大模型笔记02--基于fastgpt和oneapi构建大模型应用平台
大模型笔记02--基于fastgpt和oneapi构建大模型应用平台
- 介绍
- 部署&测试
- 部署fastgpt+oneapi服务
- 部署向量模型m3e和nomic-embed-text
- 测试大模型
- 注意事项
- 说明
介绍
随着大模型的快速发展,众多IT科技厂商都开发训练了各自的大模型,并提供了各具特色的AI产品。早期比较常见的做法是提供聊天机器人,如今逐步发展为各类AI智能体,用户可以在平台上选择自己需要能力构建特有的智能体。例如语聚AI,智谱清言,Fastgpt, coze, dify 等平台,它们都具备了较强的智能体定制能力。
如果想快速体验可以直接在平台上注册账号,按需使用即可。若想为自己的团队或者公司提供智能体,那么就可以基于开源产品搭建相关平台,或者二开。
本文基于开源的FastGPT, Ollama, Oneapi搭建一个基于LLM大语言模型的知识库问答平台, 实现知识管理和检索能力。
部署&测试
前提条件需要部署ollama,具体步骤可以参考文档 大模型笔记01–基于ollama和open-webui快速部署chatgpt。
其次需要部署FastGPT和Oneapi, 它们的主要用途如下:
FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景。
Oneapi一个开源的OpenAI 接口管理 & 分发系统,它支持 Azure,Anthropic Claude,Google PaLM 2 & Gemini, Ollama、智谱 ChatGLM、百度文心一言、讯飞星火认知、阿里通义千问、360 智脑以及腾讯混元等大模型,可用于二次分发管理 key.
部署fastgpt+oneapi服务
fastgpt提供了基于docker compose的快速部署方式,此处直接使用docker compose来部署:
mkdir fastgpt
cd fastgpt
curl -O https://raw.githubusercontent.com/labring/FastGPT/main/projects/app/data/config.json
# pgvector 版本(测试推荐,简单快捷)
curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/files/docker/docker-compose-pgvector.yml
docker compose up -d
# milvus 版本
# curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/files/docker/docker-compose-milvus.yml
# zilliz 版本
# curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/files/docker/docker-compose-zilliz.yml
服务正常拉起来后,可以通过docker compose ps 开到如下6个运行的容器:

通过 http://127.0.0.1:3000 访问fastgpt, 默认账号/密码: root / 1234

通过 http://127.0.0.1:3001/ 访问oneapi, 默认账号/密码: root / 123456

在oneapi中按需配置ollama渠道,使用Ollama自己部署模型的时候秘钥可以随意写,使用其它大模型厂商的话要按需填写提供的秘钥

渠道添加完成后记得测试一下,确保可以正常访问ollama

在fastgpt的confg.json中加上对应的模型,按需更改model和name字段,然后重启fastgpt服务即可
vim config.json
"llmModels": [{"model": "gemma2:9b", // 模型名(对应OneAPI中渠道的模型名)"name": "ollama-gemma2-9b", // 模型别名"avatar": "/imgs/model/openai.svg", // 模型的logo"maxContext": 125000, // 最大上下文"maxResponse": 16000, // 最大回复"quoteMaxToken": 120000, // 最大引用内容"maxTemperature": 1.2, // 最大温度"charsPointsPrice": 0, // n积分/1k token(商业版)"censor": false, // 是否开启敏感校验(商业版)"vision": true, // 是否支持图片输入"datasetProcess": true, // 是否设置为知识库处理模型(QA),务必保证至少有一个为true,否则知识库会报错"usedInClassify": true, // 是否用于问题分类(务必保证至少有一个为true)"usedInExtractFields": true, // 是否用于内容提取(务必保证至少有一个为true)"usedInToolCall": true, // 是否用于工具调用(务必保证至少有一个为true)"usedInQueryExtension": true, // 是否用于问题优化(务必保证至少有一个为true)"toolChoice": true, // 是否支持工具选择(分类,内容提取,工具调用会用到。目前只有gpt支持)"functionCall": false, // 是否支持函数调用(分类,内容提取,工具调用会用到。会优先使用 toolChoice,如果为false,则使用 functionCall,如果仍为 false,则使用提示词模式)"customCQPrompt": "", // 自定义文本分类提示词(不支持工具和函数调用的模型"customExtractPrompt": "", // 自定义内容提取提示词"defaultSystemChatPrompt": "", // 对话默认携带的系统提示词"defaultConfig": {} // 请求API时,挟带一些默认配置(比如 GLM4 的 top_p)},{"model": "qwen2:7b", // 模型名(对应OneAPI中渠道的模型名)"name": "ollama-qwen2-7b", // 模型别名......"defaultConfig": {} // 请求API时,挟带一些默认配置(比如 GLM4 的 top_p)},{"model": "llama3.1:8b", // 模型名(对应OneAPI中渠道的模型名)"name": "ollama-llama3.1-8b", // 模型别名......}
docker restart fastgpt

部署向量模型m3e和nomic-embed-text
可以通过docker的形式部署m3e, 也可以通过ollama的形式部署
docker:
docker run -d --net=host --name m3e -p 6008:6008 --gpus all -e sk-key=111111admin registry.cn-hangzhou.aliyuncs.com/fastgpt_docker/m3e-large-api
测试方法
$ curl --location --request POST 'http://0.0.0.0:6008/v1/embeddings' \
--header 'Authorization: Bearer 111111admin' \
--header 'Content-Type: application/json' \
--data-raw '{"model": "m3e","input": ["laf是什么"]
}'ollama:
ollama pull nomic-embed-text:v1.5
ollama pull milkey/m3e:large-f16
测试方法
curl http://localhost:11434/api/embeddings -d '{"model": "nomic-embed-text:v1.5","prompt": "The sky is blue because of Rayleigh scattering"
}'
m3e-large-api测试输出:

nomic-embed-text:v1.5 测试输出:

测试成功后在oneapi中配置上述向量模型。
若使用m3e,其代理填写 http://192.xx.xx.1:6008(按需填写实际m3e服务的ip和端口),秘钥填写上述sk-key对应的内容;
若通过ollama访问向量模型,其代理需要配置为 http://192.x.x.1:11435(前面ip根据实际填写即可,此处使用代理的端口11435),ollama默认使用/api/embeddings提供向量访问,因此我们需要使用代理将/v1/embeddings转发到该接口,具体配置见 注意事项->问题4中的 /etc/nginx/conf.d/ollama.conf ;
配置完成后需要测试可用性, 然后在 config.json 中加上自己的向量模型,具体配置如下:
vim config.json
"vectorModels": [{"model": "nomic-embed-text:v1.5", // 模型名(与OneAPI对应)"name": "nomic-embed-text-v1.5", // 模型展示名"avatar": "/imgs/model/openai.svg", // logo"charsPointsPrice": 0, // n积分/1k token"defaultToken": 500, // 默认文本分割时候的 token"maxToken": 2000, // 最大 token"weight": 100, // 优先训练权重"defaultConfig": {}, // 自定义额外参数。例如,如果希望使用 embedding3-large 的话,可以传入 dimensions:1024,来返回1024维度的向量。(目前必须小于1536维度)"dbConfig": {}, // 存储时的额外参数(非对称向量模型时候需要用到)"queryConfig": {} // 参训时的额外参数},{"model": "text-embedding-3-small","name": "text-embedding-3-small","avatar": "/imgs/model/openai.svg","charsPointsPrice": 0,"defaultToken": 512,"maxToken": 3000,"weight": 100},{"model": "m3e","name": "m3e","avatar": "/imgs/model/openai.svg","charsPointsPrice": 0,"defaultToken": 512,"maxToken": 3000,"weight": 100}]
测试大模型
- 新建数据集
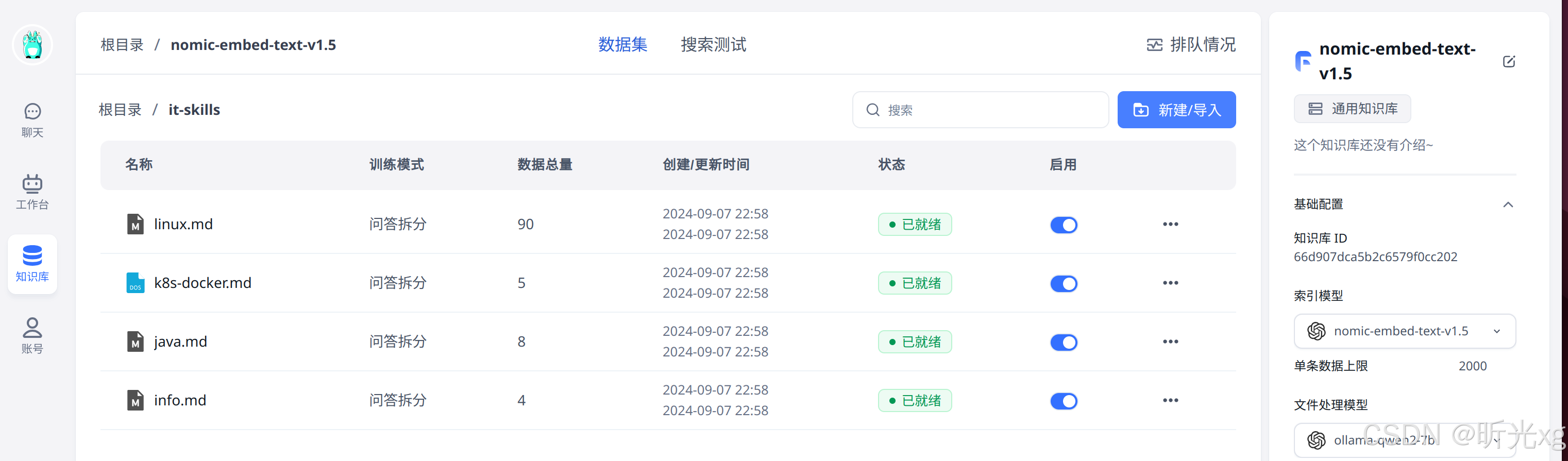
如下图,我们直接新建数据集 nomic-embed-text-v1.5 ,使用nomic-embed-text:v1.5 和 qwen2:7b 两个模型。

在skills目录提前准备好的文档,并按照步骤导入,数据导入到Ready需要大模型发一些时间处理(GPU一般的话就比较慢,笔者P2200 5G显存就有点慢),耐心等待处理完成即可

- 新建大模型应用
参考官方文档在工作台新建一个大模型应用,此处新建agent-qwen2-7b,使用qwen2-7b大模型,关联上知识库 nomic-embed-text-v1.5(搜索模式使用混合检索), 配置完成后测试一下结果,可以发现它有从5个目标参考文档中检索知识,结合检索的目标知识回答我们的问题。

测试完成,点击发布,发布成功后可以直接通过聊天界面进入到agent-qwen2-7b应用了,如下图:

至此,一个具备知识库能力的智能体应用已经完成了; 若需要让其更加智能,我们可以按需补充合适的文档和提示词,让其按照我们的方式检索、回答问题。
注意事项
-
ollama需要配置 OLLAMA_HOST=0.0.0.0 , 否则oneapi容器无法正常访问ollama服务。
-
配置渠道的时候最好每个渠道配置唯一的一个模型,这样使用的时候容易区分。
-
新增知识库导入数据时候报错"当前分组 default 下对于模型 text-embedding-ada-002 无可用渠道"

如果有openai的token的话可以在oneapi配置text-embedding-ada-002这个渠道,没有的话自行部署向量模型,并在oneapi新建对应的渠道,新建知识库的时使用自己新建的渠道即可。
当前分组 default 下对于模型 text-embedding-ada-002 无可用渠道 -
在使用知识库的时候,发现数据一直处于索引中,机器CPU长期处于高负荷状态

发现fastgpt报错503, upstream_error, 如下图所示:

oneapi报错:

因为 ollama向量接口为 /api/embeddings, 而fastgpt调用onepai默认接口为/v1/embeddings, 因此会报错,此时可以在本地通过nginx代理ollama,将oneapi的/v1/embeddings转发到ollama的 /api/embeddings中。
代理配置如下:vim /etc/nginx/conf.d/ollama.conf server {listen 11435;server_name ollama-server;location / {proxy_pass http://127.0.0.1:11434;proxy_set_header Host $host;proxy_set_header X-Real-IP $remote_addr;proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;proxy_set_header X-Forwarded-Proto $scheme;}location /v1/embeddings {rewrite ^/v1/embeddings$ /api/embeddings break;}location /api/embeddings {proxy_pass http://127.0.0.1:11434;proxy_set_header Host $host;proxy_set_header X-Real-IP $remote_addr;proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;proxy_set_header X-Forwarded-Proto $scheme;} }转发成功后可以看到nginx日志请求正常:

oneapi中/v1/embeddings接口也恢复正常:

过一段时间后数据集准备就绪,节点CPU慢慢降下来恢复正常
ollama向量模型知识库上传数据一直卡在索引,docker日志报404 中提到配置host.docker.internal, 笔者测试过几次不行,最后通过nginx代理解决该问题。 -
fastgpt 通过oneapi调用ollama qwen2:2b报错 error unmarshalling stream response
fastgpt提示: LLM api response empty oneapi报错: [SYS] 2024/09/08 - 11:18:57 | error unmarshalling stream response: invalid character '}' after top-level value 解决方法: 将渠道设置为自定义,暂时不用配置为ollama, 调整后重启oneapi就没有继续报错了 参考 [ollama部署qwen2:7b api调用报错](https://github.com/songquanpeng/one-api/issues/1646)
说明
软件:
ubuntu2404 Desktop
oneapi v0.6.8
fastgpt v4.8.10
ollama 0.3.6
参考文档:
fastgpt官方文档
one-api github
ollama + fastgpt搭建本地私有AI大模型智能体工作流(AI Agent Flow)-- windows环境
Fastgpt配合chatglm+m3e或ollama+m3e搭建个人知识库
大模型必备 - 中文最佳向量模型 acge_text_embedding
Ollama 中文文档
奔跑的蜗牛-人工智能案例合集
相关文章:
大模型笔记02--基于fastgpt和oneapi构建大模型应用平台
大模型笔记02--基于fastgpt和oneapi构建大模型应用平台 介绍部署&测试部署fastgptoneapi服务部署向量模型m3e和nomic-embed-text测试大模型 注意事项说明 介绍 随着大模型的快速发展,众多IT科技厂商都开发训练了各自的大模型,并提供了各具特色的AI产…...

linux-用户与权限管理-组管理
在 Linux 系统中,用户、组与权限管理是保障系统安全的重要机制。用户和组的管理不仅涉及对系统资源的访问控制,还用于权限的分配和共享。组管理在 Linux 中尤其重要,它能够帮助管理员组织用户并为不同的组分配特定权限,从而控制用…...
Day23_0.1基础学习MATLAB学习小技巧总结(23)——句柄图形
利用空闲时间把碎片化的MATLAB知识重新系统的学习一遍,为了在这个过程中加深印象,也为了能够有所足迹,我会把自己的学习总结发在专栏中,以便学习交流。 参考书目:《MATLAB基础教程 (第三版) (薛山)》 之前的章节都是…...

同步io和异步io
同步 I/O 和异步 I/O 是处理输入输出操作的两种不同策略,它们各有优缺点,适用于不同的场景。下面是它们的主要区别: 同步 I/O 定义:在同步 I/O 模型中,发起 I/O 操作的线程会被阻塞,直到操作完成。换句话说…...

AI基础 L19 Quantifying Uncertainty and Reasoning with Probabilities I 量化不确定性和概率推理
Acting Under Uncertainty 1 Reasoning Under Uncertainty • Real world problems contain uncertainties due to: — partial observability, — nondeterminism, or — adversaries. • Example of dental diagnosis using propositional logic T oothache ⇒ C av ity • H…...

C++ 关于时间的轮子
时间字符串转chrono::system_clock std::chrono::system_clock::time_point parse_date(const std::string& date_str) {std::tm tm {};std::istringstream ss(date_str);ss >> std::get_time(&tm, "%Y-%m-%d"); // 假设日期字符串格式为YYYY-MM-DDr…...

阿里达摩院:FunASR - onnxruntime 部署
阿里达摩院:FunASR - onnxruntime 部署 git clone https://github.com/alibaba/FunASR.git 切换到 onnxruntime cd FunASR/runtime/onnxruntime1下载 onnxruntime wget https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/dep_libs/onnxruntime-linux-x64-1.14.0.t…...
SpringMvc注解
SpringMvc注解 1 SpringMcv基础环境搭建 注:如果已经有SpringMvc项目直接跳过这个就可以了 1 新建项目 2.修改文件为packaging 为war包 <packaging>war</packaging> <?xml version"1.0" encoding"UTF-8"?> <pr…...

队列的基本概念及顺序实现
队列的基本概念 队列的定义 队列(Queue)简称队,也是一宗操作受限的线性表,只允许在表的一段进行插入,而在表的另一端进行删除。向队列中插入元素成为入队或进队;删除元素成为出队或离队。 特性:先进先出 (Fir…...

Leetcode 最长连续序列
算法流程: 哈希集合去重: 通过将数组中的所有元素放入 unordered_set,自动去除重复元素。集合的查找操作是 O(1),这为后续的快速查找提供了保证。 遍历数组: 遍历数组中的每一个元素。对于每个元素,首先检…...

linux网络编程——UDP编程
写在前边 本文是B站up主韦东山的4_8-3.UDP编程示例_哔哩哔哩_bilibili视频的笔记,其中有些部分博主也没有理解,希望各位辩证的看。 UDP协议简介 UDP 是一个简单的面向数据报的运输层协议,在网络中用于处理数据包,是一种无连接的…...

第四部分:1---文件内核对象,文件描述符,输出重定向
目录 struct file内核对象: 如何读写文件? 文件描述符在文件描述符表中的分配规则: 输出重定向初步解析: dup2实现复制文件描述符: struct file内核对象: struct file 是在内核空间中创建的用于描述文…...

如何在开发与生产环境中应用 Flask 进行数据库管理:以 SQLAlchemy 和 Flask-Migrate 为例
在使用 Flask 进行开发时,数据库管理是一个至关重要的环节。借助 SQLAlchemy 作为 ORM(对象关系映射)工具和 Flask-Migrate 进行数据库迁移,开发者可以高效地进行数据库管理,并在不同的环境(如开发环境和生…...
【Java零基础】Java核心知识点之:Map
HashMap(数组链表红黑树) HashMap 根据键的 hashCode 值存储数据,大多数情况下可以直接定位到它的值,因而具有很快的访问速度,但遍历顺序却是不确定的。 HashMap 最多只允许一条记录的键为 null,允许多条记录的值为 null。HashMa…...

9.12日常记录
1.extern关键字 1)诞生动机:在一个C语言项目中,需要再多个文件中使用同一全局变量或是函数,那么就需要在这些文件中再声明一遍 2)用于声明在其他地方定义的一个变量或是函数,在当前位置只是声明,告诉编译器…...

光纤的两种模式
光纤主要分为两种模式:单模光纤(Single-Mode Fiber, SMF)和多模光纤(Multi-Mode Fiber, MMF)。这两种光纤在传输特性、应用场景以及传输距离上存在显著差异。12 单模光纤 定义:单模光纤…...
SpringMVC的初理解
1. SpringMVC是对表述层(Controller)解决方案 主要是 1.简化前端参数接收( 形参列表 ) 2.简化后端数据响应(返回值) 1.数据的接受 1.路径的匹配 使用RequestMapping(可以在类上或在方法上),支持模糊查询,在内部有method附带…...
Python 基本库用法:数学建模
文章目录 前言数据预处理——sklearn.preprocessing数据标准化数据归一化另一种数据预处理数据二值化异常值处理 numpy 相关用法跳过 nan 值的方法——nansum和nanmean展开多维数组(变成类似list列表的形状)重复一个数组——np.tile 分组聚集——pandas.…...

Android Greendao的数据库复制到设备指定位置
方法如下: private void export() {// 确保您已经请求并获得了WRITE_EXTERNAL_STORAGE权限// 获取要储存的设备路径String picturesDirPath Environment.getExternalStoragePublicDirectory(Environment.DIRECTORY_PICTURES).getAbsolutePath();// 在公共目录下创建…...
Ajax 揭秘:异步 Web 交互的艺术
Ajax 揭秘:异步 Web 交互的艺术 一 . Ajax 的概述1.1 什么是 Ajax ?1.2 同步和异步的区别1.3 Ajax 的应用场景1.3.1 注册表单的用户名异步校验1.3.2 内容自动补全 二 . Ajax 的交互模型和传统交互模型的区别三 . Ajax 异步请求 axios3.1 axios 介绍3.1.1 使用步骤3…...

Chrome 148紧急安全更新深度解析:127个漏洞背后的GPU UAF沙箱逃逸与防御实战
一、引言:史上最密集的Chrome安全更新风暴 2026年5月5日,Google紧急推送了Chrome 148稳定版的第二次安全更新(版本号Windows/Mac 148.0.7778.96/97,Linux 148.0.7778.96),一次性修复了127个安全漏洞&#x…...

终极免费音频智能分割工具:快速解放你的音频处理工作流
终极免费音频智能分割工具:快速解放你的音频处理工作流 【免费下载链接】audio-slicer A simple GUI application that slices audio with silence detection 项目地址: https://gitcode.com/gh_mirrors/aud/audio-slicer 还在为处理长音频文件而烦恼吗&…...

ROS导航避坑指南:搞清rviz里‘2D Pose Estimate’和‘2D Nav Goal’的区别与正确使用姿势
ROS导航避坑指南:rviz中‘2D Pose Estimate’与‘2D Nav Goal’的深度解析与实践技巧 在机器人操作系统(ROS)的导航栈开发中,rviz作为可视化调试的核心工具,其2D Pose Estimate和2D Nav Goal两个功能按钮看似简单&…...

终极指南:5步掌握番茄小说下载器的完整使用方案
终极指南:5步掌握番茄小说下载器的完整使用方案 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 在数字阅读时代,我们常常面临一个共同的问题࿱…...

2026年主流抓娃娃App大对比,哪个才是你的“抓宝神器”?
在当今快节奏的生活中,年轻人面临着来自学业、工作、社交等多方面的压力。为了缓解这些压力,寻找适合的解压方式成为了大家的共同需求。抓娃娃App作为一种新兴的娱乐方式,正逐渐受到年轻人的喜爱。下面我们就从潮流趋势、科技前沿、行业洞察等…...

【HarmonyOS 6.1 全场景实战】《灵犀厨房》之【营养分析引擎】计算个性化卡路里建议:给《灵犀厨房》装上“营养大脑”
【营养分析引擎】计算个性化卡路里建议:给《灵犀厨房》装上“营养大脑” 摘要:从“爱吃什么”到“该吃什么”,是《灵犀厨房》进化的关键一步。上一篇我们刚打通了 Health Kit 数据,今天,我们就要基于 Mifflin-St Jeor …...

Seraphine:英雄联盟智能BP助手与战绩查询工具完整指南
Seraphine:英雄联盟智能BP助手与战绩查询工具完整指南 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 在英雄联盟的对局中,BP(禁选英雄)阶段往往是决定胜负的关…...

Windows Cleaner终极指南:3步彻底解决C盘爆红问题,让电脑重获新生!
Windows Cleaner终极指南:3步彻底解决C盘爆红问题,让电脑重获新生! 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 还在为Wind…...

Go语言静态站点生成器Zeuxis:极简架构与高性能构建实践
1. 项目概述:一个轻量级、高性能的静态站点生成器最近在折腾个人博客和文档站点,发现市面上的静态站点生成器虽然多,但要么配置复杂、学习曲线陡峭,要么过于臃肿,启动和构建速度慢得让人抓狂。直到我遇到了bnomei/zeux…...

嵌入式开发内存优化实战:裁剪IRLib2红外库,释放微控制器Flash空间
1. 项目概述:当红外遥控遇上内存焦虑红外遥控,这个听起来有点“复古”的技术,至今仍是智能家居、玩具和各类嵌入式设备里最经济可靠的无线通信方案之一。它的原理不复杂:用一个特定频率(通常是38kHz)的载波…...