日志可视化监控体系ElasticStack 8.X版本全链路实战
目录
一、SpringBoot3.X整合logback配置1.1 log4j、logback、self4j 之间关系
1.2 SpringBoot3.X整合logback配置
二、日志可视化分析ElasticStack
2.1为什么要有Elastic Stack
2.2 什么是Elastic Stack
三、ElasticSearch8.X源码部署
四、Kibana源码部署
五、LogStash8.X源码安装部署
5.1 LogStash宏观配置文件组成
5.2 安装部署
六、FileBeat安装部署
6.1为什么要有FileBeat?
6.2FileBeat配置
七、ElasticStack全链路配置
7.1 Filebeat部署
本博文将详细阐述如何通过一系列技术栈——包括Filebeat、Logstash、Elasticsearch(ES)和Kibana——来处理、索引、存储并可视化nannanw-demo.log日志文件的整个过程。将详细介绍这些步骤,确保您能够轻松地检索、分析和洞察日志文件中的重要信息。
通过下面的流程,nannanw-demo.log日志文件将被Filebeat高效地收集,并通过Logstash进行必要的转换和过滤,然后发送到Elasticsearch集群中进行索引和存储。最终,用户将能够通过Kibana这个强大的数据可视化工具来检索和分析这些日志数据,从而获取有价值的业务洞察。
一、SpringBoot3.X整合logback配置
1.1 log4j、logback、slf4j 之间关系
SLF4J(Simple logging Facade for Java) 门面设计模式 |外观设计模式
把不同的日志系统的实现进行了具体的抽象化,提供统一的日志使用接口具体的日志系统就有log4j,logback等;
logback也是log4j的作者完成的,有更好的特性,可以取代log4j的一个日志框架, 是slf4j的原生实现
log4j、logback可以单独的使用,也可以绑定slf4j一起使用
编码规范建议不直接用log4j、logback的API,应该用slf4j, 日后更换框架所带来的成本就很低
1.2 SpringBoot3.X整合logback配置
打印代码:
private static final Logger logger =LoggerFactory.getLogger(ProductController.class);@RequestMapping("findById")public Object findById(@RequestParam("id") long id ){ProductDO productDO = productService.findById(id);logger.info("这个是查询接口日志,info级别");logger.error("这个是查询接口日志,error级别");return productDO;}
配置文件
<?xml version="1.0" encoding="UTF-8"?>
<configuration><property name="LOG_HOME" value="./logs" /><!--采用打印到控制台,记录日志的方式--><appender name="console" class="ch.qos.logback.core.ConsoleAppender"><encoder><pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern></encoder></appender><!-- 采用保存到日志文件 记录日志的方式,%d{yyyy-MM-dd HH:mm:ss.SSS}:输出日志发生的时间,精确到毫秒。[%thread]:输出日志所在的线程名。%-5level:输出日志级别,使用占位符%5level可以保持日志级别的对齐。%logger{36}:输出日志所在的类名(只输出类名的后36个字符)。%msg:输出日志消息。%n:新行。--><appender name="rollingFile" class="ch.qos.logback.core.rolling.RollingFileAppender"><file>${LOG_HOME}/nannanw-demo.log</file><rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><fileNamePattern>${LOG_HOME}/nannanw-demo-%d{yyyy-MM-dd}.log</fileNamePattern></rollingPolicy><encoder><pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern></encoder></appender><!-- 指定某个类单独打印日志 logger是配置某个包或者类采用哪几个appender记录日志,比如控制台/文件;--><logger name="net.nannanw.service.impl.LogServiceImpl"level="INFO" additivity="false"><appender-ref ref="rollingFile" /><appender-ref ref="console" /></logger><root level="INFO" additivity="false"><appender-ref ref="rollingFile" /></root></configuration>
二、日志可视化分析ElasticStack
2.1为什么要有Elastic Stack
操作系统、网关、应用程序产生了很多日志,有单机有分布式部署,怎么看方便?
日志数据,字段格式参差不齐,如果进行过滤处理?
服务器多肉眼查看日志不方便,是否有各种图表、仪表盘,将数据分析结果以可视化的方式展示出来,更好理解和分析数据?
2.2 什么是Elastic Stack
它是一个开源的数据分析和可视化平台,由Elasticsearch、Logstash、Kibana和Beats组成,广泛用于实时数据分析、搜索和可视化
我们之前说的ELK实际上是分别由Elasticsearch、 Logstash、Kibana组成
在这两年发展的过程中有新成员Beats的加入,所以就形成了Elastic Stack,ELK是旧的称呼,Elastic Stack是新的名字
常见的数据采集流程:Beats 采集(Filebeat/Metricbeat)–> Logstash –> Elasticsearch –> Kibana
Elasticsearch:一个分布式实时搜索和分析引擎,能够快速地存储、搜索和分析大量结构化和非结构化数据,它是Elastic Stack的核心组件,提供分布式数据存储和搜索能力。
Logstash:是一个用于数据收集、转换和传输的数据处理引擎,支持从各种来源(如文件、日志、数据库等)收集数据
可以对数据进行结构化、过滤和转换,然后将数据发送到Elasticsearch等目标存储或分析系统。
Kibana:数据可视化和仪表盘工具,连接到Elasticsearch,通过简单易用的用户界面创建各种图表、图形和仪表盘
Beats:是轻量级的数据收集器,用于收集和发送各种类型的数据到Elasticsearch或Logstash
Beats提供了多种插件和模块,用于收集和传输日志、指标数据、网络数据和安全数据等
总结:Elastic Stack的架构主要是将各个组件连接起来形成数据处理和分析的流程
三、ElasticSearch8.X源码部署
1.上传安装包和解压:
tar -zxvf elasticsearch-8.4.1-linux-x86_64.tar.gz

2.新建一个用户,安全考虑,elasticsearch默认不允许以root账号运行
创建用户:useradd es_user
设置密码:passwd es_user

3.修改目录权限
# chmod是更改文件的权限
# chown是改改文件的属主与属组
# chgrp只是更改文件的属组。
chgrp -R es_user /usr/local/software/elk_test/elasticsearch-8.4.1
chown -R es_user /usr/local/software/elk_test/elasticsearch-8.4.1
chmod -R 777 /usr/local/software/elk_test/elasticsearch-8.4.1

4.修改文件和进程最大打开数,需要root用户,如果系统本身有这个文件最大打开数和进程最大打开数配置,则不用
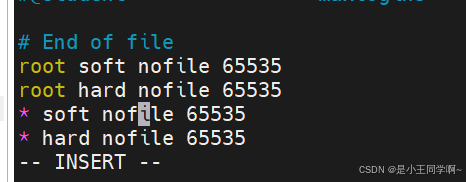
在文件内容最后添加后面两行(切记*不能省略)
vim /etc/security/limits.conf
* soft nofile 65535
* hard nofile 65535

5.修改虚拟内存空间,默认太小
在配置文件中改配置 最后一行上加上,执行 sysctl -p(立即生效)
vim /etc/sysctl.conf
vm.max_map_count=262144
6.修改elasticsearch的JVM内存,机器内存不足,常规线上推荐16到24G内存
vim config/jvm.options
-Xms1g
-Xmx1g

7.修改 elasticsearch相关配置
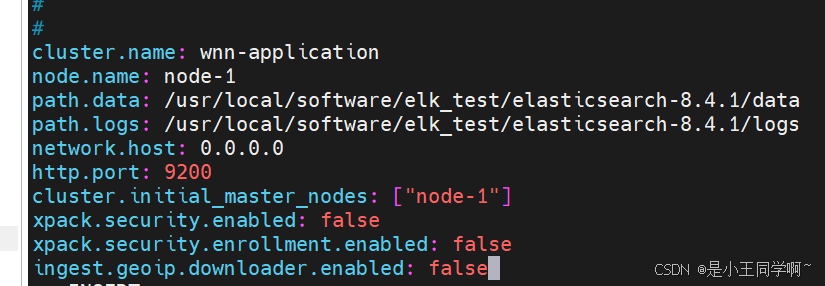
vim config/elasticsearch.yml
cluster.name: nannanw-application
node.name: node-1
path.data: /usr/local/software/elk_test/elasticsearch-8.4.1/data
path.logs: /usr/local/software/elk_test/elasticsearch-8.4.1/logs
network.host: 0.0.0.0
http.port: 9200
cluster.initial_master_nodes: ["node-1"]
xpack.security.enabled: false
xpack.security.enrollment.enabled: false
ingest.geoip.downloader.enabled: false

8.配置说明
cluster.name: 指定Elasticsearch集群的名称。所有具有相同集群名称的节点将组成一个集群。
node.name: 指定节点的名称。每个节点在集群中应该具有唯一的名称。
path.data: 指定用于存储Elasticsearch索引数据的路径。
path.logs: 指定Elasticsearch日志文件的存储路径。
network.host: 指定节点监听的网络接口地址。0.0.0.0表示监听所有可用的网络接口,开启远程访问连接
http.port: 指定节点上的HTTP服务监听的端口号。默认情况下,Elasticsearch的HTTP端口是9200。
cluster.initial_master_nodes: 指定在启动集群时作为初始主节点的节点名称。
xpack.security.enabled: 指定是否启用Elasticsearch的安全特性。在这里它被禁用(false),意味着不使用安全功能。
xpack.security.enrollment.enabled: 指定是否启用Elasticsearch的安全认证和密钥管理特性。在这里它被禁用(false)。
ingest.geoip.downloader.enabled: 指定是否启用GeoIP数据库下载功能。在这里它被禁用(false)
9.启动ElasticSearch
切换到es_user用户启动, 进入bin目录下启动, &为后台启动,再次提示es消息时 Ctrl + c 跳出
./elasticsearch &

10.常见命令,可以用postman访问(使用阿里云网络安全组记得开放端口)
#查看集群健康情况
http://112.24.7.xxx:9200/_cluster/health#查看分片情况
http://11224.7.xxx9200/_cat/shards?v=true&pretty#查看节点分布情况
http://112.24.7.xxx:9200/_cat/nodes?v=true&pretty#查看索引列表
http://112.24.7.xxx:9200/_cat/indices?v=true&pretty
11.常见问题注意
磁盘空间需要85%以下,不然ES状态会不正常
不要用root用户安装
linux内存不够
linux文件句柄
没开启远程访问 或者 网络安全组没看开放端口
有9300 tcp端口,和http 9200端口,要区分
没权限访问,重新执行目录权限分配
chgrp -R es_user /usr/local/software/elk_test/elasticsearch-8.4.1
chown -R es_user /usr/local/software/elk_test/elasticsearch-8.4.1
chmod -R 777 /usr/local/software/elk_test/elasticsearch-8.4.1

四、Kibana源码部署
1.上传安装包和解压
tar -zxvf kibana-8.4.1-linux-x86_64.tar.gz
2.配置用户权限
chgrp -R es_user /usr/local/software/elk_test/kibana-8.4.1
chown -R es_user /usr/local/software/elk_test/kibana-8.4.1
chmod -R 777 /usr/local/software/elk_test/kibana-8.4.1

3.修改配置文件
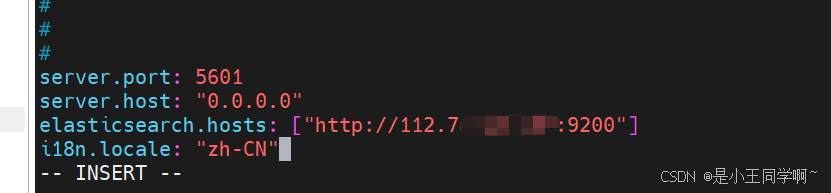
vim config/kibana.yml
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://112.74.7.xxx:9200"]
i18n.locale: "zh-CN" #汉化
server.port: 指定Kibana服务器监听的端口号,Kibana将在5601端口上监听HTTP请求。
server.host: 指定Kibana服务器绑定的网络接口地址, "0.0.0.0"表示监听所有可用的网络接口。
elasticsearch.hosts: 指定ES集群的主机地址,可以配置多个,Kibana将连接到位于"112.74.7.xxx"主机上、使用默认HTTP端口9200的es
i18n.locale: 指定Kibana界面的语言区域,"zh-CN"表示使用简体中文作为语言。
4.启动,切换到es_user 用户, 建议先不用守护进程方式启动,可以直接启动查看日志
./kibana &
5.访问(网络安全组记得开发端口)
# 验证请求
http://112.74.7.xxx:5601
#查看集群健康情况
GET /_cluster/health
#查看分片情况
GET /_cat/shards?v=true&pretty
#查看节点分布情况
GET /_cat/nodes?v=true&pretty
#查看索引列表
GET /_cat/indices?v=true&pretty
验证连接es是否成功:
五、LogStash8.X源码安装部署
5.1 LogStash宏观配置文件组成
# 输入
input {
...
}
# 过滤器
filter {
...
}
# 输出
output {
...
}
5.2 安装部署
1.上传安装包和解压
tar -zxvf logstash-8.4.1-linux-x86_64.tar.gz
JVM内存不够的话修改 config/jvm.options
2.创建新配置文件 touch config/test-logstash.conf
input {
file {
path => "/usr/local/software/elk_test/nannanw-demo.log"
start_position => "beginning"
stat_interval => "3"
type => "nannanw-demo-log"
}
}output {
if [type] == "nannanw-demo-log" {
elasticsearch {
hosts => ["http://112.74.97.xxx:9200"]
index => "nannanw-demo-%{+YYYY.MM.dd}"
}
}
}

注: 这个内容输入得时候,注意不要有多余得换行符 空格等得。建议在linux中 vim直接编辑。
3.配置文件
input:指定Logstash接收数据的输入插件,使用file插件作为输入。file插件用于读取并处理文件中的数据。
file:指定使用的输入插件是file插件。
path:指定要读取的文件路径,Logstash会读取位于"/usr/local/software/elk_test/log/springboot-nannanw-demo.log"路径下的文件。
start_position:指定从文件的哪个位置开始读取数据。设置为"beginning"表示从文件的开始位置开始读取数据。
stat_interval:指定文件的状态检查间隔(以秒为单位)。设置为"3"表示每隔3秒检查一次文件状态,以判断是否有新数据。
type:指定数据的类型名称。设置为"nannanw-demo-log"表示数据的类型是SpringBoot访问日志。
output:指定Logstash处理完数据后的输出插件。使用elasticsearch插件将处理后的日志数据发送到Elasticsearch。
elasticsearch:指定使用的输出插件是elasticsearch插件。
hosts:指定Elasticsearch集群的主机地址。Logstash将处理后的数据发送到位于"112.74.97.XXXX"主机上,HTTP端口9200的ES节点
index:指定数据在Elasticsearch中的索引名称,比如【filebeat-8.4.1-2024.06.16 】
使用[@metadata][beat]字段、[@metadata][version]字段和当前日期来构建索引名称
可以根据采集数据的来源和版本动态创建索引。
4.启动,进入bin目录
./logstash -f /usr/local/software/elk_test/logstash-8.4.1/config/test-logstash.conf &
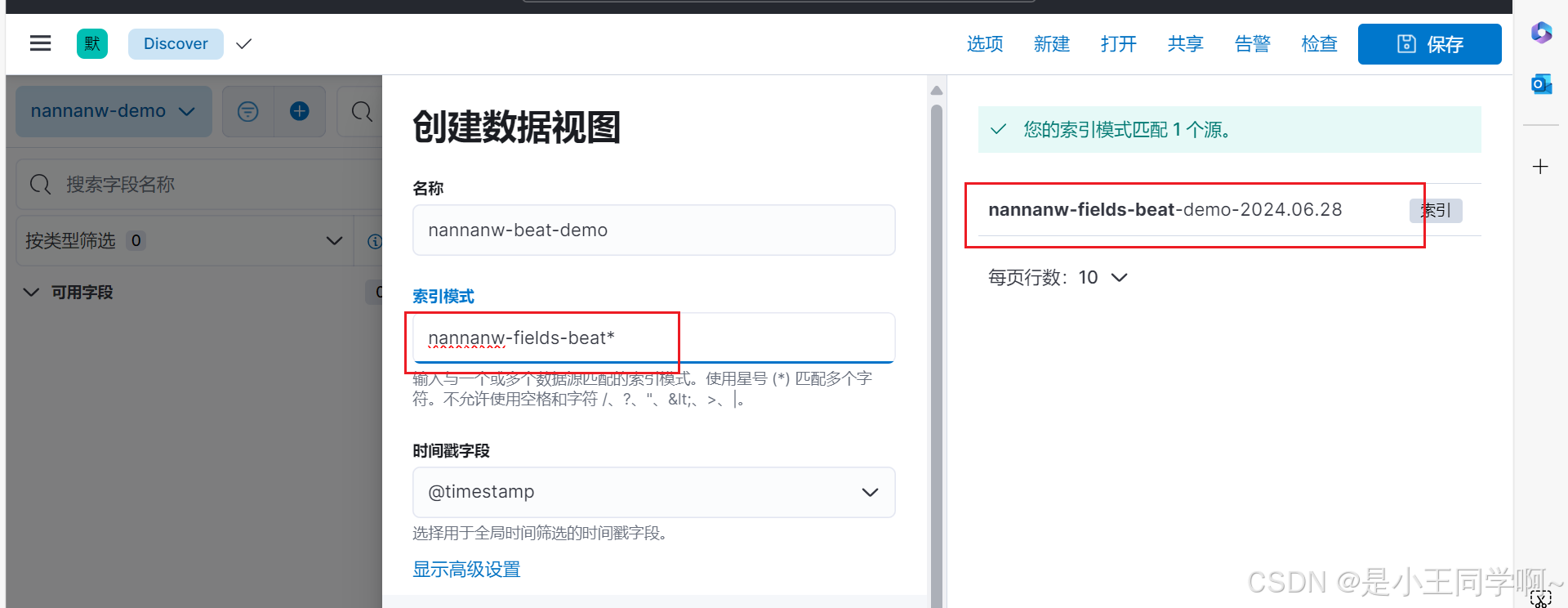
执行成功后,进入kibana索引管理页面查看:
出现下图得这种就表示logstash内容已经写入es了

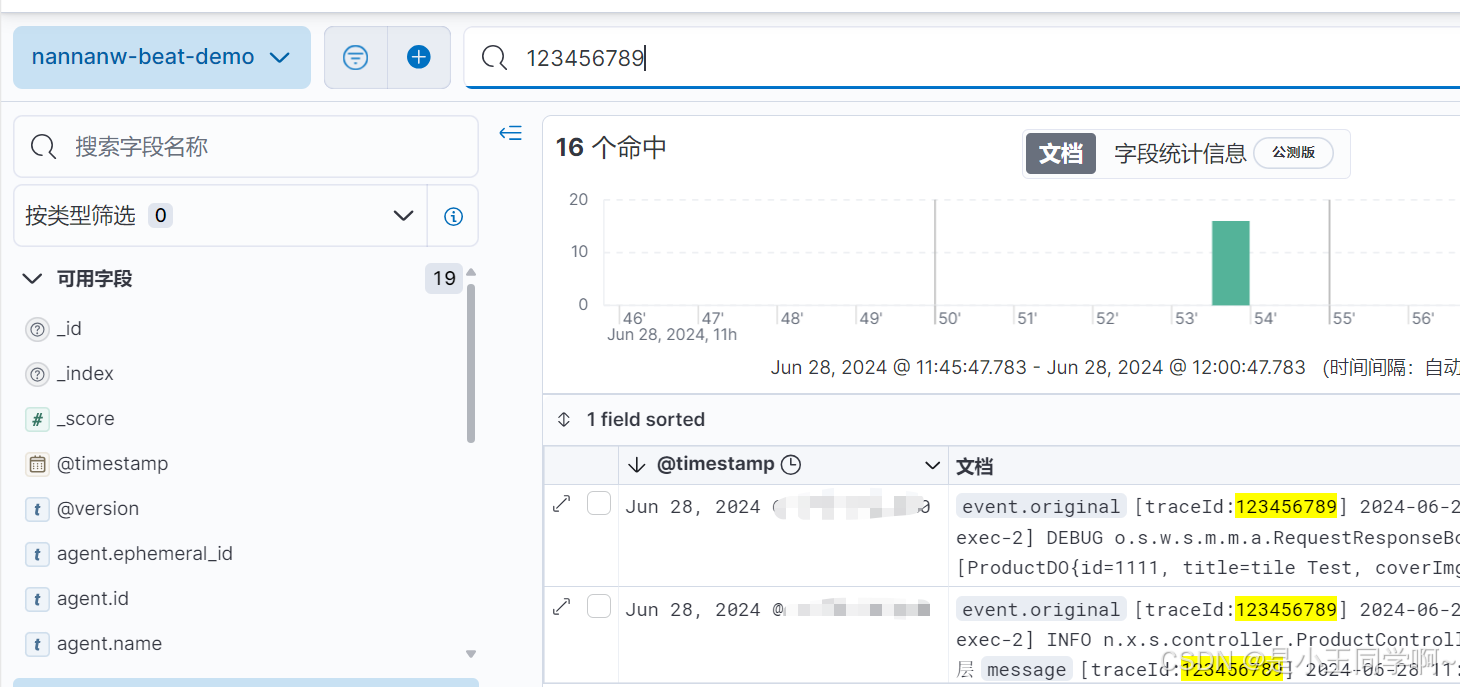
通过kibana查看es日志:
可以指定traceId:888888889123进行检索

六、FileBeat安装部署
6.1为什么要有FileBeat?
Beats 可以直接把数据直接写入到 Elasticsearch 之中,为什么还需要 Logstash 呢?
是因为 Logstash 有丰富的 filter 供我们使用,可以帮加工数据,并最终把数据转为对应要求的格式
beats是轻量级的用来收集日志的 用来优化logstash的, 而logstash更加专注一件事(消耗的性能比较多),那就是数据转换,格式化,等处理工作
6.2FileBeat配置
filebeat.inputs: //指定Filebeat的输入配置,用于定义要监视的日志文件。
- type: log //指定日志文件的类型, 可以是log、file等。
paths:
- /path/to/logfile1.log //指定要监视的日志文件的路径。可以是单个路径或多个路径的列表。
- /path/to/logfile2.log
fields: //为每个输入配置添加自定义字段,用于标记和分类日志数据。
app: myapp
fields_under_root: true//控制是否将fields字段中的自定义字段添加到根级别的事件中,以便在输出时可见。output.logstash://指定Filebeat的输出配置,将日志数据发送到Logstash
hosts: ["logstash-host:5044"]//指定Logstash的地址和端口号,可以是单个地址或多个地址的列表。
此外,Filebeat配置文件还可以包含其他参数,用于定制Filebeat的行为和功能,如日志采集的过滤规则、证书设置、日志解析器等。
七、ElasticStack全链路配置
数据采集链路
Beats 采集(Filebeat/Metricbeat)–> Logstash –> Elasticsearch –> Kibana
7.1 Filebeat部署
1.安装包和解压
tar -zxvf filebeat-8.4.1-linux-x86_64.tar.gz

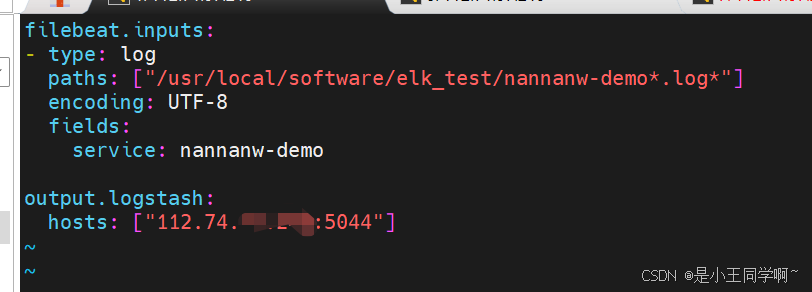
2.进入目录,创建配置文件 touch test-filebeat.yml
filebeat.inputs:
- type: log
paths: ["/usr/local/software/elk_test/nannanw-demo*.log*"]
encoding: UTF-8
fields:
service: nannanw-demooutput.logstash:
hosts: ["112.74.97.xxx:5044"]
模拟日志数据,准备日志文件,/usr/local/software/elk_test/nannanw-demo.log
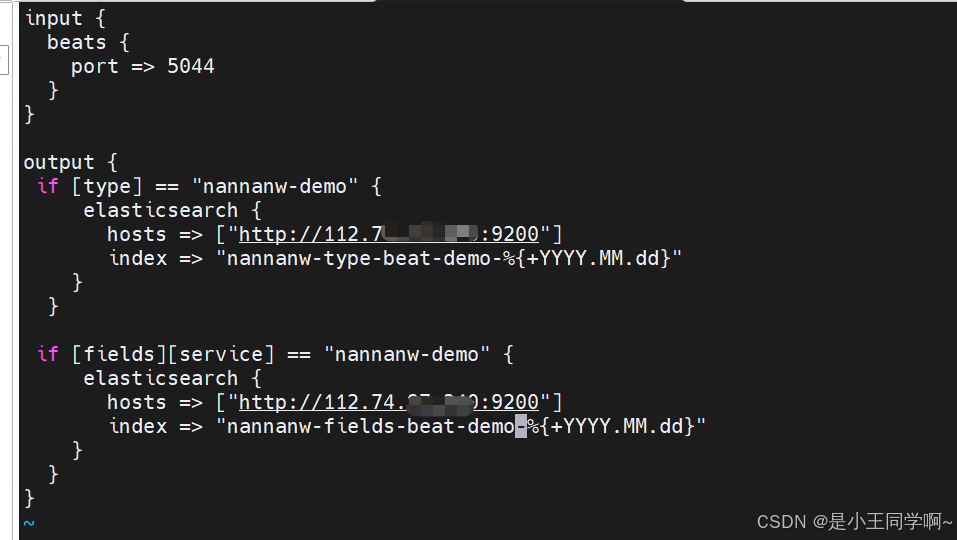
3.配置LogStash配置文件
input {
beats {
port => 5044
}
}output {
if [type] == "nannanw-demo" {
elasticsearch {
hosts => ["http://112.74.97.xxx:9200"]
index => "nannanw-type-beat-demo-%{+YYYY.MM.dd}"
}
}if [fields][service] == "nannanw-demo" {
elasticsearch {
hosts => ["http://112.74.97.xxx:9200"]
index => "nannanw-fields-beat-demo-%{+YYYY.MM.dd}"
}
}
}
input:指定Logstash接收数据的输入插件。使用beats插件作为输入.beats插件用于接收来自Beats数据采集器的日志数据。
beats:指定使用的输入插件是beats插件。
port:指定beats插件监听的端口号, Logstash会监听5044端口,等待来自Beats采集器的数据。
4.启动logstash (停止之前进程)
./logstash -f /usr/local/software/elk_test/logstash-8.4.1/config/test-beat-logstash.conf &
5.启动filebeat,停止方案 ps -ef |grep filebeat
./filebeat -e -c test-filebeat.yml &
6.kibana验证

全文到这就结束了,以上内容就是nannanw-demo.log 从文件到写入es 到kibana展示检索得全部过程~
相关文章:
日志可视化监控体系ElasticStack 8.X版本全链路实战
目录 一、SpringBoot3.X整合logback配置1.1 log4j、logback、self4j 之间关系 1.2 SpringBoot3.X整合logback配置 二、日志可视化分析ElasticStack 2.1为什么要有Elastic Stack 2.2 什么是Elastic Stack 三、ElasticSearch8.X源码部署 四、Kibana源码部署 五、LogSta…...

【LinuxC语言】定义线程池结果
文章目录 前言任务结构体线程池定义总结前言 在并发编程中,线程池是一种非常重要的设计模式。线程池可以有效地管理和控制线程的数量,避免线程频繁创建和销毁带来的性能开销,提高系统的响应速度。在Linux环境下,我们可以使用C语言来实现一个简单的线程池。 线程池的主要组…...

uniapp分包
分包是为了优化小程序的下载和启动速度 小程序启动默认下载主包并启动页面,当用户进入分包时,才会下载对应的分包,下载完进行展示。 /* 在manifest.json配置下添加optimization,开启分包优化 */ "mp-weixin" : {/**分包…...
Python 生成Md文件带超链 和 PDF文件 带分页显示内容
software.md # -*- coding: utf-8 -*- import os f open("software.md", "w", encoding"utf-8") f.write(内部测试版2024 MD版\n) for root, dirs, files in os.walk(path): dax os.path.basename(root)if dax "":print("空白…...

行业模板|DataEase旅游行业大屏模板推荐
DataEase开源数据可视化分析工具于2022年6月发布模板市场(https://templates-de.fit2cloud.com),并于2024年1月新增适用于DataEase v2版本的模板分类。模板市场旨在为DataEase用户提供专业、美观、拿来即用的大屏模板,方便用户根据…...

this.$refs[tab.$attrs.id].scrollIntoView is not a function
打印this.$refs[tab.$attrs.id].scrollIntoView 在控制台看到的是一个undefined 是因为this.$refs[tab.$attrs.id] 不是一个dom 是一个vuecomponent 如图所示: 所以我用的这个document.querySelector(.${tab.$attrs.id})获取dom document.querySelector(.${tab.$attrs.id})…...

【AI是在帮助开发者还是取代他们?】AI与开发者:合作与创新的未来
目录 前言一、AI工具现状(一)GitHub Copilot(二)TabNine 二、AI对开发者的影响(一)影响和优势(二)新技能和适应策略(三)保持竞争力的策略 三、AI开发的未来&a…...
【SpringBoot Web框架实战教程(开源)】01 使用 pom 方式创建 SpringBoot 第一个项目
导读 这是一系列关于 SpringBoot Web框架实战 的教程,从项目的创建,到一个完整的 web 框架(包括异常处理、拦截器、context 上下文等);从0开始,到一个可以直接运用在生产环境中的web框架。而且所有源码均开…...

Boosting【文献精读、翻译】
Boosting Bhlmann, P., & Yu, B. (2009). Boosting. Wiley Interdisciplinary Reviews: Computational Statistics, 2(1), 69–74. doi:10.1002/wics.55 摘要 在本文中,我们回顾了Boost方法,这是分类和回归中最有效的机器学习方法之一。虽然我们也讨…...

保姆级教程|如何配置ROS1主从机
在机器人开发经常遇到使用两个板子通信问题,比如一个板子跑底层的运动控制,一个板子跑定位导航。为了确保两个板子之间的ROS通信流畅,我们需要在两个板子的.bashrc文件中添加必要的环境变量配置。首先,确保你的 /etc/hosts 文件中…...
及其Python 和 MATLAB 实现)
贝叶斯优化算法(Bayesian Optimization)及其Python 和 MATLAB 实现
贝叶斯优化算法(Bayesian Optimization)是一种基于贝叶斯统计理论的优化方法,通常用于在复杂搜索空间中寻找最优解。该算法能够有效地在未知黑盒函数上进行优化,并在相对较少的迭代次数内找到较优解,因此在许多领域如超…...

NLP - 基于bert预训练模型的文本多分类示例
项目说明 项目名称 基于DistilBERT的标题多分类任务 项目概述 本项目旨在使用DistilBERT模型对给定的标题文本进行多分类任务。项目包括从数据处理、模型训练、模型评估到最终的API部署。该项目采用模块化设计,以便于理解和维护。 项目结构 . ├── bert_dat…...

数据库备份和还原
一、备份 备份类型 1.完全备份 全备份是指对整个数据集进行完整备份。每次备份都会复制所有选定的数据,无论这些数据是否发生了变化。 2.增量备份 增量备份是指仅备份自上次备份(无论是全备份还是增量备份)以来发生变化的数据。它记录了…...
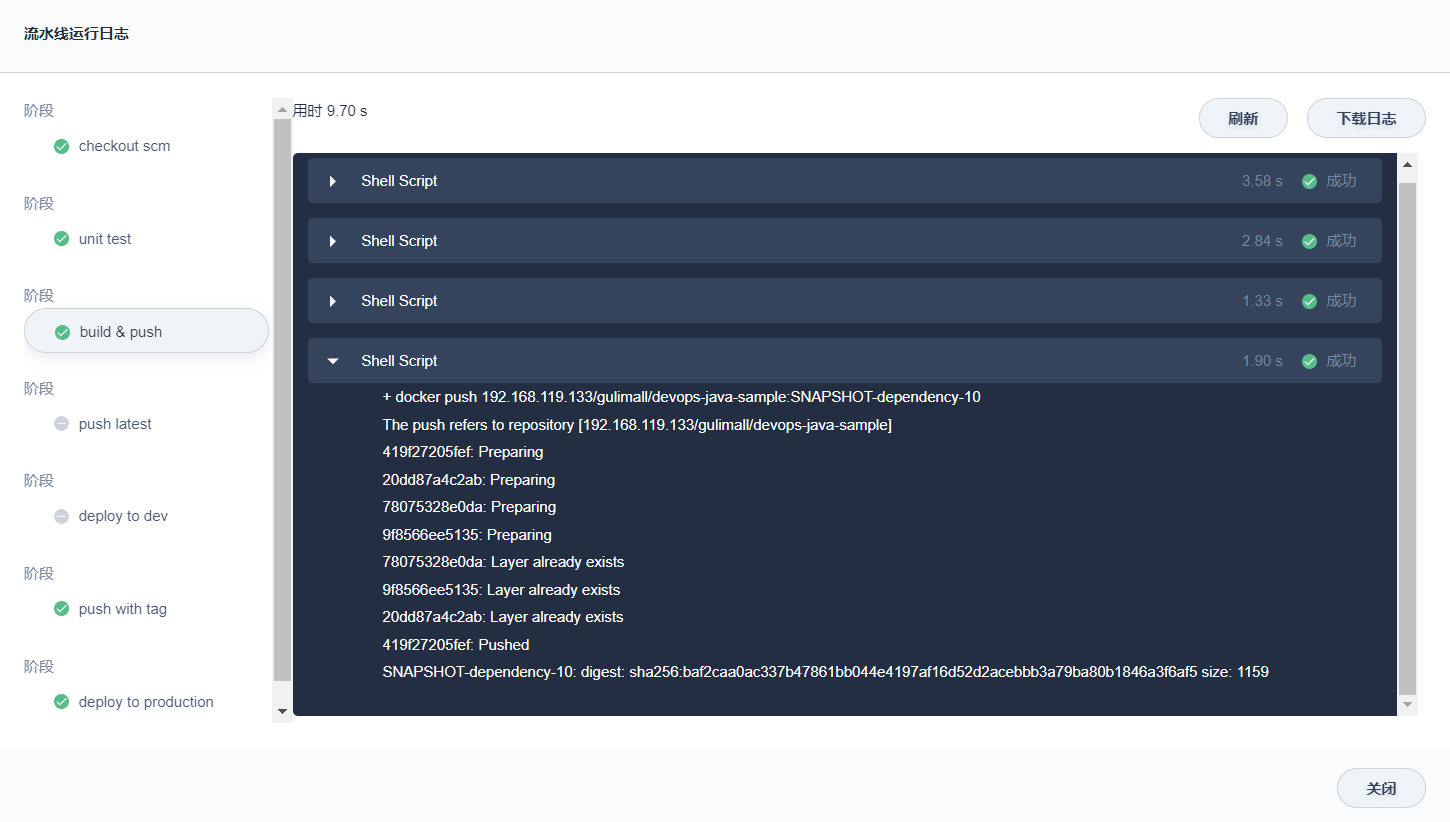
谷粒商城-个人笔记(集群部署篇一)
前言 学习视频:Java项目《谷粒商城》架构师级Java项目实战,对标阿里P6-P7,全网最强学习文档: 谷粒商城-个人笔记(基础篇一)谷粒商城-个人笔记(基础篇二)谷粒商城-个人笔记(基础篇三)谷粒商城-个人笔记(高级篇一)谷粒商城-个…...

Linux环境下的字节对齐现象
在Linux环境下,字节对齐是指数据在内存中的存储方式。字节对齐是为了提高内存访问的效率和性能。 在Linux中,默认情况下,结构体和数组的成员会进行字节对齐。具体的对齐方式可以通过编译器选项来控制。 在使用C语言编写程序时,可…...
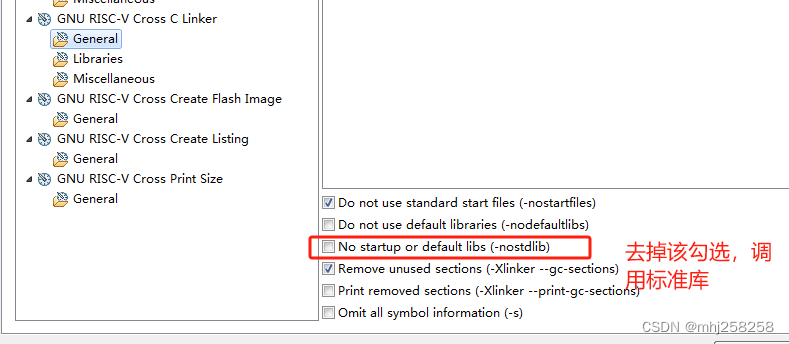
没有调用memcpy却报了undefined reference to memcpy错误
现象 在第5行出现了,undefined reference to memcpy’ 1 static void printf_x(unsigned int val) 2{ 3 char buffer[32]; 4 const char lut[]{0,1,2,3,4,5,6,7,8,9,A,B,C,D,E,F}; 5 char *p buffer; 6 while (val || p buffer) { 7 *(p) …...

import和require的区别
import是ES6标准中的模块化解决方案,require是node中遵循CommonJS规范的模块化解决方案。 后者支持动态引入,也就是require(${path}/xx.js),前者目前不支持,但是已有提案。 前者是关键词,后者不是。 前者是编译时加…...

白骑士的Python教学高级篇 3.3 数据库编程
系列目录 上一篇:白骑士的Python教学高级篇 3.2 网络编程 SQL基础 Structured Query Language (SQL) 是一种用于管理和操作关系型数据库的标准语言。SQL能够执行各种操作,如创建、读取、更新和删除数据库中的数据(即CRUD操作)&a…...

macOS 安装redis
安装Redis在macOS上通常通过Homebrew进行,Homebrew是macOS上一个流行的包管理器。以下是安装Redis的步骤: 一 使用Homebrew安装Redis 1、安装Homebrew(如果尚未安装): 打开终端(Terminal)并执…...
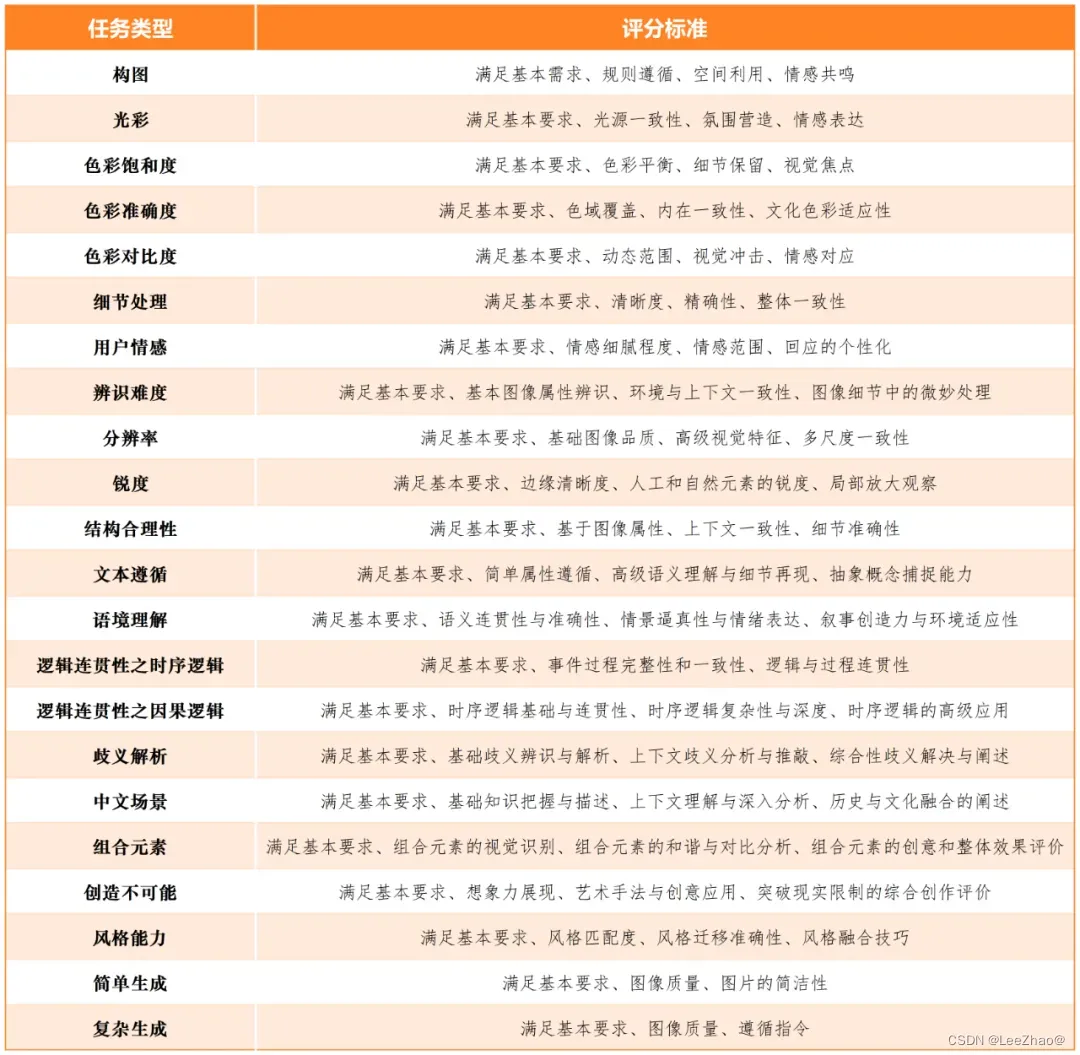
【AIGC评测体系】大模型评测指标集
大模型评测指标集 (☆)SuperCLUE(1)SuperCLUE-V(中文原生多模态理解测评基准)(2)SuperCLUE-Auto(汽车大模型测评基准)(3)AIGVBench-T2…...

强化学习在并行机构人形机器人控制中的应用
1. 项目概述在机器人控制领域,强化学习(RL)正逐渐成为解决复杂动力学系统问题的有力工具。然而,当面对具有并行驱动机构的人形机器人时,传统RL训练方法往往面临一个关键挑战:大多数仿真环境无法准确模拟闭环运动链(Closed Kinemat…...

隧道裂缝剥落病害AI识别系统
我国现有公路隧道超2.5万座,总里程超2.8万公里,其中运营超过15年的老旧隧道占比达35%。据交通运输部2025年统计,年均因隧道结构病害导致的交通中断超1200次,直接经济损失超45亿元。传统检测模式暴露四大核心痛点:检测周…...

深度学习从心电信号中解码呼吸频率:原理、实现与临床价值
1. 项目概述:从心电信号中“听”到呼吸声呼吸频率,这个我们每分钟都在进行却很少被精确量化的生命体征,在临床医学中扮演着至关重要的角色。它不仅是评估呼吸系统功能的直接指标,更是反映全身代谢、循环乃至神经系统状态的“窗口”…...

基于LM22678的树莓派硬盘专用电源设计:解决供电不稳与电流冲击
1. 项目概述:为什么我们需要一个“专用”电源?如果你正在用树莓派搭配一块机械硬盘搭建一个家庭服务器或者个人云存储,可能已经遇到了一个不大不小的麻烦:供电不稳。树莓派官方推荐的5V/3A电源,单独带树莓派4B跑满负载…...

Java数组工具类实战:设计不可实例化的静态工具类
实现一个工具类 MathUtils,满足以下要求: 1. 所有方法均为静态,且该类不能从外部实例化(提示:使用私有构造器)。 2. 提供三个静态方法:- maxArray(int[] arr):返回较大值;…...

Veo 2胶片质感生成器失效?——深度解析Color Science v2.3内核中被屏蔽的Cinematic Grain Injection层
更多请点击: https://kaifayun.com 第一章:Veo 2胶片质感生成器失效现象全景透视 近期大量用户反馈,Veo 2 胶片质感生成器在调用 generate_film_effect() 接口后返回空纹理、纯灰帧或 HTTP 503 Service Unavailable 错误,且该问题…...

6款高效降AI率工具 改写实力出众
写论文时反复检测出的AI痕迹总让你提心吊胆?别担心,这里整理了6款真正好用的论文降AI率工具,堪称应对AI生成特征的“得力助手”。它们能有效识别并消除AI生成的痕迹,改写能力出众,帮你快速降低查重率,顺利通…...

TorchDynamo与TorchInductor:PyTorch编译器生态的完整解析
TorchDynamo与TorchInductor:PyTorch编译器生态的完整解析 【免费下载链接】torchdynamo A Python-level JIT compiler designed to make unmodified PyTorch programs faster. 项目地址: https://gitcode.com/gh_mirrors/to/torchdynamo TorchDynamo 是一个…...

php有什么版本,php语言有几个版本
php有什么版本,php语言有几个版本PHP的大版本主要分四支:PHP4/PHP5/PHP6/PHP7 其中,PHP4由于太古老、对OO支持不力已基本被淘汰,请无视PHP4。 PHP6由于基本没有生产线上的应用,还基本只是一款概念产品,很多功能已在PHP…...

告别坐标点击!用Poco精准定位UI控件,让你的Airtest安卓自动化脚本更稳定
告别坐标点击!用Poco精准定位UI控件,让你的Airtest安卓自动化脚本更稳定每次UI微调就导致脚本大面积失效?分辨率变化让精心编写的自动化测试瞬间崩溃?作为从坐标点击转型到控件识别的实践者,我深刻理解这种挫败感。三年…...