NCNN 源码(1)-模型加载-数据预处理-模型推理
参考 ncnn 第一个版本的代码。
0 整体流程 demo:squeezenet
ncnn 自带的一个经典 demo:squeezenet 的代码:
// 网络加载
ncnn::Net squeezenet;
squeezenet.load_param("squeezenet_v1.1.param");
squeezenet.load_model("squeezenet_v1.1.bin");// 数据预处理
ncnn::Mat in = ncnn::Mat::from_pixels_resize(image.data, ncnn::Mat::PIXEL_BGR, image.cols, image.rows, 227, 227);
const float mean_vals[3] = { 104.f, 117.f, 123.f };
in.substract_mean_normalize(mean_vals, 0);// 网络推理
ncnn::Extractor ex = squeezenet.create_extractor();
ex.input("data", in);
ncnn::Mat out;
ex.extract("prob", out);
上面的代码描述了从模型加载到模型推理的完整过程:
- 网络加载
- load_param
- load_model
- 数据预处理
- from_pixels_resize
- substract_mean_normalize
- 网络推理
- create_extractor
- input
- extract
- 每一层的推理(隐含在模型内,这里没有体现出来)
1 模型加载
ncnn::Net squeezenet;
squeezenet.load_param("squeezenet_v1.1.param");
squeezenet.load_model("squeezenet_v1.1.bin");
这里首先新建一个 ncnn::Net 对象,用来记录网络,除此之外,还有 load_param和load_model方法,分别用来加载网络模型的 param(参数) 文件和 bin(模型)文件。
1.1 load_param
param 文件内容:

在 param 文件中,第一行记录了模型的 layer 和 blob 的数量,后面的每一行分别记录一个 layer 的一些属性信息。
- 第一行
- 第一个数:记录该 param 所表示的模型一共有多少 layer,所以如果增删某几行,这里也要对应修改
- 第二个数,记录该模型有多少个 blob,可以理解成有多少个数据流节点。例如一个卷积就是一个输入 blob 一个输出 blob,数据在 blob 之间流动。
- 其他行:除了第一行,其他的都是 layer 行,上图用第三行举例,具体行内容依次为:
- layer_type:该行记录的 layer 对应的类型,例如输入 Input、卷积 Convolution、激活 ReLU、池化 Pooling 等
- layer_name:该行记录的 layer 的名字,这个可以自己起,模型导出的时候导出工具自动生成的
- bottom_count:这里的 bottom 表示该 layer 在谁的下面,因此这个参数的含义是前置节点的数量
- top_count:该 layer 后置节点的数量
- bottom_name:这个名字的数量由 bottom_count 指示,上图因为 bottom_count 为 1 所以只有一个。这个参数的含义是前置节点的名称
- blob_name:后置节点的名字
- 特有参数:这个是该 layer 特有的一些参数。例如卷积有 kernel_size、stride_size、padding_size,Softmax 则需要一个指示维度的参
load_param 流程伪代码:
# layers 列表,存下所有 layer
# blobs 列表,背后维护,为 find_blob 服务layer_count, blob_count = read(param_file) # 读取第一行数据for param_file is not EOF: # 循环读取每一行的layer数据layer_type, layer_name, bottom_count, top_count = read(param_file) # 读取前四个固定参数layer = create_layer(layer_type) # 根据layer类型创建一个layerfor bottom_count:bottom_name = read(param_file) # 读取每一个bottom_nameblob = find_blob(bottom_name) # 查找该 blob,没有的话就要新建一个blob.consumers.append(layer) # 当前层是这个 blob 的消费者,这里的 blob 是前置节点layer.bottoms.append(blob) # 记录前置节点的名称for top_count:blob_name= read(param_file) # 读取每一个 blob_nameblob = find_blob(bottom_name) # 查找该 blob,没有的话就要新建一个blob.producer = layer # 当前层是这个 blob 的生产者,这里的blob是后置节点layer.tops.append(blob) # 记录后置节点的名称layer.param = read(param_file) # 读取该层的一些特殊参数layers.append(layer)
2 数据预处理
ncnn::Mat in = ncnn::Mat::from_pixels_resize(image.data, ncnn::Mat::PIXEL_BGR, image.cols, image.rows, 227, 227);
in.substract_mean_normalize(mean_vals, norm_vals);
数据预处理部分主要是这样的两个函数:
ncnn::Mat::from_pixels_resize:将cv::Mat格式的image.data转成ncnn::Mat格式,之后将其 resize 到固定的 shapesubstract_mean_normalize:对输入数据进行减均值、乘以方差的处理
2.1 ncnn::Mat::from_pixels_resize
先对输入的 image 数据进行 resize 处理,之后将 resize 之后的数据转成ncnn::Mat格式。
2.1.1 resize
ncnn::Mat::from_pixels_resize的 resize 处理支持三种格式的图像:单通道的灰度图像 GRAY,三通道的 RGB 和 BGR,四通道的 RGBA。
resize 使用的是双线性插值算法,即 bilinear:
- 计算 x、y 方向上插值点的位置索引 xofs 和 yofs
- 计算 x、y 方向上插值点左右的两个插值系数 ialpha 和 ibeta
- 遍历插值,x 方向上的插值用 xofs 和 ialpha 得到,y 方向上的插值用 yofs 和 ibeta 得到
2.1.2 from_pixels
这里是先申请一块ncnn::Mat的内存,之后再将转换好的数据逐个填进去即可。这里支持三通道、三通道、四通道的图片输入,一些颜色转换 RGB2BGR、RGB2GRAY 这些也都是在这里实现。
RGB 转 GRAY 的实现如下,from_rgb2gray:
static Mat from_rgb2gray(const unsigned char* rgb, int w, int h) {const unsigned char Y_shift = 8;//14const unsigned char R2Y = 77;const unsigned char G2Y = 150;const unsigned char B2Y = 29;Mat m(w, h, 1);if (m.empty())return m;float* ptr = m;int size = w * h;int remain = size;for (; remain > 0; remain--) {*ptr = (rgb[0] * R2Y + rgb[1] * G2Y + rgb[2] * B2Y) >> Y_shift;rgb += 3;ptr++;}return m;
}
代码中,首先定义了转换时 R、G、B 对应要乘的系数,这里用的是整数乘法,所以系数放大了 2 8 2^8 28,因此后面算结果那里再右移回去。后面就是 for 循环遍历每一个 pixel,全部遍历完并把数据写进 ncnn::Mat 就可以了。
2.2 substract_mean_normalize
这个代码同时支持只mean不norm,只norm不mean,既mean又norm。既 mean 又 norm:
void Mat::substract_mean_normalize(const float* mean_vals, const float* norm_vals) {int size = w * h;for (int q = 0; q < c; q++) {float* ptr = data + cstep * q;const float mean = mean_vals[q];const float norm = norm_vals[q];int remain = size;for (; remain > 0; remain--) {*ptr = (*ptr - mean) * norm;ptr++;}}
}
遍历 Mat 所有数据,减 mean 乘 norm。
3 模型推理
ncnn::Extractor ex = squeezenet.create_extractor();
ex.input("data", in);
ncnn::Mat out;
ex.extract("prob", out);
这里主要是三个步骤:
- ncnn::Extractor,即 create_extractor,是一个专门用来维护推理过程数据的类,跟 ncnn::Net 解耦开,这个最主要的就是开辟了一个大小为网络的 blob size 的 std::vectorncnn::Mat 来维护计算中间的数据
- input,在上一步开辟的 vector 中,把该 input 的 blob 的数据 in 放进去
- extract,做推理,计算目标层的数据
3.1 extract
int Extractor::extract(const char* blob_name, Mat& feat) {int blob_index = net->find_blob_index_by_name(blob_name);if (blob_index == -1)return -1;int ret = 0;if (blob_mats[blob_index].dims == 0) {int layer_index = net->blobs[blob_index].producer;ret = net->forward_layer(layer_index, blob_mats, lightmode);}feat = blob_mats[blob_index];return ret;
}
find_blob_index_by_name, 查找输入的 blob 名字在 vector 中的下标- 判断
blob_mats[blob_index].dims ==0- 如果这个 blob 没有计算过,那么该 blob 对应的数据应该是空的,说明要进行推理
- 如果 blob 计算过,就有数据了,那么 dims 就不会等于 0,不用再算了,直接取数据就可以了
net->forward_layer,又回到了ncnn::Net,ncnn::Extractor也可以从代码中看出来主要就是维护数据
3.2 forward_layer
函数声明:
int Net::forward_layer(int layer_index, std::vector<Mat>& blob_mats, bool lightmode)
三个参数,
- layer_index,要计算哪一层
- blob_mats,记录计算中的数据
- lightmode 配合 inplace 来做一些动态的 release,及时释放内存资源
推理分 layer 是不是一个输入一个输出 和 其它。一个输入一个输出的代码比较简单,先看这个,
// 1. 获取当前层
const Layer* layer = layers[layer_index];// 2. 获取当前层的前置节点和后置节点
int bottom_blob_index = layer->bottoms[0];
int top_blob_index = layer->tops[0];// 3. 前置节点如果没有推理,就先推理前置节点
if (blob_mats[bottom_blob_index].dims == 0) {int ret = forward_layer(blobs[bottom_blob_index].producer, blob_mats, lightmode);if (ret != 0)return ret;
}// 4. 推理当前节点
Mat bottom_blob = blob_mats[bottom_blob_index];
Mat top_blob;
int ret = layer->forward(bottom_blob, top_blob);
if (ret != 0)return ret;// 5. 当前节点的输出送至后置节点
blob_mats[top_blob_index] = top_blob;
从上面的代码接哦股很清晰,是一个递归,当前层需要的输入 blob 还没算,就递归进去算,算完就算当前层,这里layer->forward是每一层的特定实现
再看非一个输入一个输出的复杂一点的:
const Layer* layer = layers[layer_index];// 1. 所有的前置节点里面,没有推理的都先推理
std::vector<Mat> bottom_blobs;
bottom_blobs.resize(layer->bottoms.size());
for (size_t i=0; i<layer->bottoms.size(); i++) {int bottom_blob_index = layer->bottoms[i];if (blob_mats[bottom_blob_index].dims == 0) {int ret = forward_layer(blobs[bottom_blob_index].producer, blob_mats, lightmode);if (ret != 0)return ret;}bottom_blobs[i] = blob_mats[bottom_blob_index];
}// 2. 前置节点推理完成后,推理当前节点
std::vector<Mat> top_blobs;
top_blobs.resize(layer->tops.size());
int ret = layer->forward(bottom_blobs, top_blobs);
if (ret != 0)return ret;// 3. 当前节点的数据送到所有后置节点
for (size_t i=0; i<layer->tops.size(); i++)
{int top_blob_index = layer->tops[i];blob_mats[top_blob_index] = top_blobs[i];
}
多输入多输出,就是所有前置节点都要先算完,然后再算自己,最后给后置节点送数据。
3.3 推理流程总结
ncnn 推理的整体简要流程:
- 读取 param 和 bin 文件,记录下每一层的 layer、layer 的输入输出节点、layer 的特定参数
- 推理
- 维护一个列表用于存所有节点的数据
- 给输入节点放入输入数据
- 计算输出节点的 layer
- 计算 layer 所需的输入节点还没给输入——>递归调用上一层 layer 计算
- 有输入了——>计算当前 layer
- 输出结果,数据送入后置节点
相关文章:
NCNN 源码(1)-模型加载-数据预处理-模型推理
参考 ncnn 第一个版本的代码。 0 整体流程 demo:squeezenet ncnn 自带的一个经典 demo:squeezenet 的代码: // 网络加载 ncnn::Net squeezenet; squeezenet.load_param("squeezenet_v1.1.param"); squeezenet.load_model("squeezenet_…...

重修设计模式-结构型-享元模式
重修设计模式-结构型-享元模式 复用不可变对象,节省内存 享元模式(Flyweight Pattern)核心思想是通过共享对象方式,达到节省内存和提高性能的目的。享元对象需是不可变对象,因为它会被多处代码共享使用,要避…...

JavaScript 运算符
JavaScript 中的运算符可以根据其功能和用途分为几类。以下是主要的运算符类型及其用法: 1. 算术运算符 用于执行基本的数学运算。 : 加法 let sum 5 3; // 8- : 减法 let difference 5 - 3; // 2* : 乘法 let product 5 * 3; // 15/ : 除法 let quotient 5…...

3.js - 运动曲线
这个球,绕着这个红色的线圈转 代码 import * as THREE from three import { OrbitControls } from three/examples/jsm/controls/OrbitControlslet scene,camera,renderer,controls nulllet moon,earth null// 根据,一系列的点,创建曲线 le…...
免费ppt模板哪里找?职场必备这些利器
一眨眼,9月份的尾声渐近,无论是学生还是职场人士,都开始准备着新一轮的演讲和报告。在这个忙碌的时期,一份精美的PPT模板能够大幅提升你的工作效率,让你的演示更加引人入胜。 不用担心高昂的版权费用,市场…...

wampserve 配置本地域名,出现错误
概述 今天更换了电脑,在本地安装和配置docker的时候,想用自定义域名访问NGINX容器,127.0.0.1和localhost都可以访问,但是自定义域名无法访问, 接着去捯饬已经使用的wampserver的集成环境,出现了同样的问题…...

MySQL慢查询优化指南
博客主页: 南来_北往 系列专栏:Spring Boot实战 前言 当遇到慢查询问题时,不仅影响服务效率,还可能成为系统瓶颈。作为一位软件工程师,掌握MySQL慢查询优化技巧至关重要。今天,我们就来一场“数据库加速之旅…...
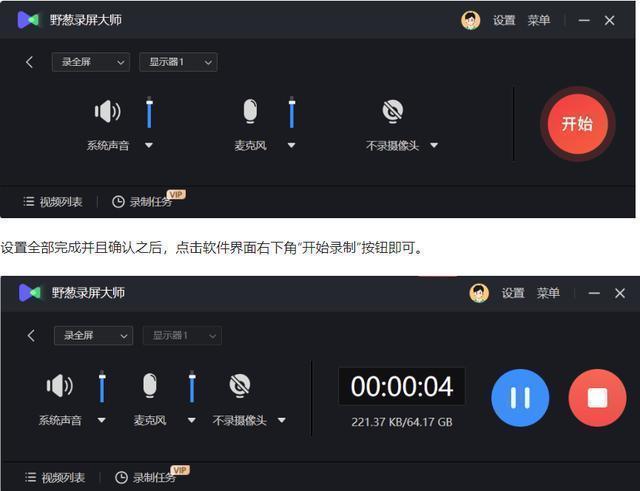
怎么录制游戏视频?精选5款游戏录屏软件
对于热爱游戏的你来说,记录游戏中的精彩瞬间并分享给朋友或粉丝,无疑是一种享受。然而,在众多录屏软件中,如何选择最适合你的那一款?今天,我们就为大家精选了五款游戏录屏软件,需要的朋友快来选…...

论文阅读 - MDFEND: Multi-domain Fake News Detection
https://arxiv.org/pdf/2201.00987 目录 ABSTRACT INTRODUCTION 2 RELATED WORK 3 WEIBO21: A NEW DATASET FOR MFND 3.1 Data Collection 3.2 Domain Annotation 4 MDFEND: MULTI-DOMAIN FAKE NEWS DETECTION MODEL 4.1 Representation Extraction 4.2 Domain Gate 4.…...
LabVIEW软件出现Bug如何解决
在LabVIEW开发中,程序出现bug是不可避免的。无论是小型项目还是复杂系统,调试与修复bug都是开发过程中的重要环节。下文介绍如何有效解决LabVIEW软件中的bug,包括常见错误类型、调试工具、错误处理机制。 1. 常见Bug类型分析 在LabVIEW中&am…...

【数据结构-栈】力扣844. 比较含退格的字符串
给定 s 和 t 两个字符串,当它们分别被输入到空白的文本编辑器后,如果两者相等,返回 true 。# 代表退格字符。 注意:如果对空文本输入退格字符,文本继续为空。 示例 1: 输入:s “ab#c”, t “…...

DataFrame生成excel后为什么多了一行数字
问题描述 python查询数据生成excel文件,生成的excel多了第一行数字索引,1,2,3,4,5...... 代码: df pd.DataFrame(data)df.to_excel(filename, sheet_name用户信息表, indexFalse) 解决: 原理也很简单,就是设置个参…...
分析)
linux 内存屏障(barrier)分析
谈起内存屏障,大家感觉这个"玩意儿"很虚,不太实际,但是内核代码中又广泛地可以看到起身影。内存屏障,英文barrier,这个"玩意儿"它还不太好去定义它。barrier,中文翻译为栅栏,栅栏大家都见过,现实生活中就是防止他人或者动物非法闯入而用来进行隔…...

【人工智能】Transformers之Pipeline(十九):文生文(text2text-generation)
目录 一、引言 二、文生文(text2text-generation) 2.1 概述 2.2 Flan-T5: One Model for ALL Tasks 2.3 pipeline参数 2.3.1 pipeline对象实例化参数 2.3.2 pipeline对象使用参数 2.3.3 pipeline返回参数 …...

如何使用ssm实现基于VUE的儿童教育网站的设计与实现+vue
TOC ssm676基于VUE的儿童教育网站的设计与实现vue 第一章 课题背景及研究内容 1.1 课题背景 信息数据从传统到当代,是一直在变革当中,突如其来的互联网让传统的信息管理看到了革命性的曙光,因为传统信息管理从时效性,还是安全…...

MODBUS TCP 转 CANOpen
产品概述 SG-TCP-COE-210 网关可以实现将 CANOpen 接口设备连接到 MODBUS TCP 网络中。用户不需要了解具体的 CANOpen 和 Modbus TCP 协议即可实现将CANOpen 设备挂载到 MODBUS TCP 接口的 PLC 上,并和 CANOpen 设备进行数据交互。 产品特点 …...
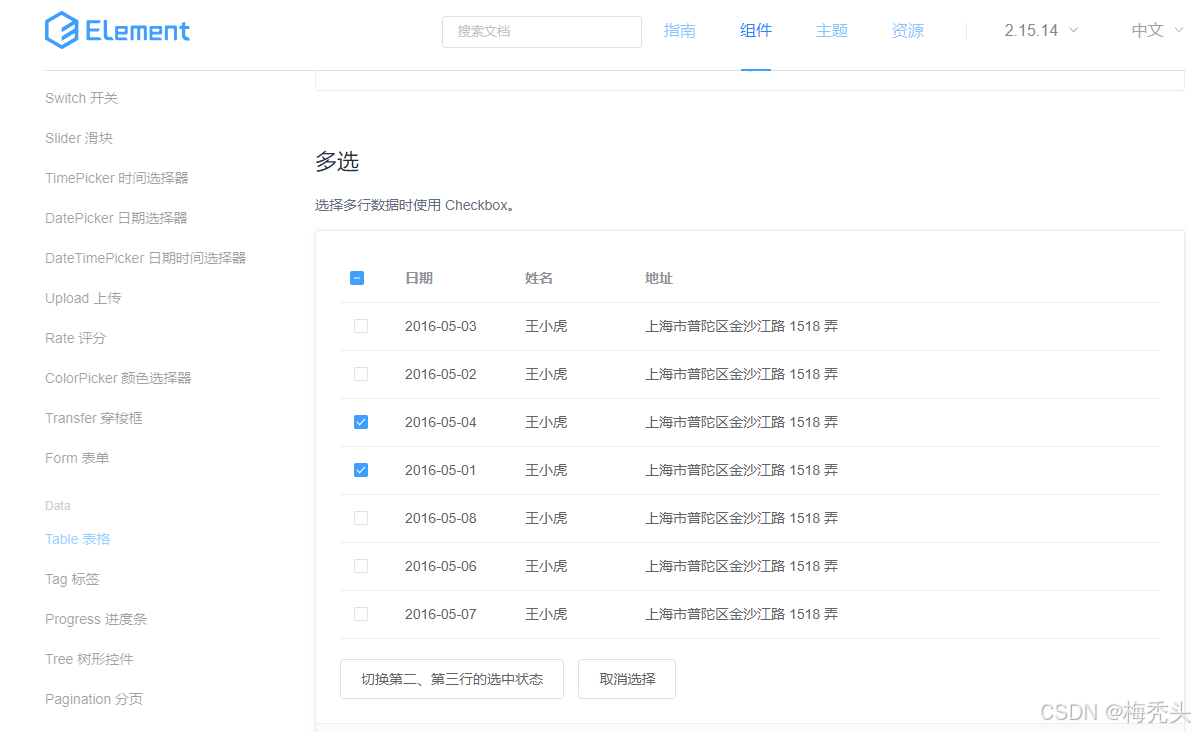
vue2+elementUI实现handleSelectionChange批量删除-前后端
功能需求:实现选中一个或多个执行批量删除操作 在elementUI官网选择一个表格样式模板,Element - The worlds most popular Vue UI framework 这里采用的是 将代码复制到前端,这里是index.vue <template><el-button type"dang…...
的简介、安装和使用方法、案例应用之详细攻略)
LLMs之OCR:llm_aided_ocr(基于LLM辅助的OCR项目)的简介、安装和使用方法、案例应用之详细攻略
LLMs之OCR:llm_aided_ocr(基于LLM辅助的OCR项目)的简介、安装和使用方法、案例应用之详细攻略 目录 llm_aided_ocr的简介 1、特性 2、详细技术概览 PDF处理和OCR PDF到图像转换 OCR处理 文本处理流程 分块创建 错误校正与格式化 重复内容移除 标题和页码…...

低代码平台后端搭建-阶段完结
前言 最近又要开始为跳槽做准备了,发现还是写博客学的效率高点,在总结其他技术栈之前准备先把这个专题小完结一波。在这一篇中我又试着添加了一些实际项目中可能会用到的功能点,用来验证这个平台的扩展性,以及总结一些学过的知识。…...

暑假考研集训营游记
文章目录 摘要:1.对各大辅导机构考研封闭集训营的一些个人看法:2.对于考研原因一些感想:结语 摘要: Ashy在暑假的时候参加了所在辅导班的为期一个月的考研封闭集训营,有了一些全新的感悟,略作记录。 1.对…...

【UE5】数字人实战:从动捕到物理发型的全链路解析
1. 数字人制作全流程概览 数字人制作是一个从建模到最终呈现的完整技术链条。在UE5引擎中,我们可以将动捕数据、表情捕捉和物理发型等模块有机整合,打造出逼真可交互的数字角色。整个流程可以划分为三个核心环节:表情捕捉(LiveLin…...

Inter字体终极指南:如何为现代数字界面选择最佳开源字体方案?
Inter字体终极指南:如何为现代数字界面选择最佳开源字体方案? 【免费下载链接】inter The Inter font family 项目地址: https://gitcode.com/gh_mirrors/in/inter Inter字体是一款专为数字屏幕精心设计的开源无衬线字体系统,通过科学…...
详解)
Redis Sorted Set(有序集合)详解
Redis 里面有一种非常强大的数据结构: Sorted Set(有序集合)简称: ZSet这是 Redis 面试和项目里非常高频的东西。一、什么是 Sorted Set 先记住一句话: Sorted Set 自动排序的 Set它具备: Set 的去重自动排…...

互联网大厂 Java 求职面试全景:从音视频场景到微服务架构的深入探讨
互联网大厂 Java 求职面试全景:从音视频场景到微服务架构的深入探讨 在互联网大厂的招聘中,Java 开发者的面试不仅技术含量高,还充满了戏剧性。今天,我们将通过一位求职者燕双非与面试官的对话,带你走进这个复杂而有趣…...

图像采集卡与相机内置采集:架构差异、性能对比与选型指南
1. 项目概述:从“外挂”到“内置”的采集路径之争在视觉系统集成或工业检测项目里,选型阶段总会遇到一个基础但关键的问题:图像采集卡和相机内置的采集功能,到底该用哪个?这可不是一个简单的“哪个更好”的问题&#x…...
)
Arcgis新手必看:用‘焦点统计’和‘设为空函数’搞定栅格数据清洗(附避坑要点)
ArcGIS栅格数据清洗实战:焦点统计与设为空函数的高效应用指南 当你第一次拿到一份满是噪点的DEM数据或存在异常值的土地利用分类图时,那种手足无措的感觉我深有体会。栅格数据清洗是GIS分析中看似简单却暗藏玄机的关键步骤,一个不当的参数设置…...

GPT-4V食物识别实测:准确率真能到87.5%?我们复现了那篇论文的实验
GPT-4V食物识别技术深度测评:从实验室数据到真实场景的挑战 当一张摆盘精致的牛排照片被上传到GPT-4V界面,三秒后系统不仅识别出"肋眼牛排",还精确标注出"约350克"和"780千卡"时,这种看似科幻的场景…...
)
告别黑盒渲染!用Nvdiffrast手把手教你从零搭建可微渲染管线(PyTorch版)
从零构建可微渲染管线:Nvdiffrast深度实践指南 在计算机图形学与深度学习交叉领域,可微渲染技术正掀起一场革命。传统渲染管线如同黑盒,输入3D场景参数,输出2D图像,但反向路径却被阻断——这正是Nvdiffrast要解决的痛点…...

5分钟精通英雄联盟信息修改:LeaguePrank新手完全使用指南
5分钟精通英雄联盟信息修改:LeaguePrank新手完全使用指南 【免费下载链接】LeaguePrank 项目地址: https://gitcode.com/gh_mirrors/le/LeaguePrank 你是否曾在英雄联盟中羡慕别人的华丽段位边框,却苦于自己的段位不够理想?你是否想要…...

别再硬刚滑块了!一个Python脚本自动搞定淘宝X5SEC验证码
Python自动化破解淘宝X5SEC滑块验证码实战指南 淘宝作为国内最大的电商平台之一,其反爬机制一直处于行业领先水平。其中X5SEC滑块验证码是淘宝用来识别自动化程序的主要手段之一。对于需要批量采集商品数据或进行价格监控的开发者来说,频繁的手动滑块验证…...