基于YOLO的植物病害识别系统:从训练到部署全攻略
基于深度学习的植物叶片病害识别系统(UI界面+YOLOv8/v7/v6/v5代码+训练数据集)
1. 引言
在农业生产中,植物叶片病害是影响作物产量和质量的主要因素之一。传统的病害检测方法依赖于人工识别,效率低且易受主观因素影响。随着深度学习技术的发展,基于计算机视觉的植物叶片病害自动识别系统得到了广泛关注和应用。本教程旨在通过构建一个基于YOLO模型的植物叶片病害识别系统,帮助读者掌握相关技术,实现从数据准备、模型训练到部署的全过程。
2. 项目准备
必备环境与工具
- Python:项目开发的主要编程语言
- Anaconda:Python数据科学平台,便于环境管理和包管理
- YOLO (You Only Look Once):目标检测模型,选择v8/v7/v6/v5版本
- OpenCV:计算机视觉库
- Flask/Django:用于搭建UI界面的Web框架
安装与配置步骤
-
安装Python与Anaconda
从Python官网下载安装Python:https://www.python.org/downloads/
从Anaconda官网下载安装Anaconda:https://www.anaconda.com/products/distribution
-
配置YOLO环境
安装YOLO依赖:
pip install torch torchvision torchaudio pip install -U git+https://github.com/ultralytics/yolov5
3. 数据集准备
数据集简介
使用Kaggle上的植物叶片病害数据集,包含多种植物叶片的病害图像和标注。
数据集下载链接:https://www.kaggle.com/datasets
数据预处理
-
数据增强与标注
使用LabelImg进行图像标注:https://github.com/tzutalin/labelImg
安装LabelImg:
pip install labelImg运行LabelImg进行图像标注:
labelImg -
数据集划分
将数据集划分为训练集、验证集和测试集:
import os import shutil import randomdef split_dataset(source_dir, train_dir, val_dir, test_dir, train_ratio=0.7, val_ratio=0.2):all_files = os.listdir(source_dir)random.shuffle(all_files)train_count = int(len(all_files) * train_ratio)val_count = int(len(all_files) * val_ratio)for i, file in enumerate(all_files):if i < train_count:shutil.move(os.path.join(source_dir, file), train_dir)elif i < train_count + val_count:shutil.move(os.path.join(source_dir, file), val_dir)else:shutil.move(os.path.join(source_dir, file), test_dir)split_dataset('data/source', 'data/train', 'data/val', 'data/test')
4. 模型训练
YOLO模型简介
YOLO (You Only Look Once) 是一种快速准确的目标检测模型。YOLOv8/v7/v6/v5 是不同版本的YOLO模型,性能和速度有所不同。
配置与训练
-
配置文件的修改
修改YOLO配置文件:
# example.yaml train: data/train val: data/val nc: 5 # number of classes names: ['class1', 'class2', 'class3', 'class4', 'class5'] -
超参数调整
在配置文件中调整超参数,如batch size、learning rate等。
-
训练模型的步骤
使用以下命令训练模型:
python train.py --img 640 --batch 16 --epochs 50 --data example.yaml --cfg yolov5s.yaml --weights yolov5s.pt
训练过程中的常见问题与解决
- 内存不足:减少batch size
- 训练速度慢:使用GPU加速,确保CUDA正确安装
5. 模型评估与优化
模型评估指标
- 准确率 (Accuracy)
- 召回率 (Recall)
- F1分数 (F1 Score)
from sklearn.metrics import accuracy_score, recall_score, f1_scorey_true = [...] # true labels
y_pred = [...] # predicted labelsaccuracy = accuracy_score(y_true, y_pred)
recall = recall_score(y_true, y_pred, average='macro')
f1 = f1_score(y_true, y_pred, average='macro')print(f"Accuracy: {accuracy}, Recall: {recall}, F1 Score: {f1}")
模型优化策略
- 数据增强:使用更多的数据增强技术,如旋转、缩放、裁剪等
- 超参数调优:通过网格搜索或贝叶斯优化找到最佳超参数
- 使用迁移学习:使用预训练模型进行微调
6. 模型部署
Flask/Django搭建UI界面
-
项目结构介绍
plant_disease_detection/ ├── app.py ├── templates/ │ ├── index.html │ └── result.html ├── static/ │ └── styles.css └── models/└── yolov5s.pt -
创建基础的网页模板
-
index.html
<!DOCTYPE html> <html lang="en"> <head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>Plant Disease Detection</title><link rel="stylesheet" href="{{ url_for('static', filename='styles.css') }}"> </head> <body><h1>Plant Disease Detection</h1><form action="/predict" method="post" enctype="multipart/form-data"><input type="file" name="file"><button type="submit">Upload</button></form> </body> </html> -
result.html
<!DOCTYPE html> <html lang="en"> <head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>Result</title><link rel="stylesheet" href="{{ url_for('static', filename='styles.css') }}"> </head> <body><h1>Detection Result</h1><img src="{{ url_for('static', filename='uploads/' + filename) }}" alt="Uploaded Image"><p>{{ result }}</p> </body> </html>
-
后端集成
-
接口设计与实现
- app.py
from flask import Flask, request, render_template, url_for import os from werkzeug.utils import secure_filename import torch from PIL import Imageapp = Flask(__name__) app.config['UPLOAD_FOLDER'] = 'static/uploads/'model = torch.hub.load('ultralytics/yolov5', 'custom', path='models/yolov5s.pt')@app.route('/') def index():return render_template('index.html')@app.route('/predict', methods=['POST']) def predict():if 'file' not in request.files:return 'No file part'file = request.files['file']if file.filename == '':return 'No selected file'if file:filename = secure_filename(file.filename)filepath = os.path.join(app.config['UPLOAD_FOLDER'], filename)file.save(filepath)img = Image.open(filepath)results = model(img)results.save(save_dir=app.config['UPLOAD_FOLDER'])return render_template('result.html', filename=filename, result=results.pandas().xyxy[0].to_json(orient="records"))if __name__ == '__main__':app.run(debug=True)
- app.py
部署模型到服务器
-
使用Gunicorn或其他部署工具
pip install gunicorn gunicorn -w 4 app:app -
部署到云服务器
以AWS为例,创建EC2实例,配置安全组,上传项目文件,并使用Gunicorn运行应用。
7. 系统测试与演示
本地测试
-
测试用例设计
设计多种病害图像测试系统的准确性。
-
测试结果分析
记录测试结果,分析模型的准确性和误差。
在线演示
-
系统演示视频
使用录屏软件录制系统的操作流程。
-
在线测试链接
部署到云服务器后,提供在线测试链接供用户体验。
8. 总结与展望
项目总结
-
项目成果回顾
本项目成功实现了基于YOLO的植物叶片病害识别系统,从数据准备、模型训练到部署的完整流程。
-
实践中的收获与心得
通过本项目,读者能够掌握深度学习项目的完整开发流程,了解YOLO模型的应用和优化方法。
未来工作展望
-
系统优化方向
进一步优化模型,提高检测准确性,减少误报和漏报。
-
更多应用场景探讨
将该技术应用于更多的农作物病害检测,以及其他领域的目标检测任务。
9. 声明
声明:本文只是简单的项目思路,如有部署的想法,想要(UI界面+YOLOv8/v7/v6/v5代码+训练数据集+视频教学)的可以联系作者.
相关文章:

基于YOLO的植物病害识别系统:从训练到部署全攻略
基于深度学习的植物叶片病害识别系统(UI界面YOLOv8/v7/v6/v5代码训练数据集) 1. 引言 在农业生产中,植物叶片病害是影响作物产量和质量的主要因素之一。传统的病害检测方法依赖于人工识别,效率低且易受主观因素影响。随着深度学…...

数据库开发:MySQL基础(二)
MySQL基础(二) 一、表的关联关系 在关系型数据库中,表之间可以通过关联关系进行连接和查询。关联关系是指两个或多个表之间的关系,通过共享相同的列或键来建立连接。常见的关联关系有三种类型:一对多关系,…...

实现物理数据库迁移到云上
实现物理数据库迁移到云上 以下是一个PHP脚本,用于实现物理数据库迁移到云上的步骤: <?php// 评估和规划 $databaseSize "100GB"; $performanceRequirements "high"; $dataComplexity "medium";$cloudProvider &…...

[Spring] MyBatis操作数据库(进阶)
🌸个人主页:https://blog.csdn.net/2301_80050796?spm1000.2115.3001.5343 🏵️热门专栏: 🧊 Java基本语法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12615970.html?spm1001.2014.3001.5482 🍕 Collection与…...

【Websim.ai】一句话让AI帮你生成一个网页
【Websim.ai】一句话让AI帮你生成一个网页 网站链接 websim.ai 简介 websim.ai接入了Claude Sonnet 3.5,GPT-4o等常用的LLM,只需要在websim.ai的官网指令栏中编写相关指令,有点类似大模型的Prompt,指令的好坏决定了网页生成的…...

云计算实训16——关于web,http协议,https协议,apache,nginx的学习与认知
一、web基本概念和常识 1.Web Web 服务是动态的、可交互的、跨平台的和图形化的为⽤户提供的⼀种在互联⽹上浏览信息的服务。 2.web服务器(web server) 也称HTTP服务器(HTTP server),主要有 Nginx、Apache、Tomcat 等。…...
2024年必备技能:小红书笔记评论自动采集,零基础也能学会的方法
摘要: 面对信息爆炸的2024年,小红书作为热门社交平台,其笔记评论成为市场洞察的金矿。本文将手把手教你,即便编程零基础,也能轻松学会利用Python自动化采集小红书笔记评论,解锁营销新策略,提升…...

【Gitlab】SSH配置和克隆仓库
生成SSH Key ssh-keygen -t rsa -b 4096 私钥文件: id_rsa 公钥文件:id_rsa.pub 复制生成的ssh公钥到此处 克隆仓库 git clone repo-address 需要进行推送和同步来更新本地和服务器的文件 推送更新内容 git push <remote><branch> 拉取更新内容 git pull &…...

[Day 35] 區塊鏈與人工智能的聯動應用:理論、技術與實踐
區塊鏈的分布式存儲技術 區塊鏈技術自2008年比特幣白皮書發表以來,已經成為一種革命性的技術,帶來了許多創新。區塊鏈本質上是一個去中心化的分布式賬本,每個節點都持有賬本的副本,並參與記錄和驗證交易。分布式存儲是區塊鏈的重…...

Vue 3 中使用 inMap.js 实现蜂窝热力图的可视化
本文由ScriptEcho平台提供技术支持 项目地址:传送门 Vue 3 中使用 inMap.js 实现蜂窝热力图的可视化 应用场景介绍 蜂窝热力图是一种可视化技术,用于在地图上显示数据的分布情况。它将数据点划分为六边形单元格,并根据单元格内数据的密度…...

nginx隐藏server及版本号
1、背景 为了提高nginx服务器的安全性,降低被攻击的风险,需要隐藏nginx的server和版本号。 2、隐藏nginx版本号 在 http {—}里加上 server_tokens off; 如: http {……省略sendfile on;tcp_nopush on;keepalive_timeout 60;tcp_nodelay o…...

Oracle DBMS_XPLAN包
DBMS_XPLAN 包的解释和关键点 DBMS_XPLAN 包是 Oracle 数据库中一个重要的工具,它允许数据库管理员和开发人员以各种方式显示 SQL 语句的执行计划,这对于 SQL 优化和性能诊断至关重要。以下是主要函数及其描述: 用于显示执行计划的主要函数…...

【ffmpeg命令入门】分离音视频流
文章目录 前言音视频交错存储概念为什么要进行音视频交错存储:为什么要分离音视频流: 去除音频去除视频 总结 前言 FFmpeg 是一款强大的多媒体处理工具,广泛应用于音视频的录制、转换和流媒体处理等领域。它支持几乎所有的音频和视频格式&am…...
小红书笔记评论采集全攻略:三种高效方法教你批量导出
摘要: 本文将深入探讨如何利用Python高效采集小红书平台上的笔记评论,通过三种实战策略,手把手教你实现批量数据导出。无论是市场分析、竞品监测还是用户反馈收集,这些技巧都将为你解锁新效率。 一、引言:小红书数据…...
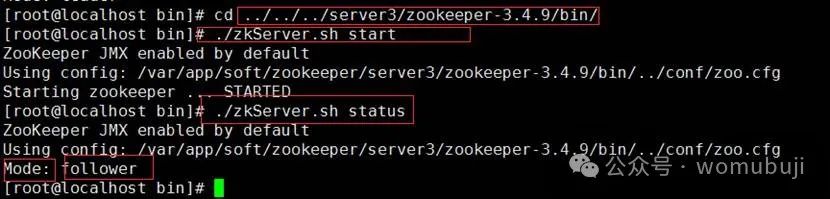
实战:ZooKeeper 操作命令和集群部署
ZooKeeper 操作命令 ZooKeeper的操作命令主要用于对ZooKeeper服务中的节点进行创建、查看、修改和删除等操作。以下是一些常用的ZooKeeper操作命令及其说明: 一、启动与连接 启动ZooKeeper服务器: ./zkServer.sh start这个命令用于启动ZooKeeper服务器…...

linux运维一天一个shell命令之 top详解
概念: top 命令是 Unix 和类 Unix 操作系统(如 Linux、macOS)中一个常用的系统监控工具,它提供了一个动态的实时视图,显示系统的整体性能信息,如 CPU 使用率、内存使用情况、进程列表等。 基本用法 root…...
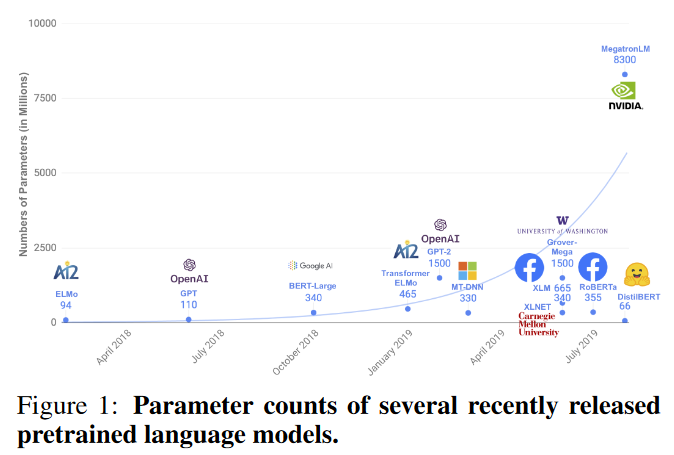
大模型微调:参数高效微调(PEFT)方法总结
PEFT (Parameter-Efficient Fine-Tuning) 参数高效微调是一种针对大模型微调的技术,旨在减少微调过程中需要调整的参数量,同时保持或提高模型的性能。 以LORA、Adapter Tuning 和 Prompt Tuning 为主的PEFT方法总结如下 LORA 论文题目:LORA:…...

Spark+实例解读
第一部分 Spark入门 学习教程:Spark 教程 | Spark 教程 Spark 集成了许多大数据工具,例如 Spark 可以处理任何 Hadoop 数据源,也能在 Hadoop 集群上执行。大数据业内有个共识认为,Spark 只是Hadoop MapReduce 的扩展(…...

WPF多语言国际化,中英文切换
通过切换资源文件的形式实现中英文一键切换 在项目中新建Language文件夹,添加资源字典(xaml文件),中文英文各一个。 在资源字典中写上想中英文切换的字符串,需要注意,必须指定key值,并且中英文…...
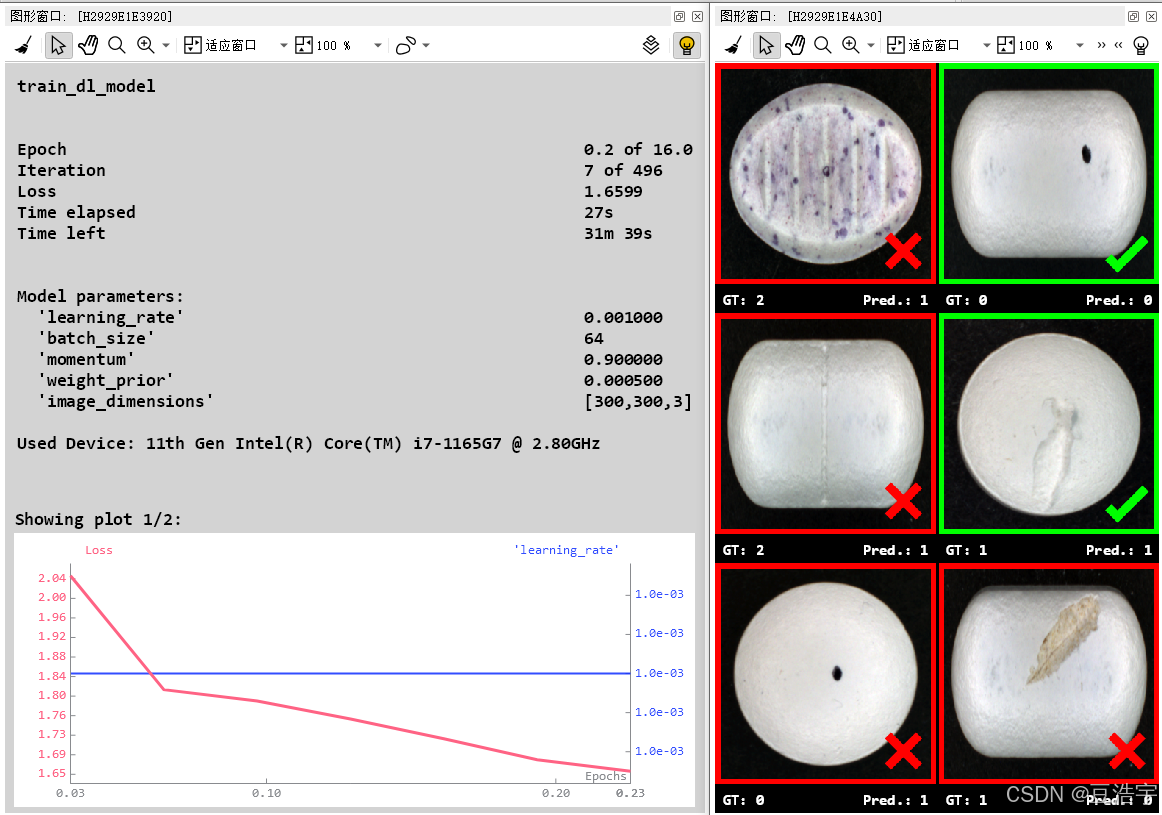
Halcon深度学习分类模型
1.Halcon20之后深度学习支持CPU训练模型,没有money买显卡的小伙伴有福了。但是缺点也很明显,就是训练速度超级慢,推理效果也没有GPU好,不过学习用足够。 2.分类模型是Halcon深度学习最简单的模型,可以用在物品分类&…...

AI驱动的网络安全:深度学习与LLM在威胁检测与教育中的应用
1. 项目概述:AI赋能的网络安全新范式在网络安全领域,我们正面临着一个日益严峻的悖论:一方面,攻击手段正变得前所未有的复杂和自动化;另一方面,74%的安全事件仍然源于人为因素。这种技术与人的双重挑战催生…...

NCCL watchdog timeout 先别只会加 timeout:PyTorch 新出的 Flight Recorder,真正值钱的是能把第一处 collective 分歧揪出来
NCCL watchdog timeout 先别只会加 timeout:PyTorch 新出的 Flight Recorder,真正值钱的是能把第一处 collective 分歧揪出来 很多人第一次遇到 NCCL watchdog timeout,第一反应都是三件事:查网络、调大 timeout、怀疑 NCCL 又炸了。这个顺序经常不够用。因为在很多真实训…...

C++ 时间戳实战:从GetTickCount64到std::chrono的跨平台精度选择
1. 为什么我们需要精确的时间戳? 在开发高性能应用时,时间戳的精度往往决定了程序的可靠性。想象一下,你在开发一个在线游戏服务器,玩家A声称自己先击中了玩家B,但服务器记录的两次命中时间差只有几毫秒。如果使用秒级…...

【研报 A111】中国生命科学AI行业发展蓝皮书:三阶段演进,2026年进入创造应用期
摘要:生命科学领域的AI赋能正迎来产业跃迁,AI4LS作为AIforScience最核心的应用场景,凭借处理多维复杂数据的天然优势,破解生命科学研发周期长、数据庞杂的痛点。当前行业正处于2.0预测阶段向3.0创造阶段的过渡期,Alpha…...

C#上位机开发入门:手把手教你用PowerPMAC SDK实现第一个通讯Demo
C#上位机开发入门:从零构建PowerPMAC通讯Demo的实战指南 引言 当你第一次打开PowerPMAC开发套件时,面对密密麻麻的库文件和数百页的技术手册,是否感到无从下手?作为工业自动化领域的核心控制器,PowerPMAC与上位机的通讯…...
安装配置学习分享教程(四篇连载)第四篇:ADT连接故障排查与环境迁移教程)
SAP-ABAP:ABAP Development Tools(ADT)安装配置学习分享教程(四篇连载)第四篇:ADT连接故障排查与环境迁移教程
ABAP Development Tools(ADT)安装配置学习分享教程(四篇连载) 第四篇:ADT连接故障排查与环境迁移教程 ADT连不上SAP后端?刚刚还好好的系统突然报错了?换了新电脑要重建整个开发环境?…...

CANN/asc-devkit SPM缓冲区写入API
WriteSpmBuffer 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode…...

宇树GO2机器人ROS2控制:从零到自主导航的完整指南
宇树GO2机器人ROS2控制:从零到自主导航的完整指南 【免费下载链接】go2_ros2_sdk Unofficial ROS2 SDK support for Unitree GO2 AIR/PRO/EDU 项目地址: https://gitcode.com/gh_mirrors/go/go2_ros2_sdk Unitree GO2 ROS2 SDK是一个专门为宇树科技GO2系列机…...
)
告别OrthoFinder限制:用IQtree+Notung搞定跨物种基因家族树(附兰科NB-ARC实战)
突破OrthoFinder局限:基于IQtree与Notung的跨物种基因家族进化分析实战 当你在研究一个特定基因家族的进化历程时,OrthoFinder的默认聚类机制可能会成为一道难以逾越的障碍。想象一下这样的场景:你精心收集了四个兰科物种的NB-ARC结构域序列&…...

气象数据分析实战:用Python+cinrad从雷达基数据中提取组合反射率并可视化
气象数据分析实战:用Pythoncinrad从雷达基数据中提取组合反射率并可视化 雷达基数据是气象业务和科研中的宝贵资源,尤其在强对流天气监测和短临预报中发挥着关键作用。对于气象从业者来说,如何高效地从原始雷达数据中提取组合反射率…...