HQL 55 题【持续更新】
前言
今天开始为期一个多月的 HQL 练习,共 55 道 HQL 题,大概每天两道,从初级函数到中级函数。这次的练习不再是基础的 join 那种通用 SQL 语法了,而是引入了更多 Hive 的函数(单行函数、窗口函数等)。
我会把 HQL 中函数和语法的一些注意事项写在每一题下面的 "知识点" 中,方便上课复习。同样这博客估计没人看,如果谁实在需要建表语句给我留言就行。
3-10
1、查询累积销量排名第二的商品(中级)
SELECT sku_id from(SELECT sku_id,rank() OVER(ORDER BY order_sum desc) rkfrom(SELECT sku_id,sum(sku_num) order_sumFROM order_detailGROUP BY sku_idORDER BY order_sum descLIMIT 2)as t1)as t2
WHERE rk=2;知识点:
- SQL 中 distinct 必须跟在 select 之后
- distinct 不能单独用于选择性地仅对结果集中的某个字段去重,而不影响其他字段
select distinct sku_id, sku_num,rk from(...
);
-- 尽管查询结果中 sku_id 字段的值可能重复,但是不能通 select distinct 来对单个属性去重
sku_id sku_num rk
1 2 1
1 3 2
- Hive 的子查询必须要有别名 !
3-12
1、筛选2021年总销量小于100的商品(初级)
- 需求:从订单明细表(order_detail)中筛选出2021年总销量小于100的商品及其销量,假设今天的日期是2022-01-10,不考虑上架时间小于一个月的商品。
- 思路:拿 2021 年总销量小于100的商品id和上架时间大于30的商品id进行join
| order_detail_id | order_id | sku_id | create_date | price | sku_num |
|---|---|---|---|---|---|
| 1 | 1 | 1 | 2021-09-27 | 2000.00 | 2 |
| 2 | 1 | 3 | 2021-09-27 | 5000.00 | 5 |
| 3 | 2 | 4 | 2021-09-28 | 6000.00 | 9 |
| 4 | 2 | 5 | 2021-09-28 | 500.00 | 33 |
2.1、查询出2021年总销量小于 100 的商品
-- 1.1 2021年销售总量小于100的商品
select sku_id, sum(sku_num) order_sum
from order_detail
where year(create_date)=2021
group by sku_id
having order_sum<100;2.2、查询出上架时间大于30天的商品
-- 1.2 上架时间小于 30 天的商品
select sku_id,name from sku_info
where datediff('2022-01-10',from_date)>30;2.3、join
-- join 两个子表
select t1.sku_id,name from (select sku_id, sum(sku_num) order_sumfrom order_detailwhere year(create_date)=2021group by sku_idhaving order_sum<100)t1 join (select sku_id,name from sku_infowhere datediff('2022-01-10',from_date)>30)t2 on t1.sku_id = t2.sku_id;知识点:
- datediff('2022-01-10','2021-01-10') = 365,注意:日期1必须大于日期2否则结果是负数
2、查询每日新增用户(初级)
| uer_id | ip_address | login_ts | logout_ts |
|---|---|---|---|
| 101 | 180.149.130.161 | 2021-09-21 08:00:00 | 2021-09-27 08:30:00 |
| 101 | 180.149.130.161 | 2021-09-27 08:00:00 | 2021-09-27 08:30:00 |
| 101 | 180.149.130.161 | 2021-09-28 09:00:00 | 2021-09-28 09:10:00 |
| 101 | 180.149.130.161 | 2021-09-29 13:30:00 | 2021-09-29 13:50:00 |
思路1:每天有多少人是首日登录就有多少新增用户。查询出每个用户的首日登录时间,然后按照日期分组聚合就得到了每日新增用户。而不是去考虑开窗(我是这么想的)
思路2:开窗也可以实现,用 row_numer 对每个用户的登录时间进行排名(group by user_id),然后根据登录时间进行分区将该天 row_number=1 的值(说明是首次登录)进行聚合。
思路1
2.1、查询用户首日登录日期
-- 查询用户首次登录的日期
select user_id,min(date_format(login_ts,'yyyy-MM-dd')) first_login_date
from user_login_detail
group by user_id;2.2、查询每天有多少用户是首日登录
-- 按照日期分组得到每天的新增用户
select first_login_date,count(*) from(select user_id,min(date_format(login_ts,'yyyy-MM-dd')) first_login_datefrom user_login_detailgroup by user_id)t1
group by first_login_date;注意:怎么把 login_ts (格式:2021-09-21 08:00:00)这种时间字符串指定的字段取出来?
我是这么实现的:
select concat_ws('-',string(year(date_format(login_ts,'yyyy-MM-dd HH:mm:ss'))),string(month(date_format(login_ts,'yyyy-MM-dd HH:mm:ss'))),string(day(date_format(login_ts,'yyyy-MM-dd HH:mm:ss')))),
标准:
select date_format(login_ts,'yyyy-MM-dd') from user_login_detail;思路2
select dt,sum(`if`(rk=1,1,0)) new_user_nums from(select user_id,date_format(login_ts,'yyyy-MM-dd') dt,row_number() over (partition by user_id order by login_ts) rkfrom user_login_detail)t1
group by dt
having new_user_nums>0;3、用户注册、登录、下单综合统计(初级)
需求:从用户登录明细表(user_login_detail)和订单信息表(order_info)中查询每个用户的注册日期(首次登录日期)、总登录次数,以及2021年的登录次数、订单数和订单总额。
思路:无脑 join 没有什么难度
order_info:
| 序号 | 编号 | 日期 | 金额 |
|---|---|---|---|
| 1 | 101 | 2021-09-27 | 29000.00 |
| 2 | 101 | 2021-09-28 | 70500.00 |
| 3 | 101 | 2021-09-29 | 43300.00 |
| 4 | 101 | 2021-09-30 | 860.00 |
user_login_detail:
3.1、用户首日登录日期
-- 用户首日登录日期
select user_id,min(date_format(login_ts,'yyyy-MM-dd')) register_date
from user_login_detail
group by user_id;注意:能 group by 就 group by 不然 join 之后报错。
3.2、用户累积登录次数
-- 用户累积登录次数
select user_id,size(collect_set(date_format(login_ts,'yyyy-MM-dd'))) total_login_count
from user_login_detail
group by user_id;知识点: 利用 collect_set() 把登录日期收集到一个集合里,正好做了去重,就不用担心用户一天登录多次的情况了。
3.3、用户2021年登录次数
-- 用户2021登录次数
select user_id,size(collect_set(date_format(login_ts,'yyyy-MM-dd'))) login_count_2021
from user_login_detail
where year(date_format(login_ts,'yyyy-MM-dd'))=2021
group by user_id;3.4、用户2021年下单次数和下单金额
-- 用户2021年下单次数和下单金额
select user_id,count(order_id) order_count_2021,sum(total_amount) order_amount_2021
from order_info
where year(create_date)=2021
group by user_id,year(create_date);3.5、join起来
select t1.user_id,register_date,total_login_count,login_count_2021,order_count_2021,order_amount_2021 from(select user_id,min(date_format(login_ts,'yyyy-MM-dd')) register_date from user_login_detail group by user_id)t1 join (select user_id,size(collect_set(date_format(login_ts,'yyyy-MM-dd'))) total_login_countfrom user_login_detailgroup by user_id)t2 on t1.user_id=t2.user_id
join (select user_id,size(collect_set(date_format(login_ts,'yyyy-MM-dd'))) login_count_2021
from user_login_detail
where year(date_format(login_ts,'yyyy-MM-dd'))=2021
group by user_id)t3 on t1.user_id=t3.user_id
join (select user_id,count(order_id) order_count_2021,sum(total_amount) order_amount_2021from order_infowhere year(create_date)=2021group by user_id,year(create_date))t4 on t1.user_id=t4.user_id;3.13
1、向用户推荐朋友收藏的商品
需求:请向所有用户推荐其朋友收藏但是自己未收藏的商品,从好友关系表(friendship_info)和收藏表(favor_info)中查询出应向哪位用户推荐哪些商品。
firendship_info:
| user1_id | user2_id |
|---|---|
| 101 | 1010 |
| 101 | 108 |
| 101 | 106 |
| 101 | 104 |
favor_info:
| user_id | sku_id | create_date |
|---|---|---|
| 101 | 3 | 2021-09-23 |
| 101 | 12 | 2021-09-23 |
| 101 | 6 | 2021-09-25 |
| 101 | 10 | 2021-09-21 |
思路:
- 核心就是 left join ,因为 left join 可以把保留左表的内容(这里我们保留的是好友的商品收藏表),我们只要根据用户喜欢的商品id和好友喜欢的商品id进行 left join ,得到的字段"sku_id"如果不为 null 就说明这件商品他俩都收藏了,如果为 null 就说明这件商品好友收藏了,但是用户没有收藏。
1.1、获取用户所有好友
-- 查询所有用户的好友
select user1_id user_id,user2_id friend_id from friendship_info
union
select user2_id,user1_id from friendship_info;
知识点:
- join 是横向合并,会形成宽表;而 union 是纵向合并,形成长表(union 会对结果进行排序去重,union all 不会)
1.2、得到用户好友的收藏列表
-- join得到用户好友收藏的商品select user1_id user_id,user2_id friend_id from friendship_infounionselect user2_id,user1_id from friendship_infojoin favor_info firend_favoron user2_id=firend_favor.user_id;1.3、left join 过滤
select distinct t1.user_id,firend_favor.sku_id
from (select user1_id user_id,user2_id friend_id from friendship_infounionselect user2_id,user1_id from friendship_info
)t1join favor_info firend_favoron t1.friend_id=firend_favor.user_idleft join favor_info user_favoron t1.user_id=user_favor.user_id and firend_favor.sku_id=user_favor.sku_idwhere user_favor.sku_id is null;2、男性和女性每日的购物总金额统计(初级)
需求:从订单信息表(order_info)和用户信息表(user_info)中,分别统计每天男性和女性用户的订单总金额,如果当天男性或者女性没有购物,则统计结果为0。
order_info:
user_info:
| 编号 | 性别 | 出生日期 |
|---|---|---|
| 101 | 男 | 1990-01-01 |
| 102 | 女 | 1991-02-01 |
| 103 | 女 | 1992-03-01 |
| 104 | 男 | 1993-04-01 |
思路1
1、获取不同性别的消费信息
select t2.gender,t1.create_date,t1.total_amount
from order_info t1
join user_info t2 on t1.user_id=t2.user_id我们没有必要查询用户的 id 信息,只需要性别(后面我们需要根据性别过滤)、创建订单的日期(后面我们需要根据日期分组)和订单总额(我们需要根据不同性别统计每天的订单总额)即可。
2、按照日期 join 不同性别的每天销售总额
select coalesce(t3.create_date,t4.create_date),`if`(t3.total_amount_male is null,0,t3.total_amount_male),`if`(t4.total_amount_female is null ,0,t4.total_amount_female) from(select create_date,sum(total_amount) total_amount_male from(select t2.gender,t1.create_date,t1.total_amountfrom order_info t1join user_info t2 on t1.user_id=t2.user_id)t1where gender='男'group by create_date)t3 full join (select create_date,sum(total_amount) total_amount_female from(select t2.gender,t1.create_date,t1.total_amountfrom order_info t1join user_info t2 on t1.user_id=t2.user_id)t2where gender='女'group by create_date)t4 on t3.create_date=t4.create_date知识点:
- 显然 t3 和 t4 这两个子表分别是男性和女性的每天购物总额,这里我们进行的是 full join 这样会保留两张表的所有数据,因为数据中存在某 一天男生购物了但是女生没有,或者女士购物了男性没有。
- 对于最后查询结果的日期字段就需要保证这个日期不能为 null,但是我们又不能显示 t3 t4 两个日期,所以我们使用了 coalesce 字段来获取非 null 的日期字段(前后顺序并不影响)
- COALESCE 函数用于返回多个表达式中的第一个非NULL值。
思路2
思路1是我自己实现的一种方式,思路2是答案,不得不说还是这种写法高级:
select create_date,cast(sum(`if`(gender='男',total_amount,0)) as decimal(16,2)) total_amount_male,cast(sum(`if`(gender='女',total_amount,0)) as decimal(16,2)) total_amount_female
from order_info oi
join user_info ui on oi.user_id=ui.user_id
group by create_date;知识点:
-
cast(expr as <type>):将expr的执行结果转换为<type>类型的数据并返回,expr可以是函数(可以嵌套)、字段或字面值。转换失败返回null,对于cast(expr as boolean),对任意的非空字符串expr返回true
-
decimal(精度,标度):比如 decimal(16,2)表示一个十进制数,其中16是总的数字数量(精度),而2是小数点后的数字数量(标度)
相关文章:

HQL 55 题【持续更新】
前言 今天开始为期一个多月的 HQL 练习,共 55 道 HQL 题,大概每天两道,从初级函数到中级函数。这次的练习不再是基础的 join 那种通用 SQL 语法了,而是引入了更多 Hive 的函数(单行函数、窗口函数等)。 我…...

lqb省赛日志[8/37]-[搜索·DFS·BFS]
一只小蒟蒻备考蓝桥杯的日志 文章目录 笔记DFS记忆化搜索 刷题心得小结 笔记 DFS 参考 深度优先搜索(DFS) 总结(算法剪枝优化总结) DFS的模板框架: function dfs(当前状态){if(当前状态 目的状态){}for(寻找新状态){if(状态合法){vis[访问该点];dfs(新状态);?…...
uni app 钓鱼小游戏
最近姑娘喜欢玩那个餐厅游戏里的钓鱼 ,经常让看广告,然后就点点点... 自己写个吧。小鱼的图片自己搞。 有问题自己改,不要私信我 <template><view class"page_main"><view class"top_linear"><v…...
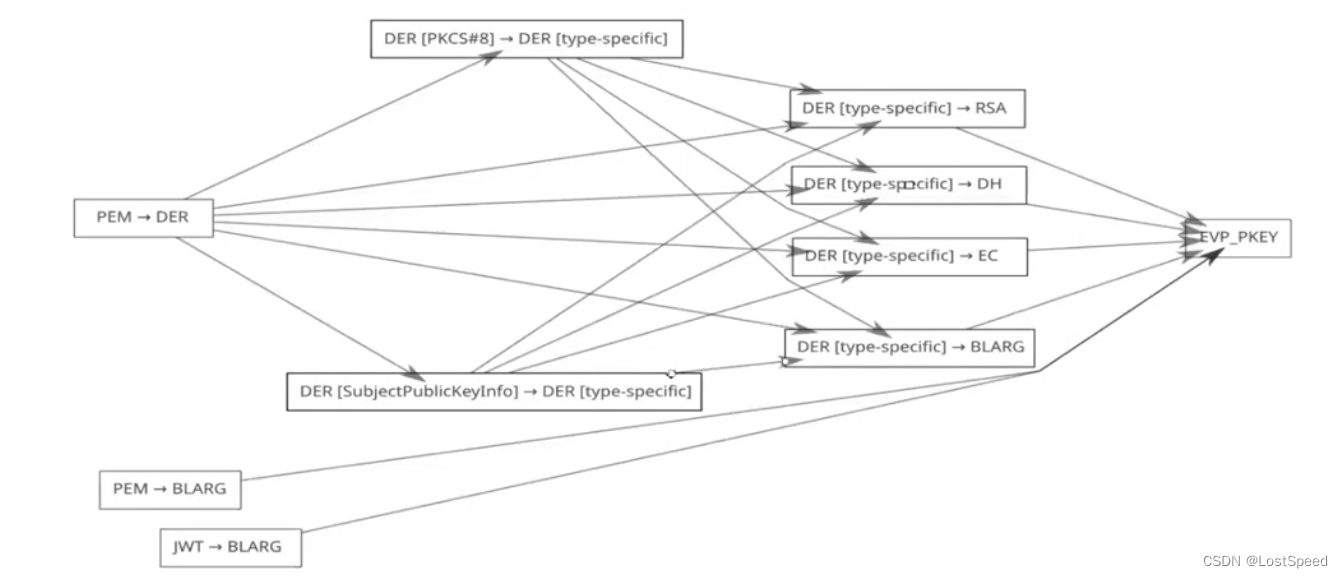
openssl3.2 - note - Decoders and Encoders with OpenSSL
文章目录 openssl3.2 - note - Decoders and Encoders with OpenSSL概述笔记编码器/解码器的调用链OSSL_STORE 编码器/解码器的名称和属性OSSL_FUNC_decoder_freectx_fnOSSL_FUNC_encoder_encode_fn官方文档END openssl3.2 - note - Decoders and Encoders with OpenSSL 概述 …...

分享几个 Selenium 自动化常用操作
最近工作会用到selenium来自动化操作一些重复的工作,那么在用selenium写代码的过程中,又顺手整理了一些常用的操作,分享给大家。 常用元素定位方法 虽然有关selenium定位元素的方法有很多种,但是对于没有深入学习,尤…...
 的常见操作)
【Python】【数据类型】List (列表) 的常见操作
1. 创建 使用内置函数list()将字符串创建为列表 list1 [a, b, c, d] print(list1 , list1) # list1 [a, b, c, d] list1 list(abcd) print(list1) # [a, b, c, d]使用列表推导式创建列表 list1 [x for x in range(1, 10)] print(list1) # [1, 2, 3, 4, 5, 6, 7, 8, 9]多…...

【C语言】病人信息管理系统
本设计实现了一个病人信息管理系统,通过链表数据结构来存储和操作病人的信息。用户可以通过菜单选择录入病人信息、查找病人信息、修改病人信息、删除病人信息、查看所有病人信息和查看专家信息等操作,还可以根据病人的科室、姓名、性别和联系方式进行查找,以及支持修改病人…...

Java Spring Boot 接收时间格式的参数
报错 JSON parse error: Cannot deserialize value of type java.time.LocalDateTime from String “2024-03-14 12:30:00”: Failed to deserialize java.time.LocalDateTime: (java.time.format.DateTimeParseException) Text ‘2024-03-14 12:30:00’ could not be parsed a…...
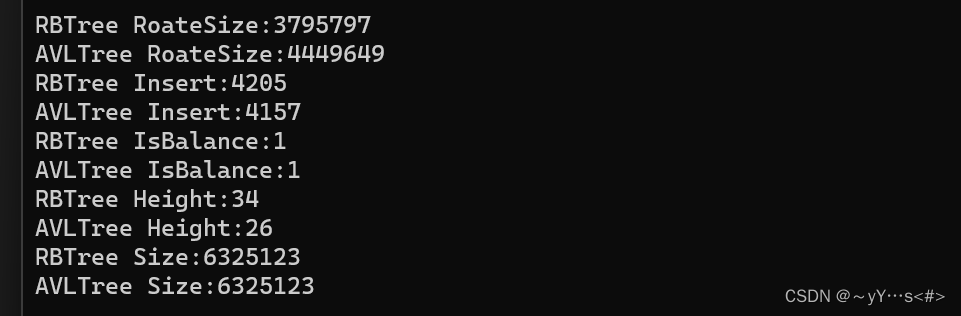
【C++】实现红黑树
目录 一、认识红黑树1.1 概念1.2 定义 二、实现红黑树2.1 插入2.2 与AVL树对比 一、认识红黑树 1.1 概念 红黑树是一个二叉搜索树,与AVL树相比,红黑树不再使用平衡因子来控制树的左右子树高度差,而是用颜色来控制平衡,颜色为红色…...
)
爬虫(六)
复习回顾: 01.浏览器一个网页的加载全过程1. 服务器端渲染html的内容和数据在服务器进行融合.在浏览器端看到的页面源代码中. 有你需要的数据2. 客户端(浏览器)渲染html的内容和数据进行融合是发生在你的浏览器上的.这个过程一般通过脚本来完成(javascript)我们通过浏览器可以…...

最长连续序列 - LeetCode 热题 3
大家好!我是曾续缘💝 今天是《LeetCode 热题 100》系列 发车第 3 天 哈希第 3 题 ❤️点赞 👍 收藏 ⭐再看,养成习惯 最长连续序列 给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素…...
运营模型—RFM 模型
运营模型—RFM 模型 RFM 是什么其实我们前面的文章介绍过,这里我们不再赘述,可以参考运营数据分析模型—用户分层分析,今天我们要做的事情是如何落地RFM 模型 我们的数据如下,现在我们就开始进行数据处理 数据预处理 因为数据预处理没有一个固定的套路,都是根据数据的实…...
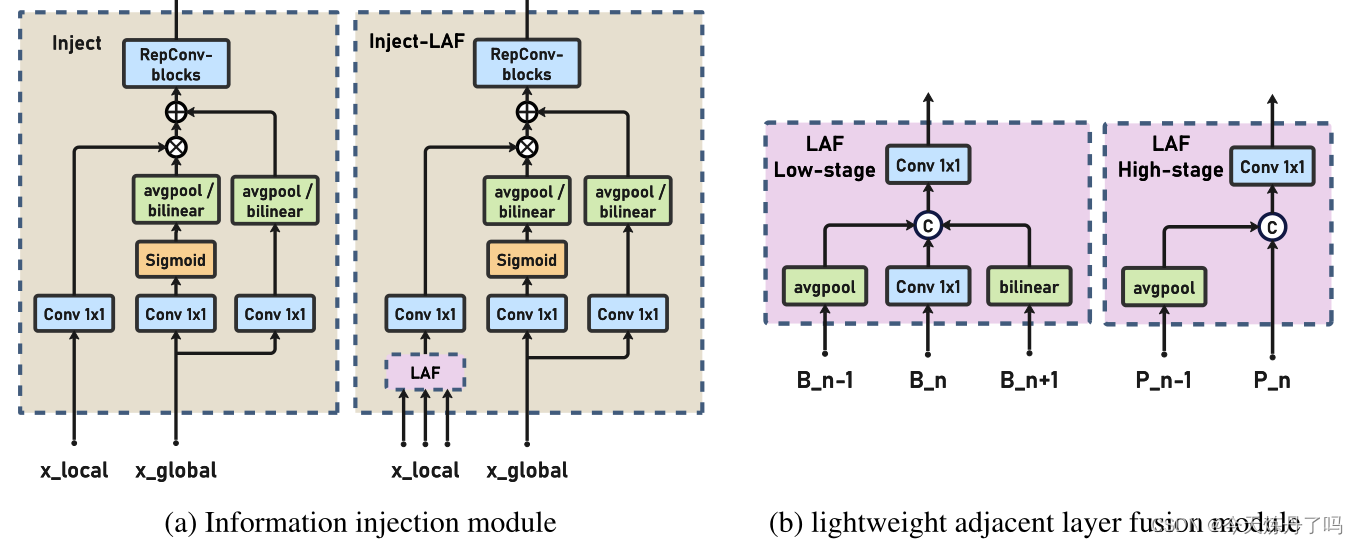
YOLOv9|加入2023Gold YOLO中的GD机制!遥遥领先!
专栏介绍:YOLOv9改进系列 | 包含深度学习最新创新,助力高效涨点!!! 一、Gold YOLO摘要 在过去的几年里,YOLO系列模型已经成为实时目标检测领域的领先方法。许多研究通过修改体系结构、增加数据和设计新的损…...
WRF模型运行教程(ububtu系统)--III.运行WRF模型(官网案例)
零、创建DATA目录 # 1.创建一个DATA目录用于存放数据(一般为fnl数据,放在Build_WRF目录下)。 mkdir DATA # 2.进入 DATA cd DATA 一、WPS预处理 在模拟之前先确定模拟域(即模拟范围),并进行数据预处理(…...
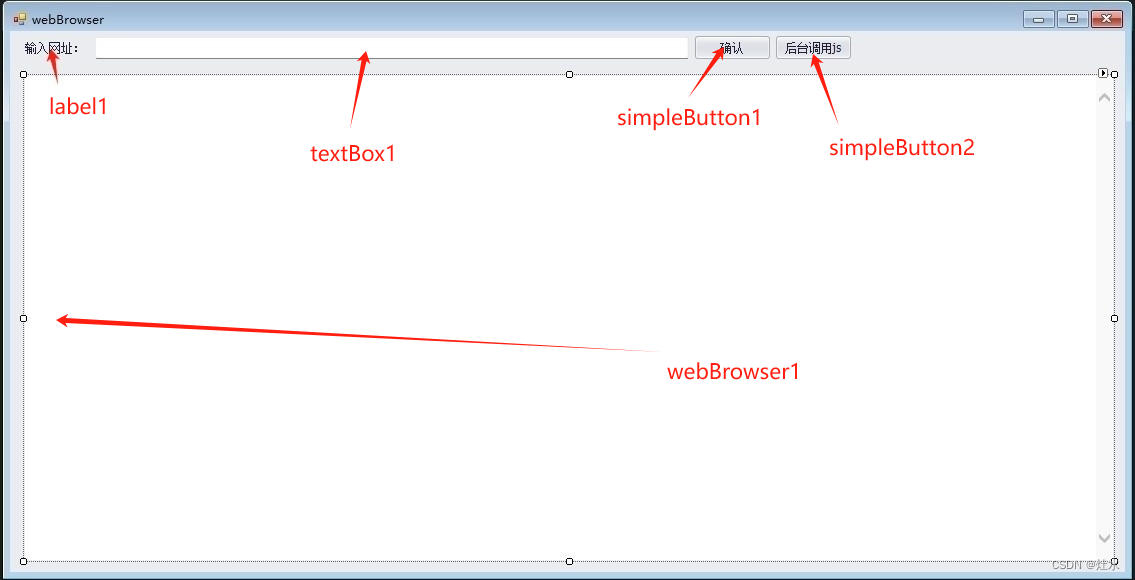
html和winform webBrowser控件交互并播放视频(包含转码)
1、 为了使网页能够与winform交互 将com的可访问性设置为真 [System.Security.Permissions.PermissionSet(System.Security.Permissions.SecurityAction.Demand, Name "FullTrust")][System.Runtime.InteropServices.ComVisibleAttribute(true)] 2、在webBrow…...
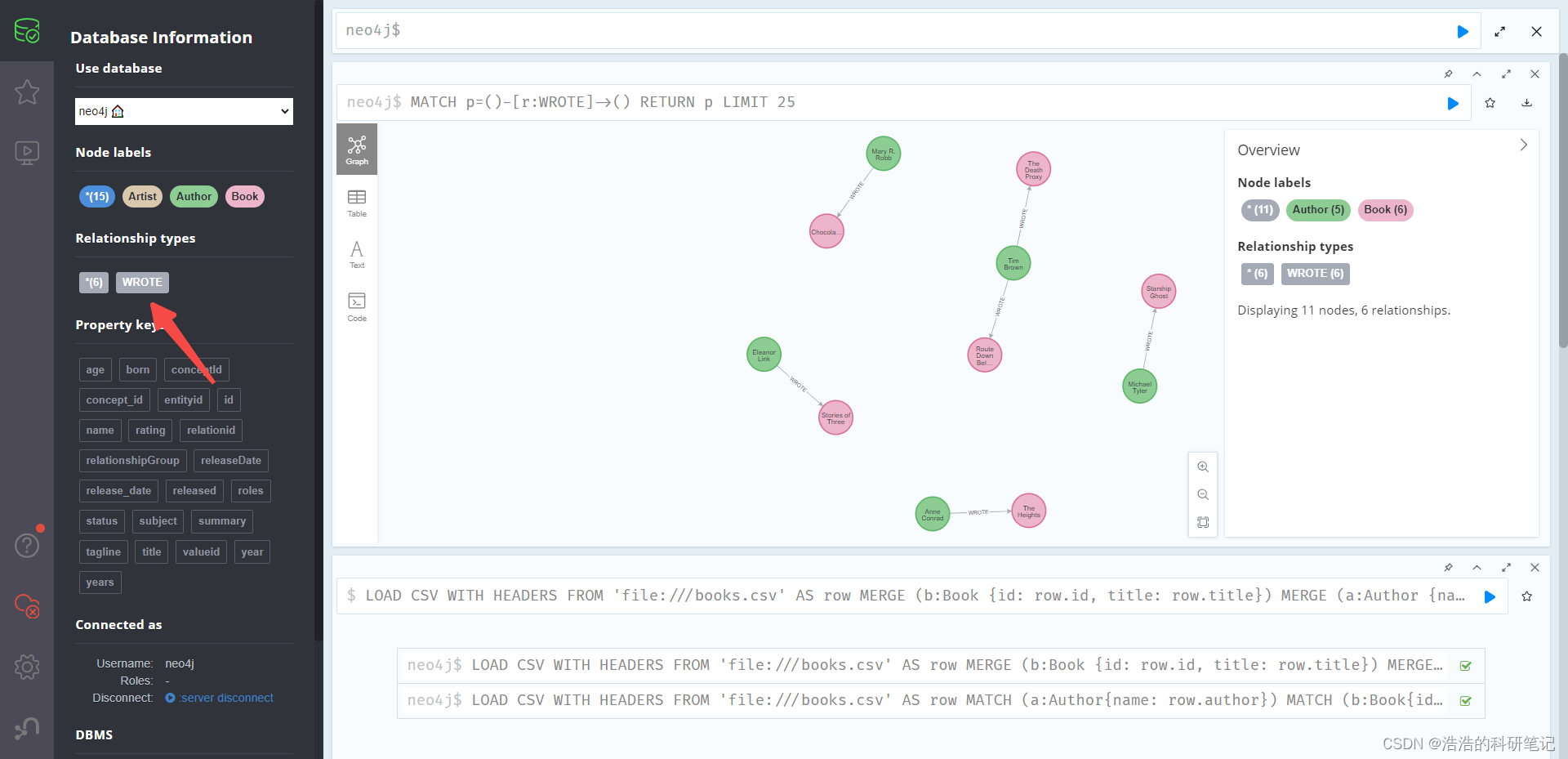
Neo4j 批量导入数据 从官方文档学习LOAD CSV 命令 小白可食用版
学习LOAD CSV🚀 在使用Neo4j进行大量数据导入的时候,发现如果用代码自动一行一行的导入效率过低,因此明白了为什么需要用到批量导入功能,在Neo4j中允许批量导入CSV文件格式,刚开始从网上的中看了各种半残的博客或者视频…...
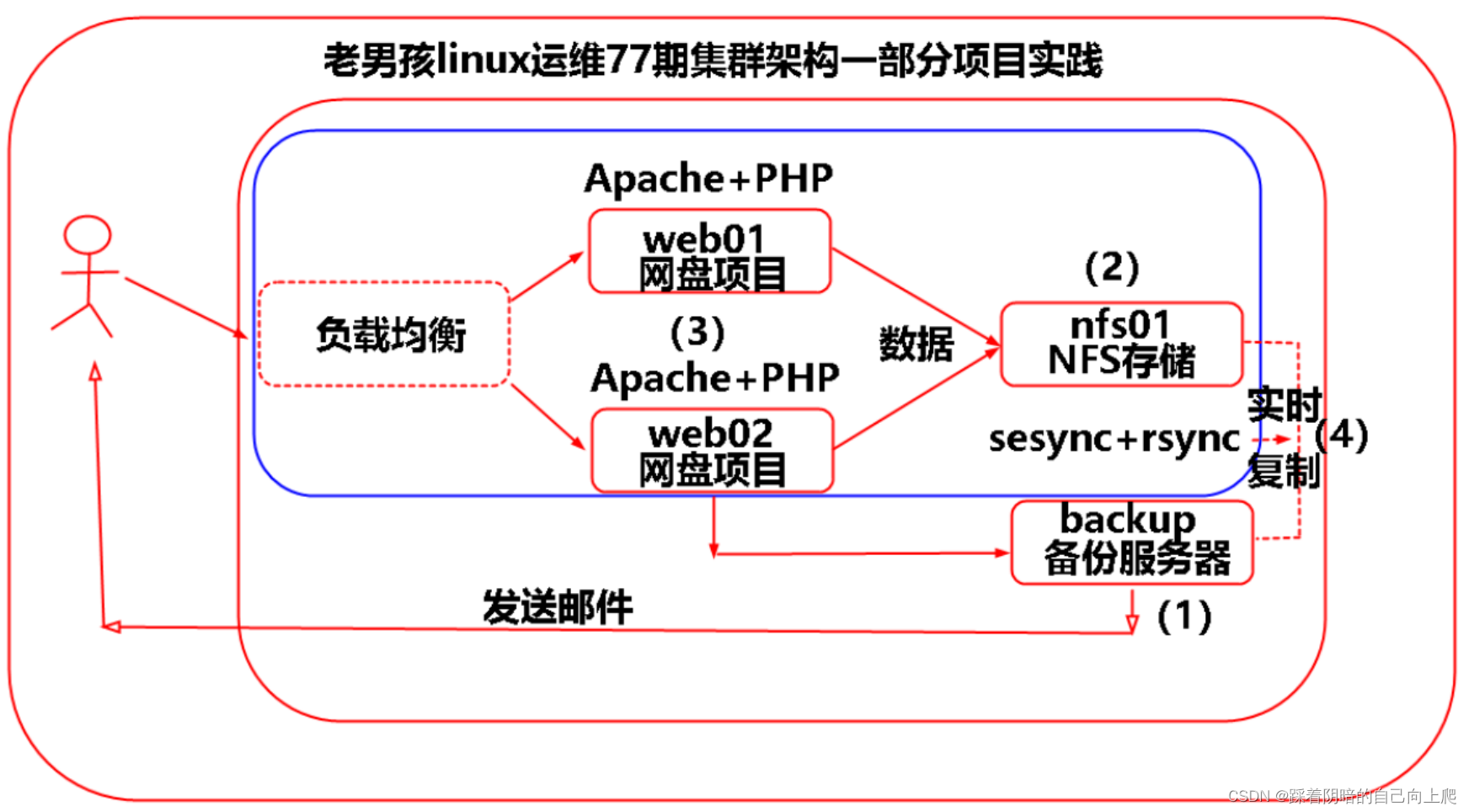
Day43-2-企业级实时复制intofy介绍及实践
Day43-2-企业级实时复制intofy介绍及实践 1. 企业级备份方案介绍1.1 利用定时方式,实现周期备份重要数据信息。1.2 实时数据备份方案1.3 实时复制环境准备1.4 实时复制软件介绍1.5 实时复制inotify机制介绍1.6 项目部署实施1.6.1 部署环境准备1.6.2 检查Linux系统支…...

2024年AI辅助研发趋势深度解析:科技革新与效率提升的双重奏
随着人工智能技术的迅猛发展,AI辅助研发正逐渐成为科技界和工业界的热门话题。特别是在2024年,这一趋势将更加明显,AI辅助研发将在各个领域展现出强大的潜力和应用价值。 首先,AI辅助研发将进一步提升研发效率。传统的研发模式往…...

bash: mysqldump: command not found
问题:在linux上执行mysql备份的时候,出现此异常 mysqldump命令找不到 解决: 1、找到mysql目录(找到mysql可执行命令目录) which mysql 有图可知,mysql安装在: /usr1/local/java/mysql 2、my…...

hcie数通和云计算选哪个好?
1. 基础知识与技能要求 数通技术是网络技术的核心,它涉及到网络协议、路由交换、网络安全等多个方面。如果你是一名网络工程师或开发者,想要在数通领域有所建树,你需要具备扎实的基础知识和丰富的实战经验。 云计算则更注重于虚拟化、存储、网…...

AX-MES生产制造管理系统-总览
前言说起 MES 就不得不说 ERP,但是 ERP 大家基本上都知道,MES 就不一定了,常见的 ERP 系统包括 SAP、金蝶、用友等,ERP的流程相对来说也比较统一;MES就不同了,基本上熟悉业务流程的软件公司都可以开发并实施…...

终极鼠标连点器使用指南:3分钟掌握高效自动化技巧
终极鼠标连点器使用指南:3分钟掌握高效自动化技巧 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ,操作…...
 第五篇:声明时的键值设计技巧:结构与内表的主键、非主键配置指南)
SAP-ABAP:变量、常量、结构与内表声明(10篇博客合集) 第五篇:声明时的键值设计技巧:结构与内表的主键、非主键配置指南
变量、常量、结构与内表声明(10篇博客合集) 第五篇:声明时的键值设计技巧:结构与内表的主键、非主键配置指南如果把内表比作一张内存中的“数据库表”,那么键就是这张表的索引甚至主键。键的设计直接决定了数据的唯一性…...

如何从零构建智能FOC轮腿机器人:完整开源硬件系统终极指南
如何从零构建智能FOC轮腿机器人:完整开源硬件系统终极指南 【免费下载链接】foc-wheel-legged-robot Open source materials for a novel structured legged robot, including mechanical design, electronic design, algorithm simulation, and software developme…...

原神私服新纪元:KCN-GenshinServer图形化服务端全功能解析
原神私服新纪元:KCN-GenshinServer图形化服务端全功能解析 【免费下载链接】KCN-GenshinServer 基于GC制作的原神一键GUI多功能服务端。 项目地址: https://gitcode.com/gh_mirrors/kc/KCN-GenshinServer 你是否曾想过拥有一个完全由自己掌控的提瓦特大陆&am…...

Jetson Orin上TVA模型DLA精准卸载配置
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

昇腾CANN elec-ops-simulation 实战:电力系统仿真——潮流计算与暂态稳定分析在 NPU 上的加速
电力系统仿真:500 节点电网的牛顿-拉夫逊潮流计算 → 解 10001000 稀疏雅可比矩阵(每迭代 1 次矩阵求逆)→ CPU 迭代 15 次 2.4s。实时调度要求 < 100ms → NPU 加速:雅可比矩阵求解用 Cube 单元做批量小矩阵 LU 分解 → 每迭…...

C++的单例模式及其作用
什么是单例模式?无论是在面向对象编程还是软件架构中,单例模式都扮演着至关重要的角色。它不仅能够确保一个类只有一个实例存在,还能够提供全局访问点,使得我们可以方便地在程序的任何地方使用该实例。但有几个设计模式并非解决抽…...

机器学习预测关税冲击下的股市波动:随机森林、SVR、kNN与线性回归实战对比
1. 项目概述与核心问题拆解做量化研究的朋友们,尤其是关注宏观事件对市场冲击的,应该都对“黑天鹅”事件不陌生。政策变动,特别是像关税这种直接影响国际贸易成本和公司利润的宏观变量,往往会在短期内引发市场剧烈波动。传统的做法…...

QuickDraw MediaPipe手势识别:无需画笔的手势控制绘画应用
QuickDraw MediaPipe手势识别:无需画笔的手势控制绘画应用 【免费下载链接】QuickDraw Implementation of Quickdraw - an online game developed by Google 项目地址: https://gitcode.com/gh_mirrors/qu/QuickDraw QuickDraw MediaPipe手势识别是一款创新…...