python网络爬虫(四)——实战练习
0.为什么要学习网络爬虫
深度学习一般过程:

收集数据,尤其是有标签、高质量的数据是一件昂贵的工作。
爬虫的过程,就是模仿浏览器的行为,往目标站点发送请求,接收服务器的响应数据,提取需要的信息,并进行保存的过程。
Python为爬虫的实现提供了工具:requests模块、BeautifulSoup库
1.爬虫练习前言
本次实践使用Python来爬取百度百科中《青春有你2》所有参赛选手的信息。
数据获取:https://baike.baidu.com/item/青春有你第二季

普通用户:
打开浏览器 --> 往目标站点发送请求 --> 接收响应数据 --> 渲染到页面上。
爬虫程序:
模拟浏览器 --> 往目标站点发送请求 --> 接收响应数据 --> 提取有用的数据 --> 保存到本地/数据库。
本实践中将会使用以下两个模块,首先对这两个模块简单了解以下:
request模块:
requests是python实现的简单易用的HTTP库,官网地址:http://cn.python-requests.org/zh_CN/latest/
requests.get(url)可以发送一个http get请求,返回服务器响应内容。
BeautifulSoup库:
BeautifulSoup是一个可以从HTML或XML文件中提取数据的Python库。
网址:https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
BeautifulSoup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,其中一个是 lxml。
BeautifulSoup(markup, “html.parser”)或者BeautifulSoup(markup,
“lxml”),推荐使用lxml作为解析器,因为效率更高。
2.程序代码
import json
import re
import requests
import datetime
from bs4 import BeautifulSoup
from urllib import parse
import ostoday = datetime.date.today().strftime('%Y%m%d')def crawl_wiki_data():"""爬取百度百科中《青春有你2》中参赛选手信息,返回html"""headers = {#'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'#'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.41 Safari/537.36 Edg/101.0.1210.32''User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36 Edg/128.0.0.0'}url='https://baike.baidu.com/item/青春有你第二季'try:response = requests.get(url, headers=headers)print(response.status_code)# 将一段文档传入BeautifulSoup的构造方法,就能得到一个文档的对象, 可以传入一段字符串soup = BeautifulSoup(response.text, 'lxml')# 返回的是class为table-view log-set-param的<table>所有标签tables = soup.find_all('table', {'class': 'table-view log-set-param'})crawl_table_title = "参赛学员"for table in tables:# 对当前节点前面的标签和字符串进行查找table_titles = table.find_previous('div').find_all('h3')for title in table_titles:if (crawl_table_title in title):return tableexcept Exception as e:print(e)def parse_wiki_data(table_html):'''从百度百科返回的html中解析得到选手信息,以当前日期作为文件名,存JSON文件,保存到work目录下'''bs = BeautifulSoup(str(table_html), 'lxml')all_trs = bs.find_all('tr')error_list = ['\'', '\"']stars = []for tr in all_trs[1:]:all_tds = tr.find_all('td')star = {}# 姓名star["name"] = all_tds[0].text# 个人百度百科链接star["link"] = 'https://baike.baidu.com' + all_tds[0].find('a').get('href')# 籍贯star["zone"] = all_tds[1].text# 星座star["constellation"] = all_tds[2].text# 身高star["height"] = all_tds[3].text# 体重star["weight"] = all_tds[4].text# 花语,去除掉花语中的单引号或双引号flower_word = all_tds[5].textfor c in flower_word:if c in error_list:flower_word = flower_word.replace(c, '')# 公司if not all_tds[6].find('a') is None:star["company"] = all_tds[6].find('a').textelse:star["company"] = all_tds[6].textstar["flower_word"] = flower_wordstars.append(star)json_data = json.loads(str(stars).replace("\'", "\""))with open('data/' + today + '.json', 'w', encoding='UTF-8') as f:json.dump(json_data, f, ensure_ascii=False)def crawl_pic_urls():'''爬取每个选手的百度百科图片,并保存'''with open('data/' + today + '.json', 'r', encoding='UTF-8') as file:json_array = json.loads(file.read())statistics_datas = []headers = {# 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36''User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.41 Safari/537.36 Edg/101.0.1210.32'}for star in json_array:name = star['name']link = star['link']# 向选手个人百度百科发送一个http get请求response = requests.get(link, headers=headers)# 将一段文档传入BeautifulSoup的构造方法,就能得到一个文档的对象bs = BeautifulSoup(response.text, 'lxml')# 从个人百度百科页面中解析得到一个链接,该链接指向选手图片列表页面pic_list_url = bs.select('.summary-pic a')[0].get('href')pic_list_url = 'https://baike.baidu.com' + pic_list_url# 向选手图片列表页面发送http get请求pic_list_response = requests.get(pic_list_url, headers=headers)# 对选手图片列表页面进行解析,获取所有图片链接bs = BeautifulSoup(pic_list_response.text, 'lxml')pic_list_html = bs.select('.pic-list img ')pic_urls = []for pic_html in pic_list_html:pic_url = pic_html.get('src')pic_urls.append(pic_url)# 根据图片链接列表pic_urls, 下载所有图片,保存在以name命名的文件夹中down_pic(name, pic_urls)def down_pic(name,pic_urls):'''根据图片链接列表pic_urls, 下载所有图片,保存在以name命名的文件夹中,'''path = 'work/'+'pics/'+name+'/'if not os.path.exists(path):os.makedirs(path)for i, pic_url in enumerate(pic_urls):try:pic = requests.get(pic_url, timeout=15)string = str(i + 1) + '.jpg'with open(path+string, 'wb') as f:f.write(pic.content)print('成功下载第%s张图片: %s' % (str(i + 1), str(pic_url)))except Exception as e:print('下载第%s张图片时失败: %s' % (str(i + 1), str(pic_url)))print(e)continuedef show_pic_path(path):'''遍历所爬取的每张图片,并打印所有图片的绝对路径'''pic_num = 0for (dirpath, dirnames, filenames) in os.walk(path):for filename in filenames:pic_num += 1print("第%d张照片:%s" % (pic_num, os.path.join(dirpath, filename)))print("共爬取《青春有你2》选手的%d照片" % pic_num)if __name__ == '__main__':#爬取百度百科中《青春有你2》中参赛选手信息,返回htmlhtml = crawl_wiki_data()#解析html,得到选手信息,保存为json文件parse_wiki_data(html)#从每个选手的百度百科页面上爬取图片,并保存crawl_pic_urls()#打印所爬取的选手图片路径#('/home/aistudio/work/pics/')print("所有信息爬取完成!")
相关文章:
python网络爬虫(四)——实战练习
0.为什么要学习网络爬虫 深度学习一般过程: 收集数据,尤其是有标签、高质量的数据是一件昂贵的工作。 爬虫的过程,就是模仿浏览器的行为,往目标站点发送请求,接收服务器的响应数据,提取需要的信息,…...

tio websocket 客户端 java 代码 工具类
为了更好地组织代码并提高可复用性,我们可以将WebSocket客户端封装成一个工具类。这样可以在多个地方方便地使用WebSocket客户端功能。以下是使用tio库实现的一个WebSocket客户端工具类。 1. 添加依赖 确保项目中添加了tio的依赖。如果使用的是Maven,可以…...

通过卷积神经网络(CNN)识别和预测手写数字
一:卷积神经网络(CNN)和手写数字识别MNIST数据集的介绍 卷积神经网络(Convolutional Neural Networks,简称CNN)是一种深度学习模型,它在图像和视频识别、分类和分割任务中表现出色。CNN通过模仿…...

【A题第二套完整论文已出】2024数模国赛A题第二套完整论文+可运行代码参考(无偿分享)
“板凳龙” 闹元宵路径速度问题 摘要 本文针对传统舞龙进行了轨迹分析,并针对一系列问题提出了解决方案,将这一运动进行了模型可视化。 针对问题一,我们首先对舞龙的螺线轨迹进行了建模,将直角坐标系转换为极坐标系࿰…...

一份热乎的数据分析(数仓)面试题 | 每天一点点,收获不止一点
目录 1. 已有ods层⽤⼾表为ods_online.user_info,有两个字段userid和age,现设计数仓⽤⼾表结构如 下: 2. 设计数据仓库的保单表(⾃⾏命名) 3. 根据上述两表,查询2024年8⽉份,每⽇,…...

3 html5之css新选择器和属性
要说css的变化那是发展比较快的,新增的选择器也很多,而且还有很多都是比较实用的。这里举出一些案例,看看你平时都是否用过。 1 新增的一些写法: 1.1 导入css 这个是非常好的一个变化。这样可以让我们将css拆分成公共部分或者多…...

【Kubernetes】K8s 的鉴权管理(一):基于角色的访问控制(RBAC 鉴权)
K8s 的鉴权管理(一):基于角色的访问控制(RBAC 鉴权) 1.Kubernetes 的鉴权管理1.1 审查客户端请求的属性1.2 确定请求的操作 2.基于角色的访问控制(RBAC 鉴权)2.1 基于角色的访问控制中的概念2.1…...

保研 比赛 利器: 用AI比赛助手降维打击数学建模
数学建模作为一个热门但又具有挑战性的赛道,在保研、学分加分、简历增色等方面具有独特优势。近年来,随着AI技术的发展,特别是像GPT-4模型的应用,数学建模的比赛变得不再那么“艰深”。通过利用AI比赛助手,不仅可以大大…...
秋招校招,在线性格测评应该如何应对
秋招校招,如果遇到在线测评,如何应对? 这里写个总结稿,希望对大家有些帮助。在线测评是企业深入了解求职人的渠道,如果是性格测试,会要求测试者能够快速答出,以便于反应实际情况(时间…...
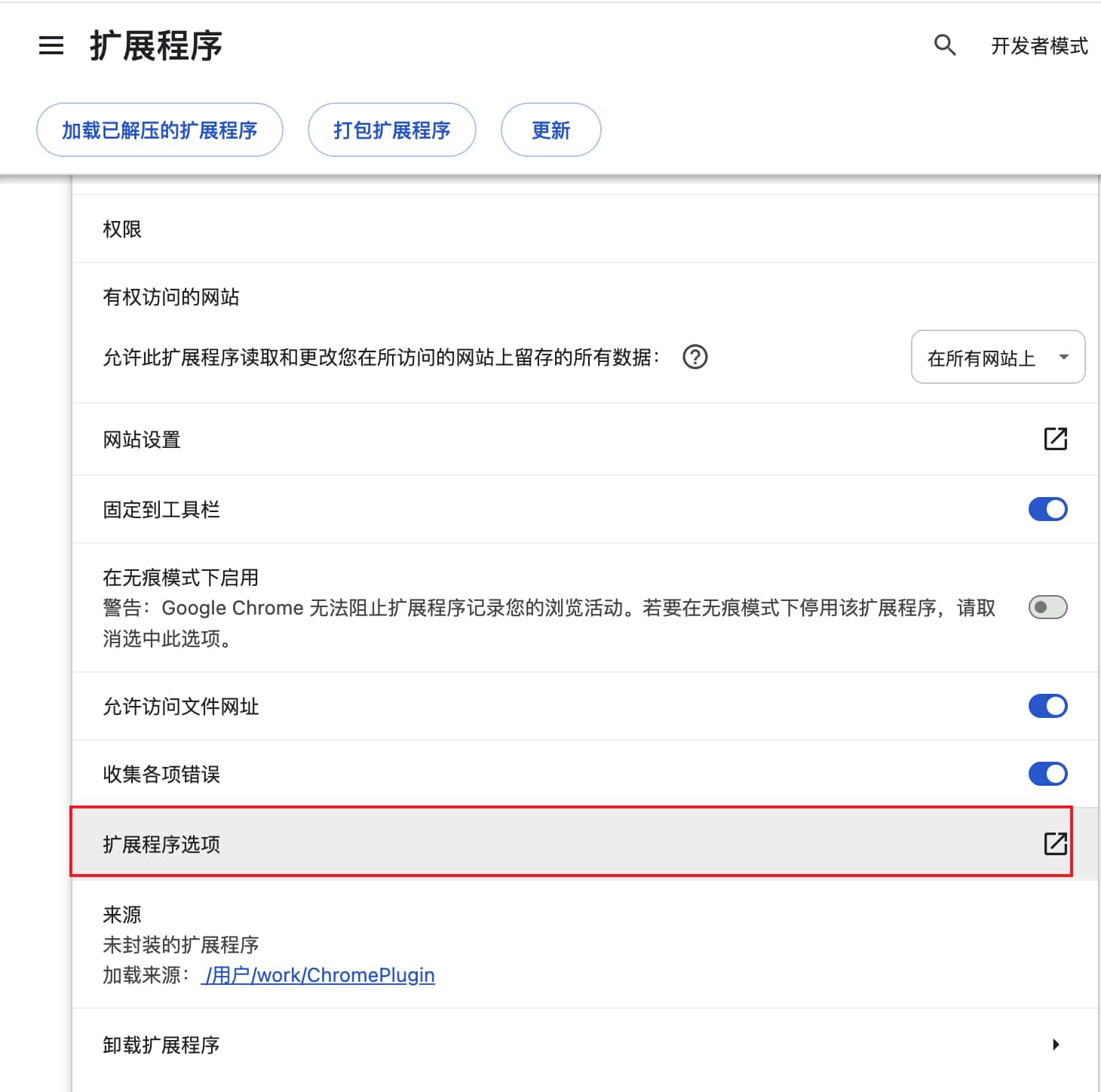
chrome 插件开发入门
1. 介绍 Chrome 插件可用于在谷歌浏览器上控制当前页面的一些操作,可自主控制网页,提升效率。 平常我们可在谷歌应用商店中下载谷歌插件来增强浏览器功能,作为开发者,我们也可以自己开发一个浏览器插件来配合我们的日常学习工作…...

揭开面纱--机器学习
一、人工智能三大概念 1.1 AI、ML、DL 1.1.1 什么是人工智能? AI:Artificial Intelligence 人工智能 AI is the field that studies the synthesis and analysis of computational agents that act intelligently AI is to use computers to analog and instead…...

Python中的私有属性与方法:解锁面向对象编程的秘密
在Python的广阔世界里,面向对象编程(OOP)是一种强大而灵活的方法论,它帮助我们更好地组织代码、管理状态,并构建可复用的软件组件。而在这个框架内,私有属性与方法则是实现封装的关键机制之一。它们不仅有助…...

开篇_____何谓安卓机型“工程固件” 与其他固件的区别 作用
此系列博文将分析安卓系列机型与一些车机 wifi板子等工程固件的一些常识。从早期安卓1.0起始到目前的安卓15,一些厂家发布新机型的常规流程都是从工程机到量产的过程。在其中就需要调试各种参数以便后续的量产参数可以固定到最佳,工程固件由此诞生。 后…...

DBeaver 连接 MySQL 报错 Public Key Retrieval is not allowed
DBeaver 连接 MySQL 报错 Public Key Retrieval is not allowed 文章目录 DBeaver 连接 MySQL 报错 Public Key Retrieval is not allowed问题解决办法 问题 使用 DBeaver 连接 MySQL 数据库的时候, 一直报错下面的错误 Public Key Retrieval is not allowed详细…...

三个月涨粉两万,只因为知道了这个AI神器
大家好,我是凡人,最近midjourney的账号到期了,正准备充值时,被一个国内AI图片的生成神器给震惊了,不说废话,先上图看看生成效果。 怎么样还不错吧,是我非常喜欢的国风画,哈哈&#x…...

vulhub GhostScript 沙箱绕过(CVE-2018-16509)
1.搭建环境 2.进入网站 3.下载包含payload的png文件 vulhub/ghostscript/CVE-2018-16509/poc.png at master vulhub/vulhub GitHub 4.上传poc.png图片 5.查看创建的文件...

李宏毅机器学习笔记——反向传播算法
反向传播算法 反向传播(Backpropagation)是一种用于训练人工神经网络的算法,它通过计算损失函数相对于网络中每个参数的梯度来更新这些参数,从而最小化损失函数。反向传播是深度学习中最重要的算法之一,通常与梯度下降…...

内推|京东|后端开发|运维|算法...|北京 更多岗位扫内推码了解,直接投递,跟踪进度
热招岗位 更多岗位欢迎扫描末尾二维码,小程序直接提交简历等面试。实时帮你查询面试进程。 安全运营中心研发工程师 岗位要求 1、本科及以上学历,3年以上的安全相关工作经验; 2、熟悉c/c、go编程语言之一、熟悉linux网络编程和系统编程 3、…...

编写Dockerfile第二版
目标 更快的构建速度 更小的Docker镜像大小 更少的Docker镜像层 充分利用镜像缓存 增加Dockerfile可读性 让Docker容器使用起来更简单 总结 编写.dockerignore文件 容器只运行单个应用 将多个RUN指令合并为一个 基础镜像的标签不要用latest 每个RUN指令后删除多余文…...

校验码:奇偶校验,CRC循环冗余校验,海明校验码
文章目录 奇偶校验码CRC循环冗余校验码海明校验码 奇偶校验码 码距:任何一种编码都由许多码字构成,任意两个码字之间最少变化的二进制位数就称为数据检验码的码距。 奇偶校验码的编码方法是:由若干位有效信息(如一个字节),再加上…...

如何在浏览器中一键解密所有加密音乐文件:Unlock-Music完全指南
如何在浏览器中一键解密所有加密音乐文件:Unlock-Music完全指南 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地…...

DS4Windows终极指南:3步让PS手柄在PC上完美运行游戏
DS4Windows终极指南:3步让PS手柄在PC上完美运行游戏 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 还在为PS手柄连接Windows电脑后无法识别而烦恼吗?🎮…...

总线式智能提示灯系统设计:从恒流驱动到模块化架构
1. 项目概述:从传统到智能的剧场提示灯系统革新在剧场、演播室或者大型活动现场的后台,如果你待过,一定对那套“红灯停,绿灯行”的提示灯系统不陌生。导演或舞台监督通过对讲机喊“Standby”(准备)…...

【大模型聚合平台深度评测:阿里云百炼 vs 腾讯云 ADP,企业如何选型?】
大模型聚合平台深度评测:阿里云百炼 vs 腾讯云 ADP,企业如何选型? 随着大模型技术的快速发展,越来越多的企业开始将 AI 能力融入到业务流程中。然而,面对市场上众多的大模型产品,企业往往面临着 “选择困难…...

NBT数据可视化编辑解决方案:NBTExplorer技术解析与应用指南
NBT数据可视化编辑解决方案:NBTExplorer技术解析与应用指南 【免费下载链接】NBTExplorer A graphical NBT editor for all Minecraft NBT data sources 项目地址: https://gitcode.com/gh_mirrors/nb/NBTExplorer NBTExplorer是一款面向Minecraft数据管理的…...

基于ATmega328P与TFT屏的园艺环境监控系统:硬件选型与软件架构详解
1. 项目概述:打造你的家庭园艺数据监控中心如果你和我一样,是个喜欢在阳台或后院捣鼓花草的园艺爱好者,同时又对电子DIY有点兴趣,那么这个项目绝对会让你兴奋。我们不是在简单地种花,而是在用数据“聆听”植物的需求。…...

<数据集>yolo高粱叶片病害识别<目标检测>
数据集下载链接https://download.csdn.net/download/qq_53332949/92902223数据集格式:VOCYOLO格式 图片数量:3242张 标注数量(xml文件个数):3242 标注数量(txt文件个数):3242 标注类别数:1 使用标注工具ÿ…...

通过用量看板清晰观测Taotoken的API调用成本与消耗
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过用量看板清晰观测Taotoken的API调用成本与消耗 对于将大模型能力集成到产品中的团队而言,API调用成本是项目预算与…...

D3KeyHelper终极指南:5分钟掌握暗黑3技能自动化
D3KeyHelper终极指南:5分钟掌握暗黑3技能自动化 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper D3KeyHelper是一款专为《暗黑破坏神3》玩…...
机制)
不只是改注册表:深入理解UE引擎GPU超时检测与恢复(TDR)机制
不只是改注册表:深入理解UE引擎GPU超时检测与恢复(TDR)机制当你在虚幻引擎中调试一个复杂的场景时,突然屏幕冻结,紧接着弹出一个令人沮丧的GPU崩溃提示——这种经历对于任何使用UE4/5的开发者来说都不陌生。表面上看&a…...