U-Net网络
U-Net网络
一、基本架构
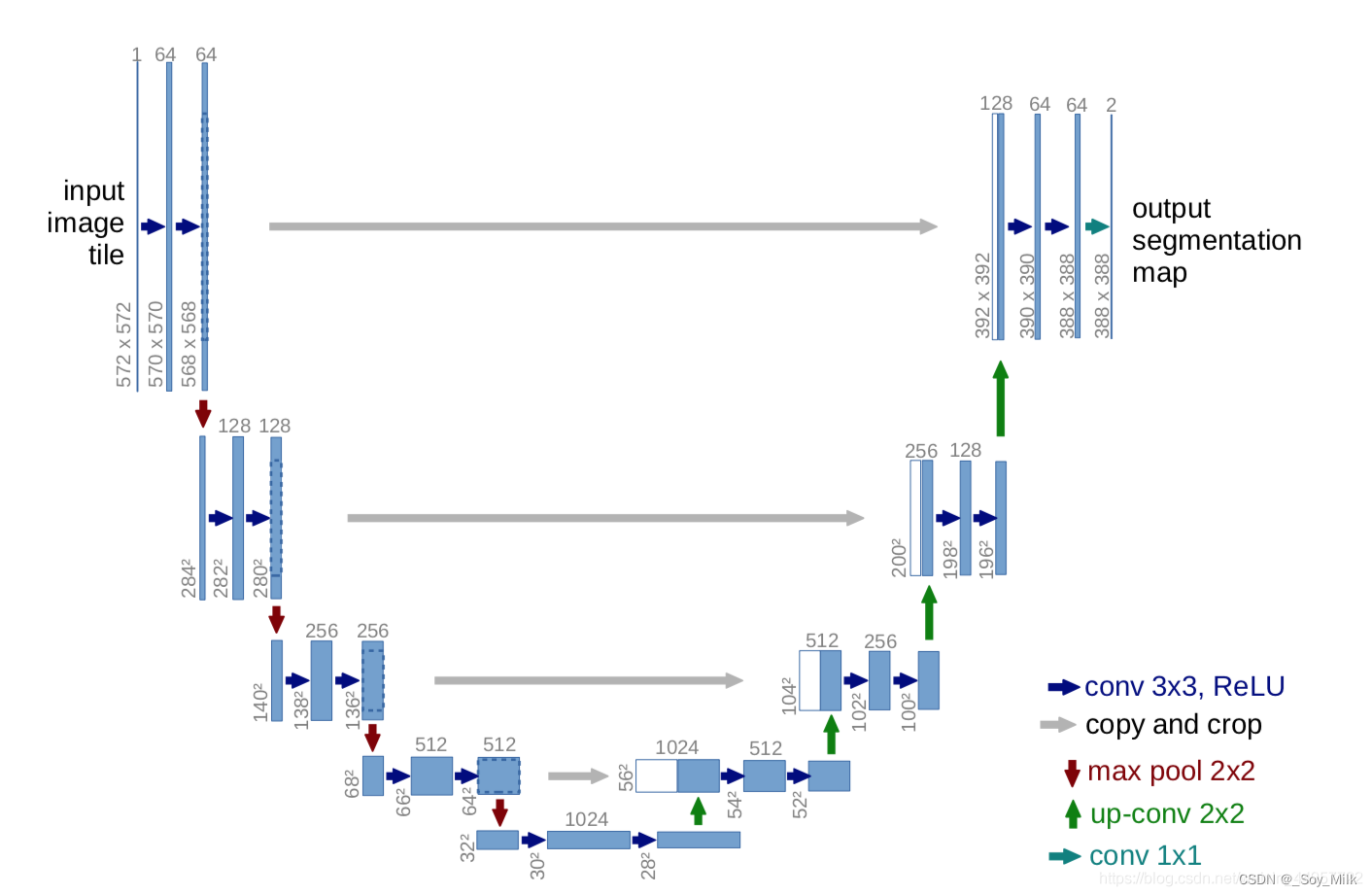
各个箭头的解释:
- conv 3 * 3, ReLU:表示通过一个3 * 3的卷积层,并且该层自动附带一个非线性激活层(
ReLu)- copy and crop:表示进行裁剪然后再进行拼接(在
channel的维度上进行拼接)- max pool 2 * 2:表示通过一个2 * 2的最大池化下采样层,(这一个步骤可以通过一个卷积层进行实现,如果使用最大池化下采样层则会导致丢失
pixel(像素)信息)- up-conv 2 * 2:表示一个上采样过程,可以使用转置卷积来实现,也可以使用最邻近插值法来实现,由于使用转置卷积会导致出现很多空洞,因此我们使用最邻近差值法。
- conv 1 * 1:表示一个卷积核大小为1 * 1 的卷积层,作用主要是改变维度(即
channel的大小)
在实际代码中构建网络时,我们一共为U-Net网络构建了三个模块:
- 蓝色箭头:我们构建为卷积块,并且使用
padding直接进行填充,这样做不会使图片的分辨率发生改变。 - 红色箭头:我们构建为下采样块,并且使用的是卷积的操作进行的下采样,因为最大池化层会使得丢失太多的图片信息。
- 绿色箭头:我们构建为上采样块,并且与灰色箭头一同实现,上下样的过程中,我们使用的是最邻近插值法。
二、理论分析:
论文解读
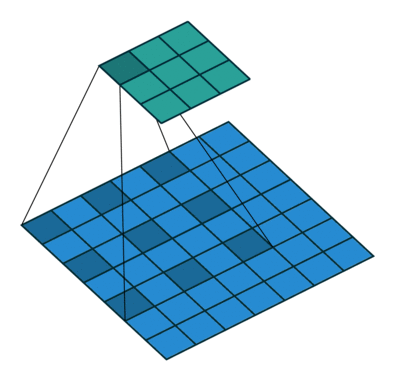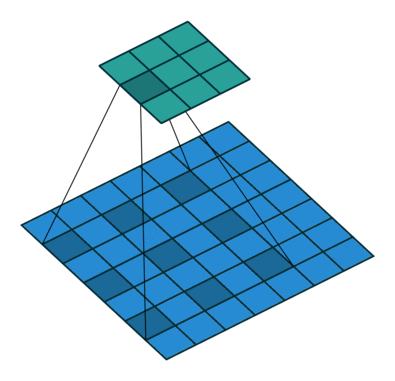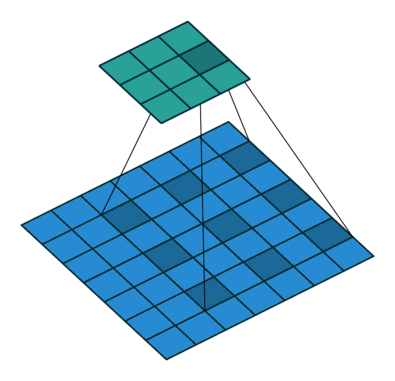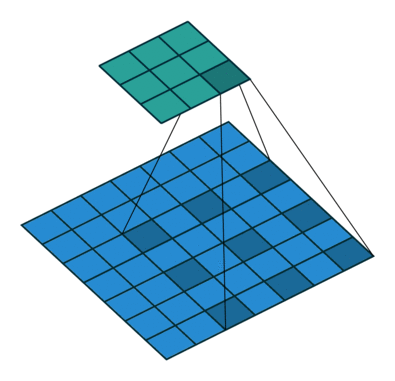
对于一个高分辨率的图像,如果直接输入网络则会爆显存,因此需要每次将该图像的一小部分输入网络,并且要求每次输入的一小部分需要与之前输入的部分有重叠,这样做可以很好的利用图像的边缘信息。具体方式如下:
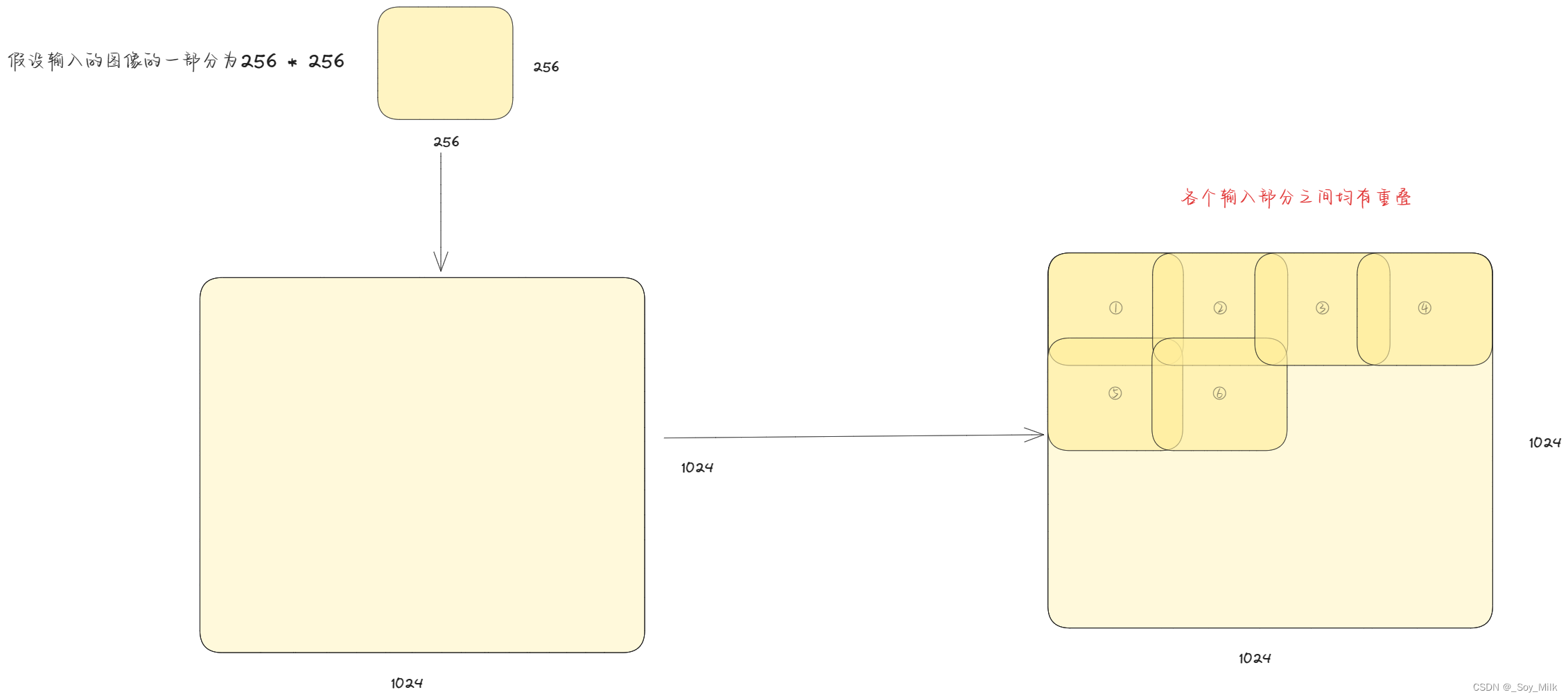
上图展示了将一个1024 * 1024分辨率的图像进行拆分为N个256 * 256分辨率大小的部分,然后再输入到网络中。
预测边缘图像:

由于该论文用于医学图像分割领域,作者研究发现,对于细胞与细胞之间的区域分割是有一定困难的,因此,作者提出了Pixel-Weight lose weight的一个方案,也就是在细胞与细胞之间的这些背景区,我们给它施加一个更大的权重,而对于大片的背景区,我们就给它施加一个比较小的权重。
实验分析:
由U-Net网络的架构可以看出,网络的核心是构建了三个模块,即:3 * 3的卷积层构成的卷积块、下采样块、上采样块,由于网络多次使用这三个模块,因此我们可以将这三个模块进行封装。
计算卷积后图像的宽度和高度(公式一):
I n p u t : ( N , C i n , H ( i n ) , W ( i n ) ) Input:(N, C_{in}, H_(in), W_(in)) Input:(N,Cin,H(in),W(in))
O u t P u t : ( N , C ( o u t ) , H ( o u t ) , W ( o u t ) ) OutPut:(N, C_(out), H_(out), W_(out)) OutPut:(N,C(out),H(out),W(out))
H ( o u t ) = [ H ( i n ) + 2 × p a d d i n g [ 0 ] − d i l a t i o n [ 0 ] × ( k e r n e l s i z e [ 0 ] − 1 ) − 1 s t r i d e [ 0 ] + 1 ] H_(out) = [\frac{H_(in) + 2 \times padding[0] - dilation[0] \times (kernel_{size[0]} - 1) - 1}{stride[0]} + 1] H(out)=[stride[0]H(in)+2×padding[0]−dilation[0]×(kernelsize[0]−1)−1+1]
·W ( o u t ) = [ W ( i n ) + 2 × p a d d i n g [ 1 ] − d i l a t i o n [ 1 ] × ( k e r n e l s i z e [ 1 ] − 1 ) s t r i d e [ 0 ] − 1 ] W_(out) = [\frac{W_(in) + 2 \times padding[1] - dilation[1] \times (kernel_{size[1]} - 1)}{stride[0]} - 1] W(out)=[stride[0]W(in)+2×padding[1]−dilation[1]×(kernelsize[1]−1)−1]
参数解释:
padding是填充的大小,dilation是空洞卷积的大小(即卷积核各个单元之间有多少个间隔),kernel_size是卷积核的大小。空洞卷积:
1. 卷积块
-
首先定义一个Convolution(卷积层),卷积核大小为3 * 3(即:
kernel_size = 3),分析U-Net架构图(输入:[1, 572, 572]==> 输出:[64, 570, 570])可以得到,channel的维度由1 上升到了64,所以定义64个卷积核,由于后面的copy and crop拼接的时候还需要进行裁剪,会导致很麻烦,因此现在的主流的方式是将卷积层加上一个padding,即通过卷积层后不会改变图像的高和宽,并且会在卷积核与 ReLU 之间加上一个BN(Batch normalization),由于没有使用空洞卷积,默认dilatation = 1,由**(公式一)**可以得到stride = 1,padding = 1,这样保证了卷积后图像的高度和宽度不会改变。 -
然后再添加一个Batch normalization层进行归一化处理,这样的好处是加快收敛。
-
再添加一个Dropout层,Dropout 是一种正则化技术,通过在训练过程中随机丢弃一部分神经元的输出,可以减少过拟合并提升模型的泛化能力。
-
最后添加一个LeakReLU层
LeakyReLU 函数在处理负值时不像 ReLU 那样完全将其置零,而是允许一小部分负输入信息的线性泄漏。这有助于缓解ReLU 死亡问题,即神经元可能陷入零激活状态,使得模型难以学习。
数学上,LeakyReLU 函数的定义如下:
f(x) = max(ax, x)
其中:
-
x 表示函数的输入,
-
a 是一个小常数(通常是一个小的正值,如 0.01),它代表函数负值部分的斜率。
由于U-Net网络每次需要添加两次卷积层,因此需要将上述定义的卷积层再次重复一次
-
卷积块代码:
class Conv_Block(nn.Module):def __init__(self, in_channel, out_channel):super(Conv_Block, self).__init__()self.layer = nn.Sequential(nn.Conv2d(in_channel, out_channel, kernel_size=3, stride=1, padding=1, padding_mode='reflect', bias=False), # 填充模式padding_mode='reflect'表示边界向内复制, 第二个参数out_channel表示卷积核的数量nn.BatchNorm2d(out_channel), # 归一化处理,参数为特征图的通道数nn.Dropout(0.3), # 这条语句的作用是创建一个丢弃比例为0.3的 Dropout 层,也就是30%的输入将被随机置为0。。Dropout 是一种正则化技术,通过在训练过程中随机丢弃一部分神经元的输出,可以减少过拟合并提升模型的泛化能力nn.LeakyReLU(),nn.Conv2d(out_channel, out_channel, kernel_size=3, stride=1, padding=1, padding_mode='reflect', bias=False),nn.BatchNorm2d(out_channel),nn.Dropout(0.3),nn.LeakyReLU())def forward(self, x):return self.layer(x)
2. 下采样块
由于最大池化丢弃了太多的特征,因此我们使用一个3 * 3 的卷积来进行最大池化
- 首先定义一个3 * 3 的卷积核,并且通过U-Net网络的结构图(输入:
[64, 568, 568]==> 输出:[64, 284, 284])可以知到,相当于将图像的宽度和高度进行了减半,因此我们在卷积核中设置padding = 1,stride = 2。 - 然后添加一个Batch Normalization层
- 最后添加一个LeakReLU层
下采样块代码:
class DownSample(nn.Module):def __init__(self, channel):super(DownSample, self).__init__()self.layer = nn.Sequential(# 最大池化时,通道数量不变nn.Conv2d(channel, channel, kernel_size=3, stride=2, padding=1, padding_mode='reflect', bias=False),# 'reflect' 模式意味着在边缘周围反射输入图像的像素值。这种模式可以减少边缘效应,并且有助于保持特征图的边界信息。nn.BatchNorm2d(channel),nn.LeakyReLU())def forward(self, x):return self.layer(x)
3. 上采样块
由于使用转置卷积会导致出现很多空洞,因此我们使用最邻近差值法
- 首先使用最邻近插值法对输入的特征图进行处理(Pytorch中的方法是:
nn.Functional()函数)。 - 然后使用一个1 * 1的卷积将图像进行升维。
- 最后将与该层对应的层在
channel维度上进行拼接(Pytorch中的方法是:torch.cat())。
上采样块代码:
class UpSample(nn.Module):def __init__(self, channel):super(UpSample, self).__init__()self.layer = nn.Conv2d(channel, channel // 2, kernel_size=1, stride=1)def forward(self, x, feature_map):up = F.interpolate(x, scale_factor=2, mode='nearest') # 参数解释:scale_factor :变为原来的2倍, mode :使用什么方式,这里为使用最邻近插值法out = self.layer(up)# 实现拼接return torch.cat((out, feature_map), dim=1) # [N, C, H, W] 在通道的维度进行拼接
U-Net的整体定义
- 首先定义一个卷积层,后面连接一个下采样层,重复4次。
- 然后添加一个卷积层。
- 再添加一个上采样层,后面连接一个卷积层,重复4次。
- 最后添加一个3 * 3的卷积层,将维度映射为(
RGB)3个channel。
U-Net整体代码:
class Unet(nn.Module):def __init__(self):super(Unet, self).__init__()self.c1 = Conv_Block(3, 64)self.d1 = DownSample(64)self.c2 = Conv_Block(64, 128)self.d2 = DownSample(128)self.c3 = Conv_Block(128, 256)self.d3 = DownSample(256)self.c4 = Conv_Block(256, 512)self.d4 = DownSample(512)self.c5 = Conv_Block(512, 1024)# 开始进行上采样self.u1 = UpSample(1024)self.c6 = Conv_Block(1024, 512)self.u2 = UpSample(512)self.c7 = Conv_Block(512, 256)self.u3 = UpSample(256)self.c8 = Conv_Block(256, 128)self.u4 = UpSample(128)self.c9 = Conv_Block(128, 64)# 进行输出self.out = nn.Conv2d(64, 3, (3, 3), 1, 1)self.Th = nn.Sigmoid() # 由于我们只需要直到图像的蒙版,只需要知到这个像素是黑的还是白的,因此这是一个二分类问题def forward(self, x):R1 = self.c1(x)R2 = self.c2(self.d1(R1))R3 = self.c3(self.d2(R2))R4 = self.c4(self.d3(R3))R5 = self.c5(self.d4(R4))# 进行上采样O1 = self.c6(self.u1(R5, R4)) # 进行拼接O2 = self.c7(self.u2(O1, R3))O3 = self.c8(self.u3(O2, R2))O4 = self.c9(self.u4(O3, R1))return self.Th(self.out(O4))
三、代码实现:
U_Net_model.py
import torch
from torch import nn
from torch.nn import functional as F# 构建卷积块
class Conv_Block(nn.Module):def __init__(self, in_channel, out_channel):super(Conv_Block, self).__init__()self.layer = nn.Sequential(nn.Conv2d(in_channel, out_channel, kernel_size=(3, 3), stride=1, padding=1, padding_mode='reflect', bias=False), # 填充模式padding_mode='reflect'表示边界向内复制, 第二个参数out_channel表示卷积核的数量nn.BatchNorm2d(out_channel), # 归一化处理,参数为特征图的通道数nn.Dropout(0.3), # 这条语句的作用是创建一个丢弃比例为0.3的 Dropout 层,也就是30%的输入将被随机置为0。。Dropout 是一种正则化技术,通过在训练过程中随机丢弃一部分神经元的输出,可以减少过拟合并提升模型的泛化能力nn.LeakyReLU(),nn.Conv2d(out_channel, out_channel, kernel_size=3, stride=1, padding=1, padding_mode='reflect', bias=False),nn.BatchNorm2d(out_channel),nn.Dropout(0.3),nn.LeakyReLU())def forward(self, x):return self.layer(x)# 最大池化下采样(由于最大池化丢弃了太多的特征,因此我们使用一个3 * 3 的卷积来进行最大池化)
class DownSample(nn.Module):def __init__(self, channel):super(DownSample, self).__init__()self.layer = nn.Sequential(# 最大池化时,通道数量不变nn.Conv2d(channel, channel, kernel_size=3, stride=2, padding=1, padding_mode='reflect', bias=False),nn.BatchNorm2d(channel),nn.LeakyReLU())def forward(self, x):return self.layer(x)# 下采样(由于使用转置卷积会导致出现很多空洞,因此我们使用最邻近差值法)
class UpSample(nn.Module):def __init__(self, channel):super(UpSample, self).__init__()self.layer = nn.Conv2d(channel, channel // 2, kernel_size=1, stride=1)def forward(self, x, feature_map):up = F.interpolate(x, scale_factor=2, mode='nearest') # 参数解释:scale_factor :变为原来的2倍, mode :使用什么方式,这里为使用最邻近插值法out = self.layer(up)# 实现拼接return torch.cat((out, feature_map), dim=1) # [N, C, H, W] 在通道的维度进行拼接class Unet(nn.Module):def __init__(self):super(Unet, self).__init__()self.c1 = Conv_Block(3, 64)self.d1 = DownSample(64)self.c2 = Conv_Block(64, 128)self.d2 = DownSample(128)self.c3 = Conv_Block(128, 256)self.d3 = DownSample(256)self.c4 = Conv_Block(256, 512)self.d4 = DownSample(512)self.c5 = Conv_Block(512, 1024)# 开始进行上采样self.u1 = UpSample(1024)self.c6 = Conv_Block(1024, 512)self.u2 = UpSample(512)self.c7 = Conv_Block(512, 256)self.u3 = UpSample(256)self.c8 = Conv_Block(256, 128)self.u4 = UpSample(128)self.c9 = Conv_Block(128, 64)# 进行输出self.out = nn.Conv2d(64, 3, 3, 1, 1)self.Th = nn.Sigmoid() # 由于我们只需要直到图像的蒙版,只需要知到这个像素是黑的还是白的,因此这是一个二分类问题def forward(self, x):R1 = self.c1(x)R2 = self.c2(self.d1(R1))R3 = self.c3(self.d2(R2))R4 = self.c4(self.d3(R3))R5 = self.c5(self.d4(R4))# 进行上采样O1 = self.c6(self.u1(R5, R4)) # 进行拼接O2 = self.c7(self.u2(O1, R3))O3 = self.c8(self.u3(O2, R2))O4 = self.c9(self.u4(O3, R1))return self.Th(self.out(O4))if __name__ == '__main__':'''定义网络的结构使用的代码,整个U-Net网络'''x = torch.randn(2, 3, 572, 572)net = Unet()print(net(x).shape)
utils.py
utils.py文件用于对输入的图片的shape进行处理
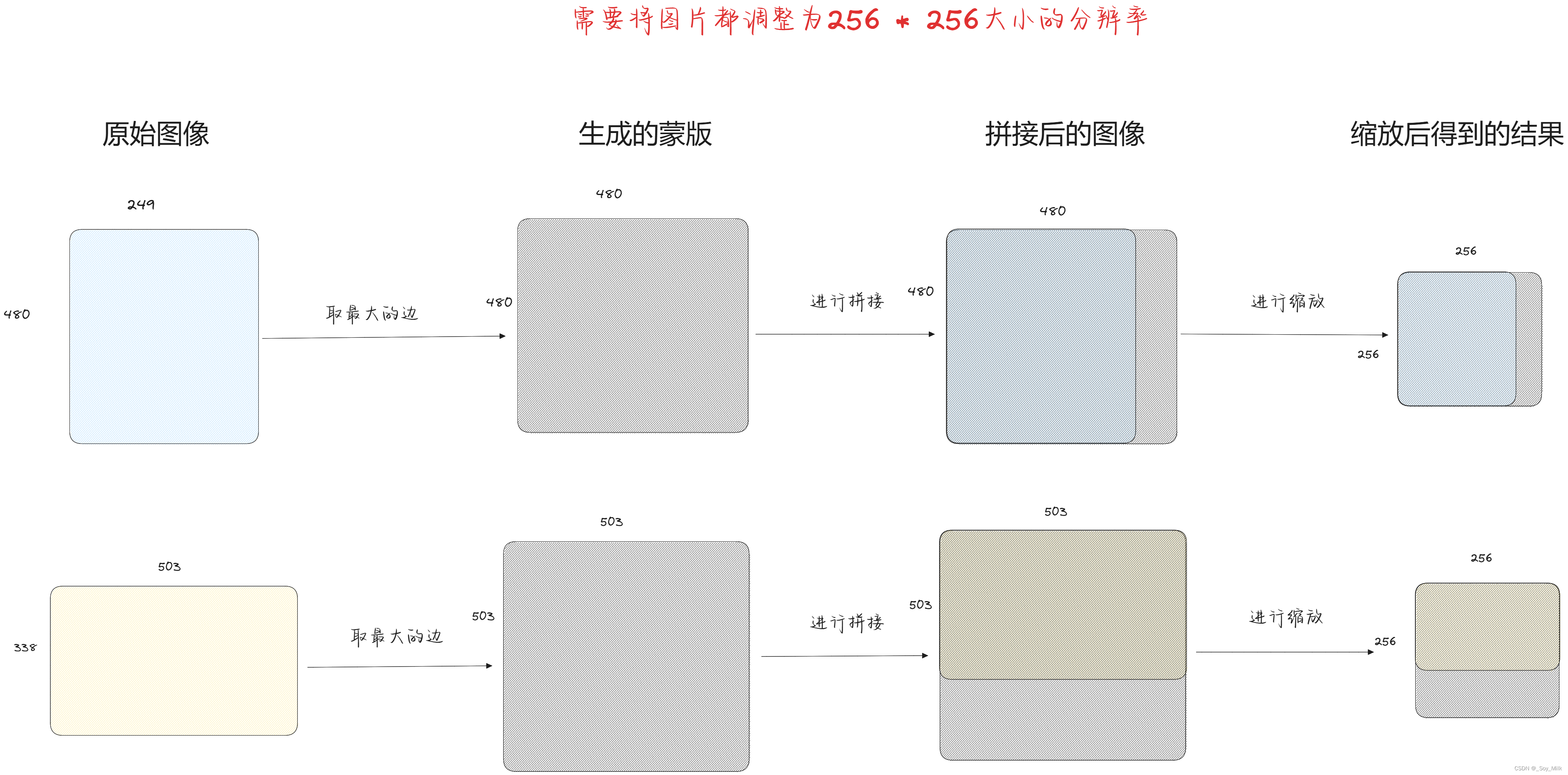
由于直接对图像进行缩放会导致图像进行变形,这就导致图像的特征发生了变化,为了保证图像特征的完整性,我们使用蒙版的方法进行设定输入图像的大小,具体方式如下:
- 首先找到图像中最大的边。
- 然后利用此边设定一个值为0的方形蒙版。
- 将图片粘贴到该蒙版上。
- 对结合后的蒙版进行等比缩放得到需要的图片大小。
from PIL import Image# 对图片进行缩放
def keep_image_size_open(path, size=(256, 256)):img = Image.open(path)# img.size返回的是一个元组,temp获取的是每一张图片的最大长度temp = max(img.size)# Image.new(mode, size, color),用于创建一个新的图像。color表示图像的初始颜色mask = Image.new('RGB', (temp, temp), (0, 0, 0)) '''mask.paste(im, box, mask=None) 用于将一个图像粘贴到另一个图像上,并可以指定粘贴的位置以及透明度,参数解释:im表示要粘贴的图像,box定义了粘贴位置和大小的矩形框(0, 0)表示从左上角进行粘贴'''mask.paste(img, (0, 0)) mask = mask.resize((size)) # 调整大小return maskif __name__ == '__main__':keep_image_size_open("./data/JPEGImages/000033.jpg").show()
My_DataSet.py
import osfrom torch.utils.data import Dataset
from utils import *
from torchvision import transforms# 将数据转换为Tenso类型
transform = transforms.Compose([transforms.ToTensor()
])# 定义数据集(图像分割数据集)
class MyDataset(Dataset):def __init__(self, path):self.path = pathself.name = os.listdir(os.path.join(path, "SegmentationClass"))def __len__(self):return len(self.name)def __getitem__(self, index):segment_name = self.name[index] # 格式:xxx.png# 拼接得到蒙版的地址segment_path = os.path.join(self.path, 'SegmentationClass', segment_name)# 拼接得到原图的地址image_paht = os.path.join(self.path, 'JPEGImages', segment_name.replace('png', 'jpg'))# 将蒙版与原图进行读取进来segment_image = keep_image_size_open(segment_path)image = keep_image_size_open(image_paht)return transform(image), transform(segment_image)if __name__ == '__main__':path = './data'data = MyDataset(path)print(data[0][0].shape)print(data[0][1].shape)train.py
from torch import nn, optim
import torch
from torch.utils.data import DataLoader
from My_DataSet import *
from net import *
from torchvision.utils import save_imagedevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
weight_path = 'params/unet.pth'
data_pth = './Data/VOCdevkit/VOC2007'
save_path = 'train_image'def main():'''训练网络使用的代码'''data_loader = DataLoader(MyDataset(data_pth), batch_size=2, shuffle=True)net = Unet().to(device)# 读取之前训练的权重if os.path.exists(weight_path):net.load_state_dict(torch.load(weight_path))print("SUCCESSFUL LOAD WEIGHT!")else:print("NOT SUCCESSFUL LOAD WEIGHT")# 设置优化器以及损失函数opt = optim.Adam(net.parameters())loss_fn = nn.BCELoss()epochs = 1000for epoch in range(epochs):for i, (image, segment_image) in enumerate(data_loader):image, segment_image = image.to(device), segment_image.to(device)out_image = net(image)train_loss = loss_fn(out_image, segment_image)opt.zero_grad()train_loss.backward()opt.step()# 每训练5个图片输出一次损失if i % 5 == 0:print(f'{epoch}-{i}-train_loss---->>{train_loss.item()}')# 每训练50个图片更新一次权重if i % 50 == 0:torch.save(net.state_dict(), weight_path)# 每训练100个图片if i % 100 == 0:_image = image[0]_segment_image = segment_image[0]_out_image = out_image[0]img = torch.stack([_image, _segment_image, _out_image], dim=0)save_image(img, f'{save_path}/{i}.png')if __name__ == '__main__':main()
predict.py
import os.path
import torch
from utils import *
from net import *
from My_DataSet import *
from torchvision.utils import save_image# 实例化U-Net网络
net = Unet().cuda()# 读取训练的权重
weights = 'params/unet.pth'
if os.path.exists(weights):net.load_state_dict(torch.load(weights))print('SUCCESSFULLY')
else:print('NO LOADING')# 输入需要预测的图片的路径
_input = input('please input JPEGImages path:')# 对图片的格式进行调整
img = keep_image_size_open(_input)
# 指定调用的硬件资源
img_data = transform(img).cuda()
# 在第0维增加一维,因为训练的时候有batch维度,这里需要添加一维
img_data = torch.unsqueeze(img_data, dim=0)
# 得到网络的输出
out = net(img_data)
# 对预测的得到的蒙版进行保存
save_image(out, 'result/result.jpg')
print(out.shape)
相关文章:
U-Net网络
U-Net网络 一、基本架构 各个箭头的解释: conv 3 * 3, ReLU:表示通过一个3 * 3的卷积层,并且该层自动附带一个非线性激活层(ReLu)copy and crop:表示进行裁剪然后再进行拼接(在channel的维度上…...

不拍视频,不直播怎么在视频号卖货赚钱?开一个它就好了!
大家好,我是电商糖果 视频号这两年看着抖音卖货的热度越来越高,也想挤进电商圈。 于是它模仿抖音推出了自己的电商平台——视频号小店。 只要商家入驻视频号小店,就可以在视频号售卖商品。 具体怎么操作呢,需要拍视频…...

【vue-5】双向数据绑定v-model及修饰符
单向数据绑定:当数据发生改变时,视图会自动更新,但当用户手动更改input的值,数据不会自动更新; 双向数据绑定:当数据发生改变时,视图会自动更新,但当用户手动更改input的值…...
[STM32-HAL库]AS608-指纹识别模块-STM32CUBEMX开发-HAL库开发系列-主控STM32F103C8T6
目录 一、前言 二、详细步骤 1.光学指纹模块 2.配置STM32CUBEMX 3.程序设计 3.1 输出重定向 3.2 导入AS608库 3.3 更改端口宏定义 3.4 添加中断处理部分 3.5 初始化AS608 3.6 函数总览 3.7 录入指纹 3.8 验证指纹 3.9 删除指纹 3.10 清空指纹库 三、总结及资源 一、前言 …...

【java程序设计期末复习】chapter4 类和对象
类和对象 编程语言的几个发展阶段 (1)面向机器语言 计算机处理信息的早期语言是所谓的机器语言,使用机器语言进行程序设计需要面向机器来编写代码,即需要针对不同的机器编写诸如0101 1100这样的指令序列。 (2&#x…...
ios:Command PhaseScriptExecution failed with a nonzero exit code
问题 使用 xcode 跑项目真机调试的时候,一直报错 Command PhaseScriptExecution failed with a nonzero exit code。 解决 最终靠以下方法解决 删除Podfile.lock文件删除Pods文件删除.xcworkspace文件Pod installCommandShiftK 清理一下缓存 亲测有效...
《拯救大学生课设不挂科第四期之蓝桥杯是什么?我是否要参加蓝桥杯?选择何种语言?如何科学备赛?方法思维教程》【官方笔记】
背景: 有些同学在大一或者大二可能会被老师建议参加蓝桥杯,本视频和文章主要是以一个过来人的身份来给与大家一些思路。 比如蓝桥杯是什么?我是否要参加蓝桥杯?参加蓝桥杯该选择何种语言?如何科学备赛?等…...
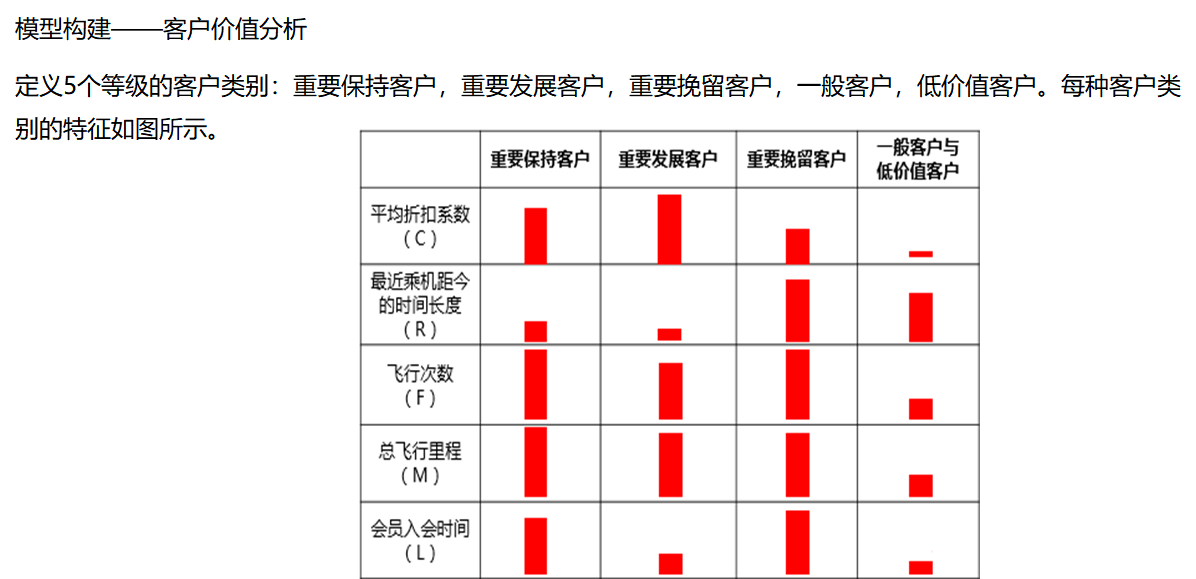
数据挖掘案例-航空公司客户价值分析
文章目录 1. 案例背景2. 分析方法与过程2.1 分析流程步骤2.2 分析过程1. 数据探索分析2. 描述性统计分析3. 分布分析1.客户基本信息分布分析2. 客户乘机信息分布分析3. 客户积分信息分布分析 4. 相关性分析 3. 数据预处理3.1 数据清洗3.2 属性约束3. 3 数据转换 4. 模型构建4. …...

决策树与机器学习实战【代码为主】
文章目录 🛴🛴引言🛴🛴决策树使用案例🛴🛴numpy库生成模拟数据案例🛴🛴决策树回归问题🛴🛴决策树多分类问题 🛴🛴引言 决策树是一种经…...
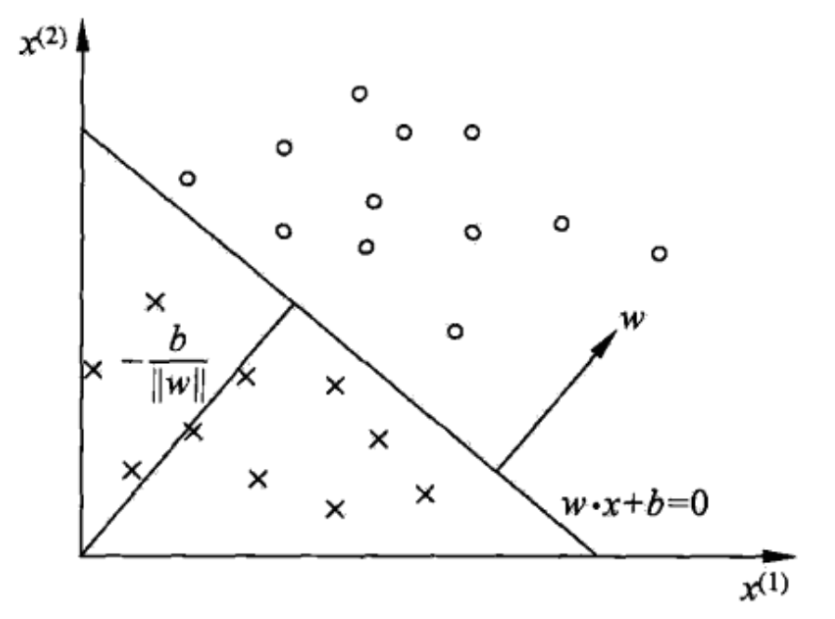
从感知机到神经网络
感知机 一、感知机是什么二、用感知机搭建简单逻辑电路2.1 与门2.2 与非门2.3 或门 三、感知机的局限性3.1 异或门3.2 线性和非线性 四、多层感知机4.1 已有门电路的组合4.2 Python异或门的实现 五、感知机模型5.1 感知机模型5.2 感知机损失函数5.3 感知机学习算法 六、感知机原…...

【HMGD】STM32/GD32 I2C DMA 主从通信
STM32 I2C配置 主机配置 主机只要配置速度就行 从机配置 从机配置相同速度,可以设置第二地址 因为我的板子上面已经有了上拉电阻,所以可以直接通信 STM32 I2C DMA 定长主从通信代码示例 int state 0; static uint8_t I2C_recvBuf[10] {0}; stat…...
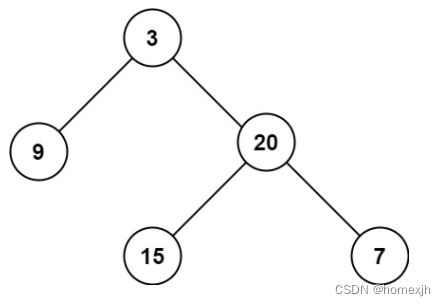
leecode 226 翻转二叉树、101 对称二叉树、104 二叉树的最大深度
leecode 226 翻转二叉树、101 对称二叉树、104 二叉树的最大深度 leecode 226 翻转二叉树 题目链接 :https://leetcode.cn/problems/invert-binary-tree/description/ 题目 给你一棵二叉树的根节点 root ,翻转这棵二叉树,并返回其根节点。…...

Redux基础
简介 状态管理工具,集中式管理react、vue、angular等应用中多个组件的状态,是一个库,使用之后可以清晰的知道应用里发生了什么以及数据是如何修改,如何更新的 在项目中添加 Redux 并不是必须的,根据项目需求选择是否引入 Redux 三个原则 …...

国外目标公司的任何一个联系人也许都有意义
我们说跟进一个项目,最好能够联系上拥有决策权的人,不然中间隔着几重关系,所有的更新都需要层层审批申报,特别麻烦,总是要等,也许等到最后就是一场空。如果能够直接和老板或者是拍板的人沟通,则…...

因为本地证书太旧或不全导致的 HTTPS 访问失败问题20240520
因为本地证书太旧或不全导致的 HTTPS 访问失败问题 在生产环境中,我们经常需要使用 curl 命令来测试和调试 HTTPS URL。然而,最近我遇到了一个棘手的问题:在测试环境中使用 curl 可以正常访问某个 URL,但在生产环境中却遇到了 SS…...

Lua获取表的长度
1.代码 -- 创建一个表并添加一些元素 local myTable {10, 20, 30, 40}-- 打印表的长度 print(#myTable) -- 输出 4,因为表中有 4 个元素-- 使用 # 来遍历表中的所有元素 for i 1, #myTable doprint(myTable[i]) end -- 这将依次打印 10, 20, 30, 40...

python九九乘法表的打印思考及实现
新书上架~👇全国包邮奥~ python实用小工具开发教程http://pythontoolsteach.com/3 欢迎关注我👆,收藏下次不迷路┗|`O′|┛ 嗷~~ 目录 一、问题引入 九九乘法表的显示需求 二、问题分析 嵌套循环的概念 屏幕宽度与换行的考虑…...

2.Spring中用到的设计模式
Spring框架中使用了多种设计模式来构建其强大且灵活的功能,这里举例说明Spring中的一些功能使用到的设计模式。 工厂模式:Spring容器本质是一个大工厂,使用工厂模式通过BeanFactory和ApplicationContext这两个核心接口来创建和管理bean对象。…...
.NET调用阿里云人脸核身服务端 (ExecuteServerSideVerification)简易流程保姆级教学
需要注意的是,以下内容仅限基础调用 功能说明 该功能是输入核验人的姓名和身份证以及人脸照片,去阿里库里面匹配,3个信息是否一致,一致则验证通过,需要注意的是,人脸有遮挡,或者刘海࿰…...
]C语言堆排序技术详解)
[大师C语言(第十二篇)]C语言堆排序技术详解
引言 堆排序(Heap Sort)是一种基于比较的排序算法,它利用堆这种数据结构的特点来进行排序。堆是一种近似完全二叉树的结构,并同时满足堆积的性质:即子节点的键值或索引总是小于(或者大于)它的父…...

从准确率到社会福利:机器学习在社会资源分配中的范式演进
1. 从预测到分配:为什么准确率不再是社会场景下机器学习的唯一目标 在过去的十几年里,我亲眼见证了机器学习从一个学术概念,成长为驱动我们数字生活乃至部分现实决策的核心引擎。从最初在实验室里调参,看着模型在MNIST数据集上的准…...
)
用Python复现电池寿命预测论文:从数据清洗到模型调优的完整实战(附代码)
用Python实战电池寿命预测:从特征工程到模型优化的全流程解析在新能源与储能技术快速发展的今天,锂离子电池的健康状态(SOH)预测已成为工业界和学术界共同关注的核心课题。不同于传统实验室环境下耗时数月的电池老化测试ÿ…...

2026年论文党必备:盘点2026年倾心之选的的降AIGC网站
轻松降低论文AI率在2026年已不再是天方夜谭。以下是2026年最炸裂、实测效果显著的降AIGC网站神器,覆盖AI痕迹消除、文本改写润色、降重优化、学术合规检测四大核心场景,帮你稳妥搞定毕业论文。 一、全流程王者:一站式搞定论文全链路 这类工具…...

软考中级嵌入式——第九章 数据结构与算法
1.数据结构与算法概念1.1数据结构数据结构概述:数据结构是计算机存储、组织数据的方式。简单来说,就是如何把现实中的数据(如数字、文字、图片)合理地整理好,放进计算机里,并定义好对这些数据可以做什么操作…...

Shutter Encoder:构建高效媒体工作流的FFmpeg图形化解决方案
Shutter Encoder:构建高效媒体工作流的FFmpeg图形化解决方案 【免费下载链接】shutter-encoder A professional video compression tool accessible to all, mostly based on FFmpeg. 项目地址: https://gitcode.com/gh_mirrors/sh/shutter-encoder 在数字媒…...

SQL 数据库从免费到付费选型实战:支撑真实规模产品的能力分析与选择指南
引言:为什么 SQL 数据库选型如此重要? 在当今数据驱动的时代,数据库是任何数字产品的核心基础设施。无论是初创公司的 MVP(最小可行产品),还是日活百万的成熟应用,数据库的选择直接影响着产品的性能、成本、可扩展性和开发效率。 对于技术决策者而言,面对琳琅满目的 …...

Python爬虫实战:爬取论文期刊 文献整理+管理表生成
写论文的时候最烦什么?不是写内容,是找文献和整理文献。相信每个研究生都有过这样的经历:打开十几个浏览器标签页,一篇一篇复制论文标题、作者、期刊、发表时间、摘要,然后粘贴到Excel里,一不小心还会复制错…...

AI 安全生产管理平台:用数字技术筑牢企业安全防线
传统企业安全生产长期依赖“人工巡检、事后整改”的模式,人工排查存在疲劳漏检、响应滞后、标准不一等痛点,很难全天候守住生产安全底线。而 AI 安全生产管理平台依托人工智能、物联网、边缘计算、大数据等核心技术,彻底打破传统“人防”局限…...

告别Typora和Vditor?在WordPress后台打造你的全能Markdown写作环境
在WordPress中构建专业级Markdown写作环境的完整指南 对于习惯使用Typora、Vditor等独立Markdown编辑器的创作者来说,WordPress后台的默认编辑器往往显得笨重且功能有限。但通过合理的插件配置和主题选择,我们完全可以在WordPress中打造一个媲美专业编辑…...

机场应急处置保障:黎阳之光无感赋能,精准调度救援,提升处置能力
机场空间结构复杂、人员高度密集、设备设施集中,易受突发天气、设备故障、突发险情等各类突发事件影响,应急处置、人员疏散、救援调度的效率,是保障机场安全运行的核心关键。传统应急模式下,现场人员分布态势模糊、被困位置无法快…...