hdfs复习
一.hadoop概述
1.4高(优势)
1).高可靠性:hadoop底层多个数据副本,即使某个计算节点存储出现故障,不会导致数据丢失。
2).高扩展性:可以动态增加服务器节点。
3).高效性:在MapReducer思想下,hadoop并行工作,加快任务处理速度。
4).高容错性:能将失败的任务,进行自动分配。
缺点:
1).不适合低延时数据访问,比如:快速查询,快速增删改查做不到。
2).无法高效的对大量小文件进行存储。存储大量小文件会造成namenode大量的内存来存储文件目录和块的信息。(namenode内存有限)
3).小文件寻址时间过长,会超过读取时间,违背了hdfs的设计目标。
4).不支持并发写入,文件随机修改。(一个文件只有一个写,不允许多个线程同时并发写入)
5).支持追加写入,不支持文件随机修改。
2.hdfs组成
namenode:数据都存储在什么位置
datanode:具体存储文件块数据
2nn:备份数据,辅助namenode工作
common:
3.yarn组成
rm:资源老大
nodemanager:单节点资源老大
appmaster:单个任务老大
contain:容器,独立的cpu,内存,磁盘,网络等。
4.mapreduce组成
map:
reduce:
5.hdfs-yarn-mapreduce三者之间关系(重点)
sbin:跟hdfs,yarn,mapreduce有关
hdfs存储,yarn
6.hdfs客户端:对集群进行增删改查操作的:
HDFS WEB UI、HDFS Shell命令以及Http方式访问HDFS,
参考必看:https://www.cnblogs.com/tesla-turing/p/11488100.html
6.hdfs块大小
hdfs块大小的一般是2.x版本128M,1.x版本64m,256M主要用于大型公司
7.为何不能设置块太大或者太小
HDFS等下设置的时间太小,会增加磁盘寻址时间,程序一直在找块的初始位置。
如果块设置的过大,从磁盘传输数据的时间会明显大于块定位这个块开始位置所需的时间。
HDFS块大小设置主要取决于磁盘传输速率。
7.HDFS的shell操作(开发重点)
hdfs客户端创建文件夹:hadoop fs /sanguo
删除命令一定注意!
修改文件副本数:hadoop fs -setrep 数量 /XXX
8.Windows Hdfs客户端代码
在集群上创建一个目录:
客户端代码常用模版:
①.获取一个客户端对象
②.执行想关的命令
③.关闭资源
Hdfs API的使用代码3遍:
9.机架感知(3种方式)
进展60章节
10.集群时间同步
如果服务器在公网环境(能连接外网),可以不采用集群时间同步,因为服务器会定期和公网时间进行校准;
在内网环境,要配置集群时间同步。否则,时间久了,会导致时间偏差,导致集群执行任务时间不同步。
2)时间服务器配置(必须root用户)
(1)查看所有节点ntpd服务状态和开机自启动状态
[atguigu@hadoop102 ~]$ sudo systemctl status ntpd
[atguigu@hadoop102 ~]$ sudo systemctl start ntpd
[atguigu@hadoop102 ~]$ sudo systemctl is-enabled ntpd
(2)修改hadoop102的ntp.conf配置文件
[atguigu@hadoop102 ~]$ sudo vim /etc/ntp.conf
修改内容如下
(a)修改1(授权192.168.10.0-192.168.10.255网段上的所有机器可以从这台机器上查询和同步时间)
#restrict 192.168.10.0 mask 255.255.255.0 nomodify notrap
为restrict 192.168.10.0 mask 255.255.255.0 nomodify notrap
(b)修改2(集群在局域网中,不使用其他互联网上的时间)
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst
为
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
(c)添加3(当该节点丢失网络连接,依然可以采用本地时间作为时间服务器为集群中的其他节点提供时间同步)
server 127.127.1.0
fudge 127.127.1.0 stratum 10
(3)修改hadoop102的/etc/sysconfig/ntpd 文件
[atguigu@hadoop102 ~]$ sudo vim /etc/sysconfig/ntpd
增加内容如下(让硬件时间与系统时间一起同步)
SYNC_HWCLOCK=yes
(4)重新启动ntpd服务
[atguigu@hadoop102 ~]$ sudo systemctl start ntpd
(5)设置ntpd服务开机启动
[atguigu@hadoop102 ~]$ sudo systemctl enable ntpd
3)其他机器配置(必须root用户)
(1)关闭所有节点上ntp服务和自启动
[atguigu@hadoop103 ~]$ sudo systemctl stop ntpd
[atguigu@hadoop103 ~]$ sudo systemctl disable ntpd
[atguigu@hadoop104 ~]$ sudo systemctl stop ntpd
[atguigu@hadoop104 ~]$ sudo systemctl disable ntpd
(2)在其他机器配置1分钟与时间服务器同步一次
[atguigu@hadoop103 ~]$ sudo crontab -e
编写定时任务如下:
*/1 * * * * /usr/sbin/ntpdate hadoop102
(3)修改任意机器时间
[atguigu@hadoop103 ~]$ sudo date -s "2021-9-11 11:11:11"
(4)1分钟后查看机器是否与时间服务器同步
[atguigu@hadoop103 ~]$ sudo date
11.HDFS的API操作
1)hdfs客户端环境准备
2)HDFS的API实操
客户端代码常用套路:hdfs,zookeeper
①、获取一个客户端的对象
②、执行相关的操作命令
③、关闭资源
12.参数优先级
参数优先级排序:(1)客户端代码中设置的值 >(2)ClassPath下的用户自定义配置文件 >(3)然后是服务器的自定义配置(xxx-site.xml) >(4)服务器的默认配置(xxx-default.xml)
副本数设置:dfs.replication 在hdfs-default.xml中设置
参数优先级:最低优先级:hdfs-default.xml==》hdfs-site.xml==>在项目资源目录下的配置文件
13.hdfs功能解释
HDFS客户端:就是客户端。
1、提供一些命令来管理、访问 HDFS,比如启动或者关闭HDFS。
2、与 DataNode 交互,读取或者写入数据;读取时,要与 NameNode 交互,获取文件的位置信息;写入 HDFS 的时候,Client 将文件切分成 一个一个的Block,然后进行存储
NameNode:即Master,
1、管理 HDFS 的名称空间。
2、管理数据块(Block)映射信息
3、配置副本策略
4、处理客户端读写请求。
DataNode:
就是Slave。NameNode 下达命令,DataNode 执行实际的操作。
1、存储实际的数据块。
2、执行数据块的读/写操作。
Secondary NameNode:
并非 NameNode 的热备。当NameNode 挂掉的时候,它并不能马上替换 NameNode 并提供服务。
1、辅助 NameNode,分担其工作量。
2、定期合并 fsimage和fsedits,并推送给NameNode。
3、在紧急情况下,可辅助恢复 NameNode。
14.网络拓扑-节点距离计算
节点距离,是到达共同祖先之和。
15.副本节点选择
第一副本在机架1:节点最近,上传更快。
第二个副本在另外一个机器的随机一个节点:
第三个副本在第二个副本所在机架的随机节点
16.元数据
元数据:是描述其它数据的数据。
文件元数据:包含文件名,大小,创建日期,修改日期,作者,权限等。
等
17.namenode是放在内存还是磁盘
相关文章:

hdfs复习
一.hadoop概述 1.4高(优势) 1).高可靠性:hadoop底层多个数据副本,即使某个计算节点存储出现故障,不会导致数据丢失。 2).高扩展性:可以动态增加服务器节点。 3).高效…...
css-Ant-Menu 导航菜单更改为左侧列表行选中
1.Ant-Menu导航菜单 导航菜单是一个网站的灵魂,用户依赖导航在各个页面中进行跳转。一般分为顶部导航和侧边导航,顶部导航提供全局性的类目和功能,侧边导航提供多级结构来收纳和排列网站架构。 2.具体代码 html <!-- 左侧切换 --><…...
02-CSS3基本样式
目录 1. CSS3简介 1.1 CSS3的兼容情况 1.2 优雅降级和渐进增强的开发思想 2. 新增选择器 2.1 选择相邻兄弟 2.2 匹配选择器 2.3 属性选择器(重点) 2.4 结构性伪类选择器(重点) 2.4.1 整体结构类型 2.4.2 标签结构类型 2.4.3 指定子元素的序号&…...
USART串口外设
USART介绍 USART:另外我们经常还会遇到串口,叫UART,少了个S,就是通用异步收发器,一般我们串口很少使用这个同步功能,所以USART和UART使用起来,也没有什么区别。 其实这个STM32的USART同步模式&a…...
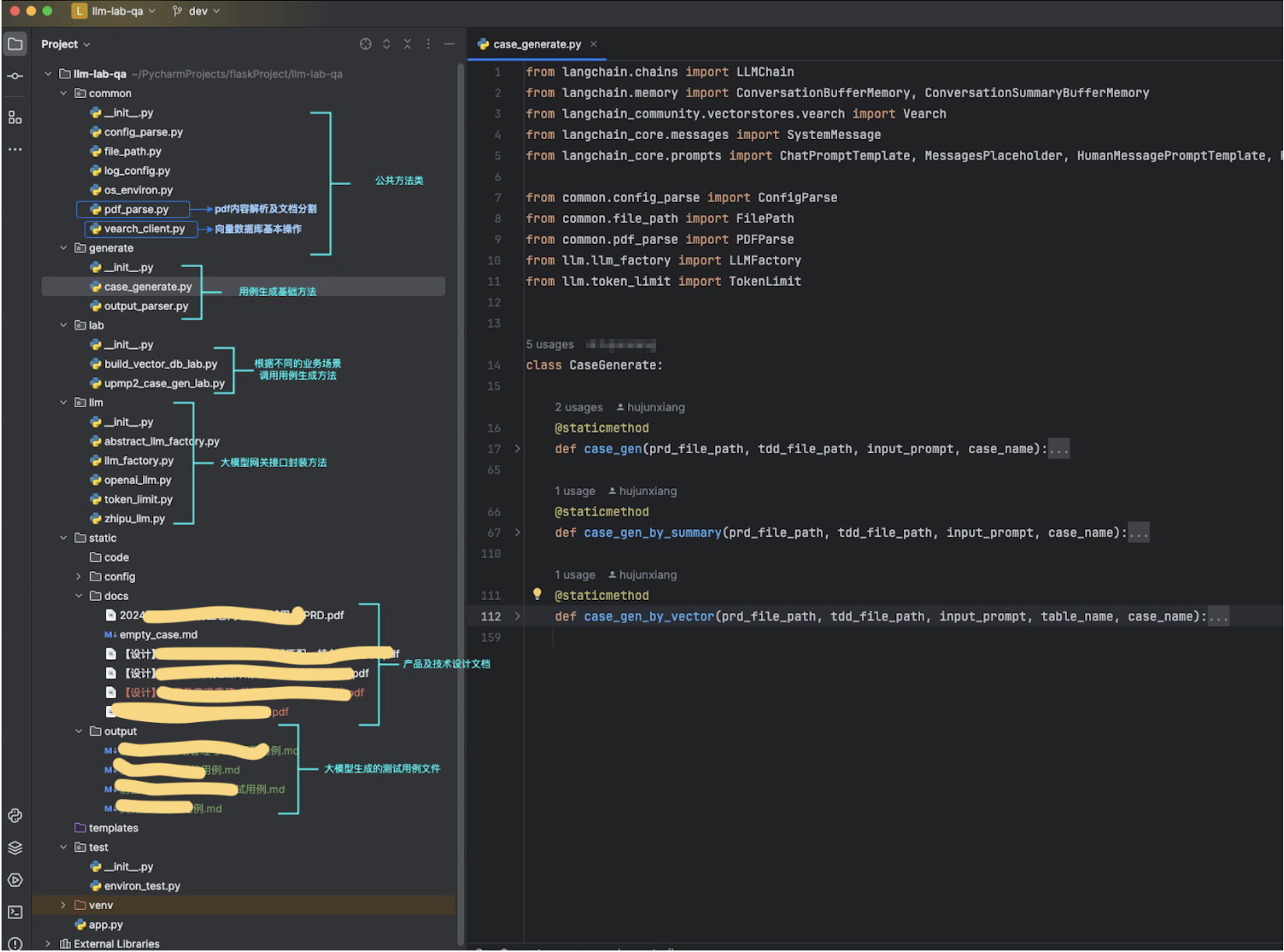
大模型应用之基于Langchain的测试用例生成
一 用例生成实践效果 在组内的日常工作安排中,持续优化测试技术、提高测试效率始终是重点任务。近期,我们在探索实践使用大模型生成测试用例,期望能够借助其强大的自然语言处理能力,自动化地生成更全面和高质量的测试用例。 当前…...

C++之map
1、标准库的map类型 2、插入数据 #include <map> #include <string> #include <iostream>using namespace std;int main() {map<string, int> mapTest;// 插入到map容器内部的元素是默认按照key从小到大来排序// key类型一定要重载小于号<运算符map…...

【量算分析工具-方位角】GeoServer改造Springboot番外系列六
【量算分析工具-概述】GeoServer改造Springboot番外系列三-CSDN博客 【量算分析工具-水平距离】GeoServer改造Springboot番外系列四-CSDN博客 【量算分析工具-水平面积】GeoServer改造Springboot番外系列五-CSDN博客 【量算分析工具-方位角】GeoServer改造Springboot番外系列…...

【机器学习】机器学习与大模型在人工智能领域的融合应用与性能优化新探索
文章目录 引言机器学习与大模型的基本概念机器学习概述监督学习无监督学习强化学习 大模型概述GPT-3BERTResNetTransformer 机器学习与大模型的融合应用自然语言处理文本生成文本分类机器翻译 图像识别自动驾驶医学影像分析 语音识别智能助手语音转文字 大模型性能优化的新探索…...

上传图片并显示#Vue3#后端接口数据
上传图片并显示#Vue3#后端接口数据 效果: 上传并显示图片 代码: <!-- 上传图片并显示 --> <template><!-- 上传图片start --><div><el-form><el-form-item><el-uploadmultipleclass"avatar-uploader&quo…...

音视频开发14 FFmpeg 视频 相关格式分析 -- H264 NALU格式分析
H264简介-也叫做 AVC H.264,在MPEG的标准⾥是MPEG-4的⼀个组成部分–MPEG-4 Part 10,⼜叫Advanced Video Codec,因此常常称为MPEG-4 AVC或直接叫AVC。 原始数据YUV,RGB为什么要压缩-知道就行 在⾳视频传输过程中,视频⽂件的传输…...
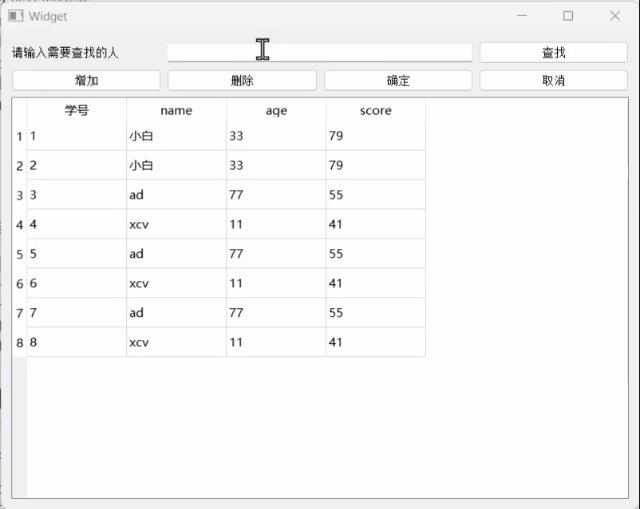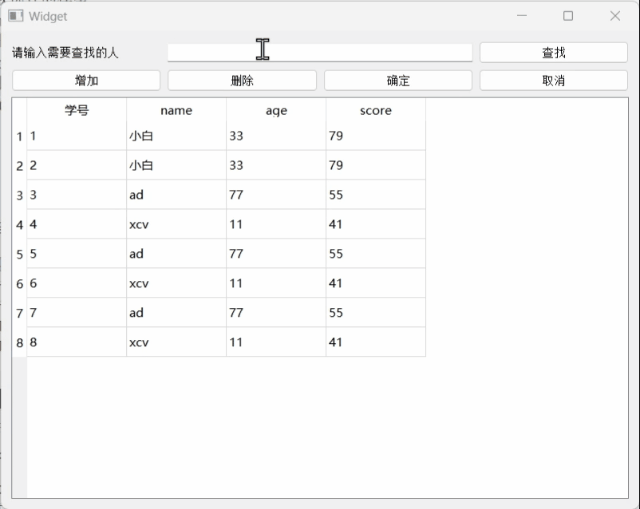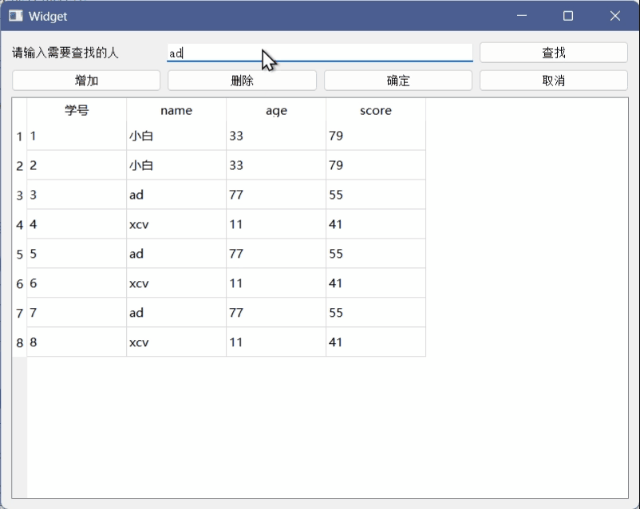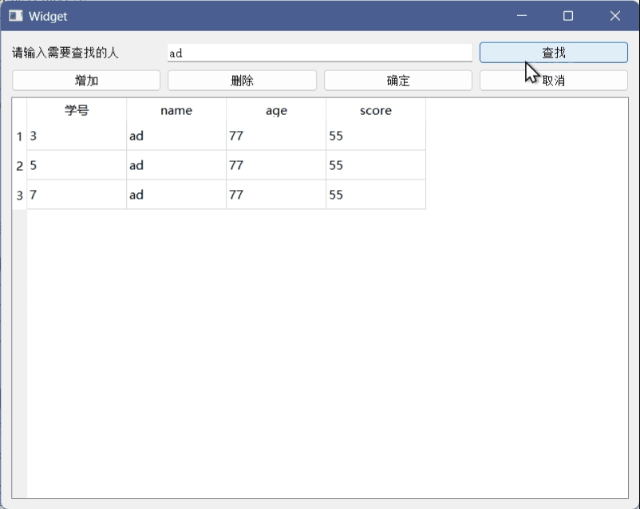
Qt学习记录(15)数据库
目录 前言: 数据库连接 项目文件加上sql 打印查看Qt支持哪些数据库驱动 QMYSQL [static] QSqlDatabase QSqlDatabase::addDatabase(const QString &type, const QString &connectionName QLatin1String(defaultConnection)) 数据库插入 头文件.h 源…...

c++常用设计模式
1、单例模式(Singleton):保证一个类只有一个实例,提供一个全局访问点; class Singleton { private:static Singleton* instance;Singleton() {}public:static Singleton* getInstance() {if (instance nullptr) {instance new Singleton()…...

【动手学深度学习】softmax回归从零开始实现的研究详情
目录 🌊1. 研究目的 🌊2. 研究准备 🌊3. 研究内容 🌍3.1 softmax回归的从零开始实现 🌍3.2 基础练习 🌊4. 研究体会 🌊1. 研究目的 理解softmax回归的原理和基本实现方式;学习…...
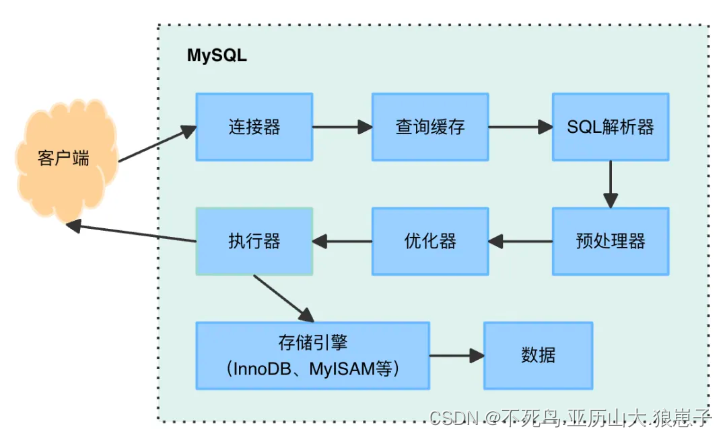
MySQL:MySQL执行一条SQL查询语句的执行过程
当多个客户端同时连接到MySQL,用SQL语句去增删改查数据,针对查询场景,MySQL要保证尽可能快地返回客户端结果。 了解了这些需求场景,我们可能会对MySQL进行如下设计: 其中,连接器管理客户端的连接,负责管理连接、认证鉴权等;查询缓存则是为了加速查询,命中则直接返回结…...

解决Python导入第三方模块报错“TypeError: the first argument must be callable”
注意以下内容只对导包时遇到同样的报错会有参考价值。 问题描述 当你尝试导入第三方模块时,可能会遇到如下报错信息: TypeError: the first argument must be callable 猜测原因 经过仔细检查代码,我猜测这个错误的原因是由于变量名冲突所…...

在python中连接了数据库后想要在python中通过图形化界面显示数据库的查询结果,请问怎么实现比较好? /ttk库的treeview的使用
在Python中,你可以使用图形用户界面(GUI)库来显示数据库的查询结果。常见的GUI库包括Tkinter(Python自带)、PyQt、wxPython等。以下是一个使用Tkinter库来显示数据库查询结果的简单示例。 首先,你需要确保…...
OZON的选品工具,OZON选品工具推荐
在电商领域,选品一直是决定卖家成功与否的关键因素之一。随着OZON平台的崛起,越来越多的卖家开始关注并寻求有效的选品工具,以帮助他们在这个竞争激烈的市场中脱颖而出。本文将详细介绍OZON的选品工具,并推荐几款实用的辅助工具&a…...
营销方案撰写秘籍:包含内容全解析,让你的方案脱颖而出
做了十几年品牌,策划出身,混迹过几个知名广告公司,个人经验供楼主参考。 只要掌握以下这些营销策划案的要点,你就能制作出既全面又专业的策划案,让你的工作成果不仅得到同事的认可,更能赢得老板的赏识&…...
如何制作一本温馨的电子相册呢?
随着科技的不断发展,电子相册已经成为了一种流行的方式来记录和分享我们的生活。一张张照片,一段段视频,都能让我们回忆起那些温馨的时光。那么,如何制作一本温馨的电子相册呢? 首先,选择一款合适的电子相册…...

485通讯网关
在工业自动化与智能化的浪潮中,数据的传输与交互显得尤为重要。作为这一领域的核心设备,485通讯网关凭借其卓越的性能和广泛的应用场景,成为了连接不同设备、不同协议之间数据转换和传输的桥梁。在众多485通讯网关中,HiWoo Box以其…...

ZeRO显存优化原理:从Adam状态切分到三阶段实战配置
1. 项目概述:当大模型训练卡在显存上,ZeRO 是怎么“拆墙”又“省电”的?你有没有试过在单张 A100 上跑一个 7B 参数的 LLaMA 模型微调?刚把模型 load 进去,torch.cuda.memory_allocated()就飙到 98%,OOM报错…...

微信小程序逆向工程:5步掌握wxappUnpacker核心技术与安全分析实战
微信小程序逆向工程:5步掌握wxappUnpacker核心技术与安全分析实战 【免费下载链接】wxappUnpacker forked from https://github.com/qwerty472123/wxappUnpacker 项目地址: https://gitcode.com/gh_mirrors/wxappu/wxappUnpacker 在当今移动应用生态中&#…...

区块链与计算机视觉融合:构建可信机器感知系统的架构与实践
1. 项目概述:当计算机视觉遇见区块链在人工智能的浪潮中,计算机视觉(CV)无疑是那颗最耀眼的明星之一。它让机器拥有了“看”和理解世界的能力,从医疗影像中精准定位病灶,到自动驾驶汽车识别路况,…...

3分钟掌握md2pdf:离线Markdown转PDF的终极指南
3分钟掌握md2pdf:离线Markdown转PDF的终极指南 【免费下载链接】md2pdf Offline markdown to pdf, choose -> edit -> transform 🥂 项目地址: https://gitcode.com/gh_mirrors/md/md2pdf 你是否经常需要将Markdown文档转换为PDF格式&#…...

Webdash社区贡献指南:如何参与开源项目并开发优质插件
Webdash社区贡献指南:如何参与开源项目并开发优质插件 【免费下载链接】webdash 🔥 Orchestrate your web project with Webdash the customizable web dashboard 项目地址: https://gitcode.com/gh_mirrors/we/webdash Webdash作为一款可定制的W…...

EdgeRemover终极指南:3种简单方法彻底卸载Windows 10/11的Microsoft Edge浏览器
EdgeRemover终极指南:3种简单方法彻底卸载Windows 10/11的Microsoft Edge浏览器 【免费下载链接】EdgeRemover A PowerShell script that correctly uninstalls or reinstalls Microsoft Edge on Windows 10 & 11. 项目地址: https://gitcode.com/gh_mirrors/…...
)
【云计算学习之路】学习Centos7系统:服务搭建(NFS)
文章目录【云计算学习之路】学习Centos7系统:服务搭建(NFS)前言一、NFS 核心原理与架构1.1 NFS 服务简介1.2 NFS 核心依赖与守护进程、端口机制1.2.1 基础依赖组件1.2.2 NFS 核心守护进程1.2.3 核心通信端口规则1.3 NFS 完整工作流程(附原理图解)1.4 常用…...

周末造AI公司:无代码+AI工作流48小时MVP实战
1. 项目概述:当“周末造AI公司”成为可复现的工程实践你有没有见过这样的场景:周五下班前,三个人在咖啡馆里画了一张白板草图;周六上午用Notion搭好产品框架、下午用Glide连上Airtable跑通用户注册流程;周日下午把Chat…...
)
Spring Boot项目实战:手把手教你集成银联B2B无卡支付(SM2国密证书版)
Spring Boot实战:银联B2B无卡支付集成全流程解析(SM2国密证书版) 在企业级应用开发中,支付功能是不可或缺的核心模块。银联B2B无卡支付作为国内企业间交易的重要渠道,其安全性和稳定性备受开发者关注。本文将带你从零开…...

模拟电路噪声分析五大误区:从频谱密度到电阻选型的实战避坑指南
1. 引言:噪声,模拟工程师的“老朋友”与“老对手”在模拟电路设计的江湖里,噪声就像一位如影随形的“老朋友”,你永远无法彻底摆脱它,却又不得不时刻提防它。它也是我们最棘手的“老对手”,一个不小心&…...