【机器学习实战】Baseline精读笔记
比赛用到的库
-
numpy:提供(多维)数组操作
-
pandas:提供数据结构、数据分析
-
catboost:用于机器学习的库,特别是分类和回归任务
-
sklearn.model_selection:包含模型选择的多种方法,如交叉验证
-
sklearn.metrics:包含评估模型性能的多种指标,提供如accuracy_score这样的方法
-
sklearn.feature_extraction.text:提供将文本转换为特征向量的TF-idf向量化器
-
rdkit:化学信息学和机器学习软件,处理化学结构
-
tqdm:用于在长循环中添加进度条的库
-
sys:与Python解释器密切相关的模块和由解释器使用或维护的变量和函数
-
os:提供与操作系统交互的功能
-
gc:垃圾收集器接口:用于手动标记对象为可删除
-
re:正则表达式库,用于字符串搜索和替换
-
argparse:用于编写用户友好的命令行接口
-
warnings:用于发出警告,或忽略警告。
使用到的关键的库文档链接:
numpy:NumPy 参考 — NumPy v2.0 手册
pandas:API reference — pandas 2.2.2 documentation (pydata.org)
catboost:CatBoost | CatBoost
sklearn:API Reference — scikit-learn 1.5.1 documentation
rdkit:RDKit中文教程 — RDKit 中文教程 2020.09 文档 (chenzhaoqiang.com)
sys:sys — System-specific parameters and functions — Python 3.12.4 documentation
库的导入
import numpy as np
import pandas as pd
from catboost import CatBoostClassifier
from sklearn.model_selection import StratifiedKFold, KFold, GroupKFold
from sklearn.metrics import f1_score
from rdkit import Chem
from rdkit.Chem import Descriptors
from sklearn.feature_extraction.text import TfidfVectorizer
import tqdm, sys, os, gc, re, argparse, warnings
warnings.filterwarnings('ignore') # 忽略警告
数据预处理
train = pd.read_excel('./dataset-new/traindata-new.xlsx')
test = pd.read_excel('./dataset-new/testdata-new.xlsx')# test数据不包含 DC50 (nM) 和 Dmax (%)
train = train.drop(['DC50 (nM)', 'Dmax (%)'], axis=1)# 定义了一个空列表drop_cols,用于存储在测试数据集中非空值小于10个的列名。
drop_cols = []
for f in test.columns:if test[f].notnull().sum() < 10:drop_cols.append(f)# 使用drop方法从训练集和测试集中删除了这些列,以避免在后续的分析或建模中使用这些包含大量缺失值的列
train = train.drop(drop_cols, axis=1)
test = test.drop(drop_cols, axis=1)# 使用pd.concat将清洗后的训练集和测试集合并成一个名为data的DataFrame,便于进行统一的特征工程处理
data = pd.concat([train, test], axis=0, ignore_index=True)
cols = data.columns[2:]
除此之外,数据预处理可以使用数据增强、数据清洗、手动扩充等方法。
特征工程
# 将SMILES转换为分子对象列表,并转换为SMILES字符串列表
data['smiles_list'] = data['Smiles'].apply(lambda x:[Chem.MolToSmiles(mol, isomericSmiles=True) for mol in [Chem.MolFromSmiles(x)]])
data['smiles_list'] = data['smiles_list'].map(lambda x: ' '.join(x)) # 使用TfidfVectorizer计算TF-IDF
tfidf = TfidfVectorizer(max_df = 0.9, min_df = 1, sublinear_tf = True)
res = tfidf.fit_transform(data['smiles_list'])# 将结果转为dataframe格式
tfidf_df = pd.DataFrame(res.toarray())
tfidf_df.columns = [f'smiles_tfidf_{i}' for i in range(tfidf_df.shape[1])]# 按列合并到data数据
data = pd.concat([data, tfidf_df], axis=1)# 自然数编码
def label_encode(series):unique = list(series.unique())return series.map(dict(zip(unique, range(series.nunique()))))for col in cols:if data[col].dtype == 'object':data[col] = label_encode(data[col])train = data[data.Label.notnull()].reset_index(drop=True)
test = data[data.Label.isnull()].reset_index(drop=True)# 特征筛选
features = [f for f in train.columns if f not in ['uuid','Label','smiles_list']]# 构建训练集和测试集
x_train = train[features]
x_test = test[features]# 训练集标签
y_train = train['Label'].astype(int)
特征工程是构建一个良好的机器学习模型的关键步骤。有用的特征使得模型表现更好。
在这个特征工程中,使用了具有关键特征的简单模型,要想用最佳方式完成特征工程,必须对问题的领域有一定的了解,并且很大程度上取决于相关数据。
特征方程不仅仅是创建新特征,还包括不同类型的归一化和转换。
在这一段代码里,没有归一化流程,只有转换。
常见的归一化手段:
- Min-Max缩放
- Z-score标准化
- Robust缩放
而在这段代码里:
-
SMILES转换:使用RDKit库将数据集中的SMILES字符串转换回字符串的列表。这是特征工程的一部分:这是为了便于下一步特征的提取,SMILES可以使用TF-IDF计算方法。这是一种数据预处理的手段。
-
字符串处理:将SMILES字符串列表转换为单个字符串,每个SMILES之间用空格分隔。
-
TF-IDF计算:使用TfidfVectorizer从处理后的SMILES字符串创建TF-IDF特征矩阵,TF-IDF是一种词文本的统计学方法,用于统计词文本在文件中出现的频率,衡量该词条的重要程度。这是一种特征提取手段。
-
自然数编码:定义了一个函数
label_encode,将分类特征(对象类型)转换为整数编码。首先,它接受一个pandas Series作为输入,获取Series中的唯一值列表,然后创建一个字典,将每个唯一值映射到一个整数,最后使用这个字典将原始Series中的每个值映射到相应的整数。检测到object类型,就应用label_encode进行编码。这样的编码方式比较直观,同时符合需要顺序的特点。 -
特征和标签准备:对于所有的特征列(
cols),如果它们的数据类型是对象(通常表示为字符串),则应用自然数编码;从合并后的数据集中分离出训练集和测试集,其中训练集包含标签(Label),测试集不包含。 -
特征和标签的筛选:由于不需要uuid、Label和smiles_list,剔除并提取标签列。
-
数据类型转换:将Label转换为整数类型,便于训练。
模型训练与预测
def cv_model(clf, train_x, train_y, test_x, clf_name, seed=2022):kf = KFold(n_splits=5, shuffle=True, random_state=seed)train = np.zeros(train_x.shape[0])test = np.zeros(test_x.shape[0])cv_scores = []# 100, 1 2 3 4 5# 1 2 3 4 5# 1 2 3 5。 4# 1for i, (train_index, valid_index) in enumerate(kf.split(train_x, train_y)):print('************************************ {} {}************************************'.format(str(i+1), str(seed)))trn_x, trn_y, val_x, val_y = train_x.iloc[train_index], train_y[train_index], train_x.iloc[valid_index], train_y[valid_index]params = {'learning_rate': 0.1, 'depth': 6, 'l2_leaf_reg': 10, 'bootstrap_type':'Bernoulli','random_seed':seed,'od_type': 'Iter', 'od_wait': 100, 'allow_writing_files': False, 'task_type':'CPU'}model = clf(iterations=20000, **params, eval_metric='AUC')model.fit(trn_x, trn_y, eval_set=(val_x, val_y),metric_period=100,cat_features=[], use_best_model=True, verbose=1)val_pred = model.predict_proba(val_x)[:,1]test_pred = model.predict_proba(test_x)[:,1]train[valid_index] = val_predtest += test_pred / kf.n_splitscv_scores.append(f1_score(val_y, np.where(val_pred>0.5, 1, 0)))print(cv_scores)print("%s_score_list:" % clf_name, cv_scores)print("%s_score_mean:" % clf_name, np.mean(cv_scores))print("%s_score_std:" % clf_name, np.std(cv_scores))return train, testcat_train, cat_test = cv_model(CatBoostClassifier, x_train, y_train, x_test, "cat")pd.DataFrame({'uuid': test['uuid'],'Label': np.where(cat_test>0.5, 1, 0)}
).to_csv('submit.csv', index=None)
代码定义了一个名为cv_model的函数,用于交叉验证和预测。这段代码的核心是交叉验证和CatBoost训练模型。
K折交叉验证
交叉检验是评估模型性能的常用方法。交叉检验是使用训练数据集来训练模型,然后使用测试数据集来评估模型性能。*一轮交叉验证包括将数据样本划分为互补子集,对一个子集(称为训练集)执行分析,并在另一个子集(称为验证集或测试集)上验证分析结果。为了减少可变性,在大多数方法中,使用不同的分区执行多轮交叉验证,并且在这些回合中验证结果被组合(例如,平均)以估计最终的预测模型。(引自:维基百科)*作者使用了暂留集(hold-out set)这种方法:在一部分上训练模型,然后在另一部分上检查其性能。这也是交叉检验的一种。
选择正确的交叉检验取决于所处理的数据集。在一个数据集上适用的交叉检验并不一定就适合别的数据集。
有几种交叉检验技术最为流行和广泛使用:
-
k折交叉检验
-
分层k折交叉检验
-
留一交叉检验
-
分组k折交叉检验
交叉检验是将训练数据分层几个部分,在一部分上训练模型,在其余部分上测试。
得到一个数据集来构建机器学习模型时,可以把他们分为两个不同的集:训练集和验证集。训练集用来训练模型,验证集用来评估模型。实际上很多人会用第三个集:测试集,在下述代码中只使用两个集。
我们可以将数据分为k个互不关联的不同集合,即所谓的k折交叉验证。这样每一个不同的集合称为一个“褶皱”。
注意,交叉验证非常强大,几乎所有类型的数据集都可以使用此流程。
在本例Baseline里,Kfold进行了5折交叉验证。
CatBoost分类器训练模型
最大迭代次数是iterations=20000,eval_metric=‘AUC’,表示使用AUC作为评估指标。
AUC(Area Under the ROC Curve)是一种评价二分类模型性能的指标之一,ROC(Receiver Operating Characteristic)曲线是基于不同的分类阈值计算得出的,展示了在各种阈值下真阳性率(True Positive Rate,即召回率)和假阳性率(False Positive Rate)之间的权衡。
具体来说:
-
ROC 曲线:ROC 曲线是以假阳性率(FPR)为横轴,真阳性率(TPR)为纵轴绘制的曲线。在理想情况下,ROC 曲线应该尽量靠近左上角,表示在保持高真阳性率的同时,尽量低假阳性率。
-
AUC 值:AUC 值是 ROC 曲线下的面积,即 Area Under the ROC Curve。AUC 的取值范围在 0 到 1 之间,通常用来表示分类器的性能。AUC 值越大,说明模型在不同阈值下的性能越好。
接着,使用验证集val_x和val_y对模型进行评估,获取预测概率val_pred。
使用测试集test_x获取测试集预测概率test_pred。
F1_score(F1分数): F 1 = 2 ∗ T F 2 ∗ T F + F P + F N F1=\frac{2*TF}{2*TF+FP+FN} F1=2∗TF+FP+FN2∗TF,它是精确度和召回率的调和平均值,是衡量测试准确度的标准。可能的最高值为1,表示完美的精确度和召回率。
精准率(P,Precision):它用于衡量模型的查准性能,正确预测的样本中,预测为正的样本的比例。
召回率(R,Recall):它用于衡量模型的查全性能,预测为正的样本中,实际为正的样本的比例。
CatBoost 是一种高效的梯度提升算法(Gradient Boosting),专为处理分类特征和提高机器学习模型性能而设计。以下是 CatBoost 的主要特点和使用说明:
1. 梯度提升算法
CatBoost 属于梯度提升算法家族,通过迭代训练一组弱学习器(通常是决策树)来提高预测准确性。每一步都会根据前一步模型的错误来改进当前模型。
2. 处理分类特征
CatBoost 的一个显著优势是能够直接处理分类特征,无需将它们转换为数值形式(如独热编码)。CatBoost 采用了专门的技术来编码分类特征,简化了数据预处理过程,并且往往能提升模型性能。
3. 高性能
- 优化的计算效率:CatBoost 进行了许多优化,能够高效地进行梯度提升训练。
- 支持并行计算和 GPU 加速:CatBoost 支持多线程计算和 GPU 加速,能显著缩短训练时间。
4. 正则化
CatBoost 默认包含 L2 正则化等技术来防止模型过拟合,提高模型的泛化能力。
5. 兼容性
CatBoost 支持分类(如二分类、多分类)和回归任务。你可以在 CPU 或 GPU 上训练模型,适用于各种硬件配置。
CatBoost接收的主要的参数有最大迭代次数iterations,最大深度depth,学习率learning_rate(梯度学习算法中控制每棵树贡献的步长大小的参数,通常小于1),分类特征cat_features,它是一个用于指定哪些特征是分类变量的列表。CatBoost可以直接处理这些分类特征,而不依赖于数值转换。
相关文章:

【机器学习实战】Baseline精读笔记
比赛用到的库 numpy:提供(多维)数组操作 pandas:提供数据结构、数据分析 catboost:用于机器学习的库,特别是分类和回归任务 sklearn.model_selection:包含模型选择的多种方法,如交…...

Redis 缓存问题及解决
所有问题解决的关键就是尽少的访问数据库,或者避免太集中的访问。 一,缓存穿透(key在数据库不存在) 当数据既不在缓存中,也不在数据库中,导致请求访问缓存没数据,访问数据库也没数据,…...

RISC-V的历史与设计理念
指令集是什么? 如果把软件比作螺丝钉,硬件比作螺母,那么指令集架构就是螺丝钉与螺母的蓝图。我们需要根据蓝图设计可以匹配的螺丝钉与螺母。——包云岗老师 RISC-V的起源 以往比较流行的指令集:ARM,MIPS,X…...

山西车间应用LP-LP-SCADA系统的好处有哪些
关键字:LP-SCADA系统, 传感器可视化, 设备可视化, 独立SPC系统, 智能仪表系统,SPC可视化,独立SPC系统 LP-SCADA(监控控制与数据采集)系统是工业控制系统的一种,主要用于实时监控、控制和管理工业生产过程。 在车间应用LP-SCADA系统…...

setjmp和longjmp函数使用
这里用最简单直接的描述:这两组函数是用于实现类似vscode全局的标签跳转功能,setjmp负责埋下标签,longjmp负责标签跳转。 #include <stdio.h> #include <stdlib.h> #include <setjmp.h>jmp_buf envbuf1; jmp_buf envbuf2;…...
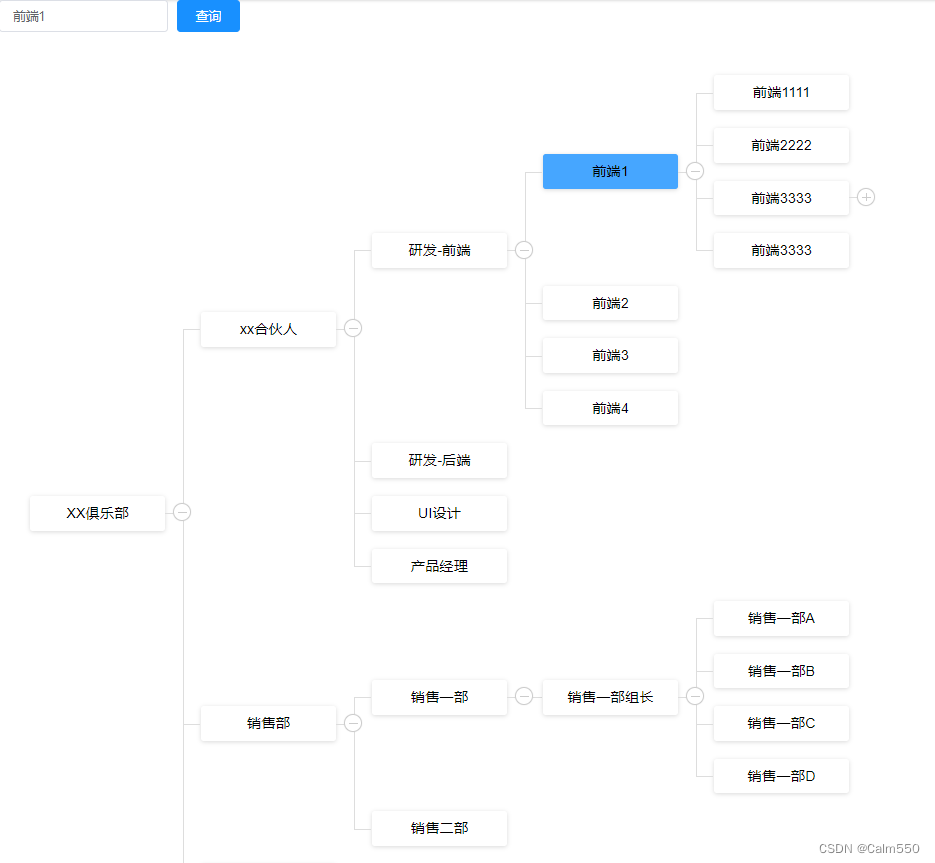
vue-org-tree搜索到对应项高亮展开
效果图: 代码: <template><div class"AllTree"><el-form :inline"true" :model"formInline" class"demo-form-inline"><el-form-item><el-input v-model"formInline.user&quo…...
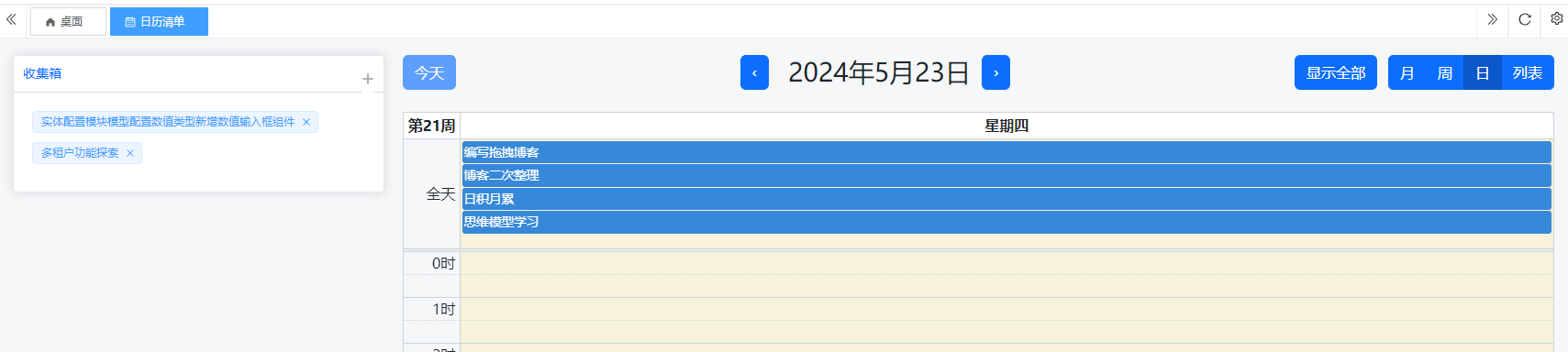
FullCalendar日历组件集成实战(17)
背景 有一些应用系统或应用功能,如日程管理、任务管理需要使用到日历组件。虽然Element Plus也提供了日历组件,但功能比较简单,用来做数据展现勉强可用。但如果需要进行复杂的数据展示,以及互动操作如通过点击添加事件࿰…...

【图像分割】mask2former:通用的图像分割模型详解
最近看到几个项目都用mask2former做图像分割,虽然是1年前的论文,但是其attention的设计还是很有借鉴意义,同时,mask2former参考了detr的query设计,实现了语义和实例分割任务的统一。 1.背景 1.1 detr简介 detr算是第…...
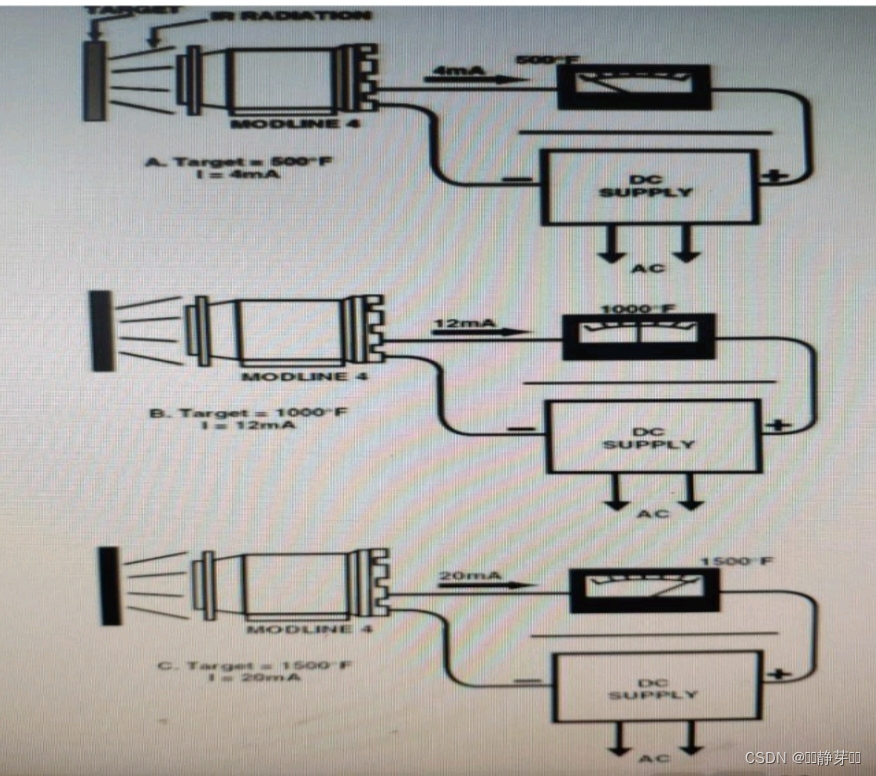
【不锈钢酸退作业区退火炉用高温辐射计快速安装】
项目名称 不锈钢酸退作业区退火炉用高温辐射计快速安装 改造实施项目简介项目提出前状况:不锈钢生产过程中,各种型号的不锈钢带钢在退火工艺中对带钢温度的准确性要求很高,带钢温度的检测直接影响带钢的产品质量,不锈钢带钢温度测量依靠的是高温辐射计,其测量的准确性、稳…...
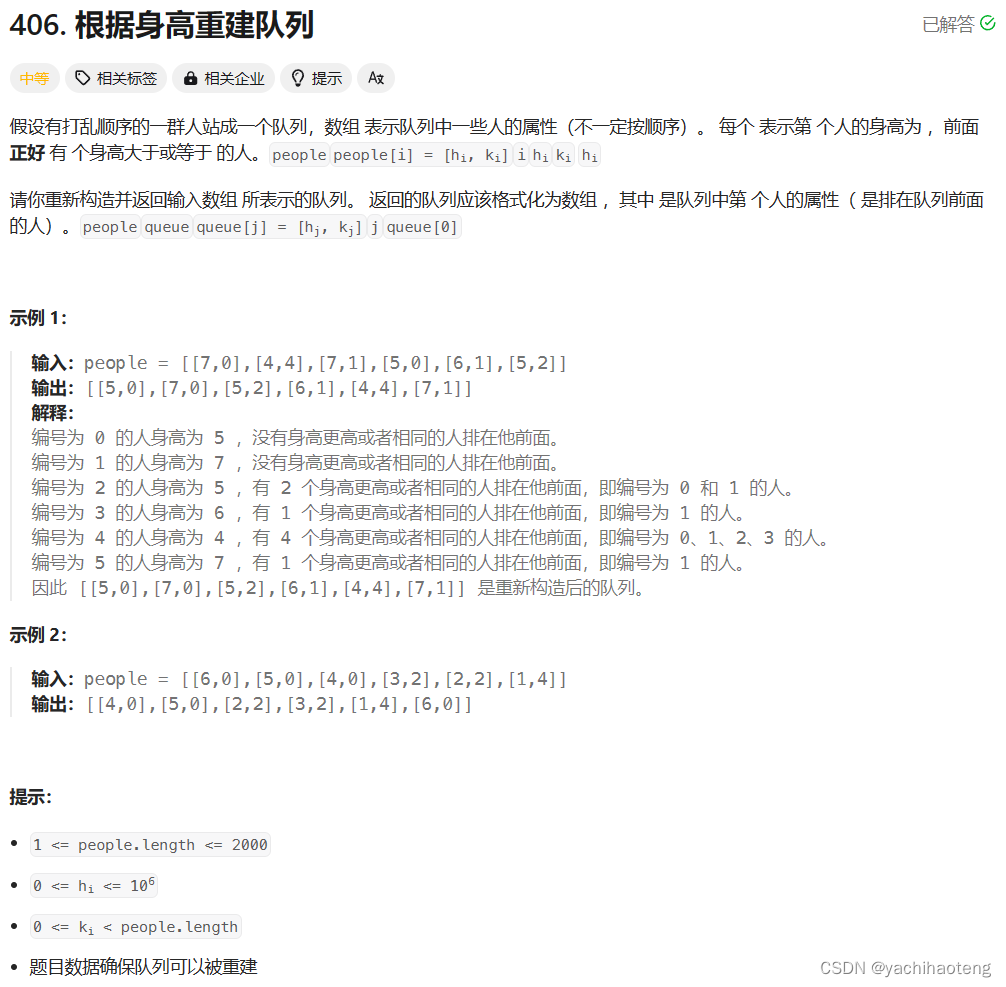
Studying-代码随想录训练营day29| 134. 加油站、135. 分发糖果、860.柠檬水找零、406.根据身高重建队列
第29天,贪心part03,快过半了(ง •_•)ง💪,编程语言:C 目录 134.加油站 135. 分发糖果 860.柠檬水找零 406.根据身高重建队列 134.加油站 文档讲解:代码随想录加油站 视频讲解:手撕加油站…...

Understanding Zero Knowledge Proofs (ZKP)
Bilingual Tutorial: Understanding Zero Knowledge Proofs (ZKP) 双语教程:理解零知识证明(ZKP) Introduction 介绍 English: Zero Knowledge Proofs (ZKP) are a fascinating concept in cryptography where one party (the prover) can…...

微信小程序 DOM 问题
DOM 渲染问题 问题 Dom limit exceeded, please check if theres any mistake youve made.测试页面 1 <template><scroll-view scroll"screen" style"width: 100%;height: 100vh;" :scroll-y"true" :scroll-with-animation"tru…...

可视化作品集(03):旅游景区的应用,美爆啦。
景区可视化通常指的是利用现代科技手段,如地图、虚拟现实(VR)、增强现实(AR)、无人机航拍等技术,将景区的地理信息、景点分布、交通路线、游客服务设施等内容以可视化的方式呈现给游客或者管理者࿰…...

嵌入式实时操作系统:Intewell操作系统与VxWorks操作系统有啥区别
Intewell操作系统和VxWorks操作系统都是工业领域常用的操作系统,它们各有特点和优势。以下是它们之间的一些主要区别: 架构差异: Intewell操作系统采用微内核架构,这使得它具有高实时性、高安全性和强扩展性的特点。微内核架构…...
PCDN技术如何提高内容分发效率?(壹)
PCDN技术提高内容分发效率的操作主要体现在以下几个方面: 利用P2P技术:PCDN以P2P技术为基础,通过挖掘利用边缘网络的海量碎片化闲置资源,实现内容的分发。这种方式可以有效减轻中心服务器的压力,降低内容传输的延迟&a…...

Java 中Json中既有对象又有数组的参数 如何转化成对象
1.示例一:解析一个既包含对象又包含数组的JSON字符串,并将其转换为Java对象 在Java中处理JSON数据,尤其是当JSON结构中既包含对象又包含数组时,常用的库有org.json、Gson和Jackson。这里我将以Gson为例来展示如何解析一个既包含对…...
)
什么是数据挖掘(python)
文章目录 1.什么是数据挖掘2.为什么要做数据挖掘?3数据挖掘有什么用处?3.1分类问题3.2聚类问题3.3回归问题3.4关联问题 4.数据挖掘怎么做?4.1业务理解(Business Understanding)4.2数据理解(Data Understanding&#x…...

【Tomcat】Linux下安装帆软(fineReport)服务器 Tomcat
需求:帆软(fineReport)数据集上传至服务器 工具:XSHELL XFTP 帮助文档 一. 安装帆软服务器Tomcat 提供 Linux X86 和 Linux ARM 两种类型的部署包 ,所以在下载部署钱需要确认系统架构不支持在 32 位操作系统上安装 查…...

C++ | Leetcode C++题解之第213题打家劫舍II
题目: 题解: class Solution { public:int robRange(vector<int>& nums, int start, int end) {int first nums[start], second max(nums[start], nums[start 1]);for (int i start 2; i < end; i) {int temp second;second max(fi…...

windows系统中快速删除node_modules文件
npx命令方式 npx rimraf node_modules 项目中设置 "scripts": {# 安装依赖"i": "pnpm install",# 检测可更新依赖"npm:check": "npx npm-check-updates",# 删除 node_modules"clean": "npx rimraf node_m…...

别再只把PCA当降维工具了!用Python+Sklearn实战服装标准与消费支出分析
解锁PCA的隐藏技能:用Python实战服装标准与消费支出分析当我们谈论主成分分析(PCA)时,大多数人首先想到的是"降维"——这个标签如此深入人心,以至于我们常常忽略了PCA作为"数据解释器"和"可视…...

2026年杭州靠谱的GEO优化公司,杭州这里通网络科技值得选择吗?
在数字化时代,企业越来越重视线上推广,GEO优化服务能有效提升企业在AI平台上的曝光和流量,因此很多企业关注靠谱的GEO优化公司。杭州这里通网络科技就是一家值得了解的企业。 ### 选择标准 技术能力:靠谱的GEO优化公司应具备强大…...

卖轴承怎么找客户?下游工厂在哪里
卖轴承找客户,本质是找用轴承的下游工厂,核心难点是拿到这些下游厂的名单和联系人。轴承是机械传动的通用基础件,消耗量大、采购频繁,但下游行业分散、各自聚集在不同产业带,如果没有系统盘过下游版图,销售…...

CVE-2017-17215实战复现:华为HG532路由器栈溢出漏洞深度解析
1. 这不是“打靶练习”,而是一次对嵌入式设备安全边界的实地测绘CVE-2017-17215这个编号,在漏洞数据库里只占一行,但在真实世界中,它曾让数百万台华为HG532系列家用路由器暴露在远程接管风险之下。我第一次在实验室复现它时&#…...

别再交智商税了!实测告诉你:用AI写论文,哪款软件控制重复率和AI率效果最好?
眼下毕业生和科研工作者的焦虑点很集中:论文查重率好不容易过关,AIGC疑似率却频频爆红;花了大把时间手动改写降AI痕迹,重复率又反弹回来。想靠普通工具同时守住查重和AI两道防线,根本就是天方夜谭。 事实上通用模型AI…...

QrazyBox终极指南:专业二维码修复工具拯救你的损坏二维码
QrazyBox终极指南:专业二维码修复工具拯救你的损坏二维码 【免费下载链接】qrazybox QR Code Analysis and Recovery Toolkit 项目地址: https://gitcode.com/gh_mirrors/qr/qrazybox 你是否曾因打印模糊、水渍污染或屏幕划痕导致的重要二维码无法扫描而焦急…...

通过 curl 命令快速测试 Taotoken 不同模型的对话效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过 curl 命令快速测试 Taotoken 不同模型的对话效果 在开发或调试大模型应用时,有时我们可能没有现成的 SDK 环境&am…...

机器学习势函数在暗物质探测中的应用:计算晶体缺陷存储能
1. 项目概述:当机器学习势函数遇上暗物质探测在粒子物理与凝聚态物理的交叉前沿,有一个看似微小却至关重要的物理细节,正困扰着新一代的暗物质与中微子探测实验:当一个来自宇宙的弱相互作用粒子(WIMP)或一个…...

Gofile极速下载器:3倍下载速度的完整指南
Gofile极速下载器:3倍下载速度的完整指南 【免费下载链接】gofile-downloader Download files from https://gofile.io 项目地址: https://gitcode.com/gh_mirrors/go/gofile-downloader 在数字时代,文件分享已成为日常工作的一部分,但…...

5分钟解锁Cursor Pro:免费使用AI编程助手的终极指南
5分钟解锁Cursor Pro:免费使用AI编程助手的终极指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your trial…...