k8s集群部署elk
一、前言
本次部署elk所有的服务都部署在k8s集群中,服务包含filebeat、logstash、elasticsearch、kibana,其中elasticsearch使用集群的方式部署,所有服务都是用7.17.10版本
二、部署
部署elasticsearch集群
部署elasticsearch集群需要先优化宿主机(所有k8s节点都要优化,不优化会部署失败)
vi /etc/sysctl.conf
vm.max_map_count=262144重载生效配置
sysctl -p
以下操作在k8s集群的任意master执行即可
创建yaml文件存放目录
mkdir /opt/elk && cd /opt/elk
这里使用无头服务部署es集群,需要用到pv存储es集群数据,service服务提供访问,setafuset服务部署es集群
创建svc的无头服务和对外访问的yaml配置文件
vi es-service.yaml
kind: Service
metadata:name: elasticsearchnamespace: elklabels:app: elasticsearch
spec:selector:app: elasticsearchclusterIP: Noneports:- port: 9200name: db- port: 9300name: intervi es-service-nodeport.yaml
apiVersion: v1
kind: Service
metadata:name: elasticsearch-nodeportnamespace: elklabels:app: elasticsearch
spec:selector:app: elasticsearchtype: NodePortports:- port: 9200name: dbnodePort: 30017- port: 9300name: internodePort: 30018创建pv的yaml配置文件(这里使用nfs共享存储方式)
vi es-pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:name: es-pv1
spec:storageClassName: es-pv #定义了存储类型capacity:storage: 30GiaccessModes:- ReadWriteManypersistentVolumeReclaimPolicy: Retainnfs:path: /volume2/k8s-data/es/es-pv1server: 10.1.13.99
---
apiVersion: v1
kind: PersistentVolume
metadata:name: es-pv2
spec:storageClassName: es-pv #定义了存储类型capacity:storage: 30GiaccessModes:- ReadWriteManypersistentVolumeReclaimPolicy: Retainnfs:path: /volume2/k8s-data/es/es-pv2server: 10.1.13.99
---
apiVersion: v1
kind: PersistentVolume
metadata:name: es-pv3
spec:storageClassName: es-pv #定义了存储类型capacity:storage: 30GiaccessModes:- ReadWriteManypersistentVolumeReclaimPolicy: Retainnfs:path: /volume2/k8s-data/es/es-pv3server: 10.1.13.99创建setafulset的yaml配置文件
vi es-setafulset.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:name: elasticsearchnamespace: elklabels:app: elasticsearch
spec:podManagementPolicy: Parallel serviceName: elasticsearchreplicas: 3selector:matchLabels:app: elasticsearchtemplate:metadata:labels:app: elasticsearchspec:tolerations: #此配置是容忍污点可以使pod部署到master节点,可以去掉- key: "node-role.kubernetes.io/control-plane"operator: "Exists"effect: NoSchedulecontainers:- image: elasticsearch:7.17.10name: elasticsearchresources:limits:cpu: 1memory: 2Girequests:cpu: 0.5memory: 500Mienv:- name: network.hostvalue: "_site_"- name: node.namevalue: "${HOSTNAME}"- name: discovery.zen.minimum_master_nodesvalue: "2"- name: discovery.seed_hosts #该参数用于告诉新加入集群的节点去哪里发现其他节点,它应该包含集群中已经在运行的一部分节点的主机名或IP地址,这里我使用无头服务的地址value: "elasticsearch-0.elasticsearch.elk.svc.cluster.local,elasticsearch-1.elasticsearch.elk.svc.cluster.local,elasticsearch-2.elasticsearch.elk.svc.cluster.local"- name: cluster.initial_master_nodes #这个参数用于指定初始主节点。当一个新的集群启动时,它会从这个列表中选择一个节点作为初始主节点,然后根据集群的情况选举其他的主节点value: "elasticsearch-0,elasticsearch-1,elasticsearch-2"- name: cluster.namevalue: "es-cluster"- name: ES_JAVA_OPTSvalue: "-Xms512m -Xmx512m"ports:- containerPort: 9200name: dbprotocol: TCP- name: intercontainerPort: 9300volumeMounts:- name: elasticsearch-datamountPath: /usr/share/elasticsearch/datavolumeClaimTemplates:- metadata:name: elasticsearch-dataspec:storageClassName: "es-pv"accessModes: [ "ReadWriteMany" ]resources:requests:storage: 30Gi创建elk服务的命名空间
kubectl create namespace elk创建yaml文件的服务
kubectl create -f es-pv.yaml
kubectl create -f es-service-nodeport.yaml
kubectl create -f es-service.yaml
kubectl create -f es-setafulset.yaml
查看es服务是否正常启动
kubectl get pod -n elk
检查elasticsearch集群是否正常
http://10.1.60.119:30017/_cluster/state/master_node,nodes?pretty可以看到集群中能正确识别到三个es节点

elasticsearch集群部署完成
部署kibana服务
这里使用deployment控制器部署kibana服务,使用service服务对外提供访问
创建deployment的yaml配置文件
vi kibana-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: kibananamespace: elklabels:app: kibana
spec:replicas: 1selector:matchLabels:app: kibanatemplate:metadata:labels:app: kibanaspec:tolerations:- key: "node-role.kubernetes.io/control-plane"operator: "Exists"effect: NoSchedulecontainers:- name: kibanaimage: kibana:7.17.10resources:limits:cpu: 1memory: 1Grequests:cpu: 0.5memory: 500Mienv:- name: ELASTICSEARCH_HOSTSvalue: http://elasticsearch:9200ports:- containerPort: 5601protocol: TCP创建service的yaml配置文件
vi kibana-service.yaml
apiVersion: v1
kind: Service
metadata:name: kibananamespace: elk
spec:ports:- port: 5601protocol: TCPtargetPort: 5601nodePort: 30019type: NodePortselector:app: kibana创建yaml文件的服务
kubectl create -f kibana-service.yaml
kubectl create -f kibana-deployment.yaml查看kibana是否正常
kubectl get pod -n elk
部署logstash服务
logstash服务也是通过deployment控制器部署,需要使用到configmap存储logstash配置,还有service提供对外访问服务
编辑configmap的yaml配置文件
vi logstash-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:name: logstash-configmapnamespace: elklabels:app: logstash
data:logstash.conf: |input {beats {port => 5044 #设置日志收集端口# codec => "json"}}filter {}output {# stdout{ 该被注释的配置项用于将收集的日志输出到logstash的日志中,主要用于测试看收集的日志中包含哪些内容# codec => rubydebug# }elasticsearch {hosts => "elasticsearch:9200"index => "nginx-%{+YYYY.MM.dd}"}}编辑deployment的yaml配置文件
vi logstash-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: logstashnamespace: elk
spec:replicas: 1selector:matchLabels:app: logstashtemplate:metadata:labels:app: logstashspec:containers:- name: logstashimage: logstash:7.17.10imagePullPolicy: IfNotPresentports:- containerPort: 5044volumeMounts:- name: config-volumemountPath: /usr/share/logstash/pipeline/volumes:- name: config-volumeconfigMap:name: logstash-configmapitems:- key: logstash.confpath: logstash.conf编辑service的yaml配置文件(我这里是收集k8s内部署的服务日志,所以没开放对外访问)
vi logstash-service.yaml
apiVersion: v1
kind: Service
metadata:name: logstashnamespace: elk
spec:ports:- port: 5044targetPort: 5044protocol: TCPselector:app: logstashtype: ClusterIP创建yaml文件的服务
kubectl create -f logstash-configmap.yaml
kubectl create -f logstash-service.yaml
kubectl create -f logstash-deployment.yaml查看logstash服务是否正常启动
kubectl get pod -n elk
部署filebeat服务
filebeat服务使用daemonset方式部署到k8s的所有工作节点上,用于收集容器日志,也需要使用configmap存储配置文件,还需要配置rbac赋权,因为用到了filebeat的自动收集模块,自动收集k8s集群的日志,需要对k8s集群进行访问,所以需要赋权
编辑rabc的yaml配置文件
vi filebeat-rbac.yaml
apiVersion: v1
kind: ServiceAccount
metadata:name: filebeatnamespace: elklabels:app: filebeat
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:name: filebeatlabels:app: filebeat
rules:
- apiGroups: [""]resources: ["namespaces", "pods", "nodes"] #赋权可以访问的服务verbs: ["get", "list", "watch"] #可以使用以下命令
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:name: filebeat
subjects:
- kind: ServiceAccountname: filebeatnamespace: elk
roleRef:kind: ClusterRolename: filebeatapiGroup: rbac.authorization.k8s.io编辑configmap的yaml配置文件
vi filebeat-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:name: filebeat-confignamespace: elkdata:filebeat.yml: |filebeat.autodiscover: #使用filebeat的自动发现模块providers:- type: kubernetes #类型选择k8s类型templates: #配置需要收集的模板- condition:and:- or:- equals:kubernetes.labels: #通过标签筛选需要收集的pod日志app: foundation- equals:kubernetes.labels:app: api-gateway- equals: #通过命名空间筛选需要收集的pod日志kubernetes.namespace: java-serviceconfig: #配置日志路径,使用k8s的日志路径- type: containersymlinks: true paths: #配置路径时,需要使用变量去构建路径,以此来达到收集对应服务的日志- /var/log/containers/${data.kubernetes.pod.name}_${data.kubernetes.namespace}_${data.kubernetes.container.name}-*.logoutput.logstash:hosts: ['logstash:5044']关于filebeat自动发现k8s服务的更多内容可以参考elk官网,里面还有很多的k8s参数可用
参考:Autodiscover | Filebeat Reference [8.12] | Elastic

编辑daemonset的yaml配置文件
vi filebeat-daemonset.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:name: filebeatnamespace: elklabels:app: filebeat
spec:selector:matchLabels:app: filebeattemplate:metadata:labels:app: filebeatspec:serviceAccountName: filebeatterminationGracePeriodSeconds: 30containers:- name: filebeatimage: elastic/filebeat:7.17.10args: ["-c", "/etc/filebeat.yml","-e",]env:- name: NODE_NAMEvalueFrom:fieldRef:fieldPath: spec.nodeNamesecurityContext:runAsUser: 0resources:limits:cpu: 200mmemory: 200Mirequests:cpu: 100mmemory: 100MivolumeMounts:- name: configmountPath: /etc/filebeat.ymlreadOnly: truesubPath: filebeat.yml- name: log #这里挂载了三个日志路径,这是因为k8s的container路径下的日志文件都是通过软链接去链接其它目录的文件mountPath: /var/log/containersreadOnly: true- name: pod-log #这里是container下的日志软链接的路径,然而这个还不是真实路径,这也是个软链接mountPath: /var/log/podsreadOnly: true- name: containers-log #最后这里才是真实的日志路径,如果不都挂载进来是取不到日志文件的内容的mountPath: /var/lib/docker/containersreadOnly: truevolumes:- name: configconfigMap:defaultMode: 0600name: filebeat-config- name: loghostPath:path: /var/log/containers- name: pod-loghostPath:path: /var/log/pods- name: containers-loghostPath:path: /var/lib/docker/containers创建yaml文件的服务
kubectl create -f filebeat-rbac.yaml
kubectl create -f filebeat-configmap.yaml
kubectl create -f filebeat-daemonset.yaml查看filebeat服务是否正常启动
kubectl get pod -n elk
至此在k8s集群内部署elk服务完成
相关文章:
k8s集群部署elk
一、前言 本次部署elk所有的服务都部署在k8s集群中,服务包含filebeat、logstash、elasticsearch、kibana,其中elasticsearch使用集群的方式部署,所有服务都是用7.17.10版本 二、部署 部署elasticsearch集群 部署elasticsearch集群需要先优化…...

【Python】清理conda缓存的常用命令
最近发现磁盘空间不足,很大一部分都被anaconda占据了,下面是一些清除conda缓存的命令 清理所有环境的Anaconda包缓存 删除所有未使用的包以及缓存的索引和临时文件 conda clean --all清理某一特定环境的Anaconda包缓存 conda clean --all -n 环境名清…...

代码随想录算法训练营第46天 | 完全背包,139.单词拆分
动态规划章节理论基础: https://programmercarl.com/%E5%8A%A8%E6%80%81%E8%A7%84%E5%88%92%E7%90%86%E8%AE%BA%E5%9F%BA%E7%A1%80.html 完全背包理论基础: https://programmercarl.com/%E8%83%8C%E5%8C%85%E9%97%AE%E9%A2%98%E7%90%86%E8%AE%BA%E5%9…...

rust - 将windows剪贴板的截图保存为png
本文提供了将windows系统的截图另存为png格式图片的方法。 添加依赖 cargo add clipboard-win cargo add image cargo add windows配置修改windows依赖特性 [dependencies] image "0.25.0"[target.cfg(windows).dependencies] windows "0.51.1" clipb…...

pyflink1.18.0 报错 TypeError: cannot pickle ‘_thread.lock‘ object
完整报错 Traceback (most recent call last):File "/Users//1.py", line 851, in <module>ds1 = my_datastream.key_by(lambda x: x[0]).process(MyProcessFunction()) # 返回元组即: f0 f1 f2 三列File "/Users/thomas990p/bigdataSoft/minicondaarm/…...
:Flood Fill算法)
算法学习系列(四十一):Flood Fill算法
目录 引言一、池塘计数二、城堡问题三、山峰和山谷 引言 关于这个 F l o o d F i l l Flood\ Fill Flood Fill 算法,其实我觉得就是一个 B F S BFS BFS 算法,模板其实都是非常相似的,只不过有些变形而已,然后又叫这个名字。关于…...

Re62:读论文 GPT-2 Language Models are Unsupervised Multitask Learners
诸神缄默不语-个人CSDN博文目录 诸神缄默不语的论文阅读笔记和分类 论文全名:Language Models are Unsupervised Multitask Learners 论文下载地址:https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learner…...

stm32-编码器测速
一、编码器简介 编码电机 旋转编码器 A,B相分别接通道一和二的引脚,VCC,GND接单片机VCC,GND 二、正交编码器工作原理 以前的代码是通过触发外部中断,然后在中断函数里手动进行计次。使用编码器接口的好处就是节约软件资源。对于频…...

全国各省市县统计年鉴/中国环境统计年鉴/中国工业企业数据库/中国专利数据库/污染排放数据库
统计年鉴是指以统计图表和分析说明为主,通过高度密集的统计数据来全面、系统、连续地记录年度经济、社会等各方面发展情况的大型工具书来获取统计数据资料。 统计年鉴是进行各项经济、社会研究的必要前提。而借助于统计年鉴,则是研究者常用的途径。目前国…...
MacOS和Win安装)
【LAMMPS学习】二、LAMMPS安装(2)MacOS和Win安装
2. LAMMPS安装 您可以将LAMMPS下载为可执行文件或源代码。 在下载LAMMPS源代码时,还必须构建LAMMPS。但是对于在构建中包含或排除哪些特性,您有更大的灵活性。当您下载并安装预编译的LAMMPS可执行文件时,您只能安装可用的LAMMPS版本以及这些…...

如何解决网络中IP地址发生冲突故障?
0、前言 本专栏为个人备考软考嵌入式系统设计师的复习笔记,未经本人许可,请勿转载,如发现本笔记内容的错误还望各位不吝赐教(笔记内容可能有误怕产生错误引导)。 1、个人IP地址冲突解决方案 首先winR,调出…...

机器学习常用框架
机器学习是人工智能的一个重要分支,它通过让计算机系统利用数据自我学习来改进任务执行的能力。在机器学习领域,有许多成熟的框架被广泛使用,这些框架提供了构建和训练机器学习模型的工具。以下是一些常用的机器学习框架: Tensor…...

计算机网络——物理层(信道复用技术)
计算机网络——物理层(信道复用技术) 信道复用技术频分多址与时分多址 频分复用 FDM (Frequency Division Multiplexing)时分复用 TDM (Time Division Multiplexing)统计时分复用 STDM (Statistic TDM)波分复用码分复用 我们今天接着来看信道复用技术&am…...

【Qt问题】使用QSlider创建滑块小部件无法显示
问题描述: 使用QSlider创建滑块小部件用于音量按钮的时候,无法显示,很奇怪,怎么都不显示 一直是这个效果,运行都没问题,但是就是不出现。 一直解决不了,最后我在无意中,在主程序中…...
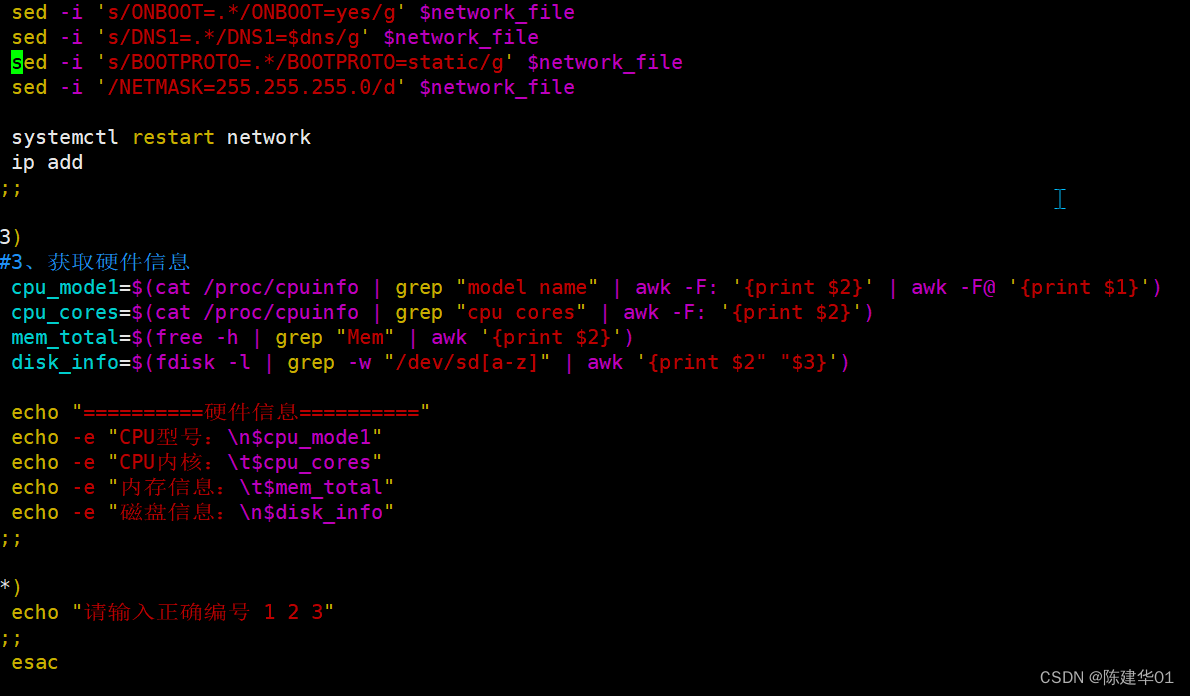
Linux--Shell脚本安装 httpd 和 修改IP
shell脚本 关闭防火墙、安装httpd、启动httpd [rootnode11 ~]# mkdir shell[rootnode11 ~]# vim abc.sh #!/bin/bash#安装httpd服务#1、挂载 准备yum源 mount /dev/sr0 /mnt &> /dev/nulldf$(df -h | grep /dev/sr0 | awk {print $6})if [ "$df" "/mn…...

mysql 常见问题
1、count(*) 、 count(1) 和 count(字段)区别 在MySQL中,COUNT(*)、COUNT(1) 和 COUNT(字段) 是用于统计行数的函数,它们的主要区别在于: COUNT(*):会统计符合条件的所有行的数量,不管这些行中…...

考研机试题
目录 头文件与STL动态规划最大数组子串和最长公共子序列最长连续公共子串最长递增子序列最大上升子序列和0-1背包多重背包多重背包问题 I整数拆分最小邮票最大子矩阵 数学问题朴素法筛素数线性筛素数快速幂 石子合并锯木棍并查集Dijkstra单源最短路Python进制转换(整数无限大)全…...
)
Java基础知识总结(6)
String类中常用的类方法: 方法名称描述format(String format, Object... args)使用指定的格式字符串和参数返回一个格式化字符串。 format - 格式字符串 args - 格式字符串中由格式说明符引用的参数。如果还有格式说明符以外的参数,则忽略这些额外的参数…...

JAVA基础—关于Java的反射机制
1. Java的反射机制是什么? 反射(reflection) 当我们谈及反射,可以将其比作正在照镜子的行为。就像你可以在禁止中看到自己的反射一样,程序在运行时可以检查自身的机构和行为。这意味这程序可以动态地了解自己地组成部分,比如类、…...

Hive中的explode函数、posexplode函数与later view函数
1.概述 在离线数仓处理通过HQL业务数据时,经常会遇到行转列或者列转行之类的操作,就像concat_ws之类的函数被广泛使用,今天这个也是经常要使用的拓展方法。 2.explode函数 2.1 函数语法 -- explode(a) - separates the elements of array …...

轻量级MCU命令行交互系统设计与优化
1. 轻量级MCU命令行交互系统设计指南1.1 系统概述在嵌入式系统开发过程中,调试和维护阶段往往需要与单片机进行参数交互和操作控制。传统解决方案如RT-Thread的finsh组件虽然功能强大,但对于资源受限的MCU(如ROM<64KB,RAM<8…...

三极管基极下拉电阻在高速电路中的关键作用解析
1. 三极管基极下拉电阻的基础认知 第一次接触三极管电路时,我和很多新手一样,对基极那个看似多余的下拉电阻充满疑惑。明明没有它电路也能工作,为什么工程师们总爱画蛇添足?直到有次调试电机驱动电路,三极管莫名其妙地…...

SEO_从基础到精通,系统学习SEO的完整路径解析
<h2>SEO的基础:了解搜索引擎优化的核心概念</h2> <p>搜索引擎优化(SEO)是一个广泛且复杂的领域,它的核心在于提升网站在搜索引擎结果页面(SERP)中的自然排名。了解SEO的基础概念是每一个…...

如何用NanoMsg的6种通信模式搞定分布式系统开发?附代码示例
如何用NanoMsg的6种通信模式构建高可靠分布式系统?实战代码解析 在分布式系统开发中,通信模式的选择往往决定了整个架构的扩展性和可靠性。NanoMsg作为轻量级高性能通信库,提供了6种经过验证的通信模式,每种都对应着特定的应用场景…...

Comsol异构电池力电热耦合模型:探索电池的多场奥秘
comsol异构电池力电热耦合模型 采用椭圆型电极颗粒模拟锂离子正负极的电极颗粒,还原真实电池的3D介观结构,耦合电化学场-热场-力学场,可模拟电流,浓度,温度,应力等多场结果在电池研究领域,深入理…...

C++ 模板与泛型编程入门
C 模板与泛型编程入门 模板把类型(及非类型参数)作为参数,在编译期由编译器按用法生成具体函数或类,是 C 泛型编程与 STL 的基础。下文以 Max、简单类模板、选择排序及可定制比较器为例说明常见写法;排序复杂度为 (O(…...

Genus水平共现网络分析:高效替代OTU的实战指南
1. 为什么需要Genus水平共现网络分析? 做微生物群落研究的朋友们应该都深有体会,OTU/ASV水平的共现网络分析简直就是个时间黑洞。我去年处理一个土壤微生物项目时,2000多个OTU的共现网络跑了整整8个小时,等结果的时候都能看完两集…...

Midscene.js从入门到精通:AI驱动的跨平台自动化技术指南
Midscene.js从入门到精通:AI驱动的跨平台自动化技术指南 【免费下载链接】midscene Let AI be your browser operator. 项目地址: https://gitcode.com/GitHub_Trending/mid/midscene 在数字化时代,软件界面的动态变化和跨平台兼容性给自动化测试…...

二分查找/二分答案
0.前言二分算法(Binary Search),也叫折半查找,是一种在有序数据集合中高效查找目标值的算法。它通过不断将查找范围缩小一半,快速定位目标,时间复杂度为 O(logn),远优于线性查找的 O(n)。1.原理…...

避坑指南:Virtio-PCI设备初始化失败的6个常见原因及解决方案
Virtio-PCI设备初始化故障深度排查手册 虚拟化技术在现代数据中心的应用已无处不在,而Virtio作为半虚拟化的事实标准协议,其PCI设备初始化过程却常常成为运维人员的"暗礁区"。上周处理某金融云平台故障时,我发现一个反复出现的现象…...