面试经典-MySQL篇
一、MySQL组成
- MySQL数据库的连接池:由一个线程来监听一个连接上请求以及读取请求数据,解析出来一条我们发送过去的SQL语句
- SQL接口:负责处理接收到的SQL语句
- 查询解析器:让MySQL能看懂SQL语句
- 查询优化器:选择最优的查询路径
- 执行器:根据执行计划调用存储引擎的接口
- 存储引擎接口:真正执行SQL语句
二、InnoDB的数据更新过程
首先InnoDB存储引擎有一个重要内存结构为缓冲池,假设我们执行如下sql:
update users set name='xxx' where id=10
那么底层将有如下几个步骤:
- 看看“id=10”这一行数据是否在缓冲池里,如果不在的话,直接从磁盘里加载到缓冲池里来
- 对这行记录加独占锁
- 假设“id=10”这行数据的name原来是“zhangsan”,现在我们要更新为“xxx”,先把要更新的原来的值“zhangsan”和“id=10”这些信息,写入到undo日志文件中去
- 更新buffer pool中的缓存数据,现在已经把内存里的数据进行了修改,但是磁盘上的数据还没修改
- 这个时候,就必须要把对内存所做的修改写入到一个redo日志
- 提交事务的时候将redo日志写入磁盘中
三、MySQL自己的日志文件(binlog)
- binlog叫做归档日志,他里面记录的是“对users表中的id=10的一行数据做了更新操作,更新以后的值是什么”
- 提交事务的时候,同时会写入binlog到磁盘文件中去
四、MySQL核心结构
- Buffer Pool
Buffer Pool本质其实就是数据库的一个内存组件,默认情况下是128MB,还是有一点偏小了,我们实际生产环境下完全可以对Buffer Pool进行调整。数据库启动时会在Buffer Pool中划分出来一个一个的缓存页,一个缓存页的大小和磁盘上的一个数据页的大小是一一对应起来的,都是16KB,每个数据页中有很多行数据。
- free链表
他是一个双向链表数据结构,只要你一个缓存页是空闲的, 那么他的描述数据块就会被放入这个free链表中,当你需要把磁盘上的数据页读取到Buffer Pool中的缓存页里去的时候,我们需要从free链表里获取一个描述数据块,然后就可以获取对应的空闲缓存页,接着我们就可以把磁盘上的数据页读取到对应的缓存页里去,最后把那个描述数据块从free链表里去除就可以了。
- 数据页缓存哈希表
我们在执行增删改查的时候,肯定是先看看这个数据页有没有被缓存,用表空间号+数据页号,作为一个key,然后缓存页的地址作为value。
- flush链表
凡是被修改过的缓存页,都会把他的描述数据块加入到flush链表中去,flush的意思就是这些都是脏页,后续都是要flush刷新到磁盘上去的。
五、事务
四大事务问题:
- 脏写:事务B更新好的值被事务A回滚为事务A原先的值。
- 脏读:事务B去查询了事务A修改过的数据,但是此时事务A还没提交
- 不可重复读:事务A执行过程中事务B执行并提交,导致事务A两次读到的值不一样
- 幻读:事务A一开始查出了10条数据,事务B新增了2条数据,并且提交了,此时事务A再查发现查出了12条数据
四大隔离级别:
- read uncommitted(读未提交):不允许发生脏写的,可能发生脏读,不可重复读,幻读。
- read committed(读已提交):不会发生脏写和脏读,可能会发生不可重复读和幻读问题
- repeatable read(可重复读):不会发生脏写和脏读和不可重复读,可能会幻读问题
- serializable(串行化):不会发生脏写和脏读和不可重复读和幻读
MySQL默认设置的事务隔离级别是可重复读,而且MySQL的可重复读级别是可以避免幻读发生的,原理就是下面的MVCC机制。
六、MVCC机制
Mysql事务通过MVCC机制得以实现,我们每条数据其实都有两个隐藏字段,一个是trx_id,一个是roll_pointer,这个trx_id就是最近一次更新这条数据的事务id,roll_pointer就是指向你了你更新这个事务之前生成的undo log链。
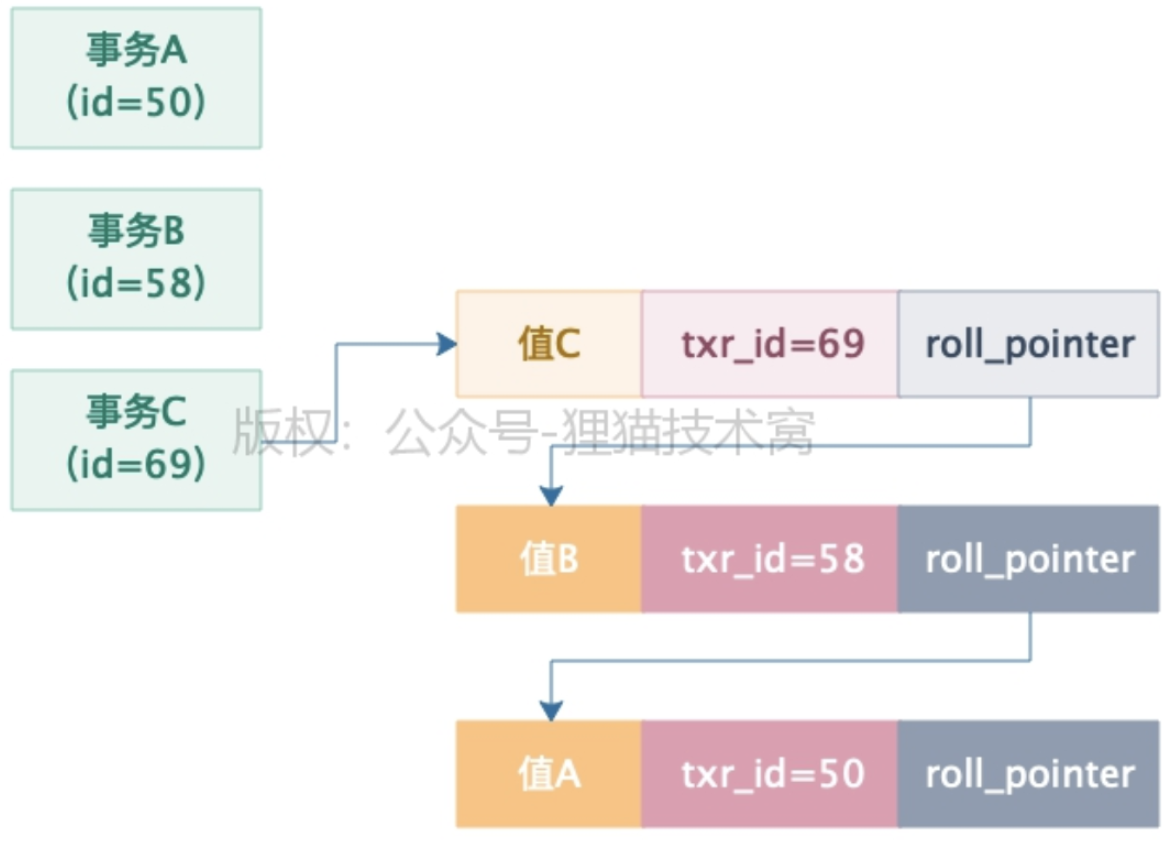
执行一个事务的时候,就给你生成一个ReadView(视图),ReadView包含以下信息:
- m_ids:此时有哪些事务在MySQL里执行还没提交的
- min_trx_id:m_ids里最小的值
- max_trx_id:mysql下一个要生成的事务id,就是最大事务id
- creator_trx_id:你这个事务的id
下面演示一下MVCC机制的执行步骤:
- 一个是事务A(id=45),一个是事务B(id=59),事务B是要去更新这行数据的,事务A是要去读取这行数据的值
- 现在事务A直接开启一个ReadView,这个ReadView里的m_ids就包含了事务A和事务B的两个id,45和59,然后min_trx_id就是45,max_trx_id就是60,creator_trx_id就是45,是事务A自己。
- 这个时候事务A第一次查询这行数据,会走一个判断,就是判断一下当前这行数据的txr_id是否小于ReadView中的min_trx_id,此时发现txr_id=32,是小于ReadView里的min_trx_id就是45的
- 说明你事务开启之前,修改这行数据的事务早就提交了,所以此时可以查到这行数据
- 接着事务B开始动手了,他把这行数据的值修改为了值B,然后这行数据的txr_id设置为自己的id,也就是59,同时roll_pointer指向了修改之前生成的一个undo log,接着这个事务B就提交了
- 这个时候事务A再次查询,此时查询的时候,会发现一个问题,那就是此时数据行里的txr_id=59,那么这个txr_id是大于ReadView里的min_txr_id(45),同时小于ReadView里的max_trx_id(60)的
- 说明更新这条数据的事务,很可能就跟自己差不多同时开启的,于是会看一下这个txr_id=59,是否在ReadView的m_ids列表里?
- 果然,在ReadView的m_ids列表里,有45和59两个事务id,直接证实了,这个修改数据的事务是跟自己同一时段并发执行然后提交的,所以对这行数据是不能查询的
- 顺着这条数据的roll_pointer顺着undo log日志链条往下找,就会找到最近的一条undo log,trx_id是32,此时发现trx_id=32,是小于ReadView里的min_trx_id(45)的
- 说明这个undo log版本必然是在事务A开启之前就执行且提交的,那么读这条数据就可以了
- 总结来说:一个事务可以读到事务ID等于自身和比自己事务ID小的事务更新的值,但是也不是所有的事务ID比自己小的事务更新的值都能读到,还不能不在m_ids中
七、锁机制
- 当有一个事务加了独占锁之后,此时其他事务再要更新这行数据只能生成独占锁在后面等待。
- 当有人在更新数据的时候,其他的事务可以读取这行数据吗?默认情况下需要加锁吗?不用!因为有人在更新数据的时候,然后你要去读取这行数据,直接默认就是开启mvcc机制的。
- 那么假设万一要是你在执行查询操作的时候,就是想要加锁呢?那也是ok的,MySQL首先支持一种共享锁,就是S锁,这个共享锁的语法如下:select * from table lock in share mode,如果此时有别的事务在更新这行数据,已经加了独占锁了,此时你的共享锁能加吗?当然不行了,共享锁和独占锁是互斥的!此时你这个查询就只能等着了。
- 那么如果你先加了共享锁,然后别人来更新要加独占锁行吗?当然不行了,共享锁和独占锁是互斥的!此时你这个查询就只能等着了。
- 那么如果你在加共享锁的时候,别人也加共享锁呢?此时是可以的,你们俩都是可以加共享锁的,共享锁和共享锁是不会互斥的。
八、索引
MySQL的索引是用B+树来组成的,索引分为两种:
- 聚簇索引
如果一颗大的B+树索引数据结构里,叶子节点就是数据页自己本身,那么此时我们就可以称这颗B+树索引为聚簇索引!这个聚簇索引默认是按照主键来组织的,所以你在增删改数据的时候,一方面会更新数据页,另一方面其实会给你自动维护B+树结构的聚簇索引。
- 二级索引
比如你基于name字段建立了一个索引,那么此时你插入数据的时候,就会重新搞一颗B+树,B+树的叶子节点也是数据页,但是这个数据页里仅仅放主键字段和name字段。针对select * from table where name='xx’这样的语句,你先根据name字段值在name字段的索引B+树里找,找到叶子节点也仅仅可以找到对应的主键值,而找不到这行数据完整的所有字段。
索引使用原则:
- 等值匹配规则
就是你where语句中的几个字段名称和联合索引的字段完全一样,而且都是基于等号的等值匹配,那百分百会用上我们的索引
- 最左侧列匹配
这个意思就是假设我们联合索引是KEY(class_name, student_name, subject_name),那么不一定必须要在where语句里根据三个字段来查,其实只要根据最左侧的部分字段来查,也是可以的。
- 最左前缀匹配原则
即如果你要用like语法来查,比如select * from student_score where class_name like ‘1%’,查找所有1打头的班级的分数,那么也是可以用到索引的。
- 范围查找规则
你的where语句里如果有范围查询,那只有对联合索引里最左侧的列进行范围查询才能用到索引!
- 等值匹配+范围匹配的规则
联合索引是KEY(class_name, student_name, subject_name),如果你要是用select * from student_score where class_name=‘1班’ and student_name>‘’ and subject_name<‘’,首先可以用class_name在索引里精准定位到一波数据,接着这波数据里的student_name都是按照顺序排列的,所以student_name>'‘也会基于索引来查找,但是接下来的subject_name<’'是不能用索引的。为什么呢?因为student_name在不相同的情况下,subject_name是无序的,所以不能走索引,只能全表扫描。
执行计划的几个级别:
- const
直接就可以通过聚簇索引或者二级索引+聚簇索引回源,轻松查到你要的数据。这里有一个要点,你的二级索引必须是unique key唯一索引,才是属于const方式的
- ref
select * from table where name=x的语句,name是个普通二级索引,不是唯一索引,如果你用name IS NULL这种语法的话,即使name是主键或者唯一索引,还是只能走ref方式
- range
select * from table where age>=x and age <=x,假设age就是一个普通索引,此时就必然利用索引来进行范围筛选
- index
只要遍历二级索引就可以拿到你想要的数据,而不需要回源到聚簇索引的访问方式
- all
全表扫描
相关文章:
面试经典-MySQL篇
一、MySQL组成 MySQL数据库的连接池:由一个线程来监听一个连接上请求以及读取请求数据,解析出来一条我们发送过去的SQL语句SQL接口:负责处理接收到的SQL语句查询解析器:让MySQL能看懂SQL语句查询优化器:选择最优的查询…...

C#控制台贪吃蛇
Console.Write("");// 第一次生成食物位置 // 随机生成一个食物的位置 // 食物生成完成后判断食物生成的位置与现在的蛇的身体或者障碍物有冲突 // 食物的位置与蛇的身体或者障碍物冲突了,那么一直重新生成食物,直到生成不冲突…...

[小程序开发] 构造页面
一、Component方法 Component方法用于创建自定义组件,小程序页面也可以使用Component方法进行创建,从而实现复杂的页面逻辑开发。 使用Component方法构造页面,可以实现更加复杂的页面逻辑开发。 二、注意事项 1、要求.json文件中必须包含usi…...
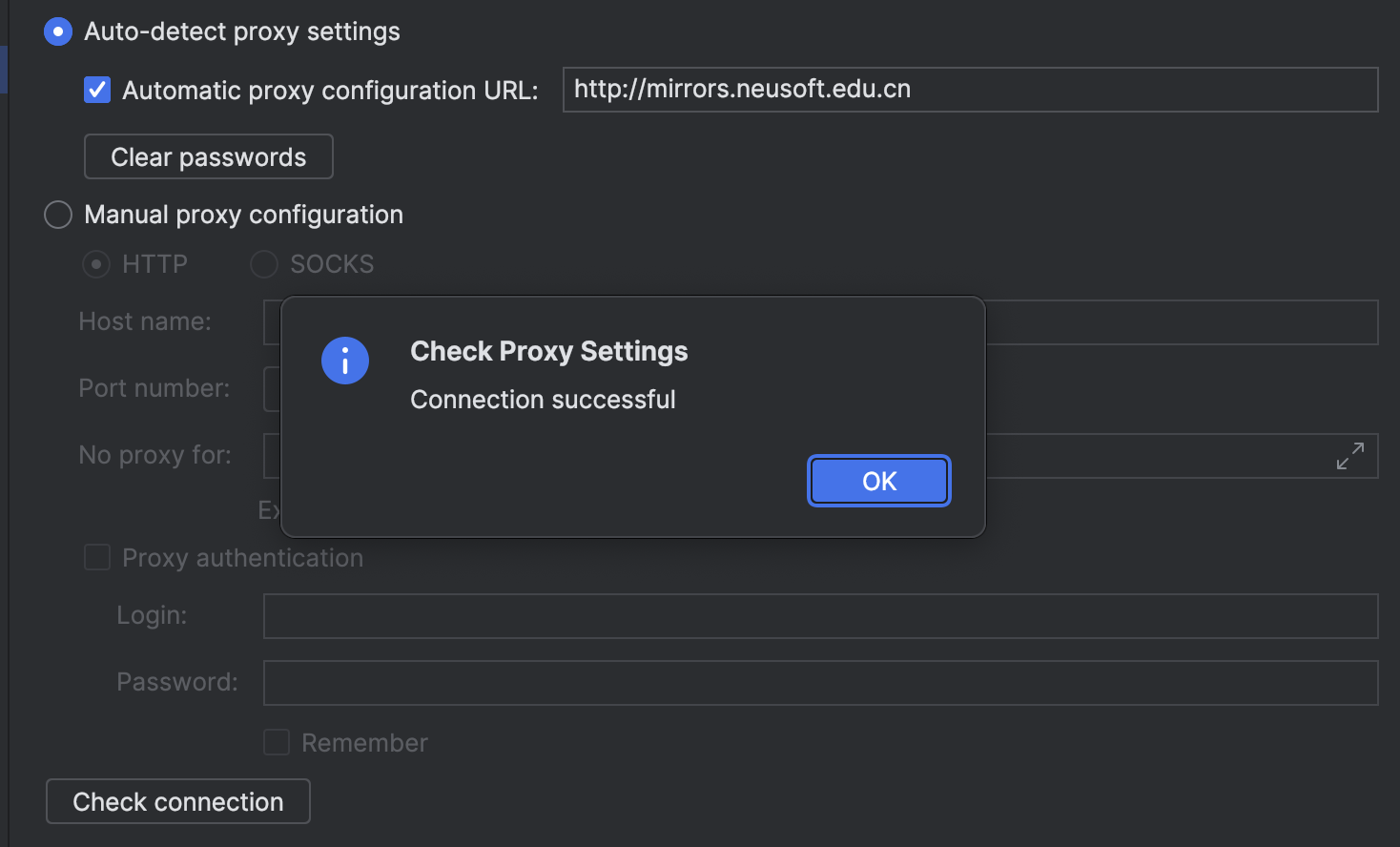
安装Android Studio遇到Unable to access Android SDK add-on list的错误
第一次安装android studio的时候,提示:unable to access Android sdk add-on list 解决办法 这个错误一般是android studoi代理没有设置导致的,需要在setting里面设置: 点击Android Studio - Preferences,在 Appeara…...
EXCEL+PYTHON学习3
1) 遍历一个SHEET,无非就是两个循环,rows属性是取得所有行。 fn data3_16.xlsx wb openpyxl.load_workbook(fn) ws wb.active for row in ws.rows:for cell in row:print(cell.value, end )print() 2) 返回工作表的最小行数…...
Rabbit MQ详解
写在前面,由于Rabbit MQ涉及的内容较多,赶在春招我个人先按照我认为重要的内容进行一定总结,也算是个学习笔记吧。主要参考官方文档、其他优秀文章、大模型问答。自己边学习边总结。后面有时间我会慢慢把所有内容补全,分享出来也是希望可以给…...

uniapp 写安卓app,运行到手机端 调试
手机 设置》关于手机》点击版本号 4-5次,弹出手机锁屏页面,输入手机锁屏密码 2.手机 设置中 》搜索 开发人员选项 》 调试》打开USB调试 同页面 找到 选择USB配置》选择 MIDIhbuilder 编辑器 点击 》运行》运行到手机或模拟器》运行到Android App基座 》…...

uniapp 实现双击点赞出现特效
更新一下 老板改了需求要加上特效 1. 创建点赞按钮 首先,在你的页面中创建一个点赞按钮 全局点赞的话就写在最外面的标签就行了。你可以使用 <button> 组件或者自定义一个视图组件。 <template> <view class"container"> <but…...
分布式搜索引擎elasticsearch(2)
1.DSL查询文档 elasticsearch的查询依然是基于JSON风格的DSL来实现的。 1.1.DSL查询分类 Elasticsearch提供了基于JSON的DSL([Domain Specific Language](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl.html))来定义查…...

如何实现一个栈或队列?
如何实现一个栈或队列? 栈(Stack)和队列(Queue)是两种常见的数据结构,它们在编程中经常被使用。下面我将分别解释如何使用Python来实现这两种数据结构。 1. 栈的实现 栈是一种后进先出(LIF…...
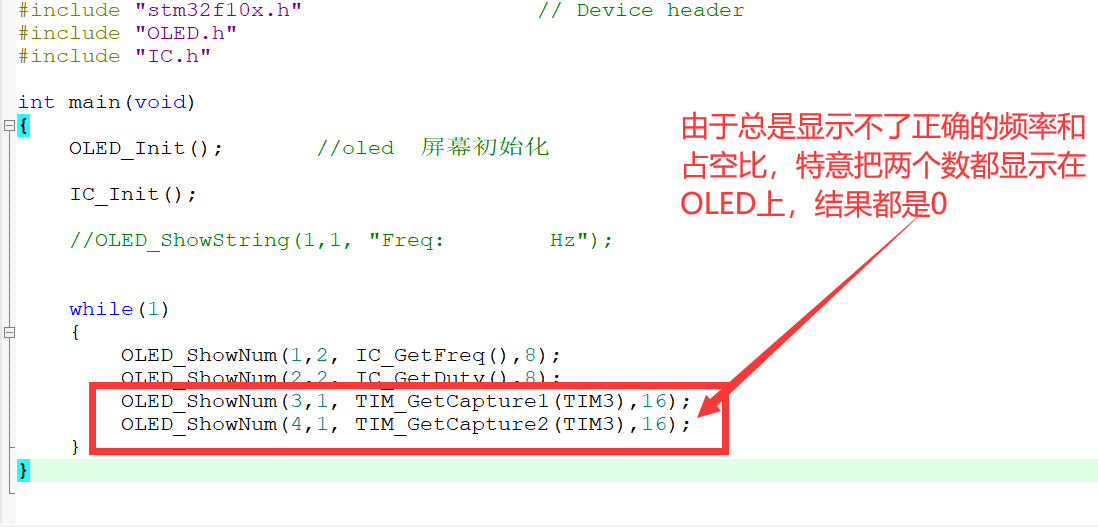
STM32输入捕获频率和占空比proteus仿真失败
这次用了两天的时间来验证这个功能,虽然实验没有成功,但是也要记录一下,后面能解决了,回来再写上解决的办法: 这个程序最后的实验结果是读取到的CCR1和CCR2的值都是0,所以没有办法算出来频率和占空比。 还…...

Kafka-SSL笔记整理
创建密钥仓库以及CA 创建密匙仓库,用户存储证书文件keytool -keystore server.keystore.jks -alias hello_kafka -validity 100000 -genkey创建CAopenssl req -new -x509 -keyout ca-key -out ca-cert -days 100000将生成的CA添加到客户端信任库keytool -keystore client.trus…...

Mysql挂掉怎么办
思路 从库处理,relaylog,讲从库升级主库。 待主机恢复后,主机替换为从库。 具体操作 简介: 主库宕机 Master DOWN机-企业场景一主多从宕机从库切换主继续和从同步过程详解 登陆从库,show processlist; 查看两个线…...
》)
《工厂模式(极简c++)》
本文章属于专栏《设计模式(极简c版)》 继续上一篇《设计原则》。本章简要说明工厂模式。本文分为模式说明、本质思想、实践建议、代码示例四个部分。 模式说明: 简单工厂模式 方案:对象不直接new,而是通过另一个类&am…...

前端学习笔记|JavaScript基础
JS基础 数据类型 基于动力节点视频。 Number、String、Boolean、object 强制转换 Number 强转,boolean强转(undefined、null、NaN都是转成false),String强转 myAge Number("123445"); Boolean(0); String(123);parseInt、parseFloat 遇到非数字&…...

springcloud五大组件:Eureka:注册中心、Zuul:服务网关、Ribbon:负载均衡、Feign:服务调用、Hystix:熔断器
你提到的这些组件都是Spring Cloud生态系统中非常关键和常用的组件。但是,关于这些组件的命名,有一点需要更正: Eureka 应该是 Eureka 或者 Eureka Server:Eureka是Netflix开源的一个服务发现组件,它本身是一个基于RE…...

Python的Selenium库中的模块、类和异常的汇总
这些是 Selenium Python 库中的模块、类和异常,用于实现自动化 Web 浏览器测试和网页操作。以下是它们的简单解释:Python Module Index — Selenium 4.18.1 documentation 1. selenium.common.exceptions:包含了 Selenium 中可能出现的异常。…...

智慧交通:构建智慧城市的重要一环
随着信息技术的飞速发展,智慧城市已成为现代城市发展的重要方向。作为智慧城市的重要组成部分,智慧交通以其高效、便捷、环保的特性,成为推动城市现代化进程的关键力量。本文将从智慧交通的概念、发展现状、面临挑战以及未来趋势等方面&#…...

BFS 求解 最小高度树 【妙用】
310. 最小高度树 链接 :题目链接 思路 常规解法是树形dp,两个dfs解决,这里不再赘述新颖解法bfs,而且实现更加简单,大体思路就是每次都从叶子节点一步步往中心爬,最后一批留在队列中的节点就为本题意的答案…...
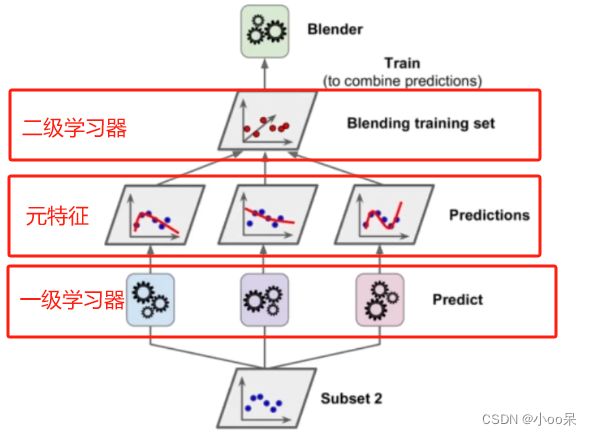
【机器学习300问】36、什么是集成学习?
一、什么是集成学习? (1)它的出现是为了解决什么问题? 提高准确性:单个模型可能对某些数据敏感或者有概念偏见,而集成多个模型可以提高预测的准确性。让模型变稳定:一些模型,如决策…...
)
DeepSeek RAG系统渗透测试全链路复现(含PoC代码与防御加固清单)
更多请点击: https://kaifayun.com 第一章:DeepSeek RAG系统渗透测试全链路复现概览 DeepSeek RAG系统作为面向企业级知识检索增强生成的典型架构,其安全边界不仅涵盖LLM服务层,更延伸至向量数据库、检索代理、提示工程网关及外部…...

癫痫手术精准定位:基于脑电信号昼夜节律与多生物标志物的机器学习分析框架
1. 项目概述:当机器学习遇见脑电信号,如何让癫痫手术更精准?作为一名长期耕耘在生物医学信号处理与机器学习交叉领域的工程师,我常常思考如何将算法模型从实验室的“玩具”变成临床医生手中可靠的“手术刀”。癫痫,这个…...

DeepSeek基准测试避坑手册:92%开发者忽略的4大陷阱——硬件配置偏差、tokenizer不一致、batch size幻觉、温度值污染
更多请点击: https://codechina.net 第一章:DeepSeek基准测试避坑手册:92%开发者忽略的4大陷阱——硬件配置偏差、tokenizer不一致、batch size幻觉、温度值污染 硬件配置偏差:GPU显存与计算精度的隐性干扰 在A100(8…...

极致精简,功能强大的PDF编辑工具
这是一款功能全面的PDF编辑工具 你只需要导入一份PDF格式文件 就可以快速的对它进行插入 批注编辑保护转换等各种操作 而且无需登录 也可以直接使用 在插入选项中可以进行插入文字图片 页面页眉页脚页码文档背景水印视频音频等 在批注选项中可以管理批注隐藏批注 高亮显示 文本…...

Onekey终极指南:如何5分钟快速获取Steam游戏清单的免费神器
Onekey终极指南:如何5分钟快速获取Steam游戏清单的免费神器 【免费下载链接】Onekey Onekey Steam Depot Manifest Downloader 项目地址: https://gitcode.com/gh_mirrors/one/Onekey 还在为复杂的Steam游戏清单下载而头疼吗?想要备份游戏资源却不…...

Vulnhub-DC-1
1.信息收集 使用工具nmap扫描主机端口 这是Drupal是使用PHP语言编写的开源内容管理框架(CMF),它由内容管理系统(CMS)和PHP开发框架(Framework)共同构成 Web指纹扫描 发现是:drupal…...

千亿镁合金产业集群正在成形:成都、抚州、池州的新版图
一个新赛道的地理坐标 如果要在中国地图上标注一条正在成形的新兴产业集群走廊,高强镁合金这条线,值得被认真画出来。 成都龙泉驿——江西抚州临川——安徽池州高新区,三个坐标,三条生产线,一家公司,两年内…...
)
CentOS服务器上VNC连接失败?手把手教你排查并修复个人端口问题(附重启命令)
CentOS服务器VNC连接故障深度排查指南:从原理到实战当你在深夜赶项目时,突然发现VNC连接不上服务器,那种焦虑感我深有体会。去年参与半导体器件仿真项目时,我也曾被这个问题困扰整整两天。本文将分享一套经过实战检验的排查方法论…...

基于随机森林的低成本传感器机器学习校准实践指南
1. 项目概述:当低成本传感器遇上机器学习校准在物联网和智能感知系统铺天盖地的今天,低成本传感器几乎无处不在。从监测办公室的空气质量,到追踪城市街道的噪音污染,再到农业大棚里的温湿度控制,这些价格亲民的“小眼睛…...

AI率总超标?2026年AI写作辅助网站排行榜权威发布,轻松定稿不是梦!
写论文效率低、熬夜赶稿、查重不过关?别慌!2026 年最新 AI 论文写作工具合集来了,覆盖选题、大纲、初稿、润色、降重、格式、文献引用全流程,帮你精准匹配最适合的学术助手,彻底告别论文内耗!🏆…...