【AutoencoderKL】基于stable-diffusion-v1.4的vae对图像重构
模型地址:https://huggingface.co/CompVis/stable-diffusion-v1-4/tree/main/vae
主要参考:Using-Stable-Diffusion-VAE-to-encode-satellite-images

sd1.4 vae
下载到本地
from diffusers import AutoencoderKL
from PIL import Image
import torch
import torchvision.transforms as T# ./huggingface/stable-diffusion-v1-4/vae 切换为任意本地路径
vae = AutoencoderKL.from_pretrained("./huggingface/stable-diffusion-v1-4/vae",variant='fp16')
# c:\Users\zeng\Downloads\vae_config.jsondef encode_img(input_img):# Single image -> single latent in a batch (so size 1, 4, 64, 64)# Transform the image to a tensor and normalize ittransform = T.Compose([# T.Resize((256, 256)),T.ToTensor()])input_img = transform(input_img)if len(input_img.shape)<4:input_img = input_img.unsqueeze(0)with torch.no_grad():latent = vae.encode(input_img*2 - 1) # Note scalingreturn 0.18215 * latent.latent_dist.sample()def decode_img(latents):# bath of latents -> list of imageslatents = (1 / 0.18215) * latentswith torch.no_grad():image = vae.decode(latents).sampleimage = (image / 2 + 0.5).clamp(0, 1)image = image.detach().cpu()# image = T.Resize(original_size)(image.squeeze())return T.ToPILImage()(image.squeeze())if __name__ == '__main__':# Load an example imageinput_img = Image.open("huge.jpg")original_size = input_img.sizeprint('original_size',original_size)# Encode and decode the imagelatents = encode_img(input_img)reconstructed_img = decode_img(latents)# Save the reconstructed imagereconstructed_img.save("reconstructed_example2.jpg")# Concatenate the original and reconstructed imagesconcatenated_img = Image.new('RGB', (original_size[0] * 2, original_size[1]))concatenated_img.paste(input_img, (0, 0))concatenated_img.paste(reconstructed_img, (original_size[0], 0))# Save the concatenated imageconcatenated_img.save("concatenated_example2.jpg")
相关文章:
【AutoencoderKL】基于stable-diffusion-v1.4的vae对图像重构
模型地址:https://huggingface.co/CompVis/stable-diffusion-v1-4/tree/main/vae 主要参考:Using-Stable-Diffusion-VAE-to-encode-satellite-images sd1.4 vae 下载到本地 from diffusers import AutoencoderKL from PIL import Image import torch import to…...
)
《警世贤文》摘抄:守法篇、惜时篇、修性篇、修身篇、待人篇、防人篇(建议多读书、多看报、少吃零食多睡觉)
若该文为原创文章,转载请注明原文出处 本文章博客地址:https://hpzwl.blog.csdn.net/article/details/140243440 长沙红胖子Qt(长沙创微智科)博文大全:开发技术集合(包含Qt实用技术、树莓派、三维、OpenCV…...
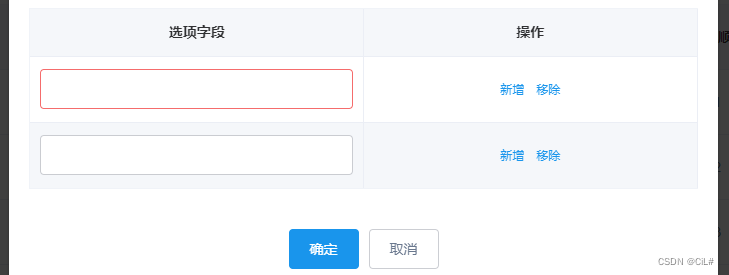
vue2+element-ui新增编辑表格+删除行
实现效果: 代码实现 : <el-table :data"dataForm.updateData"border:header-cell-style"{text-align:center}":cell-style"{text-align:center}"><el-table-column label"选项字段"align"center&…...

Day05-组织架构-角色管理
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 1.组织架构-编辑部门-弹出层获取数据2.组织架构-编辑部门-编辑表单校验3.组织架构-编辑部门-确认取消4.组织架构-删除部门5.角色管理-搭建页面结构6.角色管理-获取数…...

【LLM】二、python调用本地的ollama部署的大模型
系列文章目录 往期文章: 【LLM】一、利用ollama本地部署大模型 目录 文章目录 前言 一、ollama库调用 二、langchain调用 三、requests调用 四、相关参数说明: 总结 前言 本地部署了大模型,下一步任务便是如何调用的问题,…...

20240708 每日AI必读资讯
🤖破解ChatGPT惊人耗电!DeepMind新算法训练提效13倍,能耗暴降10倍 - 谷歌DeepMind研究团队提出了一种加快AI训练的新方法——多模态对比学习与联合示例选择(JEST),大大减少了所需的计算资源和时间。 - JE…...
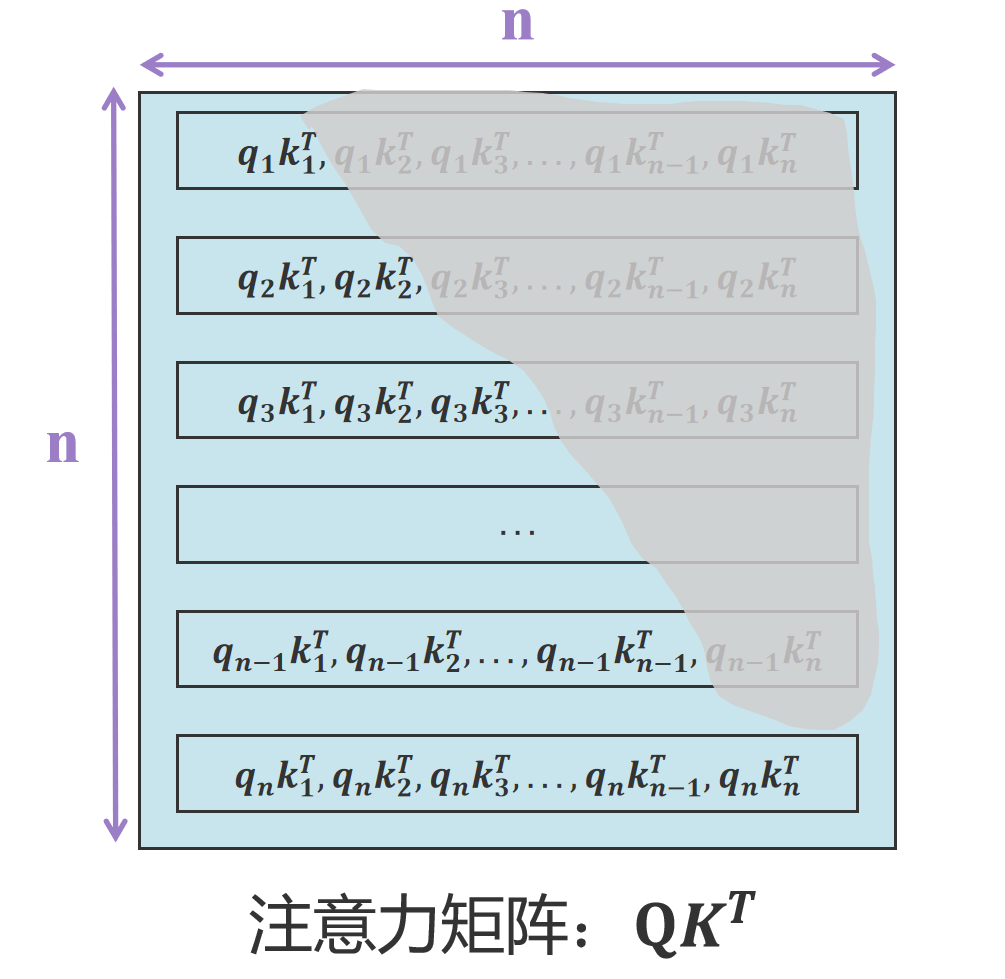
为什么KV Cache只需缓存K矩阵和V矩阵,无需缓存Q矩阵?
大家都知道大模型是通过语言序列预测下一个词的概率。假定{ x 1 x_1 x1, x 2 x_2 x2, x 3 x_3 x3,…, x n − 1 x_{n-1} xn−1}为已知序列,其中 x 1 x_1 x1, x 2 x_2 x2, x 3 x_3 x…...

VS code修改底部的行号的状态栏颜色
VSCode截图 相信很多小伙伴被底部的蓝色状态栏困扰很久了 处理的方式有两种: 1、隐藏状态栏 2、修改其背景颜色 第一种方法大伙都会,今天就使用第二种方法。 1、点击齿轮进入setting 2、我现在用的新版本,设置不是以前那种json格式展示&…...

【鸿蒙学习笔记】MVVM模式
官方文档:MVVM模式 [Q&A] 什么是MVVM ArkUI采取MVVM Model View ViewModel模式。 Model层:存储数据和相关逻辑的模型。View层:在ArkUI中通常是Component装饰组件渲染的UI。ViewModel层:在ArkUI中,ViewModel是…...

端、边、云三级算力网络
目录 端、边、云三级算力网络 NPU Arm架构 OpenStack kubernetes k3s轻量级Kubernetes kubernetes和docker区别 DCI(Data Center Interconnect) SD/WAN TF 端、边、云三级算力网络 算力网络从传统云网融合的角度出发,结合 边缘计算、网络云化以及智能控制的优势,通…...

java —— JSP 技术
一、JSP (一)前言 1、.jsp 与 .html 一样属于前端内容,创建在 WebContent 之下; 2、嵌套的 java 语句放置在<% %>里面; 3、嵌套 java 语句的三种语法: ① 脚本:<% java 代码 %>…...

【Python学习笔记】菜鸟教程Scrapy案例 + B站amazon案例视频
背景前摇(省流可以跳过这部分) 实习的时候厚脸皮请教了一位办公室负责做爬虫这块的老师,给我推荐了Scrapy框架。 我之前学过一些爬虫基础,但是用的是比较常见的BeautifulSoup和Request,于是得到Scrapy这个关键词后&am…...
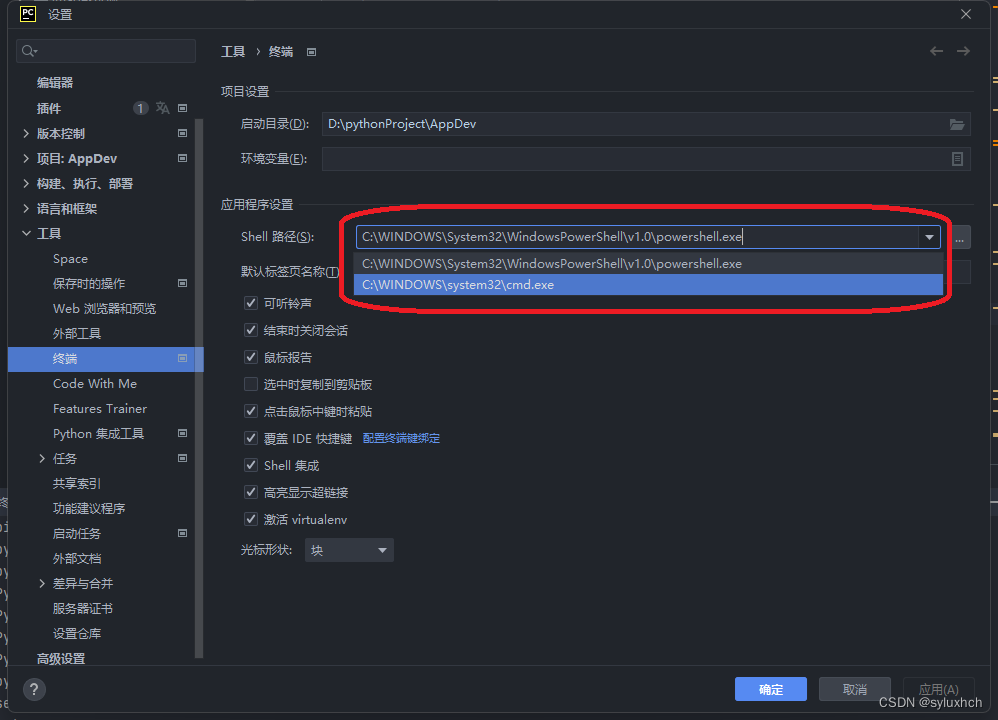
Pycharm的终端(Terminal)中切换到当前项目所在的虚拟环境
1.在Pycharm最下端点击终端/Terminal, 2.点击终端窗口最上端最右边的∨, 3.点击Command Prompt,切换环境, 可以看到现在环境已经由默认的PS(Window PowerShell)切换为项目所使用的虚拟环境。 4.更近一步,如果想让Pycharm默认显示…...

Nginx 高效加速策略:动静分离与缓存详解
在现代Web开发中,网站性能是衡量用户体验的关键指标之一。Nginx,以其出色的性能和灵活性,成为众多网站架构中不可或缺的一部分。本文将深度解析如何利用Nginx实现动静分离与缓存,从而大幅提升网站加载速度和响应效率。 理解动静分…...

Unity3D 游戏摇杆的制作与实现详解
在Unity3D游戏开发中,摇杆是一种非常常见的输入方式,特别适用于移动设备的游戏控制。本文将详细介绍如何在Unity3D中制作和实现一个虚拟摇杆,包括技术详解和代码实现。 对惹,这里有一个游戏开发交流小组,大家可以点击…...

从nginx返回404来看http1.0和http1.1的区别
序言 什么样的人可以称之为有智慧的人呢?如果下一个定义,你会如何来定义? 所谓智慧,就是能区分自己能改变的部分,自己无法改变的部分,努力去做自己能改变的,而不要天天想着那些无法改变的东西&a…...
MySQL 代理层:ProxySQL
文章目录 说明安装部署1.1 yum 安装1.2 启停管理1.3 查询版本1.4 Admin 管理接口 入门体验功能介绍3.1 多层次配置系统 读写分离将实例接入到代理服务定义主机组之间的复制关系配置路由规则事务读的配置延迟阈值和请求转发 ProxySQL 核心表mysql_usersmysql_serversmysql_repli…...

异步主从复制
主从复制的概念 主从复制是一种在数据库系统中常用的数据备份和读取扩展技术,通过将一个数据库服务器(主服务器)上的数据变更自动同步到一个或多个数据库服务器(从服务器)上,以此来实现数据的冗余备份、读…...

论文解析——Full Stack Optimization of Transformer Inference: a Survey
作者及发刊详情 摘要 正文 主要工作贡献 这篇文章的贡献主要有两部分: 分析Transformer的特征,调查高效transformer推理的方法通过应用方法学展现一个DNN加速器生成器Gemmini的case研究 1)分析和解析Transformer架构的运行时特性和瓶颈…...

selenium处理cookie问题实战
1. cookie获取不完整 需要进入的资损平台(web)首页,才会出现有效的ctoken等信息 1.1. 原因说明 未进入指定页面而获取的 cookie 与进入页面后获取的 cookie 可能会有一些差异,这取决于网站的具体实现和 cookie 的设置方式。 通常情况下,一些…...

【DeepSeek-R1代码相似度引擎解密】:3层语义比对机制、Token归一化偏差修正与Jaccard阈值黄金分割点
更多请点击: https://kaifayun.com 第一章:DeepSeek代码重复检测 DeepSeek-R1 模型在训练过程中引入了严格的代码去重机制,其核心目标是消除训练语料中语义等价或高度相似的代码片段,从而提升模型对真实编程模式的学习能力与泛化…...

QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由
QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目…...

Lindy自动化效率翻倍的秘密:从零搭建高可靠多步骤任务流的7步黄金流程
更多请点击: https://intelliparadigm.com 第一章:Lindy自动化效率翻倍的秘密:从零搭建高可靠多步骤任务流的7步黄金流程 Lindy自动化平台以“越久越可靠”为设计哲学,将经典软件工程原则与现代可观测性实践深度融合。其核心优势…...

基于可解释机器学习的城市人口流动空间降尺度分析实践
1. 项目概述:从宏观到微观,解码城市脉搏在城市的肌理中,人口的流动如同血液的循环,承载着经济活力、社会互动与空间结构的全部信息。无论是城市规划师优化公交线路,还是商业分析师评估店铺选址,亦或是公共卫…...

打不开JupyterLab
因为安装某些依赖导致JupyterLab的依赖被动升级或降级,从而影响了JupyterLab的运行,此时可以SSH登录到实例,然后输入jupyter-lab命令进行确认,如果执行命令报错则说明是此问题,那么可以通过pip install jupyterlab再次…...
)
GIS工程应用记录(AI辅助编程)
问题的问题:语境坍缩“从各个角度提出问题,AI做出对应积极答复和修改,结果没有什么变化。”这,就是元问题最核心的症状。你尝试了所有你已知的“高级”协作手段,但就像重拳打在棉花上,AI永远在积极回应&…...

微信小程序项目实战:从npm安装Vant Weapp到解决样式冲突的完整避坑指南
微信小程序工程化实战:Vant Weapp集成与样式冲突解决方案全解析 第一次在小程序里引入Vant Weapp时,我对着满屏错位的组件样式发呆了半小时——原本优雅的按钮变成了扭曲的色块,表单元素叠在一起像抽象画。这不是个例,根据社区反…...

原神私服新纪元:KCN-GenshinServer图形化服务端全功能解析
原神私服新纪元:KCN-GenshinServer图形化服务端全功能解析 【免费下载链接】KCN-GenshinServer 基于GC制作的原神一键GUI多功能服务端。 项目地址: https://gitcode.com/gh_mirrors/kc/KCN-GenshinServer 你是否曾想过拥有一个完全由自己掌控的提瓦特大陆&am…...

qobuz-dl终极实战指南:专业无损音乐下载工具架构解析与高效应用
qobuz-dl终极实战指南:专业无损音乐下载工具架构解析与高效应用 【免费下载链接】qobuz-dl A complete Lossless and Hi-Res music downloader for Qobuz 项目地址: https://gitcode.com/gh_mirrors/qo/qobuz-dl 在数字音乐时代,追求极致音质的音…...

CA-CFAR、GO-CFAR、SO-CFAR怎么选?一张图看懂三种恒虚警检测算法的适用场景与避坑指南
CA-CFAR、GO-CFAR、SO-CFAR工程选型指南:从算法原理到场景适配 雷达信号处理工程师常常面临一个经典难题:在复杂环境中如何选择合适的恒虚警检测算法?当海面杂波、多目标干扰或低信噪比条件同时出现时,CA、GO、SO三种CFAR变体的性…...