数据库(mysql)常用命令
一.常见的数据库端口号
Mysql默认端口:3306
oracle 默认端口:1521
Sql server 默认端口:1433
注:Mysql采用 的是C/S(客户端/服务器端)架构
二.sql 语法基础
服务器,数据库,数据表,记录,字段之间的关系:
一台Mysql服务器可以管理多个数据库
一个数据库可以存在多张二维表,
一张表可以存在多条记录,
一条记录由多个字段组成,
字段是最终的元数据.
注:# 为注释,不会被认为sql语句,每一条 sql语句以;(英文分号结尾)
数据库中常用的数据类型
整数:
int 有符号范围(-2147483648 ~2147483647),无符号范围(0 ~ 4294967295),
可以不用设置长度
小数;decimal, decimal(6,2)表示整数部分加小数部分
字符串:
字符串是一个或多个字符的序列,这些字符可以是字母、数字、标点符号等。在数据库中,字符
串通常用于存储文本数据,如姓名、地址、描述等。
在 SQL 语句中,使用引号可以明确告诉数据库该值是一个字符串,而不是其他类型(如整数或
浮点数)。如果不使用引号,某些字符或字符序列可能会被误认为是 SQL 命令或特殊字符,从而导
致错误。引号内的内容会被当作一个整体处理,包括其中的空格和特殊字符。
带引号的数据都是字符串,单引号、双引号都可以:
中文字符串:'文字信息'
英文字符串:'abc'
数字字符串:'123
变长字符串 :varchar 定长字符串 char
区别分析
1.都是用来存储字符串的,只是他们的保存方式不一样,并非是指对字符串长度的限制,字符串
长度的限制通过(数字)来限制长度。
2.char 有固定的长度,而 varchar 属于可变长的字符类型
整数型,tinyint,int
拥有不同长度的整型
支持整数型,但是支持不同大小的整数型。
标准的整型,4 个字节!
支持 1,2,3,4,8 种类型的长度!长度的不同,意味着整型的范围是不相同的!
小数型,
float,double,decimal
MySQL 浮点型和定点型可以用类型名称后加(M,D)来表示,M 表示该值的总共长度,D 表示
小数点后面的长度,M 和 D 又称为精度和标度。
浮点数
浮点数按小数位数分为:单精度和双精度
float,占用 4 个字节,32bit,数值范围为-3.4E38~3.4E38(7 个有效位)
double,占用 8 个字节,64bit,数值范围-1.7E308~1.7E308(15 个有效位)
定点数
decimal,数字型,128bit,不存在精度损失
MySQL DECIMAL 数据类型用于在数据库中存储精确的数值。我们经常将 DECIMAL 数据类型用于
保留准确精确度的数据,例如货币数据。
sql 语句最常报错原因:
表名重复,字母输错, 中午输入法下输如逗号,该空格的地方没空格,
navicat 闪退
原因多是由于屏幕取词功能没有开启
创建表
数据库中 列与字段的区别:
实际存在表中的就是列
在运行时创建的,表中实际不存在的就是字段,例如聚合函数的查询结果
表名默认转换成小写,列名(字段)不区分大小写
语法:
create table 表名( 列名 类型(长度) 约束1 约束2 , 列名2 类型(长度) 约束1 约束2, ....... );
常见约束:
primary key (主键约束) :表中唯一的标识符,主键不允许重复,不允许为空,
not null (非空) :此列不允许写空值
auto_increment (自动递增):此列的值会自动递增填充
unsigned 无符号数 :
default 默认值 :当不填写时会使用默认值
unique 唯一:此字段不允许重复
check 检查约束: 确保列中的值满足特定的条件
foreign key ;维护两个表之间的关联关系
comment :备
主键与唯一约束的区别
1.同一张表中只能有一个主键,但可以有多个unique
2.主键的字段值不能为nul,唯一约束的字段值可以为null
3. 主键字段可以作为其他表的外键,唯一约束不能做其他表的外键
注意:列名里面不能有空格
create table students ( name varchar(10) comment '姓名') comment '学生表';
例 2:创建学生表 student2,
字段 1:id(整数类型,不能有符号、主键、自动递增),
字段 2:姓名 name(变长字符串长度为 20、默认值为刘德华),
-字段 3:年龄 age(整数类型、不能有符号、默认值为 20),
字段 4:身高 high(小数类型,一共 5 位数字,保留小数点后两位)
create table student2(
id int unsigned primary key auto_increment,
name varchar(20) default '刘德华',
age int unsigned default 20,
high decimal(5,2)
);
字段都已经限制是 int 了,有必要还搞一个 unsigned 吗?
如果只限制 int,那么是可以输入、保存负数的
如果是 int+unsigned,那么只能输入、保存 正整数。
插入一列
alter table 表名 add 列名 类型(长度) 约束 1 约束 2
alter table students add address varchar(20);
关于反引号(``)的使用:
反引号在 mysql 中是为了区分 mysql 中的保留字符与普通字符而引入的符号,例如在出现字段
名与 SQL 关键字相同、标识中含空格等情况下就需要使用,否则可能出错,但反引号不是必须的,
在确保不会导致歧义发生的情况下可以省略掉。
删除一列
alter table 表名 drop 列名
例:删除表 students 中的地址列 address
alter table students drop address ;
删除表
1. drop table 表名 若表不存在,报错,停止执行
2.drop table if exists 表名 若表不存在,不报错继续执行
添加行信息
一.添加多行信息
insert into 表名 values (值 1, 值2 ,....),(值 1, 值2 ,....),...;
二.跨行添加信息
insert into 表名 (列名1,列名2,列名3) values(值1,值2,值3);
删除行数据
delete from 表名 where 列名 =列值 ;
delete from student3 where id=6
注意:仅执行delete from 表名; 将会删除表格中的所有行信息
update 修改数据
update 是对已经存在的数据进行修改
修改一列的值
格式:
update 表名 set列名=新值
例:给表 student 增加一列 idcord,类型:整数,然后,设置 idcord列的值为3
alter table student add idcord int;
update student set idcord =3;
修改行中多个单元格的值
格式:
update 表名 set 列1=值1,列2=值2 ....where 列名=列值;
update student set name='狄仁杰',age=20 where id=5;
将一列值增加
格式:
update 表名 set 列名=列名+i;
select 查询语句
查询表格全部信息
格式:
select * from 表名
查询某一列的信息
格式:
select 列名 from 表名
查询某几列的内容
格式:
select 列1 ,列2 from 表名
where ●难点
当需要缩小范围、限制条件的时候,可以通过 where……语句实现。
每条语句只能有一条where语句
查询行信息
在表名之后,使用 where 对表中的数据筛选,符合条件的数据会出现在结果中
语法:
select * from 表名 where 列名=列值
where 后面支持多种运算符,对条件进行处理
小于等于 <=
大于等于 >=
不是 xx 的所有结果 !=
比较运算、逻辑运算、模糊查询、范围查询、空判断
别名 as (多表联查经常使用)
给表名起一个别名 ,不会实质性修改表的内容,目的是为了使语句写起来更加简单
select * from 表名 as 别名
注意:别名可以为中文,为中文时,加不加引号都可以,仅在这一次查询中起作用
在等值连接,子查询中表名一旦起了别名,除了起别名的地方,其他地方,都只能使用别名
一旦使用原名,就会保存
distinct 消除重复行(结果展示一个)
在 select 后面 列名 前使用distinct 可以消除重复的行
语法:
select distinct 列名 from 表名
例:查询 student 表中,学生家乡 hometown 分布情况,结果去除重复
select distinct hometown form student ;
比较运算符
逻辑运算符
在 sql语句中:当需要 缩小范围,限制条件时,首先考虑使用where,如果sql 语句中已经有了
where ,则使用 and ,where 只能有一个,and可以有多个
having 只能用于group by 之后, 对内容进行 进一步的过滤
and (并且):
显示结果是多个条件(多个and)必须同时满足的结果
select * from student where class='2班'and sex='男';
or 或者:
多个条件中,哪个条件能满足,就显示他的查询结果,
如果都满足,都显示
Not 取反
效果跟 != 一样
模糊查询 like
% 表示任意多个字符,或 什么字符都没有, 主要适用字数不限制的场景
_表示一个任意字符,适用字数限制的场景
% 表示任意多个字符
like '李%' 模糊查询以 百字开头的内容
like '% 飞'模糊查询以飞字结尾的内容
like'%白%'表示内容中包含白的内容(无论第几个字)
like_表示 一个 任意字符,'李_'表示内容有 2 个字,第一个字是李
like'_亮'表示内容有 2 个字,内容第二个字是亮
like'_尚_'表示内容是 3 个字,中间的字是尚
范围查询 in
between...and....在一个连续则范围中
只适用于连续的范围内的数字
效果等同于 >= xx and <== xx
格式:
select * from 表名 where 列名 between 值1 and 值2
空判断
注意:null 与''''是不同的
null 是没有任何数据的''''是空字符串
order by 排序
语法:
升序 (从小到大): select * from 表名 order by 列名 asc (asc 可省略)
降序 (从大到小):select * from 表名 order by 列名 desc:
聚合函数
为了快速得到统计数据,常会用到聚合函数,常在select之后使用,from之前使用
注意:聚合函数不能在where中使用,常在group by中使用
注意:使用聚合函数查询时,不能编辑代码并显示其他的列名,行信息是不对应的
分组+聚合 除外
count(*) 统计表格的行数
格式:
select count(*) from 表名
max(列) 最大值
格式:
select max(列名) from 表名
说明:聚合函数从此处开始,括号内的内容是筛选数据范围的列名,含义与 count(*)不同。
例:在 students 表中,查询女生的最大年龄
select max(age) from students
min(列) 最小值
格式:
select min(列名) from 表名
例:在 students 表中,查询 1 班学生的最小年龄
select min(age) from students
sum(列) 求此列的和
注意:使用 sum(列)时,不能编辑代码并列显示其它的列名,行信息是不对应的,分组 + 聚合
除外。
格式:
select sum(列名) from 表名
例:查询北京学生的年龄总和
select sum(age) from students where hometown='北京'
avg(列) 求此列的平均值
注意:使用 avg(列)时,不能编辑代码并列显示其它的列名,行信息是不对应的,分组 + 聚合除
外
格式:
select avg(列名) from 表名
例:查询女生的平均年龄
select avg(age) from students where sex='女'
等值连接,内连接,左连接,右连接查询
当查询结果的列来源于多张表时,要将多张表连接成一个大的数据集,选择合适的列返回
等值连接查询和内连接查询: 查询的结果为连个表匹配的到的数据
左连接查询:查询结果为两个表匹配得到的数据加左表特有的数据
,于右表的数据用null填充
右连接查询:查询结果为两个表匹配得到的数据加右表特有的数据
,于左表的数据用null填充
等值连接:
等值连接语法:
select * form 表1,表2 where 表1.列名=表2.列名
(等值连接是通过值相等,来连接的,列名不同,也可以等值连接)
多表联查时,表示某一列时:要以表名.列名的格式来表示
3表联查的等值连接语法:
sleect * form 表1,表2 where 表1.列名=表2.列名 and 表2.列名=表3.列名
内链接
语法:
select * from 表1 inner join 表2 on 表1.列=表2.列
3表联查
select * form 表1 inner join 表2 on 表1.相同列=表2.相同列
inner join 表3 on 表2.相同列=表3.相同列
(inner join 语法中,inner 可以省略)
左连接
语法:(注:左表是主表,主表的名字放在 left join 的左边)
select* form表1 left join 表2 on 表1.列=表2.列
三表联查
select * from 表1 left join 表2 on 表1.相同列=表2.相同列
left join 表3 on 表2.相同列=表3.相同列
右连接
语法:
select* from表1 right join 表2 on 表1.相同列=表2.相同列
三表联查
select * from 表1 right join 表2 on 表1.相同列=表2.相同列
right join 表3 on 表2.相同列=表3.相同列
on和using的区别
多表联查,也可以试用using,结果有一定的区别
使用 using 进行多表联查的语法:
select * from 表 1 join 表 2 using(列名)
using ,是通过列名将表格连接到一起的,列名必须一致
区别 1. 语法不一样
2.使用on,结果会显示2个字段,使用using,结果只会显示1个字段
3.使用on,字段名称可以不一样,是通过等值进行的连接,使用using
字段名必须一致
union联合查询
union all
连接数据集关键字,可以将两个查询结果集拼接为一个,不会过滤掉相同的记录
union
连接数据集关键字,可以把两个查询结果拼接为一个,会过滤掉相同的记录
select name,age,class from student3
union
select name,age,class from students;
相同的查询记录会被过滤掉,只显示一次
select name,age,class from student3
union all
select name,age,class from students;
相同的查询记录不会被过滤掉,有多少条记录,就显示多少条记录
group by 分组
按照字段分组显示,此字段相同的数据会被放到分组后的一个组中,显示的结果是组名
,并不意味着该组中只有一行数据
分组之后可以利用having+聚合函数进行过滤
分组(group by )依据的列名,要出现在select之后,from之前的位置,否则逻辑错误,
查询可以成功,但是查询的结果并非一一对应
格式:
select 列 from 表名 group by 列
例:在student表中查询 按照 家乡分组
select hometown from student where hometown
having 使用
关于 where ,and having的使用方法:
当要缩小范围,限制条件,首先要考虑where ,如果SQL语句中已经有了where 了
那就使用and ,一条SQL语句只能有一个where ,可以有多个and,
having 只用 在group by 的 分组后的结果进行筛选,having后面的运算条件
跟 where 的相同
分组并统计
格式select列 from 表名 group by 列 having count(*) ......
例:统计student 表中,生源地学生的数量大于1的生源地名称
select hometown form student group by hometown having count(*)>1
分组,聚合运算
子查询中如果括号中select语句中出现分组+聚合函数,必须在括号里的select之后,from之前的聚合函数名称字后起别名 ,以供括号外的select语句调用,如果不起别名,命令就会保存!
语法:
select 列,聚合 ...from 表名 group by 列
扩展)使用第一个分组条件分组后,再使用第二个分组条件进行分组
语法:
select 条件 1,条件 2 from 表名 group by 条件 1,条件 2
例:在 students 表中,统计每个班的每种性别的人数
select class ,sex count(*) from student group by class sex
limit 获取部分行
语法:
select * from 表名 limit x, y
x 表示 从第?行开始,y表示一共显示的行数 ,x为零时
可以省略
计算机的索引从0开始
子查询
在一个select语句中,嵌入另外一个select 语句,那么被嵌入的select
语句称之为子查询
主查询和子查询的关系:
子查询前后加括号,嵌入到主查询中,子查询是辅助主查询的,要么充当条件(值),要么充当
数据源,子查询是可以独立存在的语句,是一条完整的 select 语句
子查询分类:
标量子查询、列级子查询、行级子查询、表级子查询
标量子查询
标量子查询的定义:
子查询返回的结果是表中1个单元格的数据,供外部查询语句查询
例1:查询班级学生的平均年龄
select avg(age)from student
例2,查询学生表中年龄大于平均年龄的学生信息
select * from student where age>(select avg(age) from studetnt)
列级子查询
子查询的结果是一列(一列多行) ,供外 外部查询语句查询
例 1: 根据18岁学生的学号,查询其成绩
学生表中查询18岁的学生的学号
select studentno form students where age=18
通过学号查询查成绩
select * from scores where studentno in('002','006');
通过列级子查询一部到位:
select * from scores where studentno in(select studentno form students where age=18)
行级子查询
行级子查询定义:
返回的结果是一行(一行多列),供外部查询语句其中的几个数据进行匹配
注意:
行级子查询,只能使用 = ,若使用!=连接,查询结果不准确,想要用!=的场景需要使用标量子查
询,使用 and 连接。
例 1:查询与百里玄策同性别、同班的学生信息
标量子查询:
select * from students where sex =
(select sex from students where name = '百里玄策')
and class =
(select class from students where name = '百里玄策')
行级子查询:
select * from students where (sex,class) =
(select sex,class from students where name = '百里玄策')
例 2:查询与百里玄策性别、班级都不相同的学生信息
只能使用标量子查询
select * from students where sex != (select sex from students where name = '百里玄策') and
class != (select class from students where name = '百里玄策')
表级子查询
表级子查询的定义:
内部查询结果是两行两列以上 (就可以理解为是一张表),供外部查询语句使用
当使用 select * from 表 1 a,(表级子查询) b where a.列名 = b.列名 这个表级子查询语法时,
必须给第二张表起别名,否则会报错。
子查询中的聚合函数查询结果,如果需要被主查询调用时,需要给聚合函数起别名,否则报错。
例 1:查询每个班级中比自己班级平均年龄低的学生的姓名、年龄、班级
(2 表联查,表级子查询)
第一步,按照班级分组,查询每个班级的平均年龄,得到一张表
select class,avg(age) from students group by class
第二步,2 表联查,表级子查询,限制条件
select * from
students a,(select class,avg(age) b1 from students group by class) b
where a.class = b.class and a.age < b.b1
子查询中特定关键字使用
in : (相当于多个 and)
主查询 where 条件 in (列子查询)
any | some : (相当于多个 or)
主查询 where 列 = any (列子查询)在条件查询的结果中匹配任意一个即可,
all:
主查询 where 列 = all(列子查询) : 等于里面所有格式,等价于 in
主查询 where 列 <>all(列子查询) : 不等于其中所有,等价于 not in
相关文章:
常用命令)
数据库(mysql)常用命令
一.常见的数据库端口号 Mysql默认端口:3306 oracle 默认端口:1521 Sql server 默认端口:1433 注:Mysql采用 的是C/S(客户端/服务器端)架构 二.sql 语法基础 服务器,数据库,数据表,记录,字段之间的关系: 一台Mysql服务器可以管理多个数据库 一个数据库可以存在多张二维表…...
源网荷储一体化新型电力系统解决方案
风光装机快速增长,加剧电力系统不可控性。截至2023H1,我国风电装机389.21GW,太阳能装机470.67GW,风光合计占总装机的31.76%。其中,2023年H1我国风电新增装机22.99GW,对比22年同期新增12.94GW,同…...

树莓派安装 OpenCV 教程
以下是在树莓派上安装 OpenCV 的教程: 笔者当前Python版本:3.7.3 一、更新树莓派系统 在终端中运行以下命令: sudo apt update sudo apt upgrade二、安装必要的依赖项 安装构建工具和图像 I/O 库: sudo apt install build-e…...

01,大数据总结,zookeeper
1 ,zookeeper :概述 1.1,zookeeper:作用 1 ,大数据领域 :存储配置数据 例如:hadoop 的 ha 配置信息,hbase 的配置信息,都存储在 zookeeper 2 ,应用领…...

伪工厂模式制造敌人
实现效果 1.敌人方实现 敌人代码 using UnityEngine; using UnityEngine.UI;public class EnemyBasics : MonoBehaviour {public int EnemySpeed { get; internal set; }public int EnemyAttackDistance { get; internal set; }public int EnemyChaseDistance { get; interna…...

【linux】pwd命令
pwd 命令在 Linux 和类 Unix 系统中用于显示当前工作目录的完整路径。它是 "print working directory" 的缩写。 当你在终端或命令行界面中工作时,你可能会在不同的目录(或文件夹)之间切换。pwd 命令帮助你确定你当前位于哪个目录…...

Python 如何封装工具类方法,以及使用md5加密
第一步:封装使用方法 在utils目录中,编写我的md5加密的方法,如下: import re import hashlib from os import path from typing import Callable from flask import current_app# 这里封装的是工具类的方法def basename(filenam…...

网络编程的应用
目录 1.单机程序和网络程序 2.客户端与服务端 3.网络编程三要素 3.1 IP地址 3.2 port端口 4.TCP编程 5.UDP编程 1.单机程序和网络程序 之前编写的程序都是单机程序,所有的业务功能实现及数据存储都在一个主机上完成,我们称为单机程序 我们在生活…...

佰朔资本:国内海风加速招标 船舶行业景气上行
昨日,沪指盘中一度下探失守2700点,尾盘在地产、银行等板块的带动下发力上扬,深证成指亦翻红。到收盘,沪指涨0.49%报2717.28点,深证成指涨0.11%报7992.25点,创业板指跌0.11%报1533.47点,上证50指…...

理解AAC和Opus的编码与解码流程
理解AAC和Opus的编码与解码流程及其在Android中的实现,对于音频开发非常重要。下面,我将详细解释这两种编码格式的原理、流程,并结合具体代码示例,帮助你在Android项目中合理地设计和使用它们。 一、AAC(Advanced Audio Coding) 1. AAC的原理与流程 AAC是一种有损音频压…...

设计图纸加密方法知多少?小编给你讲清楚
一、对称加密 使用对称加密算法,对设计图纸进行加密。对称加密使用相同的密钥进行加密和解密,确保只有持有正确密钥的人能够解密文件。 二、非对称加密 使用非对称加密算法,进行设计图纸的加密。非对称加密使用公钥加密、私钥解密的方式&a…...

pycv实时目标检测快速实现
使用python_cv实现目标实时检测 python 安装依赖核心代码快速使用实现结果展示enjoy python 安装依赖 opencv_python4.7.0.72 pandas1.5.3 tensorflow2.11.0 tensorflow_hub0.13.0 tensorflow_intel2.11.0 numpy1.23.5核心代码快速使用 # 使用了TensorFlow Hub和OpenCV库来实…...

记录下如何让字体在div内 自动换行 上下居中
div内样式 display: flex; // flex布局 justify-content: center; // 上下居中 align-items: center; // 左右居中 overflow-wrap: break-word; // 允许字体换行 (若行内的单词无法放下则换行) word-break: break-all; // 强制文本在任意字符间进…...

Shell篇之编写MySQL启动脚本
Shell篇之编写MySQL启动脚本 1. 脚本内容 vim mysql_ctl.sh#!/bin/bashmysql_port3306 mysql_username"root" mysql_password"molinker" mysql_conf"/opt/lanmp/mysql/etc/my.cnf" mysql_sock"/opt/lanmp/mysql/var/mysql.sock"func…...

supermap Iclient3d for cesium加载地形并夸大地形
先看效果图 这是没有夸张之前的都江堰 这是夸大五倍后的都江堰 下面展示代码 主要就是加载supermaponline的skt地形然后夸大 <template><div class"PartOneBox"><div id"cesiumContainer"></div></div> </template>…...

一文解读OLAP的工具和应用软件
OLAP(OnlineAnalyticalProcessing)是一种用于快速分析大规模、多维度数据的方法。OLAP工具和应用软件则是帮助人们进行OLAP分析的重要工具。本文将介绍几种常见的OLAP工具和应用软件,并探讨它们在数据分析中的作用。 一 OLAP工具的分类 在选…...
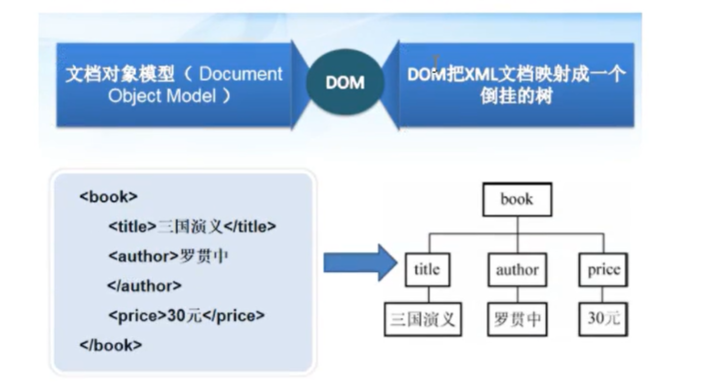
xml重点笔记(尚学堂 3h)
XML:可扩展标记语言 主要内容(了解即可) 1.XML介绍 2.DTD 3.XSD 4.DOM解析 6.SAX解析 学习目标 一. XML介绍 1.简介 XML(Extensible Markup Language) 可扩展标记语言,严格区分大小写 2.XML和HTML XML是用来传输和存储数据的。 XML多用在框架的配置文件…...
爬虫代理API的全面解析:让数据抓取更高效
在大数据时代,网络爬虫已经成为收集和分析数据的重要工具。然而,频繁的请求会导致IP被封禁,这时候爬虫代理API就显得尤为重要。本文将详细介绍爬虫代理API的作用、优势及如何使用,帮助你更高效地进行数据抓取。 什么是爬虫代理AP…...

PCL 点云中的植被信息提取(C++详细过程版)
目录 一、算法原理1、原理概述2、参考文献二、代码实现三、结果展示本文由CSDN点云侠原创,原文链接,首发于:2024年9月18日。如果你不是在点云侠的博客中看到该文章,那么此处便是不要脸的抄袭狗。 一、算法原理 1、原理概述 点云具有丰富的色彩信息,可以与植被指数结合使…...

requests-html的具体使用方法有哪些?
requests-html是一个功能强大的Python库,用于发送HTTP请求和解析HTML内容。它的使用方法包括安装库、基本使用、发送带有参数的请求、图片抓取实战案例、解析网页内容、执行JavaScript代码、使用CSS选择器来查找元素、继续跟踪链接并获取内容等。 安装request…...

MAX78000移植Zephyr RTOS实战:从BSP创建到AI边缘设备开发
1. 项目概述与动机作为一名长期在嵌入式边缘AI和机器人领域摸爬滚打的开发者,我最近把目光投向了一块相当有潜力的板子:Maxim Integrated(现为ADI一部分)的MAX78000FTHR开发套件。这块板子的核心——MAX78000微控制器,…...

rk35xx 通过recovery升级问题
Firefly 的 recovery 库是一个核心组件,它构建了一个独立的微型 Linux 系统,专门用于在设备主系统之外执行高可靠性的固件升级。简单来说,它的工作流程是:主系统通过命令触发,将升级指令写入特定分区并重启;…...

Unity渲染排序三要素:SortingLayer、Order in Layer与RenderQueue协同原理
1. 为什么刚进Unity的美术和程序总在“图层遮挡”上反复拉扯?“这个UI怎么被背景挡住了?”“粒子特效一开就穿模,明明Z轴没问题!”“我调了Order in Layer到999,还是被另一个Sprite挡住——它连Sorting Layer都没改过&…...

TV Bro电视浏览器:为智能电视打造的最佳遥控器上网解决方案
TV Bro电视浏览器:为智能电视打造的最佳遥控器上网解决方案 【免费下载链接】tv-bro Simple web browser for android optimized to use with TV remote 项目地址: https://gitcode.com/gh_mirrors/tv/tv-bro 还在为智能电视上网操作不便而烦恼吗?…...

Ubuntu经常安装软件
1、垃圾清理工具stacer sudo apt updatesudo apt install stacer apt cleanapt autocleanapt autoremove 2、类似与everything的工具Fsearcch 1sudo add-apt-repository ppa:christian-boxdoerfer/fsearch-stable 2sudo apt update 3sudo apt install fsearch (注…...

DeepSeek重复代码识别失效了?5个被90%团队忽略的AST解析盲区及修复清单
更多请点击: https://codechina.net 第一章:DeepSeek代码重复检测失效的真相与影响 DeepSeek-R1 模型在代码理解任务中表现出色,但其内置的代码重复检测机制在特定场景下存在系统性失效。根本原因在于模型对语义等价但语法结构差异显著的代…...

ModernWMS核心功能详解:从ASN入库到Dispatch出库的完整工作流
ModernWMS核心功能详解:从ASN入库到Dispatch出库的完整工作流 【免费下载链接】ModernWMS The open source simple and complete warehouse management system is derived from our many years of experience in implementing erp projects. We stripped the origin…...

第2章 谁在危险中——被AI替代的五类程序员
第2章 谁在危险中——被AI替代的五类程序员 核心问题:哪些程序员最容易被AI替代?背后的原因是什么? 2.1 问题定义:一场正在发生的结构性塌陷 2.1.1 数据不会说谎 2026年1月12日,Ravio发布了一份让整个科技圈沉默的报告:过去一年,初级开发者岗位招聘量暴跌73%。 不是…...

关于内卷,几个值得深想的洞察
首先声明:这篇不劝躺平,也不教内卷——只是想说清楚,你到底在一个什么样的游戏里。 你以为内卷是“资源不足”,其实是“分配方式” 很多人对内卷有个本质上的认知错误:以为内卷是因为资源不够,大家为了抢资…...

PlayAI实时翻译如何重构跨国协作效率?揭秘2024企业级应用的3个关键转折点
更多请点击: https://codechina.net 第一章:PlayAI实时翻译如何重构跨国协作效率?揭秘2024企业级应用的3个关键转折点 在远程办公常态化与全球供应链深度耦合的背景下,PlayAI 实时翻译已从辅助工具跃升为协同基础设施。其核心突破…...