不用从头训练,通过知识融合创建强大的统一模型
在自然语言处理(NLP)领域,大型语言模型(LLMs)的开发和训练是一个复杂且成本高昂的过程。数据需求是一个主要问题,因为训练这些模型需要大量的标注数据来保证其准确性和泛化能力;计算资源也是一个挑战,因为需要巨大的算力来处理和训练这些数据。最重要的是经济成本,这包括了硬件投资、电力消耗以及维护费用等。
除了成本问题,模型能力的局限性也是一个关键问题。不同的LLMs可能在特定的任务或领域上表现出色,但可能在其他任务上表现不佳。这种局限性意味着,尽管单个模型可能非常强大,但它们可能无法覆盖所有类型的语言理解和生成任务。另外,模型间的冗余能力也是一个问题,因为不同的模型可能在某些功能上存在重叠,这导致资源和努力的浪费。
为了克服这些挑战,研究者们开始探索知识融合这一概念。知识融合的目标是将多个预训练的LLMs的能力结合起来,形成一个统一的模型,这个模型能够继承所有源模型的优势,并在广泛的任务上表现出色。这种方法不仅可以减少重新训练模型的需求,还可以通过结合不同模型的专长来提高整体性能。

传统模型融合技术通常包括两种方式:
- 集成(Ensemble):这种方法通过直接聚合不同模型的输出来增强预测性能和鲁棒性。这可能涉及到加权平均或多数投票等技术,但它要求在推理时同时维护多个训练好的模型。
- 权重合并(Weight Merging):此方法通过参数级的算术操作直接合并几个神经网络,通常假设网络架构是统一的,并尝试在不同神经网络的权重之间建立映射。
FUSELLM方法则采用了一种新颖的视角:
- 知识外化:FUSELLM通过使用源LLMs生成的概率分布来外化它们的集体知识和独特优势。
- 轻量级持续训练:目标LLM通过这种训练,最小化其概率分布与源LLMs生成的概率分布之间的差异,从而获得提升。
与传统的训练方法相比,知识融合不寻求从头开始训练一个全新的模型,而是通过合并现有的预训练模型来创建一个功能更强大的统一模型。
在传统的训练方法中,每个LLM都是独立训练的,这意味着每个模型都是从零开始学习,需要大量的数据和计算资源。此外,由于每个模型的架构和训练数据可能不同,它们在不同任务上的表现也会有差异。例如,一个模型可能在文本分类任务上表现出色,而在机器翻译任务上则不尽如人意。这种独立训练的方法不仅效率低下,而且无法充分利用已有模型的知识。
知识融合的核心思想是将多个源LLMs的知识进行外化和转移,通过这种方式,目标模型可以继承并整合所有源模型的优势。这一过程的第一步是生成概率分布矩阵,这是通过使用源LLMs对输入文本进行预测来实现的。每个模型都会生成一个表示其对文本理解的概率分布矩阵,这些矩阵随后被用来指导目标模型的训练。
为了解决不同模型间词汇表不一致的问题,研究者们采用了一种新颖的令牌对齐策略,即最小编辑距离(MinED)方法。这种方法通过计算不同模型生成的令牌之间的编辑距离来实现对齐,从而允许不同模型的概率分布矩阵之间进行有效的映射。
接下来是概率分布的融合阶段,这是知识融合方法的关键创新之一。研究者们提出了两种融合函数:最小交叉熵(MinCE)和平均交叉熵(AvgCE)。MinCE方法选择交叉熵损失最小的分布矩阵作为融合结果,而AvgCE方法则根据每个模型的交叉熵损失对所有分布矩阵进行加权平均。这些融合函数的目的是在保留源模型独特优势的同时,整合它们的集体知识。
目标模型通过持续训练进行更新,这个过程涉及到最小化目标模型的概率分布与融合后的概率分布之间的差异。与传统的从头开始训练相比,这种轻量级的持续训练大大减少了所需的资源和时间。

以上是FUSELLM方法的完整过程在算法。FUSELLM算法可以应用于任何需要融合多个预训练LLMs的场景,特别是在资源有限或需要快速提升模型性能的情况下。通过这种方法,研究者和开发者可以有效地利用现有的模型资源,创造出更强大的语言处理能力。
研究者们精心挑选了适合的源LLMs,并对它们进行了融合。实验使用了MiniPile数据集,这是一个经过精简但内容丰富的语料库,它来源于The Pile,包含了约100万文档和1.8亿个token,覆盖了22个不同的领域。
在训练过程中,采用了Llama-2 7B模型作为目标模型,并使用AdamW优化器进行参数更新,同时采用了余弦学习率调度策略,以提高训练效率。
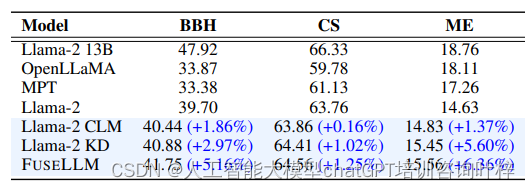
实验结果令人鼓舞,FUSELLM在多个基准测试中展现了其优越性。在Big-Bench Hard (BBH)、Common Sense (CS)和MultiPL-E (ME)等基准测试中,FUSELLM的性能在大多数任务上都超过了单独的源LLMs和基线模型。例如,在BBH任务中,FUSELLM的平均性能提升为5.16%,在CS任务中为1.25%,在ME任务中为6.36%。这些结果表明,FUSELLM能够有效地整合不同源LLMs的知识,并在广泛的任务上提升性能。


研究者们还深入分析了融合概率分布对训练过程的影响。通过比较FUSELLM和单独的Llama-2 CLM(持续语言模型)在不同规模训练数据上的表现,发现FUSELLM在训练过程中能够更快地达到更高的准确率,并且需要的训练token数量显著减少。这一发现证实了融合概率分布包含了比原始文本序列更易于学习的知识,从而加速了优化过程。
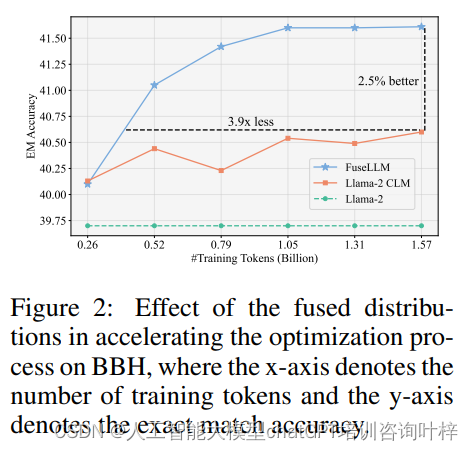
实验还包括了对FUSELLM实现过程中关键元素的分析。这包括了对源LLMs数量的影响、不同令牌对齐标准的效果以及不同融合函数的选择。研究者们发现,随着融合的源LLMs数量增加,FUSELLM的性能也随之提升。此外,最小编辑距离(MinED)方法在令牌对齐上优于精确匹配(EM)方法,而最小交叉熵(MinCE)作为融合函数在所有基准测试中均优于平均交叉熵(AvgCE)。

知识蒸馏是一种常见的技术,通过训练一个学生模型来模仿教师模型的行为。实验结果表明,尽管知识蒸馏能够提升模型性能,但FUSELLM通过结合三个7B模型的持续训练,相比于从单一13B模型中提取知识的蒸馏方法,取得了更显著的性能提升。
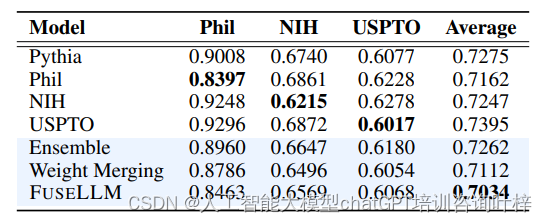
最后,研究者们还将FUSELLM与其他模型融合技术,如模型集成和权重合并,进行了比较。在模拟了多个具有相同基础模型结构但训练数据不同的LLMs的场景中,FUSELLM在所有测试域中都实现了最低的平均困惑度(perplexity),这表明其在整合多样化模型知识方面的有效性超过了传统的集成和合并方法。
FUSELLM方法成功地展示了如何通过知识融合提升LLMs的性能。该方法不仅减少了初始训练的成本,还允许目标模型继承并超越所有源模型的能力。这一发现为未来LLMs的研究和应用提供了新的方向。
论文地址:https://arxiv.org/pdf/2401.10491.pdf
git: https://github.com/fanqiwan/FuseLLM
相关文章:
不用从头训练,通过知识融合创建强大的统一模型
在自然语言处理(NLP)领域,大型语言模型(LLMs)的开发和训练是一个复杂且成本高昂的过程。数据需求是一个主要问题,因为训练这些模型需要大量的标注数据来保证其准确性和泛化能力;计算资源也是一个…...

僵尸进程、孤儿进程、守护进程
【一】僵尸进程和孤儿进程 【1】引入 我们知道在unix/linux中,正常情况下,子进程是通过父进程创建的,子进程在创建新的进程。 子进程的结束和父进程的运行是一个异步过程,即父进程永远无法预测子进程 到底什么时候结束。 当一个 进程完成它…...
【工程化】CJS 和 ESM
common js require 函数的原理伪代码: function require(path) {if (该模块有缓存) {return 该模块的缓存}function _run(exports, require, module, __filename, __dirname) {// 模块代码}// module.exports 即为模块导出的对象var module { exports: {} };_run…...

记录:mac pro 16-inch,2019安装ubuntu双系统
需要的装备:u盘,扩展坞、有线键鼠、ext4硬盘 目的:编译aosp 11 1、首先是参照如下文章,分配空间,制作启动盘(测试ubuntu20.04不行,ubuntu22.04正常) https://blog.csdn.net/LBSGKD…...
WordPress主题 7B2 PRO 5.4.2 免授权开心版源码
本资源提供给大家学习及参考研究借鉴美工之用,请勿用于商业和非法用途,无任何技术支持! WordPress主题 7B2 PRO 5.4.2 免授权开心版源码 B2 PRO 5.4.2 最新免授权版不再需要改hosts,和正版一样上传安装就可以激活。 直接在Word…...
GPT‑4o普通账户也可以免费用
网址 https://chatgpt.com/ 试了一下,免费的确实显示GPT‑4o的模型,问了一下可以联网,不知道能不能通过插件出图 有兴趣的可以试试...

复制即用!纯htmlcss写的炫酷input输入框
一般我们写css样式都要用样式库,但是嫌麻烦,如果能找到现成的内容复制上去就很香了,下文是笔者觉得好看的纯html&css写的样式,可以直接复制到Vue等内,十分方便。 input组件 1) 下面这个很推荐&#…...

前端 CSS 经典:弧形边框选项卡
1. 效果图 2. 开始 准备一个元素,将元素左上角,右上角设为圆角。 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8" /><meta name"viewport" content"widthdevice-width, i…...

前端面试题日常练-day21 【面试题】
题目 希望这些选择题能够帮助您进行前端面试的准备,答案在文末。 AJAX 是什么的缩写? a) Asynchronous JavaScript and XMLb) Asynchronous JavaScript and XHTMLc) Asynchronous Java and XMLd) Asynchronous Java and XHTML使用 AJAX 可以实现以下哪…...

几起 Linux 问题解决分享
(首发地址:学习日记 https://www.learndiary.com/2024/05/linux-problems/) 朋友们,大家好!我是淘宝网学习日记小店专注于Linux服务领域的 learndiary,今天很高兴能与大家分享近期处理的一些Linux故障案例&…...

LeetCode题解:9. 回文数,翻转一半数字,JavaScript,详细注释
原题链接 9. 回文数 解题思路 翻转数字 利用循环,每次将x右移一位将移出的数字存储到reversed的个位中每次存储前,需要将reversed左移一位 判断结果 当原x的长度为偶数,翻转后的结果相等当原x的长度为奇数,reversed一定比翻转后…...

微博:一季度运营利润9.11亿元,经营效率持续提升
5月23日,微博发布2024年第一季度财报。一季度微博总营收3.955亿美元,约合28.44亿元人民币,超华尔街预期。其中,广告营收达到3.39亿美元,约合24.39亿元人民币。一季度调整后运营利润达到1.258亿美元,约合9.1…...

Mysql总结1
Mysql常见日志 (1)错误日志:记录数据库服务器启动、停止、运行时存在的问题; (2)慢查询日志:记录查询时间超过long_query_time的sql语句,其中long_query_time可配置,且…...

three.js能实现啥效果?看过来,这里都是它的菜(05)
这是第五期了,本期继续分享three.js可以实现的3D动画案例,捎带讲一下如何将模型导入到three.js中。 如何将模型导入three.js中 three.js可以通过多种方式导入3D模型,以下是其中几种常见的方法: 使用three.js自带的OBJLoader或M…...

innerText和innerHTML的区别
innerHTML和innerText都是元素的属性,通过修改这个元素的属性可以达到修改元素内容的目的。但是二者之间略有不同。具体来说,它们的区别如下: innerHTML可以获取或设置元素内部的HTML内容,包括HTML标签,而innerText则…...
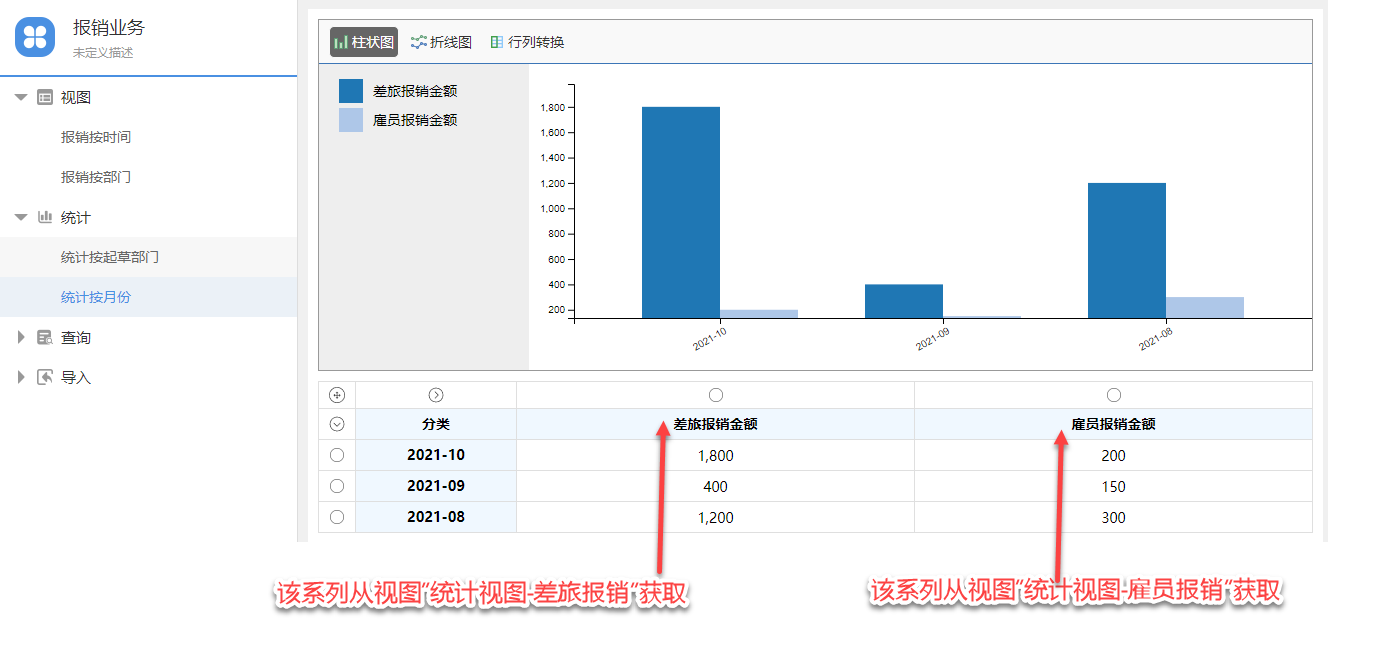
O2OA(翱途)开发平台数据统计如何配置?
O2OA提供的数据管理中心,可以让用户通过配置的形式完成对数据的汇总,统计和数据分组展现,查询和搜索数据形成列表数据展现。也支持用户配置独立的数据表来适应特殊的业务的数据存储需求。本文主要介绍如何在O2OA中开发和配置统计。 一、先决…...

网关过滤器使用及其原理分析
1.网关过滤器介绍 网关过滤器的用途一般是修改请求或响应信息,例如编解码、Token验证、流量复制等 官方文档地址:Spring Cloud Gateway 网关过滤器分为GloablFilter、GatewayFilter及DefaultFilter 过滤器的执行顺序由Order决定,Order值越小,优先级越高,越先执行 1.1…...

jiebaNET中文分词器
最近我接手了一个有趣的需求,需要对用户评价进行分词,进行词频统计和情绪分析,并且根据词频权重制成词云图以供后台数据统计,于是我便引入了jieba分词器,但是我发现网上关于jiebaNET相关文档实在太少了,甚至连配置文件…...
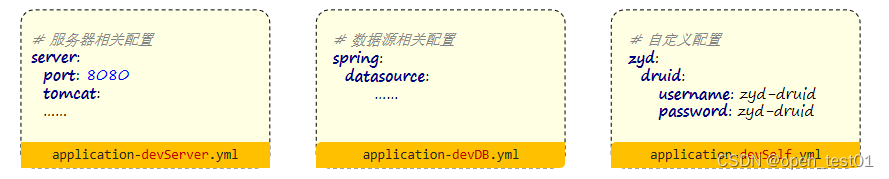
springboot3项目练习详细步骤(第四部分:文件上传、登录优化、多环境开发)
目录 本地文件上传 接口文档 业务实现 登录优化 SpringBoot集成redis 实现令牌主动失效机制 多环境开发 本地文件上传 接口文档 业务实现 创建FileUploadController类并编写请求方法 RestController public class FileUploadController {PostMapping("/upload&…...

视觉里程计的融合方法及优缺点分析
视觉里程计是视觉slam的一部分,即前端部分,用于前端跟踪并建立局部地图。多用于重定位或辅助定位,常用的有特征点法,光流法和直接法,其区别和优缺点如下。 特征点法,需要计算特征点和描述子,计算…...

终极指南:如何免费解锁Cursor Pro完整功能 - 突破AI编辑器限制的完整方案
终极指南:如何免费解锁Cursor Pro完整功能 - 突破AI编辑器限制的完整方案 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youv…...

穿越机老鸟踩坑实录:MPU6000传感器在F4飞控上的IMU方向“玄学”配置
穿越机IMU方向配置实战:从MPU6000异常自旋到飞控底层校准 当你的穿越机在通电瞬间像被无形大手狠狠抽了一记耳光般疯狂自旋,而Betaflight地面站里陀螺仪数据却显示"一切正常"时,这往往意味着你正遭遇IMU方向配置的"量子纠缠态…...

开源自动驾驶系统终极指南:从入门到精通
开源自动驾驶系统终极指南:从入门到精通 【免费下载链接】openpilot openpilot is an operating system for robotics. Currently, it upgrades the driver assistance system on 300 supported cars. 项目地址: https://gitcode.com/GitHub_Trending/op/openpilo…...

5分钟免费获取:开源鼠标连点器MouseClick完整使用指南
5分钟免费获取:开源鼠标连点器MouseClick完整使用指南 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ,…...

紧急更新!Midjourney 6.2.1已悄然修复碳素印相的硫化银衰减模拟缺陷——但97%用户仍在用旧参数,立即校准你的工作流
更多请点击: https://intelliparadigm.com 第一章:碳素印相的视觉本质与Midjourney 6.2.1修复的底层动因 碳素印相的物质性光感逻辑 碳素印相并非数字渲染的模拟,而是一种基于明胶-碳黑颗粒物理沉积的连续调成像工艺。其高密度阴影区呈现哑…...
基于Circuit Playground Express与NeoPixel的四季交互灯光装置设计与实现
1. 项目概述与核心思路几年前,我在一个艺术展上看到一组悬挂在枯树枝上的玻璃瓶,里面装着会呼吸般变幻光线的LED灯,那种静谧又灵动的美感让我念念不忘。作为一个喜欢把代码和电路“藏”进生活场景里的硬件爱好者,我一直在琢磨如何…...

ESP32-S2 Reverse TFT Feather开发板深度解析:从核心硬件到物联网项目实战
1. 项目概述:为什么选择ESP32-S2 Reverse TFT Feather?如果你正在寻找一款能让你快速搭建物联网设备原型,尤其是那些需要一块漂亮屏幕来交互或显示信息的项目,那么ESP32-S2 Reverse TFT Feather绝对是一个值得你花时间研究的开发板…...

面向开发者的轻量级计划管理工具:配置驱动与命令行优先
1. 项目概述:一个为开发者而生的计划管理工具在软件开发的世界里,我们每天都在与各种“计划”打交道:版本迭代计划、个人学习计划、项目里程碑、甚至是每日的待办清单。然而,一个尴尬的现实是,市面上大多数项目管理工具…...

Python邮件自动化实战:基于mymailclaw的监控报警与Slack集成
1. 项目概述与核心价值最近在折腾邮件自动化处理的时候,发现了一个挺有意思的开源项目,叫psandis/mymailclaw。乍一看这个名字,你可能会联想到“邮件抓取”或者“邮件爬虫”。没错,它的核心定位就是一个用 Python 写的邮件客户端自…...

OPAL:基于OPA的实时策略数据分发与权限治理实践
1. 项目概述:什么是OPAL,以及它解决了什么核心痛点?如果你在负责一个微服务架构或者分布式系统的权限管理,大概率遇到过这样的场景:每次权限策略有更新,都需要重启服务、重新部署,或者等待一个漫…...