Python爬虫技术及其原理探秘
导言
随着互联网的发展,大量的数据被存储在网络上,而我们需要从中获取有用的信息。Python作为一种功能强大且易于学习的编程语言,被广泛用于网络爬虫的开发。本文将详细介绍Python爬虫所需的技术及其原理,并提供相关的代码案例。
1. HTTP请求与响应
在爬取网页数据之前,我们需要了解HTTP协议,它是在Web上进行数据交互的基础协议。HTTP请求与响应是爬虫工作的基础,我们需要了解它们的结构和交互方式。
1.1 HTTP请求
HTTP请求由请求行、请求头和请求体组成。其中,请求行包括请求方法、请求的URL和协议版本;请求头包含了用于描述请求的各种信息;请求体是可选项,用于传输请求的数据。下面是一个HTTP请求的示例:
GET /path/to/resource HTTP/1.1 Host: www.example.com User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8 ...
在Python中,我们可以使用requests库发送HTTP请求。下面是一个使用requests库发送GET请求的示例代码:
import requestsurl = 'http://www.example.com' response = requests.get(url) print(response.text)
1.2 HTTP响应
HTTP响应由响应行、响应头和响应体组成。响应行包含了响应的状态码和状态消息;响应头包含了用于描述响应的各种信息;响应体是实际返回的数据。下面是一个HTTP响应的示例:
HTTP/1.1 200 OK Content-Type: text/html; charset=utf-8 Content-Length: 1234 ... <html> ... </html>
在Python中,我们可以使用requests库获取HTTP响应。下面是一个获取HTTP响应的示例代码:
import requestsurl = 'http://www.example.com' response = requests.get(url) print(response.status_code) print(response.headers) print(response.text)
2. 网页解析技术
爬虫需要从网页中提取有用的数据,而网页通常采用HTML或XML格式存储。为了解析网页,我们可以使用以下几种技术。
2.1 正则表达式
正则表达式是一种强大的文本匹配技术,我们可以使用它来提取网页中的数据。例如,我们可以使用正则表达式提取HTML中的所有链接。
下面是一个使用正则表达式提取HTML中的链接的示例代码:
import rehtml = '< a href=" ">Example</ a>'
links = re.findall('< a href="([^"]*)">([^<]*)</ a>', html)
for link in links:print(link[0], link[1])
2.2 XPath
XPath是一种用于在XML文档中定位节点的语言,它可以与HTML文档一样使用。我们可以使用XPath提取网页中的数据。例如,我们可以使用XPath提取HTML中的所有链接。
下面是一个使用XPath提取HTML中的链接的示例代码(需要使用lxml库):
from lxml import etreehtml = '< a href="http://www.example.com">Example</ a>'
tree = etree.HTML(html)
links = tree.xpath('//a')
for link in links:print(link.get('href'), link.text)
2.3 BeautifulSoup
BeautifulSoup是一个HTML和XML解析库,提供了简单灵活的API。我们可以使用BeautifulSoup解析网页并提取数据。
下面是一个使用BeautifulSoup解析HTML并提取链接的示例代码(需要使用beautifulsoup4库):
from bs4 import BeautifulSouphtml = '< a href="http://www.example.com">Example</ a>'
soup = BeautifulSoup(html, 'html.parser')
links = soup.find_all('a')
for link in links:print(link.get('href'), link.text)
2.4 提取数据
有了解析后的HTML内容,我们可以根据具体的需求,使用CSS选择器或XPath表达式来定位和提取所需的数据。
下面示范了使用BeautifulSoup提取网页中所有超链接的代码:
links = soup.select('a')
for link in links:href = link['href']text = link.get_text()print(href, text)
在这个示例中,我们使用soup.select()方法配合CSS选择器字符串'a',选取网页中所有的<a>标签。然后使用link['href']和link.get_text()分别提取超链接的URL和文字内容。
2.5 数据存储与再处理
爬虫获取到数据后,通常需要将其保存起来供后续处理和分析。常见的存储方式有保存为文件(如CSV、JSON格式),或者存储到数据库中。
以下是一个使用csv库将提取的数据保存为CSV文件的示例代码:
import csvdata = [['url', 'text'], [href, text]]
with open('output.csv', 'w', newline='') as file:writer = csv.writer(file)writer.writerows(data)
在这个示例中,我们首先准备好要保存的数据data,其中包含了提取到的URL和文字内容。然后使用csv.writer()和writerows()方法将数据写入到CSV文件中。
3. 爬虫框架
在实际的爬虫开发中,我们通常会使用一些爬虫框架,它们提供了更高级别的抽象和更方便的功能。以下是一些常用的Python爬虫框架。
3.1 Scrapy
Scrapy是一个快速、可扩展且高级别的Web爬取框架。它提供了强大的抓取功能和数据处理能力,使爬虫开发更加高效。下面是一个使用Scrapy爬取网页的示例代码:
import scrapyclass MySpider(scrapy.Spider):name = 'example.com'start_urls = ['http://www.example.com']def parse(self, response):# 处理响应# 提取数据# 发送更多请求pass
3.2 BeautifulSoup + requests
BeautifulSoup和requests的组合是另一种常用的爬虫开发方式。使用BeautifulSoup解析网页,使用requests发送HTTP请求。
下面是一个使用BeautifulSoup和requests爬取网页的示例代码:
import requests from bs4 import BeautifulSoupurl = 'http://www.example.com' response = requests.get(url) soup = BeautifulSoup(response.text, 'html.parser') # 处理页面,提取数据
3.3 Selenium
Selenium是一种自动化浏览器工具,可以模拟浏览器行为。它通常与浏览器驱动一起使用,如ChromeDriver。使用Selenium可以解决一些JavaScript渲染的网页爬取问题。
下面是一个使用Selenium模拟浏览器爬取网页的示例代码(需要使用selenium库):
from selenium import webdriverdriver = webdriver.Chrome('path/to/chromedriver')
driver.get('http://www.example.com')
# 处理页面,提取数据
driver.quit()
4. 其他
除了了解基本的爬虫工作原理,还需要掌握一些相关的技术,以便更好地应对各种复杂情况。下面是几个常用的技术要点:
4.1 User-Agent伪装
为了防止网站屏蔽爬虫,我们可以在发送HTTP请求时设置User-Agent头部,将其伪装成浏览器的请求。这样可以减少被服务器识别为爬虫的概率。
Python requests库可以通过设置headers参数来添加自定义的HTTP头部。
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
response = requests.get(url, headers=headers)
4.2 反爬虫策略与解决方法
为了防止被爬虫抓取数据,网站可能会采取一些反爬虫策略,如限制请求频率、设置验证码、使用动态加载等。对于这些情况,我们可以采取以下解决方法:
-
限制请求频率:可以通过设置合适的时间间隔来控制请求的频率,避免过快访问网站。
-
验证码识别:可以使用第三方的验证码识别库(如Tesseract-OCR)来自动识别并输入验证码。
-
动态加载页面:对于使用JavaScript动态加载的页面,可以使用Selenium库模拟浏览器行为进行处理。
4.3 网页登录与Session管理
有些网站需要登录后才能获取到所需的数据。在这种情况下,我们可以通过模拟登录行为,发送POST请求并记录登录后的Session信息,以便后续的数据访问。
下面是一个使用requests库模拟登录的示例代码:
import requestslogin_url = 'https://example.com/login'
data = {'username': 'your_username','password': 'your_password'
}
response = requests.post(login_url, data=data)
session = response.cookiesdata_url = 'https://example.com/data'
response = requests.get(data_url, cookies=session)
data = response.text
在这个示例中,我们首先发送POST请求模拟登录,将用户名和密码作为表单数据data发送给登录页面login_url,并保存返回的Session信息。
然后我们可以使用requests.get()方法发送GET请求,同时将保存的Session信息作为cookies参数传入,以便获取登录后的数据。
5. 实例:爬取简书网站文章信息
为了更好地演示Python爬虫的技术和原理,我们选取了简书网站作为示例。我们将爬取简书网站中的热门文章列表,提取出每篇文章的标题、作者和链接。
以下是完整的实现代码:
import requests
from bs4 import BeautifulSoup# 发送HTTP请求
url = 'https://www.jianshu.com'
response = requests.get(url)
html = response.text# 解析HTML内容
soup = BeautifulSoup(html, 'html.parser')# 提取数据
articles = soup.select('.note-list li')data = []
for article in articles:title = article.select('a.title')[0].string.strip()author = article.select('.name')[0].string.strip()href = 'https://www.jianshu.com' + article.select('a.title')[0]['href']data.append([title, author, href])# 数据存储
import csv
with open('jianshu_articles.csv', 'w', newline='', encoding="utf-8") as file:writer = csv.writer(file)writer.writerows(data)
在这个示例中,我们首先发送GET请求获取简书网站的HTML内容,然后使用BeautifulSoup库进行解析。
接着,我们使用CSS选择器字符串.note-list li选取所有文章的外层容器,并使用CSS选择器和字典键值对的方式提取文章的标题、作者和链接。
最后,我们采用CSV格式将提取的数据保存到了名为jianshu_articles.csv的文件中。
结语
本文详细介绍了Python爬虫所需的技术及其原理,包括HTTP请求与响应、网页解析技术和爬虫框架。通过掌握这些技术,我们可以有效地开发出强大且高效的Python爬虫。希望本文能对你理解和掌握Python爬虫有所帮助。
请注意,在进行网络爬虫时,需要遵守网站的使用条款,并遵守相关法律法规。同时,合理使用爬虫技术,不对网络资源进行滥用和破坏。
相关文章:

Python爬虫技术及其原理探秘
导言 随着互联网的发展,大量的数据被存储在网络上,而我们需要从中获取有用的信息。Python作为一种功能强大且易于学习的编程语言,被广泛用于网络爬虫的开发。本文将详细介绍Python爬虫所需的技术及其原理,并提供相关的代码案例。…...

堆和栈的区别及应用场景
堆和栈的区别及应用场景 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 在计算机科学和编程领域,堆(Heap)和栈(…...

vant的dialog触发了其他overlay
原代码: <!-- dialog --><van-dialog v-model"showTipsDialog" title"温馨提示"><p>dialog内容</p></van-dialog><!-- overlay --><van-overlay style"display: flex" :show"showLoadingOverlay&q…...
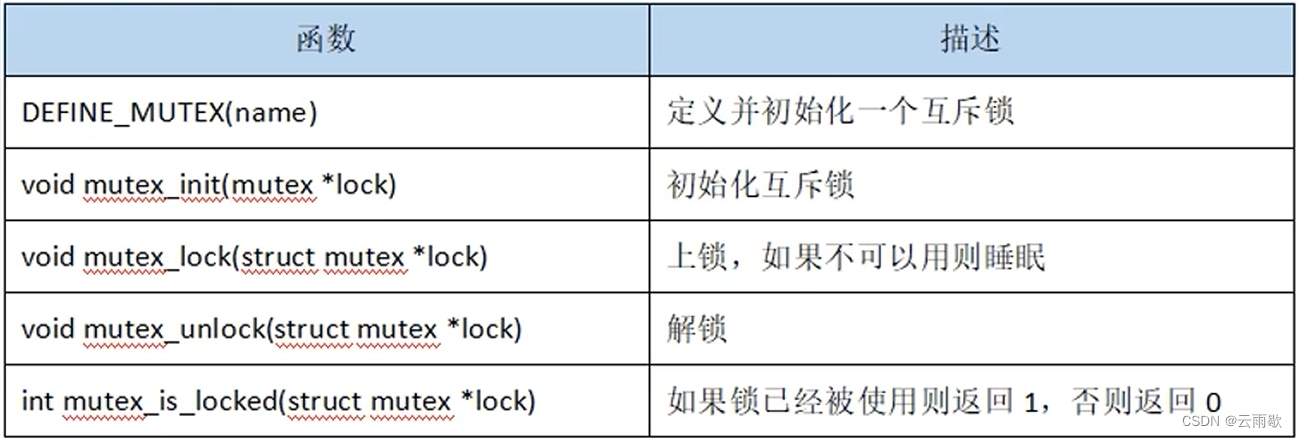
Linux驱动开发笔记(十二)并发与竞争
文章目录 前言一、并发与竞争的引入1.1 并发1.2 竞争1.3 解决方法 二、原子操作2.1 概念2.2 使用方法 三、自旋锁3.1 概念3.2 使用方法3.3 自旋锁死锁 四、信号量4.1 概念4.2 使用方法 五、互斥锁5.1 概念5.2 使用方法 前言 Linux的子系统我们已经大致学习完了,笔者…...

【Mac】Listen 1 for Mac(最强的音乐搜索工具)软件介绍
软件介绍 Listen 1 for Mac 是一款非常方便的音乐播放软件,主要功能是集成多个音乐平台,让用户可以方便地搜索、播放和管理音乐。它是一个用 Python 语言开发的免费开源综合音乐搜索工具项目,最大的亮点在于可以搜索和播放来自网易云音乐&am…...

nginx 1024 worker_connections are not enough while connecting to upstream
现象 请求api响应慢,甚至出现504 gateway timeout,重启后端服务不能恢复,但重启nginx可以恢复。 解决方案 worker_connections使用了默认值 1024,当流量增长时,导致连接不够 在nginx.conf中修改连接数就可以了&…...

在Ubuntu 16.04上安装和配置Elasticsearch的方法
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 简介 Elasticsearch 是一个用于实时分布式搜索和数据分析的平台。它因易用性、强大功能和可扩展性而备受欢迎。 Elasticsearch 支持 R…...

C#给SqlSugar封装一个单例类
.NET兼职社区 可以直接用,轻量方便,无需重复造轮子。 这里只对CRUD进行封装,我的应用比较简单。 using SqlSugar; using System.Collections.Generic;namespace MusicApp.Assist {internal class SqlSugarAssist{private static readonly ob…...
)
Postman接口测试工具的原理及应用详解(六)
本系列文章简介: 在当今软件开发的世界中,接口测试作为保证软件质量的重要一环,其重要性不言而喻。随着前后端分离开发模式的普及,接口测试已成为连接前后端开发的桥梁,确保前后端之间的数据交互准确无误。在这样的背景…...

【算法 之插入排序 原理及案例】
插入排序原理: 插入排序(Insertion Sort)是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。插入排序在实现上,通常…...
第一节:如何开发第一个spring boot3.x项目(自学Spring boot 3.x的第一天)
大家好,我是网创有方,从今天开始,我会记录每篇我自学spring boot3.x的经验。只要我不偷懒,学完应该很快,哈哈,更新速度尽可能快,想和大佬们一块讨论,如果需要讨论的欢迎一起评论区留…...

JS逆向:由 words 、sigBytes 引发的一系列思考与实践
【作者主页】:小鱼神1024 【擅长领域】:JS逆向、小程序逆向、AST还原、验证码突防、Python开发、浏览器插件开发、React前端开发、NestJS后端开发等等 在做JS逆向时,你是否经常看到 words 和 sigBytes 这两个属性呢,比如ÿ…...
)
计算机的错误计算(十五)
摘要 介绍历史上由于计算精度问题引起的灾难或事件。 今天换个话题,说说历史上曾经发生过的一些事件。 1961 年 , 美国麻省理工学院气象学家洛伦兹在仿真天气预报时 , 将 0.506127 舍入到 0.506 , 所得计算结果大相径庭 ! 这种“差之毫厘 , 谬以千里”的现象…...

制作img文件
安装软件包 sudo apt-get install dosfstools dump parted kpartx 创建空白img文件 sudo dd if/dev/zero ofraspberrypi.img bs1M count4000 给img文件分区 sudo parted raspberrypi.img --script -- mklabel msdos sudo parted raspberrypi.img --script -- mkpart primar…...

GB28181视频汇聚平台EasyCVR接入Ehome设备视频播放出现异常是什么原因?
多协议接入视频汇聚平台EasyCVR视频监控系统采用了开放式的架构,系统可兼容多协议接入,包括市场标准协议:国标GB/T 28181协议、GA/T 1400协议、JT808、RTMP、RTSP/Onvif协议;以及主流厂家私有协议及SDK,如:…...

Java利用poi实现word,excel,ppt,pdf等各类型文档密码检测
介绍 最近工作上需要对word,excel,ppt,pdf等各类型文档密码检测,对文件进行分类,有密码的和没密码的做区分。查了一堆资料和GPT都不是很满意,最后东拼西凑搞了个相对全面的检测工具代码类,希望能给需要的人带来帮助。 说明 这段…...

顺序表与链表学习笔记
顺序表及其结构定义 (1)结构定义 顺序存储: 顺序表的元素按顺序存储在一块连续的内存区域中,每个元素占用相同大小的存储空间。通过数组实现,每个元素可以通过下标快速访问。 存储密度高: 因为顺序表使用…...
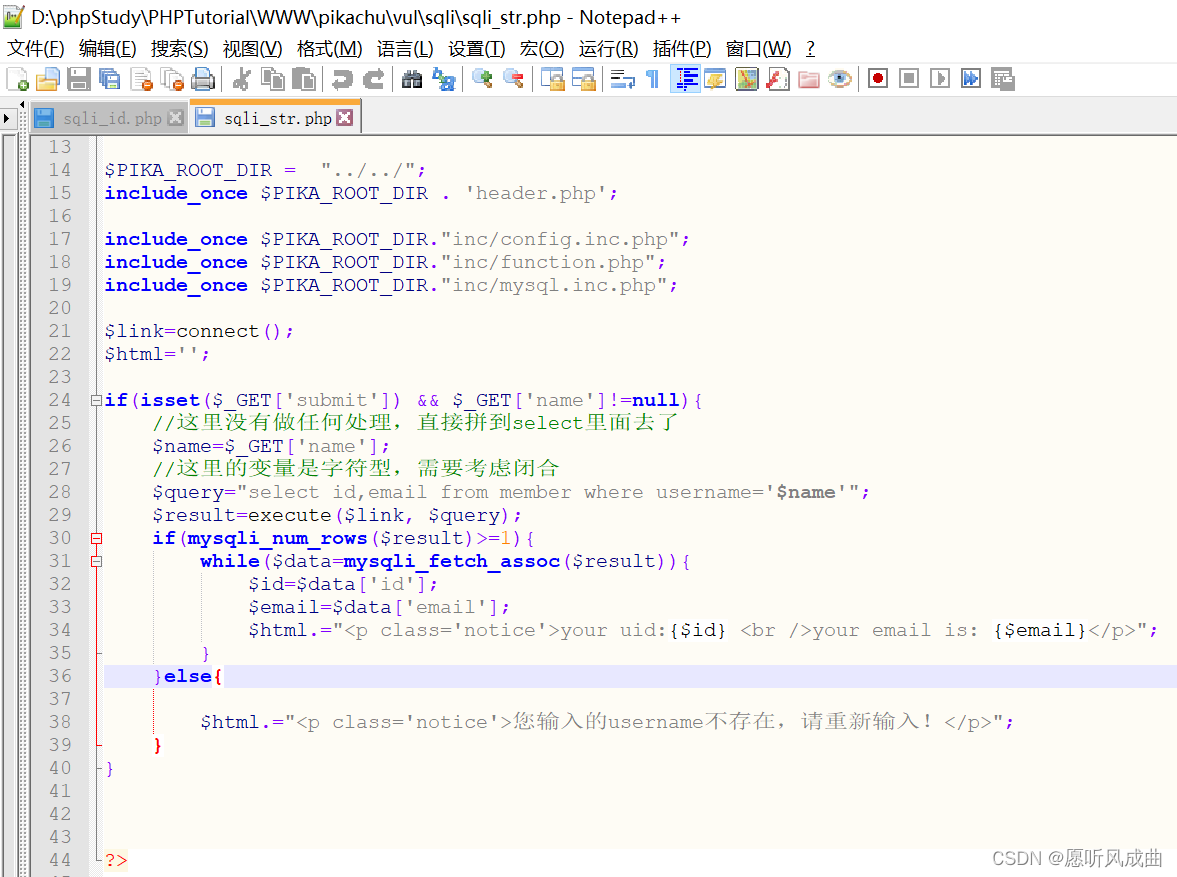
2.SQL注入-字符型
SQL注入-字符型(get) 输入kobe查询出现id和邮箱 猜测语句,字符在数据库中需要用到单引号或者双引号 select 字段1,字段2 from 表名 where usernamekobe;在数据库中查询对应的kobe,根据上图对应上。 select id,email from member where usernamekobe;编写payload语…...

在Ubuntu 14.04上安装和配置Elasticsearch的方法
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 简介 Elasticsearch 是一个用于实时分布式搜索和数据分析的平台。它因易用性、强大功能和可扩展性而备受欢迎。 Elasticsearch 支持 R…...

C++:inline关键字nullptr
inline关键字 C中inline使用关键点强调 (1)inline是一种“用于实现的关键字”,而不是一种“用于声明的关键字”,所以关键字 inline 必须与函数定义体放在一起,而不是和声明放在一起 (2)如果希望在多个c文件中使用,则inline函数应…...

别再重装系统了!Ubuntu 20.04 下 libsnark 零知识证明环境一次搭建成功的保姆级避坑指南
零知识证明开发实战:Ubuntu 20.04下libsnark环境高效搭建指南 在区块链和密码学领域,零知识证明技术正成为隐私保护的核心解决方案。作为最具代表性的开源库之一,libsnark因其高效的证明系统实现而被众多隐私项目采用。然而,许多开…...

打磨与展望:RAG 的进阶技巧与避坑指南
走过了从加载文档到完整问答链的全程,恭喜你——你已经亲手建造出了一台可以和自己文档“对话”的 RAG 引擎。但任何一个上过生产环境的开发者都知道:原型和产品之间,往往隔着一条名为“细节”的护城河。 用户开始提各种刁钻问题,…...

别再死记硬背了!Vivado伪双口RAM的wea、ena信号到底怎么用?一个实例讲透
Vivado伪双口RAM控制信号实战指南:从原理到避坑 第一次接触Vivado的伪双口RAM时,那些密密麻麻的控制信号确实让人头疼。尤其是wea和ena这两个看似简单却暗藏玄机的信号,稍不注意就会导致数据读取异常或者意外覆盖。记得去年我在一个图像处理项…...

2026年企业制品管理平台选型推荐:Gitee Repo 如何构建安全高效协作基石
在软件研发的关键环节中,制品管理正经历着从基础存储工具向安全可信协作中枢的深刻演进。面对开源风险、跨团队协作效率与版本追溯等多重挑战,企业对于一套能够深度守护制品安全并支撑高效协同的解决方案需求迫切。Gitee Repo 制品管理平台凭借其全面的能…...

基于树莓派与AstroPrint搭建无线3D打印控制中心实战指南
1. 项目概述:为什么需要无线3D打印控制?如果你和我一样,是个喜欢折腾3D打印机的创客或爱好者,那你肯定经历过这样的场景:为了打印一个模型,需要先在电脑上用切片软件生成G-code文件,然后找到读卡…...
)
DeepSeek Chat功能测试实战手册:5步完成生产级对话模型验收(附测试用例模板)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek Chat功能测试实战手册:5步完成生产级对话模型验收(附测试用例模板) DeepSeek Chat 作为开源大语言模型对话接口,其生产就绪性需通过结构化、可…...

基于红外通信的实体寻宝游戏:从MakeCode到CircuitPython的嵌入式开发实践
1. 项目概述:用红外线玩一场实体寻宝游戏如果你手头有几块Adafruit的Circuit Playground Express开发板,除了点亮LED、播放声音这些基础操作,有没有想过用它们来设计一个能跑能藏的实体互动游戏?红外寻宝游戏就是一个绝佳的选择。…...

从CineCamera到硬盘:UE中RenderTarget图像捕获与导出全流程解析
1. 从CineCamera到硬盘:RenderTarget图像捕获与导出全流程 在虚幻引擎(UE)开发中,经常需要将CineCamera相机拍摄的高质量画面保存为图片文件。无论是用于过场动画截图、后期处理还是游戏内截图功能,掌握RenderTarget的…...

深度解析AKTools金融数据接口的HTTP API优化与数据一致性终极方案
深度解析AKTools金融数据接口的HTTP API优化与数据一致性终极方案 【免费下载链接】aktools AKTools is an elegant and simple HTTP API library for AKShare, built for AKSharers! 项目地址: https://gitcode.com/gh_mirrors/ak/aktools 在量化投资和金融数据分析领域…...

JoyCon-Driver:让Switch手柄在Windows上焕发新生的终极方案
JoyCon-Driver:让Switch手柄在Windows上焕发新生的终极方案 【免费下载链接】JoyCon-Driver A vJoy feeder for the Nintendo Switch JoyCons and Pro Controller 项目地址: https://gitcode.com/gh_mirrors/jo/JoyCon-Driver 还在为闲置的任天堂Switch手柄感…...