【JVM篇2】垃圾回收机制
目录
一、GC的作用
申请变量的时机&销毁变量的时机
内存泄漏
内存溢出(oom)
垃圾回收的劣势
二、GC的工作过程
回收垃圾的过程
第一阶段:找垃圾/判定垃圾
方案1:基于引用计数(非Java语言)
引用计数方式的缺陷
方案2:可达性分析(基于Java语言)
GCRoots是哪些变量(3类)
第二阶段:回收垃圾(释放内存)
策略1:标记-清除策略
策略1存在问题分析:(内存碎片)
策略2:复制算法
复制算法存在问题分析:
策略3:标记——整理
分代回收
三、垃圾收集器有哪些
第一类:Serial收集器&Serial Old收集器(串行收集)
第二类:ParNew收集器&Parallel Old收集器&Parallel Scavenge收集器(并发收集)
第三类:CMS收集器
步骤1:找到GCRoots(会引发STW)
步骤2:并发标记
步骤3:重新标记(会引发STW)
步骤4:回收内存
第四类:G1收集器
一、GC的作用
GC:全称是Garbage Clean(垃圾回收)。我们平时写代码的时候,经常会申请内存。例如:
创建变量、new对象、加载类...
但是,由于内存空间是有限的,因此就需要"有借有还"。
如下代码,就是申请了两个变量:一个a,另外一个是object
int a=3;Object obj=new Object()申请变量的时机&销毁变量的时机
申请一个变量(申请内存的时机)是确定的。就是new或者int a=...这种。但是,这个变量什么时候不需要使用了,那这个时期就不确定了。
例如:内存释放得偏早:如果还想要使用obj对象,但是如果这一个对象被回收了,那这样就显得不合理了。
又或者:内存的释放比较偏迟,对象一直占着"坑位"。
对于内存什么时候被释放这个问题, 不同的语言有不同的处理方式。
对于C语言:程序没有提供垃圾回收机制。因此当内存需要释放的时候,必须由程序员手动进行释放(调用free函数),因此,就会引入一个臭名昭著的问题,那就是"内存泄漏"。
内存泄漏
如果申请的内存越来越多,那么就意味着可用的内存越来越少,最终无内存可用了。这种现象就叫做"内存泄漏"。
虽然垃圾回收可以让开发的程序员专注于设计业务上面的代码,无需关心内存泄露的问题,但是仍然有一定的劣势。
提到内存泄露,那么我们再谈一下一个和它容易混淆的概念——内存溢出。(但是和上面讨论的话题没有关系)
内存溢出(oom)
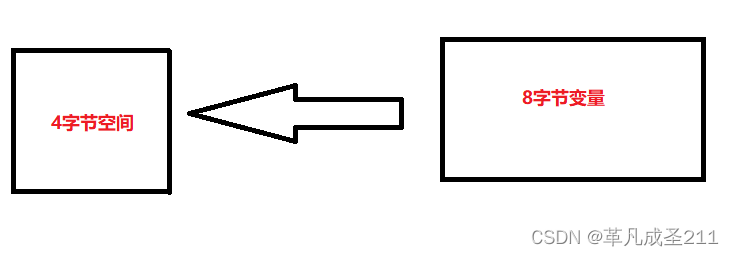
程序在申请内存的时候,没有足够的内存提供给申请者使用。这种现象就被称为"内存溢出"。
例如给一个int类型空间的大小,却存储一个long类型的数据,这样就会导致"内存溢出"。
垃圾回收的劣势
1、引入了额外的开销(消耗资源更多了)
2、可能会影响程序的流畅运行:垃圾回收经常会出现:STW(stop the work)问题。
二、GC的工作过程
回收的是什么样的对象
在上一篇文章当中,我们提到了:JVM的内存区域划分主要分为4个部分:
程序计数器、栈、堆、方法区。
对于栈区,只要方法返回之后,就会自动从栈上面消失了,不需要GC。
对于堆区,就很需要GC了,因为堆区当中存放的大量都是new出来的对象。
我们来画一张图,描述一下根据内存使用与否的图:

因此,需要回收的对象,都是一些没有使用,但是同时也占用着内存的对象。
回收垃圾的过程
垃圾回收的过程,分为两大阶段:
第一阶段:找垃圾/判定垃圾
方案1:基于引用计数(非Java语言)
针对每一个对象,都引入一小块的内存,保存这一个对象有多少个引用指向它。
例如:(此时有两个引用都指向new Test()对象)
//t1引用指向new Test()对象
Test t1=new Test();
//t2引用指向new Test()对象
Test t2=t1;那么,此时在new Test()当中,就会有一个引用计数器,显示指向这个对象的引用个数为2。
那么,当引用计数为0的时候,也就意味着此时没有引用指向这个对象了,需要GC对于这一个对象进行回收操作。
什么时候引用计数为0呢?下面举一个例子:
private static void func2() {//让t1指向new Test1()对象Test1 t1=new Test1();//让t2指向new Test1()对象Test1 t2=t1;} 在一个方法当中,两个引用(t1,t2)同时指向了new Test1()对象。 当调用func2()方法的时候,t1和t2引用会保存在func2()方法的栈帧上面。两个引用同时指向了堆上面的new Test1()对象。 
当func2()调用结束之后,会从栈帧上面消失,那么t1和t2引用也会随之消失。
那么,也就意味着:new Test2()这一个对象没有引用指向它了,认为它是一个"垃圾",也就会被回收。
引用计数方式的缺陷
缺点1:空间利用率比较低
每一个new的对象都必须要搭配一个计数器来记录几个引用。引用计数器的大小为4个字节,但是如果一个对象除了引用计数器以外的部分本身也就只有4个字节大小,那么就意味着比较浪费空间。

缺点2:会有循环引用的问题
下面,来举一个例子说明一下什么是循环引用问题:
首先:创建一个Test类,在内部有一个属性,就是Test t=null;
然后:在测试类当中,创建这一个类的实例对象:
class Test {Test t = null;
}/*** @author 25043*/
public class Test2 {public static void main(String[] args) {Test t1 = new Test();Test t2 = new Test();}
}到这一步的时候,来画一个引用——对象的指向图:
 然后,接下来:执行下面的代码:
然后,接下来:执行下面的代码:
public static void main(String[] args) {//对象1Test t1 = new Test();//对象2Test t2 = new Test();t1.t = t2;t2.t = t1;}到了这一步,再画一下引用指向的图:(把t2引用指向的对象赋给了对象1的t属性、把t1引用指向的对象赋给了对象2的t属性)
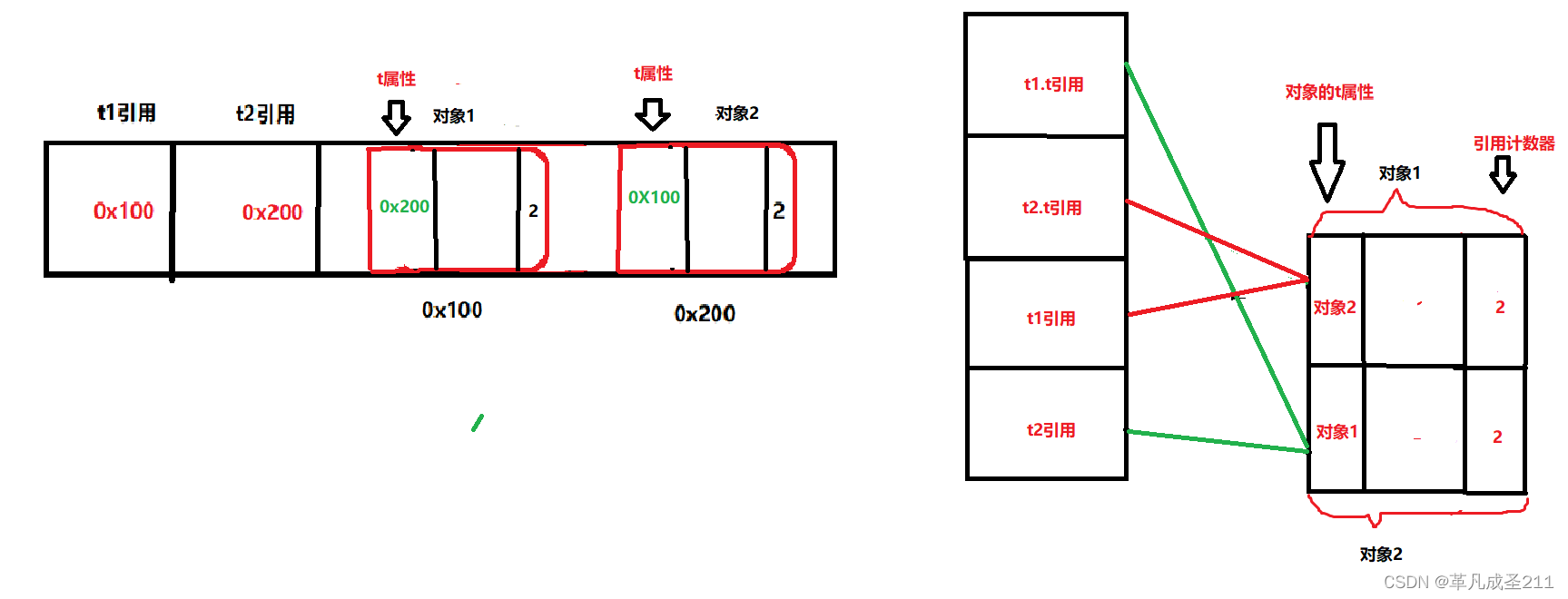
到这一步的时候:
对象1有两个引用指向(t1、t2.t);
对象2有两个引用指向(t2、t1.t)。
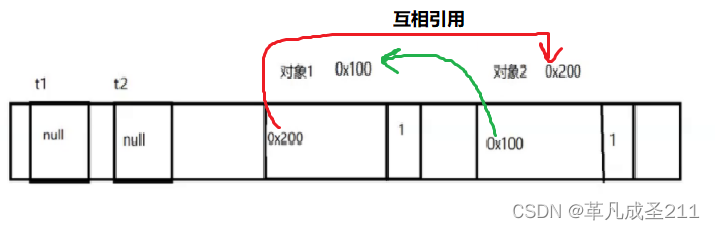
接下来:令:t1=null,t2=null。
public static void main(String[] args) {//对象1Test t1 = new Test();//对象2Test t2 = new Test();t1.t = t2;t2.t = t1;t1 = null;t2 = null;}那么此时可以认为:
t1的指向为null,并且t2的指向为null。
那么对应的指向对象1的引用减少了一个,只剩下(t2.t)
同时,指向对象2的引用也减少了一个,只剩下(t1.t)
两个对象的引用计数器各自减少为1。
由于引用计数不为0,也就是两个对象互相引用。那么,这两个对象无法被回收。但是,外部的引用又无法访问这两个对象。因此,这两个对象就永远无法被回收,也永远无法被使用。这样,也就出现了内存泄漏。
由于上述的两个缺点,因此引入了方案2(基于Java语言的解决方案:基于可达性分析)
方案2:可达性分析(基于Java语言)
通过一个额外的线程,定期地针对整个内存空间的对象进行扫描。
有一些起始的位置(称为GCroots),然后类似于深度优先搜索的方式,把可以访问到的对象都标记一遍。那么,带有标记的对象就是"可达的"。没有被标记的对象,那就是"垃圾"。这样就很好地解决了对象不可达的问题。(避免了两个对象相互引用、但是没有外部引用指向的问题) 
尽管可达性分析方法可以有效解决引用循环的问题,但是如果一个程序当中的对象特别多,那么也一定会造成比较大的性能损耗,因为整个搜索的过程也是比较消耗时间的。
GCRoots是哪些变量(3类)
第一类:栈上的局部变量;
第二类:常量池当中的引用指向的变量;
第三类:方法区当中的静态成员指向的对象。
第二阶段:回收垃圾(释放内存)
回收垃圾主要分为三种策略:
策略1:标记-清除策略;
策略2:复制算法;
策略3:标记-整理策略
下面,将分别介绍这三种策略:
策略1:标记-清除策略
标记,就是可达性分析的过程。例如在一次搜索当中,发现了以下几个部分是"垃圾"。清除,就是直接释放内存。
策略1存在问题分析:(内存碎片)
此时如果直接释放,虽然内存的确还给了操作系统了,但是内存还是离散的,也就不是连续的,这样带来的问题就是"内存碎片",影响程序的运行效率。
策略2:复制算法
为了解决内存碎片,引入的复制算法。如下图:把内存一分为二:
然后,把正常的对象(没有被标记为垃圾的对象)的拷贝到令一半。
 最后,把左侧的空前全部释放掉。此时,内存碎片问题就迎刃而解了。
最后,把左侧的空前全部释放掉。此时,内存碎片问题就迎刃而解了。

复制算法存在问题分析:
复制算法有效解决了上述的内存碎片问题,但是,仍然有以下的两个问题没有解决:
问题1:内存空间利用率低,只能利用一半的空间。
问题2:开销大。如果垃圾比较少,那么这种搬运得不偿失。
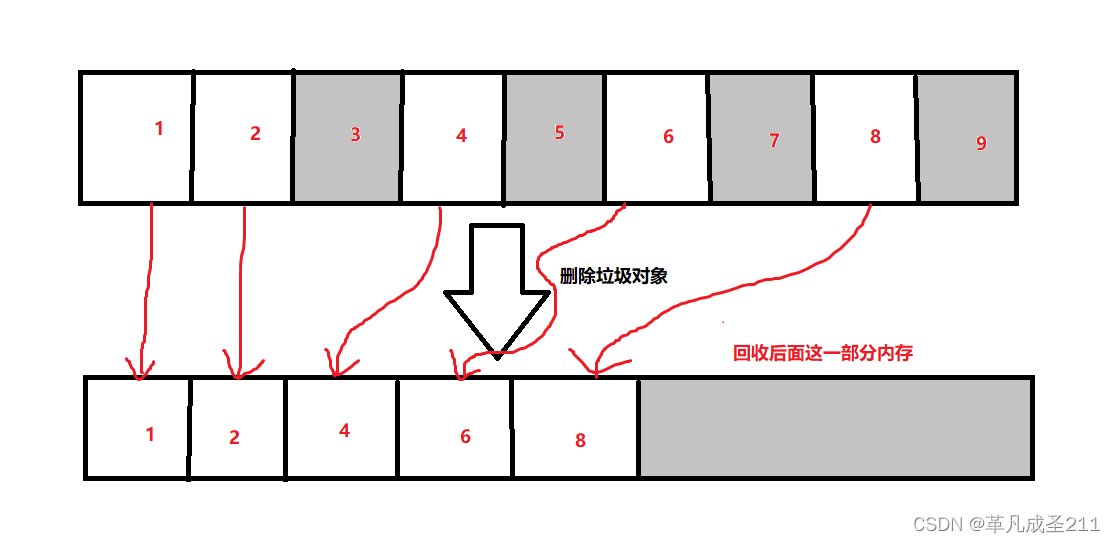
策略3:标记——整理
这个过程,就是把正常的对象(没有被标记为垃圾的)往前搬运。最后,释放掉最后面的内存。
下图当中,灰色部分的为垃圾。
但是,这个拷贝也是有开销的。
上述的3种方案,虽然可以解决问题,但是都有缺陷。因此,实际上JVM当中,会结合多种方案一起来实现,并不是采用单一的策略。这种方式,就是"分代回收"。
分代回收
分代回收,其实就是针对对象进行"分类",根据对象的"年龄"进行回收。
对象的年龄:每熬过GC的一轮扫描没有被回收,那么对象的年龄就+1岁。这个年龄存储在"对象头"当中。
大致是这样的一个过程:
存储对象的内存区域大致就被分为了两部分:新生代和老年代
在新生代当中,分为了两部分:伊甸区和幸存区。一共有2个幸存区
步骤1:对于刚刚产生的对象,都会被存放在"伊甸区"。
步骤2:如果熬过一轮GC,那么就会被拷贝到"幸存区",(应用了复制算法)。但是大部分对象都熬不过一轮的GC。
步骤3:在后续的几轮GC当中,幸存区的对象就在两个幸存区当中来回拷贝。此处也是采用了"复制算法",来淘汰掉一些对象。
步骤4:经过了多轮的GC后,如果一个对象还是没有被淘汰,那么就会被放入"老年代"。此时就认为这个对象存活的可能性就比较大了。对于老年代的对象来说,GC扫描的次数就远远低于新生代了。同时,老年代当中采用的就是"标记——整理"的方式来回收。

但是,有一种特殊的情况,就是当一个对象特别"大",也就是占用内存比较多的时候,无需经过多轮GC的扫描,就可以直接进入"老年代"了,因为回收这一类的对象比较消耗性能。
三、垃圾收集器有哪些
第一类:Serial收集器&Serial Old收集器(串行收集)
这两个垃圾收集器是串行收集的。那么也就意味着,在垃圾的扫描和释放的时候,其他的业务线程都需要停止工作。这种方式扫描得慢、释放得慢、也产生了严重的STW。
第二类:ParNew收集器&Parallel Old收集器&Parallel Scavenge收集器(并发收集)
这三个收集器、引入了多线程的方式来进行回收,也就是"并发收集"。并不影响业务线程执行业务代码。
第三类:CMS收集器
执行步骤:
步骤1:找到GCRoots(会引发STW)
找到GCRoots,但是会引起短暂的STW。
步骤2:并发标记
和业务线程一起执行。
步骤3:重新标记(会引发STW)
步骤4:回收内存
这个步骤,也是和业务线程一起执行的。

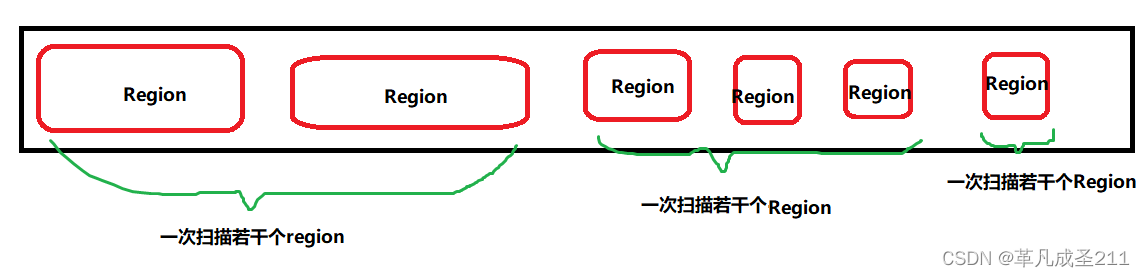
第四类:G1收集器
把整个内存,分成了很多个小的区域(Region)
给这些Region进行了不同的标记。有一些region存放新生的对象,有一些存放老年代的对象。
然后一次扫若干个Region(但不是全部扫完)
相关文章:
【JVM篇2】垃圾回收机制
目录 一、GC的作用 申请变量的时机&销毁变量的时机 内存泄漏 内存溢出(oom) 垃圾回收的劣势 二、GC的工作过程 回收垃圾的过程 第一阶段:找垃圾/判定垃圾 方案1:基于引用计数(非Java语言) 引用计数方式的缺陷 方案2:可达性分析…...
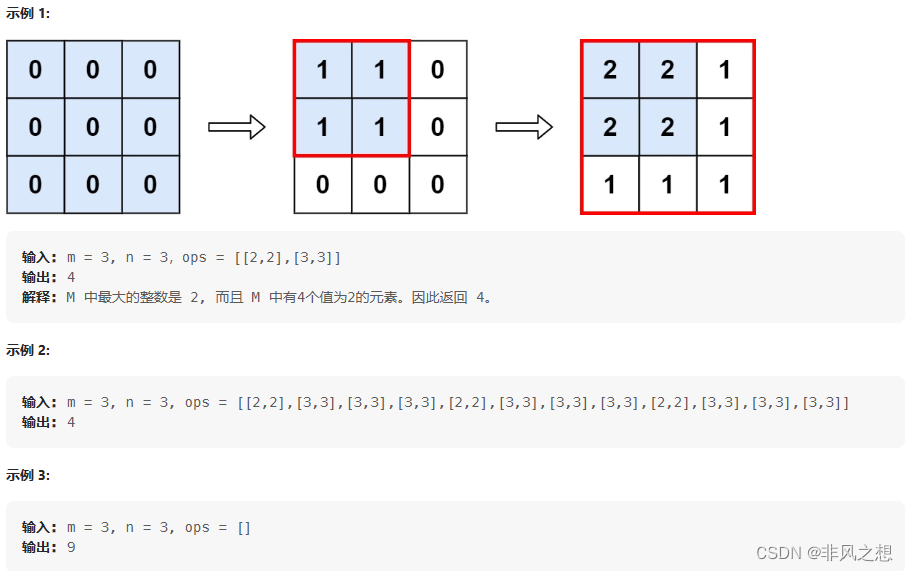
LeetCode598. 范围求和 II(python)
题目 给你一个 m x n 的矩阵 M ,初始化时所有的 0 和一个操作数组 op ,其中 ops[i] [ai, bi] 意味着当所有的 0 < x < ai 和 0 < y < bi 时, M[x][y] 应该加 1。 提示: 1 < m, n < 4 * 104 0 < ops.length < 104 o…...

观察者模式与发布订阅模式
前言 我的任督二脉终于被打通了,现在该你了 区别 观察者模式 就2个角色:观察者和被观察者(重要)明确知道状态源,明确知道对方是谁一对多关系 发布订阅模式 有3个角色:发布者,订阅者和发布订阅…...

磨金石教育摄影技能干货分享|烟花三月下扬州,是时候安排了!
人间三月最柔情,杨柳依依水波横。三月的风将要吹来,春天的门正式打开。对中国人来说,古往今来,赏春最好的地方是江南。人人都说江南好,可是江南哪里好呢?古人在这方面早就给出了答案:故人西辞黄…...

Kafka 消费组位移
Kafka 消费组位移消费者 API命令行Kafka : 基于日志结构(log-based)的消息引擎 消费消息时,只是从磁盘文件上读取数据,不会删除消息数据位移数据能由消费者控制,能很容易修改位移的值,实现重复消费历史数据…...

Python|数学|贪心|数组|动态规划|单选记录:实现保留3位有效数字(四舍六入五成双规则)|用Python来创造一个提示用户输入数字的乘法表|最小路径和
1、实现保留3位有效数字(四舍六入五成双规则)(数学,算法) 贡献者:weixin_45782673 输入:1234 输出:1234 12 12.0 4 4.00 0.2 0.200 0.32 0.320 1.3 1.30 1.235 1.24 1.245 1.24 1.…...

【MySQL】MySQL的索引
目录 介绍 索引的分类 索引的操作-创建索引-单列索引-普通索引 格式 操作 索引的操作-创建索引-单列索引-唯一索引 索引的操作-创建索引-单列索引-主键索引 索引的操作-创建索引-组合索引 索引的操作-全文索引 索引的操作-空间索引 索引的验证 索引的特点 介绍…...
弱监督实例分割 Box-supervised Instance Segmentation with Level Set Evolution 论文笔记
弱监督实例分割 Box-supervised Instance Segmentation with Level Set Evolution 论文笔记一、Abstract二、引言三、相关工作3.1 基于 Box 的实例分割3.2 基于层级的分割四、提出的方法4.1 图像分割中的层级模型4.2 基于 Box 的实例分割在 Bounding Box 内的层级进化输入的数据…...
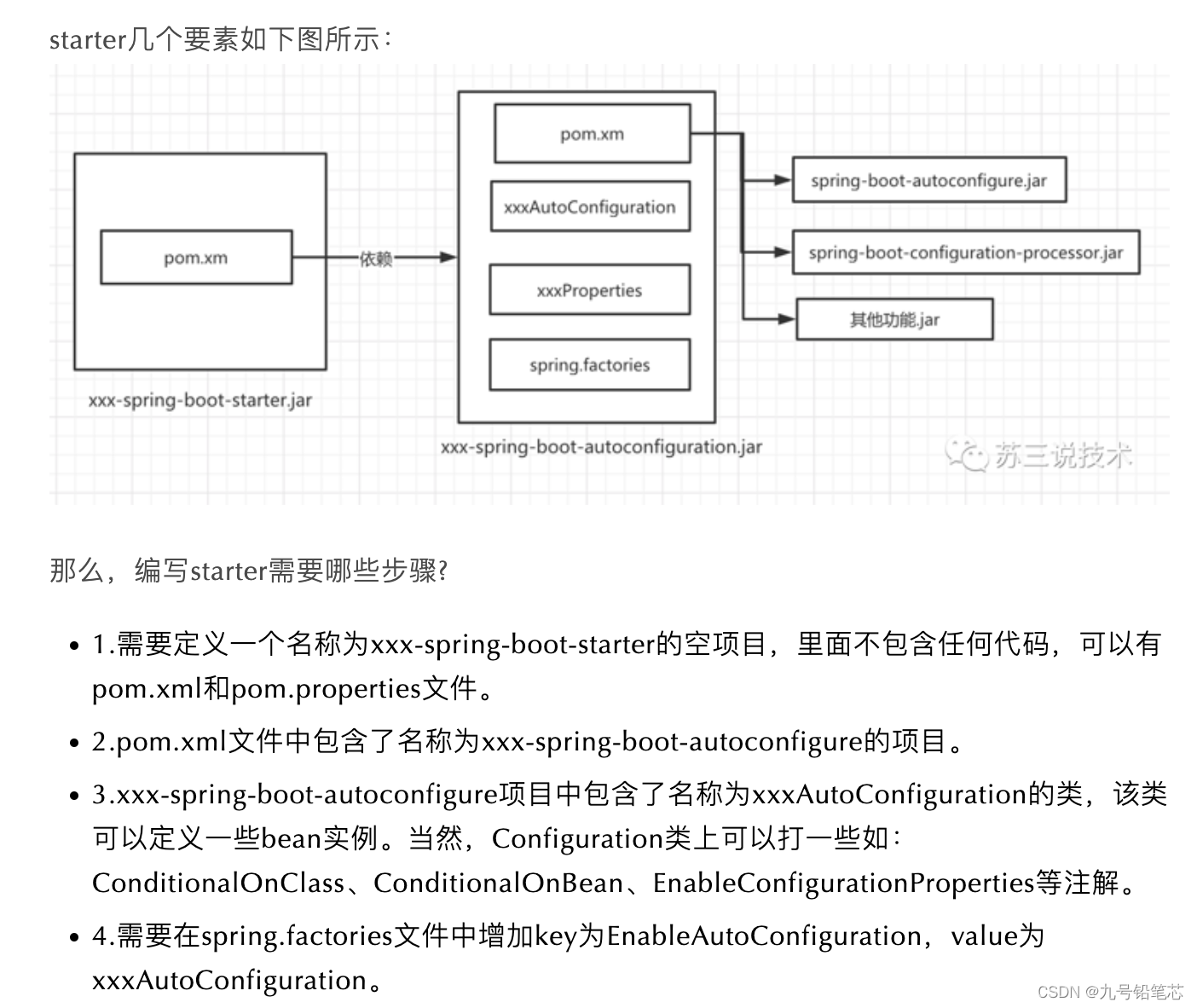
Springboot是什么
目录 为什么会要用springboot 1、之前 2、现在 springboot优点 springboot四大核心 自动装配介绍 1、自动装配作用是什么 2、自动装配原理 springboot starter是什么 1、starter作用 2、比如:我们想搭建java web框架 3、starter原理 SpringBootApplica…...
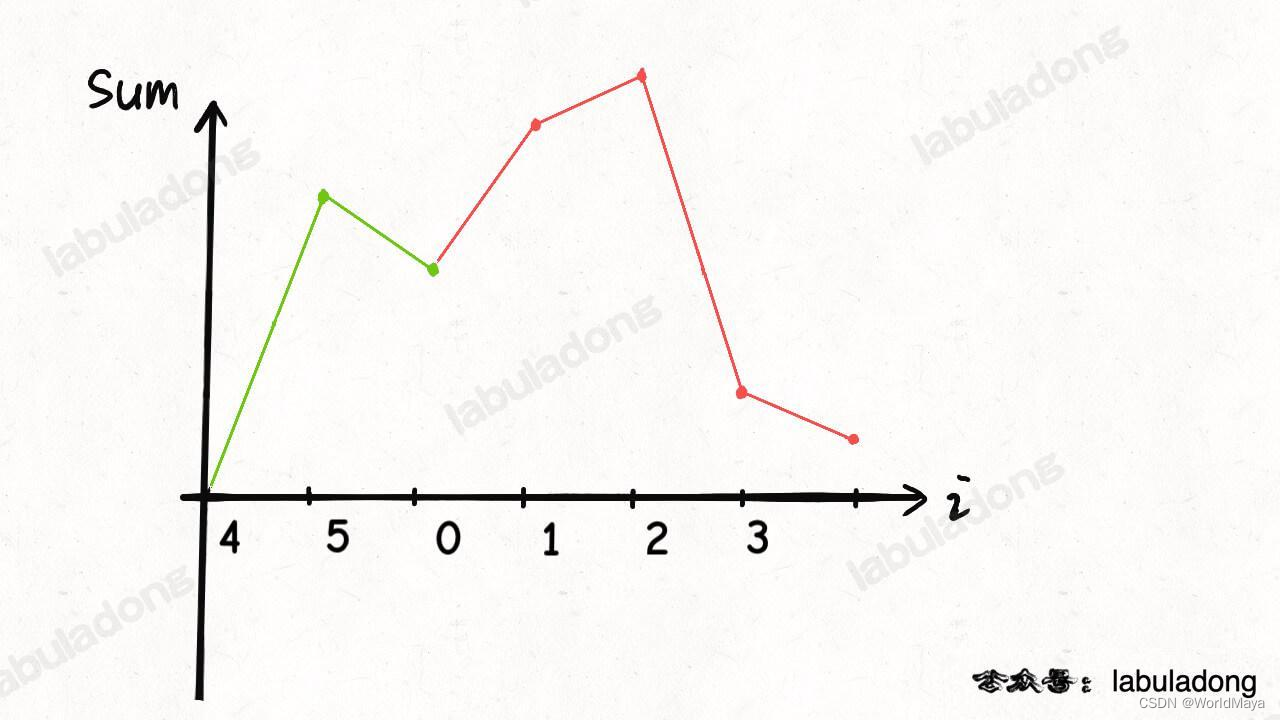
LeetCode 134. 加油站(函数图像法 / 贪心)
题目: 链接:LeetCode 134. 加油站 难度:中等 在一条环路上有 n 个加油站,其中第 i 个加油站有汽油 gas[i] 升。 你有一辆油箱容量无限的的汽车,从第 i 个加油站开往第 i1 个加油站需要消耗汽油 cost[i] 升。你从其中…...

王道计算机组成原理课代表 - 考研计算机 第三章 存储系统 究极精华总结笔记
本篇博客是考研期间学习王道课程 传送门 的笔记,以及一整年里对 计算机组成 知识点的理解的总结。希望对新一届的计算机考研人提供帮助!!! 关于对 存储系统 章节知识点总结的十分全面,涵括了《计算机组成原理》课程里…...
Flask-mock接口数据流程
背景:由于在开发过程中,会遇到以下的痛点 1.服务端接口提测延期,具体接口逻辑未完成实现,接口未能正常调通,导致客户端提测停滞; 2.因为前期已在技术评审上已与客户端开发定好接口字段,客户端比…...

springboot项目配置序列化,反序列化器
介绍本文介绍在项目中时间类型、枚举类型的序列化和反序列化自定义的处理类,也可以使用注解。建议枚举都实现一个统一的接口,方便处理。我这定义了一个Dict接口。枚举类型注解处理这种方式比较灵活,可以让枚举按照自己的方式序列化࿰…...
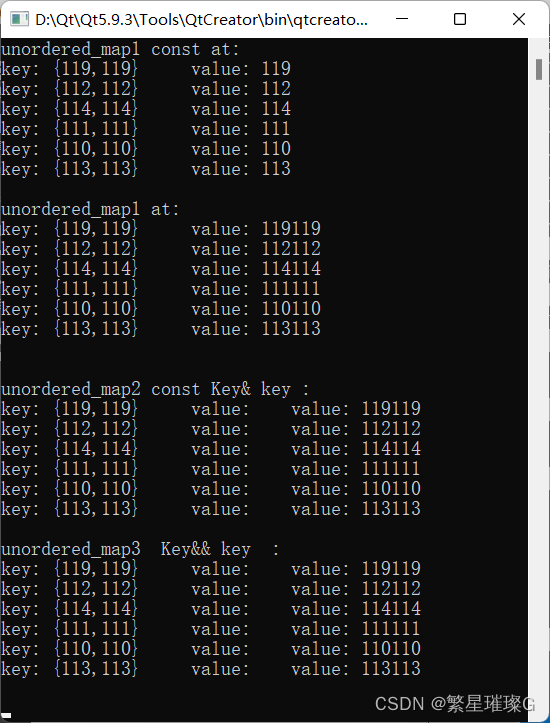
c++11 标准模板(STL)(std::unordered_map)(九)
定义于头文件 <unordered_map> template< class Key, class T, class Hash std::hash<Key>, class KeyEqual std::equal_to<Key>, class Allocator std::allocator< std::pair<const Key, T> > > class unordered…...

Seay代码审计工具
一、简介Seay是基于C#语言开发的一款针对PHP代码安全性审计的系统,主要运行于Windows系统上。这款软件能够发现SQL注入、代码执行、命令执行、文件包含、文件上传、绕过转义防护、拒绝服务、XSS跨站、信息泄露、任意URL跳转等漏洞,基本上覆盖常见PHP漏洞…...
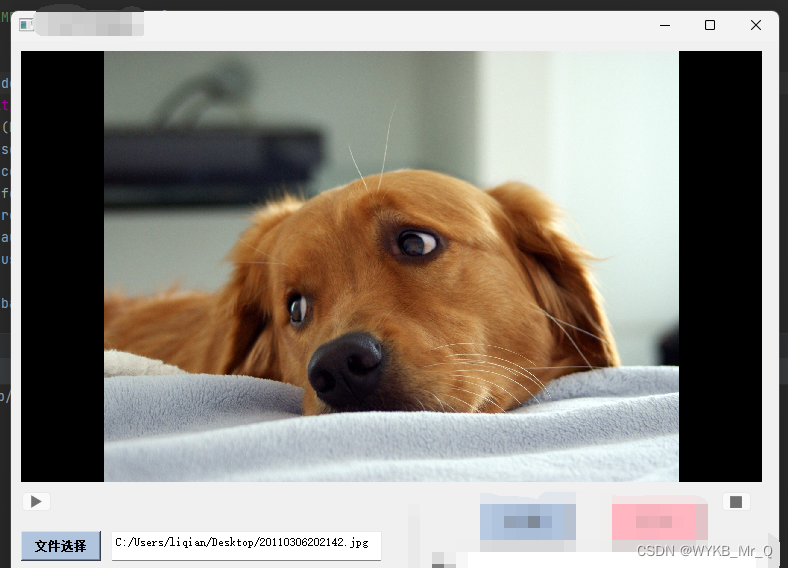
界面开发(4)--- PyQt5实现打开图像及视频播放功能
PyQt5创建打开图像及播放视频页面 上篇文章主要介绍了如何实现登录界面的账号密码注册及登录功能,还简单介绍了有关数据库的连接方法。这篇文章我们介绍一下如何在设计的页面中打开本地的图像,以及实现视频播放功能。 实现打开图像功能 为了便于记录实…...
核心系统国产平台迁移验证
核心系统国产平台迁移验证 摘要:信息技术应用创新,旨在实现信息技术领域的自主可控,保障国家信息安全。金融领域又是关系国家经济命脉的行业,而对核心交易系统的信息技术应用创新是交易所未来将要面临的重大挑战。为了推进国产化进…...

【数据结构之二叉树】——二叉树的概念及结构,特殊的二叉树和二叉树性质
文章目录一、二叉树的概念及结构1.概念2.现实中的二叉树3. 特殊的二叉树:3.二叉树的性质二、二叉树练习题总结一、二叉树的概念及结构 1.概念 一棵二叉树是结点的一个有限集合,该集合: 或者为空由一个根节点加上两棵别称为左子树和右子树的二叉树组成…...

Android学习之帧动画和视图动画
帧动画 帧动画中的每一帧其实都是一张图片,将许多图片连起来播放,就形成了帧动画。 在drawable目录下新建frmae_animation文件,在这个文件中定义了帧动画的每一帧要显示的图片,播放时,按从上到下显示。 <?xml v…...

vue2和vue3的区别
这周呢主要就是整理整理学的东西,不然看的也记不住,把这些学的东西做成笔记,感觉会清楚许多,这次就把vue2和vue3的区别总结一下,明天要考四级,嗐,本来想着复习四级,结果只写了一两套…...

5大核心功能揭秘:如何用LeagueAkari游戏辅助工具提升竞技水平
5大核心功能揭秘:如何用LeagueAkari游戏辅助工具提升竞技水平 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit LeagueAkari是一款基…...

从STM32到华大HC32F460:USB HOST MSC + FatFs R0.13c移植避坑全记录
从STM32到华大HC32F460:USB HOST MSC FatFs R0.13c移植实战指南 作为一名长期使用STM32的嵌入式开发者,第一次接触华大半导体的HC32F460系列MCU时,既兴奋又忐忑。兴奋的是国产MCU的性能已经能够媲美国际大厂,忐忑的是生态差异带来…...

储能出海架构重构:摒弃传统x86工控机,基于ARM边缘节点的EMS策略下沉实战
摘要: 随着储能系统在全球范围的大规模部署,出海项目的硬件BOM成本压力与恶劣环境下的维护成本日益凸显。传统的“x86工控机下发控制 透传网关上传数据”的双体架构显得极度臃肿且易引发单点故障。本文从底层研发架构师视角出发,深度拆解符合…...

数据采集系统演进:从插卡到嵌入式,技术选型与实战指南
1. 数据采集系统演进史:从插卡到嵌入式的四十年变迁聊起数据采集,很多刚入行的工程师可能觉得这是现代计算机技术催生的产物,无非是传感器、ADC、USB模块和LabVIEW那一套。但如果你翻翻行业的历史,会发现这条技术演进之路远比想象…...

华为OD新系统机试真题 2026.5.10 - 美观的灯笼
美观的灯笼(Py/Java/C/C/Js/Go)题解 华为OD新系统机试真题 华为OD新系统上机考试真题 5月10号 100分题型 华为OD新系统机试真题目录点击查看: 华为OD新系统机试真题题库目录|机考题库 算法考点详解 题目描述 春节将至,工人要在古镇老街挂灯笼。街上有…...

FGA自动化助手:告别FGO重复刷本,每天节省3小时游戏时间
FGA自动化助手:告别FGO重复刷本,每天节省3小时游戏时间 【免费下载链接】FGA Auto-battle app for F/GO Android 项目地址: https://gitcode.com/gh_mirrors/fg/FGA 你是否厌倦了在《命运/冠位指定》(FGO)中重复点击刷素材…...

基于微信小程序的校园水果配送商城毕设源码
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。一、研究目的本研究旨在构建一个基于微信小程序的校园水果配送商城系统以解决传统校园水果采购与配送模式中存在的效率低下问题。当前高校后勤管理普遍面临供应链管理复杂、信…...

打造高效愉悦的开发环境:从工具选型到实战配置全指南
1. 项目概述与核心价值最近在整理自己的开发工具箱时,发现了一个非常有意思的GitHub仓库,叫做awesome-vibe-coding-tools。这个标题本身就充满了吸引力——“Awesome”系列通常意味着精选和高质量,“Vibe”这个词则暗示着一种氛围、感觉或体验…...

Windows系统渗透利器:KitHack Winpayloads深度解析
Windows系统渗透利器:KitHack Winpayloads深度解析 【免费下载链接】KitHack Hacking tools pack & backdoors generator. 项目地址: https://gitcode.com/gh_mirrors/ki/KitHack KitHack是一款功能强大的渗透测试工具包,集成了多种黑客工具和…...

Neoscroll.nvim与Telescope集成:实现搜索结果的流畅滚动
Neoscroll.nvim与Telescope集成:实现搜索结果的流畅滚动 【免费下载链接】neoscroll.nvim Smooth scrolling neovim plugin written in lua 项目地址: https://gitcode.com/gh_mirrors/ne/neoscroll.nvim Neoscroll.nvim是一款用Lua编写的Neovim平滑滚动插件…...