掌握Python中的文件序列化:Json和Pickle模块解析
Python 文件操作与管理:Open函数、Json与Pickle、Os模块
在Python中,文件是一个重要的数据处理对象。无论是读取数据、保存数据还是进行数据处理,文件操作都是Python编程中不可或缺的一部分。本文将详细介绍Python中文件操作的几种常用方法,包括open函数的使用、数据序列化与反序列化,以及os模块在文件和目录管理中的应用。
Open函数的使用
open()函数是Python中打开文件的通用方法,使用它可以打开一个文件,并返回一个文件对象。这个文件对象可以用于后续的读写等操作。
函数格式
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
参数说明
file:文件路径。mode:打开方式,如'r'(只读)、'w'(只写)、'a'(追加)、'b'(二进制模式)等。encoding:指定编码类型。errors:指定错误处理方式。
示例代码
# 读取文件内容
with open('example.txt', 'r', encoding='utf-8') as file:content = file.read()print(content)# 写入文件
with open('example.txt', 'w', encoding='utf-8') as file:file.write('Hello, world!')# 追加内容
with open('example.txt', 'a', encoding='utf-8') as file:file.write('\nAppend this line.')
数据序列化:Json与Pickle
序列化是指将对象状态转换为可存储或传输的形式的过程。Python中提供了多种序列化方法,其中json和pickle是常用的两种。
Json序列化与反序列化
json模块可以将Python对象转换成JSON格式字符串,并能从JSON格式字符串中转换回Python对象。
import json# 序列化
data = {'key': 'value'}
json_str = json.dumps(data)
print(json_str) # {"key": "value"}# 反序列化
data_back = json.loads(json_str)
print(data_back) # {'key': 'value'}
Pickle序列化与反序列化
pickle模块可以将Python对象序列化并保存到文件中,也能从文件中恢复这些对象。
import pickle# 序列化
data = {'key': 'value'}
with open('data.pickle', 'wb') as file:pickle.dump(data, file)# 反序列化
with open('data.pickle', 'rb') as file:data_loaded = pickle.load(file)
文件和目录管理:os模块
os模块提供了丰富的方法用于文件和目录的管理。
文件和目录操作
import os# 获取当前工作目录
current_directory = os.getcwd()
print(current_directory)# 创建目录
os.makedirs('new_directory', exist_ok=True)# 列出目录中的文件
files = os.listdir(current_directory)
print(files)# 删除文件
os.remove('example.txt')# 删除目录
os.rmdir('new_directory')
路径操作与文件属性
# 检查路径存在性
is_exist = os.path.exists('example.txt')
print(is_exist)# 获取文件大小
file_size = os.path.getsize('example.txt')
print(file_size)# 分离文件名与路径
file_name = os.path.basename('example/path/file.txt')
file_path = os.path.dirname('example/path/file.txt')
print(file_name, file_path)# 检查文件或目录类型
is_file = os.path.isfile('example.txt')
is_dir = os.path.isdir('example/directory')
print(is_file, is_dir)
通过本文的学习,我们了解了如何在Python中使用open()函数进行文件操作,使用json和pickle模块进行数据的序列化与反序列化,以及使用os模块进行文件和目录的管理。掌握这些技巧将大大提高我们的编程效率。
希望本文能够帮助读者在Python开发中熟练处理文件和操作系统相关任务。如果你在实践中遇到任何问题,欢迎在评论区提出,我们一起讨论解决。
最后,值得一提的是,除了本文介绍的这些方法,Python还有许多其他优秀的库和工具,可以帮助我们更高效地进行文件操作和管理。例如,PlugLink 是一个开源的Python库,提供了一些额外的文件操作功能,可以作为本文内容的补充。
相关文章:

掌握Python中的文件序列化:Json和Pickle模块解析
Python 文件操作与管理:Open函数、Json与Pickle、Os模块 在Python中,文件是一个重要的数据处理对象。无论是读取数据、保存数据还是进行数据处理,文件操作都是Python编程中不可或缺的一部分。本文将详细介绍Python中文件操作的几种常用方法&…...

WordPress 6.6 “Dorsey多尔西”发布
WordPress 6.6 “Dorsey多尔西”已经发布,它以传奇的美国大乐队领袖 Tommy Dorsey 名字命名。Dorsey 以其音调流畅的长号和作品而闻名,他的音乐以其情感深度和充满活力的能量吸引了观众。 当您探索 WordPress 6.6 的新功能和增强功能时,让您的…...

核函数支持向量机(Kernel SVM)
核函数支持向量机(Kernel SVM)是一种非常强大的分类器,能够在非线性数据集上实现良好的分类效果。以下是关于核函数支持向量机的详细数学模型理论知识推导、实施步骤与参数解读,以及两个多维数据实例(一个未优化模型&a…...

二分查找(折半查找)
这次不排序了,对排好序的数组做个查找吧 介绍 二分查找排序英文名为BinarySort,是一种效率较高的查找方法要求线性表必须采用顺序存储结构 基本思路 通过不断地将搜索范围缩小一半来找到目标元素: 1、假定数组为arr,需要查找的…...
)
arcgis紧凑型切片缓存(解决大范围切片,文件数量大的问题)
ArcGIS 切片缓存的紧凑型存储格式是一种优化的存储方式,用于提高切片缓存的存储效率和访问速度。紧凑型存储格式将多个切片文件合并为一个单一的 .bundle 文件,从而减少文件系统的开销和切片的加载时间。这类格式已经应用很久了,我记得2013我…...
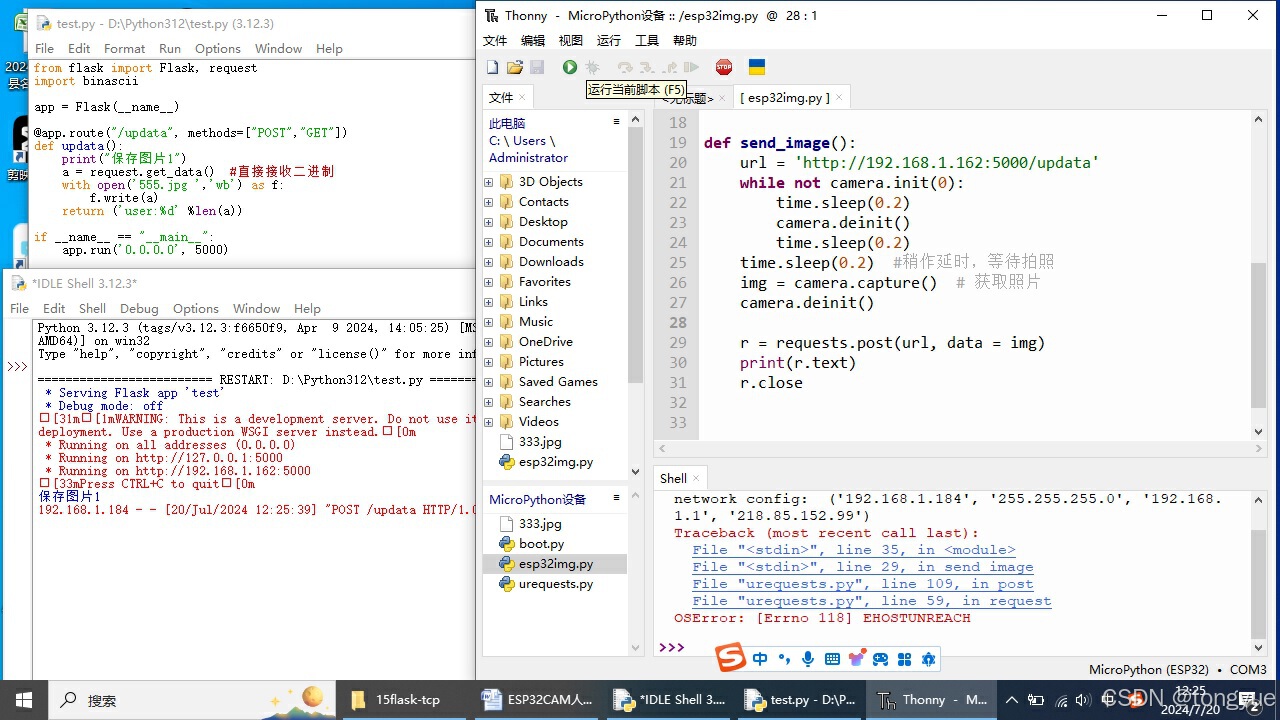
ESP32CAM人工智能教学15
ESP32CAM人工智能教学15 Flask服务器TCP连接 小智利用Flask在计算机中创建一个虚拟的网页服务器服务器,让ESP32Cam通过WiFi连接,把摄像头拍摄到的图片发送到电脑中,并在电脑中保存成图片文件。 Flask是用Python编写的网页服务程序WebServer。…...

Pandas 33个冷知识 0721
Pandas 33个冷知识 从Excel读取数据: 使用 pd.read_excel(file.xlsx) 来读取Excel文件。 写入Excel: 使用 df.to_excel(file.xlsx, indexFalse) 将DataFrame写入Excel文件。 创建日期索引: 使用 df.set_index(pd.to_datetime(df[date])) 创建日期索引。 向后填充缺失值: 使用…...

C++ map和set的使用
目录 0.前言 1.关联式容器 2.键值对 3.树形结构的关联式容器 3.1树形结构的特点 3.2树形结构在关联式容器中的应用 4.set 4.1概念与性质 4.2使用 5.multiset 5.1概念与性质 5.2使用 6.map 6.1概念与性质 6.2使用 7.multimap 7.1概念与性质 7.2使用 8.小结 &a…...

yarn的安装和配置以及更新总结,npm的对照使用差异
1. Yarn简介 Yarn 是一个由 Facebook 开发的现代 JavaScript 包管理器,旨在提供更快、更安全、更可靠的包管理体验。 1.1 什么是Yarn Yarn 是一个快速、可靠和安全的 JavaScript 包管理器,它通过并行化操作和智能缓存机制,显著提升了依赖安…...

【Git命令】git rebase之合并提交记录
使用场景 在本地提交了两个commit,但是发现根本没有没必要分为两次,需要想办法把两次提交合并成一个提交;这个时候可以使用如下命令启动交互式变基会话: git rebase -i HEAD~N这里 N 是你想要重新调整的最近的提交数。 如下在本地…...

为什么品牌需要做 IP 形象?
品牌做IP形象的原因有多方面,这些原因共同构成了IP形象在品牌建设中的重要性和价值,主要原因有以下几个方面: 增强品牌识别度与记忆点: IP形象作为品牌的视觉符号,具有独特性和辨识性,能够在消费者心中留…...

Kubernetes 1.24 版弃用 Dockershim 后如何迁移到 containerd 和 CRI-O
在本系列的上一篇文章中,我们讨论了什么是 CRI 和 OCI,Docker、containerd、CRI-O 之间的区别以及它们的架构等。最近,我们得知 Docker 即将从 kubernetes 中弃用!(查看 kubernetes 官方的这篇文章)那么让我…...
 】)
70. 爬楼梯【 力扣(LeetCode) 】
一、题目描述 假设你正在爬楼梯。需要 n 阶你才能到达楼顶。 每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢? 二、测试用例 示例 1: 输入:n 2 输出:2 解释:有两种方法可以爬到楼顶。 1. 1 阶…...

R语言优雅的把数据基线表(表一)导出到word
基线表(Baseline Table)是医学研究中常用的一种数据表格,用于在研究开始时呈现参与者的初始特征和状态。这些特征通常包括人口统计学数据、健康状况和疾病史、临床指标、实验室检测、生活方式、社会经济等。 本人在既往文章《scitb包1.6版本发…...

XMl基本操作
引言 使⽤Mybatis的注解⽅式,主要是来完成⼀些简单的增删改查功能. 如果需要实现复杂的SQL功能,建议使⽤XML来配置映射语句,也就是将SQL语句写在XML配置⽂件中. 之前,我们学习了,用注解的方式来实现MyBatis 接下来我们…...

Linux——Shell脚本和Nginx反向代理服务器
1. Linux中的shell脚本【了解】 1.1 什么是shell Shell是一个用C语言编写的程序,它是用户使用Linux的桥梁 Shell 既是一种命令语言,有是一种程序设计语言 Shell是指一种应用程序,这个应用程序提供了一个界面,用户通过这个界面访问…...

pyspark使用 graphframes创建和查询图的方法
1、安装graphframes的步骤 1.1 查看 spark 和 scala版本 在终端输入: spark-shell --version 查看spark 和scala版本 1.2 在maven库中下载对应版本的graphframes https://mvnrepository.com/artifact/graphframes/graphframes 我这里需要的是spark 2.4 scala 2.…...

【web】-flask-简单的计算题(不简单)
打开页面是这样的 初步思路,打开F12,查看头,都发现了这个表达式的base64加密字符串。编写脚本提交答案,发现不对; 无奈点开source发现源代码,是flask,初始化表达式,获取提交的表达式࿰…...

Apache Sqoop
Apache Sqoop是一个开源工具,用于在Apache Hadoop和关系型数据库(如MySQL、Oracle、PostgreSQL等)之间进行数据的批量传输。其主要功能包括: 1. 数据导入:从关系型数据库(如MySQL、Oracle等)中将…...

【Python】TensorFlow介绍与实战
TensorFlow介绍与使用 1. 前言 在人工智能领域的快速发展中,深度学习框架的选择至关重要。TensorFlow 以其灵活性和强大的社区支持,成为了许多研究者和开发者的首选。本文将进一步扩展对 TensorFlow 的介绍,包括其优势、应用场景以及在最新…...

Fulling框架:构建完整AI智能体的工程化实践指南
1. 项目概述:从“FullAgent”到“Fulling”的智能体进化之路最近在开源社区里,一个名为“Fulling”的项目引起了我的注意。它隶属于“FullAgent”这个组织,名字本身就很有意思。“Fulling”这个词,在英语里有“使…丰满、充实”的…...

C#初步认识/入门基础
一、注释/运行/项目介绍1.注释1.// 双斜杠是单行注释,注释代码不会被执行;/* */是多行注释格式。两种均不会被执行;.///三斜杠一般写在方法前//1111/*111*11*////11112.运行2.运行调试 : 实心三角(运行控制台后会消失…...

别再手动点选了!用C#写个SolidWorks插件,一键智能识别并拉伸草图里的特定轮廓
用C#开发SolidWorks智能插件:一键识别并拉伸特定草图轮廓的工程实践 在机械设计领域,SolidWorks作为主流三维CAD软件,其草图绘制与特征创建是产品开发的基础环节。工程师们经常遇到这样的场景:复杂草图中包含多个相交轮廓…...

3分钟上手OmenSuperHub:解锁暗影精灵笔记本的真正性能潜力
3分钟上手OmenSuperHub:解锁暗影精灵笔记本的真正性能潜力 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 你是否厌倦了官方OMEN Gaming Hub的…...

传统RAG把文档切碎,TreeSearch不接受,结果反而更快更准
无需 Embedding,无需向量库,无需切分——开源项目TreeSearch 用树结构保留文档灵魂,毫秒级检索万级文档。 你是不是也被 RAG 切碎过? 用过 RAG 的人都知道这个痛点: 文档被机械地切成固定大小的 chunk,喂…...

5分钟快速上手:qmcdump免费解密QQ音乐文件的终极指南
5分钟快速上手:qmcdump免费解密QQ音乐文件的终极指南 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump 你是否…...

Starter计划配额耗尽预警失效?我们逆向解析其API响应头,发现3个未文档化的速率控制暗门
更多请点击: https://intelliparadigm.com 第一章:Starter计划配额耗尽预警失效?我们逆向解析其API响应头,发现3个未文档化的速率控制暗门 在对 Starter 计划的 API 调用行为进行深度监控时,我们观察到配额耗尽告警频…...

专业级macOS歌词同步方案:LyricsX核心功能深度解析
专业级macOS歌词同步方案:LyricsX核心功能深度解析 【免费下载链接】LyricsX 🎶 Ultimate lyrics app for macOS. 项目地址: https://gitcode.com/gh_mirrors/ly/LyricsX LyricsX是一款专为macOS设计的专业级歌词同步工具,通过智能歌词…...

W4A4量化技术:OSC框架如何实现高效LLM部署
1. OSC框架:硬件高效的W4A4量化革命在大型语言模型(LLM)部署领域,4-bit量化(W4A4)正成为突破算力瓶颈的关键技术。传统8-bit量化虽已成熟,但当我们将精度压缩至4-bit时,激活张量中的异常值(Outliers)会像"黑洞"般吞噬有…...

初创公司如何借助Taotoken控制大模型API试用与正式成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创公司如何借助Taotoken控制大模型API试用与正式成本 对于初创公司而言,在产品从原型验证到正式上线的过程中&#x…...