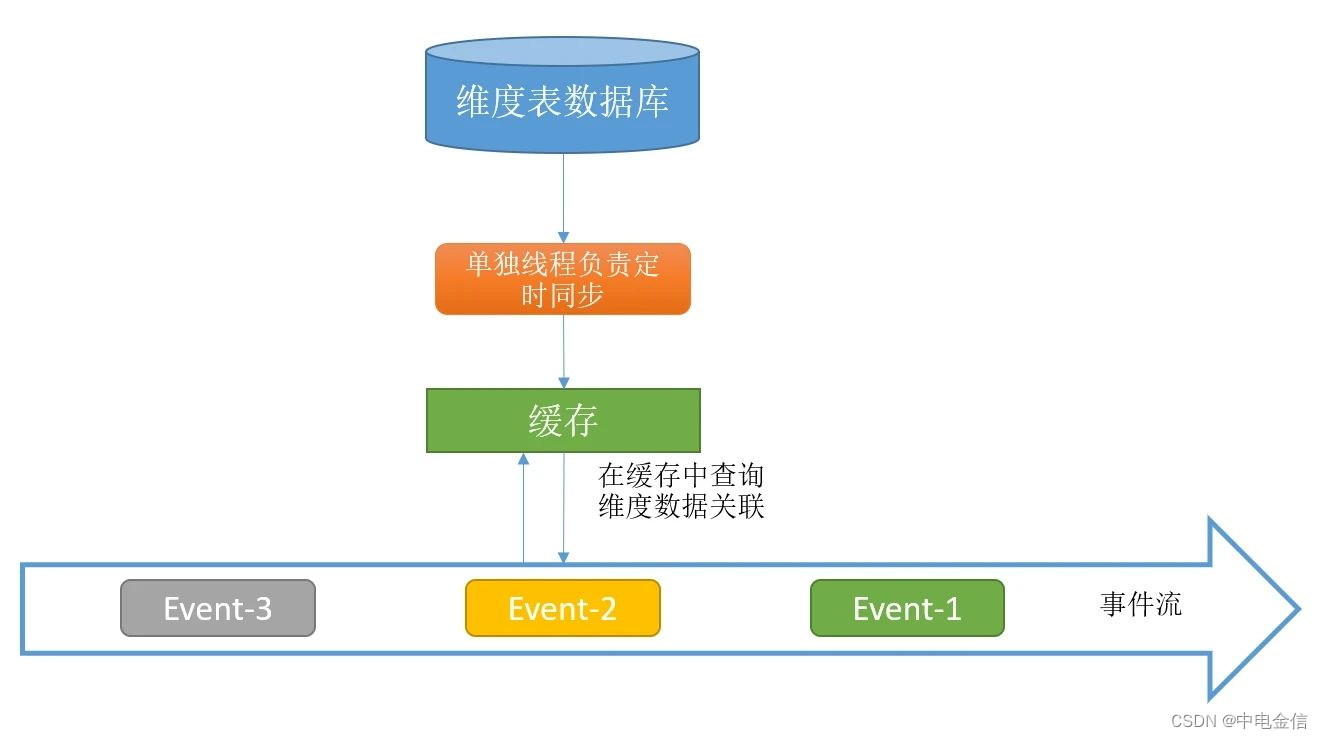
2.3 启动时预加载维表并定时刷新
预加载维度数据只有在Job启动时才会加载维度表数据,这会导致维度数据变更无法被识别,在open方法中初始化一个额外的线程来定时更新内存中的维度表数据,可以一定程度上缓解维度表更新问题,但无法彻底解决。
示例代码参考如下:
public class ProLoadDimMap extends RichMapFunction<Tuple2<String,Integer>,Tuple2<String,String>> {private static final Logger LOG = LoggerFactory.getLogger(ProLoadDimMap.class.getName());ScheduledExecutorService executor = null;private Map<String,String> cache;@Overridepublic void open(Configuration parameters) throws Exception {executor.scheduleAtFixedRate(new Runnable() {@Overridepublic void run() {try {load();} catch (Exception e) {e.printStackTrace();}}},5,5, TimeUnit.MINUTES);//每隔 5 分钟拉取一次维表数据}@Overridepublic void close() throws Exception {}@Overridepublic Tuple2<String, String> map(Tuple2<String, Integer> stringIntegerTuple2) throws Exception {String username = stringIntegerTuple2.f0;Integer city_id = stringIntegerTuple2.f1;String cityName = cache.get(city_id.toString());return new Tuple2<String,String>(username,cityName);}public void load() throws Exception {Class.forName("com.mysql.jdbc.Driver");Connection con = DriverManager.getConnection("jdbc:mysql://172.XX.XX.XX:XX06/yumd?useSSL=false&characterEncoding=UTF-8", "root", "Root@123");PreparedStatement statement = con.prepareStatement("select city_id,city_name from city_dim;");ResultSet rs = statement.executeQuery();//全量更新维度数据到内存while (rs.next()) {String cityId = rs.getString("city_id");String cityName = rs.getString("city_name");cache.put(cityId, cityName);}con.close();}
}2.4 启动时预加载维表并实时lookup数据库
此种方案就是将启动预加载维表和实时look两种方式混合使用,将预加载的维表作为缓存给实时lookup使用,未命中则到数据库里查找。该方案可解决关联不上的问题。
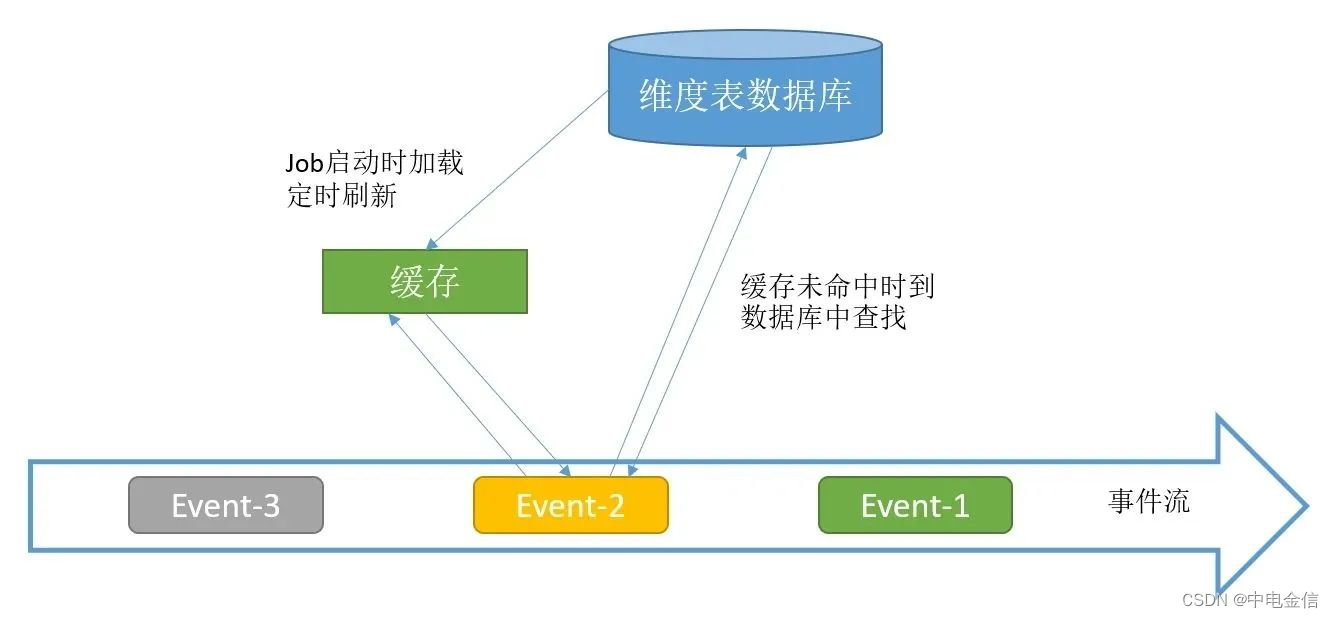
03 广播维度表
广播维度表方案是将维度表数据用流的方式接入Flink Job 程序,并将维度表数据进行广播,再与事件流数据进行关联,此种方式可以及时获取维度表的数据变更,但因数据保存在内存中,因此支持的维度表数据量较小。
示例代码参考如下:
首先将维度表进行广播。
//维度数据源
DataStream<Tuple2<Integer,String>> dimSource = env.addSource(new DimSource1());// 生成MapStateDescriptor
MapStateDescriptor<Integer,String> dimState = new MapStateDescriptor<Integer, String>("dimState",BasicTypeInfo.INT_TYPE_INFO,BasicTypeInfo.STRING_TYPE_INFO);
BroadcastStream<Tuple2<Integer,String>> broadcastStream = dimSource.broadcast(dimState);实现BroadcastProcessFunction类的processElement方法处理事实流与广播流的关联,并返回关联结果。
SingleOutputStreamOperator<String> output = dataSource.connect(broadcastStream).process(new BroadcastProcessFunction<Tuple2<String, Integer>, Tuple2<Integer, String>, String>() {@Overridepublic void processElement(Tuple2<String, Integer> input, ReadOnlyContext readOnlyContext, Collector<String> collector) throws Exception {ReadOnlyBroadcastState<Integer,String> state = readOnlyContext.getBroadcastState(dimState);String name = input.f0;Integer city_id = input.f1;String city_name="NULL";if (state.contains(city_id)){city_name=state.get(city_id);collector.collect("result is : "+name+" ,"+city_id+" ,"+city_name);}}实现BroadcastProcessFunction类的processBroadcastElement方法处理广播流数据,将新的维度表数据进行广播。
@Override
public void processBroadcastElement(Tuple2<Integer, String> input, Context context, Collector<String> collector) throws Exception {LOG.info("收到广播数据:"+input);context.getBroadcastState(dimState).put(input.f0,input.f1);
}04 Temporal Table Function Join
Temporal Table Function Join仅支持在Flink SQL API中使用,需要将维度表数据作为流的方式传入Flink Job。该种方案可支持大数据量的维度表,且维度表更新及时,关联数据准确性更高,缺点是会占用状态后端和内存的资源,同时自行实现的代码复杂度过高。
Temporal Table是持续变化表上某一时刻的视图,Temporal Table Function是一个表函数,传递一个时间参数,返回Temporal Table这一指定时刻的视图。可以将维度数据流映射为Temporal Table,主流与这个Temporal Table进行关联,可以关联到某一个版本(历史上某一个时刻)的维度数据。
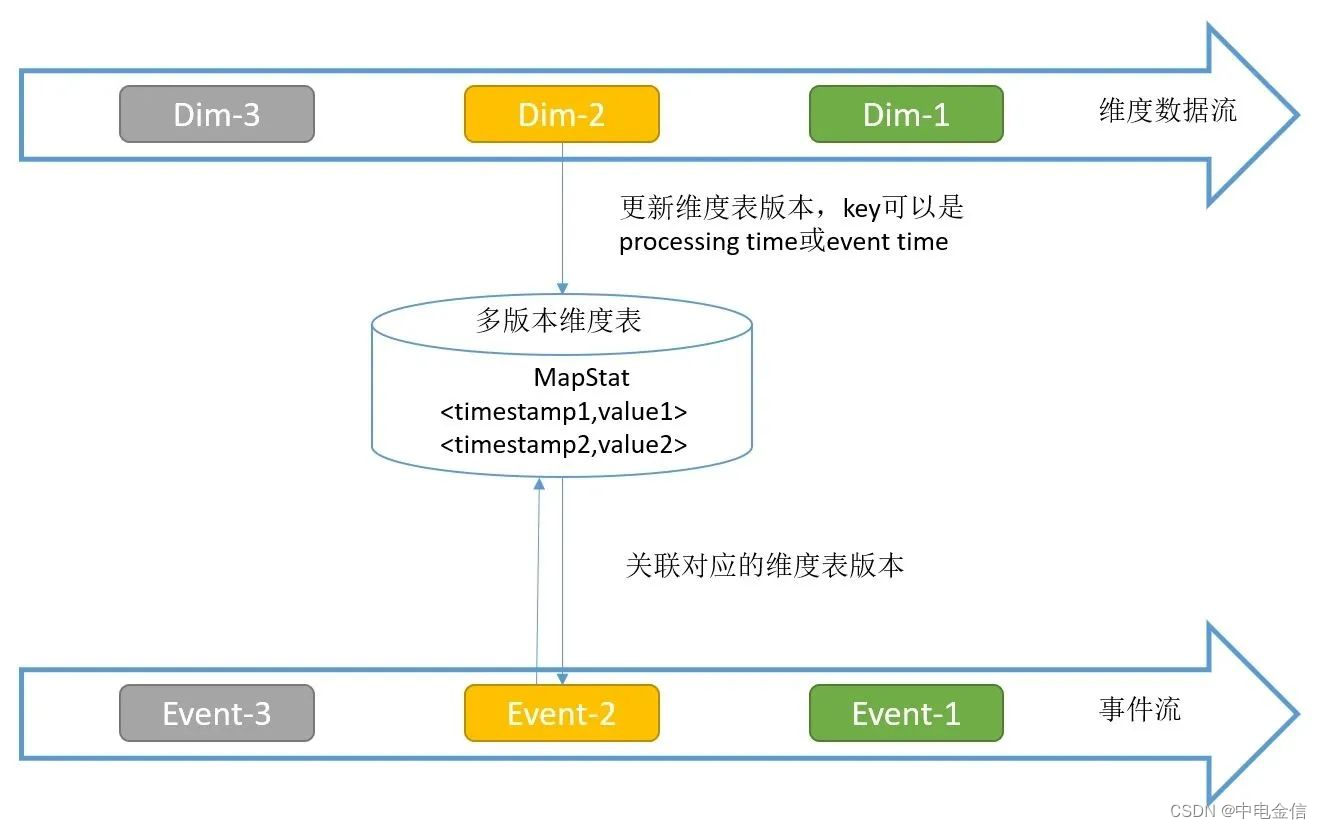
示例代码参考如下:
public class TemporalFunTest {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);EnvironmentSettings bsSettings = EnvironmentSettings.newInstance().inStreamingMode().build();StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, bsSettings);env.setParallelism(1);//定义主流DataStream<Tuple3<String,Integer,Long>> dataSource = env.addSource(new EventSource2()).assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<Tuple3<String,Integer,Long>>(Time.seconds(0)){@Overridepublic long extractTimestamp(Tuple3<String, Integer, Long> stringIntegerLongTuple3) {return stringIntegerLongTuple3.f2;}});//定义维度流DataStream<Tuple3<Integer, String, Long>> cityStream = env.addSource(new DimSource()).assignTimestampsAndWatermarks(//指定水位线、时间戳new BoundedOutOfOrdernessTimestampExtractor<Tuple3<Integer, String, Long>>(Time.seconds(0)) {@Overridepublic long extractTimestamp(Tuple3<Integer, String, Long> element) {return element.f2;}});//主流,用户流, 格式为:user_name、city_id、tsTable userTable = tableEnv.fromDataStream(dataSource,"user_name,city_id,ts.rowtime");//定义城市维度流,格式为:city_id、city_name、tsTable cityTable = tableEnv.fromDataStream(cityStream,"city_id,city_name,ts.rowtime");tableEnv.createTemporaryView("userTable", userTable);tableEnv.createTemporaryView("cityTable", cityTable);//定义一个TemporalTableFunctionTemporalTableFunction dimCity = cityTable.createTemporalTableFunction("ts", "city_id");//注册表函数tableEnv.registerFunction("dimCity", dimCity);Table u = tableEnv.sqlQuery("select * from userTable");u.printSchema();tableEnv.toAppendStream(u, Row.class).print("user streaming receive : ");Table c = tableEnv.sqlQuery("select * from cityTable");c.printSchema();tableEnv.toAppendStream(c, Row.class).print("city streaming receive : ");//关联查询Table result = tableEnv.sqlQuery("select u.user_name,u.city_id,d.city_name,u.ts " +"from userTable as u " +", Lateral table (dimCity(u.ts)) d " +"where u.city_id=d.city_id");//打印输出DataStream resultDs = tableEnv.toAppendStream(result, Row.class);resultDs.print("\t\t join result out:");env.execute("joinDemo");}
}最后,总结各种维度表关联方案的特点如下: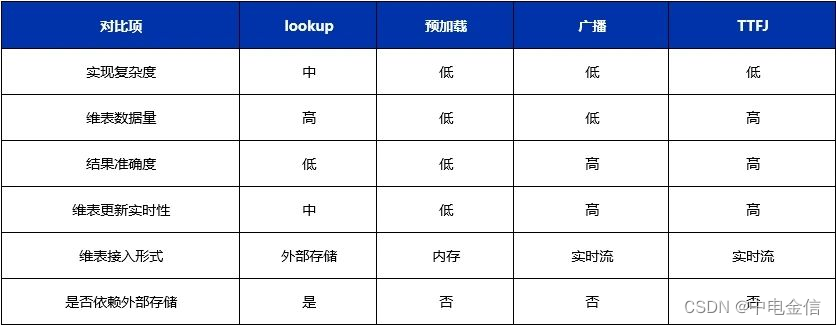
相关文章:
中电金信:技术实践|Flink维度表关联方案解析
导语:Flink是一个对有界和无界数据流进行状态计算的分布式处理引擎和框架,主要用来处理流式数据。它既可以处理有界的批量数据集,也可以处理无界的实时流数据,为批处理和流处理提供了统一编程模型。 维度表可以看作是用户来分析数…...

HQL 55 题【持续更新】
前言 今天开始为期一个多月的 HQL 练习,共 55 道 HQL 题,大概每天两道,从初级函数到中级函数。这次的练习不再是基础的 join 那种通用 SQL 语法了,而是引入了更多 Hive 的函数(单行函数、窗口函数等)。 我…...

lqb省赛日志[8/37]-[搜索·DFS·BFS]
一只小蒟蒻备考蓝桥杯的日志 文章目录 笔记DFS记忆化搜索 刷题心得小结 笔记 DFS 参考 深度优先搜索(DFS) 总结(算法剪枝优化总结) DFS的模板框架: function dfs(当前状态){if(当前状态 目的状态){}for(寻找新状态){if(状态合法){vis[访问该点];dfs(新状态);?…...
uni app 钓鱼小游戏
最近姑娘喜欢玩那个餐厅游戏里的钓鱼 ,经常让看广告,然后就点点点... 自己写个吧。小鱼的图片自己搞。 有问题自己改,不要私信我 <template><view class"page_main"><view class"top_linear"><v…...
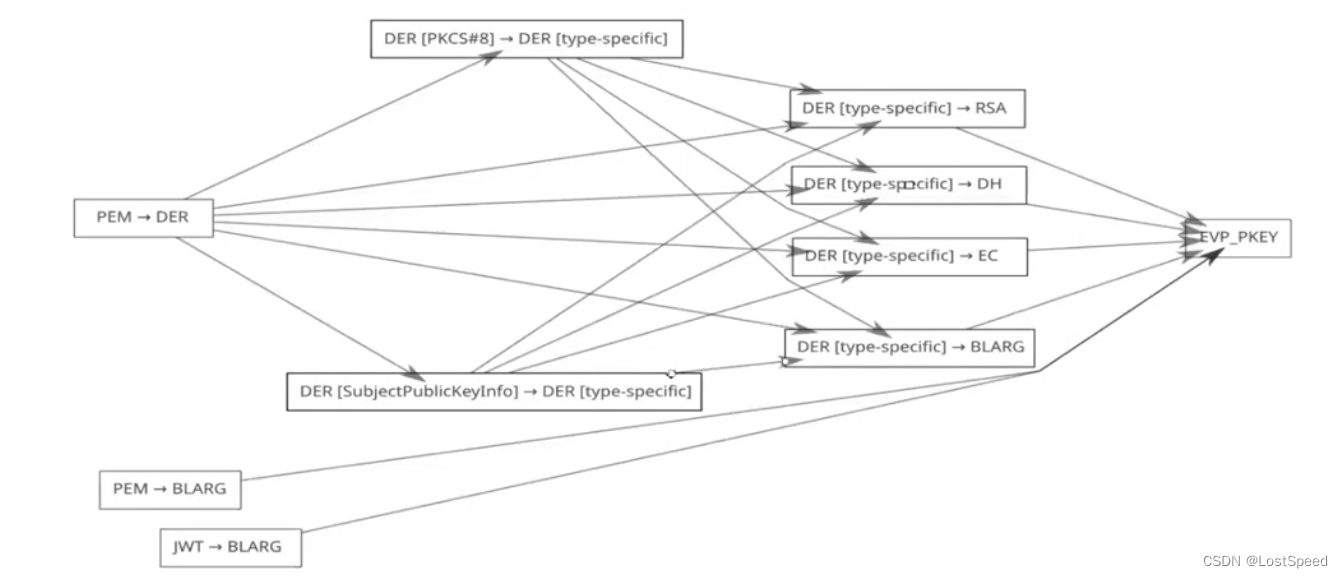
openssl3.2 - note - Decoders and Encoders with OpenSSL
文章目录 openssl3.2 - note - Decoders and Encoders with OpenSSL概述笔记编码器/解码器的调用链OSSL_STORE 编码器/解码器的名称和属性OSSL_FUNC_decoder_freectx_fnOSSL_FUNC_encoder_encode_fn官方文档END openssl3.2 - note - Decoders and Encoders with OpenSSL 概述 …...

分享几个 Selenium 自动化常用操作
最近工作会用到selenium来自动化操作一些重复的工作,那么在用selenium写代码的过程中,又顺手整理了一些常用的操作,分享给大家。 常用元素定位方法 虽然有关selenium定位元素的方法有很多种,但是对于没有深入学习,尤…...
 的常见操作)
【Python】【数据类型】List (列表) 的常见操作
1. 创建 使用内置函数list()将字符串创建为列表 list1 [a, b, c, d] print(list1 , list1) # list1 [a, b, c, d] list1 list(abcd) print(list1) # [a, b, c, d]使用列表推导式创建列表 list1 [x for x in range(1, 10)] print(list1) # [1, 2, 3, 4, 5, 6, 7, 8, 9]多…...

【C语言】病人信息管理系统
本设计实现了一个病人信息管理系统,通过链表数据结构来存储和操作病人的信息。用户可以通过菜单选择录入病人信息、查找病人信息、修改病人信息、删除病人信息、查看所有病人信息和查看专家信息等操作,还可以根据病人的科室、姓名、性别和联系方式进行查找,以及支持修改病人…...

Java Spring Boot 接收时间格式的参数
报错 JSON parse error: Cannot deserialize value of type java.time.LocalDateTime from String “2024-03-14 12:30:00”: Failed to deserialize java.time.LocalDateTime: (java.time.format.DateTimeParseException) Text ‘2024-03-14 12:30:00’ could not be parsed a…...
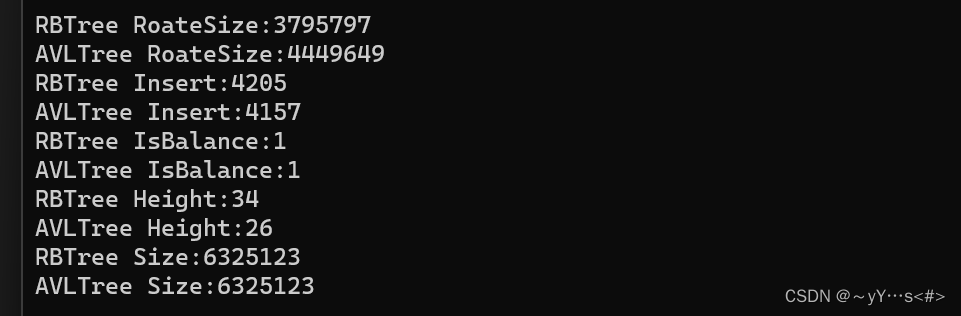
【C++】实现红黑树
目录 一、认识红黑树1.1 概念1.2 定义 二、实现红黑树2.1 插入2.2 与AVL树对比 一、认识红黑树 1.1 概念 红黑树是一个二叉搜索树,与AVL树相比,红黑树不再使用平衡因子来控制树的左右子树高度差,而是用颜色来控制平衡,颜色为红色…...
)
爬虫(六)
复习回顾: 01.浏览器一个网页的加载全过程1. 服务器端渲染html的内容和数据在服务器进行融合.在浏览器端看到的页面源代码中. 有你需要的数据2. 客户端(浏览器)渲染html的内容和数据进行融合是发生在你的浏览器上的.这个过程一般通过脚本来完成(javascript)我们通过浏览器可以…...

最长连续序列 - LeetCode 热题 3
大家好!我是曾续缘💝 今天是《LeetCode 热题 100》系列 发车第 3 天 哈希第 3 题 ❤️点赞 👍 收藏 ⭐再看,养成习惯 最长连续序列 给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素…...
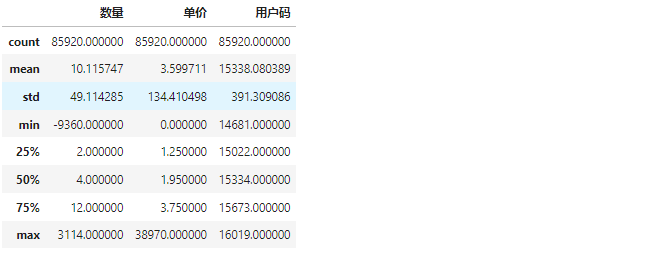
运营模型—RFM 模型
运营模型—RFM 模型 RFM 是什么其实我们前面的文章介绍过,这里我们不再赘述,可以参考运营数据分析模型—用户分层分析,今天我们要做的事情是如何落地RFM 模型 我们的数据如下,现在我们就开始进行数据处理 数据预处理 因为数据预处理没有一个固定的套路,都是根据数据的实…...
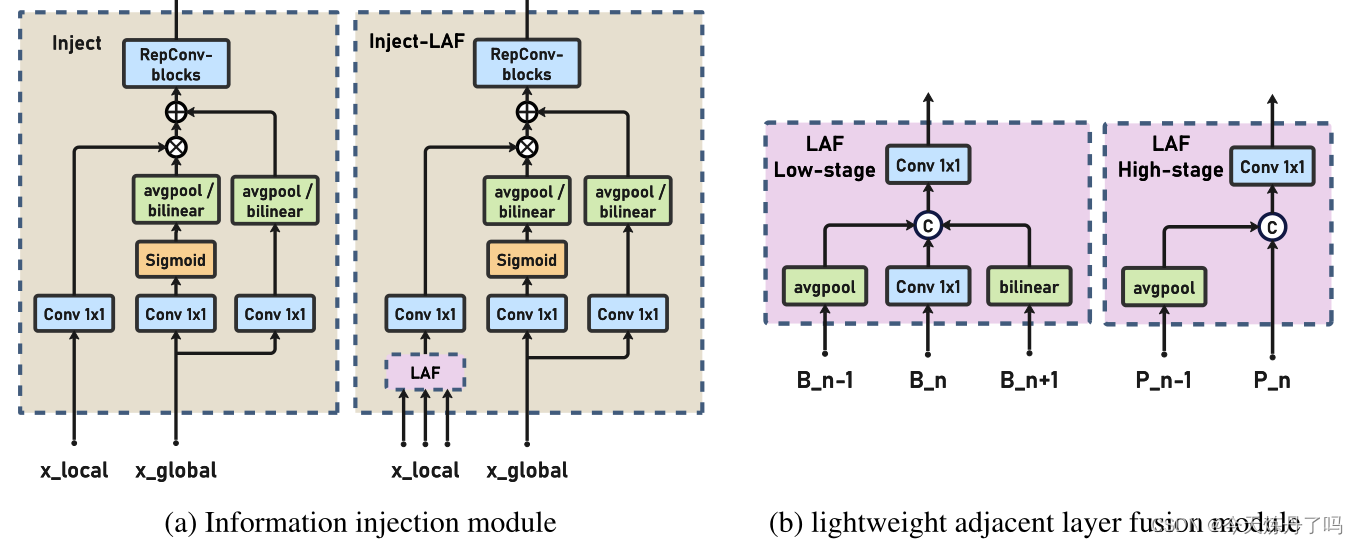
YOLOv9|加入2023Gold YOLO中的GD机制!遥遥领先!
专栏介绍:YOLOv9改进系列 | 包含深度学习最新创新,助力高效涨点!!! 一、Gold YOLO摘要 在过去的几年里,YOLO系列模型已经成为实时目标检测领域的领先方法。许多研究通过修改体系结构、增加数据和设计新的损…...
WRF模型运行教程(ububtu系统)--III.运行WRF模型(官网案例)
零、创建DATA目录 # 1.创建一个DATA目录用于存放数据(一般为fnl数据,放在Build_WRF目录下)。 mkdir DATA # 2.进入 DATA cd DATA 一、WPS预处理 在模拟之前先确定模拟域(即模拟范围),并进行数据预处理(…...
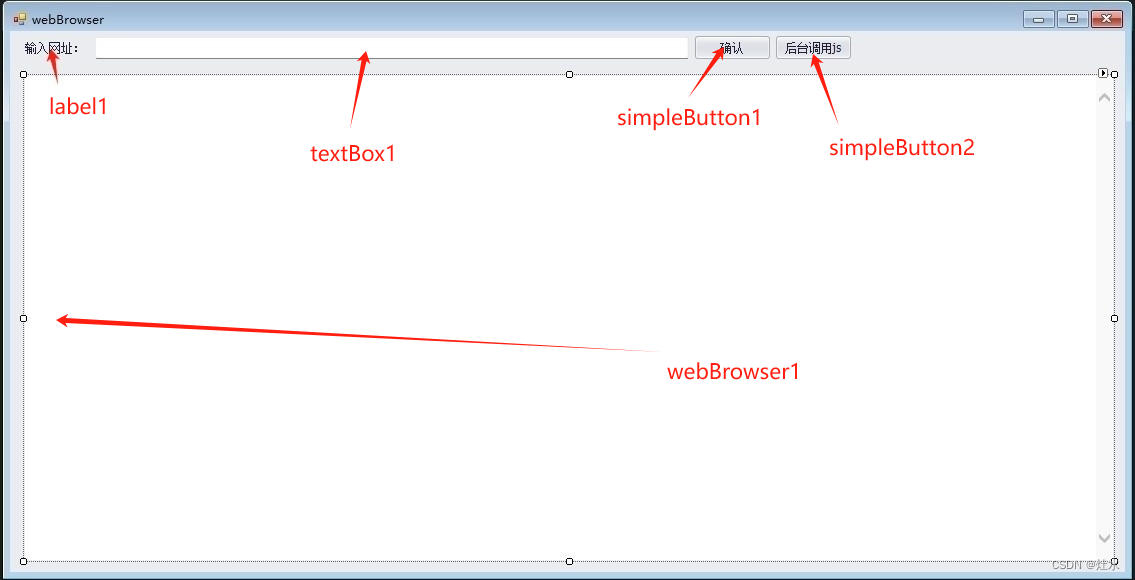
html和winform webBrowser控件交互并播放视频(包含转码)
1、 为了使网页能够与winform交互 将com的可访问性设置为真 [System.Security.Permissions.PermissionSet(System.Security.Permissions.SecurityAction.Demand, Name "FullTrust")][System.Runtime.InteropServices.ComVisibleAttribute(true)] 2、在webBrow…...
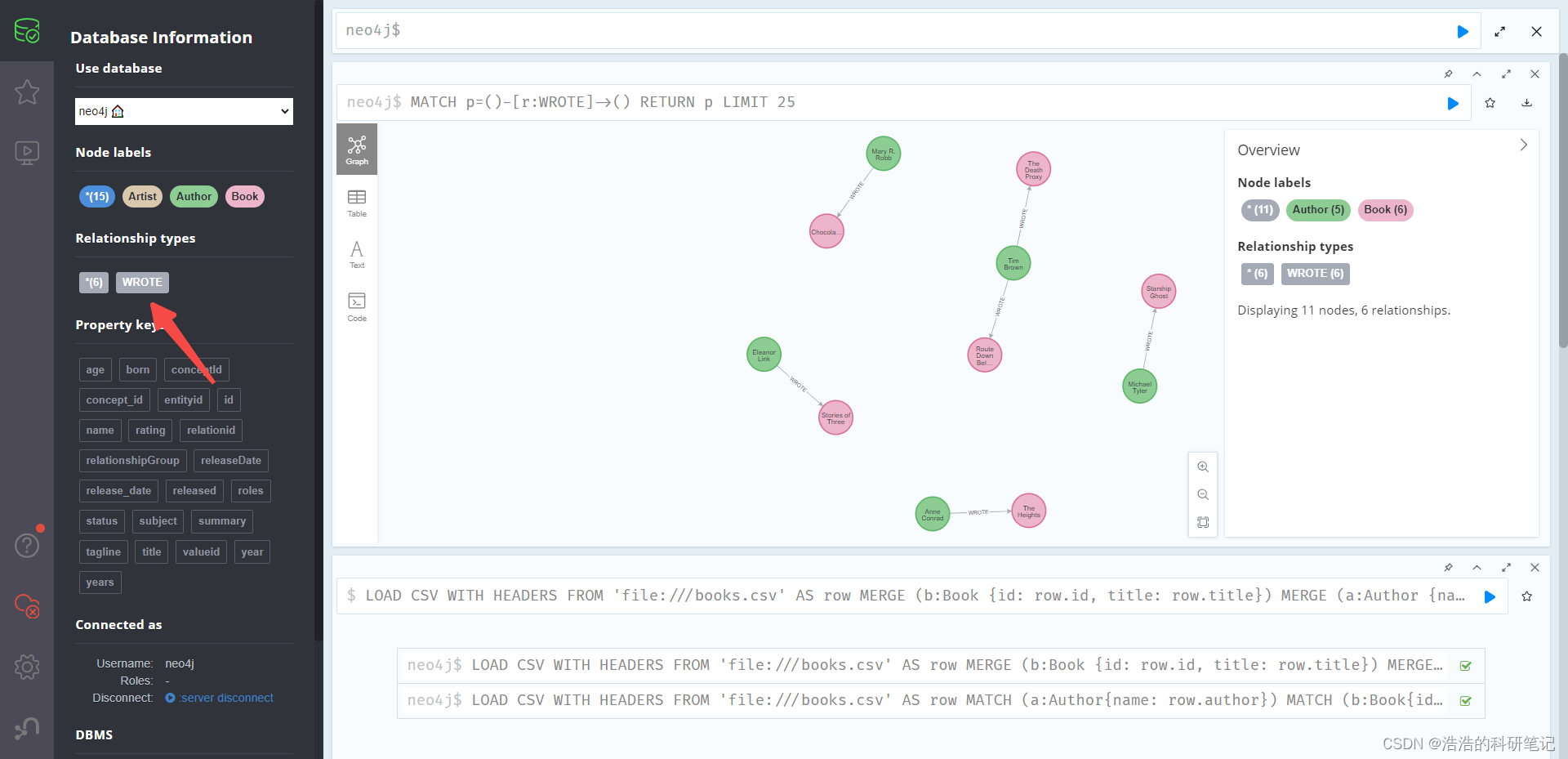
Neo4j 批量导入数据 从官方文档学习LOAD CSV 命令 小白可食用版
学习LOAD CSV🚀 在使用Neo4j进行大量数据导入的时候,发现如果用代码自动一行一行的导入效率过低,因此明白了为什么需要用到批量导入功能,在Neo4j中允许批量导入CSV文件格式,刚开始从网上的中看了各种半残的博客或者视频…...
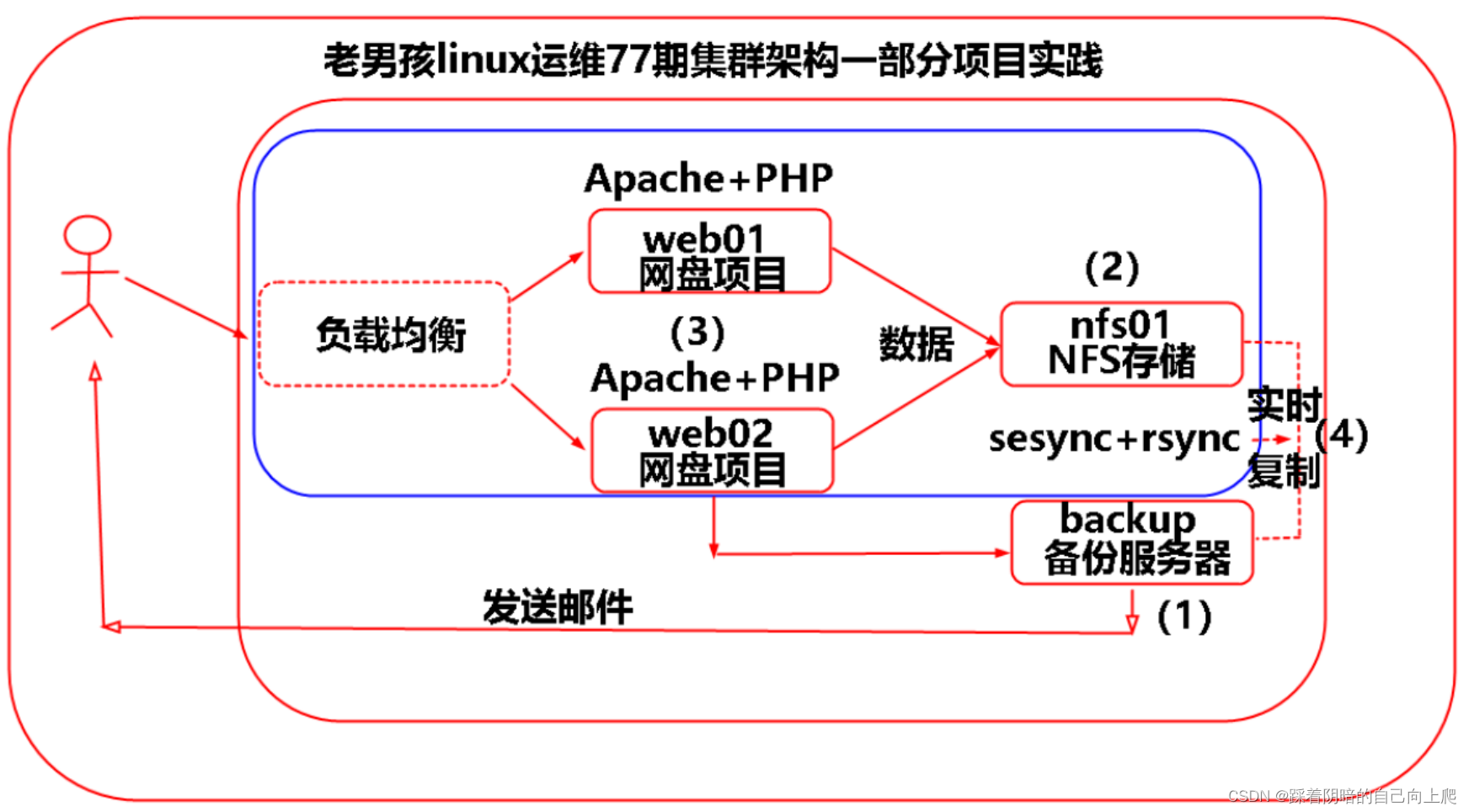
Day43-2-企业级实时复制intofy介绍及实践
Day43-2-企业级实时复制intofy介绍及实践 1. 企业级备份方案介绍1.1 利用定时方式,实现周期备份重要数据信息。1.2 实时数据备份方案1.3 实时复制环境准备1.4 实时复制软件介绍1.5 实时复制inotify机制介绍1.6 项目部署实施1.6.1 部署环境准备1.6.2 检查Linux系统支…...

2024年AI辅助研发趋势深度解析:科技革新与效率提升的双重奏
随着人工智能技术的迅猛发展,AI辅助研发正逐渐成为科技界和工业界的热门话题。特别是在2024年,这一趋势将更加明显,AI辅助研发将在各个领域展现出强大的潜力和应用价值。 首先,AI辅助研发将进一步提升研发效率。传统的研发模式往…...

bash: mysqldump: command not found
问题:在linux上执行mysql备份的时候,出现此异常 mysqldump命令找不到 解决: 1、找到mysql目录(找到mysql可执行命令目录) which mysql 有图可知,mysql安装在: /usr1/local/java/mysql 2、my…...

Python基础语法:访问器@property和修改器@xxx.setter
一、简介 访问器和修改器也是装饰器的一种。 property: 访问器,getter xxx.setter: 修改器,setter 访问器和修改器的根本目的是想将属性私有化,提供getter&setter去访问。 访问器和修改器能够做到访问属性其实在调用getter方法࿰…...

Kerberos身份认证原理与企业级排错实战指南
1. 这不是“另一个登录框”,而是一套精密运转的身份验证齿轮系统很多人第一次听说 Kerberos,是在公司内网登录邮箱或访问内部系统时,看到那个带小盾牌图标的弹窗——“正在使用 Kerberos 协议进行身份验证”。于是下意识觉得:“哦…...

三十岁想从零转行现实吗?带你分辨真正有前景的好工作
我是29岁那年,完成从转行裸辞副业的职业转型。 如果你把职业生涯看成是从现在开始30岁,到你退休那年,中间这么漫长的30年,那么30岁转行完全来得及…...

基于可解释机器学习的城市人口流动空间降尺度分析实践
1. 项目概述:从宏观到微观,解码城市脉搏在城市的肌理中,人口的流动如同血液的循环,承载着经济活力、社会互动与空间结构的全部信息。无论是城市规划师优化公交线路,还是商业分析师评估店铺选址,亦或是公共卫…...

解密高校教师必会的Gemini 3.1 Pro五大科研隐藏技能:从论文评估到创新点锁定
各位同仁好,我是七哥。一个在高校里从事人工智能相关领域研究,钻研用大模型AI实操的学术人。可以和七哥交流学术写作或Gemini、GPT、Claude等大模型学术实操相关问题,多多交流,相互成就,共同进步。 科研路上,有人发完顶刊顺利晋升,有人还在为创新点抓耳挠腮。 大多数教…...

基于雷达与光敏传感器的低功耗智能窗防设备设计与实现
1. 项目概述:一个基于雷达与光敏的智能窗防设备几年前,我因为一次短暂的出差,家里空置了几天,回来后就一直琢磨着怎么给家里的窗户加点“动静”。市面上的智能安防摄像头固然好,但要么需要复杂的布线,要么云…...

Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南
Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南 【免费下载链接】atomic-layout Build declarative, responsive layouts in React using CSS Grid. 项目地址: https://gitcode.com/gh_mirrors/at/atomic-layout Atomic Layout…...

什么情况下会核销贷款
贷款核销的核心前提是:贷款被认定为 “损失类” 且经 “穷尽追偿” 仍无法收回,银行按监管与会计规则从账面冲销,但债权不消灭、仍可追偿。一、核心认定条件(满足其一即可)破产 / 注销 / 吊销:借款人和担保…...

Linux 负载均衡的 cache_nice_tries:缓存友好的迁移尝试
简介现如今服务器、嵌入式设备、工控主板普遍采用多核、NUMA 架构 CPU,多进程多线程并发运行模式成为常态。Linux 内核依靠调度域分层负载均衡机制,分散 CPU 运行压力,避免单核心负载过高、其余核心空闲浪费硬件算力。但任务跨核心迁移是一把…...

修复 PowerShell 7 下 conda activate 报错的指南
修复 PowerShell 7 下 conda activate 报错的指南 适用场景:升级到 PowerShell 7.x 后,conda activate 突然报错,但 Windows PowerShell 5.1 正常。 发布日期:2026-05-24 适用版本:conda 23.x PowerShell 7.x 一、问题…...