培训第二十五天(python中执行mysql操作并将python脚本共享)
mysql下载路径:
MySQL :: MySQL Community Downloads

[root@2 ~]# vim py001.pya=3b=4print(a+b)print(a**2+b**2)[root@2 ~]# python py001.py 725[root@2 ~]# python3>>> import random>>> random<module 'random' from '/usr/lib64/python3.6/random.py'>>>> quit()[root@2 ~]# vim /usr/lib64/python3.6/random.py
上午
1、通过frp内网穿透共享数据库信息
[root@1 ~]# mysql -p'密码'mysql> create user 'li'@'%' identified by '1';mysql> create database test;mysql> grant all on test.* to 'li';[root@1 ~]# tar -xf frp_0.33.0_linux_amd64.tar.gz[root@1 ~]# cd frp_0.33.0_linux_amd64/[root@1 frp_0.33.0_linux_amd64]# vim frpc.ini [common]server_addr = 123.249.27.70server_port = 7000token=15773141955[mysql]type = tcplocal_ip = 127.0.0.1local_port = 3306remote_port = 6000[root@1 frp_0.33.0_linux_amd64]# ./frpc -c frpc.ini 访问公网ip的7500端口,查看控制面板

在数据库连接工具上,使用公网ip与自己规定的端口号访问数据库

对test数据库具有所有权限
2、在python中连接数据库并结合游标对数据库进行操作
前提:要有python3环境
pip3 config set global.index-url Simple Index //设置 pip3 的全局配置,将默认的 Python 包索引源(index-url)修改为清华大学的镜像源 https://pypi.tuna.tsinghua.edu.cn/simple
上面命令执行失败:执行该命令[root@2 ~]# python3 -m pip install --upgrade pip
1、设置清华镜像站(从国内下载安装包,提高下载和安装工具速度)
2、安装pandas数据分析工具(pandas是知名的数据分析工具,pandas有完整的读取数据的工具,以及DateFrame数据框架,用于保存从数据库中读取的数据)
3、安装pymysql连接器(oracle为开发者提供的python管理mysql的工具,通过这个工具,就可以在不替换原有代码的情况下,应对数据库软件的升级)
[root@2 ~]# python3 -m pip install --upgrade pip #将 pip 工具升级到最新版本[root@2 ~]# pip3 config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple #设置 pip3的全局配置[root@2 ~]# pip3 install pandas #安装Python的pandas库[root@2 ~]# pip3 install pymysql #用于安装pymysql库[root@2 ~]# python3>>> import pymysql as py #以别名py导入pymysql库,可以使用更简洁的别名py来调用pymysql库中的函数和方法>>> import pandas as pd #以别名py导入pandas库>>> py #表示 Python 成功识别了导入的pymysql库,并能够展示关于这个模块的一些基本信息,包括它的位置<module 'pymysql' from '/usr/local/lib/python3.6/site-packages/pymysql/__init__.py'>>>> pd #表示 Python 成功识别了导入的pandas库<module 'pandas' from '/usr/local/lib64/python3.6/site-packages/pandas/__init__.py'>>>> conn=py.connect( #使用pymysql库建立了一个到指定MySQL数据库的连接,变量conn成功保存了这个数据库连接,可以通过它进行后续的数据操作... host='123.249.27.70',... user='abcd',... password='abcd',... database='test',... port=6001);>>> conn #表明您成功创建了一个与 MySQL数据库的连接对象conn,0x7f529dda29b0是这个连接对象在内存中的地址<pymysql.connections.Connection object at 0x7f529dda29b0>>>> cursor=conn.cursor() #创建一个游标对象 cursor>>> cursor<pymysql.cursors.Cursor object at 0x7f52b7ade710>>>> sql="select * from student" #定义了一个SQL查询语句>>> sql'select * from student'>>> cursor.execute(sql) #将您定义的SQL语句select * from student发送到数据库服务器执行5 #查询的结果会被存储在游标内部,您可以通过后续的操作来获取和处理这些结果>>> cursor.fetchall() #获取所有的查询结果,以元组的形式返回一个包含所有行数据的列表((1, '章三', '男'), (2, '李四', '女'), (3, '小凤仙', '女'), (4, '章丘铁锅', '男'), (6, '孙颖莎', '女'))>>> cursor.description #返回一个描述结果集中列的元组序列,通常包括列名、数据类型、显示大小、内部大小、精度、小数位数和是否可为空等(('id', 3, None, 11, 11, 0, False), ('name', 253, None, 180, 180, 0, False), ('gender', 253, None, 16, 16, 0, False))>>> res=cursor.fetchall()>>> res((1, '章三', '男'), (2, '李四', '女'), (3, '小凤仙', '女'), (4, '章丘铁锅', '男'), (6, '孙颖莎', '女'))>>> head=[] # 创建一个head列表>>> desc=cursor.description>>> for var in desc:... print(var)... ('id', 3, None, 11, 11, 0, False)('name', 253, None, 180, 180, 0, False)('gender', 253, None, 16, 16, 0, False)>>> for var in desc:... print(var[0])... idnamegender>>> for var in desc:... head.append(var[0])... >>>head['id', 'name', 'gender']>>> pd.DataFrame(data=res,columns=head) #使用了pandas库创建了一个DataFrame,data=res 表示数据内容,columns=head 指定了列名id name gender0 1 章三 男1 2 李四 女2 3 小凤仙 女3 4 章丘铁锅 男4 6 孙颖莎 女
下午
1、制作python脚本操作数据库
[root@2 ~]# vim python_mysql.pyimport pymysql as pmimport pandasclass Python_Mysql_01(object): #定义了一个名为Python_Mysql_01的类,用于与 MySQL 数据库进行交互并将查询结果转换为 pandas 的 DataFramedef __init__(self): #类的初始化方法,用于标识类的实例化操作print("test")def getConn(self): #用于建立与指定MySQL数据库的连接,并返回连接对象 connconn=pm.connect(host='123.249.27.70',user='abcd',password='abcd',database='test',port=6001)# print(conn)return conndef getRes(self,cursor,sql): #接收一个游标对象cursor和一个SQL语句 sql 。执行 SQL 语句并获取查询结果data,提取表头信息head,然后将结果和表头组成 DataFrame 并返回cursor.execute(sql)# 获得查询的数据data=cursor.fetchall()# 表头head=[item[0] for item in cursor.description]# 组成pandas数据框 DataFramereturn pandas.DataFrame(data=data,columns=head)if __name__=="__main__":# 初始化Python_Mysql_01类,创建实例,pmp,之后所有的方法都可以在实例中>调用pmp=Python_Mysql_01() #实例化Python_Mysql_01类为pmp# 获得connconn=pmp.getConn() #通过pmp调用getConn方法获取数据库连接conn# 获得游标cursor=conn.cursor() #从conn获取游标cursor# print(cursor)df=pmp.getRes(cursor,"select * from student")print(df) #调用pmp的getRes方法执行select * from student语句,并将结果存储在df中,最后打印df[root@2 ~]# python3 python_mysql.py testid name gender0 1 章三 男1 2 李四 女2 3 小凤仙 女3 4 章丘铁锅 男4 6 孙颖莎 女
2、总结
(1)和shell脚本一样python文件也可以称为py脚本,也是将python指令做一个集合
(2)为了脚本更加的智能化和自动化,添加选择语句(智能)循环语句(自动化)
(3)同时为了开发效率,可读性,做了方法,类,模块
3、修改脚本(添加input语句)
conn=pm.connect(host=input("sign host_ip|name:"),user=input("sign database username:"),password=input("sign database password:"),database=input("sign database name:"),port=int(input("sign port no")))......tablename=input("sign tablename")df=pmp.getRes(cursor,"select * from "+tablename)[root@2 ~]# python3 python_mysql.pytestsign host_ip|name:123.249.27.70sign database username:abcdsign database password:abcdsign database name:testsign port no 6001sign tablenamestudentid name gender0 1 章三 男1 2 李四 女2 3 小凤仙 女3 4 章丘铁锅 男4 6 孙颖莎 女
4、打包脚本生成可执行文件
pyinstaller --onefile python_mysql.py
--onefile 选项表示将所有的依赖和代码打包到一个单独的文件中,这样生成的可执行文件更便于分发和使用。
完成打包后,会在当前目录的 dist 文件夹中找到生成的可执行文件。可以将这个可执行文件拷贝到其他机器上(即使该机器没有安装 Python 环境)运行。
[root@2 ~]# pip3 install pyinstaller #安装 PyInstaller 库,用于将 Python 程序打包成可执行文件[root@2 ~]# which pyinstaller #在系统的环境变量路径中查找 pyinstaller 可执行文件的位置[root@2 ~]# pyinstaller --onefile python_mysql.py #使用 PyInstaller 将名为 python_mysql.py 的 Python 脚本打包成一个独立的可执行文件[root@2 ~]# lsanaconda-ks.cfg dist __pycache__ python_mysql.py vbuild py001.py python_mysql_01.spec python_mysql.spec[root@2 ~]# cd dist/[root@2 dist]# lspython_mysql[root@2 dist]# ./python_mysql testsign host_ip|name:123.249.27.70sign database username:abcdsign database password:abcdsign database name:testsign port no:6001sign tablename:studentid name gender0 1 章三 男1 2 李四 女2 3 小凤仙 女3 4 章丘铁锅 男4 6 孙颖莎 女[root@2 ~]# python3 -m http.server 8000 #会在当前目录下启动一个简单的 HTTP 服务器,监听端口 8000[root@2 ~]# nohup python3 -m http.server 8000& #将执行放入后台[1] 12237[root@2 ~]# nohup: 忽略输入并把输出追加到"nohup.out"# 浏览器访问ip加端口号

5、总结
(1)python脚本完成并配置成功之后,将脚本部署为一个二进制的可执行文件
(2)因为py文件要被执行需要在linux中安装python环境
(3)但是二进制可执行文件,不要环境,在任何linux主机上都可以执行
(4)步骤
安装pyinstaller
pip3 install pyinstaller
使用pyinstaller生成可执行文件
pyinstaller --onefile xxx.py# py文件中必须是有if __name__=="__main__";# xxxx
python模块发布web服务
python3 -m http.server 9971
相关文章:
培训第二十五天(python中执行mysql操作并将python脚本共享)
mysql下载路径: MySQL :: MySQL Community Downloads [root2 ~]# vim py001.pya3b4print(ab)print(a**2b**2)[root2 ~]# python py001.py 725[root2 ~]# python3>>> import random>>> random<module random from /usr/lib64/python3.6/random…...

LVS实战项目
LVS简介 LVS:Linux Virtual Server,负载调度器,内核集成,章文嵩,阿里的四层SLB(Server LoadBalance)是基于LVSkeepalived实现。 LVS集群的类型 lvs-nat : 修改请求报文的目标IP, 多目标 IP 的 DNAT lvs-dr ÿ…...

笔记小结:《利用python进行数据分析》之层次化索引
层次化索引 导入样例 层次化索引(hierarchical indexing)是pandas的一项重要功能,它使你能在一个轴上拥有多个(两个以上)索引级别。抽象点说,它使你能以低维度形式处理高维度数据。我们先来看一个简单的例…...

Linux的线程篇章 - 线程池、进程池等知识】
Linux学习笔记---018 Linux之线程池、进程池知识储备1、线程池1.1、池化技术1.1.1、定义与原理1.1.2、优点1.1.3、应用场景 1.2、线程池的特点与优势1.3、线程池的适用场景1.4、线程池的实现 2、进程池2.1、定义和基本概念2.2、进程池的特点与优势2.3、进程池的适用场景&#x…...

汇昌联信做拼多多运营正规吗?
汇昌联信在拼多多平台上的运营是否正规,是许多商家和消费者都关心的问题。随着电商行业的快速发展,平台运营的正规性直接关系到消费者的购物体验和商家的信誉。 一、公司背景与资质审核 明确回答问题:汇昌联信作为一家专业的电商运营公司&…...

240810-Gradio自定义Button按钮+事件函数+按钮图标样式设定
A. 最终效果 B. 参考代码 要通过自定义HTML按钮来触发Gradio自带按钮的 click 函数,你可以使用JavaScript来模拟点击Gradio的按钮。这里是一个示例代码,展示了如何实现这一点: import gradio as gr# 自定义的 JavaScript,用于捕…...

排序算法--快速排序
一、三色旗问题 问题描述 有一个数组是只由0,1,2三种元素构成的整数数组,请使用交换、原地排序而不是计数进行排序: 解题思路 1.定义两个变量,i和j(下标),从index0开始遍历 2.如…...
springMVC -- 学习笔记
前言简介演示 ⇒ (最简单的原理,开发并不这样,理解一下就好)演示 ⇒ 接近真实注解开发(好好理解一下)重要的源码献上 Controller 讲解RequestMapper ⇒ 没啥记的,第一个案例看看就行了RestFul 风…...
连接服务器使用zsh出现乱跳的问题)
修复本地终端(windows)连接服务器使用zsh出现乱跳的问题
目前市面上还没有发现解决方案,记录一下! 1.起因: 在服务器配置了zsh后,用本地的windows去连接的时候,终端内容会出现乱跳,比如输入了一个“l”,后面出现多个“lll”,如下: ⚡ roo…...

【扒代码】regression_head.py
import torch from torch import nnclass UpsamplingLayer(nn.Module):# 初始化 UpsamplingLayer 类def __init__(self, in_channels, out_channels, leakyTrue):super(UpsamplingLayer, self).__init__() # 调用基类的初始化方法# 初始化一个序列模型,包含卷积层、…...

vue2 使用axios 请求后台返回文件流导出为excel
目录 步骤 1: 安装 Axios 步骤 2: 创建 Axios 实例 步骤 3: 发起请求并处理文件流 说明 步骤 1: 安装 Axios 首先,确保项目中已经安装了 Axios。如果没有,可以通过以下命令进行安装: npm install axios 步骤 2: 创建 Axios 实例 为了更…...
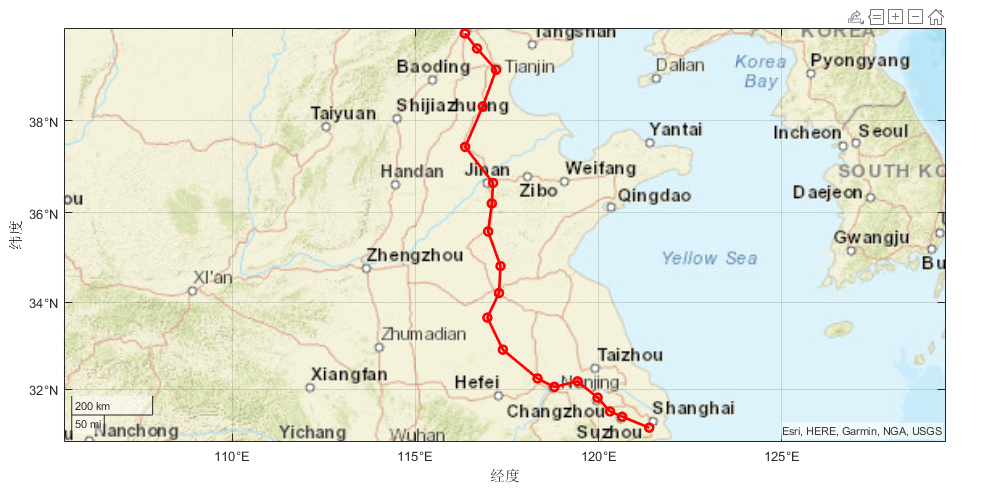
MATLAB数据可视化:在地图上画京沪线的城市连线
matlab自带的geoplot(lat,lon) 可以在地理坐标中绘制线条。使用 lat和lon分别指定以度为单位的经度和纬度坐标。 绘制京沪线所经城市线条: citys [116.350009,39.853928; 116.683546,39.538304; 117.201509,39.085318; 116.838715,38.304676;...116.359244,37.436…...

【AI】CV基础1
定期更新,建议关注更新收藏。 本站友情链接: OCR篇1 可变形卷积Deformable Conv opencv-python形态学操作合集 目录 仿射变换图像二阶导数本质探讨PIL通道、模式、尺寸、坐标系统、调色板、信息滤波器实现图像格式转换 OpenCV轮廓提取 仿射变换 仿射变换…...

数据结构《栈》
数据结构《栈》 1、栈的概念及结构2、栈的实现3、练习: 1、栈的概念及结构 栈:一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操作。进行数据插入和删除操作的一端 称为栈顶,另一端称为栈底。栈中的数据元素遵守后进先出LIFO&…...

说一说mysql的having?和where有什么区别?
在 MySQL 中,HAVING 子句和 WHERE 子句都是用于过滤查询结果的,但它们之间有一些重要的区别。下面我将详细介绍这两个子句的区别以及它们的使用场景。 1. HAVING 子句 作用: HAVING 子句用于过滤聚合后的结果集。它通常与 GROUP BY 子句一起使用&#x…...

LeetCode45. 跳跃游戏 II
题目链接: 45. 跳跃游戏 II - 力扣(LeetCode) 思路分析:这属于上一题的变种,思路有所不同,要用到贪心的思想。从第一步开始,在可以跳跃的范围内,选择能够到达最远位置的点将其作为…...

算法打卡 Day19(二叉树)-平衡二叉树 + 二叉树的所有路径 + 左叶子之和 + 完全二叉树的节点个数
Leetcode 101-平衡二叉树 文章目录 Leetcode 101-平衡二叉树题目描述解题思路 Leetcode 257-二叉树的所有路径题目描述解题思路 Leetcode 404-左叶子之和题目描述解题思路 Leetcode 222-完全二叉树的节点个数题目描述解题思路 题目描述 https://leetcode.cn/problems/balanced…...
/国际专线(IPLC)-全球覆盖,无界沟通)
国际以太网专线 (IEPL)/国际专线(IPLC)-全球覆盖,无界沟通
中国联通国际公司产品:国际以太网专线 (IEPL)/国际专线(IPLC)—— 跨境数据传输的坚实桥梁 在全球化日益加深的今天,跨境、跨地域的数据传输需求激增,企业对数据传输的速度、安全性和稳定性提出了前所未有的高要求。中…...

信息安全管理知识体系攻略(至简)
信息安全管理知识体系主要包括信息安全管理体系、信息安全策略、信息安全系统、信息安全技术体系等。 一、信息安全管理 1、信息安全管理体系(ISMS)。ISO27001是国际标准化组织(ISO)和国际电工委员会(ICE)…...

HCIE学习笔记:IPV6 地址、ICMP V6、NDP 、DAD (更新补充中)
系列文章目录 提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 系列文章目录前言一、IPV4、IPv6包头对比1. IPV4包头2.IPv6包头3.IPV6扩展包头 二、IPV6基础知识地址结构、地址分类三、ICMPV4、ICMPV61、 lnternet控…...

为什么92%的Sora 2初学者卡在第4步?——帧一致性崩塌诊断工具包+时间轴锚点校准法
更多请点击: https://kaifayun.com 第一章:Sora 2视频生成的核心原理与环境准备 Sora 2并非OpenAI官方发布的模型,而是社区基于Sora技术理念构建的开源复现与增强框架,其核心依托于时空联合建模的扩散变换器(Spacetim…...

UE4动画蓝图实战:用双骨骼IK节点搞定手部穿模,附完整蓝图节点截图
UE4动画蓝图实战:双骨骼IK节点解决手部穿模的完整指南在角色动画开发中,手部穿模问题堪称"视觉杀手"。想象一下精心设计的角色挥拳时,拳头直接穿过墙壁或敌人身体——这种违和感足以毁掉整个场景的沉浸感。本文将彻底解决这个痛点&…...

Obsidian PDF++:如何在Obsidian中实现PDF与笔记的无缝双向链接?
Obsidian PDF:如何在Obsidian中实现PDF与笔记的无缝双向链接? 【免费下载链接】obsidian-pdf-plus PDF: the most Obsidian-native PDF annotation & viewing tool ever. Comes with optional Vim keybindings. 项目地址: https://gitcode.com/gh_…...

HFSS仿真结果怎么看?一文读懂S参数与电场图,让你的T型波导分析不再迷茫
HFSS仿真结果深度解析:从S参数到电场图的工程实践指南面对HFSS仿真生成的复杂数据图表,许多工程师常陷入"看得见数据却读不懂含义"的困境。本文将带您穿透数据表象,掌握T型波导性能分析的核心方法论。1. S参数:波导性能…...
)
Claude端到端测试设计:从零搭建可审计、可回放、可量化的AI服务测试流水线(含开源Schema校验工具)
更多请点击: https://codechina.net 第一章:Claude端到端测试设计 端到端测试是验证Claude模型在真实用户交互链路中行为一致性的关键手段。它覆盖从原始提示输入、上下文管理、流式响应生成,到输出解析与业务校验的全路径,确保模…...

广州因特智能:AI视觉软硬结合,打破半导体检测装备“卡脖子”困境
【导语:广州因特智能科技孵化于西安电子科技大学广州研究院,专注用AI视觉技术解决工业场景的“卡脖子”检测难题,为半导体、光通信、新能源三大领域提供高端检测装备。】校地合作孵化,构建完整能力体系广州因特智能科技由西安电子…...
)
Unity/Unreal开发者必看:用手机和陀螺仪实验,5分钟搞懂万向节死锁(附避坑指南)
Unity/Unreal开发者实战指南:用手机陀螺仪5分钟破解万向节死锁当你调试第一人称视角时,角色突然卡在墙面无法转动;当无人机模型在俯冲90度时失控乱转——这些很可能都是万向节死锁(Gimbal Lock)在作祟。作为实时3D开发中最恼人的数学陷阱之一…...

圈复杂度>12=技术债炸弹?DeepSeek静态分析实战:从17.8→3.2的重构路径全披露
更多请点击: https://codechina.net 第一章:圈复杂度>12技术债炸弹?DeepSeek静态分析实战:从17.8→3.2的重构路径全披露 当函数圈复杂度(Cyclomatic Complexity)持续高于12,它不再是…...

用PyTorch复现FactorVAE:一个能同时预测收益和风险的量化模型实战教程
用PyTorch实战FactorVAE:构建收益与风险双预测的量化模型 在量化投资领域,传统线性因子模型正逐渐被非线性机器学习方法所取代。然而金融数据特有的低信噪比特性,使得直接从市场数据中提取有效因子成为一项艰巨挑战。本文将深入探讨如何利用P…...

模式分层预测驱动推断:处理复杂缺失数据的统计新框架
1. 项目概述:当数据“缺胳膊少腿”时,如何做出靠谱的推断?在数据科学和统计建模的日常工作中,我们最怕遇到什么?不是复杂的算法,也不是海量的数据,而是数据本身“缺胳膊少腿”——也就是缺失值。…...