深入浅出3D感知中的优化与基于学习的技术1(原创系列)
近期几乎看了所有有关NERF技术论文,本身我研究的领域不在深度学习技术方向,是传统的机器人控制和感知。所以总结了下这部分基于学习的感知技术,会写一个新的系列教程讲解这部分三维感知技术的发展到最新的技术细节,并支持自己最近的项目开发和论文。本系列禁止转载,有技术探讨可以发邮件给我 fanzexuan135@163.com
深入浅出3D感知中的优化与学习技术
1 引言
3D感知是计算机视觉和机器人领域的一个核心问题,旨在从2D图像恢复场景的3D结构和运动。它在自动驾驶、虚拟/增强现实、智能制造等许多领域有着广泛应用。传统的3D感知算法大多基于几何视觉的理论,通过精心建模和优化来求解相机位姿、场景结构等几何量。而近年来,深度学习的崛起为3D感知问题带来了新的思路和活力。本文将对3D感知中的经典优化方法和深度学习方法进行综述和对比,并重点介绍一些将二者结合的新进展,让读者对这一领域的基本概念和前沿成果有一个全面的了解。
2 将3D感知问题建模为优化问题
在3D感知的诸多任务中,如相机定位、稠密重建、非刚性形变估计等,我们面临的核心问题往往可以表述为一个优化问题:
min x ∈ X E ( x ; y ) ( 1 ) \min\limits_{x \in X} E(x; y) \qquad (1) x∈XminE(x;y)(1)
其中 y y y表示输入的观测数据(如一组图像),而 x x x表示我们感兴趣的几何量(如相机位姿、场景深度),构成了优化变量。 X X X表示 x x x的可行域,囊括了我们对 x x x已知的先验知识(如相机姿态必须是刚体变换)。 E ( x ; y ) E(x; y) E(x;y)是一个衡量 x x x与 y y y匹配程度的目标函数(或代价函数),可以分解为数据项和正则项两部分:
E ( x ; y ) = D ( x ; y ) + R ( x ) ( 2 ) E(x; y) = D(x; y) + R(x) \qquad (2) E(x;y)=D(x;y)+R(x)(2)
数据项 D ( x ; y ) D(x; y) D(x;y)度量了在当前估计 x x x下,观测数据 y y y的拟合/重投影误差,反映了 x x x对 y y y的解释能力。以双目立体匹配为例,若 y y y为左右两帧图像,而 x x x为像素的视差值,则数据项可以定义为:
D ( x ; y l , y r ) = ∑ p ρ ( y l ( p ) , y r ( p − [ x ( p ) , 0 ] T ) ) ( 3 ) D(x; y_l, y_r) = \sum_p \rho\Big( y_l(p), y_r\big(p - [x(p), 0]^T\big) \Big) \qquad (3) D(x;yl,yr)=p∑ρ(yl(p),yr(p−[x(p),0]T))(3)
其中 p p p遍历所有像素, ρ ( ⋅ ) \rho(\cdot) ρ(⋅)为某种颜色/梯度constancy误差度量。这个数据项的意义是:在估计的视差 x x x下,将左图 y l y_l yl的像素 p p p投影到右图 y r y_r yr,若视差正确,则左右图像的局部外观应该一致。
正则项 R ( x ) R(x) R(x)通常基于一些先验假设,对 x x x施加额外约束,鼓励解具有某些良好性质。以稠密重建为例,我们通常假设相邻像素的深度值是接近的(分段光滑),于是可以定义一个鼓励深度图光滑的正则项:
R ( x ) = ∑ p ∥ ∇ x ( p ) ∥ 1 ( 4 ) R(x) = \sum_p \|\nabla x(p)\|_1 \qquad (4) R(x)=p∑∥∇x(p)∥1(4)
其中 p p p遍历像素, ∇ x ( p ) \nabla x(p) ∇x(p)为深度图在 p p p处的梯度。
求解优化问题(1),得到的 x ∗ x^* x∗就是在观测数据 y y y下对真实几何量 x ^ \hat{x} x^的最大后验估计(MAP):
x ∗ = arg max x P ( x ∣ y ) = arg max x P ( y ∣ x ) P ( x ) ( 5 ) x^* = \arg\max_x P(x|y) = \arg\max_x P(y|x) P(x) \qquad (5) x∗=argxmaxP(x∣y)=argxmaxP(y∣x)P(x)(5)
换言之,优化求解的过程可以看作是在先验( R ( x ) R(x) R(x))和似然( D ( x ; y ) D(x; y) D(x;y))之间寻求平衡,得到后验概率最大的估计值。
当目标函数是凸的,且其梯度/Hessian矩阵容易计算时,优化问题可以用牛顿法、高斯牛顿法、梯度下降等经典算法有效求解。然而,3D感知问题的目标函数往往是高度非线性和非凸的,优化变量 x x x所在的空间(如李群流形SE(3))也可能是非欧的,这给问题的求解带来很大挑战。
3 经典的优化算法及其局限性
针对非线性最小二乘型的3D感知问题,高斯牛顿法是最常用的优化算法。它在当前估计点 x k x_k xk处,对目标函数 E ( x ) E(x) E(x)做二阶泰勒展开:
E ( x ) ≈ E ( x k ) + J ( x k ) Δ x + 1 2 Δ x T H ( x k ) Δ x ( 6 ) E(x) \approx E(x_k) + J(x_k) \Delta x + \frac{1}{2} \Delta x^T H(x_k) \Delta x \qquad (6) E(x)≈E(xk)+J(xk)Δx+21ΔxTH(xk)Δx(6)
其中 J ( x k ) = ∂ E ∂ x ∣ x = x k J(x_k) = \frac{\partial E}{\partial x}|_{x=x_k} J(xk)=∂x∂E∣x=xk为 E E E在 x k x_k xk处的Jacobian矩阵, H ( x k ) = ∂ 2 E ∂ x 2 ∣ x = x k ≈ J ( x k ) T J ( x k ) H(x_k) = \frac{\partial^2 E}{\partial x^2}|_{x=x_k} \approx J(x_k)^T J(x_k) H(xk)=∂x2∂2E∣x=xk≈J(xk)TJ(xk)为近似的Hessian矩阵。高斯牛顿法通过求解如下线性方程来生成更新步长 Δ x k \Delta x_k Δxk:
H ( x k ) Δ x k = − J ( x k ) T r ( x k ) ( 7 ) H(x_k) \Delta x_k = -J(x_k)^T r(x_k) \qquad (7) H(xk)Δxk=−J(xk)Tr(xk)(7)
其中 r ( x k ) : = D ( x ; y ) ∣ x = x k r(x_k) := D(x; y)|_{x=x_k} r(xk):=D(x;y)∣x=xk为数据项的残差。然后用 Δ x k \Delta x_k Δxk更新当前估计:
x k + 1 = x k ⊞ Δ x k ( 8 ) x_{k+1} = x_k \boxplus \Delta x_k \qquad (8) xk+1=xk⊞Δxk(8)
直到 Δ x k \Delta x_k Δxk足够小。这里的 ⊞ \boxplus ⊞表示在流形空间(如SE(3))上的加法。注意 ( 7 ) (7) (7)是个高维稀疏线性系统,可用Cholesky分解或预条件共轭梯度等方法高效求解。
当目标函数局部可以很好地用二次函数近似时,高斯牛顿法具有二阶收敛速度。然而它也有一些局限性:
-
在最优解附近,目标函数的Hessian阵必须是正定的,否则 ( 7 ) (7) (7)不保证有解。
-
Jacobian矩阵 J ( x k ) J(x_k) J(xk)中的某些项可能在数值上或理论上难以定义/求导,如光度误差对姿态变量的导数。
-
算法容易停留在局部极小值,缺乏全局视野。
-
若目标函数含有非光滑的正则项(如 L 1 L_1 L1范数),则Jacobian在奇异点不存在。
一些改进的优化技术如Levenberg-Marquardt方法通过信赖域策略缓解了正定性问题,但其它问题仍然存在。
为了增强鲁棒性,人们常常在数据项中使用截断二次等M估计函数,降低异常值的影响。但这些非凸函数也使得优化更加困难,可能需要更复杂的启发式或全局优化策略。
4 基于深度学习的端到端方法
与经典建模范式不同,深度学习采用了一种数据驱动的端到端方法。其基本思想是:收集一个有代表性的数据集 D = { ( y i , x i ∗ ) } i = 1 N \mathcal{D}=\{(y_i, x_i^*)\}_{i=1}^N D={(yi,xi∗)}i=1N,其中 y i y_i yi为输入图像, x i ∗ x_i^* xi∗为图像对应的ground truth几何参数(如深度图、光流场等)。然后训练一个深层神经网络 f θ : y ↦ x f_\theta: y \mapsto x fθ:y↦x,其参数 θ \theta θ通过最小化如下经验风险而学习得到:
L ( θ ) = ∑ i = 1 N l ( f θ ( y i ) , x i ∗ ) ( 9 ) \mathcal{L}(\theta) = \sum_{i=1}^N l\big(f_\theta(y_i), x_i^*\big) \qquad (9) L(θ)=i=1∑Nl(fθ(yi),xi∗)(9)
其中 l ( ⋅ ) l(\cdot) l(⋅)为某种loss函数,如 L 1 / L 2 L_1/L_2 L1/L2 loss。这一范式的优点是:
-
端到端可微分,不需要人工提取特征或设计目标函数/优化策略。只要定义合适的网络结构和loss函数,就可以从数据中自动学习复杂的映射。
-
前向推断速度快,可满足实时性需求。
-
可迁移性好。从一个场景学到的泛化能力可迁移到新场景。
以单目深度估计为例,Eigen等[1]首次将CNN应用于该任务。他们在网络的encoder中使用了两个并行的VGG分支分别提取全局和局部特征,decoder采用多尺度架构,在4个spatial resolution下估计深度,并对深度图施加了尺度不变loss和平滑loss。Laina等[2]提出了更深的ResNet架构,并引入了反距离的Berhu loss,取得了更好的效果。
对于光流估计,FlowNet[3]首次证明了深度回归在该任务上的有效性。后续的FlowNet2[4]引入了级联和迭代细化,大幅提升了估计精度。RAFT[5]从另一角度解决该问题,巧妙地将经典的优化过程与深度特征提取相结合,可以看作本文后面要重点介绍的一类混合方法。
尽管深度学习取得了瞩目成绩,但纯端到端的黑盒回归也有其局限性:
-
缺乏对几何和物理规律的显式建模,纯数据驱动的学习有时不够稳定,容易受domain gap影响。
-
需要大量paired数据做监督训练,在许多3D感知任务上难以获得,labeled数据的稀缺限制了模型的表现。
-
不可解释和可控。学习到的映射高度复杂,缺乏可解释性。网络的预测结果不能保证满足一些几何约束。
因此,如何将基于物理的归纳偏置与深度学习的表达能力相结合,已成为新的研究热点。
5 将深度学习嵌入优化过程
一类有前景的混合方法是将深度学习嵌入到传统优化过程中,形成"可学习"、"可微分"的复合层。这类方法在经典优化算法的框架下,用学习的模块替代手工设计的某些部分(如能量/梯度的计算),并端到端训练整个系统。RAFT[5]是这一思想在光流估计任务上的代表作。
与FlowNet等直接回归光流场的方法不同,RAFT明确建模了光流估计中的迭代优化过程。记 I 1 , I 2 \mathcal{I}_1, \mathcal{I}_2 I1,I2为输入的两帧图像,网络的目标是学习一个映射:
f 1 , f 2 , … , f N = R A F T ( I 1 , I 2 ) ( 10 ) f_1, f_2, \dots, f_N = \mathrm{RAFT}(\mathcal{I}_1, \mathcal{I}_2) \qquad (10) f1,f2,…,fN=RAFT(I1,I2)(10)
其中 f k ∈ R H × W × 2 f_k \in \mathbb{R}^{H \times W \times 2} fk∈RH×W×2为第 k k k次迭代估计的光流场。具体来说,RAFT包含三个关键组件:
(1) 特征提取网络,用CNN从输入图像中提取高层特征:
F 1 = F e a t u r e E n c o d e r ( I 1 ) , F 2 = F e a t u r e E n c o d e r ( I 2 ) ( 11 ) \mathbf{F}_1 = \mathrm{FeatureEncoder}(\mathcal{I}_1), \quad \mathbf{F}_2 = \mathrm{FeatureEncoder}(\mathcal{I}_2) \qquad (11) F1=FeatureEncoder(I1),F2=FeatureEncoder(I2)(11)
(2) 相关体计算模块,基于当前估计的光流场 f k f_k fk和特征 F 1 , F 2 \mathbf{F}_1, \mathbf{F}_2 F1,F2构造一个4D相关体:
C k = C o m p u t e C o r r e l a t i o n ( f k , F 1 , F 2 ) ( 12 ) \mathbf{C}_k = \mathrm{ComputeCorrelation}(f_k, \mathbf{F}_1, \mathbf{F}_2) \qquad (12) Ck=ComputeCorrelation(fk,F1,F2)(12)
直观上, C k [ i , j , p , q ] \mathbf{C}_k[i, j, p, q] Ck[i,j,p,q]度量了以 f k [ i , j ] f_k[i, j] fk[i,j]为中心的 I 1 \mathcal{I}_1 I1局部patch与 I 2 \mathcal{I}_2 I2中对应patch的相似性。这一步可以看作传统优化方法中计算匹配代价的过程。
(3) GRU更新单元,迭代细化光流估计:
h k + 1 , f k + 1 = G R U U p d a t e ( f k , h k , C k ) ( 13 ) h_{k+1}, f_{k+1} = \mathrm{GRUUpdate}(f_k, h_k, \mathbf{C}_k) \qquad (13) hk+1,fk+1=GRUUpdate(fk,hk,Ck)(13)
其中 h k h_k hk是隐藏状态, f k + 1 f_{k+1} fk+1是细化后的光流场。这一步可以看作传统优化中的梯度下降更新。但与手工设计的梯度不同,这里的更新方向由数据驱动学习得到。
整个RAFT网络是端到端可训练的,所有参数都通过最小化预测光流场 f N f_N fN与GT光流场 f ∗ f^* f∗的差异来学习:
L ( θ ) = ∑ i = 1 M ∥ f N ( i ) − f ∗ ( i ) ∥ 1 ( 14 ) \mathcal{L}(\theta) = \sum_{i=1}^M \|f_N^{(i)} - f^{*(i)}\|_1 \qquad (14) L(θ)=i=1∑M∥fN(i)−f∗(i)∥1(14)
RAFT的优点在于,它将学习的连续warp和相关计算嵌入到每一步的迭代更新中,而非单纯堆叠卷积层,赋予了网络更强的归纳偏置。同时,显式建模迭代过程也使得网络更加可解释。实验表明,这一混合范式在准确性和泛化性方面都优于纯端到端的回归方法。
类似地,BA-Net[6]以及LM-Reloc[7]将深度学习引入SLAM后端优化中。它们用学习的网络模块替代了传统的 bundle adjustment (BA) 流程中的某些手工设计部分,如:
(1) 在Pose-Graph优化中,用GNN预测每条边的信息矩阵,作为Mahalanobis距离的权重[6];
(2) 在特征点BA中,用CNN预测每对匹配的置信度,作为Huber损失的权重[7]。
这些学习的模块可以看作是传统目标函数的"插件",使优化过程更加自适应和数据驱动。实验表明,嵌入学习模块的SLAM系统在准确性、鲁棒性方面都有明显提升。
6 将优化嵌入深度学习
与上一节"learning in optimization"的思路互补,另一类混合范式是将优化模块嵌入到深度网络中,形成端到端可训练的"可微分优化层"。这类方法用可微分的优化层(用内部迭代求解一个隐式函数)替代网络中的某些前馈层,使网络输出自动满足一些硬约束。
以经典的PnP问题为例,已知一组3D点 { X i } \{\mathbf{X}_i\} {Xi}在世界坐标系下的坐标和它们在相机中的2D投影 { x i } \{\mathbf{x}_i\} {xi},估计相机的位姿 T ∈ S E ( 3 ) \mathbf{T} \in \mathrm{SE}(3) T∈SE(3)。传统的DLT、P3P等解法先建立目标函数:
E ( T ) = ∑ i = 1 N ∥ π ( T X i ) − x i ∥ 2 ( 15 ) E(\mathbf{T}) = \sum_{i=1}^N \|\pi(\mathbf{T}\mathbf{X}_i) - \mathbf{x}_i\|^2 \qquad (15) E(T)=i=1∑N∥π(TXi)−xi∥2(15)
其中 π : P 3 → P 2 \pi: \mathbb{P}^3 \to \mathbb{P}^2 π:P3→P2为相机投影模型。然后用SVD或Ransac求解一个闭式解 T ∗ = arg min T E ( T ) \mathbf{T}^* = \arg\min_{\mathbf{T}} E(\mathbf{T}) T∗=argminTE(T)。
DSAC[8]提出了一种可微分的RANSAC层,可以集成到任意网络中用于PnP估计。该层将传统RANSAC的采样、模型估计和评价过程公式化为可微分的操作,关键是将假设模型的评价函数softmax化:
s i = exp ( − E ( T i ) / τ ) ∑ j exp ( − E ( T j ) / τ ) ( 16 ) s_i = \frac{\exp(-E(\mathbf{T}_i)/\tau)}{\sum_{j} \exp(-E(\mathbf{T}_j)/\tau)} \qquad (16) si=∑jexp(−E(Tj)/τ)exp(−E(Ti)/τ)(16)
其中 τ \tau τ为温度参数。DSAC层的输出是加权的假设集合:
T ∗ = ∑ i s i T i , s.t. ∑ i s i = 1 ( 17 ) \mathbf{T}^* = \sum_{i} s_i \mathbf{T}_i, \quad \text{s.t.} \sum_{i} s_i = 1 \qquad (17) T∗=i∑siTi,s.t.i∑si=1(17)
DSAC层可以插入到任意2D-3D匹配网络中,使网络输出的匹配自动满足PnP约束。实验表明,这种端到端的可微分求解范式可以明显提高姿态估计的精度,且节省后处理时间。
类似地,一些工作将ICP[9]、特征匹配[10]、mesh简化[11]等传统几何任务重构为可微分层,嵌入到深度网络中,实现几何约束感知的端到端学习。
参考文献:
[1] Eigen D, Puhrsch C, Fergus R. Depth map prediction from a single image using a multi-scale deep network[J]. NeurIPS, 2014.
[2] Laina I, Rupprecht C, Belagiannis V, et al. Deeper depth prediction with fully convolutional residual networks[C]//3DV. IEEE, 2016.
[3] Dosovitskiy A, Fischer P, Ilg E, et al. Flownet: Learning optical flow with convolutional networks[C]//ICCV, 2015.
[4] Ilg E, Mayer N, Saikia T, et al. Flownet 2.0: Evolution of optical flow estimation with deep networks[C]//CVPR, 2017.
[5] Teed Z, Deng J. RAFT: Recurrent all-pairs field transforms for optical flow[C]//ECCV, 2020.
[6] Tang C, Tan P. BA-Net: Dense bundle adjustment network[J]. arXiv, 2018.
[7] Wei Y, Liu S, Zhao W, et al. Deepsfm: Structure from motion via deep bundle adjustment[C]//ECCV, 2020.
[8] Brachmann E, Krull A, Nowozin S, et al. DSAC-differentiable RANSAC for camera localization[C]//CVPR, 2017.
[9] Wang Y, Solomon J M. Deep closest point: Learning representations for point cloud registration[C]//ICCV, 2019.
[10] Zhang J, Sun D, Luo Z, et al. Learning two-view correspondences and geometry using order-aware network[C]//ICCV, 2019.
[11] Hanocka R, Hertz A, Fish N, et al. MeshCNN: a network with an edge[J]. ACM TOG, 2019.
7 基于优化与学习的混合范式
7.1 引入物理约束和先验知识
将物理规律、几何约束等先验知识纳入深度学习pipeline,是混合范式的一个关键优势。这不仅可以提高模型输出的几何一致性和物理合理性,还能降低模型对label数据的依赖。那么如何设计高效、通用的约束编码和融合机制呢?
一种思路是将约束显式地嵌入loss函数中。如Pixel2Mesh[1]在mesh变形的同时,加入了拉普拉斯loss和法向loss,鼓励相邻顶点的位置和法向保持局部一致。SDFDIFF[2]在用SDF表示形状时,设计了Eikonal loss L E = ∫ Ω ( ∣ ∇ f ( x ) ∣ − 1 ) 2 d x \mathcal{L}_E=\int_\Omega (|\nabla f(\mathbf{x})|-1)^2\mathrm{d}\mathbf{x} LE=∫Ω(∣∇f(x)∣−1)2dx,鼓励SDF满足 i s o \mathrm{iso} iso-surface的性质。
另一思路是将约束隐式地嵌入网络结构中。如Shen等[3]在点云配准中,用一个预训练的网络估计两组点之间的软对应,再用 S V D \mathrm{SVD} SVD求解最优刚体变换,从而将 S E ( 3 ) \mathrm{SE}(3) SE(3)流形约束融入前向传播。RAFT[4]用相关体搜索匹配,用GRU迭代更新optical flow,从而将光流平滑性、small displacement等先验隐式地编码入网络计算图。
此外,还可将约束直接纳入输入和输出表示中。如 NeuralSym[5] 用球谐函数(SPHARM)表示物体形状,从而显式建模物体的拓扑和对称性。Gao等[6]发现用黎曼度量等内蕴表示取代欧式表示,可使网络更好地适应非欧流形(如旋转群 S O ( 3 ) \mathrm{SO(3)} SO(3))。
7.2 降低对label数据的依赖
大量的label数据对于监督深度学习至关重要,但在许多3D感知任务中,精确的逐点标注非常困难。因此,如何最大限度地利用无监督和弱监督信号,来指导深度网络学习更加鲁棒和可泛化的表示,成为一个重要课题。
合理利用数据本身蕴含的某些不变性,是构建自监督loss的重要手段。一个典型例子是对极几何约束:从不同视角观测同一个刚体,任意匹配点的深度值应满足对极方程。基于这一原理,Zhou等[7]联合训练两个CNN分别估计单目深度和相机姿态,并设计loss监督二者的一致性,实现了仅需monocular视频的深度自监督学习。
多模态感知也为弱监督学习开辟了新路径。投影laser点提供的稀疏深度能为image depth估计构建有力的监督信号[8];而在缺乏audio-visual pair的情况下,音频和视频互为表征空间,音频事件和视觉目标的同步性能为它们构建弱监督[9]。
此外,知识的迁移和先验的编码也能降低学习难度。如 D O N \mathrm{DON} DON[10]将ShapeNet上预训练的object detector迁移到KITTI数据,仅用很少的label数据微调,就实现了高精度的outdoor 3D检测。Neural Point Descriptor[11]基于可区分性、平滑性、局部一致性等先验,无监督地学习了一个通用、紧致的3D点云描述子表示。
7.3 提高系统的泛化性和适应性
现实世界的视觉环境千差万别,数据分布也呈现多样性(multi-modality)。因此,如何确保算法能够适应不同的场景、传感器和外部条件,是3D感知落地应用必须考虑的问题。现有的一些研究思路包括:
(1) 基于元学习的快速自适应。Finn等[12]提出MAML算法,通过二次梯度下降学习一个对不同任务都有良好初始化的meta-learner,从而实现少样本条件下的快速finetune。类似思想也被用于6D位姿估计[13]、深度估计[14]等任务的domain adaptation中。
(2) 不变特征表示学习。Cohen等[15]利用群等变性,设计了对SO(3)旋转不变的spherical CNN,使学习到的3D形状描述子具有更好的泛化能力。Zhu等[16]用cycle-consistency loss实现了跨模态(如CT-X光)医学图像的迁移,学到了对成像原理不变的语义特征。
(3) 持续学习与渐进优化。Dai等[17]提出渐进网络,在连续的优化域上学习网络权重,避免在新样本到来时catastrophic forgetting。VASE[18]引入外显记忆模块,实现了open-set的语义场景理解。
(4) 主动学习与探索。Chaplot等[19]让agent主动探索周围环境并搜集hard samples,再将其用于导航策略学习,实现了indoor navigation任务的自我强化。Luo等[20]提出主动多视图深度估计,学习next-best-view并动态重建,在固定预算下提高深度图的精度和完整性。
7.4 提高模型的可解释性和可控性
深度学习模型常被比作"黑盒",内部工作机制难以洞察,这在一定程度上阻碍了其在自动驾驶等高安全性要求场合的应用。有鉴于此,AI可解释性、可控性研究受到学界和业界的高度重视。在3D感知领域,一些有益的尝试包括:
(1) 显式编码高层语义概念。3D-RCNN[21]在两阶段检测框架中引入orientation anchor,将物体的朝向显式地建模到网络中,在提高精度的同时,输出也更符合人的直觉。Han等[22]提出将场景组织为物体-关系图,并用GCN建模推理其中的语义,使基于图的3D重建更加可解释。
(2) 模仿人类的感知推理过程。投射3D模型到2D,再回归6D位姿[23];或者先粗略估计物体的3D包围盒,再迭代优化[24],都是在网络的计算过程中模仿人类"从粗到精分解子任务"的认知习惯。类似地,Neural-Sym[5]通过显式建模视图间和物体内的对称关系,模仿人类对物体形状的感知。
(3) 对抗性学习增强网络鲁棒性。Xiao等[25]发现,添加物理上合理的random perturbation(如小幅度旋转平移),可使PointNet等3D分类网络产生错误预测。为此,他们提出对抗性训练和r-max pooling等策略,增强网络应对形变的能力。Zeng等[26]研究了移动机器人中传感器和运动规划模块的"协同对抗",揭示了其内部机理。
(4) 后修正与自我纠错。Hu等[27]提出gradslam,学习一个RNN,在SLAM过程中接收未来观测,主动返回过去重新优化历史帧的位姿。这种"后知后觉"(hindsight)的反复修正机制,使SLAM系统更接近人脑的思维过程。Liao等[28]在VO pipeline后附加一个correction network,显式地估计前一阶段pose的不确定性并订正,可视为自我纠错的一种形式。
7.5 拓展应用场景
除了3D感知,混合优化-学习范式在其他需要求解复杂逆问题的领域也有广阔的应用前景。它可以用于学习加速物理模拟[29]、drug discovery中的分子优化[30]、机器人强化学习中的运动规划[31]等。这也为3D感知和其他AI领域的cross-fertilization提供了新的可能。
尽管基于优化的传统3D感知方法和基于学习的新兴方法各有所长,但它们在求解相同问题时往往是互补的。将二者有机融合、协同优化,对于开发更加鲁棒、高效、可解释的3D感知系统至关重要。
这一节的技术还在不断探索,参考了如下论文
参考文献:
[1] Wang N, Zhang Y, Li Z, et al. Pixel2mesh: Generating 3d mesh models from single rgb images[C]//ECCV 2018.
[2] Jiang Y, Ji D, Han Z, et al. Sdfdiff: Differentiable rendering of signed distance fields for 3d shape optimization[C]//CVPR 2020.
[3] Shen W, Zhang B, Huang S, et al. Learning-based Optimization for Robust Registration of Point Clouds[J]. arXiv preprint arXiv:2103.05858, 2021.
[4] Teed Z, Deng J. RAFT: Recurrent all-pairs field transforms for optical flow[C]//ECCV 2020.
[5] Hosseinzadeh M, Li K, Latif Y, et al. Neural-Sym: Learning to Generate Symbolic 3D Shapes from 2D Images[J]. arXiv preprint arXiv:2106.00722, 2021.
[6] Gao R, Xie J, Zhang M, et al. Learning canonical pose and viewpoint for object categories in the wild[J]. arXiv preprint arXiv:2109.00106, 2021.
[7] Zhou T, Brown M, Snavely N, et al. Unsupervised learning of depth and ego-motion from video[C]//CVPR 2017.
[8] Ma F, Cavalheiro G V, Karaman S. Self-supervised sparse-to-dense: Self-supervised depth completion from lidar and monocular camera[C]//ICRA 2019.
[9] Yang Z, Shi D, Jain S, et al. Lane[C]//ICASSP 2021.
[10] Qi C R, Liu W, Wu C, et al. Frustum pointnets for 3d object detection from rgb-d data[C]//CVPR 2018.
[11] Elbaz G, Avraham T, Fischer A. 3d point cloud registration for localization using a deep neural network auto-encoder[C]//CVPR 2017.
[12] Finn C, Abbeel P, Levine S. Model-agnostic meta-learning for fast adaptation of deep networks[C]//ICML 2017.
[13] Xiang Y, Schmidt T, Narayanan V, et al. Posecnn: A convolutional neural network for 6d object pose estimation in cluttered scenes[J]. RSS, 2018.
[14] Tonioni A, Rahnama O, Joy T, et al. Learning to adapt for stereo[C]//CVPR 2019.
[15] Cohen T S, Geiger M, Koehler J, et al. Spherical cnns[J]. ICLR, 2018.
[16] Zhu J Y, Zhang R, Pathak D, et al. Toward multimodal image-to-image translation[J]. NeurIPS, 2017.
[17] Dai X, Yang G, Chen X, et al. Progressive Self-Supervised Representation Learning for Skeleton-Based Action Recognition[J]. IEEE Trans. Multimedia, 2021.
[18] Gül S, Abolghasemi M, Bätz M, et al. Vase: A new approach for video-based active speaker detection[J]. arXiv preprint arXiv:2105.09897, 2021.
[19] Chaplot D S, Gandhi D, Gupta S, et al. Learning to explore using active neural slam[J]. arXiv preprint arXiv:2004.05155, 2020.
[20] Luo K, Guan T, Ju L, et al. Learning-based Automatic Reconstruction of 3D Models from Real-World Images[J]. arXiv preprint arXiv:2103.14098, 2021.
[21] Kundu A, Li Y, Rehg J M. 3d-rcnn: Instance-level 3d object reconstruction via render-and-compare[C]//CVPR 2018.
[22] Han Z, Wang X, Vong C M, et al. 3DViewGraph: learning global features for 3d shapes from a graph of unordered views with attention[C]//ICLR 2019.
[23] Xiang Y, Schmidt T, Narayanan V, et al. Posecnn: A convolutional neural network for 6d object pose estimation in cluttered scenes[J]. RSS, 2018.
[24] Kehl W, Manhardt F, Tombari F, et al. SSD-6D: Making rgb-based 3d detection and 6d pose estimation great again[C]//ICCV 2017.
[25] Xiao C, Yang J, Li B, et al. Generating adversarial point clouds in 3D[J]. arXiv preprint arXiv:2101.11589, 2021.
[26] Zeng A, Feng Z, Zhang H, et al. Adversarial Feature Learning for Collaborative Motion Prediction[J]. arXiv preprint arXiv:2109.06467, 2021.
[27] Hu Y, Luo Z, Wang X, et al. GradSLAM: Dense SLAM Meets Automatic Differentiation[J]. IEEE Trans. Robot., 2021.
[28] Liao Z, Ji X, Wang W, et al. DNET: A deep network for correcting the correspondence of visual odometry[J]. arXiv pre
相关文章:
)
深入浅出3D感知中的优化与基于学习的技术1(原创系列)
近期几乎看了所有有关NERF技术论文,本身我研究的领域不在深度学习技术方向,是传统的机器人控制和感知。所以总结了下这部分基于学习的感知技术,会写一个新的系列教程讲解这部分三维感知技术的发展到最新的技术细节,并支持自己最近…...

【CentOS 7 上安装 Oracle JDK 8u333】
文章目录 下载 Oracle JDK 8u333:上传 RPM 包到服务器安装 Oracle JDK设置 JAVA_HOME 环境变量验证 下载 Oracle JDK 8u333 访问 https://www.oracle.com/java/technologies/javase/javase8-archive-downloads.html 找到 JDK 8u333 版本,并下载适用于 L…...
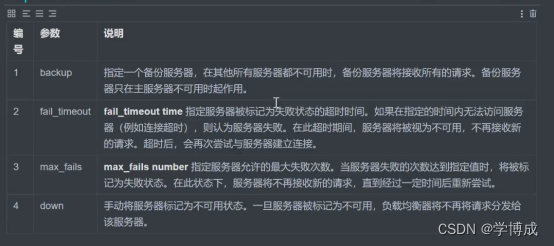
Nginx 常用配置与应用
Nginx 常用配置与应用 官网地址:https://nginx.org/en/docs/ 目录 Nginx 常用配置与应用 Nginx总架构 正向代理 反向代理 Nginx 基本配置反向代理案例 负载均衡 Nginx总架构 进程模型 正向代理 反向代理 Nginx 基本配置反向代理案例 负载均衡 Nginx 基本配置…...

基于Springboot的智慧养老中心管理系统
文章目录 项目介绍主要功能截图:部分代码展示设计总结项目获取方式🍅 作者主页:超级无敌暴龙战士塔塔开 🍅 简介:Java领域优质创作者🏆、 简历模板、学习资料、面试题库【关注我,都给你】 🍅文末获取源码联系🍅 项目介绍 基于Springboot的智慧养老中心管理系统,…...

数据结构笔记第3篇:双向链表
1、双向链表的结构 注意:这里的 "带头" 跟前面我们说的 "头结点" 是两个概念,实际前面的在单链表阶段称呼不严谨,但是为了同学们更好的理解就直接称为单链表的头结点。 带头链表里的头结点,实际为 "哨兵…...

详细对比Java SPI、Spring SPI 和 Dubbo SPI
SPI(Service Provider Interface)概述 定义:SPI是一种动态替换发现机制,用于实现接口与实现的解耦,提高框架的可扩展性。核心思想:解耦和方便扩展。 Java SPI 约定规范: 扩展类文件放在META-…...

CPU的核心数和线程数
CPU的核心数和线程数 一、关系: 1、线程数可以模拟出不同的CPU核心数。 CPU的核心数指的是硬件上存在着几个核心,而线程数可以模拟出多个核心数的功能。线程数越多,越有利于同时运行多个程序,因为线程数等同于在某个瞬间CPU能同…...
电脑游戏录屏,3款实用软件推荐给你
在电竞游戏热潮席卷全球的今天,电脑游戏录屏早已不再是简单的画面捕捉,它成为了记录电竞风采、打造专属游戏记忆的重要手段。通过游戏录屏,我们可以定格游戏中的精彩瞬间,重温那些令人热血沸腾的电竞时刻。那么,在进行…...

C#桌面应用开发:番茄定时器
C#桌面应用开发:番茄定时器 1、环境搭建和工程创建: 步骤一:安装visual studio2022 步骤二:新建工程 2、制作窗体部件 *踩过的坑: (1)找不到工具箱控件,现象如下:…...
PHP智慧门店微信小程序系统源码
🔍【引领未来零售新风尚】🔍 🚀升级启航,智慧零售新篇章🚀 告别传统门店的束缚,智慧门店v3微信小程序携带着前沿科技与人性化设计,正式启航!这个版本不仅是对过往功能的全面优化&a…...
SerDes介绍以及原语使用介绍(2)OSERDESE2原语仿真
文章目录 前言一、SDR模式1.1、设计代码1.2、testbench代码1.3、仿真分析 二、DDR模式下2.1、设计代码2.2、testbench代码2.3、仿真分析 三、OSERDES2级联3.1、设计代码3.2、testbench代码3.3、代码分析 前言 上文通过xilinx ug471手册对OSERDESE有了简单的了解,接…...

【稳定检索/投稿优惠】2024年教育、人文发展与艺术国际会议(EHDA 2024)
2024 International Conference on Education, Humanities Development and Arts 2024年教育、人文发展与艺术国际会议 【会议信息】 会议简称:EHDA 2024 大会时间:点击查看 截稿时间:点击查看 大会地点:中国北京 会议官网&#…...

Docker拉取失败,利用 Git将 Docker镜像重新打 Tag 推送到阿里云等其他公有云镜像仓库里
目录 一、开通阿里云容器镜像服务 二、Git配置 三、去DockerHub找镜像 四、编写images.txt文件 五、演示 六、其他注意事项 最近一段时间 Docker 镜像一直是 Pull 不下来的状态,想直连 DockerHub 是几乎不可能的。更糟糕的是,很多原本可靠的国内…...

【区分vue2和vue3下的element UI Breadcrumb 面包屑组件,分别详细介绍属性,事件,方法如何使用,并举例】
在 Vue 2 中,Element UI 提供了 el-breadcrumb 面包屑组件,而在 Vue 3 中,Element UI 的官方版本并没有直接更新以支持 Vue 3,但有一个类似的库叫做 Element Plus,它是为 Vue 3 设计的。 Vue 2 Element UI 在 Vue 2…...

gdb调试命令大全
基本命令 #gdb test test是要调试的程序,由gcc test.c -g -o test生成。进入后提示符变为(gdb) 。 start : 指令会执行程序至main() 主函数的起始位置,即在main() 函数的第一行语句处停止执行(该行代码尚未执行) cont…...

ESP32之arduino环境安装及点灯
目录 前言 前两天安装了VScode,奈何资源找的困难,于是咨询淘宝客服,他说arduino用的多,资源多.然后就安装了a…...
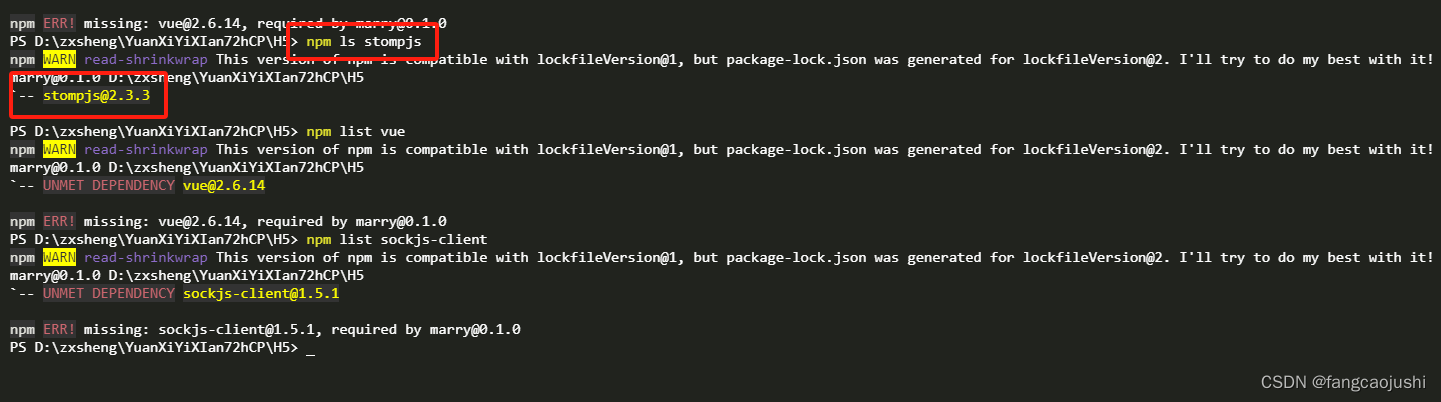
查看VUE中安装包依赖的版本号
查看VUE中安装包依赖的版本号 全部依赖包版本查看某个依赖的例:查看stompjs 应用命令npm ls stompjs 全部依赖包版本 使用npm命令 使用 npm ls 命令可以列出项目中所有已安装的依赖包及其版本。 使用 npm list --depth1 命令可以列出项目中直接依赖的包及其版本&a…...

博途通讯笔记1:1200与1200之间S7通讯
目录 一、添加子网连接二、创建PUT GET三、各个参数的意义 一、添加子网连接 二、创建PUT GET 三、各个参数的意义...
)
Kafka搭建(集群版)
Kafka单机版 部署前提 VMware环境 : 两台centos系统 Jdk包:jdk-8u202-linux-x64.tar.gz Kafka包:kafka_2.12-3.5.0.tgz Zookeeper包:apache-zookeeper-3.7.2-bin.tar.gz 百度网盘自取: 链接: https://pan.baidu.com/s/11EWuhBoSmH3musd_3Rgodw?pwde32t 提取码: e32t Kafka搭建…...

【康复学习--LeetCode每日一题】3115. 质数的最大距离
题目: 给你一个整数数组 nums。 返回两个(不一定不同的)质数在 nums 中 下标 的 最大距离。 示例 1: 输入: nums [4,2,9,5,3] 输出: 3 解释: nums[1]、nums[3] 和 nums[4] 是质数。因此答案是…...

思源宋体CN:7种字重完整字体库,打造专业级中文排版体验
思源宋体CN:7种字重完整字体库,打造专业级中文排版体验 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 还在为中文排版不够优雅而烦恼吗?Source Han…...

Windows苹果设备驱动一键安装:告别iTunes臃肿体验的完整解决方案
Windows苹果设备驱动一键安装:告别iTunes臃肿体验的完整解决方案 【免费下载链接】Apple-Mobile-Drivers-Installer Powershell script to easily install Apple USB and Mobile Device Ethernet (USB Tethering) drivers on Windows! 项目地址: https://gitcode.…...

JMeter梯度压测:精准定位系统可扩展性边界
1. 为什么“梯度式压测”不是加个线程组就完事了?很多人第一次打开JMeter,照着教程建个线程组、加个HTTP请求、跑个聚合报告,看到TPS从200涨到800就以为“压测完成了”。结果上线后流量一上来,服务直接503,监控里CPU没…...

别再折腾LibreOffice了!CentOS 7.9上老牌Apache OpenOffice 4.1.14的完整部署与避坑指南
企业级文档服务选型:Apache OpenOffice 4.1.14在CentOS 7.9的深度实践当我们需要在Linux服务器上搭建文档处理服务时,开源办公套件的选择往往令人纠结。Apache OpenOffice作为历经20年发展的老牌解决方案,在企业级环境中仍有一席之地。本文将…...

3分钟掌握百度网盘直链解析:告别限速的全新下载方案
3分钟掌握百度网盘直链解析:告别限速的全新下载方案 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 还在为百度网盘的非会员限速而烦恼吗?今天我要为你…...

从哈密顿量到李代数:对称性识别与结构常数计算实践
1. 从哈密顿量到李代数:物理学家工具箱里的对称性语言在理论物理和数学物理的日常工作中,我们常常面对一个核心问题:如何从一堆看似复杂的运动方程或一个写出来的哈密顿量中,快速识别出系统隐藏的“灵魂”?这个灵魂&am…...

量子机器学习在基因组分类中的实践:特征映射与模型选择指南
1. 项目概述:当量子计算遇上基因组学如果你和我一样,既对量子计算的神秘力量感到好奇,又长期在生物信息学的数据海洋里“游泳”,那么“量子机器学习”这个交叉领域绝对值得你投入时间。这听起来像是科幻小说的情节,但现…...

机器学习势函数在铌辐照损伤模拟中的关键作用与验证
1. 项目概述:为什么铌的辐照损伤模拟需要更精确的势函数? 在核反应堆堆芯、聚变装置第一壁或是航天器推进系统这些极端环境中,材料不仅要承受高温高压,更要直面高能粒子(如中子、离子)的持续轰击。这种辐照…...

微生物代谢建模与计算机视觉特征匹配技术解析
1. 微生物代谢建模中的协同设计1.1 工业生物技术中的代谢网络基础微生物代谢网络是细胞内酶催化化学反应的综合体系,不同物种间存在显著差异。在工业生物技术领域,这些网络能将废物流等原料转化为高附加值产品。以丁酸梭菌(Clostridium butyr…...

电池阻抗测量技术:伪随机序列与信号处理应用
1. 电池阻抗测量技术概述电池阻抗测量作为电化学系统状态监测的核心手段,其原理基于对电池施加特定激励信号并测量响应信号,通过分析两者的幅值和相位关系来获取阻抗谱。这种频域分析方法能够反映电池内部电荷转移、扩散过程等动力学特性,为电…...