Git代码冲突原理与三路合并算法
Git代码冲突原理
Git合并文件是以行为单位进行一行一行合并的,但是有些时候并不是两行内容不一样Git就会报冲突,这是因为Git会帮助我们进行分析得出哪个结果是我们所期望的最终结果。而这个分析依据就是三路合并算法。当然,三路合并算法并不能帮助我们绝对的避免冲突,当三路合并算法也不能帮助我们合并结果时,这个时候Git会将冲突交由开发者,由开发者进行人工干预得出最终合并结果。
1.1 两路合并算法
学习三路合并时我们先了解一下"两路合并"。两路合并算法就是将两个文件进行逐行对别,如果行的内容不同就报冲突,两路合并示意图如下图所示。

两路合并的弊端是非常大的,他几乎没有任何作用。因为在两路合并中缺少了一个比较基准,在两个分支进行合并时,只要两个文件有某一行不一样,那么合并时必定出现冲突,这显然是不友好的。
假设对于同一个文件,其中有一个人在分支上修改了内容,但是我们并没有修改文件内容,此时我们想要合并其他人刚刚修改的内容,我们当前版本的内容(Ours)和其他人当前版本的(Theirs)Git都认为正确的,最终Git只能让我们自己来处理这种冲突了,这种情况非常多且没有必要出现冲突。而这种情况产生的核心就是缺少比较基准,即不知道Ours和Theirs上一个版本是什么,无法得出Ours和Theirs有没有对上一个版本进行改动。
1.2 三路合并算法
三路合并是Git中用于解决分支间差异和冲突的核心算法。在Git进行分支合并时,它会寻找三个提交点:两个分支的HEAD(即当前提交)以及它们共同的最近祖先提交。这被称为“三路”:
- 共同祖先(Common Ancestor):这是两个分支合并前的最近共享提交
- 当前分支(Ours):即将合并到的分支,通常是你正在操作并想要合并其他分支到的分支
- 待合并分支(Theirs):你想要合并进当前分支的那个分支
三路合并算法的工作原理如下:
- 对于每个文件,Git会对比这三个提交点(三路)中的内容。
- 如果在共同祖先之后,两个分支对同一文件做出了不同的修改,那么就会出现冲突,Git会在合并过程中标记出这些冲突,并暂停合并,等待用户手动解决。
- 如果双方对某个文件的修改不冲突(修改的内容是一致的),Git则能自动将这些更改合并在一起。
如下图,我们的代码(Ours)需要合并其他人的代码(Theris)的时候,Git会尝试找到这两次提交的共同祖先(Base),以共同祖先作为比较基准,如果一方相对于Base进行了修改,另一方相当于Base没有修改,那么此时合并成功,如果双方都相对于Base进行了修改,那么此时合并就会出现冲突。
如下图所示

代码演示如下:
rm -rf ./* .git # 重新初始化仓库
git init
echo "Hello" >> aaa.txt
git add ./
git commit -m 'Hello' ./git checkout -b test # 创建并切换到一个新分支
vi aaa.txt # 编辑为Hello World
cat aaa.txt
Hello Worldgit commit -m 'Hello World' ./ # 提交
git log --oneline # 此时还是同轴开发路线
* 594456e (HEAD -> test) Hello World
* 2bd777a (master) Hellogit checkout master
git merge test # 属于快进合并(不会出现代码冲突)
cat aaa.txt
Hello World
如下图,在Ours合并Theirs时,双方都相对于比较基准Base进行了修改,那么此时合并就会出现冲突。我们不难发现,下图描述的其实是一个典型合并的场景。

代码演示如下:
rm -rf ./* .git # 重新初始化仓库
git init
echo "Hello" >> aaa.txt
git add ./
git commit -m 'Hello' ./
git branch testvi aaa.txt
cat aaa.txt
Hello Gitgit commit -m 'Hello Git' ./
git log --oneline --all --graph
* 1317c49 (HEAD -> master) Hello Git
* 75b8528 (test) Hellogit checkout test # 切换到test分支开发
vi aaa.txt
cat aaa.txt
Hello Worldgit commit -m 'Hello World' ./
git log --oneline --all --graph
* c7aefff (HEAD -> test) Hello World # 产生分叉开发路线
| * 1317c49 (master) Hello Git
|/
* 75b8528 Hellogit checkout master # 切换回master分支
git merge test # 合并test分支(出现代码冲突)
Auto-merging aaa.txt
CONFLICT (content): Merge conflict in aaa.txt
Automatic merge failed; fix conflicts and then commit the result.cat aaa.txt # 查看冲突内容
<<<<<<< HEAD
Hello Git
=======
Hello World
>>>>>>> test
了解完上面的案例,我们可以把测试变为更加复杂,如下图。

通过上图我们可以得出如下规则。
- 只有一方修改了同一个文件的同一行内容,则最终合并结果为修改过的内容
- 双方都修改了同一文件的同一行内容:
- 如果双方修改的内容一致,则最终合并结果为修改过的内容
- 如果双方修改的内容不一致,则出现冲突
代码演示如下:
rm -rf ./* .git
git init
echo "A1" >> aaa.txt
echo "B2" >> aaa.txt
echo "C3" >> aaa.txt
echo "C3" >> aaa.txt
echo "D4" >> aaa.txt
echo "D4" >> aaa.txt
echo "E5" >> aaa.txt
git add ./
git commit -m 'a' ./git checkout -b test
echo "A1" > aaa.txt # 注意 ">" 会清空文件
echo "B2" >> aaa.txt
echo "C3" >> aaa.txt
echo "C0" >> aaa.txt
echo "D4" >> aaa.txt
echo "D1" >> aaa.txt
echo "E0" >> aaa.txt
git commit -m 'b' ./git checkout master
echo "A1" > aaa.txt # 注意 ">" 会清空文件
echo "B0" >> aaa.txt
echo "C3" >> aaa.txt
echo "C0" >> aaa.txt
echo "D4" >> aaa.txt
echo "D0" >> aaa.txt
echo "E0" >> aaa.txt
git commit -m 'c' ./# 合并test分支(产生冲突)
git merge test
Auto-merging aaa.txt
CONFLICT (content): Merge conflict in aaa.txt
Automatic merge failed; fix conflicts and then commit the result.# 查看冲突文件
cat aaa.txt
A1
B0
C3
C0
D4
<<<<<<< HEAD # 只有这一行出现了冲突
D0
=======
D1
>>>>>>> test
E0
通过这种三路合并策略,Git能够高效地处理大部分情况下的代码合并,同时确保开发者可以准确无误地解决任何出现的合并冲突,以维护项目历史的一致性和可追溯性。
通过三路合并算法,Git能够很灵活的帮助我们在一些情况下进行自动的代码合并,以及识别出代码是否冲突、冲突的部分等。但是Git底层判断文件差异的变更却是依赖于diff文件差异算法。也就是说,只有通过diff算法得出文件差异之后,才能够根据三路合并来进行下一步操作,例如是应该合并代码还是出现冲突以及冲突代码的识别等操作。这在某些情况下可能会出现一些细小的问题,例如我们分析下面案例。

通过我们之前分析的案例可以得出,冲突的只有第四行。
代码演示如下:
rm -rf ./* .git
git init
echo "A1" >> aaa.txt
echo "B2" >> aaa.txt
echo "C3" >> aaa.txt
echo "D4" >> aaa.txt
echo "E5" >> aaa.txt
git add ./
git commit -m 'a' ./git checkout -b test
echo "A1" > aaa.txt # 注意 ">" 会清空文件
echo "B2" >> aaa.txt
echo "C0" >> aaa.txt
echo "D1" >> aaa.txt
echo "E0" >> aaa.txt
git commit -m 'b' ./git checkout master
echo "A1" > aaa.txt # 注意 ">" 会清空文件
echo "B0" >> aaa.txt
echo "C3" >> aaa.txt
echo "D0" >> aaa.txt
echo "E0" >> aaa.txt
git commit -m 'c' ./# 合并test分支(产生冲突)
git merge test
Auto-merging aaa.txt
CONFLICT (content): Merge conflict in aaa.txt
Automatic merge failed; fix conflicts and then commit the result.cat aaa.txt
A1
<<<<<<< HEAD
B0
C3
D0
=======
B2
C0
D1
>>>>>>> test
E0
但是我们实际测试得出,出现冲突的不仅仅是第四行,如下图所示。

为什么②和③也会出现冲突呢?这中间就存在了diff算法的影响,diff算法计算从①之后的代码大部分都发生了变更,并没有逐行去对比内容,而是抛出了一整块的代码冲突。这可能是Git出于性能的考虑,虽然这样的做法在某些情况下并不明智,但这并不会对我们的开发造成很大的影响。在绝大多数情况下,我们并不会对代码那几行出现了冲突很敏感,我们只要灵活的掌握如何处理代码冲突就能应对实际开发过程中的实际问题。
1.3 递归三路合并
三路合并为我们在合并分支时提供了基准(Base),这个基准就是要合并分支的共同祖先,但有时候两个分支之间的共同祖先存在多个,这个时候Git就会将这两个分支的共同祖先做一次虚拟合并,当做这两个分支的共同祖先。这种情况常见于交叉合并,如下图所示。

B、C先合并一次成为D,然后B、C再合并一次成为E,此时E、D存在多个共同祖先为B和C。此时E和D如果要进行合并,需要找到一个唯一的共同祖先,Git的做法是先将B和C这两个共同祖先做一次虚拟合并为X,以X节点作为E和D合并时的唯一共同祖先。然而在合并B和C时又需要找到B和C的共同祖先(A),如果此时B和C也存在多个共同祖先,那么同样先把B和C的共同祖先做一次虚拟合并成为一个唯一的共同祖先。这个过程就是递归三路合并。
下面我们通过代码来完成上述图中表示。
(1)初始化仓库。
rm -rf .git ./*
git init
echo 'A' >> aaa.txt
git add ./
git commit -m 'A' ./
(2)开发B版本。
echo 'B' >> aaa.txt
git commit -m 'B' ./git log --oneline --all --graph
* 4bdf139 (HEAD -> master) B
* 18e222f A
(3)在A版本处建立分支,开发C版本。
git checkout -b test 18e222f # 在A版本处建立分支
echo "C" >> aaa.txt
git commit -m 'C' ./git log --oneline --all --graph
* 940e119 (HEAD -> test) C
| * 4bdf139 (master) B
|/
* 18e222f A
(4)切换到master分支,合并test分支。相当于B合并C。
git checkout master # 切换回master分支
git merge test # 合并test分支,相当与B合并C,出现冲突
cat aaa.txt # 查看冲突内容
A
<<<<<<< HEAD
B
=======
C
>>>>>>> testvi aaa.txt # 编辑文件(解决冲突)
cat aaa.txt
A
B
Cgit add ./
git commit -m 'D'
git log --oneline --all --graph
* 1262b32 (HEAD -> master) D
|\
| * 940e119 (test) C
* | 4bdf139 B
|/
* 18e222f A
(5)在B版本处建立一个新的分支,然后切换到该分支合并test分支。相当与B再合并一次C。
git checkout -b test-B 4bdf139 # 在B节点处建立一个新的分支
git log --oneline --all --graph
* 1262b32 (master) D
|\
| * 940e119 (test) C # test分支的位置
* | 4bdf139 (HEAD -> test-B) B # 新分支的位置
|/
* 18e222f Agit merge test # 合并test分支,相当于B合并C,出现冲突
cat aaa.txt # 查看冲突内容
A
<<<<<<< HEAD
B
=======
C
>>>>>>> testvi aaa.txt # 编辑文件(解决冲突)
cat aaa.txt # 查看内容
A
C
Bgit add./
git commit -m 'E'
git log --oneline --all --graph
* 9e610d9 (HEAD -> test-B) E # E的祖先有B和C
|\
| | * 1262b32 (master) D # D的祖先有B和C
| |/|
|/|/
| * 940e119 (test) C
* | 4bdf139 B
|/
* 18e222f A
(6)切换回master分支,合并test-B分支。相当于D合并E。
git checkout master # 切换到master分支
git merge test-B # 合并test-B分支,相当于D合并E,出现冲突
cat aaa.txt # 查看冲突内容
A
<<<<<<< HEAD
B
C
=======
C
B
>>>>>>> test-B
我们结合代码和文件内容等一起来分析一下Git递归三路合并算法,如图所示。
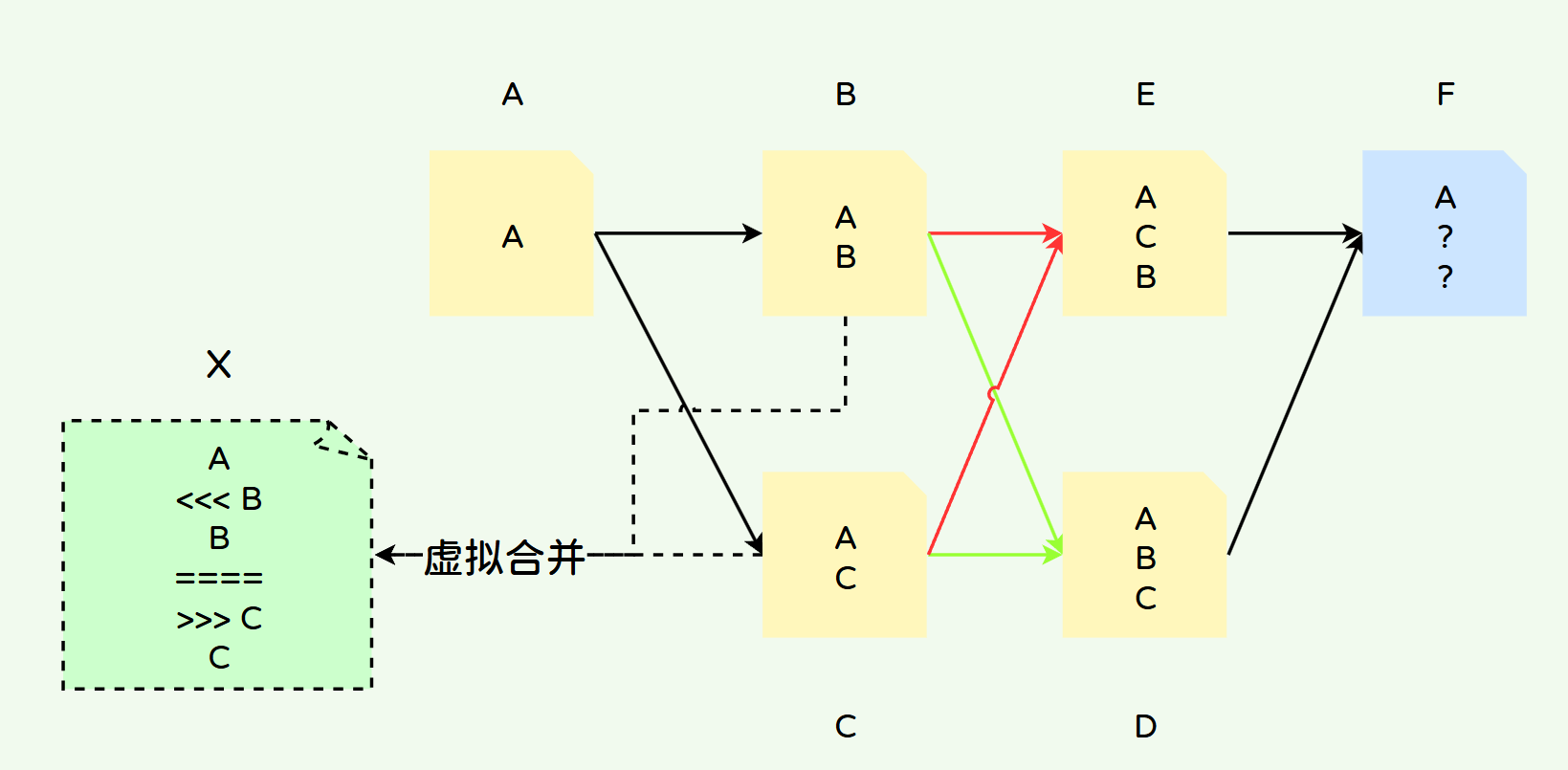
E和D合并时寻找共同祖先,找到了B和C,接着B和C做一次虚拟合并为X,其结果如下:
A
<<<<< B
B
=====
C
>>>>> C
本次X就是E和D合并时的共同祖先;Git将X节点冲突部分忽略,将剩余部分作为共同祖先的基准内容;因此,在D合并E时,出现如下内容:
A
<<<<<<< D
B
C
=======
C
B
>>>>>>> E
相关文章:
Git代码冲突原理与三路合并算法
Git代码冲突原理 Git合并文件是以行为单位进行一行一行合并的,但是有些时候并不是两行内容不一样Git就会报冲突,这是因为Git会帮助我们进行分析得出哪个结果是我们所期望的最终结果。而这个分析依据就是三路合并算法。当然,三路合并算法并不…...

聆思CSK6大模型开发板英语评测类开源SDK详解
离线英文评测算法SDK 能力简介 CSK6 大模型开发套件可以对用户通过语音输入的英文单词进行精准识别,并对单词的发音、错读、漏读、多读等方面进行评估,进行音素级的识别,根据用户的发音给出相应的建议和纠正,帮助用户更好地掌握单…...

通用大模型VS垂直大模型,你更青睐哪一方?
这里写目录标题 一、通用大模型简介二、垂直大模型简介三、通用大模型与垂直大模型的比较四、如何选择适合的模型五、通用大模型和垂直大模型的应用场景六、总结 近年来,随着人工智能技术的飞速发展,大模型的应用越来越广泛。无论是自然语言处理、计算机…...
Python第二语言(十四、高阶基础)
目录 1. 闭包 1.1 使用闭包注意事项 1.2 小结 2. 装饰器:实际上也是一种闭包; 2.1 装饰器的写法(闭包写法) :基础写法,只是解释装饰器是怎么写的; 2.2 装饰器的语法糖写法:函数…...

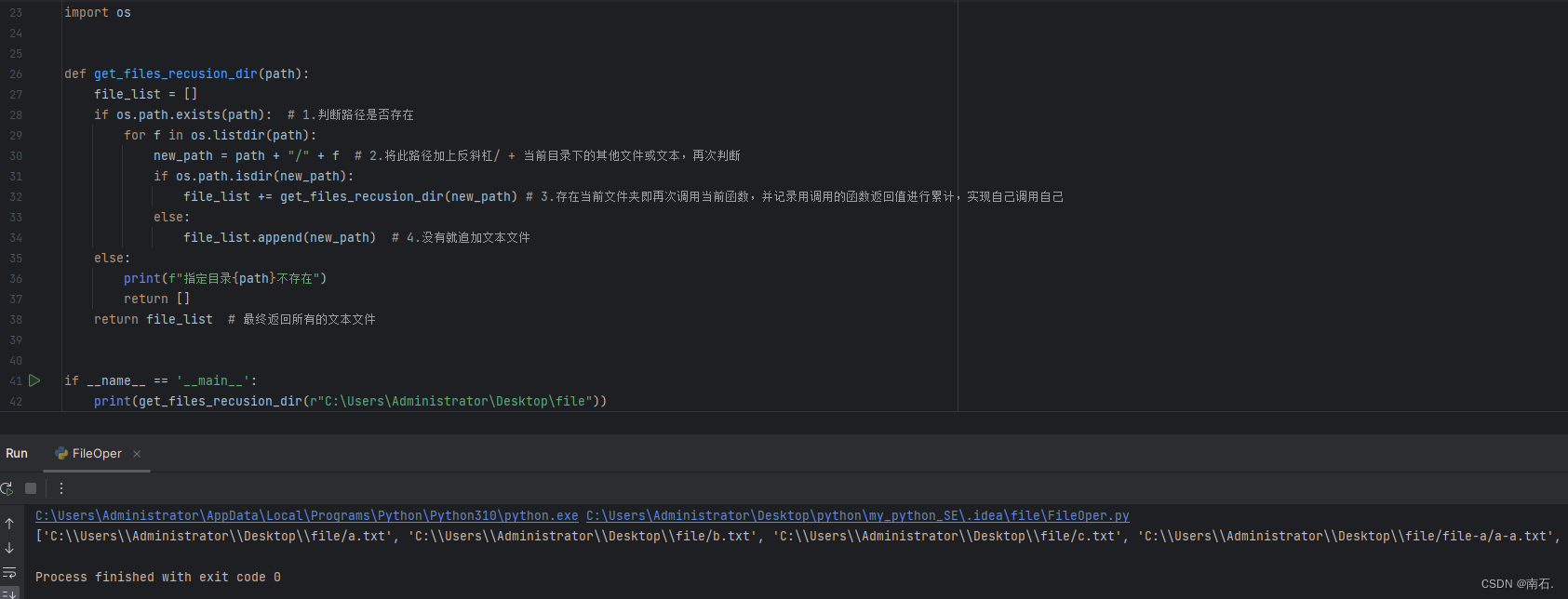
python脚本之调用其他目录脚本
import sys# 添加新路径到搜索路径中 sys.path.append(/脚本父级)# 现在可以导入该路径下的模块了 from 脚本 import 方法方法()...
定义及其使用)
C# 事件(Event)定义及其使用
1.定义个委托和类 //委托 public delegate void ProductEventHandler(Product product);/// <summary> /// 产品 /// </summary> public class Product {public int Id { get; set; }public string Code { get; set; }public string Name { get; set; }private de…...

2.负载压力测试
负载压力测试是一种重要的系统测试方法,旨在评估系统在正常和峰值负载情况下的性能表现。 一、基本概念: 负载压力测试是在一定约束条件下,通过模拟实际用户访问系统的行为,来测试系统所能承受的并发用户数、运行时间、数据量等&…...
【AI工具】jupyter notebook和jupyterlab对比和安装
简单说,jupyterlab是jupyter notebook的下一代。 选择安装一个即可。 一、这里是AI对比介绍 Jupyter Notebook和JupyterLab都是基于Jupyter内核的交互式计算环境,但它们在设计和功能上有一些关键的区别: 用户界面: Jupyter Not…...

Linux 基本指令3
date指令 date[选项][格式] %Y--年 %m--月 %d--日 %H--小时 %M--分 %S--秒 中间可用其他符号分割,不能使用空格。 -s 设置时间,会返回设置时间的信息并不是改变当前时间 设置全部时间年可用-或者:分割日期和时间用空格分隔ÿ…...
、PEM格式的公钥和PEM格式的私钥。)
在Linux系统中,可以使用OpenSSL来生成CSR(Certificate Signing Request)、PEM格式的公钥和PEM格式的私钥。
在Linux系统中,可以使用OpenSSL来生成CSR(Certificate Signing Request)、PEM格式的公钥和PEM格式的私钥。以下是生成这些文件的命令: 首先,生成私钥(通常是以.key结尾,但可以转换成PEM格式&am…...
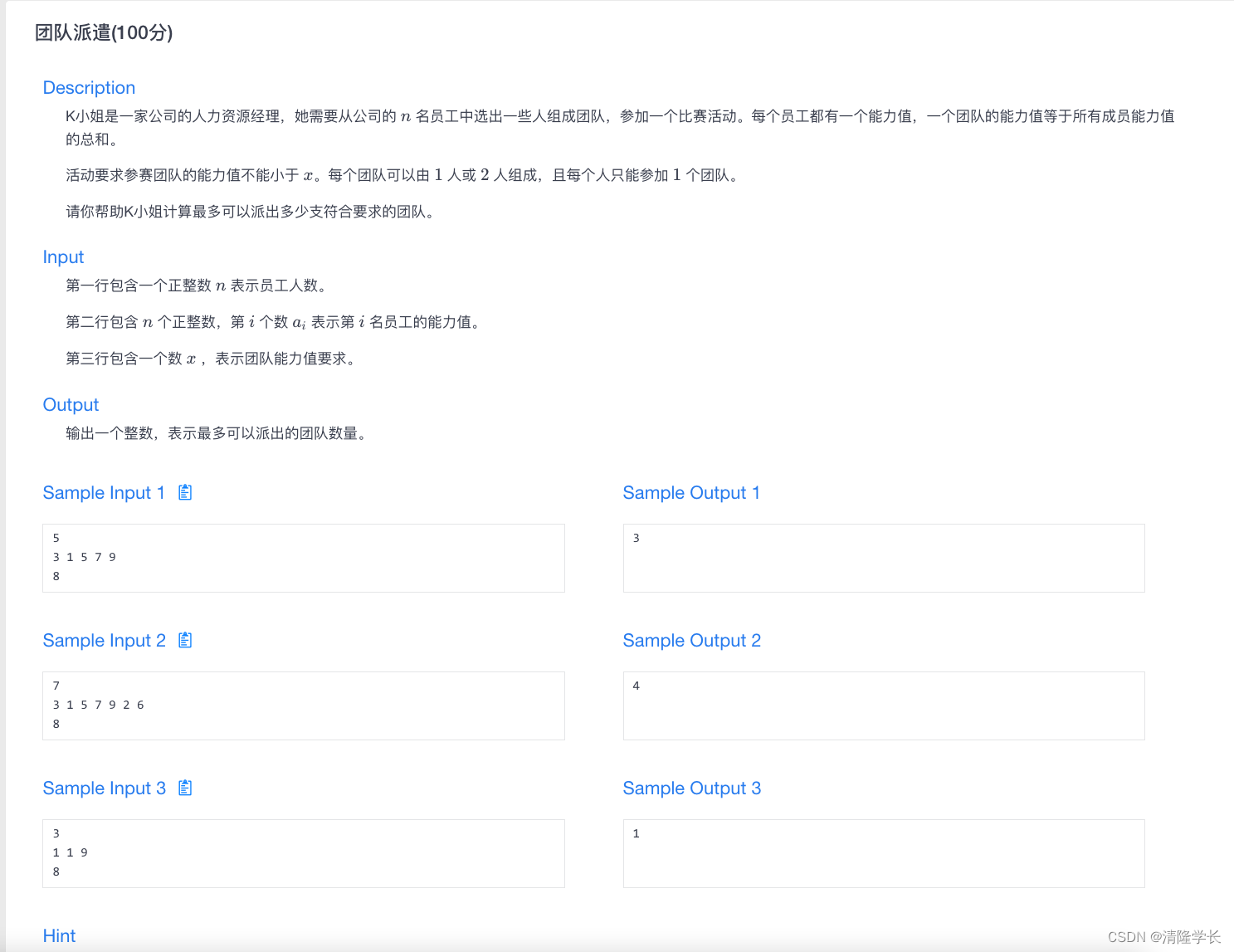
【2024最新华为OD-C/D卷试题汇总】[支持在线评测] 团队派遣(100分) - 三语言AC题解(Python/Java/Cpp)
🍭 大家好这里是清隆学长 ,一枚热爱算法的程序员 ✨ 本系列打算持续跟新华为OD-C/D卷的三语言AC题解 💻 ACM银牌🥈| 多次AK大厂笔试 | 编程一对一辅导 👏 感谢大家的订阅➕ 和 喜欢💗 🍓OJ题目截图 📎在线评测链接 团队派遣(100分) 🌍 评测功能需要订阅专栏…...

Python数据分析与机器学习在医疗诊断中的应用
文章目录 📑引言一、数据收集与预处理1.1 数据收集1.2 数据预处理 二、特征选择与构建2.1 特征选择2.2 特征构建 三、模型选择与训练3.1 逻辑回归3.2 随机森林3.3 深度学习 四、模型评估与调优4.1 交叉验证4.2 超参数调优 五、模型部署与应用5.1 模型保存与加载5.2 …...

vite.config.js如何使用env的环境变量
了解下环境变量在vite中 官方文档走起 https://cn.vitejs.dev/guide/env-and-mode.html#env-variables-and-modes 你见到的.env,.env.production等就是放置环境变量的 官方文档说到.env.[mode] # 只在指定模式下加载,比如.env.development只在开发环境加载 至于为什么是deve…...

MySql几十万条数据,同时新增或者修改
项目场景: 十万条甚至更多的数据新增或者修改 问题描述 现在有十万条数据甚至更多数据,在这些数据中,有部分数据存在数据库中,有部分数据确是新数据,存在的数据需要更新,不存在的数据需要新增 原因分析&a…...

如何提高MySQL DELETE 速度
提高MySQL中DELETE操作的速度通常涉及多个方面,包括优化查询、索引、表结构、硬件和配置等。以下是一些建议,以及一些示例代码,用于帮助我们提高DELETE操作的速度。 1.提高MySQL DELETE 速度的方法 1.1 优化查询 只删除必要的行:…...
本地Zabbix开源监控系统安装内网穿透实现远程访问详细教程
文章目录 前言1. Linux 局域网访问Zabbix2. Linux 安装cpolar3. 配置Zabbix公网访问地址4. 公网远程访问Zabbix5. 固定Zabbix公网地址 💡推荐 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。【…...

从Android刷机包提取System和Framework
因为VIVO的手机很难解锁BL和Root,故直接从ADB中获取完整的Framework代码是比较困难的。我就考虑直接从VIVO提供的刷机包文件中获取相关的代码 由于vivo把system.new.dat分割了,所以下一步,我们使用cat命令,合并这些文件࿰…...

分布式光纤测温DTS与红外热成像系统的主要区别是什么?
分布式光纤测温DTS和红外热成像系统在应用领域和工作原理上存在显著的区别,两者具有明显的差异性。红外热成像系统适用于表现扩散式发热、面式场景以及环境条件较好的情况下。它主要用于检测物体表面的温度,并且受到镜头遮挡或灰尘等因素的影响会导致失效…...
python数据分析-问卷数据分析(地理课)
学生问卷 分析学生背景:班级分布、每周地理课数量、地理成绩分布 根据问卷,可以知道: 班级分布: 七年级有118名学生。 八年级有107名学生。 每周地理课的数量: 有28名学生每周有1节地理课。 有99名学生每周有2…...

【ARM64 常见汇编指令学习 19.3 -- ARMv8 三目运算指令 csel 详细介绍】
请阅读【嵌入式开发学习必备专栏】 文章目录 三目运算指令 csel地址获取条件选择用途 三目运算指令 csel 本篇文章以下面汇编代码介绍三目运算指令csel: adr x0, pass_messageadr x1, fail_messagecsel x1, x0, x1, pl下面是对这几行代码的详解&#x…...

影墨·今颜GPU算力适配:RTX 4090单卡实测每秒1.8张1024x1536图
影墨今颜GPU算力适配:RTX 4090单卡实测每秒1.8张1024x1536图 1. 引言:当顶级AI影像遇上顶级显卡 如果你是一位内容创作者,或者对AI生成人像有浓厚兴趣,那么“影墨今颜”这个名字最近可能已经进入了你的视野。它被描述为一款融合…...

效率提升:基于快马平台实现openclaw windows部署的自动化与优化
最近在团队里负责优化openclaw在Windows环境的部署流程,发现传统手动部署方式存在不少效率瓶颈。经过在InsCode(快马)平台上的实践,我们实现了一套自动化部署方案,效果提升明显。这里分享几个关键优化点: 全流程一键化部署 过去部…...

AntimicroX完全指南:游戏手柄映射的艺术与科学
AntimicroX完全指南:游戏手柄映射的艺术与科学 【免费下载链接】antimicrox Graphical program used to map keyboard buttons and mouse controls to a gamepad. Useful for playing games with no gamepad support. 项目地址: https://gitcode.com/GitHub_Trend…...
Pixel Aurora Engine效果展示:青蓝+明黄配色系像素画作视觉冲击力解析
Pixel Aurora Engine效果展示:青蓝明黄配色系像素画作视觉冲击力解析 1. 视觉震撼力解析 Pixel Aurora Engine通过精心设计的青蓝明黄配色方案,创造出极具视觉冲击力的像素艺术作品。这种色彩组合源自经典16位游戏的美学理念,但通过现代AI技…...

Wan2.2-I2V-A14B企业应用:法律文书解读AI动画视频生成系统
Wan2.2-I2V-A14B企业应用:法律文书解读AI动画视频生成系统 1. 系统概述与核心价值 法律行业每天需要处理大量文书材料,传统的人工解读和可视化呈现方式效率低下且成本高昂。Wan2.2-I2V-A14B法律文书解读AI动画视频生成系统正是为解决这一痛点而生。 这…...

Phi-3-mini-4k-instruct-gguf多场景落地:跨境电商多语言商品描述批量生成
Phi-3-mini-4k-instruct-gguf多场景落地:跨境电商多语言商品描述批量生成 1. 跨境电商的痛点与解决方案 跨境电商卖家每天面临的最大挑战之一,就是为同一款商品准备不同语言版本的描述。传统做法要么需要雇佣多语种文案人员,要么使用机械的…...

别再手动画封装了!用嘉立创EDA免费库5分钟搞定Altium Designer缺失的器件
5分钟极速救援:用嘉立创EDA破解Altium Designer封装缺失难题 深夜11点,李工盯着屏幕上闪烁的光标和半成品的PCB布局图,额头渗出细密的汗珠。项目交付截止前48小时,团队突然发现Altium Designer官方库中缺少关键芯片TPS5430DDAR的封…...

**元宇宙经济中的智能合约开发实战:用Solidity构建去中心化资产交易系统**在元宇宙经济蓬勃发展的今
元宇宙经济中的智能合约开发实战:用Solidity构建去中心化资产交易系统 在元宇宙经济蓬勃发展的今天,数字资产的流通与确权成为核心议题。无论是虚拟土地、NFT艺术品还是游戏道具,背后都离不开区块链技术的支持。而智能合约正是连接现实世界资…...

如何快速掌握MelonLoader:从零基础到精通Unity游戏模组加载的完整教程
如何快速掌握MelonLoader:从零基础到精通Unity游戏模组加载的完整教程 【免费下载链接】MelonLoader The Worlds First Universal Mod Loader for Unity Games compatible with both Il2Cpp and Mono 项目地址: https://gitcode.com/gh_mirrors/me/MelonLoader …...

避开这3个坑!Cortex-M3/M4使用DWT计数器时的常见错误与解决方法
Cortex-M3/M4开发实战:DWT计数器避坑指南与高阶应用技巧 在嵌入式系统开发中,精确的时间测量往往是性能优化和调试的关键。Cortex-M3/M4内核内置的DWT(Data Watchpoint and Trace)组件,特别是其CYCCNT计数器,为开发者提供了一个零…...