笔记小结:《利用python进行数据分析》之层次化索引
层次化索引
导入样例
层次化索引(hierarchical indexing)是pandas的一项重要功能,它使你能在一个轴上拥有多个(两个以上)索引级别。抽象点说,它使你能以低维度形式处理高维度数据。我们先来看一个简单的例子:创建一个Series,并用一个由列表或数组组成的列表作为索引:
In [9]: data = pd.Series(np.random.randn(9),...: index=[['a', 'a', 'a', 'b', 'b', 'c', 'c', 'd', 'd'],...: [1, 2, 3, 1, 3, 1, 2, 2, 3]])
In [10]: data
Out[10]:
a 1 -0.2047082 0.4789433 -0.519439
b 1 -0.5557303 1.965781
c 1 1.3934062 0.092908
d 2 0.2817463 0.769023
dtype: float64看到的结果是经过美化的带有MultiIndex索引的Series的格式。索引之间的“间隔”表示“直接使用上面的标签”。
MultiIndex对象
In [11]: data.index
Out[11]:
MultiIndex(levels=[['a', 'b', 'c', 'd'], [1, 2, 3]],labels=[[0, 0, 0, 1, 1, 2, 2, 3, 3], [0, 1, 2, 0, 2, 0, 1, 1, 2]])输出结果是一个MultiIndex对象,它是由两个层级组成的多级索引。这个多级索引的结构如下:
levels:这是两个列表的列表,表示索引的两个级别。第一个列表包含大写字母['a', 'b', 'c', 'd'],这是索引的第一级;第二个列表包含数字[1, 2, 3],这是索引的第二级。labels:这是一个二维数组,表示每个索引元素在levels中的位置。labels的第一行对应于levels的第一级,第二行对应于levels的第二级。例如,labels=[[0, 0, 0, 1, 1, 2, 2, 3, 3], [0, 1, 2, 0, 2, 0, 1, 1, 2]]表示:- 第一个元素的索引是('a', 1)
- 第二个元素的索引是('a', 2)
- 第三个元素的索引是('a', 3)
- 以此类推...
这种多级索引在数据分析中非常有用,便于对数据进行更复杂的分组和操作。
索引和切片操作
对于一个层次化索引的对象,可以使用所谓的部分索引,使用它选取数据子集的操作更简单:
In [12]: data['b']
Out[12]:
1 -0.555730
3 1.965781
dtype: float64
In [13]: data['b':'c']
Out[13]:
b 1 -0.5557303 1.965781
c 1 1.3934062 0.092908
dtype: float64
In [14]: data.loc[['b', 'd']]
Out[14]:
b 1 -0.5557303 1.965781
d 2 0.2817463 0.769023
dtype: float64-
data['b']:这个操作是使用第一级索引(即大写字母)来选择所有与'b'相关的元素。输出结果显示了所有索引为'b'的Series元素。 -
data['b':'c']:这个操作是使用索引的切片功能,选择了从'b'到'c'(包含'b'和'c')的所有元素。输出结果展示了索引在'b'和'c'之间的所有Series元素。 -
data.loc[['b', 'd']]:这个操作使用了.loc属性,它允许通过提供一个索引列表来选择数据。这里选择了索引为'b'和'd'的所有元素。输出结果展示了这两个索引下的所有Series元素。
基于标签在内层进行索引
有时甚至还可以在“内层”中进行选取:
In [15]: data.loc[:, 2]
Out[15]:
a 0.478943
c 0.092908
d 0.281746
dtype: float64在您的代码片段 data.loc[:, 2] 中,使用了 .loc 属性来进行基于标签的索引操作。这里的操作是选择所有第一级索引(即大写字母 'a', 'b', 'c', 'd')下,第二级索引为 2 的所有数据。下面是具体的解释:
data:是之前创建的Pandas Series对象,具有多级索引。.loc:是Pandas中用于基于标签的索引操作的属性。[:, 2]:这个索引器指定了要选择的行和列。在这个例子中,冒号:表示选择所有的第一级索引(即所有的大写字母),而数字2表示选择第二级索引中的2。由于您的数据集中第二级索引是数字1、2、3,所以这里的2将匹配所有索引为2的元素。
输出结果 Out[15] 展示了所有第二级索引为2的元素,即:
- 'a' 下索引为2的元素,值为 0.478943
- 'c' 下索引为2的元素,值为 0.092908
- 'd' 下索引为2的元素,值为 0.281746
注意,尽管索引 'b' 存在,但在数据集中并没有索引为 ('b', 2) 的元素,因此在输出结果中没有显示。这种索引方式非常适合于选择特定级别的索引数据,无论是行还是列。
stack与unstack方法
层次化索引在数据重塑和基于分组的操作(如透视表生成)中扮演着重要的角色。例如,可以通过unstack方法将这段数据重新安排到一个DataFrame中:
In [16]: data.unstack()
Out[16]: 1 2 3
a -0.204708 0.478943 -0.519439
b -0.555730 NaN 1.965781
c 1.393406 0.092908 NaN
d NaN 0.281746 0.769023unstack的逆运算是stack:
In [17]: data.unstack().stack()
Out[17]:
a 1 -0.2047082 0.4789433 -0.519439
b 1 -0.5557303 1.965781
c 1 1.3934062 0.092908
d 2 0.2817463 0.769023
dtype: float64每条轴的分层索引
对于一个DataFrame,每条轴都可以有分层索引:
In [18]: frame = pd.DataFrame(np.arange(12).reshape((4, 3)),....: index=[['a', 'a', 'b', 'b'], [1, 2, 1, 2]],....: columns=[['Ohio', 'Ohio', 'Colorado'],....: ['Green', 'Red', 'Green']])
In [19]: frame
Out[19]: Ohio ColoradoGreen Red Green
a 1 0 1 22 3 4 5
b 1 6 7 82 9 10 11各层都可以有名字(可以是字符串,也可以是别的Python对象)。如果指定了名称,它们就会显示在控制台输出中:
In [20]: frame.index.names = ['key1', 'key2']
In [21]: frame.columns.names = ['state', 'color']
In [22]: frame
Out[22]:
state Ohio Colorado
color Green Red Green
key1 key2
a 1 0 1 22 3 4 5
b 1 6 7 82 9 10 11有了部分列索引,因此可以轻松选取列分组:
In [23]: frame['Ohio']
Out[23]:
color Green Red
key1 key2
a 1 0 12 3 4
b 1 6 72 9 10单独创建MultiIndex然后复用
可以单独创建MultiIndex然后复用。上面那个DataFrame中的(带有分级名称)列可以这样创建:
MultiIndex.from_arrays([['Ohio', 'Ohio', 'Colorado'], ['Green', 'Red', 'Green']],names=['state', 'color'])重排与分级排序
swaplevel
有时,你需要重新调整某条轴上各级别的顺序,或根据指定级别上的值对数据进行排序。swaplevel接受两个级别编号或名称,并返回一个互换了级别的新对象(但数据不会发生变化):
In [24]: frame.swaplevel('key1', 'key2')
Out[24]:
state Ohio Colorado
color Green Red Green
key2 key1
1 a 0 1 2
2 a 3 4 5
1 b 6 7 8
2 b 9 10 11sort_index
而sort_index则根据单个级别中的值对数据进行排序。交换级别时,常常也会用到sort_index,这样最终结果就是按照指定顺序进行字母排序了:
In [25]: frame.sort_index(level=1)
Out[25]:
state Ohio Colorado
color Green Red Green
key1 key2
a 1 0 1 2
b 1 6 7 8
a 2 3 4 5
b 2 9 10 11
In [26]: frame.swaplevel(0, 1).sort_index(level=0)
Out[26]:
state Ohio Colorado
color Green Red Green
key2 key1
1 a 0 1 2b 6 7 8
2 a 3 4 5b 9 10 11根据级别汇总统计
许多对DataFrame和Series的描述和汇总统计都有一个level选项,它用于指定在某条轴上求和的级别。再以上面那个DataFrame为例,我们可以根据行或列上的级别来进行求和:
In [27]: frame.sum(level='key2')
Out[27]:
state Ohio Colorado
color Green Red Green
key2
1 6 8 10
2 12 14 16
In [28]: frame.sum(level='color', axis=1)
Out[28]:
color Green Red
key1 key2
a 1 2 12 8 4
b 1 14 72 20 10使用DataFrame的列进行索引
人们经常想要将DataFrame的一个或多个列当做行索引来用,或者可能希望将行索引变成DataFrame的列。以下面这个DataFrame为例:
In [29]: frame = pd.DataFrame({'a': range(7), 'b': range(7, 0, -1),....: 'c': ['one', 'one', 'one', 'two', 'two',....: 'two', 'two'],....: 'd': [0, 1, 2, 0, 1, 2, 3]})
In [30]: frame
Out[30]: a b c d
0 0 7 one 0
1 1 6 one 1
2 2 5 one 2
3 3 4 two 0
4 4 3 two 1
5 5 2 two 2
6 6 1 two 3DataFrame的set_index函数会将其一个或多个列转换为行索引,并创建一个新的DataFrame:
In [31]: frame2 = frame.set_index(['c', 'd'])
In [32]: frame2
Out[32]: a b
c d
one 0 0 71 1 62 2 5
two 0 3 41 4 32 5 23 6 1默认情况下,那些列会从DataFrame中移除,但也可以将其保留下来:
In [33]: frame.set_index(['c', 'd'], drop=False)
Out[33]: a b c d
c d
one 0 0 7 one 01 1 6 one 12 2 5 one 2
two 0 3 4 two 01 4 3 two 12 5 2 two 23 6 1 two 3reset_index的功能跟set_index刚好相反,层次化索引的级别会被转移到列里面:
In [34]: frame2.reset_index()
Out[34]:
c d a b
0 one 0 0 7
1 one 1 1 6
2 one 2 2 5
3 two 0 3 4
4 two 1 4 3
5 two 2 5 2
6 two 3 6 1相关文章:

笔记小结:《利用python进行数据分析》之层次化索引
层次化索引 导入样例 层次化索引(hierarchical indexing)是pandas的一项重要功能,它使你能在一个轴上拥有多个(两个以上)索引级别。抽象点说,它使你能以低维度形式处理高维度数据。我们先来看一个简单的例…...

Linux的线程篇章 - 线程池、进程池等知识】
Linux学习笔记---018 Linux之线程池、进程池知识储备1、线程池1.1、池化技术1.1.1、定义与原理1.1.2、优点1.1.3、应用场景 1.2、线程池的特点与优势1.3、线程池的适用场景1.4、线程池的实现 2、进程池2.1、定义和基本概念2.2、进程池的特点与优势2.3、进程池的适用场景&#x…...

汇昌联信做拼多多运营正规吗?
汇昌联信在拼多多平台上的运营是否正规,是许多商家和消费者都关心的问题。随着电商行业的快速发展,平台运营的正规性直接关系到消费者的购物体验和商家的信誉。 一、公司背景与资质审核 明确回答问题:汇昌联信作为一家专业的电商运营公司&…...

240810-Gradio自定义Button按钮+事件函数+按钮图标样式设定
A. 最终效果 B. 参考代码 要通过自定义HTML按钮来触发Gradio自带按钮的 click 函数,你可以使用JavaScript来模拟点击Gradio的按钮。这里是一个示例代码,展示了如何实现这一点: import gradio as gr# 自定义的 JavaScript,用于捕…...

排序算法--快速排序
一、三色旗问题 问题描述 有一个数组是只由0,1,2三种元素构成的整数数组,请使用交换、原地排序而不是计数进行排序: 解题思路 1.定义两个变量,i和j(下标),从index0开始遍历 2.如…...
springMVC -- 学习笔记
前言简介演示 ⇒ (最简单的原理,开发并不这样,理解一下就好)演示 ⇒ 接近真实注解开发(好好理解一下)重要的源码献上 Controller 讲解RequestMapper ⇒ 没啥记的,第一个案例看看就行了RestFul 风…...
连接服务器使用zsh出现乱跳的问题)
修复本地终端(windows)连接服务器使用zsh出现乱跳的问题
目前市面上还没有发现解决方案,记录一下! 1.起因: 在服务器配置了zsh后,用本地的windows去连接的时候,终端内容会出现乱跳,比如输入了一个“l”,后面出现多个“lll”,如下: ⚡ roo…...

【扒代码】regression_head.py
import torch from torch import nnclass UpsamplingLayer(nn.Module):# 初始化 UpsamplingLayer 类def __init__(self, in_channels, out_channels, leakyTrue):super(UpsamplingLayer, self).__init__() # 调用基类的初始化方法# 初始化一个序列模型,包含卷积层、…...

vue2 使用axios 请求后台返回文件流导出为excel
目录 步骤 1: 安装 Axios 步骤 2: 创建 Axios 实例 步骤 3: 发起请求并处理文件流 说明 步骤 1: 安装 Axios 首先,确保项目中已经安装了 Axios。如果没有,可以通过以下命令进行安装: npm install axios 步骤 2: 创建 Axios 实例 为了更…...
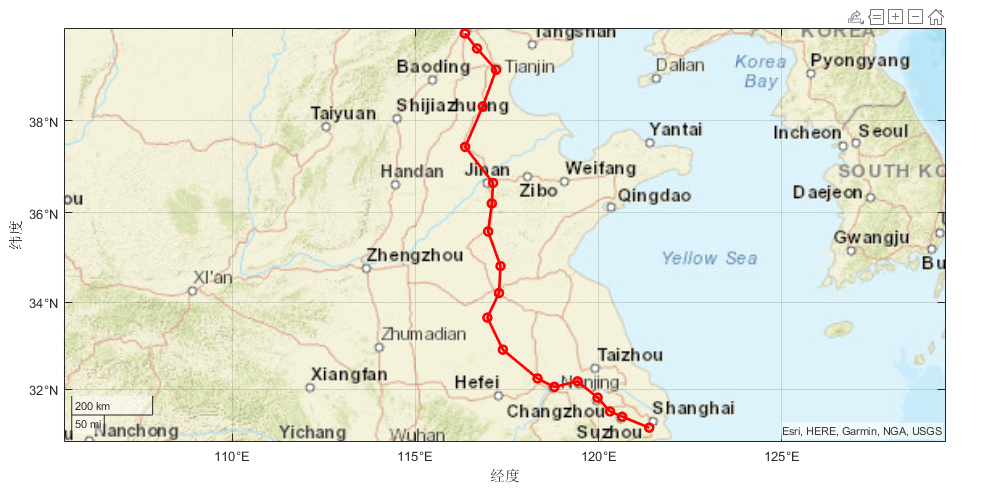
MATLAB数据可视化:在地图上画京沪线的城市连线
matlab自带的geoplot(lat,lon) 可以在地理坐标中绘制线条。使用 lat和lon分别指定以度为单位的经度和纬度坐标。 绘制京沪线所经城市线条: citys [116.350009,39.853928; 116.683546,39.538304; 117.201509,39.085318; 116.838715,38.304676;...116.359244,37.436…...

【AI】CV基础1
定期更新,建议关注更新收藏。 本站友情链接: OCR篇1 可变形卷积Deformable Conv opencv-python形态学操作合集 目录 仿射变换图像二阶导数本质探讨PIL通道、模式、尺寸、坐标系统、调色板、信息滤波器实现图像格式转换 OpenCV轮廓提取 仿射变换 仿射变换…...

数据结构《栈》
数据结构《栈》 1、栈的概念及结构2、栈的实现3、练习: 1、栈的概念及结构 栈:一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操作。进行数据插入和删除操作的一端 称为栈顶,另一端称为栈底。栈中的数据元素遵守后进先出LIFO&…...

说一说mysql的having?和where有什么区别?
在 MySQL 中,HAVING 子句和 WHERE 子句都是用于过滤查询结果的,但它们之间有一些重要的区别。下面我将详细介绍这两个子句的区别以及它们的使用场景。 1. HAVING 子句 作用: HAVING 子句用于过滤聚合后的结果集。它通常与 GROUP BY 子句一起使用&#x…...

LeetCode45. 跳跃游戏 II
题目链接: 45. 跳跃游戏 II - 力扣(LeetCode) 思路分析:这属于上一题的变种,思路有所不同,要用到贪心的思想。从第一步开始,在可以跳跃的范围内,选择能够到达最远位置的点将其作为…...

算法打卡 Day19(二叉树)-平衡二叉树 + 二叉树的所有路径 + 左叶子之和 + 完全二叉树的节点个数
Leetcode 101-平衡二叉树 文章目录 Leetcode 101-平衡二叉树题目描述解题思路 Leetcode 257-二叉树的所有路径题目描述解题思路 Leetcode 404-左叶子之和题目描述解题思路 Leetcode 222-完全二叉树的节点个数题目描述解题思路 题目描述 https://leetcode.cn/problems/balanced…...
/国际专线(IPLC)-全球覆盖,无界沟通)
国际以太网专线 (IEPL)/国际专线(IPLC)-全球覆盖,无界沟通
中国联通国际公司产品:国际以太网专线 (IEPL)/国际专线(IPLC)—— 跨境数据传输的坚实桥梁 在全球化日益加深的今天,跨境、跨地域的数据传输需求激增,企业对数据传输的速度、安全性和稳定性提出了前所未有的高要求。中…...

信息安全管理知识体系攻略(至简)
信息安全管理知识体系主要包括信息安全管理体系、信息安全策略、信息安全系统、信息安全技术体系等。 一、信息安全管理 1、信息安全管理体系(ISMS)。ISO27001是国际标准化组织(ISO)和国际电工委员会(ICE)…...

HCIE学习笔记:IPV6 地址、ICMP V6、NDP 、DAD (更新补充中)
系列文章目录 提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 系列文章目录前言一、IPV4、IPv6包头对比1. IPV4包头2.IPv6包头3.IPV6扩展包头 二、IPV6基础知识地址结构、地址分类三、ICMPV4、ICMPV61、 lnternet控…...

人工智能】Transformers之Pipeline(九):物体检测(object-detection)
目录 一、引言 二、物体检测(object-detection) 2.1 概述 2.2 技术原理 2.3 应用场景 2.4 pipeline参数 2.4.1 pipeline对象实例化参数 2.4.2 pipeline对象使用参数 2.4 pipeline实战 2.5 模型排名 三、总结 一、引言 pipel…...

[SWPUCTF 2021 新生赛]easy_md5
分析代码:1.包含flag2.php 2.GET传name,POST传password $name ! $password && md5($name) md5($password) 属于MD5绕过中的php 弱类型绕过 解题方法: 方法一 import requests# 网站的URL url "http://node7.anna.nssctf.cn:28026&q…...
 —— SPI相关概念)
STM32单片机学习(27) —— SPI相关概念
文章目录概述SPI通信的核心特性I2C和SPI的简单对比SPI学习的补充说明SPI硬件电路设计SPI的四条通信线SPI通信的片选线低电平选中不支持广播通信SPI通信的时序结构(重点)SPI通信的比特序通信空闲状态,SPI时钟极性采样时机,SPI时钟相…...

鸿蒙系统微博应用锁常见问题解答
为微博设置应用锁后,不少用户会有各种疑问:忘记密码怎么办?会不会影响消息推送?能不能只锁定某些功能?应用锁耗电吗?本文将针对这些高频问题逐一解答,帮助您更好地使用鸿蒙系统(Harm…...

神经网络与深度学习 第3周课程总结
深度学习视觉应用课程总结 一、常用计算机视觉数据集数据集名称发布方/年份规模图像规格类别数主要用途核心特点MNIST美国国家标准与技术研究院60k训练10k测试2828灰度图10类(0-9手写数字)入门级图像分类最经典的手写数字识别基准数据集Fashion-MNISTZalando(2017)60k训练10k测…...

LaTeX公式一键转Word:3步告别数学公式编辑烦恼
LaTeX公式一键转Word:3步告别数学公式编辑烦恼 【免费下载链接】LaTeX2Word-Equation Copy LaTeX Equations as Word Equations, a Chrome Extension 项目地址: https://gitcode.com/gh_mirrors/la/LaTeX2Word-Equation 还在为Word文档中的数学公式编辑而抓狂…...

通过TaotokenCLI工具一键配置开发环境接入参数
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken CLI工具一键配置开发环境接入参数 对于需要接入多个大模型服务的开发者而言,手动配置每个项目的API密钥、…...

深度解析:JetBrains IDE试用期重置机制的技术实现
深度解析:JetBrains IDE试用期重置机制的技术实现 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 在软件开发工作流中,JetBrains IDE试用期管理是一个常见的技术挑战,尤其是在多…...

如何用免费工具解锁QQ音乐、网易云音乐等加密格式:3分钟解决音乐播放限制
如何用免费工具解锁QQ音乐、网易云音乐等加密格式:3分钟解决音乐播放限制 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web…...

观察Taotoken在多模型聚合调用下的路由与失败重试效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken在多模型聚合调用下的路由与失败重试效果 在构建依赖大模型能力的应用时,服务的稳定性是开发者关注的核心…...

为什么你明明很努力,领导却总看不到?问题出在这
许多测试同行在深夜加班排查Bug时,在凌晨赶写自动化脚本时,在对着海量数据做性能分析时,内心都会浮现一个共同的困惑:我明明已经这么拼了,为什么在领导眼里,我依然是个“找茬的”,而不是“创造价…...

如何高效实现Windows自动化鼠标点击:AutoClicker完整实战指南
如何高效实现Windows自动化鼠标点击:AutoClicker完整实战指南 【免费下载链接】AutoClicker AutoClicker is a useful simple tool for automating mouse clicks. 项目地址: https://gitcode.com/gh_mirrors/au/AutoClicker AutoClicker是一款专业的Windows桌…...