【扒代码】regression_head.py
import torch
from torch import nnclass UpsamplingLayer(nn.Module):# 初始化 UpsamplingLayer 类def __init__(self, in_channels, out_channels, leaky=True):super(UpsamplingLayer, self).__init__() # 调用基类的初始化方法# 初始化一个序列模型,包含卷积层、激活函数和上采样操作self.layer = nn.Sequential(# 卷积层,用于特征图的卷积操作# in_channels 表示输入通道数,out_channels 表示输出通道数# kernel_size=3 表示卷积核大小为 3x3# padding=1 表示边缘填充,保持特征图尺寸不变nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),# 根据参数 leaky 决定使用 LeakyReLU 激活函数还是 ReLU 激活函数# LeakyReLU 在正输入值上与 ReLU 相同,但在负输入值上允许一个小的梯度(由 leaky 参数控制)nn.LeakyReLU() if leaky else nn.ReLU(),# 上采样层,使用双线性插值方法放大特征图# scale_factor=2 表示将特征图的尺寸放大两倍nn.UpsamplingBilinear2d(scale_factor=2))# 前向传播方法,将输入 x 通过定义好的层进行处理def forward(self, x):return self.layer(x)功能解释:
UpsamplingLayer类接收三个参数:in_channels(输入通道数),out_channels(输出通道数),和leaky(一个布尔值,决定是否使用 LeakyReLU 激活函数)。- 类初始化方法
__init__中,使用nn.Sequential创建了一个序列模型,它将按照顺序应用里面的层。 nn.Conv2d是一个二维卷积层,用于在卷积神经网络中进行卷积操作。nn.LeakyReLU是一种激活函数,当输入为正时,它的行为与nn.ReLU相同,当输入为负时,它允许一个非零的梯度(由leaky参数控制)。nn.UpsamplingBilinear2d是一个上采样层,使用双线性插值方法来放大特征图的尺寸。forward方法定义了模型的前向传播,它接收输入x,并通过self.layer中定义的层进行处理,然后返回处理后的结果。
整体而言,UpsamplingLayer 类实现了一个简单的上采样模块,它首先通过卷积层提取特征,然后应用激活函数,最后通过上采样层放大特征图,这在图像分割、特征细化等任务中非常有用。(这个上采样)
import torch
from torch import nn
from .upsamplinglayer import UpsamplingLayer # 假设 UpsamplingLayer 在当前包中定义class DensityMapRegressor(nn.Module):# 初始化 DensityMapRegressor 类def __init__(self, in_channels, reduction):super(DensityMapRegressor, self).__init__() # 调用基类的初始化方法# 根据 reduction 参数的不同,构建不同的回归器结构if reduction == 8:self.regressor = nn.Sequential(# 上采样层,将输入通道数 in_channels 上采样到 128UpsamplingLayer(in_channels, 128),# 继续上采样到 64UpsamplingLayer(128, 64),# 再上采样到 32UpsamplingLayer(64, 32),# 最后通过一个 1x1 卷积层将通道数减少到 1,生成密度图nn.Conv2d(32, 1, kernel_size=1),# 使用 LeakyReLU 激活函数nn.LeakyReLU())elif reduction == 16:self.regressor = nn.Sequential(# 与 reduction == 8 类似,但是最后多一个上采样步骤到 16UpsamplingLayer(in_channels, 128),UpsamplingLayer(128, 64),UpsamplingLayer(64, 32),UpsamplingLayer(32, 16),nn.Conv2d(16, 1, kernel_size=1),nn.LeakyReLU())# 初始化模型参数self.reset_parameters()# 前向传播方法,将输入 x 通过回归器处理def forward(self, x):return self.regressor(x)# 参数重置方法,使用特定的初始化方法初始化模型的权重和偏置def reset_parameters(self):for module in self.modules(): # 遍历模型中所有的模块if isinstance(module, nn.Conv2d): # 如果模块是二维卷积层# 初始化权重为标准正态分布nn.init.normal_(module.weight, std=0.01)# 如果存在偏置项,则初始化为常数 0if module.bias is not None:nn.init.constant_(module.bias, 0)功能解释:
DensityMapRegressor类用于生成对象计数的密度图,它根据输入的特征图和指定的reduction参数来构建一个回归器网络。in_channels参数指定了输入特征图的通道数。reduction参数控制了网络中上采样层的数量和最终生成的密度图的分辨率。self.regressor是一个序列模型,根据reduction参数的值,它将构建不同数量的上采样层,最后通过一个 1x1 卷积层输出通道数为 1 的密度图。forward方法定义了模型的前向传播逻辑,它接收输入x,并通过self.regressor进行处理,返回处理后的密度图。reset_parameters方法用于初始化模型的参数,这里使用正态分布初始化权重,偏置初始化为常数 0。这是为了在训练开始前给模型一个合理的初始状态。
整体而言,DensityMapRegressor 类实现了一个用于生成密度图的回归网络,它通过一系列上采样层逐步放大特征图的尺寸,并最终生成一个通道数为 1 的密度图,这个密度图可以用于表示图像中对象的分布密度。
什么是上采样?
上采样(Upsampling)是深度学习和计算机视觉中常用的一种技术,用于增加数据的空间分辨率,即增加图像的高度和宽度。上采样通常在特征图(feature maps)经过一系列卷积层后应用,以便恢复图像的空间尺寸或为后续的网络层提供合适尺寸的输入。
上采样的常见方法包括:
-
最近邻插值(Nearest Neighbor Interpolation):
- 这是最简单的上采样方法,通过选择距离最近的像素点的值来填充新像素点。
-
双线性插值(Bilinear Interpolation):
- 这种方法考虑了新像素点周围四个最近像素点的值,并通过线性方式进行插值。
-
双三次插值(Bicubic Interpolation):
- 类似于双线性插值,但使用了更高阶的多项式来提供平滑的插值效果。
-
转置卷积(Transposed Convolution):
- 也称为反卷积,通过卷积操作来增加图像的空间尺寸,同时学习如何填充新像素点的值。
-
像素 Shuffle(Pixel Shuffle):
- 通过重新排列像素来增加图像的分辨率,通常与子像素卷积一起使用。

在这个例子中,新像素点的值是通过考虑周围现有像素点的值并进行加权平均得到的。
上采样在许多深度学习任务中都非常有用,例如在语义分割任务中恢复图像分辨率,或者在生成对抗网络(GANs)中生成高分辨率的图像。通过上采样,模型能够生成更精细的特征表示,有助于提高任务的性能。
相关文章:
【扒代码】regression_head.py
import torch from torch import nnclass UpsamplingLayer(nn.Module):# 初始化 UpsamplingLayer 类def __init__(self, in_channels, out_channels, leakyTrue):super(UpsamplingLayer, self).__init__() # 调用基类的初始化方法# 初始化一个序列模型,包含卷积层、…...

vue2 使用axios 请求后台返回文件流导出为excel
目录 步骤 1: 安装 Axios 步骤 2: 创建 Axios 实例 步骤 3: 发起请求并处理文件流 说明 步骤 1: 安装 Axios 首先,确保项目中已经安装了 Axios。如果没有,可以通过以下命令进行安装: npm install axios 步骤 2: 创建 Axios 实例 为了更…...
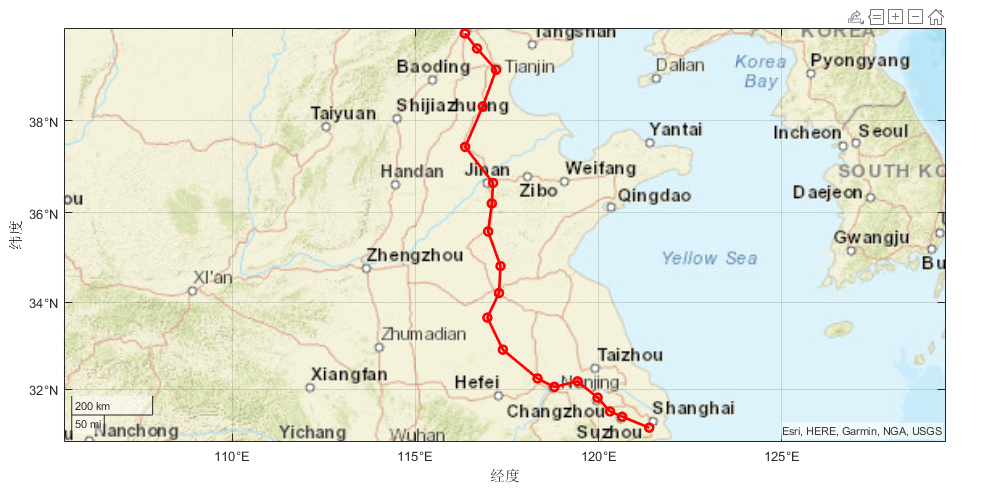
MATLAB数据可视化:在地图上画京沪线的城市连线
matlab自带的geoplot(lat,lon) 可以在地理坐标中绘制线条。使用 lat和lon分别指定以度为单位的经度和纬度坐标。 绘制京沪线所经城市线条: citys [116.350009,39.853928; 116.683546,39.538304; 117.201509,39.085318; 116.838715,38.304676;...116.359244,37.436…...

【AI】CV基础1
定期更新,建议关注更新收藏。 本站友情链接: OCR篇1 可变形卷积Deformable Conv opencv-python形态学操作合集 目录 仿射变换图像二阶导数本质探讨PIL通道、模式、尺寸、坐标系统、调色板、信息滤波器实现图像格式转换 OpenCV轮廓提取 仿射变换 仿射变换…...

数据结构《栈》
数据结构《栈》 1、栈的概念及结构2、栈的实现3、练习: 1、栈的概念及结构 栈:一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操作。进行数据插入和删除操作的一端 称为栈顶,另一端称为栈底。栈中的数据元素遵守后进先出LIFO&…...

说一说mysql的having?和where有什么区别?
在 MySQL 中,HAVING 子句和 WHERE 子句都是用于过滤查询结果的,但它们之间有一些重要的区别。下面我将详细介绍这两个子句的区别以及它们的使用场景。 1. HAVING 子句 作用: HAVING 子句用于过滤聚合后的结果集。它通常与 GROUP BY 子句一起使用&#x…...

LeetCode45. 跳跃游戏 II
题目链接: 45. 跳跃游戏 II - 力扣(LeetCode) 思路分析:这属于上一题的变种,思路有所不同,要用到贪心的思想。从第一步开始,在可以跳跃的范围内,选择能够到达最远位置的点将其作为…...

算法打卡 Day19(二叉树)-平衡二叉树 + 二叉树的所有路径 + 左叶子之和 + 完全二叉树的节点个数
Leetcode 101-平衡二叉树 文章目录 Leetcode 101-平衡二叉树题目描述解题思路 Leetcode 257-二叉树的所有路径题目描述解题思路 Leetcode 404-左叶子之和题目描述解题思路 Leetcode 222-完全二叉树的节点个数题目描述解题思路 题目描述 https://leetcode.cn/problems/balanced…...
/国际专线(IPLC)-全球覆盖,无界沟通)
国际以太网专线 (IEPL)/国际专线(IPLC)-全球覆盖,无界沟通
中国联通国际公司产品:国际以太网专线 (IEPL)/国际专线(IPLC)—— 跨境数据传输的坚实桥梁 在全球化日益加深的今天,跨境、跨地域的数据传输需求激增,企业对数据传输的速度、安全性和稳定性提出了前所未有的高要求。中…...

信息安全管理知识体系攻略(至简)
信息安全管理知识体系主要包括信息安全管理体系、信息安全策略、信息安全系统、信息安全技术体系等。 一、信息安全管理 1、信息安全管理体系(ISMS)。ISO27001是国际标准化组织(ISO)和国际电工委员会(ICE)…...

HCIE学习笔记:IPV6 地址、ICMP V6、NDP 、DAD (更新补充中)
系列文章目录 提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 系列文章目录前言一、IPV4、IPv6包头对比1. IPV4包头2.IPv6包头3.IPV6扩展包头 二、IPV6基础知识地址结构、地址分类三、ICMPV4、ICMPV61、 lnternet控…...

人工智能】Transformers之Pipeline(九):物体检测(object-detection)
目录 一、引言 二、物体检测(object-detection) 2.1 概述 2.2 技术原理 2.3 应用场景 2.4 pipeline参数 2.4.1 pipeline对象实例化参数 2.4.2 pipeline对象使用参数 2.4 pipeline实战 2.5 模型排名 三、总结 一、引言 pipel…...

[SWPUCTF 2021 新生赛]easy_md5
分析代码:1.包含flag2.php 2.GET传name,POST传password $name ! $password && md5($name) md5($password) 属于MD5绕过中的php 弱类型绕过 解题方法: 方法一 import requests# 网站的URL url "http://node7.anna.nssctf.cn:28026&q…...

Redis面试题大全
文章目录 Redis有哪几种基本类型Redis为什么快?为什么Redis6.0后改用多线程?什么是热key吗?热key问题怎么解决?什么是热Key?解决热Key问题的方法 什么是缓存击穿、缓存穿透、缓存雪崩?缓存击穿缓存穿透缓存雪崩 Redis…...

【langchain学习】BM25Retriever和FaissRetriever组合 实现EnsembleRetriever混合检索器的实践
展示如何使用 LangChain 的 EnsembleRetriever 组合 BM25 和 FAISS 两种检索方法,从而在检索过程中结合关键词匹配和语义相似性搜索的优势。通过这种组合,我们能够在查询时获得更全面的结果。 1. 导入必要的库和模块 首先,我们需要导入所需…...

【C语言】预处理详解(上)
文章目录 前言1. 预定义符号2. #define 定义常量3. #define定义宏4. 带有副作用的宏参数5. 宏替换的规则 前言 在讲解编译和链接的知识点中,我提到过翻译环境中主要由编译和链接两大部分所组成。 其中,编译又包括了预处理、编译和汇编。当时,…...

uni-app内置组件(基本内容,表单组件)()二
文章目录 一、 基础内容1.icon 图标2.text3.rich-text4.progress 二、表单组件1.button2.checkbox-group和checkbox3.editor 组件4.form5.input6.label7.picker8.picker-view 和 picker-view-column9.radio-group 和 radio10.slider11.switch12.textarea 一、 基础内容 1.icon…...

linux搭建redis超详细
1、下载redis包 链接: https://download.redis.io/releases/ 我以7.0.11为例 2、上传解压 mkdir /usr/local/redis tar -zxvf redis-7.0.11.tar.gz3、进入redis-7.0.11,依次执行 makemake install4、修改配置文件redis.conf vim redis.conf为了能够远程连接redis…...

Flink-DataWorks第二部分:数据集成(第58天)
系列文章目录 数据集成 2.1 概述 2.1.1 离线(批量)同步简介 2.1.2 实时同步简介 2.1.3 全增量同步任务简介 2.2 支持的数据源及同步方案 2.3 创建和管理数据源 文章目录 系列文章目录前言2. 数据集成2.1 概述2.1.1 离线(批量)同步…...
4个从阿里毕业的P7打工人,当起了包子铺的老板
吉祥知识星球http://mp.weixin.qq.com/s?__bizMzkwNjY1Mzc0Nw&mid2247483727&idx1&sndb05d8c1115a4539716eddd9fde4e5c9&chksmc0e47813f793f105017fb8551c9b996dc7782987e19efb166ab665f44ca6d900210e6c4c0281&scene21#wechat_redirect 《网安面试指南》h…...

机器学习赋能6G近场通信:从信道估计到波束赋形的智能革命
1. 项目概述:当6G遇见近场,为何机器学习成为破局关键?如果你关注过5G到6G的技术演进路线,会发现一个核心趋势:天线阵列的规模正在从“大规模”走向“极大规模”。这不仅仅是数量的堆砌,更是通信物理原理的一…...

基于Arduino的模块化DIY智能时钟:从RTC到RGB LED的完整实现
1. 项目概述:打造一台高度可定制的DIY RGB LED时钟如果你和我一样,对市面上千篇一律的电子钟感到审美疲劳,同时又对Arduino和电子DIY充满热情,那么这个项目可能就是为你准备的。我们不是在简单地组装一个套件,而是在亲…...

论文创新点像挤牙膏?导师强推这几个AI论文平台
想写论文又快又好,关键是用对 AI 工具、走对流程——资深教授普遍推荐:千笔AI(中文全流程首选) 豆包学术版(轻量高效) DeepSeek 学术版(理工 / 长文本) Grammarly Academicÿ…...

AI写的论文双率如何压到20%以下?这几款工具实测有效
毕业季、投稿季用AI写论文已经成为不少人的高效选择,但查重率飘红、AIGC疑似率超标两大问题,让很多人犯了难。2026年学术检测标准持续收紧,知网、维普及主流AIGC检测系统同步上线双检规则,两项指标均控制在20%以下才符合基本提交要…...

厨房空调技术白皮书:从风冷到水冷,制冷系统在厨房场景中的工程化演进
厨房空调是暖通行业近三年技术迭代最密集的细分品类。从最初的"凉霸"(本质是风扇),到风冷分体式,再到水冷一体式,每代技术都在解决上一代没有覆盖的用户痛点。本文以工程技术视角,梳理四代厨房制…...

从RD、CS到WK:一文讲透SAR主流成像算法的演进与选型实战
从RD、CS到WK:SAR成像算法选型实战指南 当无人机掠过灾区上空,或卫星扫描地球表面时,合成孔径雷达(SAR)正通过电磁波穿透云层和黑暗,将地面信息转化为高分辨率图像。而决定图像质量的关键,在于工…...

终极Chrome画中画扩展:如何在浏览器中实现高效视频多任务处理
终极Chrome画中画扩展:如何在浏览器中实现高效视频多任务处理 【免费下载链接】picture-in-picture-chrome-extension 项目地址: https://gitcode.com/gh_mirrors/pi/picture-in-picture-chrome-extension 想要在浏览网页、处理文档的同时继续观看视频内容吗…...

ZMJS,把 JavaScript 解释器放进 SAP ABAP 应用服务器之后,很多扩展思路会变得不一样
我今天看这个 oisee/zmjs 仓库时,最吸引人的不是它把 JavaScript 语法做进了 ABAP,而是它选择了一条非常 SAP 的路线,纯 ABAP、无外部依赖、无 Kernel Module、以类和接口的形式运行在 SAP 应用服务器内部。仓库自己的定位很直接,ZMJS 是一个面向 SAP ABAP 的 Mini JavaScr…...

告别枯燥理论!用Unity脚本生命周期与预制体玩转一个“会变身的敌人”
用Unity打造会变身的敌人:脚本生命周期与预制体的实战应用在游戏开发中,敌人AI的行为设计往往是新手开发者最感兴趣也最容易感到困惑的部分。Unity的脚本生命周期和预制体系统为这类需求提供了强大支持,但教科书式的讲解常常让学习者陷入枯燥…...

LoRa物联网与动态基线算法在养殖体温监测中的实战应用
1. 项目概述:为什么我们需要一个智能体温监测系统?在规模化养殖场里干了十几年,我见过太多因为体温异常没被及时发现而导致的损失。一头育肥猪突然不吃食,等饲养员第二天巡栏发现时,可能已经高烧好几天,继发…...