pytorch神经网络训练(AlexNet)
- 导包
import osimport torchimport torch.nn as nnimport torch.optim as optimfrom torch.utils.data import Dataset, DataLoaderfrom PIL import Imagefrom torchvision import models, transforms- 定义自定义图像数据集
class CustomImageDataset(Dataset): 定义一个自定义的图像数据集类,继承自Dataset
def __init__(self, main_dir, transform=None): 初始化方法,接收主目录和转换方法
self.main_dir = main_dir 主目录,包含多个子目录,每个子目录包含同一类别的图像
self.transform = transform图像转换方法,用于对图像进行预处理
self.files = [] 存储所有图像文件的路径
self.labels = [] 存储所有图像的标签
self.label_to_index = {} 创建一个字典,用于将标签映射到索引
for index, label in enumerate(os.listdir(main_dir)):遍历主目录中的所有子目录
self.label_to_index[label] = index label_dir = os.path.join(main_dir, label) 将标签映射到索引,构建标签子目录的路径
if os.path.isdir(label_dir): for file in os.listdir(label_dir): self.files.append(os.path.join(label_dir, file))self.labels.append(label) 如果是目录,遍历目录中的所有文件,将文件路径添加到列表,将标签添加到列表
def __len__(self):定义数据集的长度
return len(self.files) 返回文件列表的长度
def __getitem__(self, idx): 定义获取数据集中单个样本的方法
image = Image.open(self.files[idx]) label = self.labels[idx] if self.transform: image = self.transform(image) return image, self.label_to_index[label] 打开图像文件,获取图像的标签,如果有转换方法,对图像进行转换,返回图像和对应的标签索引
- 定义数据转换
transform = transforms.Compose([transforms.Resize((227, 227)), # AlexNet的输入图像大小transforms.RandomHorizontalFlip(), # 随机水平翻转transforms.RandomRotation(10), # 随机旋转transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), # AlexNet的标准化])- 创建数据集
dataset = CustomImageDataset(main_dir="D:\\图像处理、深度学习\\flowers", transform=transform)- 创建数据加载器
data_loader = DataLoader(dataset, batch_size=32, shuffle=True)- 加载预训练的AlexNet模型
alexnet_model = models.alexnet(pretrained=True)- 修改最后几层以适应新的分类任务
num_ftrs = alexnet_model.classifier[6].in_featuresalexnet_model.classifier[6] = nn.Linear(num_ftrs, len(dataset.label_to_index))- 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()optimizer = optim.Adam(alexnet_model.parameters(), lr=0.0001)- 如果有多个GPU,可以使用nn.DataParallel来并行化模型
if torch.cuda.device_count() > 1:alexnet_model = nn.DataParallel(alexnet_model)- 将模型发送到GPU(如果可用)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")alexnet_model.to(device) 
- 模型评估
def evaluate_model(model, data_loader, device):model.eval() # 将模型设置为评估模式correct = 0total = 0with torch.no_grad(): # 在这个块中,所有计算都不会计算梯度for images, labels in data_loader:images, labels = images.to(device), labels.to(device)outputs = model(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()accuracy = 100 * correct / totalreturn accuracy- 训练模型
num_epochs = 10for epoch in range(num_epochs):alexnet_model.train()running_loss = 0.0for images, labels in data_loader:images, labels = images.to(device), labels.to(device)前向传播
outputs = alexnet_model(images)loss = criterion(outputs, labels)反向传播和优化
optimizer.zero_grad()loss.backward()optimizer.step()running_loss += loss.item()在每个epoch结束后评估模型
train_accuracy = evaluate_model(alexnet_model, data_loader, device)print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {running_loss / len(data_loader):.4f}, Train Accuracy: {train_accuracy:.2f}%')
相关文章:
pytorch神经网络训练(AlexNet)
导包 import osimport torchimport torch.nn as nnimport torch.optim as optimfrom torch.utils.data import Dataset, DataLoaderfrom PIL import Imagefrom torchvision import models, transforms 定义自定义图像数据集 class CustomImageDataset(Dataset): 定义一个自…...

构建大语言模型友好型网站
以大语言模型为代表的AI 技术迅速发展,将会影响原有信息网络的方式。其中一个明显的趋势是通过chatGPT 对话代替搜索引擎和浏览器来获取信息。 互联网时代,主要是通过网站(website)提供信息。网站主要为人类阅读的方式构建的。主要…...
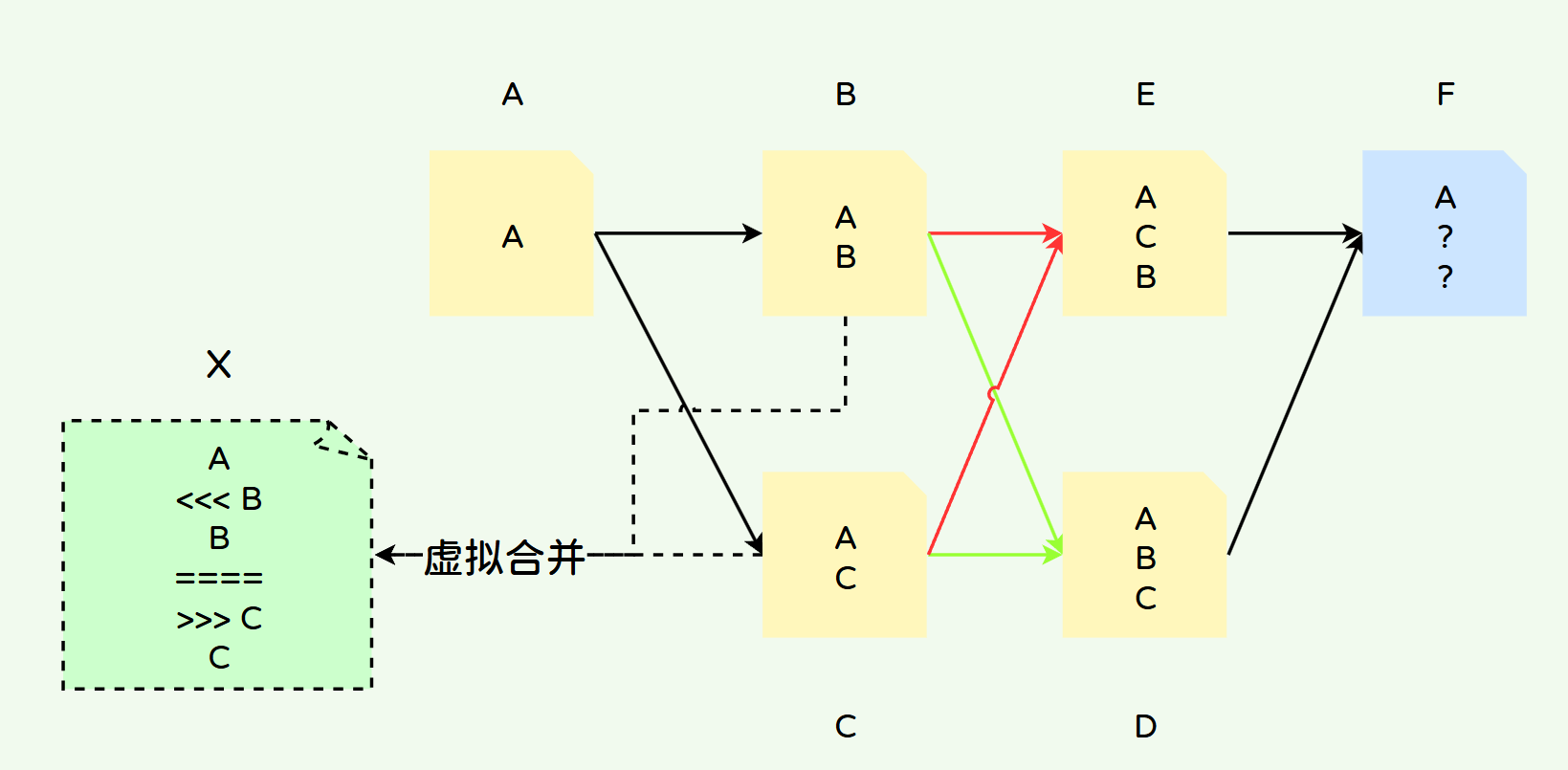
Git代码冲突原理与三路合并算法
Git代码冲突原理 Git合并文件是以行为单位进行一行一行合并的,但是有些时候并不是两行内容不一样Git就会报冲突,这是因为Git会帮助我们进行分析得出哪个结果是我们所期望的最终结果。而这个分析依据就是三路合并算法。当然,三路合并算法并不…...

聆思CSK6大模型开发板英语评测类开源SDK详解
离线英文评测算法SDK 能力简介 CSK6 大模型开发套件可以对用户通过语音输入的英文单词进行精准识别,并对单词的发音、错读、漏读、多读等方面进行评估,进行音素级的识别,根据用户的发音给出相应的建议和纠正,帮助用户更好地掌握单…...

通用大模型VS垂直大模型,你更青睐哪一方?
这里写目录标题 一、通用大模型简介二、垂直大模型简介三、通用大模型与垂直大模型的比较四、如何选择适合的模型五、通用大模型和垂直大模型的应用场景六、总结 近年来,随着人工智能技术的飞速发展,大模型的应用越来越广泛。无论是自然语言处理、计算机…...
Python第二语言(十四、高阶基础)
目录 1. 闭包 1.1 使用闭包注意事项 1.2 小结 2. 装饰器:实际上也是一种闭包; 2.1 装饰器的写法(闭包写法) :基础写法,只是解释装饰器是怎么写的; 2.2 装饰器的语法糖写法:函数…...

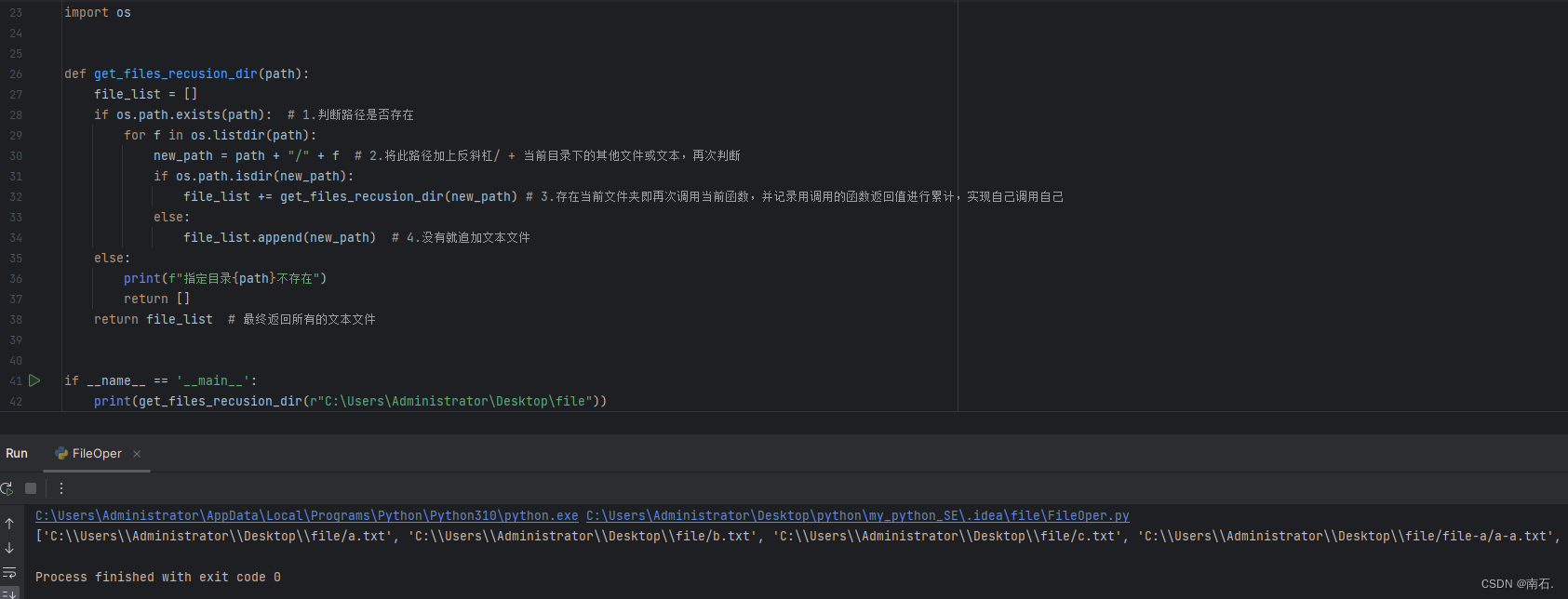
python脚本之调用其他目录脚本
import sys# 添加新路径到搜索路径中 sys.path.append(/脚本父级)# 现在可以导入该路径下的模块了 from 脚本 import 方法方法()...
定义及其使用)
C# 事件(Event)定义及其使用
1.定义个委托和类 //委托 public delegate void ProductEventHandler(Product product);/// <summary> /// 产品 /// </summary> public class Product {public int Id { get; set; }public string Code { get; set; }public string Name { get; set; }private de…...

2.负载压力测试
负载压力测试是一种重要的系统测试方法,旨在评估系统在正常和峰值负载情况下的性能表现。 一、基本概念: 负载压力测试是在一定约束条件下,通过模拟实际用户访问系统的行为,来测试系统所能承受的并发用户数、运行时间、数据量等&…...
【AI工具】jupyter notebook和jupyterlab对比和安装
简单说,jupyterlab是jupyter notebook的下一代。 选择安装一个即可。 一、这里是AI对比介绍 Jupyter Notebook和JupyterLab都是基于Jupyter内核的交互式计算环境,但它们在设计和功能上有一些关键的区别: 用户界面: Jupyter Not…...

Linux 基本指令3
date指令 date[选项][格式] %Y--年 %m--月 %d--日 %H--小时 %M--分 %S--秒 中间可用其他符号分割,不能使用空格。 -s 设置时间,会返回设置时间的信息并不是改变当前时间 设置全部时间年可用-或者:分割日期和时间用空格分隔ÿ…...
、PEM格式的公钥和PEM格式的私钥。)
在Linux系统中,可以使用OpenSSL来生成CSR(Certificate Signing Request)、PEM格式的公钥和PEM格式的私钥。
在Linux系统中,可以使用OpenSSL来生成CSR(Certificate Signing Request)、PEM格式的公钥和PEM格式的私钥。以下是生成这些文件的命令: 首先,生成私钥(通常是以.key结尾,但可以转换成PEM格式&am…...
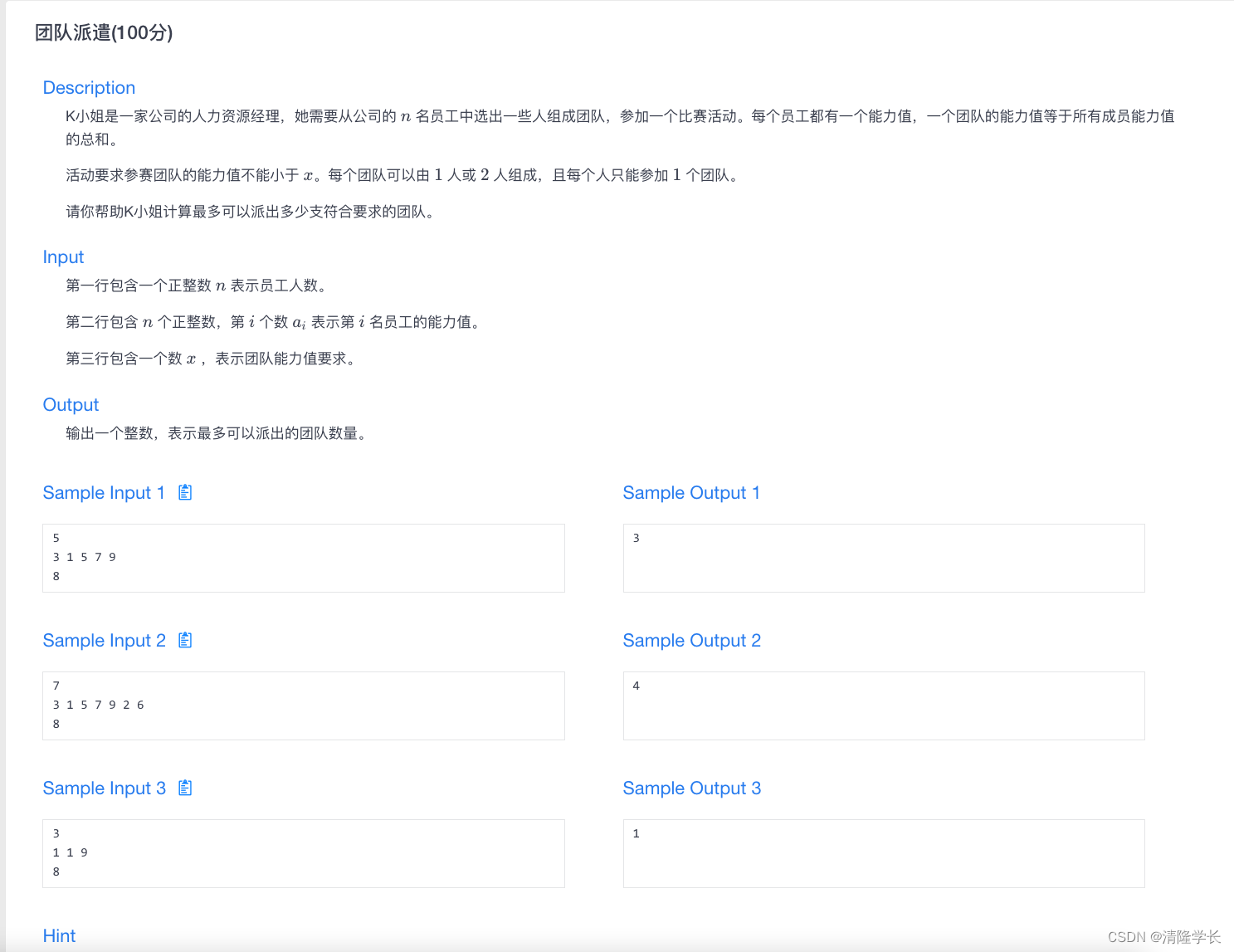
【2024最新华为OD-C/D卷试题汇总】[支持在线评测] 团队派遣(100分) - 三语言AC题解(Python/Java/Cpp)
🍭 大家好这里是清隆学长 ,一枚热爱算法的程序员 ✨ 本系列打算持续跟新华为OD-C/D卷的三语言AC题解 💻 ACM银牌🥈| 多次AK大厂笔试 | 编程一对一辅导 👏 感谢大家的订阅➕ 和 喜欢💗 🍓OJ题目截图 📎在线评测链接 团队派遣(100分) 🌍 评测功能需要订阅专栏…...

Python数据分析与机器学习在医疗诊断中的应用
文章目录 📑引言一、数据收集与预处理1.1 数据收集1.2 数据预处理 二、特征选择与构建2.1 特征选择2.2 特征构建 三、模型选择与训练3.1 逻辑回归3.2 随机森林3.3 深度学习 四、模型评估与调优4.1 交叉验证4.2 超参数调优 五、模型部署与应用5.1 模型保存与加载5.2 …...

vite.config.js如何使用env的环境变量
了解下环境变量在vite中 官方文档走起 https://cn.vitejs.dev/guide/env-and-mode.html#env-variables-and-modes 你见到的.env,.env.production等就是放置环境变量的 官方文档说到.env.[mode] # 只在指定模式下加载,比如.env.development只在开发环境加载 至于为什么是deve…...

MySql几十万条数据,同时新增或者修改
项目场景: 十万条甚至更多的数据新增或者修改 问题描述 现在有十万条数据甚至更多数据,在这些数据中,有部分数据存在数据库中,有部分数据确是新数据,存在的数据需要更新,不存在的数据需要新增 原因分析&a…...

如何提高MySQL DELETE 速度
提高MySQL中DELETE操作的速度通常涉及多个方面,包括优化查询、索引、表结构、硬件和配置等。以下是一些建议,以及一些示例代码,用于帮助我们提高DELETE操作的速度。 1.提高MySQL DELETE 速度的方法 1.1 优化查询 只删除必要的行:…...
本地Zabbix开源监控系统安装内网穿透实现远程访问详细教程
文章目录 前言1. Linux 局域网访问Zabbix2. Linux 安装cpolar3. 配置Zabbix公网访问地址4. 公网远程访问Zabbix5. 固定Zabbix公网地址 💡推荐 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。【…...

从Android刷机包提取System和Framework
因为VIVO的手机很难解锁BL和Root,故直接从ADB中获取完整的Framework代码是比较困难的。我就考虑直接从VIVO提供的刷机包文件中获取相关的代码 由于vivo把system.new.dat分割了,所以下一步,我们使用cat命令,合并这些文件࿰…...

分布式光纤测温DTS与红外热成像系统的主要区别是什么?
分布式光纤测温DTS和红外热成像系统在应用领域和工作原理上存在显著的区别,两者具有明显的差异性。红外热成像系统适用于表现扩散式发热、面式场景以及环境条件较好的情况下。它主要用于检测物体表面的温度,并且受到镜头遮挡或灰尘等因素的影响会导致失效…...
5步打造Windows桌面美学:TranslucentTB任务栏透明化完全指南
5步打造Windows桌面美学:TranslucentTB任务栏透明化完全指南 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 厌倦了Windows系…...

通义千问1.8B-Chat部署教程:Supervisor管理服务,稳定运行不中断
通义千问1.8B-Chat部署教程:Supervisor管理服务,稳定运行不中断 1. 项目概述 通义千问1.5-1.8B-Chat-GPTQ-Int4是阿里云推出的轻量级对话模型,经过GPTQ-Int4量化后,显存需求仅约4GB,非常适合在消费级GPU或边缘设备上…...

快速体验WAN2.2文生视频:ComfyUI预置工作流,2分钟生成测试视频
快速体验WAN2.2文生视频:ComfyUI预置工作流,2分钟生成测试视频 1. 为什么选择WAN2.2文生视频工作流 如果你正在寻找一个简单易用、效果出色的文生视频工具,WAN2.2文生视频工作流绝对值得一试。这个预置在ComfyUI中的工作流,让视…...

Go Module 依赖冲突调试方法
Go Module 依赖冲突调试方法 在Go语言开发中,依赖管理是一个关键环节。随着项目规模的扩大,依赖的第三方库越来越多,版本冲突问题也愈发常见。Go Module作为官方推荐的依赖管理工具,虽然简化了依赖管理流程,但在多级依…...

【生产环境禁用警告】:这6个Python内存反模式正悄悄拖垮你的K8s Pod——附自动检测脚本
第一章:Python智能体内存管理策略生产环境部署在高并发、长生命周期的Python智能体服务中,内存管理直接影响系统稳定性与响应延迟。默认的CPython引用计数循环垃圾回收(GC)机制在动态对象频繁创建销毁的场景下易引发内存抖动和不可…...

Rust Web开发:ActixWeb实战指南
1. 为什么选择ActixWeb进行Rust Web开发 我第一次接触ActixWeb是在三年前的一个电商项目里,当时团队需要处理每秒上万次的库存查询请求。测试了多个Rust框架后,ActixWeb凭借其卓越的性能表现脱颖而出——在同等硬件条件下,它的QPS(…...
)
告别台式机没麦克风的尴尬:用SonoBus+VB-Cable把手机秒变无线麦(保姆级配置)
台式机零成本无线麦克风方案:SonoBus与VB-Cable实战指南 你是否遇到过这样的尴尬时刻——台式电脑突然需要语音沟通,却发现没有麦克风?无论是紧急会议、游戏开黑还是直播互动,这种硬件缺失带来的困扰可能让你措手不及。本文将介绍…...
设计)
从原理到代码:深入解析UniFormer的多头关系聚合器(MHRA)设计
从原理到代码:深入解析UniFormer的多头关系聚合器(MHRA)设计 视频理解领域近年来经历了从3D卷积网络到视觉Transformer的范式转变,但两者在时空特征提取上各有限制。3D CNN擅长捕捉局部时空特征却受限于固定感受野,而视觉Transformer虽能建模…...

知乎上线求职工具,助力毕业生破困局
知乎上线求职利器,直击毕业生痛点2026届全国普通高校毕业生预计达1270万人,再创历史新高。与此同时,AI技术加速行业重构,部分传统岗位需求收缩,大量毕业生陷入“海投”困境,难以精准定位自身。在此背景下&a…...

Super IO:提升Blender批量处理效率的自动化流程解决方案
Super IO:提升Blender批量处理效率的自动化流程解决方案 【免费下载链接】super_io blender addon for copy paste import / export 项目地址: https://gitcode.com/gh_mirrors/su/super_io 在3D设计工作流中,设计师常常面临文件格式转换繁琐、跨…...