Python酷库之旅-第三方库Pandas(067)
目录
一、用法精讲
266、pandas.Series.dt.second属性
266-1、语法
266-2、参数
266-3、功能
266-4、返回值
266-5、说明
266-6、用法
266-6-1、数据准备
266-6-2、代码示例
266-6-3、结果输出
267、pandas.Series.dt.microsecond属性
267-1、语法
267-2、参数
267-3、功能
267-4、返回值
267-5、说明
267-6、用法
267-6-1、数据准备
267-6-2、代码示例
267-6-3、结果输出
268、pandas.Series.dt.nanosecond属性
268-1、语法
268-2、参数
268-3、功能
268-4、返回值
268-5、说明
268-6、用法
268-6-1、数据准备
268-6-2、代码示例
268-6-3、结果输出
269、pandas.Series.dt.dayofweek属性
269-1、语法
269-2、参数
269-3、功能
269-4、返回值
269-5、说明
269-6、用法
269-6-1、数据准备
269-6-2、代码示例
269-6-3、结果输出
270、pandas.Series.dt.weekday属性
270-1、语法
270-2、参数
270-3、功能
270-4、返回值
270-5、说明
270-6、用法
270-6-1、数据准备
270-6-2、代码示例
270-6-3、结果输出
二、推荐阅读
1、Python筑基之旅
2、Python函数之旅
3、Python算法之旅
4、Python魔法之旅
5、博客个人主页



一、用法精讲
266、pandas.Series.dt.second属性
266-1、语法
# 266、pandas.Series.dt.second属性
pandas.Series.dt.second
The seconds of the datetime.266-2、参数
无
266-3、功能
用于从包含datetime对象的pandas系列中提取秒数。
266-4、返回值
返回一个包含每个datetime元素的秒数部分的Series对象。
266-5、说明
使用场景:
266-5-1、详细时间分析:需要对时间戳数据进行详细分析时,可以使用dt.second提取秒数。例如,分析每天不同秒数的分布情况。
266-5-2、时间过滤:根据秒数进行数据过滤。例如,筛选出在特定秒数发生的事件。
266-5-3、特征工程:在机器学习或数据挖掘中,将秒数作为特征之一,进行模型训练和预测。
266-5-4、性能优化:在时间序列数据处理中,提取秒数可以帮助进行更细粒度的性能分析和优化。
266-5-5、日志分析:在分析服务器日志或其他时间戳数据时,提取秒数可以帮助识别特定秒数内的访问模式或事件。
266-6、用法
266-6-1、数据准备
无266-6-2、代码示例
# 266、pandas.Series.dt.second属性
# 266-1、详细时间分析
import pandas as pd
# 创建一个包含10个时间戳的Series,每个时间戳间隔1秒
data = pd.Series(pd.date_range("2024-01-01", periods=10, freq="s"))
# 提取秒数
seconds = data.dt.second
print("详细时间分析-秒数部分:")
print(seconds, end='\n\n')# 266-2、时间过滤
import pandas as pd
# 创建一个包含100个时间戳的Series,每个时间戳间隔1秒
data = pd.Series(pd.date_range("2024-01-01", periods=100, freq="s"))
# 筛选出在特定秒数(例如30秒)发生的事件
filtered_data = data[data.dt.second == 30]
print("时间过滤-特定秒数的时间戳:")
print(filtered_data, end='\n\n')# 266-3、特征工程
import pandas as pd
# 创建一个包含10个时间戳的Series,每个时间戳间隔1秒
data = pd.Series(pd.date_range("2024-01-01", periods=10, freq="s"))
# 提取秒数并作为新列加入DataFrame
data = pd.DataFrame(data, columns=['datetime'])
data['second'] = data['datetime'].dt.second
print("特征工程-添加秒数特征:")
print(data, end='\n\n')# 266-4、性能优化
import pandas as pd
# 创建一个包含100个时间戳的Series,每个时间戳间隔1分钟
start_times = pd.Series(pd.date_range("2024-01-01 12:00:00", periods=100, freq="min"))
# 提取秒数
seconds = start_times.dt.second
# 筛选出秒数为0的时间点
zero_second_times = start_times[seconds == 0]
print("性能优化-秒数为0的时间点:")
print(zero_second_times, end='\n\n')# 266-5、日志分析
import pandas as pd
# 创建一个包含特定时间戳的Series
log_times = pd.Series(pd.to_datetime(["2024-01-01 00:00:10", "2024-01-01 00:00:20", "2024-01-01 00:00:30"]))
# 提取秒数
log_seconds = log_times.dt.second
print("日志分析-日志时间戳的秒数部分:")
print(log_seconds)266-6-3、结果输出
# 266、pandas.Series.dt.second属性
# 266-1、详细时间分析
# 详细时间分析-秒数部分:
# 0 0
# 1 1
# 2 2
# 3 3
# 4 4
# 5 5
# 6 6
# 7 7
# 8 8
# 9 9
# dtype: int32# 266-2、时间过滤
# 时间过滤-特定秒数的时间戳:
# 30 2024-01-01 00:00:30
# 90 2024-01-01 00:01:30
# dtype: datetime64[ns]# 266-3、特征工程
# 特征工程-添加秒数特征:
# datetime second
# 0 2024-01-01 00:00:00 0
# 1 2024-01-01 00:00:01 1
# 2 2024-01-01 00:00:02 2
# 3 2024-01-01 00:00:03 3
# 4 2024-01-01 00:00:04 4
# 5 2024-01-01 00:00:05 5
# 6 2024-01-01 00:00:06 6
# 7 2024-01-01 00:00:07 7
# 8 2024-01-01 00:00:08 8
# 9 2024-01-01 00:00:09 9# 266-4、性能优化
# 性能优化-秒数为0的时间点:
# 0 2024-01-01 12:00:00
# 1 2024-01-01 12:01:00
# 2 2024-01-01 12:02:00
# 3 2024-01-01 12:03:00
# 4 2024-01-01 12:04:00
# ...
# 95 2024-01-01 13:35:00
# 96 2024-01-01 13:36:00
# 97 2024-01-01 13:37:00
# 98 2024-01-01 13:38:00
# 99 2024-01-01 13:39:00
# Length: 100, dtype: datetime64[ns]# 266-5、日志分析
# 日志分析-日志时间戳的秒数部分:
# 0 10
# 1 20
# 2 30
# dtype: int32267、pandas.Series.dt.microsecond属性
267-1、语法
# 267、pandas.Series.dt.microsecond属性
pandas.Series.dt.microsecond
The microseconds of the datetime.267-2、参数
无
267-3、功能
用于提取时间序列数据中微秒部分的值。
267-4、返回值
返回一个包含时间序列中每个时间戳的微秒值的Series。
267-5、说明
无
267-6、用法
267-6-1、数据准备
无267-6-2、代码示例
# 267、pandas.Series.dt.microsecond属性
# 267-1、提取微秒值
import pandas as pd
# 创建一个包含微秒部分的时间戳的Series
time_series = pd.Series(pd.date_range("2024-01-01 00:00:00", periods=5, freq="333333us"))
# 提取微秒部分
microseconds = time_series.dt.microsecond
print("微秒值:")
print(microseconds, end='\n\n')# 267-2、筛选特定微秒值的时间戳
import pandas as pd
# 创建一个包含微秒部分的时间戳的Series
time_series = pd.Series(pd.date_range("2024-01-01 00:00:00", periods=10, freq="333333us"))
# 提取微秒部分
microseconds = time_series.dt.microsecond
# 筛选出微秒部分为333333的时间戳
filtered_time_series = time_series[microseconds == 333333]
print("微秒部分为333333的时间戳:")
print(filtered_time_series, end='\n\n')# 267-3、添加微秒列到DataFrame
import pandas as pd
# 创建一个包含微秒部分的时间戳的Series
time_series = pd.Series(pd.date_range("2024-01-01 00:00:00", periods=5, freq="333333us"))
# 创建DataFrame并添加微秒列
df = pd.DataFrame(time_series, columns=['datetime'])
df['microsecond'] = df['datetime'].dt.microsecond
print("添加微秒列的DataFrame:")
print(df, end='\n\n')# 267-4、详细时间分析-微秒部分
import pandas as pd
# 创建一个包含微秒部分的时间戳的Series
time_series = pd.Series(pd.date_range("2024-01-01 00:00:00", periods=10, freq="333333us"))
# 提取微秒部分
microseconds = time_series.dt.microsecond
print("详细时间分析-微秒部分:")
print(microseconds)267-6-3、结果输出
# 267、pandas.Series.dt.microsecond属性
# 267-1、提取微秒值
# 微秒值:
# 0 0
# 1 333333
# 2 666666
# 3 999999
# 4 333332
# dtype: int32# 267-2、筛选特定微秒值的时间戳
# 微秒部分为333333的时间戳:
# 1 2024-01-01 00:00:00.333333
# dtype: datetime64[ns]# 267-3、添加微秒列到DataFrame
# 添加微秒列的DataFrame:
# datetime microsecond
# 0 2024-01-01 00:00:00.000000 0
# 1 2024-01-01 00:00:00.333333 333333
# 2 2024-01-01 00:00:00.666666 666666
# 3 2024-01-01 00:00:00.999999 999999
# 4 2024-01-01 00:00:01.333332 333332# 267-4、详细时间分析-微秒部分
# 详细时间分析-微秒部分:
# 0 0
# 1 333333
# 2 666666
# 3 999999
# 4 333332
# 5 666665
# 6 999998
# 7 333331
# 8 666664
# 9 999997
# dtype: int32268、pandas.Series.dt.nanosecond属性
268-1、语法
# 268、pandas.Series.dt.nanosecond属性
pandas.Series.dt.nanosecond
The nanoseconds of the datetime.268-2、参数
无
268-3、功能
用于提取时间序列数据中纳秒部分的值。
268-4、返回值
返回一个包含时间序列中每个时间戳的纳秒值的Series。
268-5、说明
无
268-6、用法
268-6-1、数据准备
无268-6-2、代码示例
# 268、pandas.Series.dt.nanosecond属性
# 268-1、提取纳秒值
import pandas as pd
# 创建一个包含纳秒部分的时间戳的Series
time_series = pd.Series(pd.date_range("2024-01-01 00:00:00", periods=5, freq="333333333ns"))
# 提取纳秒部分
nanoseconds = time_series.dt.nanosecond
print("纳秒值:")
print(nanoseconds, end='\n\n')# 268-2、筛选特定纳秒值的时间戳
import pandas as pd
# 创建一个包含纳秒部分的时间戳的Series
time_series = pd.Series(pd.date_range("2024-01-01 00:00:00", periods=10, freq="333333333ns"))
# 提取纳秒部分
nanoseconds = time_series.dt.nanosecond
# 筛选出纳秒部分为333333333的时间戳
filtered_time_series = time_series[nanoseconds == 333333333]
print("纳秒部分为333333333的时间戳:")
print(filtered_time_series, end='\n\n')# 268-3、添加纳秒列到DataFrame
import pandas as pd
# 创建一个包含纳秒部分的时间戳的Series
time_series = pd.Series(pd.date_range("2024-01-01 00:00:00", periods=5, freq="333333333ns"))
# 创建DataFrame并添加纳秒列
df = pd.DataFrame(time_series, columns=['datetime'])
df['nanosecond'] = df['datetime'].dt.nanosecond
print("添加纳秒列的DataFrame:")
print(df, end='\n\n')# 268-4、详细时间分析-纳秒部分
import pandas as pd
# 创建一个包含纳秒部分的时间戳的Series
time_series = pd.Series(pd.date_range("2024-01-01 00:00:00", periods=10, freq="333333333ns"))
# 提取纳秒部分
nanoseconds = time_series.dt.nanosecond
print("详细时间分析-纳秒部分:")
print(nanoseconds)268-6-3、结果输出
# 268、pandas.Series.dt.nanosecond属性
# 268-1、提取纳秒值
# 纳秒值:
# 0 0
# 1 333
# 2 666
# 3 999
# 4 332
# dtype: int32# 268-2、筛选特定纳秒值的时间戳
# 纳秒部分为333333333的时间戳:
# Series([], dtype: datetime64[ns])# 268-3、添加纳秒列到DataFrame
# 添加纳秒列的DataFrame:
# datetime nanosecond
# 0 2024-01-01 00:00:00.000000000 0
# 1 2024-01-01 00:00:00.333333333 333
# 2 2024-01-01 00:00:00.666666666 666
# 3 2024-01-01 00:00:00.999999999 999
# 4 2024-01-01 00:00:01.333333332 332# 268-4、详细时间分析-纳秒部分
# 详细时间分析-纳秒部分:
# 0 0
# 1 333
# 2 666
# 3 999
# 4 332
# 5 665
# 6 998
# 7 331
# 8 664
# 9 997
# dtype: int32269、pandas.Series.dt.dayofweek属性
269-1、语法
# 269、pandas.Series.dt.dayofweek属性
pandas.Series.dt.dayofweek
The day of the week with Monday=0, Sunday=6.Return the day of the week. It is assumed the week starts on Monday, which is denoted by 0 and ends on Sunday which is denoted by 6. This method is available on both Series with datetime values (using the dt accessor) or DatetimeIndex.Returns:
Series or Index
Containing integers indicating the day number.269-2、参数
无
269-3、功能
用于获取日期时间序列中每个日期的星期几的属性,具备此功能的还有pandas.Series.dt.day_of_week属性。
269-4、返回值
返回一个整数值,表示一周中的星期几,其中0代表星期一,6代表星期天。
269-5、说明
使用场景:
269-5-1、工作日和周末分析:在进行销售、流量或其他业务指标的分析时,可以使用该属性来区分工作日和周末,从而更好地理解客户行为模式。
269-5-2、时间序列数据的聚合:可以根据星期几对数据进行分组,从而计算每个星期几的平均值、总和或其他统计信息。例如,分析每周的销售额变化趋势。
269-5-3、调度和排班:在员工排班或资源调度中,可以利用该属性来确定哪些日期是工作日,进而制定合理的工作安排。
269-5-4、季节性趋势分析:在一些行业(如零售、旅游等),不同星期几的销售或用户活动可能存在显著差异,通过分析这些差异可以帮助制定更有效的营销策略。
269-5-5、数据清洗和预处理:在处理时间序列数据时,可以利用该属性筛选出特定的日期,例如只保留工作日的数据,去除周末的数据。
269-5-6、事件驱动分析:对于特定事件(如假期、促销活动等)的影响分析,可以使用星期几信息来比较这些事件在不同日期的效果。
269-6、用法
269-6-1、数据准备
无269-6-2、代码示例
# 269、pandas.Series.dt.dayofweek属性
# 269-1、工作日和周末分析
import pandas as pd
# 创建一个包含日期的数据
data = {'date': pd.date_range(start='2024-08-01', periods=10)}
df = pd.DataFrame(data)
# 提取星期几
df['day_of_week'] = df['date'].dt.dayofweek
# 标记工作日和周末
df['is_weekend'] = df['day_of_week'] >= 5
print(df, end='\n\n')# 269-2、时间序列数据的聚合
import pandas as pd
# 创建一个示例数据框
data = {'date': pd.date_range(start='2024-08-01', periods=30),'sales': range(30)}
df = pd.DataFrame(data)
# 提取星期几并进行分组
df['day_of_week'] = df['date'].dt.dayofweek
weekly_sales = df.groupby('day_of_week')['sales'].sum()
print(weekly_sales, end='\n\n')# 269-3、调度和排班
import pandas as pd
# 创建一个包含日期的数据
data = {'date': pd.date_range(start='2024-08-01', periods=10)}
df = pd.DataFrame(data)
# 提取星期几
df['day_of_week'] = df['date'].dt.dayofweek
# 根据星期几制定排班计划
df['shift'] = df['day_of_week'].apply(lambda x: 'Morning' if x < 5 else 'Day Off')
print(df, end='\n\n')# 269-4、季节性趋势分析
import pandas as pd
import numpy as np
# 创建一个包含日期和销售额的数据
np.random.seed(0)
data = {'date': pd.date_range(start='2024-01-01', periods=365),'sales': np.random.randint(100, 1000, size=365)}
df = pd.DataFrame(data)
# 提取星期几
df['day_of_week'] = df['date'].dt.dayofweek
# 计算每个星期几的平均销售额
weekly_avg_sales = df.groupby('day_of_week')['sales'].mean()
print(weekly_avg_sales, end='\n\n')# 269-5、数据清洗和预处理
import pandas as pd
# 创建一个包含日期和数据的示例
data = {'date': pd.date_range(start='2024-01-01', periods=10),'value': range(10)}
df = pd.DataFrame(data)
# 提取星期几
df['day_of_week'] = df['date'].dt.dayofweek
# 只保留工作日的数据
df_weekdays = df[df['day_of_week'] < 5]
print(df_weekdays, end='\n\n')# 269-6、事件驱动分析
import pandas as pd
# 创建一个包含日期和事件的数据
data = {'date': pd.date_range(start='2024-01-01', periods=10),'event': ['Promotion', 'Regular', 'Promotion', 'Regular', 'Promotion', 'Regular', 'Regular', 'Promotion', 'Regular', 'Promotion']}
df = pd.DataFrame(data)
# 提取星期几
df['day_of_week'] = df['date'].dt.dayofweek
# 按照星期几和事件类型进行聚合
event_analysis = df.groupby(['day_of_week', 'event']).size().unstack(fill_value=0)
print(event_analysis)269-6-3、结果输出
# 269、pandas.Series.dt.dayofweek属性
# 269-1、工作日和周末分析
# date day_of_week is_weekend
# 0 2024-08-01 3 False
# 1 2024-08-02 4 False
# 2 2024-08-03 5 True
# 3 2024-08-04 6 True
# 4 2024-08-05 0 False
# 5 2024-08-06 1 False
# 6 2024-08-07 2 False
# 7 2024-08-08 3 False
# 8 2024-08-09 4 False
# 9 2024-08-10 5 True# 269-2、时间序列数据的聚合
# day_of_week
# 0 58
# 1 62
# 2 66
# 3 70
# 4 75
# 5 50
# 6 54
# Name: sales, dtype: int64# 269-3、调度和排班
# date day_of_week shift
# 0 2024-08-01 3 Morning
# 1 2024-08-02 4 Morning
# 2 2024-08-03 5 Day Off
# 3 2024-08-04 6 Day Off
# 4 2024-08-05 0 Morning
# 5 2024-08-06 1 Morning
# 6 2024-08-07 2 Morning
# 7 2024-08-08 3 Morning
# 8 2024-08-09 4 Morning
# 9 2024-08-10 5 Day Off# 269-4、季节性趋势分析
# day_of_week
# 0 580.943396
# 1 493.384615
# 2 630.538462
# 3 484.019231
# 4 548.192308
# 5 583.346154
# 6 547.403846
# Name: sales, dtype: float64# 269-5、数据清洗和预处理
# date value day_of_week
# 0 2024-01-01 0 0
# 1 2024-01-02 1 1
# 2 2024-01-03 2 2
# 3 2024-01-04 3 3
# 4 2024-01-05 4 4
# 7 2024-01-08 7 0
# 8 2024-01-09 8 1
# 9 2024-01-10 9 2# 269-6、事件驱动分析
# event Promotion Regular
# day_of_week
# 0 2 0
# 1 0 2
# 2 2 0
# 3 0 1
# 4 1 0
# 5 0 1
# 6 0 1270、pandas.Series.dt.weekday属性
270-1、语法
# 270、pandas.Series.dt.weekday属性
pandas.Series.dt.weekday
The day of the week with Monday=0, Sunday=6.Return the day of the week. It is assumed the week starts on Monday, which is denoted by 0 and ends on Sunday which is denoted by 6. This method is available on both Series with datetime values (using the dt accessor) or DatetimeIndex.Returns:
Series or Index
Containing integers indicating the day number.270-2、参数
无
270-3、功能
用于提取datetime对象的星期几。
270-4、返回值
返回值是一个整数,其中0表示星期一,1表示星期二,以此类推,6表示星期日。
270-5、说明
使用场景:
270-5-1、数据分析:在进行数据分析时,了解某些事件发生的星期几可以帮助识别趋势。例如,某些销售数据可能在周末更高,而其他业务则可能在工作日更繁忙。
270-5-2、数据可视化:在绘制图表时,可以根据星期几对数据进行分组,从而更清晰地展示不同时间段的行为模式。例如,使用条形图展示每周各天的销售额。
270-5-3、业务决策:在制定营销策略时,了解客户行为与星期几的关系可以帮助优化广告投放时间和促销活动。例如,可以在特定的日子进行促销,以吸引更多顾客。
270-5-4、调度与规划:在项目管理或人力资源调度中,可以根据工作日和休息日来安排任务或人员,确保工作效率最大化。
270-5-5、时间序列分析:在时间序列数据分析中,提取星期几信息可以作为特征之一,帮助构建更精准的预测模型。
270-5-6、事件记录与跟踪:在记录事件发生时间时,可以使用星期几来分析事件的发生频率与特定日期的关系,比如员工请假、客户投诉等。
270-6、用法
270-6-1、数据准备
无270-6-2、代码示例
# 270、pandas.Series.dt.weekday属性
# 270-1、数据分析:识别销售趋势
import pandas as pd
# 创建示例销售数据
data = {'date': pd.date_range(start='2024-01-01', periods=30),'sales': [200, 220, 210, 230, 250, 270, 300, 320, 310, 330, 340, 350,360, 370, 380, 390, 400, 410, 420, 430, 440, 450, 460, 470,480, 490, 500, 510, 520, 530]
}
df = pd.DataFrame(data)
# 提取星期几
df['weekday'] = df['date'].dt.weekday
# 计算每天的平均销售额
average_sales_by_weekday = df.groupby('weekday')['sales'].mean()
print(average_sales_by_weekday, end='\n\n')# 270-2、数据可视化:展示每周各天的销售额
import pandas as pd
import matplotlib.pyplot as plt
# 创建示例销售数据
data = {'date': pd.date_range(start='2024-01-01', periods=30),'sales': [200, 220, 210, 230, 250, 270, 300, 320, 310, 330, 340, 350,360, 370, 380, 390, 400, 410, 420, 430, 440, 450, 460, 470,480, 490, 500, 510, 520, 530]
}
df = pd.DataFrame(data)
df['weekday'] = df['date'].dt.weekday
# 按星期几分组并计算总销售额
total_sales_by_weekday = df.groupby('weekday')['sales'].sum()
# 绘制条形图
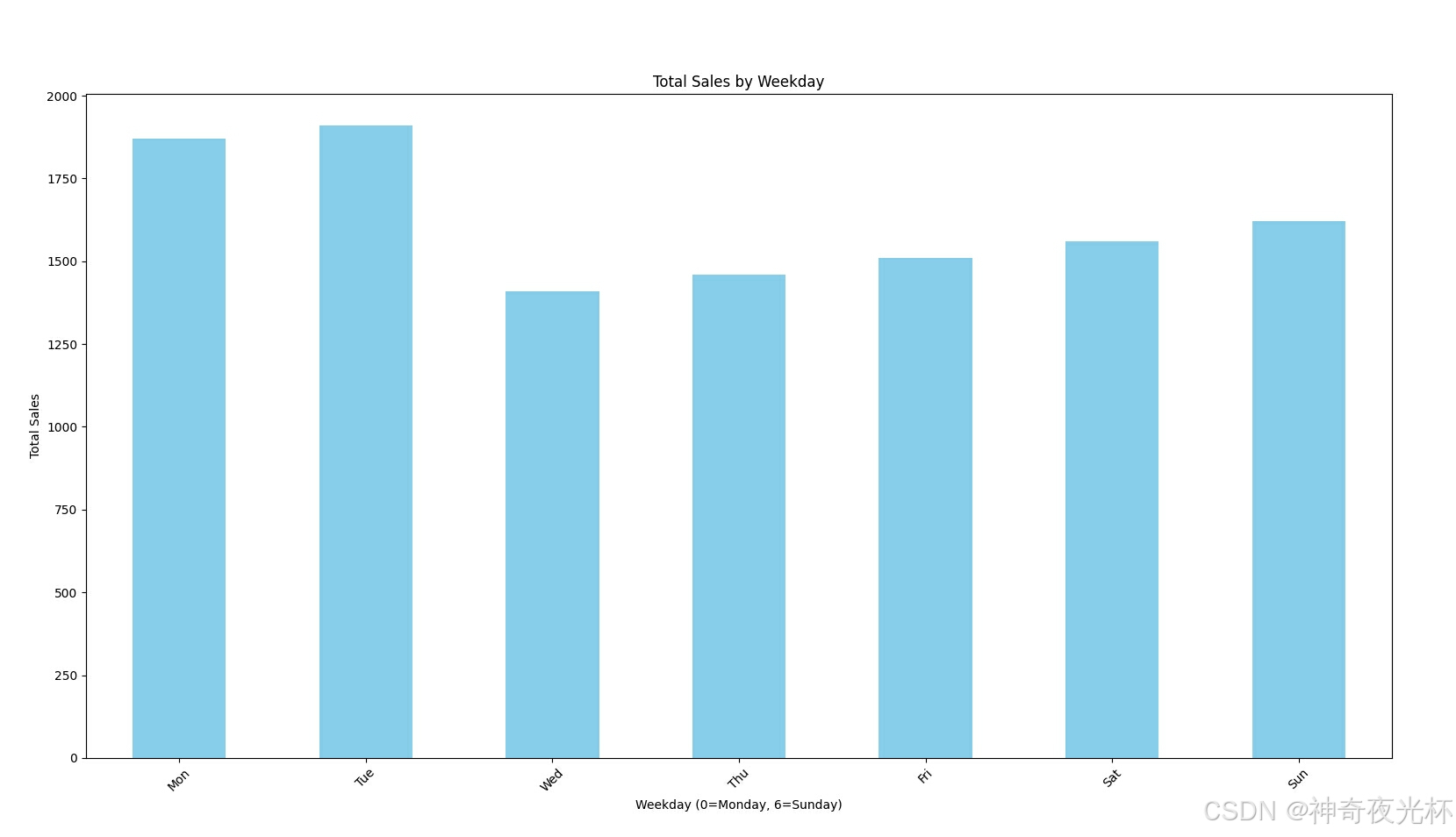
total_sales_by_weekday.plot(kind='bar', color='skyblue')
plt.xlabel('Weekday (0=Monday, 6=Sunday)')
plt.ylabel('Total Sales')
plt.title('Total Sales by Weekday')
plt.xticks(ticks=range(7), labels=['Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun'], rotation=45)
plt.show()# 270-3、业务决策:优化广告投放时间
import pandas as pd
# 创建示例广告投放数据
data = {'ad_date': pd.date_range(start='2024-01-01', periods=30),'ad_cost': [1000, 1200, 1100, 1300, 1500, 1600, 1700, 1800, 1750, 1900,2000, 2100, 2200, 2300, 2400, 2500, 2600, 2700, 2800, 2900,3000, 3100, 3200, 3300, 3400, 3500, 3600, 3700, 3800, 3900]
}
df = pd.DataFrame(data)
# 提取星期几
df['weekday'] = df['ad_date'].dt.weekday
# 计算广告成本按星期几的总和
ad_cost_by_weekday = df.groupby('weekday')['ad_cost'].sum()
print(ad_cost_by_weekday, end='\n\n')# 270-4、调度与规划:安排任务或人员
import pandas as pd
# 创建示例任务数据
tasks = {'task_date': pd.date_range(start='2024-01-01', periods=30),'task': ['Task {}'.format(i) for i in range(30)]
}
df = pd.DataFrame(tasks)
# 提取星期几
df['weekday'] = df['task_date'].dt.weekday
# 按星期几分配任务
tasks_by_weekday = df.groupby('weekday')['task'].count()
print(tasks_by_weekday, end='\n\n')# 270-5、时间序列分析:构建预测模型特征
import pandas as pd
# 创建示例时间序列数据
data = {'date': pd.date_range(start='2024-01-01', periods=100),'value': range(100)
}
df = pd.DataFrame(data)
# 提取星期几作为特征
df['weekday'] = df['date'].dt.weekday
print(df.head(), end='\n\n')# 270-6、事件记录与跟踪:分析事件发生频率
import pandas as pd
# 创建示例事件数据
events = {'event_date': pd.date_range(start='2024-01-01', periods=50),'event_type': ['Type {}'.format(i % 5) for i in range(50)]
}
df = pd.DataFrame(events)
# 提取星期几
df['weekday'] = df['event_date'].dt.weekday
# 统计每星期几的事件数量
events_by_weekday = df.groupby('weekday').size()
print(events_by_weekday)270-6-3、结果输出
# 270、pandas.Series.dt.weekday属性
# 270-1、数据分析:识别销售趋势
# weekday
# 0 374.0
# 1 382.0
# 2 352.5
# 3 365.0
# 4 377.5
# 5 390.0
# 6 405.0
# Name: sales, dtype: float64# 270-2、数据可视化:展示每周各天的销售额
# 见图1# 270-3、业务决策:优化广告投放时间
# weekday
# 0 12100
# 1 12550
# 2 8900
# 3 9400
# 4 9900
# 5 10300
# 6 10700
# Name: ad_cost, dtype: int64# 270-4、调度与规划:安排任务或人员
# weekday
# 0 5
# 1 5
# 2 4
# 3 4
# 4 4
# 5 4
# 6 4
# Name: task, dtype: int64# 270-5、时间序列分析:构建预测模型特征
# date value weekday
# 0 2024-01-01 0 0
# 1 2024-01-02 1 1
# 2 2024-01-03 2 2
# 3 2024-01-04 3 3
# 4 2024-01-05 4 4# 270-6、事件记录与跟踪:分析事件发生频率
# weekday
# 0 8
# 1 7
# 2 7
# 3 7
# 4 7
# 5 7
# 6 7
# dtype: int64图1:
二、推荐阅读
1、Python筑基之旅
2、Python函数之旅
3、Python算法之旅
4、Python魔法之旅
5、博客个人主页
相关文章:
Python酷库之旅-第三方库Pandas(067)
目录 一、用法精讲 266、pandas.Series.dt.second属性 266-1、语法 266-2、参数 266-3、功能 266-4、返回值 266-5、说明 266-6、用法 266-6-1、数据准备 266-6-2、代码示例 266-6-3、结果输出 267、pandas.Series.dt.microsecond属性 267-1、语法 267-2、参数 …...
Spring快速学习
目录 IOC控制反转 引言 IOC案例 Bean的作用范围 Bean的实例化 bean生命周期 DI 依赖注入 setter注入 构造器注入 自动装配 自动装配的方式 注意事项; 集合注入 核心容器 容器的创建方式 Bean的三种获取方式 Bean和依赖注入相关总结 IOC/DI注解开发 注解开发…...

【Web开发手礼】探索Web开发的秘密(十五)-Vue2(2)AJAX、前后端分离、前端工程化
主要介绍了AJAX、前后端分离所需的YApi、前端工程化所需要的环境安装!!! 目录 前言 AJAX 原生Ajax Axios Axios入门 案例 前后端分离开发 YApi 前端工程化 环境准备 总结 前言 主要介绍了AJAX、前后端分离所需的YApi、前端工…...

Phalco安装过程以及踩的一些坑(mac环境)
一 背景 公司用Phalcon框架好长时间了,中途发现了一些Phalcon使用的上的问题,于是想在本地搭建一套Phalcon的环境,方便排查问题使用。 二 Mac系统下的安装 看了很多说法,最终发现还是官网给力,安装Phalcon使用下列命令即可(前提条件是PHP已安装好,工具pecl也安装好了):…...

Ubuntu修改双系统默认启动顺序
1.打开grub的默认启动配置文件 sudo gedit /etc/default/grub# If you change this file, run update-grub afterwards to update # /boot/grub/grub.cfg. # For full documentation of the options in this file, see: # info -f grub -n Simple configurationGRUB_DEFAULT…...

高仲富:49岁搞AI,白天种菜卖菜,晚上学数学搞程序
这是《开发者说》的第13期,本期我们邀请的开发者是高仲富,曾是一位数学老师,自学成为一名程序员,在北京漂过,后逃回了成都,一边与病魔抗争,一边写代码,一写就是15年,制作…...
光线追踪(纹理映射)
最近在跟着ray trace in one week来学习光线追踪(很多概念茅塞顿开)做到一半想着记录一下(比较随心)上面是之前的效果。ray trace in one week Texture Coordinates for Spheres(球体纹理坐标) u, v 纹理…...

传统产品经理VS现在AI产品经理,你要学习的太多了,超详细收藏我这一篇就够了
传统产品经理想要转行成为AI产品经理,需要经历一系列的学习和实践过程。下面是一份详细的学习路线图,旨在帮助你顺利转型。 学习路线图 了解AI基础知识 AI概览:阅读《人工智能:一种现代的方法》这样的书籍,以获得对AI…...
C#使用Socket实现TCP服务器端
1、TCP服务器实现代码 using System; using System.Collections.Generic; using System.Linq; using System.Net; using System.Net.Sockets; using System.Text; using System.Threading; using System.Threading.Tasks;namespace PtLib.TcpServer {public delegate void Tcp…...
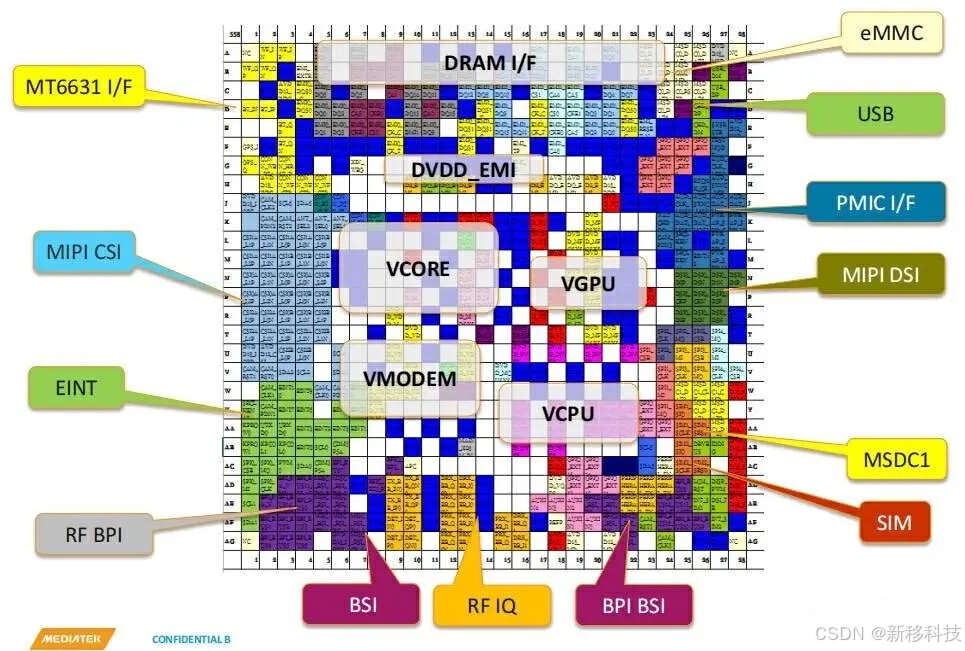
MTK联发科MT8766/MT8166安卓核心板性能参数对
MT8766核心板 采用联发科四核2G主频芯片方案,国内4G全网通。12nm先进工艺,支持 Android9.0系统。 GPU 采用超强 IMG GE8300 ,主频600MHz。支持高速LPDDR4/X,主频高达1600MHz。支持EMMC5.1。标配 WIFI 802.11 ac/abgn,BT 5.0。 支持…...
ps绘制动图
ps绘制动图教程(简易版)-直播gif动态效果图 第一步 打开ps绘制几个简单的长方形 第二步 将图层转化为智能图层 第三部 在窗口找到时间轴创建时间轴 第五步 通过变换来鼠标控制图像的变化并打下结束点 第六部 通过图像中的图像大小控制gif的大小 第七部 …...

AI学习指南机器学习篇-强化学习和深度学习简介
AI学习指南机器学习篇-强化学习和深度学习简介 强化学习和深度学习基本概念回顾 强化学习是一种机器学习方法,其目标是让智能体通过与环境的交互来学习最优的行为策略。在强化学习中,智能体不需要标记的训练数据,而是通过试错来提升自己的表…...

yolov8 bytetrack onnx模型推理
原文:yolov8 bytetrack onnx模型推理 - 知乎 (zhihu.com) 一、pt模型转onnx from ultralytics import YOLO# Load a model model YOLO(weights/yolov8s.pt) # load an official model # model YOLO(path/to/best.pt) # load a custom trained# Export the mod…...

ImageNet数据集和CIFAR-10数据集
一、为什么需要大量数据集 人工智能其实就是大数据的时代,无论是目标检测、图像分类、还是现在植入我们生活的推荐系统,“喂入”神经网络的数据越多,则识别效果越好、分类越准确。因此开源大型数据集的研究团队为人工智能的发展做了大量贡献…...

Go语言编程大全,web微服务数据库十大专题精讲
本课程主要从数据结构、Go Module 依赖管理、IO编程、数据库编程、消息队列、加密技术与网络安全、爬虫与反爬虫、web开发、微服务通用技术、Kitex框架等方面讲解~ 链接:https://pan.quark.cn/s/d65337a0e60d...
【LabVIEW学习篇 - 13】:队列
文章目录 队列 队列 队列通常情况下是一种先入先出(FIFO:First in First out)的数据结构,常用作数据缓存,通过队列结构可以保证数据有序的传递,避免竞争和冲突。 案例:利用队列,模…...

大语言模型综述泛读之Large Language Models: A Survey
摘要 这篇文章主要回顾了一些最突出的LLMs(GPT, LLaMA, PaLM)并讨论了它们的特点、贡献和局限性,就如何构建增强LLMs做了一个技术概述,然后调研了为LLM训练、微调和评估而准备的N多种流行数据集,审查了使用的LLM评价指标,在一组有代表性的基准上比较了几个流行的LLMs;最…...
奇偶函数的性质及运算
目录 定义 注意 特征 运算 拓展 定义 设函数f(x)的定义域D; 如果对于函数定义域D内的任意一个x,都有f(-x)-f(x),那么函数f(x)就叫做奇函数。如果对于函数定义域D内的任意一个x…...
代码随想录 day 32 动态规划
第九章 动态规划part01 今天正式开始动态规划! 理论基础 无论大家之前对动态规划学到什么程度,一定要先看 我讲的 动态规划理论基础。 如果没做过动态规划的题目,看我讲的理论基础,会有感觉 是不是简单题想复杂了? …...

支持目标检测的框架有哪些
目标检测是计算机视觉领域的一个重要任务,许多深度学习框架都提供了对目标检测的支持。以下是一些广泛使用的支持目标检测的深度学习框架: 1. TensorFlow TensorFlow 是一个广泛使用的开源深度学习框架,由Google开发。它提供了TensorFlow O…...
)
保姆级教程:在CentOS 7上用达梦8搭建DCA练习环境(附ulimit、VNC、ODBC全配置)
达梦8 DCA认证实战:CentOS 7环境搭建与调优全指南 在国产数据库技术快速发展的今天,达梦数据库作为核心产品之一,其DCA认证已成为众多从业者提升竞争力的重要选择。与理论为主的认证不同,DCA更注重实际操作能力,而一个…...

基于XGBoost与SHAP的分子气味预测:从特征工程到可解释性分析
1. 项目概述与核心价值在香水设计、食品风味工业乃至环境监测领域,一个核心且持久的挑战是:如何从分子的化学结构出发,准确预测其气味?这不仅仅是化学家或调香师的直觉游戏,更是一个复杂的、高维度的模式识别问题。传统…...

用C语言解决‘换硬币’问题?我来教你如何调试和验证你的循环逻辑
用C语言解决‘换硬币’问题?我来教你如何调试和验证你的循环逻辑 当你第一次面对"换硬币"这类组合问题时,那种既兴奋又困惑的感觉我至今记忆犹新。作为C语言初学者,理解多重循环的运作机制就像在迷宫中寻找出口——每次你以为找到了…...

高性能Windows流媒体服务器部署:5大核心技术与3种实战架构深度解析
高性能Windows流媒体服务器部署:5大核心技术与3种实战架构深度解析 【免费下载链接】srs-windows 项目地址: https://gitcode.com/gh_mirrors/sr/srs-windows 在Windows平台上构建专业级流媒体服务系统,需要综合考虑协议兼容性、性能优化和部署架…...

自制BLE112串口编程器:基于Bootloader的免调试器烧录方案
1. 项目概述:为BLE112模块打造一款免调试器的RS232编程器在嵌入式开发,特别是早期的蓝牙低功耗(BLE)模块应用中,我们常常会遇到一个棘手的问题:官方开发工具链的依赖和限制。以Silicon Labs(当时…...
两两交换链表中的节点)
力扣HOT100(30)两两交换链表中的节点
链表的交换要注意 “链表不断链”。前驱和后继都要连着迭代法(必学死磕!O (n) 时间,O (1) 空间)1. 为什么必须用虚拟头节点?因为交换后链表的头节点会变! 比如示例 1 中,原来的头是 1࿰…...

ARM PMU性能监控单元原理与实践指南
1. ARM PMU性能监控单元概述性能监控单元(PMU)是现代ARM处理器中用于硬件级性能分析的核心组件。它通过一组可编程的硬件计数器,实现对处理器内部各种关键事件的精确测量。这些事件涵盖了从指令执行、缓存访问到内存子系统行为等处理器活动的…...

告别浪费!SolidWorks企业级共享方案,实现降本增效全攻略
还在为 SolidWorks 高昂的硬件投入和混乱的图纸管理头疼?告别“一人一机”的浪费模式,企业级共享方案才是降本增效的正解。这套攻略基于“1 台高性能服务器 云飞云共享云桌面”架构,帮你把硬件成本砍掉 60%,把软件利用率翻倍。一…...

智能体所有权与版权:AI Agent Harness Engineering 创造的作品归谁所有?
1. 标题选项 《AI Agent创作版权迷局破解:从Harness工程原理到所有权划分的完整指南》 《智能体作品归谁?AI Agent Harness Engineering场景下的版权规则深度拆解》 《告别权属纠纷:一文搞懂AI Agent生成内容的所有权、版权与收益分配规则》 《Harness工程视角下的AI创作权:…...

SMUDebugTool终极指南:如何深度掌控AMD Ryzen处理器的隐藏性能
SMUDebugTool终极指南:如何深度掌控AMD Ryzen处理器的隐藏性能 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: ht…...