零基础自学爬虫技术该从哪里入手?
零基础学习Python并不一定是困难的,这主要取决于个人的学习方法、投入的时间以及学习目标的设定。Python是一门相对容易入门的编程语言,它有着简洁的语法、丰富的库和广泛的应用领域(如数据分析、Web开发、人工智能等),这使得它成为了很多初学者的首选。
以下是一些建议,可以帮助零基础的学习者更好地掌握Python:
-
明确学习目标:首先,你需要明确自己为什么想学Python,以及希望达到什么样的水平。有一个清晰的目标可以激励你持续学习。
-
选择合适的学习资源:网上有很多免费的Python教程、视频课程和书籍,选择适合自己的学习资源很重要。初学者可以从官方文档或入门教程开始,逐步深入。
-
实践为主:编程是一门实践性很强的学科,仅仅阅读书籍或观看视频是不够的。你需要通过编写代码来加深理解,解决实际问题。
-
耐心和坚持:学习编程需要时间和耐心,遇到难题时不要气馁,可以通过查阅资料、寻求帮助等方式解决。
-
参与社区:加入Python学习社区或论坛,与其他学习者交流心得,分享经验。这不仅可以解决你在学习过程中遇到的问题,还可以激发你的学习兴趣。
-
逐步挑战自己:随着你逐渐掌握Python的基础知识,可以尝试编写一些小型项目来锻炼自己的编程能力。通过实践,你会发现自己的编程水平在不断提高。
总之,零基础学习Python并不是一件难事,只要你保持积极的学习态度,选择合适的学习方法,并付诸实践,就一定能够掌握这门强大的编程语言。
零基础自学爬虫技术可以从以下几个方面入手:
一、基础准备
- 学习编程语言:
- Python:Python是当前爬虫开发最流行的编程语言之一,其简洁的语法和丰富的库支持使得它非常适合初学者。你需要掌握Python的基础知识,包括语法、控制流、变量、函数、面向对象编程等。
- 理解网络基础知识:
- HTTP协议:爬虫的核心是通过HTTP协议从网站服务器获取数据,因此你需要了解HTTP协议的请求和响应过程、状态码、请求头、响应头等基本概念。
- HTML语言:爬虫需要从HTML页面中提取所需信息,因此你需要熟悉HTML标签、属性、标签嵌套等。
二、深入学习爬虫技术
- 学习爬虫工具库:
- Requests:这是一个简单易用的HTTP库,用于发送HTTP请求。
- Beautiful Soup:这是一个用于解析HTML和XML文档的Python库,可以从网页中提取数据,通过解析文档为用户提供需要抓取的数据。
- lxml:与Beautiful Soup类似,但lxml在速度、内存占用和灵活性方面通常表现更优。
- Scrapy:这是一个用于爬取网站并从页面中提取结构化数据的快速高级Web抓取和网页抓取框架,可以用来抓取web站点并从页面中提取结构化的数据、提取器也可以使用lxml、xmllib、BeautifulSoup(bs4), 也可以方便地结合自己编写的解析器。
- 掌握数据解析方法:
- XPath:XPath 是一种在 XML 文档中查找信息的语言,也可以用于HTML文档。你可以使用XPath来定位HTML页面中的特定元素。
- 正则表达式:正则表达式是一种强大的文本处理工具,可以用于搜索、替换、验证文本等操作。在爬虫中,它可以用来提取或验证文本数据。
- 了解爬虫策略:
- 广度优先搜索(BFS):从起始页面开始,依次访问每个页面的链接,直到满足停止条件。
- 深度优先搜索(DFS):尽可能深地搜索树的分支,直到达到叶子或满足某个条件。
- 部分PageRank策略:借鉴PageRank算法的思想,根据网页的重要程度来决定抓取的顺序。
- 掌握数据存储与处理技术:
- 文件存储:可以将爬取的数据保存到文本文件、CSV文件或JSON文件中。
- 数据库存储:对于大量数据,可以考虑使用数据库进行存储,如MySQL、MongoDB等。
- 数据处理:使用Pandas等库对数据进行清洗、转换和分析。
三、实践与项目
- 编写简单的爬虫程序:从简单的网站开始,编写能够抓取指定页面数据的爬虫程序。
- 解决常见问题:在实践中,你会遇到各种问题,如反爬虫机制、动态加载内容等。通过查阅资料、寻求帮助等方式解决这些问题。
- 参与开源项目:参与一些开源的爬虫项目,可以锻炼你的实践能力,并学习他人的优秀代码和思路。
四、学习资源推荐
- 在线课程:在各大在线教育平台(如慕课网、网易云课堂、腾讯课堂等)上可以找到丰富的Python爬虫课程。
- 书籍推荐:
- 《Python网络爬虫开发实战》:介绍Python爬虫的基本原理和编写方法。
- 《Python爬虫技术实战》:详细介绍Python爬虫的实现过程和技术细节。
- 《Python爬虫数据分析》:在介绍爬虫技术的同时,还涉及数据分析的相关知识。
- 社区与论坛:加入相关的社区和论坛(如CSDN博客、Stack Overflow等),与同行交流经验、解决问题。
通过以上步骤的学习和实践,你可以逐步掌握爬虫技术并开发出自己的爬虫程序。
相关文章:

零基础自学爬虫技术该从哪里入手?
零基础学习Python并不一定是困难的,这主要取决于个人的学习方法、投入的时间以及学习目标的设定。Python是一门相对容易入门的编程语言,它有着简洁的语法、丰富的库和广泛的应用领域(如数据分析、Web开发、人工智能等),…...

Vue.js 基础入门指南
前言 在前端开发的广阔领域中,Vue.js 无疑是一颗璀璨的明星,以其渐进式框架的特性吸引了无数开发者的目光。Vue.js 旨在通过简洁的 API 实现响应式的数据绑定和组合的视图组件,使得构建用户界面变得既快速又简单。本文将带你走进 Vue.js 的世…...

山泰科技集团陈玉东:争当数字化时代的知识产权卫士
随着互联网和数字技术的飞速普及,大版权时代已经悄然到来。在这个新时代,信息的传播速度、广度和深度均达到了前所未有的高度,极大地拓展了人们的精神世界和知识视野。然而,这一科技发展的浪潮也为版权保护带来了前所未有的挑战。…...
WBCE CMS v1.5.2 远程命令执行漏洞(CVE-2022-25099)
前言 CVE-2022-25099 是一个影响 WBCE CMS v1.5.2 的严重安全漏洞,具体存在于 /languages/index.php 组件中。该漏洞允许攻击者通过上传精心构造的 PHP 文件在受影响的系统上执行任意代码。 技术细节 受影响组件:/languages/index.php受影响版本&…...

鸿蒙语言基础类库:【@ohos.url (URL字符串解析)】
URL字符串解析 说明: 本模块首批接口从API version 7开始支持。后续版本的新增接口,采用上角标单独标记接口的起始版本。开发前请熟悉鸿蒙开发指导文档:gitee.com/li-shizhen-skin/harmony-os/blob/master/README.md点击或者复制转到。 导入…...

【AutoencoderKL】基于stable-diffusion-v1.4的vae对图像重构
模型地址:https://huggingface.co/CompVis/stable-diffusion-v1-4/tree/main/vae 主要参考:Using-Stable-Diffusion-VAE-to-encode-satellite-images sd1.4 vae 下载到本地 from diffusers import AutoencoderKL from PIL import Image import torch import to…...
)
《警世贤文》摘抄:守法篇、惜时篇、修性篇、修身篇、待人篇、防人篇(建议多读书、多看报、少吃零食多睡觉)
若该文为原创文章,转载请注明原文出处 本文章博客地址:https://hpzwl.blog.csdn.net/article/details/140243440 长沙红胖子Qt(长沙创微智科)博文大全:开发技术集合(包含Qt实用技术、树莓派、三维、OpenCV…...
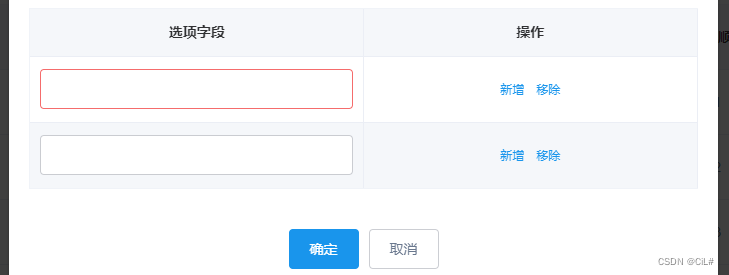
vue2+element-ui新增编辑表格+删除行
实现效果: 代码实现 : <el-table :data"dataForm.updateData"border:header-cell-style"{text-align:center}":cell-style"{text-align:center}"><el-table-column label"选项字段"align"center&…...

Day05-组织架构-角色管理
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 1.组织架构-编辑部门-弹出层获取数据2.组织架构-编辑部门-编辑表单校验3.组织架构-编辑部门-确认取消4.组织架构-删除部门5.角色管理-搭建页面结构6.角色管理-获取数…...

【LLM】二、python调用本地的ollama部署的大模型
系列文章目录 往期文章: 【LLM】一、利用ollama本地部署大模型 目录 文章目录 前言 一、ollama库调用 二、langchain调用 三、requests调用 四、相关参数说明: 总结 前言 本地部署了大模型,下一步任务便是如何调用的问题,…...

20240708 每日AI必读资讯
🤖破解ChatGPT惊人耗电!DeepMind新算法训练提效13倍,能耗暴降10倍 - 谷歌DeepMind研究团队提出了一种加快AI训练的新方法——多模态对比学习与联合示例选择(JEST),大大减少了所需的计算资源和时间。 - JE…...
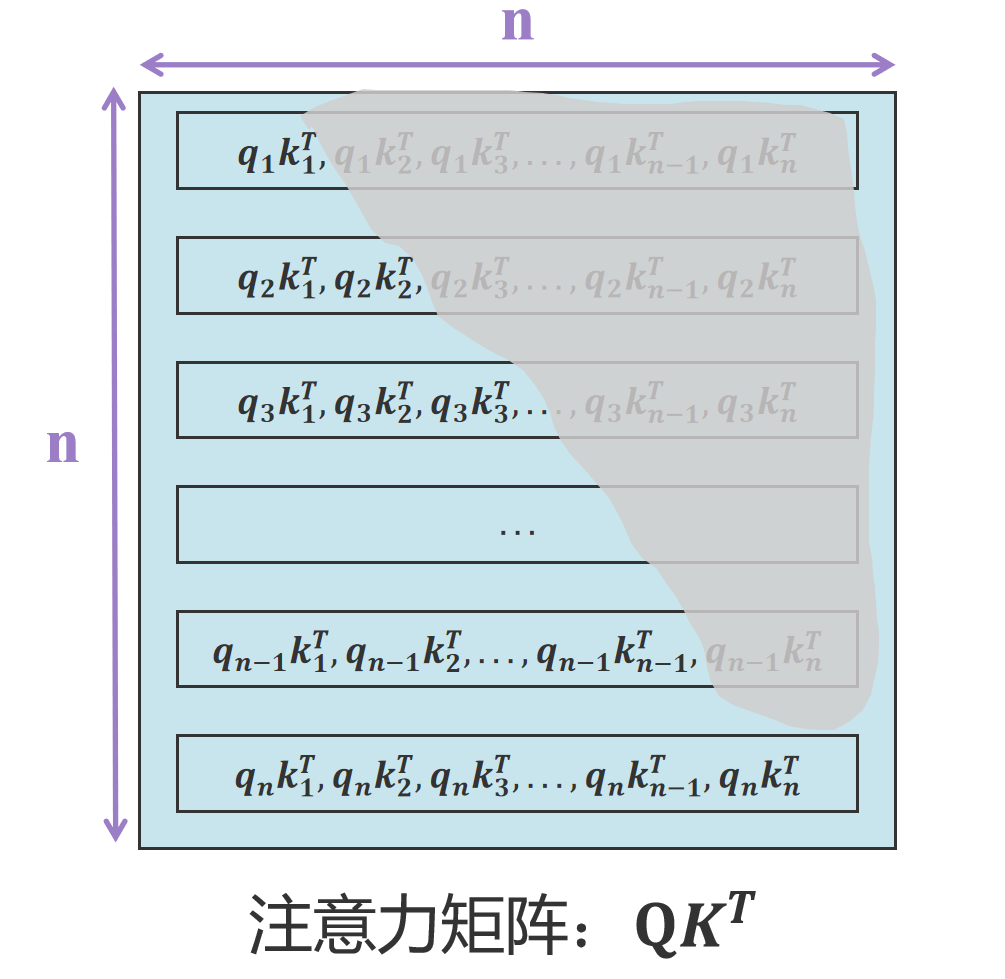
为什么KV Cache只需缓存K矩阵和V矩阵,无需缓存Q矩阵?
大家都知道大模型是通过语言序列预测下一个词的概率。假定{ x 1 x_1 x1, x 2 x_2 x2, x 3 x_3 x3,…, x n − 1 x_{n-1} xn−1}为已知序列,其中 x 1 x_1 x1, x 2 x_2 x2, x 3 x_3 x…...

VS code修改底部的行号的状态栏颜色
VSCode截图 相信很多小伙伴被底部的蓝色状态栏困扰很久了 处理的方式有两种: 1、隐藏状态栏 2、修改其背景颜色 第一种方法大伙都会,今天就使用第二种方法。 1、点击齿轮进入setting 2、我现在用的新版本,设置不是以前那种json格式展示&…...

【鸿蒙学习笔记】MVVM模式
官方文档:MVVM模式 [Q&A] 什么是MVVM ArkUI采取MVVM Model View ViewModel模式。 Model层:存储数据和相关逻辑的模型。View层:在ArkUI中通常是Component装饰组件渲染的UI。ViewModel层:在ArkUI中,ViewModel是…...

端、边、云三级算力网络
目录 端、边、云三级算力网络 NPU Arm架构 OpenStack kubernetes k3s轻量级Kubernetes kubernetes和docker区别 DCI(Data Center Interconnect) SD/WAN TF 端、边、云三级算力网络 算力网络从传统云网融合的角度出发,结合 边缘计算、网络云化以及智能控制的优势,通…...

java —— JSP 技术
一、JSP (一)前言 1、.jsp 与 .html 一样属于前端内容,创建在 WebContent 之下; 2、嵌套的 java 语句放置在<% %>里面; 3、嵌套 java 语句的三种语法: ① 脚本:<% java 代码 %>…...

【Python学习笔记】菜鸟教程Scrapy案例 + B站amazon案例视频
背景前摇(省流可以跳过这部分) 实习的时候厚脸皮请教了一位办公室负责做爬虫这块的老师,给我推荐了Scrapy框架。 我之前学过一些爬虫基础,但是用的是比较常见的BeautifulSoup和Request,于是得到Scrapy这个关键词后&am…...
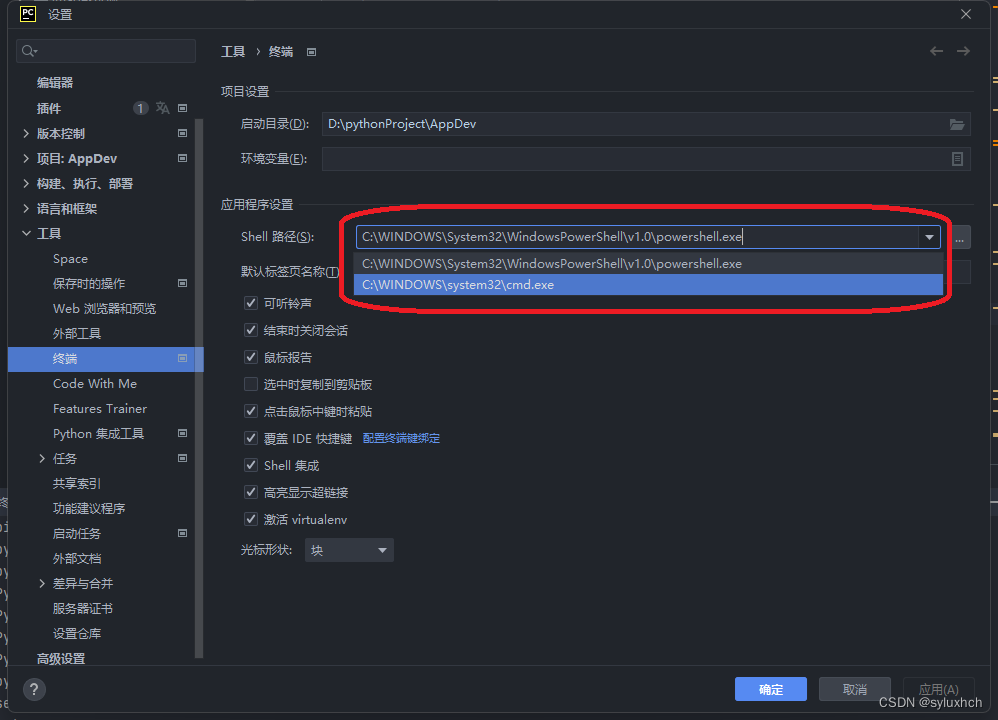
Pycharm的终端(Terminal)中切换到当前项目所在的虚拟环境
1.在Pycharm最下端点击终端/Terminal, 2.点击终端窗口最上端最右边的∨, 3.点击Command Prompt,切换环境, 可以看到现在环境已经由默认的PS(Window PowerShell)切换为项目所使用的虚拟环境。 4.更近一步,如果想让Pycharm默认显示…...

Nginx 高效加速策略:动静分离与缓存详解
在现代Web开发中,网站性能是衡量用户体验的关键指标之一。Nginx,以其出色的性能和灵活性,成为众多网站架构中不可或缺的一部分。本文将深度解析如何利用Nginx实现动静分离与缓存,从而大幅提升网站加载速度和响应效率。 理解动静分…...

Unity3D 游戏摇杆的制作与实现详解
在Unity3D游戏开发中,摇杆是一种非常常见的输入方式,特别适用于移动设备的游戏控制。本文将详细介绍如何在Unity3D中制作和实现一个虚拟摇杆,包括技术详解和代码实现。 对惹,这里有一个游戏开发交流小组,大家可以点击…...

别再死记硬背了!用Multisim仿真+图解,5分钟搞懂三极管共射放大电路工作原理
用Multisim仿真图解5分钟掌握三极管共射放大电路三极管共射放大电路是电子技术中最基础也最关键的电路之一,但传统教材中复杂的公式推导和静态图解往往让初学者望而生畏。本文将带你用Multisim仿真软件,通过可视化的方式直观理解电路工作原理,…...

【DeepSeek-R1代码相似度引擎解密】:3层语义比对机制、Token归一化偏差修正与Jaccard阈值黄金分割点
更多请点击: https://kaifayun.com 第一章:DeepSeek代码重复检测 DeepSeek-R1 模型在训练过程中引入了严格的代码去重机制,其核心目标是消除训练语料中语义等价或高度相似的代码片段,从而提升模型对真实编程模式的学习能力与泛化…...

信息系统项目管理师核心知识点精讲
一、项目整合管理(重点:项目章程与项目管理计划) 知识点详解: 项目整体管理是项目管理知识体系的核心,它确保项目各要素协调统一。在考试中,特别要掌握项目章程和项目管理计划的区别与联系。 项目章程是项目的“出生证明”,由项目发起人发布。它正式授权项目,赋予项…...

Lampiao 靶场
Lampiao 靶场完整渗透解析一、靶场环境信息攻击机(Kali)IP:192.168.146.128靶机 IP:192.168.146.129目标:获取靶机 root 权限与 flag二、步骤 1:信息收集(端口与服务扫描)nmap -p- -…...

户外实用|艾迪欧 R6000 测评 —— 户外 / 自驾 / 露营的通讯好搭档
户外出行,通讯工具的核心是稳定、清晰、耐用、续航久、功能全。艾迪欧 R6000 作为一款兼顾专业与户外的 DMR 对讲机,全频段覆盖、双模通讯、自定义功能、长续航,完美适配自驾、露营、登山、越野等户外场景,是户外爱好者的靠谱通讯…...

XML 服务器
XML 服务器 引言 XML(可扩展标记语言)服务器在现代互联网技术中扮演着至关重要的角色。它为数据的传输和处理提供了灵活且高效的方式。本文将深入探讨XML服务器的概念、工作原理、应用场景及其在软件开发中的重要性。 什么是XML服务器? XML服务器是一种用于存储、处理和…...

3分钟开启PC游戏分屏派对:NucleusCoop让单机游戏秒变多人同屏神器
3分钟开启PC游戏分屏派对:NucleusCoop让单机游戏秒变多人同屏神器 【免费下载链接】nucleuscoop Starts multiple instances of a game for split-screen multiplayer gaming! 项目地址: https://gitcode.com/gh_mirrors/nu/nucleuscoop 还在为热门PC游戏不支…...

解决方法:庐山派K230接串口没识别到端口问题
一、插入usb转串口工具之前二、插入usb转串口工具之后三、解决方法说明:🔍 核心原因:USB Serial 设备,没有被识别为 COM 口你现在看到的 USB Serial,说明开发板已经正常启动了,USB 也被电脑识别到了&#x…...

量子纠错码VarQEC:原理、实现与硬件优化
1. 量子纠错码基础与实验背景量子纠错码(Quantum Error Correction Codes, QEC)是量子计算中保护量子信息免受噪声影响的核心技术。与经典纠错码不同,量子纠错需要应对量子态特有的退相干和纠缠特性。传统QEC如[[5,1,3]]完美码虽然理论完备&a…...

应对Claude Code访问不稳定,快速切换至Taotoken的应急方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 应对Claude Code访问不稳定,快速切换至Taotoken的应急方案 对于依赖Claude Code进行日常开发或自动化任务的用户来说&a…...