MySQL基础---库的操作和表的操作(配着自己的实操图,简单易上手)
绪论
勿问成功的秘诀为何,且尽全力做您应该做的事吧。–美华纳;本章是MySQL的第二章,本章主要写道MySQL中库和表的增删查改以及对库和表的备份处理,本章是基于上一章所写若没安装mysql可以查看Linux下搭建mysql软件及登录和基本使用,同时也强烈建议先上一章在看本章。
话不多说安全带系好,发车啦(建议电脑观看)。

思维导图:

1.库的操作
1.1创建库
创建数据库
语法:
CREATE DATABASE [IF NOT EXISTS] db_name [create_specification [,create_specification] ...]create_specification:
[DEFAULT] CHARACTER SET charset_name #字符集
[DEFAULT] COLLATE collation_name #校验规则
[] 是可选项,也就表示着括号内的内容可填可不填的。
其中 IF NOT EXISTS:表示判断下创建的库是否存在(创建的文件存在了就会报错误信息)
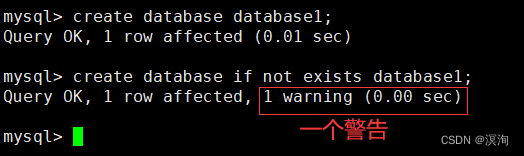
1.1.1指定编码在创建数据库时:
当我们创建数据库没有指定字符集和校验规则时,系统使用默认字符集:utf8,校验规则是:utf8_ general_ ci(在配置文件中写的)
设置库的字符集和校验规则
语法:
create database dbname charset=字符集 collate 校验规则;
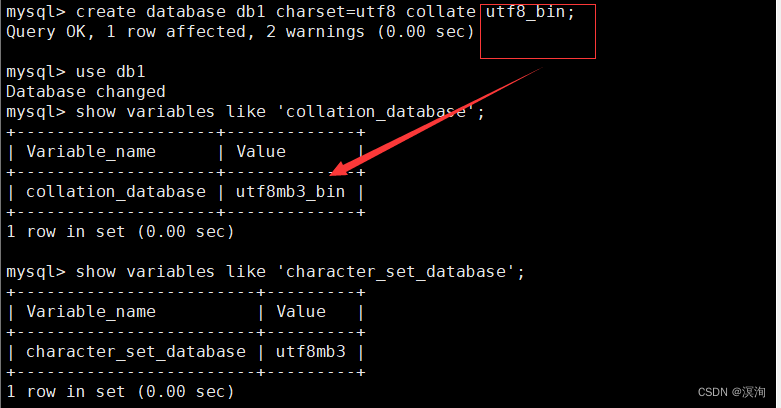
单独的设置字符集:
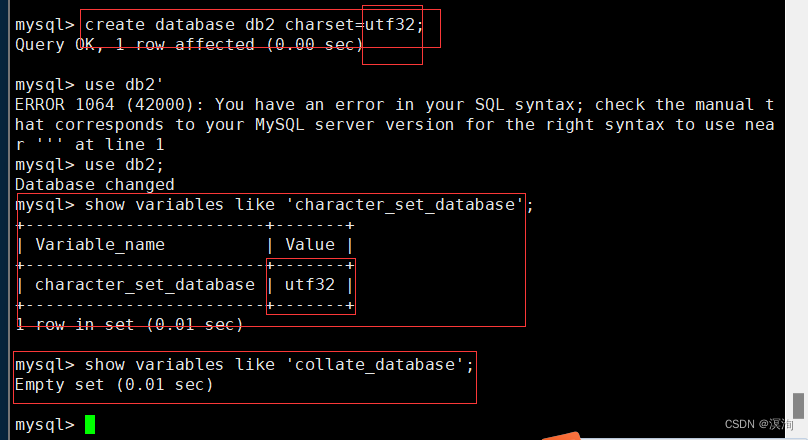
1.1.2字符集和校验规则:
- 数据库字符集 — 数据库未来存储的数据
- 数据库校验集 — 支持数据库,进行字段比较时使用的编码,本质是一种读取数据库中数据的采用的编码格式
写和读的编码集必须是统一的,也就是数据库无论对数据的任何操作,都必须保证操作和编码必须保持一致
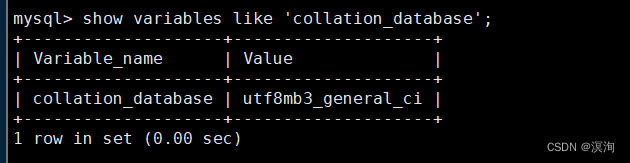
查看系统默认字符集以及校验规则:
查看字符集:
show variables like 'character_set_database';
查看校验集;
show variables like 'collation_database';

查看数据库支持的字符集和校验规则:
查看数据库所有支持的字符集:
show charset;
查看数据库支持的校验规则:
show collation;


1.1.3校验规则对数据库的影响
上面所用到的的utf8_general_ci是不区分大小写的、而utf8_bin区分大小写。
验证utf8_general_ci是不区分大小写的如下(附:db数据库的校验规则是utf_general_ci):
在表中查找某个数据验证
语法:
select * from table_name where row_name=check_information;
具体使用:
select * from person where name='a';

上图发现排序后的a、A是一样的,故是不区分大小写的。
排序方法验证(默认升序)
语法:
select * from table_name order by Row_name;
具体使用:
select * from person order by name;

utf8_bin区分大小写的:
在表中查找某个数据
语法:
select * from table_name where row_name=check_information;
具体使用:
select * from person where name='a';
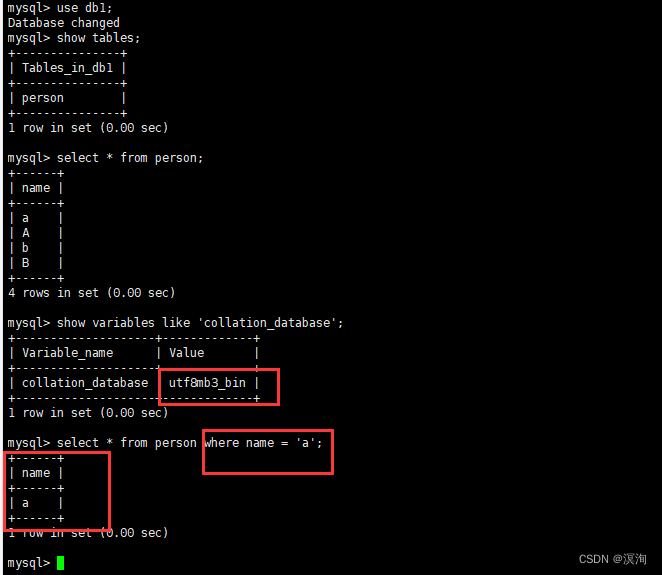
上图只查出了一个就表示是区分大小写的(a!=A)
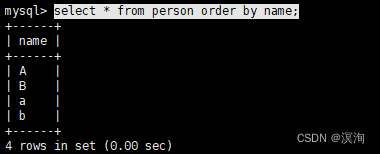
排序(默认升序):
语法:
select * from table_name order by Row_name;
具体使用:
select * from person order by name;
1.2删除库
语法:
DROP DATABASE [IF EXISTS] db_ name;
附:强烈不建议轻易的删除数据库
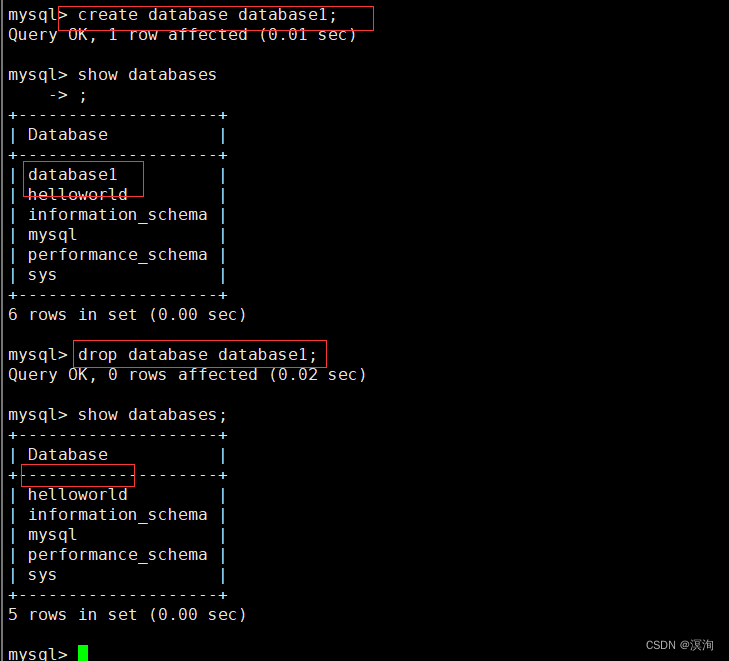
执行删除之后的结果:
- 数据库内部看不到对应的数据库
- 对应的数据库文件夹被删除,级联删除,里面的数据表全部被删
1.3查看库
查看数据库的语法:
show databases;

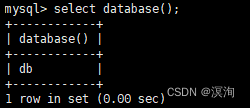
查看当前所在数据库的语法:
select database();
如当前在db数据库下:
显示创建库的语句
语法:
show create database dbname; #dbname就是数据库名

- 其中在查看到创建库的语句中的 /*!40100 default… */ 这个不是注释,表示当前mysql版本大于4.01版本,就执行这句话
1.4修改库
语法:
ALTER DATABASE db_name [alter_spacification [,alter_spacification]...]alter_spacification:
[DEFAULT] CHARACTER SET charset_name #字符集
[DEFAULT] COLLATE collation_name #校验规则
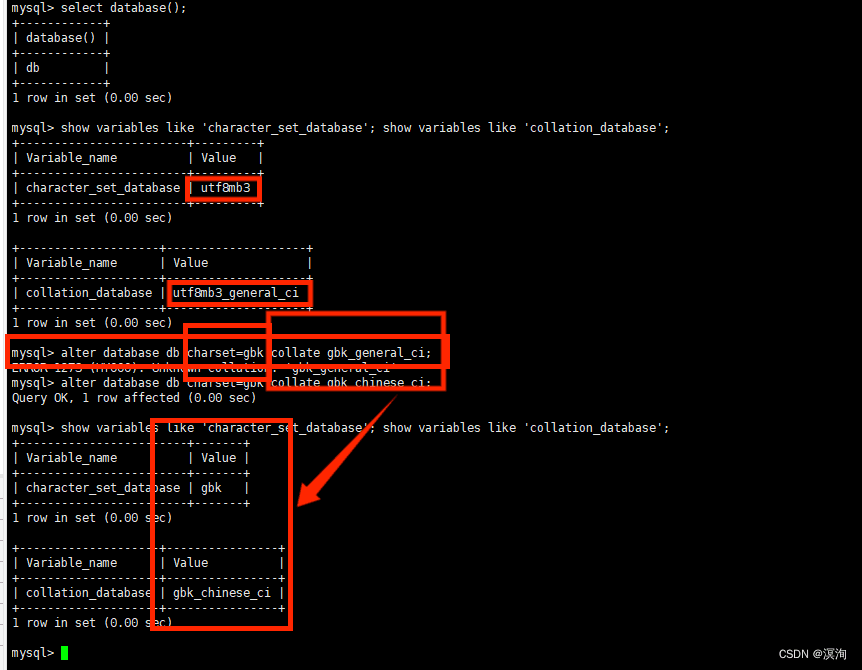
具体使用sql语句方法:
alter database db charset=gbk collate gbk_general_ci;
2.表的操作
2.1创建表
语法:
CREATE TABLE table_name (
field1 datatype,
field2 datatype,
field3 datatype
) character set 字符集 collate 校验规则 engine 存储引擎;具体使用:
1.
create table if not exists user1(id int,name varchar(20) comment '用户名',password char(32) comment '密码',birthday date comment '生日'
)character set utf8 collate utf8_general_ci engine MyIsam;2.
create table user2(id int,name varchar(20) comment '用户',password char(32) comment '密码',birthday date comment '生日'
)charset=utf8 collate=utf8_general_ci engine=InnoDB;


对比两次创表过程:最后的字符集和校验规则以及存储引擎有两种自定义的方法(自行选择顺手的使用- -)
character set utf8 collate utf8_general_ci engine MyIsam;
charset=utf8 collate=utf8_general_ci engine=InnoDB;
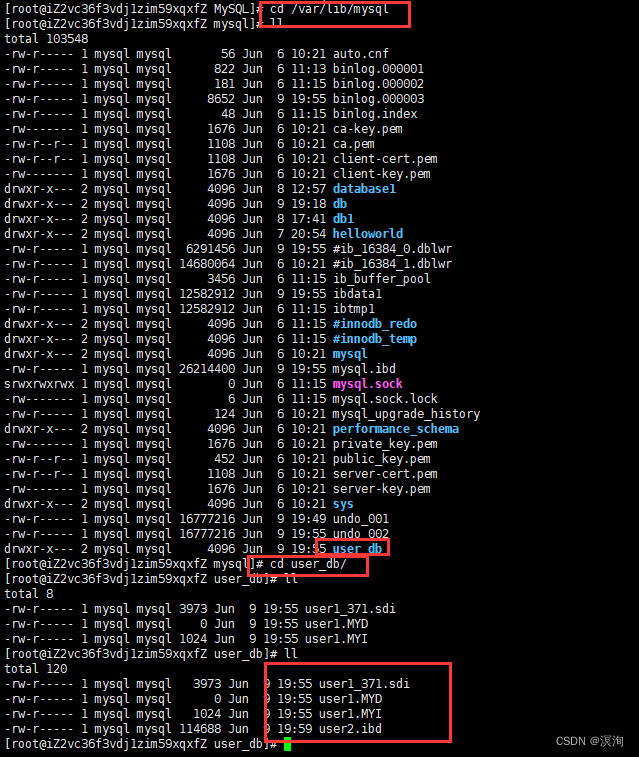
2.1.1当创建的表在库目录使用不同的存储引擎,创建表的文件也是不一样的
-
user1 表存储引擎是 MyISAM ,在数据目中有三个不同的文件,分别是:
- user1.frm:表结构
- user1.MYD:表数据
- user1.MYI:表索引
-
user2 表存储引擎是 InnoDB ,在数据目中有的文件是:
- user2.frm:表结构
- user2.ibd:表空间文件,用于存储数据和索引
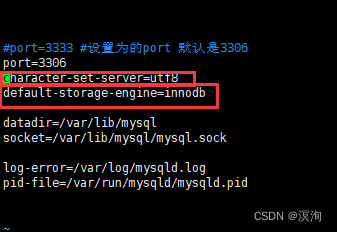
附:当不指定写字符集和校验规则以及存储引擎的话就会默认成配置文件所默认的。
配置文件所在的地址:/etc/my.cnf

1.2查看表
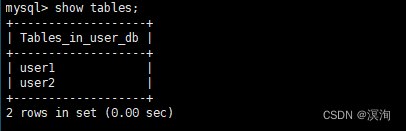
语法:
show tables;
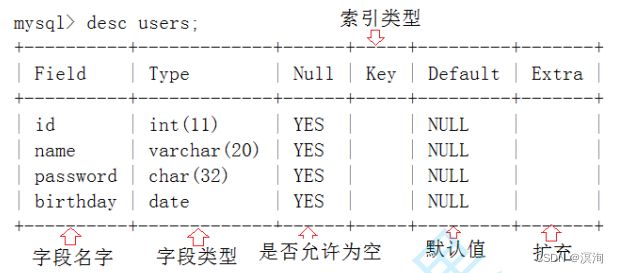
查看表结构(详细信息)
语法:
desc 表名;

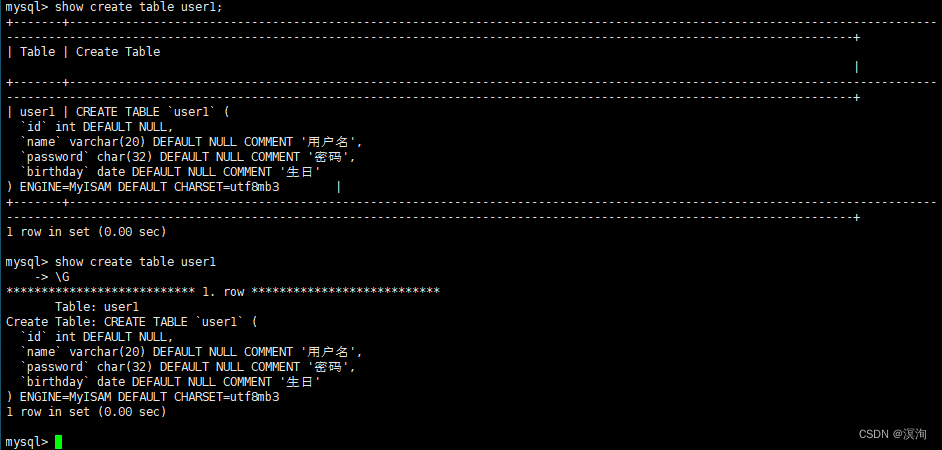
查看创建表的语句
语法:
show create table 表名;
show create table 表名 \G;#加上\G格式化展示
查看创建表的详细数据
语法:
select * form 表名;

1.3修改表
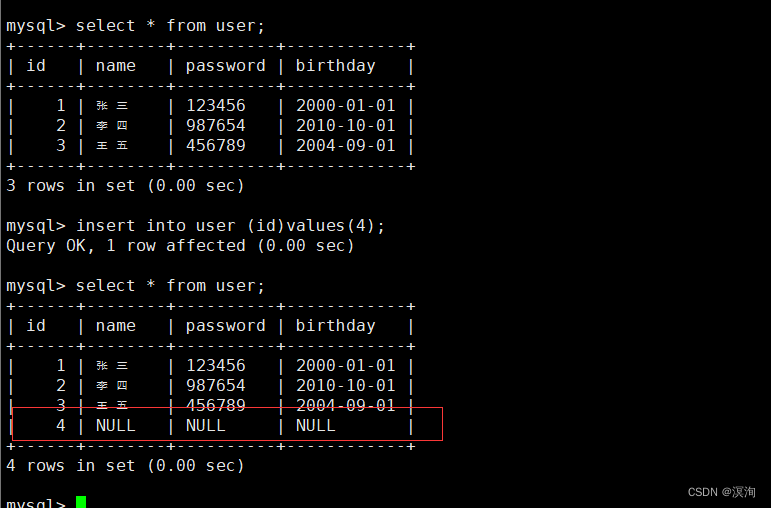
插入信息
语法:
insert into 表名 (列名)values(对应信息);

上图看出若不加列名表示在所有的行都添加信息,反之在values前面加上括号就指定了在某列中添加信息(下图在指定id处添加4)
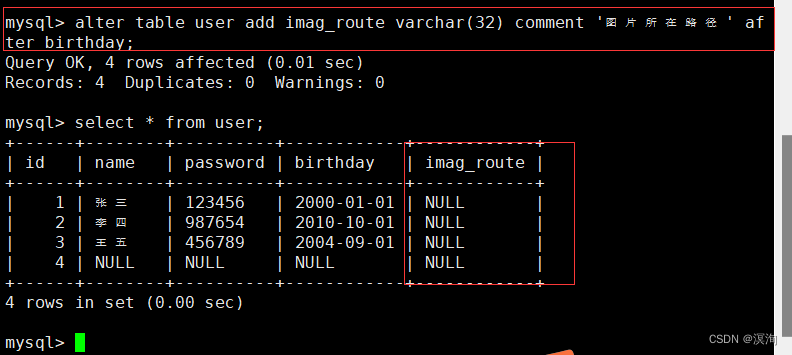
插入新的一列
语法:
alter table 表名 add 新列名 列的类型 comment '描述' after 放在那一行后面
具体使用:
修改某一列的属性
语法:
alter table tablename modify rowname 新属性;
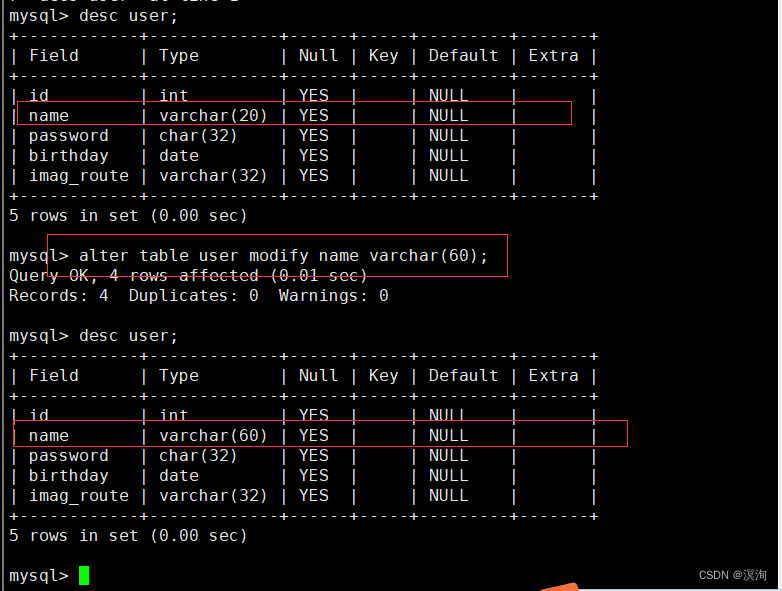
注:
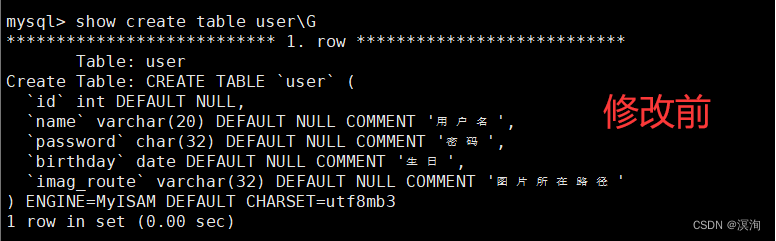
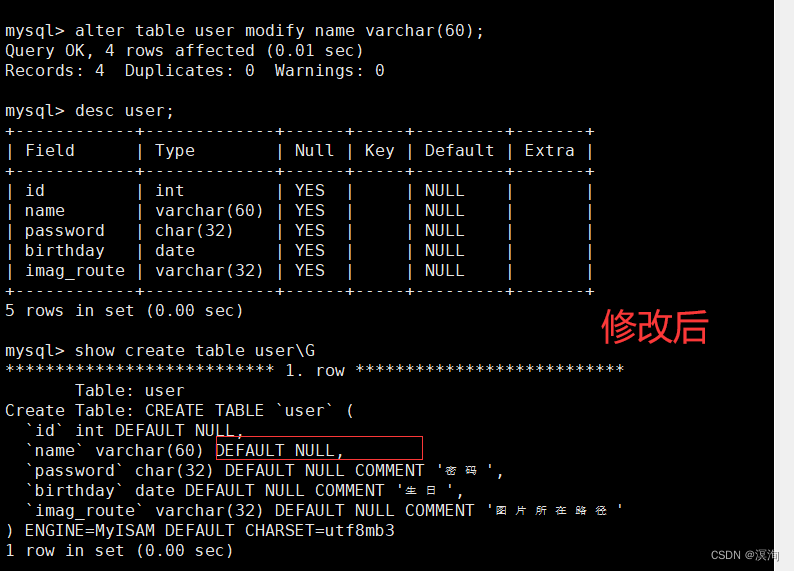
其中我们在修改时,最好写全了(包括描述),因为这是覆盖式的修改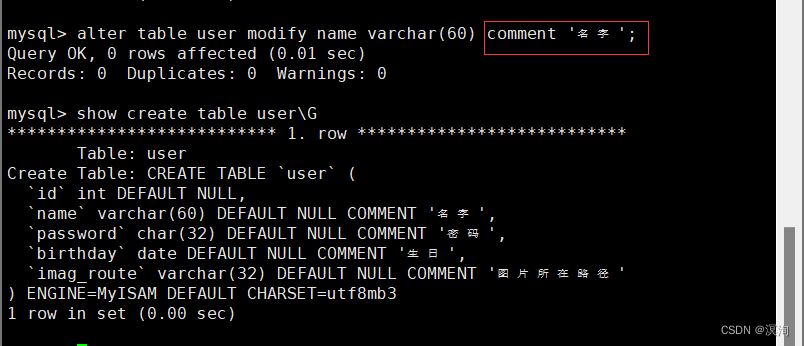
不写全的话:
修改表名
语法:
alter table 表名 rename to 新的表名;
其中 to 可以省略

修改列名
语法:
alter table 表名 change 列名 新列名;
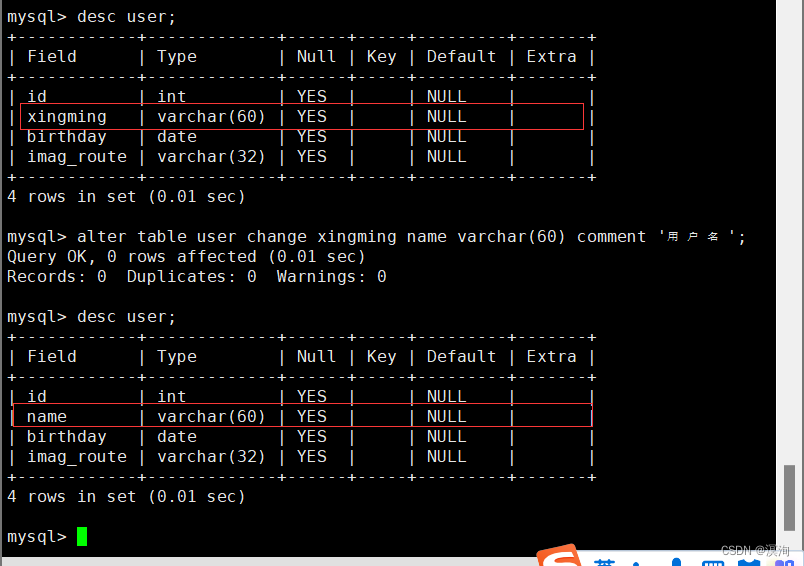
注:在重命名列名时必须要加类型,并且的同样的最好写全了!
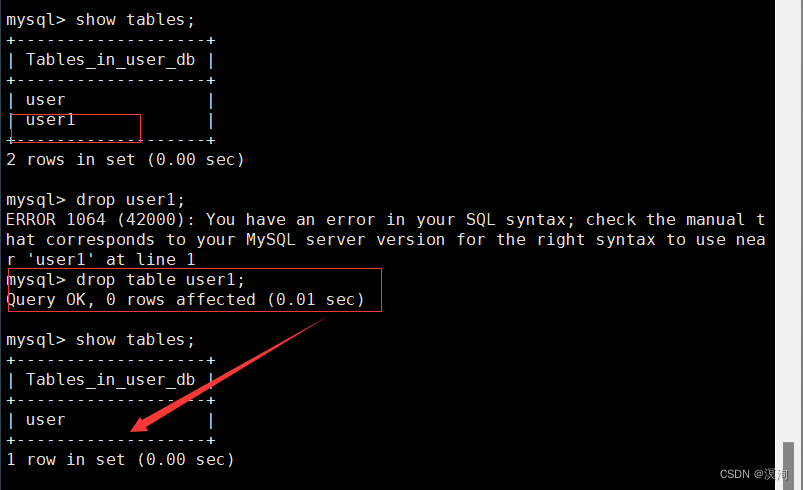
1.4删除表
语法:
DROP [TEMPORARY] TABLE [IF EXISTS] tbl_name [, tbl_name] ...
具体使用:
drop table user1;
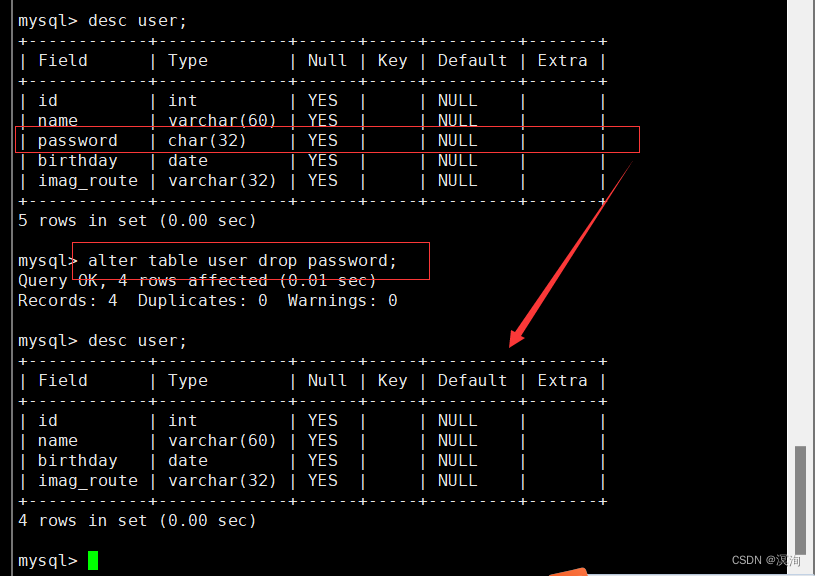
删除列
语法:
alter table 表名 drop 列名;
注:一般不要删,删除后该行的数据就再也找不到了,并且也会影响所有上层用到该数据库的地方
3.数据库中的备份和恢复
3.1备份数据:
通过在服务器上输入bash指令:
备份库:
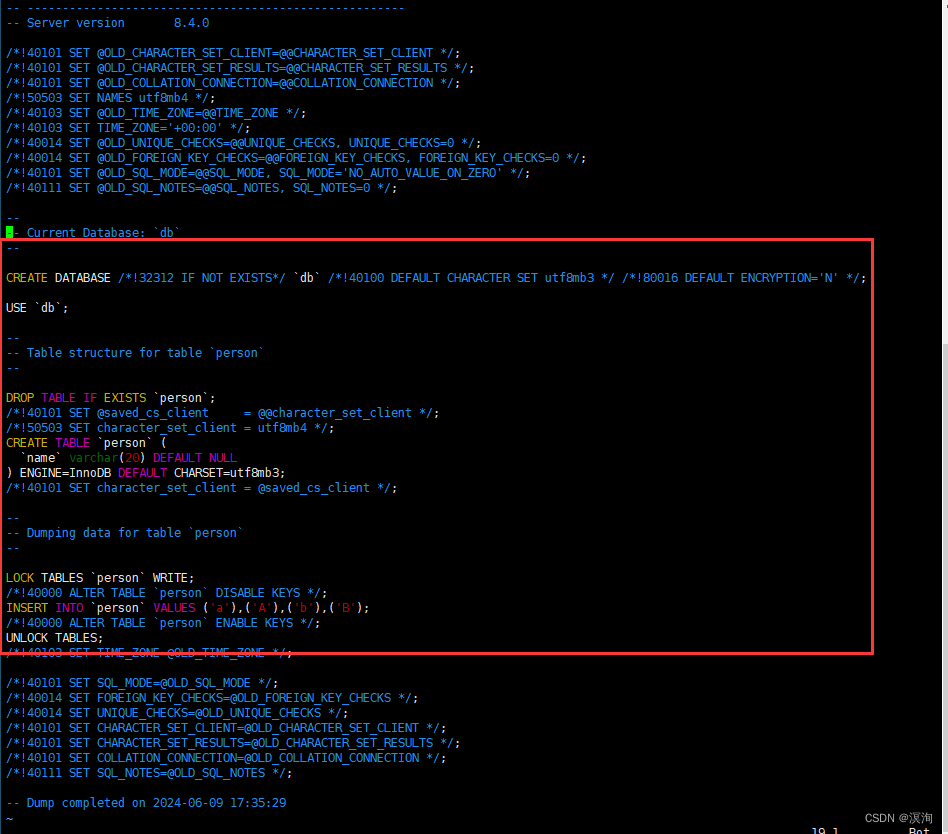
mysqldump -P3306 -uroot -p -B db > db.sql
将会生成一个db.sql备份文件
查看内部内容的语法:
vim db.sql
内部内容就是在数据库主要的sql语句:
3.2恢复数据
source 备份文件的路径;
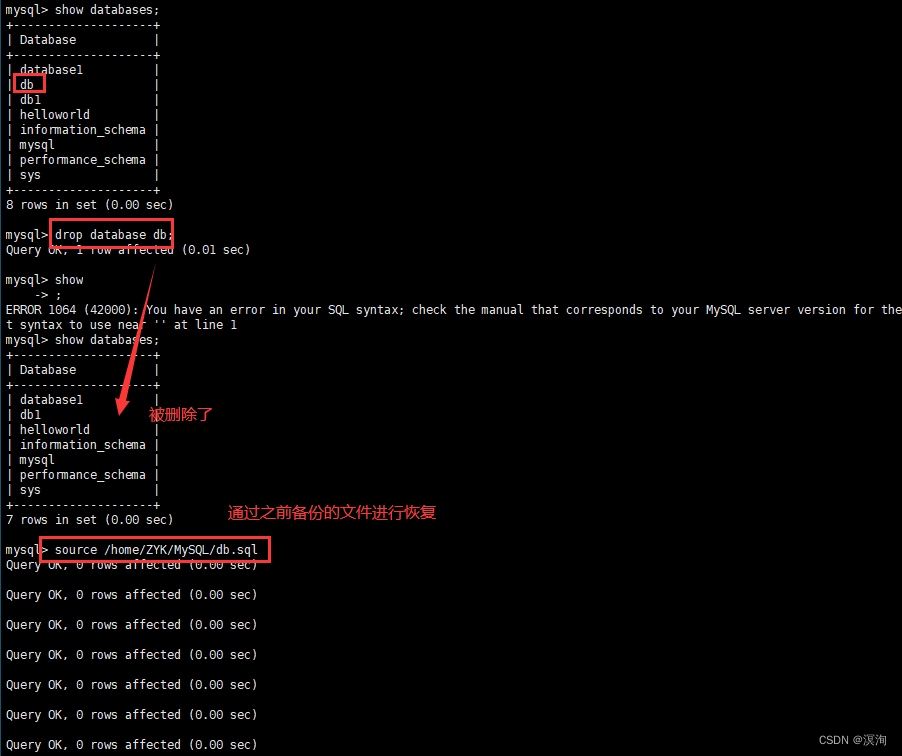
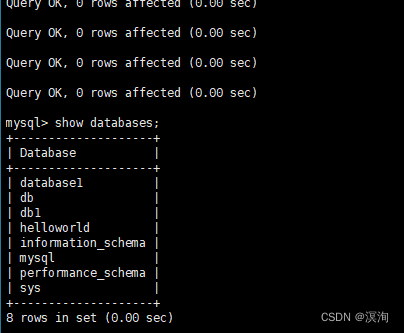
附:
- 备份某张表(恢复一样)
mysqldump -u root -p 数据库名 表名1 表名2 > D:/mytest.sql
其实也就发现和备份库不一样的是少了 -B 选项,所以也就表明了 -B 选项的含义就是在备份文件中加一个创建数据库的SQL语句
同时也侧面说明了,该还原时是需要在一个已经创建好的数据库下使用source来进行还原的!
- 同时备份多份数据库(也很简单类似于备份一个数据库)
mysql -uroot -p -B 数据库名1 数据库名2 ... > 数据库存放的路径
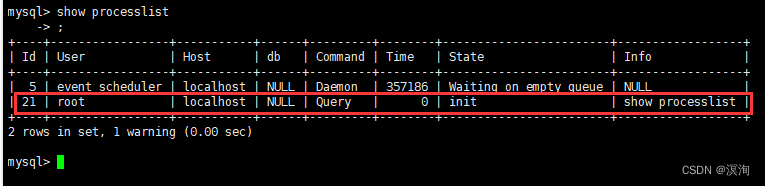
- 查看连接状态
show processlist;
本章完。预知后事如何,暂听下回分解。
如果有任何问题欢迎讨论哈!
如果觉得这篇文章对你有所帮助的话点点赞吧!
持续更新大量MySQL细致内容,早关注不迷路。
相关文章:
MySQL基础---库的操作和表的操作(配着自己的实操图,简单易上手)
绪论 勿问成功的秘诀为何,且尽全力做您应该做的事吧。–美华纳;本章是MySQL的第二章,本章主要写道MySQL中库和表的增删查改以及对库和表的备份处理,本章是基于上一章所写若没安装mysql可以查看Linux下搭建mysql软件及登录和基本…...
【6】第一个Java程序:Hello World
一、引言 Java,作为一种广泛使用的编程语言,其强大的跨平台能力和丰富的库函数使其成为开发者的首选。对于初学者来说,编写并运行第一个Java程序是一个令人兴奋的时刻。本文将指导你使用Eclipse这一流行的集成开发环境(IDE&#…...

pytorch神经网络训练(AlexNet)
导包 import osimport torchimport torch.nn as nnimport torch.optim as optimfrom torch.utils.data import Dataset, DataLoaderfrom PIL import Imagefrom torchvision import models, transforms 定义自定义图像数据集 class CustomImageDataset(Dataset): 定义一个自…...

构建大语言模型友好型网站
以大语言模型为代表的AI 技术迅速发展,将会影响原有信息网络的方式。其中一个明显的趋势是通过chatGPT 对话代替搜索引擎和浏览器来获取信息。 互联网时代,主要是通过网站(website)提供信息。网站主要为人类阅读的方式构建的。主要…...
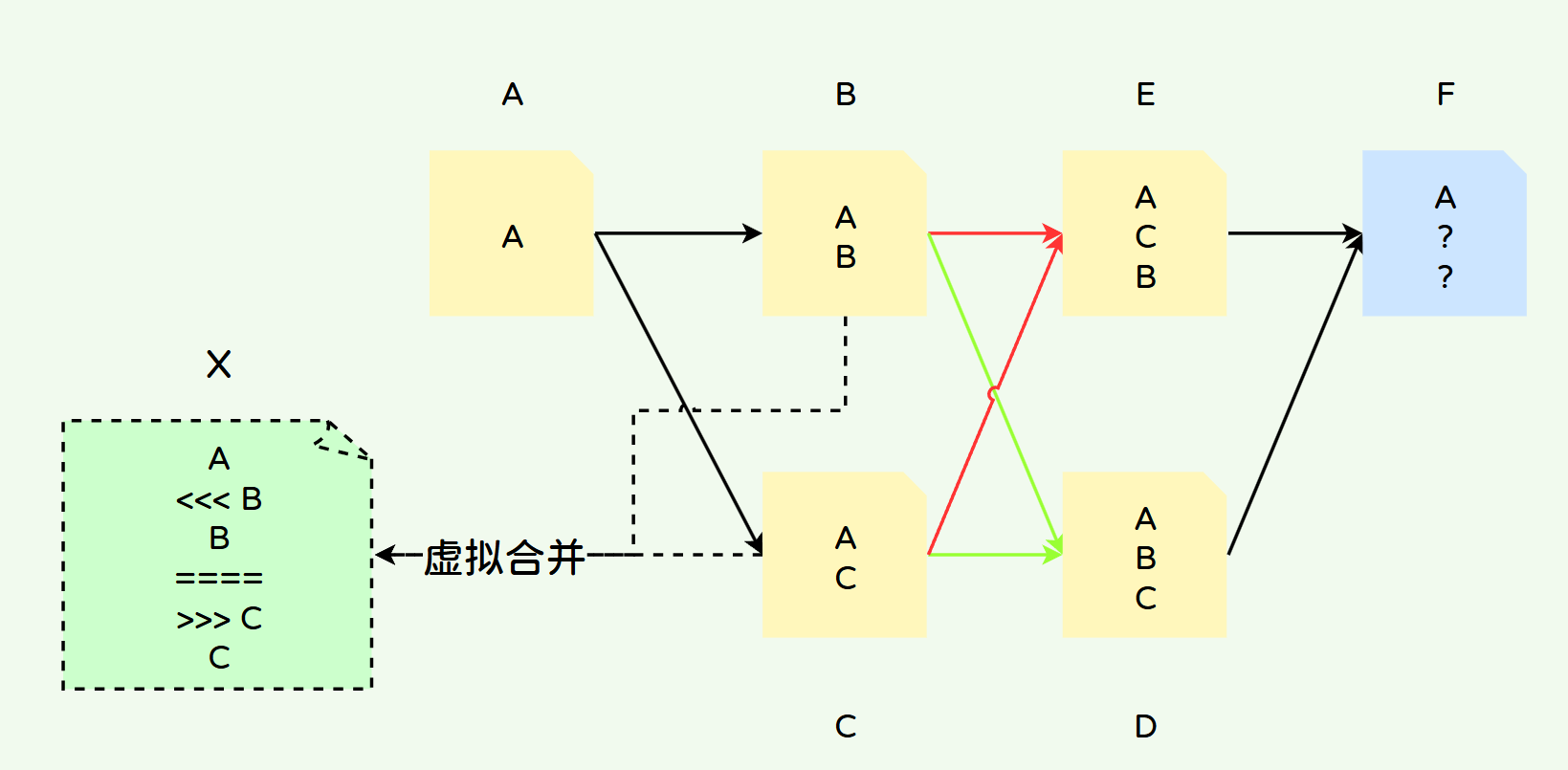
Git代码冲突原理与三路合并算法
Git代码冲突原理 Git合并文件是以行为单位进行一行一行合并的,但是有些时候并不是两行内容不一样Git就会报冲突,这是因为Git会帮助我们进行分析得出哪个结果是我们所期望的最终结果。而这个分析依据就是三路合并算法。当然,三路合并算法并不…...

聆思CSK6大模型开发板英语评测类开源SDK详解
离线英文评测算法SDK 能力简介 CSK6 大模型开发套件可以对用户通过语音输入的英文单词进行精准识别,并对单词的发音、错读、漏读、多读等方面进行评估,进行音素级的识别,根据用户的发音给出相应的建议和纠正,帮助用户更好地掌握单…...

通用大模型VS垂直大模型,你更青睐哪一方?
这里写目录标题 一、通用大模型简介二、垂直大模型简介三、通用大模型与垂直大模型的比较四、如何选择适合的模型五、通用大模型和垂直大模型的应用场景六、总结 近年来,随着人工智能技术的飞速发展,大模型的应用越来越广泛。无论是自然语言处理、计算机…...
Python第二语言(十四、高阶基础)
目录 1. 闭包 1.1 使用闭包注意事项 1.2 小结 2. 装饰器:实际上也是一种闭包; 2.1 装饰器的写法(闭包写法) :基础写法,只是解释装饰器是怎么写的; 2.2 装饰器的语法糖写法:函数…...

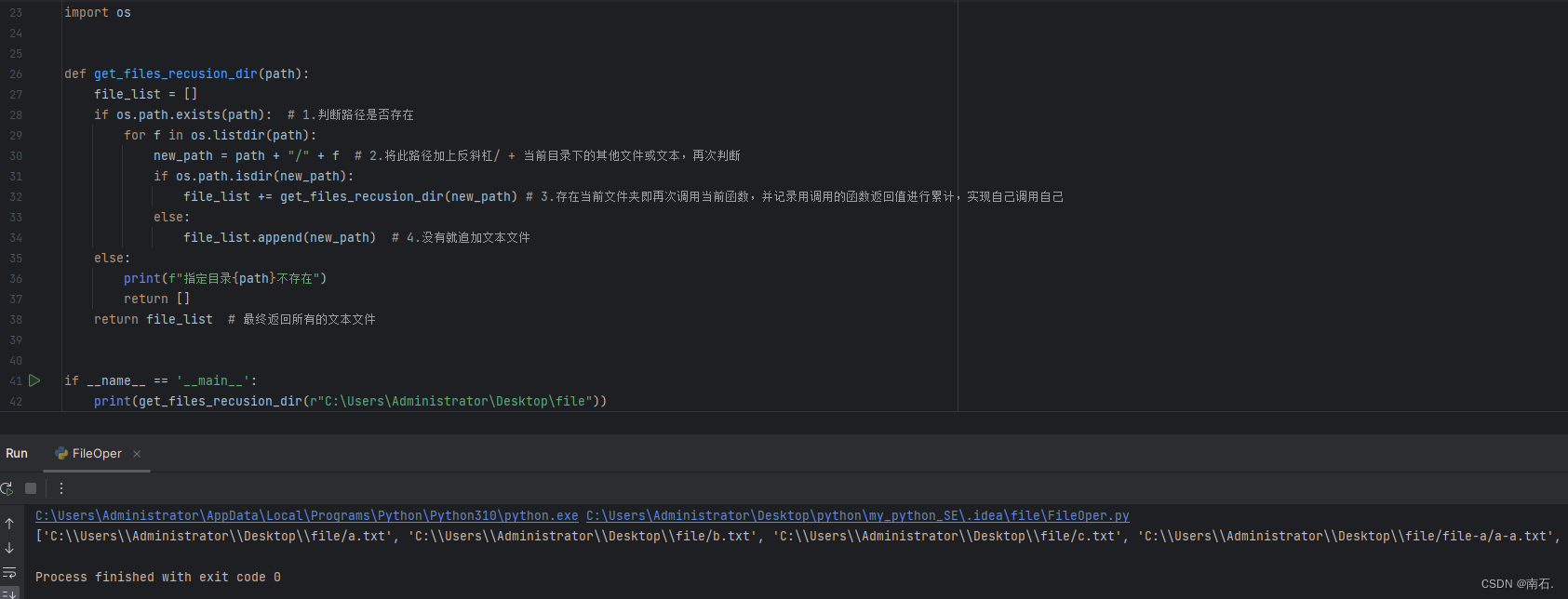
python脚本之调用其他目录脚本
import sys# 添加新路径到搜索路径中 sys.path.append(/脚本父级)# 现在可以导入该路径下的模块了 from 脚本 import 方法方法()...
定义及其使用)
C# 事件(Event)定义及其使用
1.定义个委托和类 //委托 public delegate void ProductEventHandler(Product product);/// <summary> /// 产品 /// </summary> public class Product {public int Id { get; set; }public string Code { get; set; }public string Name { get; set; }private de…...

2.负载压力测试
负载压力测试是一种重要的系统测试方法,旨在评估系统在正常和峰值负载情况下的性能表现。 一、基本概念: 负载压力测试是在一定约束条件下,通过模拟实际用户访问系统的行为,来测试系统所能承受的并发用户数、运行时间、数据量等&…...
【AI工具】jupyter notebook和jupyterlab对比和安装
简单说,jupyterlab是jupyter notebook的下一代。 选择安装一个即可。 一、这里是AI对比介绍 Jupyter Notebook和JupyterLab都是基于Jupyter内核的交互式计算环境,但它们在设计和功能上有一些关键的区别: 用户界面: Jupyter Not…...

Linux 基本指令3
date指令 date[选项][格式] %Y--年 %m--月 %d--日 %H--小时 %M--分 %S--秒 中间可用其他符号分割,不能使用空格。 -s 设置时间,会返回设置时间的信息并不是改变当前时间 设置全部时间年可用-或者:分割日期和时间用空格分隔ÿ…...
、PEM格式的公钥和PEM格式的私钥。)
在Linux系统中,可以使用OpenSSL来生成CSR(Certificate Signing Request)、PEM格式的公钥和PEM格式的私钥。
在Linux系统中,可以使用OpenSSL来生成CSR(Certificate Signing Request)、PEM格式的公钥和PEM格式的私钥。以下是生成这些文件的命令: 首先,生成私钥(通常是以.key结尾,但可以转换成PEM格式&am…...
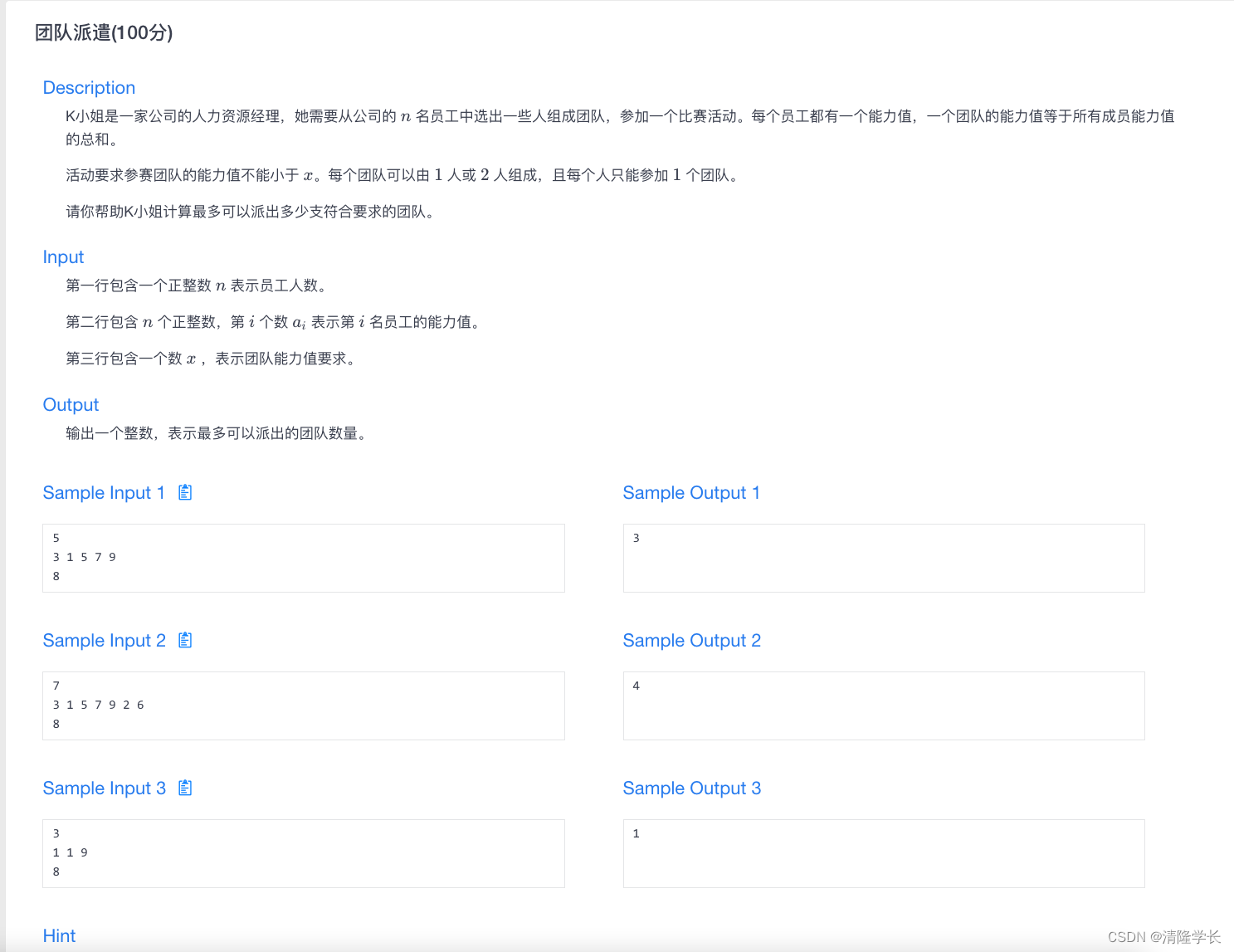
【2024最新华为OD-C/D卷试题汇总】[支持在线评测] 团队派遣(100分) - 三语言AC题解(Python/Java/Cpp)
🍭 大家好这里是清隆学长 ,一枚热爱算法的程序员 ✨ 本系列打算持续跟新华为OD-C/D卷的三语言AC题解 💻 ACM银牌🥈| 多次AK大厂笔试 | 编程一对一辅导 👏 感谢大家的订阅➕ 和 喜欢💗 🍓OJ题目截图 📎在线评测链接 团队派遣(100分) 🌍 评测功能需要订阅专栏…...

Python数据分析与机器学习在医疗诊断中的应用
文章目录 📑引言一、数据收集与预处理1.1 数据收集1.2 数据预处理 二、特征选择与构建2.1 特征选择2.2 特征构建 三、模型选择与训练3.1 逻辑回归3.2 随机森林3.3 深度学习 四、模型评估与调优4.1 交叉验证4.2 超参数调优 五、模型部署与应用5.1 模型保存与加载5.2 …...

vite.config.js如何使用env的环境变量
了解下环境变量在vite中 官方文档走起 https://cn.vitejs.dev/guide/env-and-mode.html#env-variables-and-modes 你见到的.env,.env.production等就是放置环境变量的 官方文档说到.env.[mode] # 只在指定模式下加载,比如.env.development只在开发环境加载 至于为什么是deve…...

MySql几十万条数据,同时新增或者修改
项目场景: 十万条甚至更多的数据新增或者修改 问题描述 现在有十万条数据甚至更多数据,在这些数据中,有部分数据存在数据库中,有部分数据确是新数据,存在的数据需要更新,不存在的数据需要新增 原因分析&a…...

如何提高MySQL DELETE 速度
提高MySQL中DELETE操作的速度通常涉及多个方面,包括优化查询、索引、表结构、硬件和配置等。以下是一些建议,以及一些示例代码,用于帮助我们提高DELETE操作的速度。 1.提高MySQL DELETE 速度的方法 1.1 优化查询 只删除必要的行:…...
本地Zabbix开源监控系统安装内网穿透实现远程访问详细教程
文章目录 前言1. Linux 局域网访问Zabbix2. Linux 安装cpolar3. 配置Zabbix公网访问地址4. 公网远程访问Zabbix5. 固定Zabbix公网地址 💡推荐 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。【…...
+ NVIDIA Container Toolkit)
Phi-4-mini-reasoning部署教程:容器化打包(Dockerfile)+ NVIDIA Container Toolkit
Phi-4-mini-reasoning部署教程:容器化打包(Dockerfile) NVIDIA Container Toolkit 1. 项目概述 Phi-4-mini-reasoning是微软推出的3.8B参数轻量级开源模型,专为数学推理、逻辑推导、多步解题等强逻辑任务设计。这款模型主打&quo…...

Wan2.2-I2V-A14B企业级部署案例:单卡24GB显存实现高并发视频API服务
Wan2.2-I2V-A14B企业级部署案例:单卡24GB显存实现高并发视频API服务 1. 企业级视频生成解决方案概述 在数字内容创作领域,视频生成技术正经历革命性变革。Wan2.2-I2V-A14B作为新一代文生视频模型,通过私有化部署方案,为企业提供…...

突破平台限制:WorkshopDL重构Steam创意工坊资源获取体验
突破平台限制:WorkshopDL重构Steam创意工坊资源获取体验 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL WorkshopDL作为一款仅10MB大小的开源工具,通过智…...

Enhancing LLM Reasoning with Knowledge Graphs: A Faithful and Interpretable Approach
1. 为什么需要知识图谱增强LLM推理 最近两年,大型语言模型(LLM)的表现确实让人惊艳。我测试过GPT-4在代码生成、文案创作等场景的表现,效果确实超出预期。但当我尝试用LLM做知识密集型任务时,比如回答"贾斯汀比伯…...

避开深沟槽工艺的“坑”:从DLTS数据到TCAD仿真的硅光电二极管陷阱态优化实战
硅光电二极管陷阱态优化的工程实践:从DLTS表征到TCAD仿真 在半导体制造领域,深沟槽隔离(DTI)工艺虽然能有效解决器件间的串扰问题,但其引入的界面陷阱态却成为光电二极管性能提升的"隐形杀手"。工艺工程师们…...

告别“差不多就行”:用Cascade R-CNN解决目标检测中那些“似对非对”的边界框
从边界框“模糊地带”到工业级精度:Cascade R-CNN实战全解析 当你在自动驾驶系统中看到车辆识别框与真实车身存在5个像素的偏移,或在工业质检场景中某个关键缺陷的检测框刚好漏掉了1毫米的裂纹区域,这些“看似正确实则不准”的预测结果&#…...

实战指南:基于快马平台与Touchgal,从零开发移动端手写绘图应用
今天想和大家分享一个实战项目:基于Touchgal开发移动端手写绘图应用。这个项目特别适合需要复杂手势交互的场景,比如绘图软件、地图导航等。下面我会详细介绍整个开发流程和关键实现点。 项目初始化与环境搭建 首先需要创建一个基础的HTML5项目结构。画…...

Qt QTabWidget标签页文字方向调校实战:当标签在左侧时,如何让文字乖乖水平显示?
Qt QTabWidget标签页文字方向调校实战:当标签在左侧时,如何让文字乖乖水平显示? 在桌面应用开发中,Qt框架的QTabWidget组件因其灵活性和易用性广受开发者青睐。但当我们尝试将标签页位置调整为左侧时,一个令人头疼的问…...

边缘智能部署:AI模型在边缘节点的轻量化改造
边缘智能部署:AI模型在边缘节点的轻量化改造📚 本章学习目标:深入理解AI模型在边缘节点的轻量化改造的核心概念与实践方法,掌握关键技术要点,了解实际应用场景与最佳实践。本文属于《云原生、云边端一体化与算力基建&a…...

MDXEditor指令系统详解:如何扩展Markdown语法
MDXEditor指令系统详解:如何扩展Markdown语法 【免费下载链接】editor A rich text editor React component for markdown 项目地址: https://gitcode.com/gh_mirrors/editor/editor MDXEditor是一个功能丰富的React组件,专为Markdown编辑设计&am…...