大数据处理学习笔记2.1 初识Spark
文章目录
- 零、本节学习目标
- 一、Spark的概述
- (一)Spark的组件
- 1、Spark Core
- 2、Spark SQL
- 3、Spark Streaming
- 4、MLlib
- 5、Graph X
- 6、独立调度器、Yarn、Mesos
- (二)Spark的发展史
- 1、发展简史
- 2、目前最新版本
- 二、Spark的特点
- (一)速度快
- (二)易用性
- (三)通用性
- (四)兼容性
- (五)代码简洁
- 1、采用MR实现词频统计
- 2、采用Spark实现词频统计
- 3、两种代码对比结论
- 三、Spark的应用场景
- (一)应用场景分类
- 1、数据科学
- 2、数据处理
- (二)使用Spark的公司
- 1、腾讯
- 2、Yahoo
- 3、淘宝
- 4、优酷土豆
- 四、Spark与Hadoop的对比
- (一)编程方式
- (二)数据存储
- (三)数据处理
- (四)数据容错
零、本节学习目标
- 了解什么是Spark计算框架
- 了解Spark计算框架的特点
- 了解Spark计算框架的应用场景
- 理解Spark框架与Hadoop框架的对比
一、Spark的概述
(一)Spark的组件
- Spark在
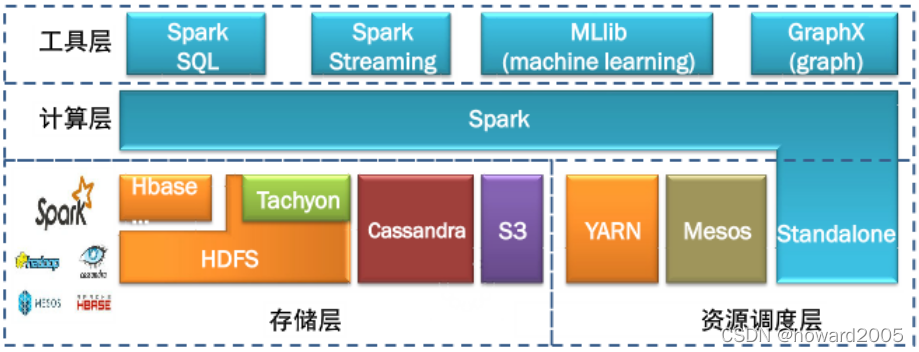
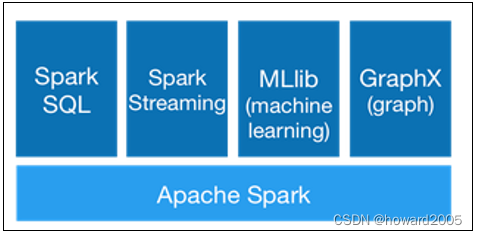
2013年加入Apache孵化器项目,之后获得迅猛的发展,并于2014年正式成为Apache软件基金会的顶级项目。Spark生态系统已经发展成为一个可应用于大规模数据处理的统一分析引擎,它是基于内存计算的大数据并行计算框架,适用于各种各样的分布式平台的系统。在Spark生态圈中包含了Spark SQL、Spark Streaming、GraphX、MLlib等组件。
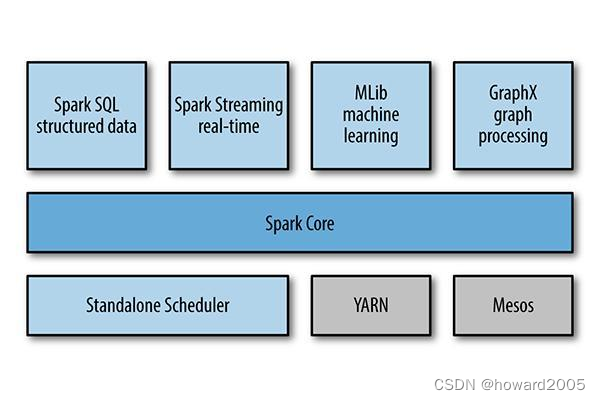
1、Spark Core
- Spark核心组件,实现了Spark的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。Spark Core中还包含对弹性分布式数据集的API定义。
2、Spark SQL
- 用来操作结构化数据的核心组件,通过Spark SQL可直接查询Hive、HBase等多种外部数据源中的数据。Spark SQL的重要特点是能够统一处理关系表和RDD。

3、Spark Streaming
- Spark提供的流式计算框架,支持高吞吐量、可容错处理的实时流式数据处理,其核心原理是将流数据分解成一系列短小的批处理作业。

4、MLlib
- Spark提供的关于机器学习功能的算法程序库,包括分类、回归、聚类、协同过滤算法等,还提供了模型评估、数据导入等额外的功能。
5、Graph X
- Spark提供的分布式图处理框架,拥有对图计算和图挖掘算法的API接口及丰富的功能和运算符,便于对分布式图处理的需求,能在海量数据上运行复杂的图算法。

6、独立调度器、Yarn、Mesos
- 集群管理器,负责Spark框架高效地在一个到数千个节点之间进行伸缩计算的资源管理。
(二)Spark的发展史
1、发展简史
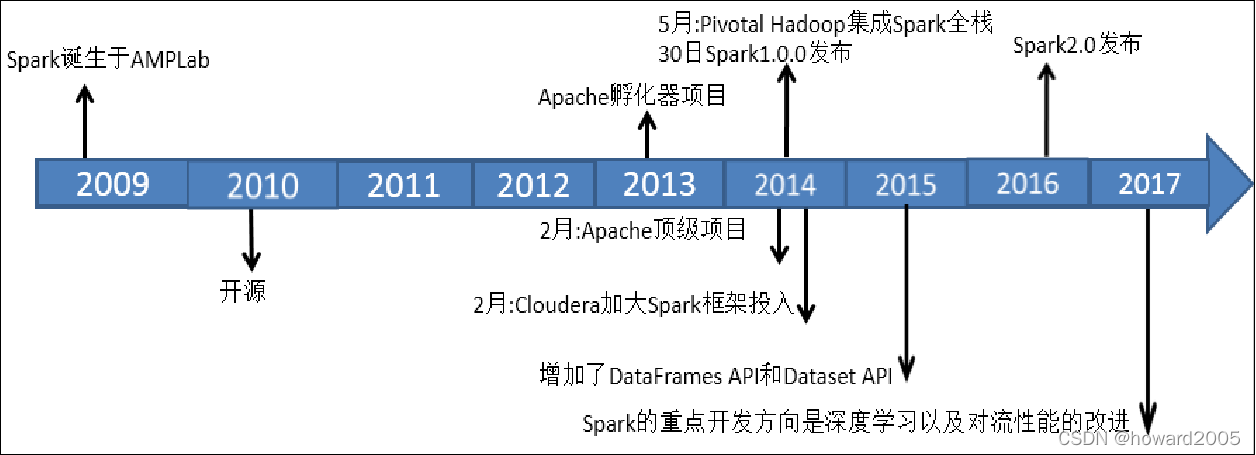
- 对于一个具有相当技术门槛与复杂度的平台,Spark从诞生到正式版本的成熟,经历的时间如此之短,让人感到惊诧。2009年,Spark诞生于伯克利大学AMPLab,最开初属于伯克利大学的研究性项目。它于2010年正式开源,并于2013年成为了Aparch基金项目,并于2014年成为Aparch基金的顶级项目,整个过程不到五年时间。
2、目前最新版本
- Spark目前最新版本是2023年2月17日发布的Spark3.3.2
二、Spark的特点
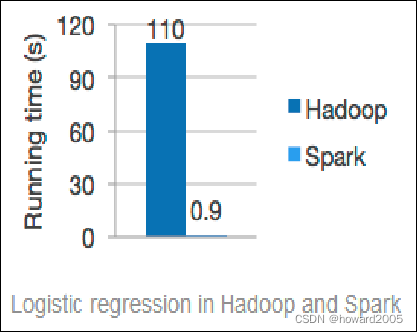
- Spark计算框架在处理数据时,所有的中间数据都保存在内存中,从而减少磁盘读写操作,提高框架计算效率。同时Spark还兼容HDFS、Hive,可以很好地与Hadoop系统融合,从而弥补MapReduce高延迟的性能缺点。所以说,Spark是一个更加快速、高效的大数据计算平台。
- Spark官网上给出Spark的特点

(一)速度快
- 与MapReduce相比,Spark可以支持包括Map和Reduce在内的更多操作,这些操作相互连接形成一个有向无环图(Directed Acyclic Graph,简称DAG),各个操作的中间数据则会被保存在内存中。因此处理速度比MapReduce更加快。Spark通过使用先进的DAG调度器、查询优化器和物理执行引擎,从而能够高性能的实现批处理和流数据处理。
(二)易用性
- Spark支持使用Scala、Python、Java及R语言快速编写应用。同时Spark提供超过80个高级运算符,使得编写并行应用程序变得容易并且可以在Scala、Python或R的交互模式下使用Spark。

(三)通用性
- Spark可以与SQL、Streaming及复杂的分析良好结合。Spark还有一系列的高级工具,包括Spark SQL、MLlib(机器学习库)、GraphX(图计算)和Spark Streaming,并且支持在一个应用中同时使用这些组件。
(四)兼容性
- 用户可以使用Spark的独立集群模式运行Spark,也可以在EC2(亚马逊弹性计算云)、Hadoop YARN或者Apache Mesos上运行Spark。并且可以从HDFS、Cassandra、HBase、Hive、Tachyon和任何分布式文件系统读取数据。

(五)代码简洁
- 参看【经典案例【词频统计】十一种实现方式】
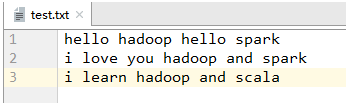
1、采用MR实现词频统计
- 编写词频统计映射器 -
WordCountMapper
package net.hw.wc;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {@Overrideprotected void map(LongWritable key, Text value, Context context)throws IOException, InterruptedException {// 获取行内容String line = value.toString();// 按空格拆分得到单词数组String[] words = line.split(" ");// 遍历单词数组,生成输出键值对for (int i = 0; i < words.length; i++) {context.write(new Text(words[i]), new IntWritable(1));}}
}
- 编写词频统计归约器 -
WordCountReducer
package net.hw.wc;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Context context)throws IOException, InterruptedException {// 定义键出现次数int count = 0;// 遍历输入值迭代器for (IntWritable value : values) {count += value.get(); // 其实针对此案例,可用count++来处理}// 输出新的键值对,注意要将java的int类型转换成hadoop的IntWritable类型context.write(key, new IntWritable(count));}
}
- 编写词频统计驱动器 -
WordCountDriver
package net.hw.wc;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.net.URI;public class WordCountDriver {public static void main(String[] args) throws Exception {// 创建配置对象Configuration conf = new Configuration();// 设置数据节点主机名属性conf.set("dfs.client.use.datanode.hostname", "true");// 获取作业实例Job job = Job.getInstance(conf);// 设置作业启动类job.setJarByClass(WordCountDriver.class);// 设置Mapper类job.setMapperClass(WordCountMapper.class);// 设置map任务输出键类型job.setMapOutputKeyClass(Text.class);// 设置map任务输出值类型job.setMapOutputValueClass(IntWritable.class);// 设置Reducer类job.setReducerClass(WordCountReducer.class);// 设置reduce任务输出键类型job.setOutputKeyClass(Text.class);// 设置reduce任务输出值类型job.setOutputValueClass(IntWritable.class);// 定义uri字符串String uri = "hdfs://master:9000";// 创建输入目录Path inputPath = new Path(uri + "/word/input");// 创建输出目录Path outputPath = new Path(uri + "/word/result");// 获取文件系统FileSystem fs = FileSystem.get(new URI(uri), conf);// 删除输出目录(第二个参数设置是否递归)fs.delete(outputPath, true);// 给作业添加输入目录(允许多个)FileInputFormat.addInputPath(job, inputPath);// 给作业设置输出目录(只能一个)FileOutputFormat.setOutputPath(job, outputPath);// 等待作业完成job.waitForCompletion(true);// 输出统计结果System.out.println("======统计结果======");FileStatus[] fileStatuses = fs.listStatus(outputPath);for (int i = 1; i < fileStatuses.length; i++) {// 输出结果文件路径System.out.println(fileStatuses[i].getPath());// 获取文件系统数据字节输入流FSDataInputStream in = fs.open(fileStatuses[i].getPath());// 将结果文件显示在控制台IOUtils.copyBytes(in, System.out, 4096, false);}}
}
- 运行程序WordCountDriver,查看结果
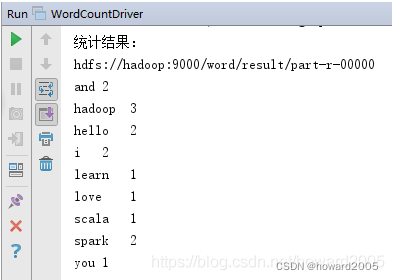
2、采用Spark实现词频统计
- 编写词频统计对象 -
WordCount
package net.hw.spark.wcimport org.apache.spark.{SparkConf, SparkContext}object WordCount {def main(args: Array[String]): Unit = {val conf = new SparkConf().setMaster("local").setAppName("wordcount")val sc = new SparkContext(conf)val rdd = sc.textFile("test.txt").flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)rdd.foreach(println)rdd.saveAsTextFile("result")}
}
- 启动程序,查看结果
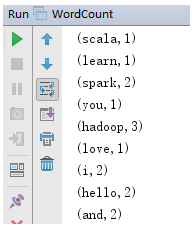
3、两种代码对比结论
- 大家可以看出,完成同样的词频统计任务,Spark代码比MapReduce代码简洁很多。
三、Spark的应用场景
(一)应用场景分类
1、数据科学
- 数据工程师可以利用Spark进行数据分析与建模,由于Spark具有良好的易用性,数据工程师只需要具备一定的SQL语言基础、统计学、机器学习等方面的经验,以及使用Python、Matlab或者R语言的基础编程能力,就可以使用Spark进行上述工作。
2、数据处理
- 大数据工程师将Spark技术应用于广告、报表、推荐系统等业务中,在广告业务中,利用Spark系统进行应用分析、效果分析、定向优化等业务,在推荐系统业务中,利用Spark内置机器学习算法训练模型数据,进行个性化推荐及热点点击分析等业务。
(二)使用Spark的公司
1、腾讯
- 广点通是最早使用Spark的应用之一。腾讯大数据精准推荐借助Spark快速迭代的优势,围绕“
数据+算法+系统”这套技术方案,实现了在“数据实时采集、算法实时训练、系统实时预测”的全流程实时并行高维算法,最终成功应用于广点通pCTR (Predict Click-Through Rate) 投放系统上,支持每天上百亿的请求量。
2、Yahoo
- Yahoo将Spark用在Audience Expansion中。Audience Expansion是广告中寻找目标用户的一种方法,首先广告者提供一些观看了广告并且购买产品的样本客户,据此进行学习,寻找更多可能转化的用户,对他们定向广告。Yahoo采用的算法是
Logistic Regression。同时由于某些SQL负载需要更高的服务质量,又加入了专门跑Shark的大内存集群,用于取代商业BI/OLAP工具,承担报表/仪表盘和交互式/即席查询,同时与桌面BI工具对接。
3、淘宝
- 淘宝技术团队使用了Spark来解决多次迭代的机器学习算法、高计算复杂度的算法等,将Spark运用于淘宝的推荐相关算法上,同时还利用GraphX解决了许多生产问题,包括以下计算场景:基于度分布的中枢节点发现、基于最大连通图的社区发现、基于三角形计数的关系衡量、基于随机游走的用户属性传播等。
4、优酷土豆
- 目前Spark已经广泛使用在优酷土豆的视频推荐,广告业务等方面,相比Hadoop,Spark交互查询响应快,性能比Hadoop提高若干倍。一方面,使用Spark模拟广告投放的计算效率高、延迟小(同Hadoop比延迟至少降低一个数量级)。另一方面,优酷土豆的视频推荐往往涉及机器学习及图计算,而使用Spark解决机器学习、图计算等迭代计算能够大大减少网络传输、数据落地等的次数,极大地提高了计算性能。
四、Spark与Hadoop的对比
(一)编程方式
- Hadoop的MapReduce计算数据时,要转化为Map和Reduce两个过程,从而难以描述复杂的数据处理过程;而Spark的计算模型不局限于Map和Reduce操作,还提供了多种数据集的操作类型,编程模型比MapReduce更加灵活。
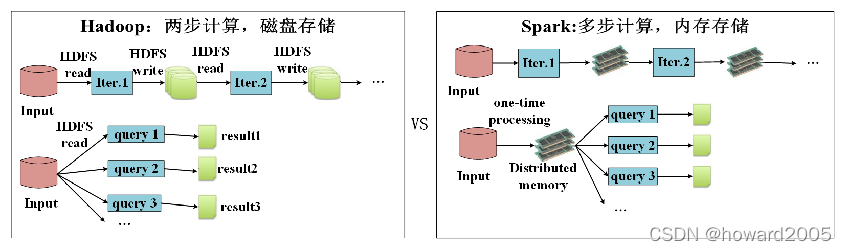
(二)数据存储
- Hadoop的MapReduce进行计算时,每次产生的中间结果都存储在本地磁盘中;而Spark在计算时产生的中间结果存储在内存中。
(三)数据处理
- Hadoop在每次执行数据处理时,都要从磁盘中加载数据,导致磁盘IO开销较大;而Spark在执行数据处理时,要将数据加载到内存中,直接在内存中加载中间结果数据集,减少了磁盘的IO开销。
(四)数据容错
- MapReduce计算的中间结果数据,保存在磁盘中,Hadoop底层实现了备份机制,从而保证了数据容错;Spark RDD实现了基于Lineage的容错机制和设置检查点方式的容错机制,弥补数据在内存处理时,因断电导致数据丢失的问题。
相关文章:
大数据处理学习笔记2.1 初识Spark
文章目录零、本节学习目标一、Spark的概述(一)Spark的组件1、Spark Core2、Spark SQL3、Spark Streaming4、MLlib5、Graph X6、独立调度器、Yarn、Mesos(二)Spark的发展史1、发展简史2、目前最新版本二、Spark的特点(一…...

太强了,英伟达面对ChatGPT还有这一招...
大家好,我是 Jack。 今年可谓是 AI 元年,ChatGPT、AIGC、VITS 都火了一波。 我也先后发布了这几期视频: 这是一个大模型的时代,AI 能在文本、图像、音频等领域大放异彩,得益于大模型。而想要预训练大模型,…...

【微服务】—— Nacos注册中心
文章目录一、Nacos 注册中心的设计原理1、数据模型2、数据⼀致性3、负载均衡4、健康检查二、Nacos 注册中心服务数据模型1、服务(Service)和服务实例(Instance)1)定义服务2)服务元数据3)定义实例…...

GPT-4是个编程高手,真服了!
上周给大家发了一个GPT-4教数学的介绍,很多人都被震撼了,感觉有可能在教育行业引发革命。它在编程领域表现如何?先不说能否替代程序员,这个还有待更多的测试和反馈,我想先试试它能不能像教数学那样教编程。我找了个Jav…...
基于深度学习的车型识别系统(Python+清新界面+数据集)
摘要:基于深度学习的车型识别系统用于识别不同类型的车辆,应用YOLO V5算法根据不同尺寸大小区分和检测车辆,并统计各类型数量以辅助智能交通管理。本文详细介绍车型识别系统,在介绍算法原理的同时,给出Python的实现代码…...
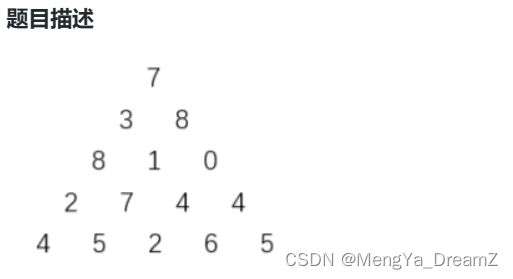
【蓝桥杯C++】3月21日刷题集训ABC-附百分代码,一目了然
目录 刷题集训 A Day 1 成绩分析 Day 1 饮料换购 刷题集训 B Day 1 分巧克力 Day 1 递增三元组 Day 1 小明的衣服 刷题集训 C Day 1 数字三角形 Day 1 跳跃 Day 1 蓝太子序列 刷题集训 A Day 1 成绩分析 题目描述 小蓝给学生…...
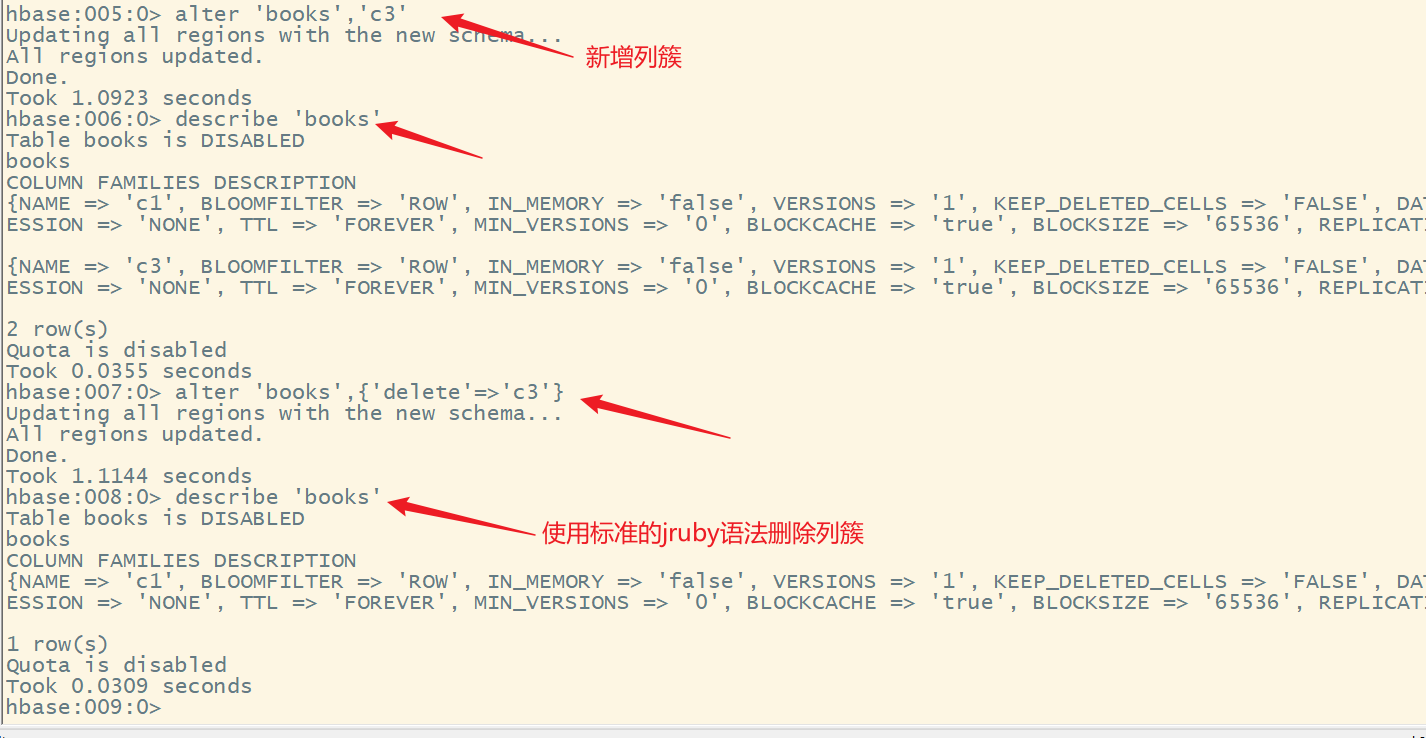
HBase高手之路4-Shell操作
文章目录HBase高手之路3—HBase的shell操作一、hbase的shell命令汇总二、需求三、表的操作1.进入shell命令行2.创建表3.查看表的定义4.列出所有的表5.删除表1)禁用表2)启用表3)删除表四、数据的操作1.添加数…...

聊聊SQL审计功能
什么是sql审计SQL审计是指对SQL语句的执行情况进行记录和追踪,包括SQL语句的执行时间、执行次数、执行结果等信息。通过SQL审计,可以对数据库的使用情况进行监控和管理,包括对SQL注入、非法访问、数据泄露等安全问题的检测和防范,…...
)
Markdown常用语法(字体颜色)
一些不错的帖子 写CSDN博客时,调节字体大小、颜色及其他样式的常用操作方法 设置字体颜色 使用<font>标记: 这是红色字体:<font colorred>我是红色的字体</font>显示效果如下: 这是红色字体:我是…...
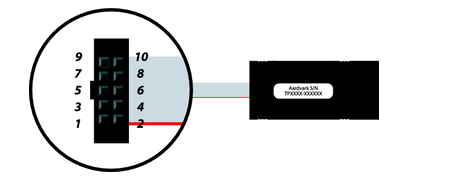
I2C模块理解
I2C模块理解 文章目录I2C模块理解1.配置I2C2.信号3.数据传输3.1主机发送3.2主机接收3.3从机发送3.4从机接收4.中断传输5.Aardvark1.配置I2C I2C的特征 只需要两条公共总线(线)即可控制I2C网络上的任何设备无需像UART通信那样事先约定数据传输速率。因此…...

手把手教你使用--常用模块--HC05蓝牙模块,无线蓝牙串口透传模块,(实例:手机蓝牙控制STM32单片机点亮LED灯)
最近在学STM32,基本的学完了,想学几个模块来巩固一下知识,就想到了蓝牙模块。玩啥好难过有很多博客教怎么连的,但自己看起来还是有点糊涂。模块的原理和知识点我就不讲解了,这里我主要手把手记录一下我是如何对蓝牙模块…...

MyBatis高频面试题
目录 1、Mybatis中#和$的区别 2、Mybatis的编程步骤是什么样的 3...
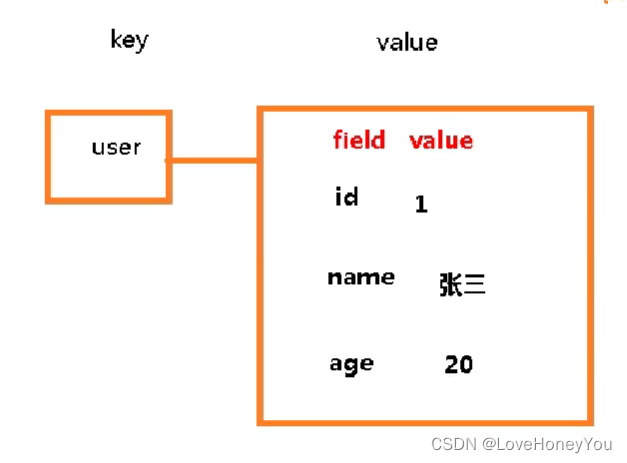
Redis基础篇
redis的三大特点: 支持多数据类型,支持持久化,单线程 多路IO复用 对键操作的命令: keys * 查看当前库所有key exists key 判断key是否存在 del key 删除 unlink key 非阻塞删除,异步删除 expire key …...

unity的C#学习——静态常量和动态常量的定义与使用
定义常量 在C#中,常量是一种不可改变的量,一旦被定义,其值就不能被修改。C#中有两种类型的常量,静态常量和动态常量。 1、静态常量的定义 静态常量是在编译时就已经确定其值的常量,使用const关键字定义。由于在编译…...
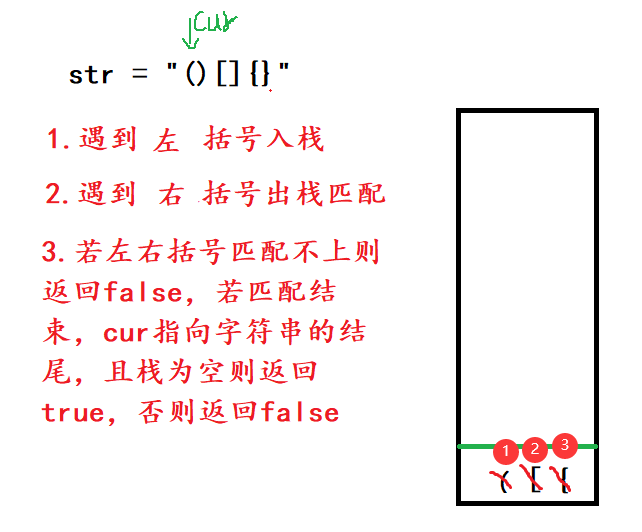
栈----数据结构
栈🔆栈的概念🔆栈的结构🔆栈的实现🔆括号匹配问题🔆结语🔆栈的概念 栈:一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操作。**进行数据插入和删除操作的一端称为栈顶&am…...
【人人都能读标准】11. 原理篇总结:一个程序的完整执行过程
本文为《人人都能读标准》—— ECMAScript篇的第11篇。我在这个仓库中系统地介绍了标准的阅读规则以及使用方式,并深入剖析了标准对JavaScript核心原理的描述。 我们一路走了很远很远,终于到了本书原理篇的最后一站。 在原理篇中,我们先讲了…...
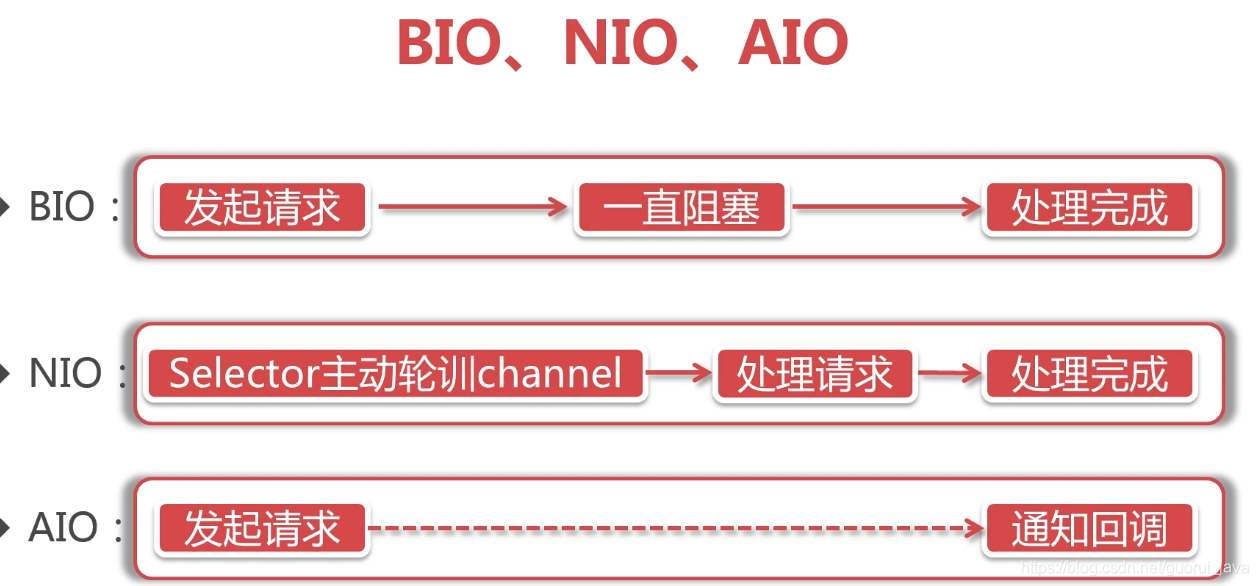
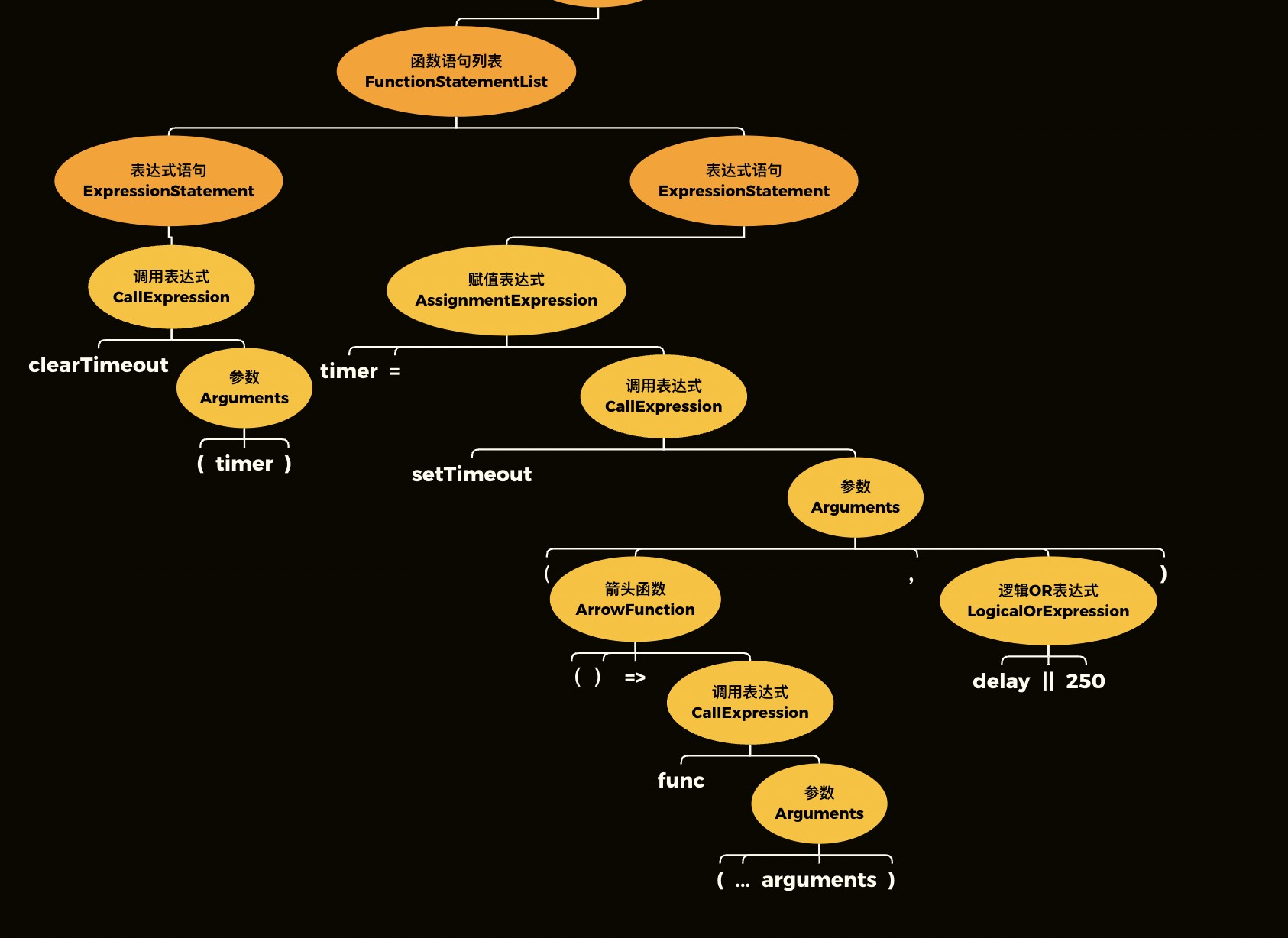
sheng的学习笔记-IO多路复用,NIO,BIO,AIO
基础概念IO分为几种:同步阻塞的BIO,同步非阻塞的NIO,异步非阻塞AIO,IO多路复用,信号驱动IO(不常用)对于一个network IO,它会涉及到两个系统对象,一个是调用这个IO的proce…...
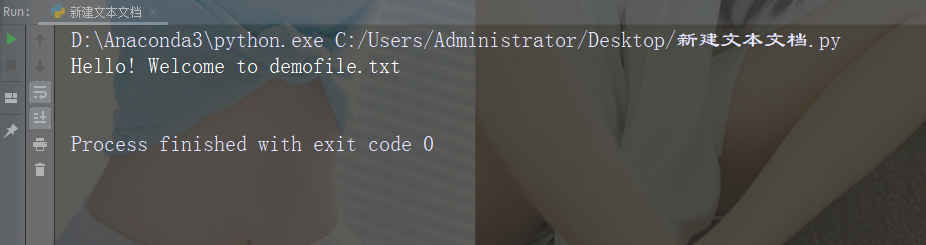
【Python入门第三十五天】Python丨文件打开
在服务器上打开文件 假设我们有以下文件,位于与 Python 相同的文件夹中。 demofile.txt Hello! Welcome to demofile.txt This file is for testing purposes. Good Luck!如需打开文件,请使用内建的 open() 函数。 open() 函数返回文件对象ÿ…...
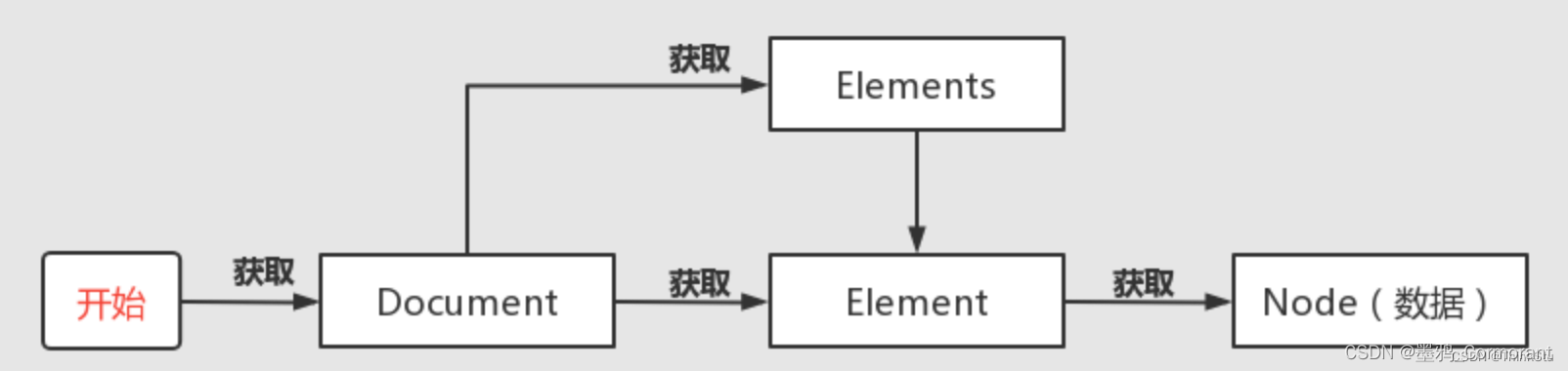
jsoup 框架的使用指南
概述 参考: 官方文档jsoup的使用JSoup教程jsoup 在 GitHub 的开源代码 概念简介 jsoup 是一款基于 Java 的 HTML 解析器,它提供了一套非常省力的 API,不但能直接解析某个 URL 地址、HTML 文本内容,而且还能通过类似于 DOM、CS…...

web前端开发和后端开发哪个难度大?
前言 因为涉及到的具体的应用的领域不同,所以说不能简单地说哪一个难,对于前端而言你会感觉到入门会非常的简单,这也是会给许多人一种错觉,前端很简单,但是只能说是在入门理解上是有利于新手的,前端在主要…...

51单片机实战:UART串口通信与数据交互优化
1. UART串口通信基础与51单片机实战价值 我第一次用51单片机做UART通信时,连波特率是什么都搞不清楚,结果电脑发过来的数据全是乱码。后来才发现是单片机定时器初值算错了,这个经历让我深刻理解到串口通信基础的重要性。 串口通信就像两个人用…...
)
告别裸机UI!用LVGL 8.3给你的STM32项目做个漂亮界面(基于HAL库和SPI屏)
从零打造STM32智能界面:LVGL 8.3实战指南 在嵌入式开发领域,用户界面往往是最容易被忽视却最能直接影响用户体验的环节。想象一下,当你精心设计的智能家居控制面板或工业仪表,因为简陋的字符界面而显得廉价时,那种挫败…...

3分钟上手!Balena Etcher:安全烧录系统镜像的终极解决方案
3分钟上手!Balena Etcher:安全烧录系统镜像的终极解决方案 【免费下载链接】etcher Flash OS images to SD cards & USB drives, safely and easily. 项目地址: https://gitcode.com/GitHub_Trending/et/etcher 你是否曾因烧录系统镜像而丢失…...

Unity内联序列化类的秘密
一个藏在Inspector面板背后的"俄罗斯套娃" 一、开篇:一个看似简单的问题 你在Unity中写了一个脚本: public class Player : MonoBehaviour {public int health;public float speed...

Xinference+tao-8k实战:快速构建文档相似度分析工具
Xinferencetao-8k实战:快速构建文档相似度分析工具 1. 从想法到工具:为什么你需要一个文档相似度分析器 想象一下这个场景:你手头有几百份技术文档、产品说明或者客户反馈,你想快速找出哪些文档在讨论同一个主题,或者…...

别再乱改NV了!深入理解高通Modem配置:从UI Task到PDN管理,这些底层逻辑你得懂
高通Modem配置深度解析:从UI Task到PDN管理的底层逻辑 1. 理解Modem配置的本质 在移动通信领域,高通平台的Modem配置一直是个既关键又复杂的课题。许多开发者习惯性地复制粘贴NV配置参数,却对背后的运行机制一知半解。这种"知其然而不知…...

4个步骤掌握ComfyUI-WanVideoWrapper:从环境搭建到视频生成全攻略
4个步骤掌握ComfyUI-WanVideoWrapper:从环境搭建到视频生成全攻略 【免费下载链接】ComfyUI-WanVideoWrapper 项目地址: https://gitcode.com/GitHub_Trending/co/ComfyUI-WanVideoWrapper ComfyUI-WanVideoWrapper是一款强大的AI视频生成插件,作…...
)
别再只盯着Loss曲线了!TensorBoard的SCALARS面板还有这些隐藏玩法(附GAN训练实战)
解锁TensorBoard SCALARS面板的隐藏战力:从GAN训练曲线中洞察模型灵魂 当你盯着GAN训练中那对纠缠不清的生成器和判别器Loss曲线时,是否感觉像在解读一部悬疑小说?TensorBoard的SCALARS面板远比大多数开发者想象的强大——它不仅是数据的展示…...

比迪丽模型在数据库课程设计中的应用:ER图可视化增强
比迪丽模型在数据库课程设计中的应用:ER图可视化增强 1. 引言 数据库课程设计是计算机专业学生的必修实践环节,其中ER图(实体-关系图)的设计与呈现是核心难点。传统工具绘制的ER图往往显得枯燥抽象,学生难以直观理解…...

FUTURE POLICE语音对齐系统:MySQL数据库集成与结果分析实战
FUTURE POLICE语音对齐系统:MySQL数据库集成与结果分析实战 1. 语音对齐数据管理的挑战与解决方案 语音识别与对齐技术正在改变我们处理音频内容的方式。FUTURE POLICE系统凭借其毫秒级精度的强制对齐能力,为语音数据处理树立了新标准。然而࿰…...