【运输层】TCP 的可靠传输是如何实现的?
目录
1、发送和接收窗口(滑动窗口)
(1)滑动窗口的工作流程
(2)滑动窗口和缓存的关系
(3)滑动窗口的注意事项
2、如何选择超时重传时间
(1)加权平均往返时间 RTTs
(2)Karn 算法
3、选择确认 SACK
1、发送和接收窗口(滑动窗口)
TCP 的滑动窗口是以字节为单位的。
(1)滑动窗口的工作流程
现假定 A 收到了 B 发来的确认报文段,其中窗口是 20 字节,而确认号是 31(这表明 B 期望收到的下一个字节序号是 31,而到序号 30 为止的数据已经收到了)。根据这两个数据,A 就构造出自己的发送窗口,如下图所示://发送窗口
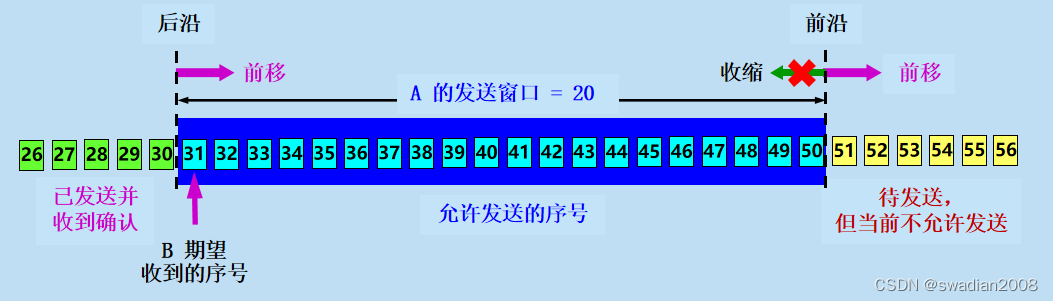
上图所示为 A 的发送窗口,发送窗口表示:在没有收到 B 的确认的情况下,A 可以连续把窗口内的数据都发送出去。凡是已经发送过的数据,在未收到确认之前都必须暂时保留,以便在超时重传时使用。
发送窗口里面的序号表示允许发送的序号。显然,窗口越大,发送方就可以在收到对方确认之前连续发送更多的数据,因而可能获得更高的传输效率。接收方会把自己的接收窗口数值放在窗口字段中发送给对方。因此,A 的发送窗口一定不能超过 B 的接收窗口数值。
发送窗口后沿的后面部分表示已发送且已收到了确认。这些数据显然不需要再保留了。而发送窗口前沿的前面部分表示不允许发送,因为接收方没有为这部分数据保留临时存放的缓存空间。//发送窗口的位置由窗口前沿和后沿的位置共同确定
现在假定 A 发送了序号为 31~41 的数据。这时,发送窗口位置并未改变,但发送窗口内靠后面有 11 个字节(灰色方框表示)表示已发送但未收到确认。而发送窗口内靠前面的 9 个字节(序号 42~50)是允许发送但尚未发送的。//发送窗口发送数据

再看一下 B 的接收窗口。设 B 的接收窗口大小是 20。在接收窗口外面,到序号为 30 的数据是已经发送过确认,并且已经交付主机了。因此在 B 可以不再保留这些数据。//接收窗口

接收窗口内的数据(序号31~50)是允许接收的。如上图所示,B 收到了序号为 32 和 33 的数据,但序号为 31 的数据没有收到(也许丢失了,也许滞留在网络中的某处)。请注意,B 只能对按序收到的数据中的最高序号给出确认,因此 B 发送的确认报文段中的确认号仍然是 31(即期望收到的序号)。
现在假定 B 收到了序号为 31 的数据,把序号为 31~33 的数据交付主机,删除这些数据。接着把接收窗口向前移动 3 个序号,如下图所示,同时给 A 发送确认,其中窗口值仍为 20,但确认号是 34。这表明 B 已经收到了到序号 33 为止的数据。//接收窗口接收数据
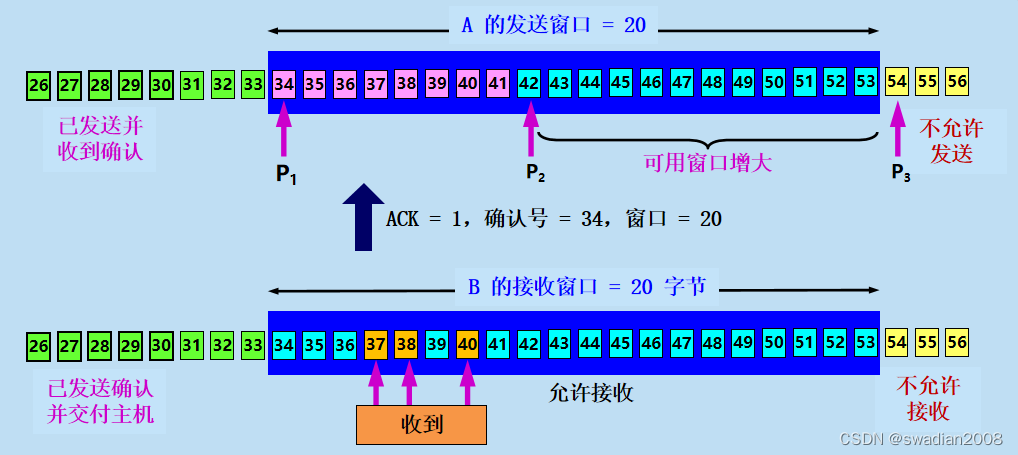
我们注意到,B 还收到了序号为 37,38 和 40 的数据,但这些数据都没有按序到达,只能先暂存在接收窗口中。A 收到 B 的确认后,就可以把发送窗口向前滑动 3 个序号,但指针 不动。可以看出,现在 A 的可用窗口增大了些,可发送的序号范围是 42~53。//窗口移动
A 在继续发送完序号 42~53 的数据后,指针 向前移动和
重合。
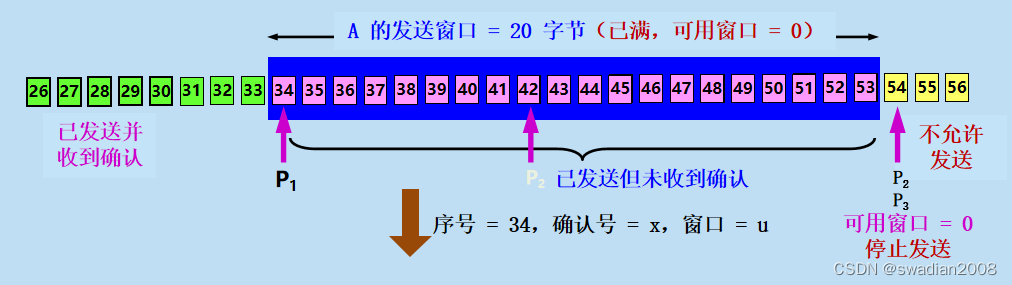
此时,发送窗口内的序号都已用完,但还没有再收到确认。由于 A 的发送窗口已满,可用窗口已减小到零,因此必须停止发送。
请注意,存在下面这种可能性,就是发送窗口内所有的数据都已正确到达 B,B 也早已发出了确认。但不幸的是,所有这些确认都滞留在网络中。在没有收到 B 的确认时,为了保证可靠传输,A 只能认为 B 还没有收到这些数据。于是,A 在经过一段时间后(由超时计时器控制)就重传这部分数据,重新设置超时计时器,直到收到 B 的确认为止。如果 A 按序收到落在发送窗口内的确认号,那么 A 就可以使发送窗口继续向前滑动,并发送新的数据。//此时可能会发生消息重传
(2)滑动窗口和缓存的关系
上边过程中,提到了缓存,那么窗口和缓存有什么关系呢?
这个关系就是:发送方的应用进程会把字节流写入 TCP 的发送缓存,接收方的应用进程从 TCP 的接收缓存中读取字节流。
发送窗口和发送缓存:
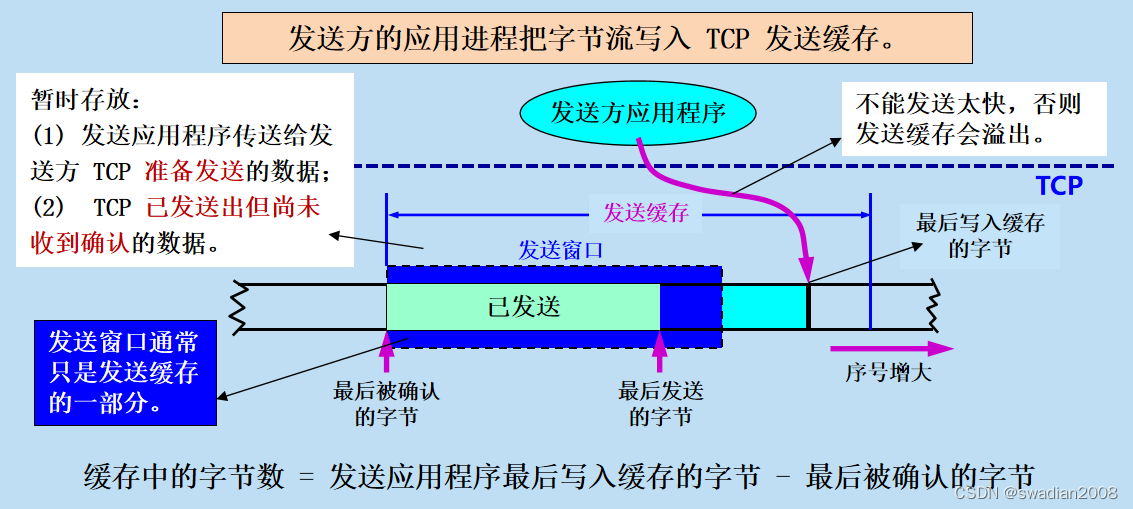
发送缓存用来暂时存放:
- 发送应用程序传送给发送方 TCP 准备发送的数据
- TCP 已发送出但尚未收到确认的数据
发送窗口通常只是发送缓存的一部分。已被确认的数据应当从发送缓存中删除,因此发送缓存和发送窗口的后沿是重合的。发送应用程序最后写入发送缓存的字节减去最后被确认的字节,就是还保留在发送缓存中的被写入的字节数。发送应用程序必须控制写入缓存的速率,不能太快,否则发送缓存就会没有存放数据的空间。
接收窗口和接收缓存:

接收缓存用来暂时存放:
- 按序到达的、但尚未被接收应用程序读取的数据
- 未按序到达的数据。
如果收到的分组被检测出有差错,则要丢弃。如果接收应用程序来不及读取收到的数据,接收缓存最终就会被填满,使接收窗口减小到零。反之,如果接收应用程序能够及时从接收缓存中读取收到的数据,接收窗口就可以增大,但最大不能超过接收缓存的大小。
(3)滑动窗口的注意事项
第一,虽然 A 的发送窗口是根据 B 的接收窗口设置的,但在同一时刻,A 的发送窗口并不总是和 B 的接收窗口一样大。这是因为通过网络传送窗口值需要经历一定的时间滞后(这个时间是不确定的)。另外,发送方 A 还可能根据网络当时的拥塞情况适当减小自己的发送窗口数值。
第二,对于不按序到达的数据应如何处理,TCP 标准并无明确规定。如果接收方把不按序到达的数据一律丢弃,那么接收窗口的管理将会比较简单,但这样做对网络资源的利用不利(因为发送方会重复传送较多的数据)。因此 TCP 通常是把不按序到达的数据先临时存放在接收窗口中,等到字节流中所缺少的字节收到后,再按序交付上层的应用进程。
第三,TCP 要求接收方必须有累积确认的功能,这样可以减小传输开销。接收方可以在合适的时候发送确认,也可以在自己有数据要发送时把确认信息顺便捎带上。但请注意两点。一是接收方不应过分推迟发送确认,否则会导致发送方不必要的重传,这反而浪费了网络的资源。TCP 标准规定,确认推迟的时间不应超过 0.5 秒。若收到一连串具有最大长度的报文段,则必须每隔一个报文段就发送一个确认。二是捎带确认实际上并不经常发生,因为大多数应用程序很少同时在两个方向上发送数据。
此外,TCP 的通信是全双工通信。通信中的每一方都在发送和接收报文段。因此,每一方都有自己的发送窗口和接收窗口。
2、如何选择超时重传时间
为什么说选择超时重传时间是 TCP 最复杂的问题之一呢?
由于 TCP 的下层是互联网环境,发送的报文段可能只经过一个高速率的局域网,也可能经过多个低速率的网络,并且每个 IP 数据报所选择的路由还可能不同。如果把超时重传时间设置得太短,就会引起很多报文段的不必要的重传,使网络负荷增大。但若把超时重传时间设置得过长,则又使网络的空闲时间增大,降低了传输效率。

那么,运输层的超时计时器的超时重传时间究竟应设置为多大呢?
(1)加权平均往返时间 RTTs
TCP 采用了一种自适应算法,它记录一个报文段发出的时间,以及收到相应的确认的时间。这两个时间之差就是报文段的往返时间 RTT。TCP 保留了 RTT 的一个加权平均往返时间 RTTs(这又称为平滑的往返时间,S 表示 Smoothed)。每当第一次测量到 RTT 样本时,RTTs 值就取为所测量到的 RTT 样本值。以后每测量到一个新的 RTT 样本,就按下式重新计算一次 RTTs:
新的RTTs = (1 - )* (旧的RTTs)+
*(新的RTT样本)
- 其中,
- 若
,表示 RTT 值更新较慢
- 若
,表示 RTT 值更新较快
- RFC 6298 推荐的
值为 1/8,即 0.125
显然,超时计时器设置的超时重传时间 RTO (RetransmissionTime-Out) 应略大于上面得出的加权平均往返时间 RTTs。RFC 6298 建议使用下式计算 RTO:
RTO = RTTs + 4 *
而 是 RTT 的偏差的加权平均值,它与 RTTs 和新的 RTT 样本之差有关。当第一次测量时,
值取为测量到的 RTT 样本值的一半。在以后的测量中,则使用下式计算加权平均的
:
新的 = (1 -
)* (旧的
)+
* | RTTs - 新的RTT样本 |
这里 是个小于 1 的系数,它的推荐值是 1/4,即 0.25。
//这些公式看起来多,实际上理解并不复杂,就是在 RTT 的加权平均值上做了一点点改动而已
上面所说的往返时间的测量方法理解起来很简单,但实现起来却相当复杂。
如下图所示,发送出一个报文段,设定的重传时间到了,还没有收到确认,于是重传报文段。经过了一段时间后,收到了确认报文段。

现在的问题是:如何判定此确认报文段是对先发送的报文段的确认,还是对后来重传的报文段的确认呢?
由于重传的报文段和原来的报文段完全一样,因此源主机在收到确认后,就无法做出正确的判断,而正确的判断对确定加权平均 RTTs 的值关系很大。
困惑的问题:重传确认影响重传时间 RTO计算不准确
若收到的确认是对重传报文段的确认,但却被源主机当成是对原来的报文段的确认,则这样计算出的 RTTs 和超时重传时间 RTO 就会偏大。若后面再发送的报文段又是经过重传后才收到确认报文段,则按此方法得出的超时重传时间 RTO 就越来越长。
同样,若收到的确认是对原来的报文段的确认,但被当成是对重传报文段的确认,则由此计算出的 RTTs 和 RTO 都会偏小。这就必然导致报文段过多地重传。这样就有可能使 RTO 越来越短。
(2)Karn 算法
根据以上所述,Karn 提出了一个算法:在计算加权平均 RTTs 时,只要报文段重传了,就不采用其往返时间样本。这样得出的加权平均 RTTs 和 RTO 就较准确。//Karn算法
但是,这又引起新的问题。设想出现这样的情况:报文段的时延突然增大了很多。因此在原来得出的重传时间内不会收到确认报文段,于是就重传报文段。但根据 Karn 算法,不考虑重传的报文段的往返时间样本。这样,超时重传时间就无法更新。
可借鉴的思想和改进:
因此要对 Karn 算法进行修正。方法是:报文段每重传一次,就把超时重传时间 RTO 增大一些。典型的做法是取新的重传时间为旧的重传时间的 2 倍。当不再发生报文段的重传时,才根据上面给出的计算公式计算超时重传时间。
所以,Karn 算法能够使运输层区分开有效的和无效的往返时间样本,从而改进了往返时间的估测,使计算结果更加合理。
3、选择确认 SACK
若收到的报文段无差错,只是未按序号,中间还缺少一些序号的数据,那么能否设法只传送缺少的数据而不重传已经正确到达接收方的数据呢?
答案是可以的。选择确认(Selective ACK) 就是一种可行的处理方法。
下边用一个例子来说明选择确认的工作原理。
TCP 的接收方在接收对方发送过来的数据字节流的序号不连续,结果就形成了一些不连续的字节块。下图中,序号 1~1000 收到了,但序号 1001 ~1500 没有收到。接下来的字节流又收到了,可是又缺少了 3001 ~ 3500。再后面从序号 4501 起又没有收到。也就是说,接收方收到了和前面的字节流不连续的两个字节块。
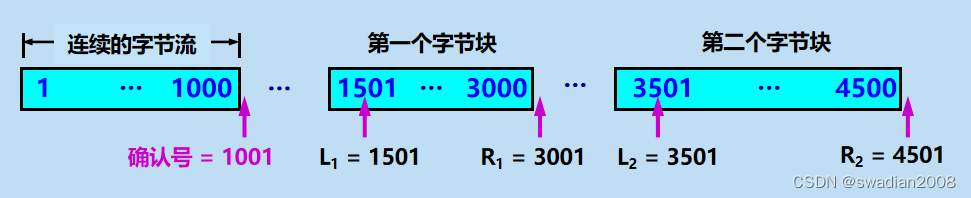
如果这些字节的序号都在接收窗口之内,那么接收方就先收下这些数据,但要把这些信息准确地告诉发送方,使发送方不要再重复发送这些已收到的数据。//解决问题的思路
从上图可看出,和前后字节不连续的每一个字节块都有两个边界:左边界和右边界,因此在图中用四个指针标记这些边界。请注意,第一个字节块的左边界 L1 = 1501,但右边界 R1 = 3001 而不是 3000。这就是说,左边界指出字节块的第一个字节的序号,但右边界减 1 才是字节块的最后一个序号。
我们知道,TCP 的首部没有哪个字段能够提供上述这些字节块的边界信息。RFC 2018规定,如果要使用选择确认 SACK,那么在建立 TCP 连接时,就要在 TCP 首部的选项中加上“允许SACK”的选项,而双方必须都事先商定好。如果使用选择确认,那么原来首部中的“确认号字段”的用法仍然不变。只是以后在 TCP 报文段的首部中都增加了 SACK 选项,以便报告收到的不连续的字节块的边界。//设置SACK的值时需要考虑TCP首部选项的长度的限制
然而,SACK 文档并没有指明发送方应当怎样响应 SACK。因此大多数的实现还是重传所有未被确认的数据块。//所以,你知道TCP进行选择确认的具体实现方案吗?如果有,请分享给我,谢谢
至此,全文结束。
相关文章:
【运输层】TCP 的可靠传输是如何实现的?
目录 1、发送和接收窗口(滑动窗口) (1)滑动窗口的工作流程 (2)滑动窗口和缓存的关系 (3)滑动窗口的注意事项 2、如何选择超时重传时间 (1)加权平均往返…...
K8s技术全景:架构、应用与优化
一、介绍 Kubernetes的历史和演进 Kubernetes(简称K8s)是一个开源的容器编排系统,用于自动化应用程序的部署、扩展和管理。它最初是由Google内部的Borg系统启发并设计的,于2014年作为开源项目首次亮相。 初始阶段 Kubernetes的诞生…...

Java的异常机制
异常机制 三种类型 检查型异常:程序员无法预见的运行时异常:在编译时会被忽略错误ERROR:错误在代码中被忽略,在编译时检查不到 异常处理机制 抛出异常捕获异常异常处理的五个关键字:try,catchÿ…...
考虑预同步的虚拟同步机T型三电平逆变器并离网MATLAB仿真模型
微❤关注“电气仔推送”获得资料(专享优惠) 模型简介 三相 T 型三电平逆变器电路如图所示,逆变器主回路由三个单相 T 型逆变器组成。 直流侧输入电压为 UPV,直流侧中点电位 O 设为零电位,交流侧输出侧是三相三线制连…...

记一次k8s取证检材过期的恢复
复盘盘古石k8s的时候碰到了证书过期的问题,在此记录解决方法 报错信息:192.168.91.171:6443 was refused - did you specify the right host or port? 查看证书是否过期 kubeadm alpha certs check-expiration或 openssl x509 -in /etc/kubernetes/…...
【网站项目】自助购药小程序
🙊作者简介:拥有多年开发工作经验,分享技术代码帮助学生学习,独立完成自己的项目或者毕业设计。 代码可以私聊博主获取。🌹赠送计算机毕业设计600个选题excel文件,帮助大学选题。赠送开题报告模板ÿ…...

Ubuntu22.04修改默认窗口系统为X11
Ubuntu22.04安装默认窗口系统为Wayland(通过设置->关于可以看到)。 一、用Ubuntu on Xorg会话登录 用户登录时,点“未列出”,输入用户名后,在登录界面底部的齿轮图标中,选择 "Ubuntu on Xorg&quo…...

延时队列实现实战:如何利用 RabbitMQ 实现延时队列,以满足特定延迟处理需求
实现延时队列,可以通过RabbitMQ的死信队列(Dead-letter queue)特性,“死信队列”是当消息过期,或者队列达到最大长度时,未消费的消息会被加入到死信队列。然后,我们可以对死信队列中的消息进行消…...

关于在Ubuntu上配置mysql踩的一些坑
最近准备换工作了,回顾了下学校时期做的那个webserver,又在linux下mysql踩了一些坑,特此记录下来 程序编译错误mysql.h: No such file or directory 云服务器缺少mysql必要的运行组件,安装: sudo apt-get install l…...
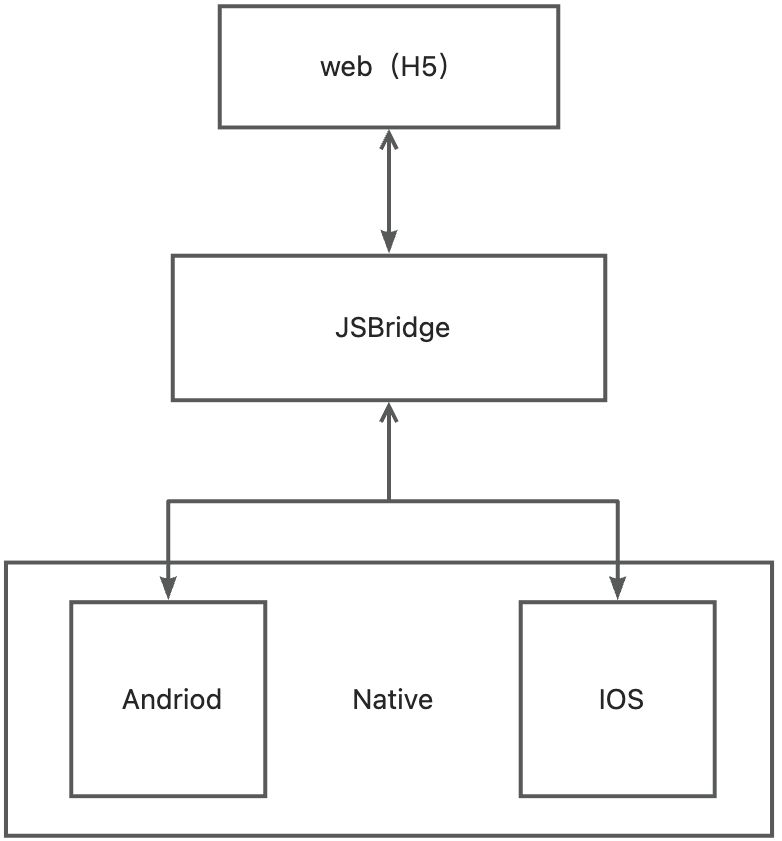
JSBridge原理 - 前端H5与客户端Native交互
1. 概述: 在混合应用开发中,一种常见且成熟的技术方案是将原生应用与 WebView 结合,使得复杂的业务逻辑可以通过网页技术实现。实现这种类型的混合应用时,就需要解决H5与Native之间的双向通信。JSBridge 是一种在混合应用中实现 …...

【Java EE】Spring请求如何传递参数详解
文章目录 🎍传递单个参数🌴传递多个参数🍀传递对象🎄后端参数重命名(后端参数映射)🌲传递数组🎍传递集合🌴传递JSON数据🌸JSON概念🌸JSON的语法&a…...

菜鸟笔记-Numpy常用函数用法汇总
NumPy(Numerical Python的简称)是Python中用于处理数组和矩阵的库,提供了大量的数学函数来操作这些数组。通过前面的学习,慢慢也能发现一些规律,以下是NumPy的一些常用函数及其用法汇总: 数组创建 numpy.a…...
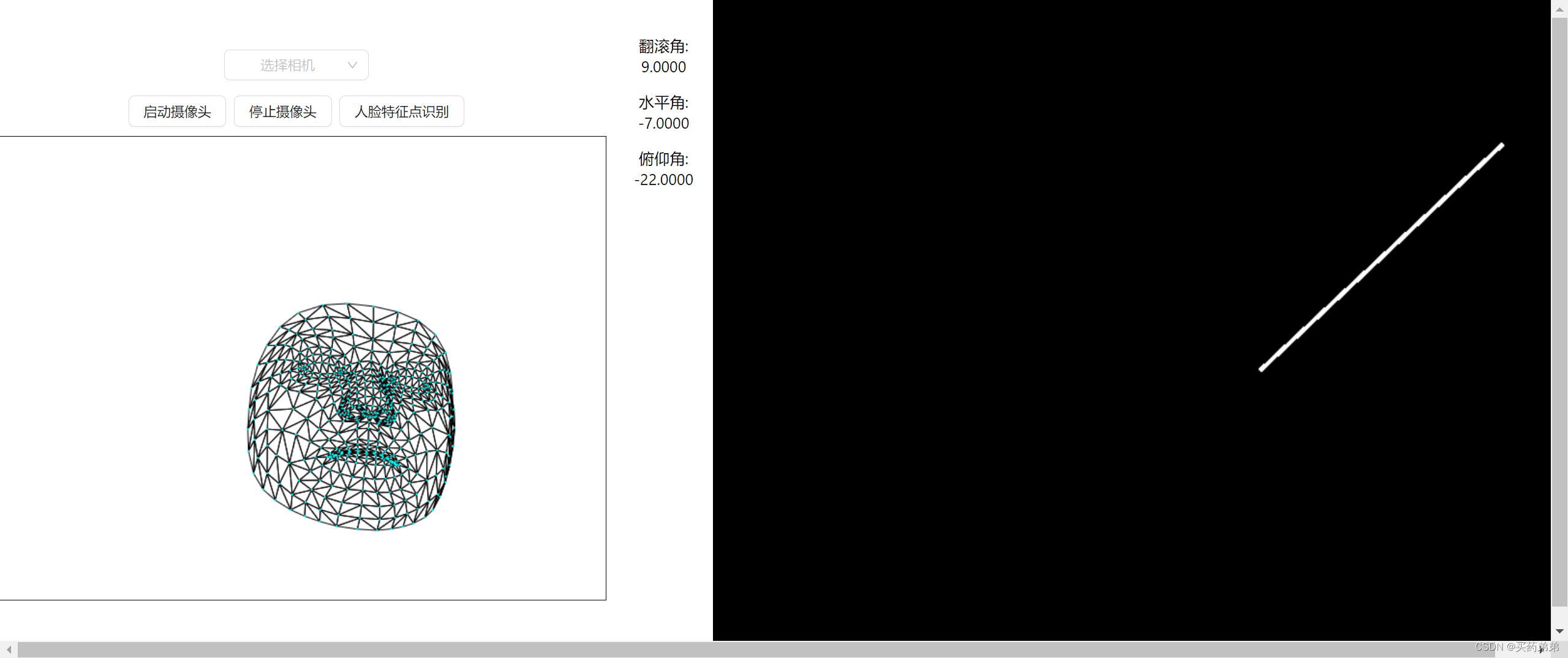
tensorflow.js 如何使用opencv.js通过面部特征点估算脸部姿态并绘制示意图
文章目录 前言一、实现步骤1. 获取所需特征点的索引2. 使用opencv.js 计算俯仰角、水平角和翻滚角cv.solvePnP介绍cv.solvePnP原理运行代码查看效果 3.绘制姿态示意直线添加canvas元素计算姿态直线坐标并绘制 总结 前言 在计算机视觉领域,估算脸部姿态是一项具有挑…...
)
Linux命令-dpkg-divert命令(Debian Linux中创建并管理一个转向列表)
说明 dpkg-divert命令 是Debian Linux中创建并管理一个转向(diversion)列表,其使得安装文件的默认位置失效的工具。 语法 dpkg-divert(选项)(参数)选项 --add:添加一个转移文件; --remove:删除一个转移…...

flex: 1 是哪些属性的缩写?
flex:1是哪些属性的缩写? flex:1 是 flex-grow: 1, flex-shrink: 1,flex-basis: 0% 的缩写; 解释下flex-grow flex-grow是将剩余的空间,根据flex-grow的值平分,然后加到flex-basis上 <!doctype html> <htm…...

python基于opencv实现数籽粒
千粒重是一个重要的农艺性状,通过对其的测量和研究,我们可以更好地理解作物的生长状况,优化农业生产,提高作物产量和品质。但数籽粒数目是一个很繁琐和痛苦的过程,我们现在用一个简单的python程序来数水稻籽粒。代码的…...

OpenCV图像处理——基于OpenCV的ORB算法实现目标追踪
概述 ORB(Oriented FAST and Rotated BRIEF)算法是高效的关键点检测和描述方法。它结合了FAST(Features from Accelerated Segment Test)算法的快速关键点检测能力和BRIEF(Binary Robust Independent Elementary Feat…...

13.JavaWeb XML:构建结构化数据的重要工具
目录 导语: 一、XML概念 (1)可拓展 (2)功能-存储数据 (3)xml与html的区别 二、XML内容 三、XML用途 四、案例:使用XML构建在线书店的书籍数据库 结语: 导语&…...

鸿蒙OS实战开发:【多设备自适应服务卡片】
介绍 服务卡片的布局和使用,其中卡片内容显示使用了一次开发,多端部署的能力实现多设备自适应。 用到了卡片扩展模块接口,[ohos.app.form.FormExtensionAbility] 。 卡片信息和状态等相关类型和枚举接口,[ohos.app.form.formInf…...
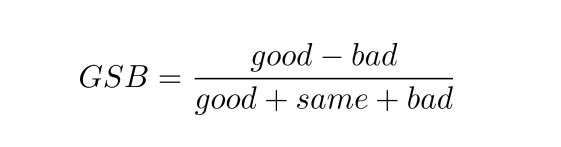
深度学习基础之一:机器学习
文章目录 深度学习基本概念(Basic concepts of deep learning)机器学习典型任务机器学习分类 模型训练的基本概念基本名词机器学习任务流程模型训练详细流程正、反向传播学习率Batch size激活函数激活函数 sigmoid 损失函数MSE & M交叉熵损失 优化器优化器 — 梯度下降优化…...

通过curl命令在无SDK环境中测试Taotoken接口连通性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令在无SDK环境中测试Taotoken接口连通性 在服务器管理、持续集成流水线或轻量级容器环境中,你可能需要在没有…...

氯气,氯水,液溴,溴水,溴的四氯化碳溶液,碘单质,碘水的颜色分别是什么?
一、氯气(Cl₂)及其溶液物质颜色备注氯气(气体)黄绿色常温下为有刺激性气味的气体氯水(水溶液)淡黄绿色因溶解少量氯气分子(Cl₂)所致;久置后因生成HClO和HCl,…...

从Typora迁移到Obsidian,我踩过的那些坑和高效配置方案
从Typora迁移到Obsidian:无缝过渡的深度实践指南 当我在2022年决定将积累了5年的技术笔记库从Typora迁移到Obsidian时,最初以为只是换个编辑器那么简单。直到实际操作时才发现,这两个看似相似的Markdown工具在使用哲学和操作细节上存在诸多差…...

STC8H8K64U USB下载避坑指南:实测与手册不一样的P3.2引脚操作细节
STC8H8K64U USB下载实战:破解P3.2引脚的操作玄机 第一次接触STC8H8K64U的USB下载功能时,本以为按照官方手册按部就班就能轻松搞定,没想到实际操作中P3.2引脚的行为完全出乎意料。这个看似简单的接地操作背后,隐藏着芯片内部状态机…...

Android项目集成CH340串口驱动:从官方Demo到体温检测模块的完整配置流程
Android项目集成CH340串口驱动:从官方Demo到体温检测模块的完整配置流程 在医疗设备、工业控制等物联网场景中,Android设备与外围硬件通过串口通信的需求日益增长。CH340作为一款高性价比的USB转串口芯片,因其稳定性和广泛兼容性成为许多硬件…...

NotebookLM如何让AI替你精准定位审稿人潜台词?——基于572份Accepted回复文本的NLP语义聚类分析
更多请点击: https://intelliparadigm.com 第一章:NotebookLM如何让AI替你精准定位审稿人潜台词?——基于572份Accepted回复文本的NLP语义聚类分析 从“Minor Revision”到“Strong Accept”的语义解码 NotebookLM 的文档锚定(D…...

智能体状态管理:会话、上下文与检查点
从一个“跑了三天三夜的Agent突然失忆”说起,聊聊状态管理的那些坑先给你讲一个让我头皮发麻的运维事故。 去年冬天,我们做了一个自动爬取竞品价格并生成调价建议的Agent。它跑得很好,连续工作了三天,完成了两万多件商品的价格监控…...

避坑指南:SAP BP客户维护cl_md_bp_maintain的那些“坑”与最佳实践
SAP BP客户维护实战:cl_md_bp_maintain深度避坑手册 当ABAP开发人员第一次接触cl_md_bp_maintain类时,往往会被其强大的业务伙伴(Business Partner)管理功能所吸引,但随之而来的是一系列令人头疼的"坑"。本文将从实际项目经验出发&…...

Multisim导入自定义三极管S8050/S8550保姆级教程:从SPICE文件到成功仿真
Multisim实战:从零构建S8050三极管模型与仿真验证全流程 在电子电路设计与仿真领域,准确的三极管模型往往是项目成功的关键。许多工程师和爱好者在使用Multisim时都遇到过这样的困境:官方元件库中缺少特定型号的三极管(如常见的S8…...

gptree:为AI生成项目结构报告,提升代码分析与协作效率
1. 项目概述与核心价值最近在整理个人项目和代码库时,我遇到了一个几乎所有开发者都会头疼的问题:项目越做越多,文件夹嵌套越来越深,README写得再好,时间一久也记不清某个具体功能的实现细节藏在哪个文件的哪个角落里。…...