利用 PostgreSQL 构建 RAG 系统实现智能问答
在现代信息检索和自然语言处理的场景中,检索增强生成 (Retrieval-Augmented Generation, RAG) 系统因其结合了知识库检索和生成模型的优势,成为了一种非常流行的智能问答方法。在这篇博文中,我将展示如何利用PostgreSQL作为向量存储数据库,配合OpenAI嵌入模型和LangChain库,构建一个完整的RAG系统。
RAG 系统简介
RAG 系统的核心理念是:首先从知识库中检索与问题相关的文档或片段,然后通过生成式语言模型(如GPT)生成基于检索结果的答案。这种方法不仅提升了模型的问答准确性,还能够在多种场景中扩展大语言模型的应用。
在本文中,我们将使用:
- LangChain:一个为构建语言模型应用提供丰富工具的框架。
- PostgreSQL:作为存储文本片段及其嵌入向量的数据库。
- OpenAI API:为文档生成嵌入向量并使用 GPT 模型生成答案。
主要实现步骤
1. 环境准备与库的导入
我们首先需要导入必要的库,其中包括用于数据库连接的psycopg2,用于加载网页的bs4,以及LangChain相关的库。
import getpass
import os
import psycopg2
from psycopg2.extras import execute_values
import bs4
from langchain_community.document_loaders import WebBaseLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
import numpy as np
from langchain_openai import ChatOpenAI
from langchain import hub
from langchain_core.output_parsers import StrOutputParser
2. 加载网页内容
我们将网页内容加载为文本,并使用LangChain提供的WebBaseLoader来解析网页,并提取需要的内容。
# 加载网页内容
loader = WebBaseLoader(web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),bs_kwargs=dict(parse_only=bs4.SoupStrainer(class_=("post-content", "post-title", "post-header"))),
)
docs = loader.load()
3. 文本切分
由于大语言模型处理较长文本时会受到限制,因此我们需要对加载的文本进行切分。在此处,使用RecursiveCharacterTextSplitter按照指定的字符大小将文本切分为多个块。
# 文本切分
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
4. 连接 PostgreSQL 并存储嵌入向量
在这里,我们将利用PostgreSQL作为数据库,存储文本的嵌入向量。我们首先连接数据库,然后利用OpenAI的嵌入模型生成文本向量,并存储到数据库中。
# 连接到 PostgreSQL 数据库
conn = psycopg2.connect(host="localhost", # 根据需要更改database="mydb", # 更改为你的数据库名user="root", # 更改为你的用户名password=getpass.getpass("请输入你的 PostgreSQL 密码: ")
)
cur = conn.cursor()# 嵌入并存储向量
embedding_model = OpenAIEmbeddings()def store_vectors_in_pg(splits):embeddings = embedding_model.embed_documents([doc.page_content for doc in splits])data = [(0, 0, doc.page_content, embedding)for doc, embedding in zip(splits, embeddings)]insert_query = """INSERT INTO knowledge.vector_data_1 (user_id, file_id, content, featrue)VALUES %s"""execute_values(cur, insert_query, data)conn.commit()store_vectors_in_pg(splits)
5. 从数据库检索相似文档
通过查询PostgreSQL中的向量数据,基于余弦相似度查找与用户查询相似的文档。我们利用向量索引(HNSW)来高效检索相似文本片段。
# 检索相似文档
def retrieve_similar_docs(query, k=5):query_embedding = embedding_model.embed_query(query)embedding_str = f"'{str(query_embedding)}'"retrieve_query = f"""SELECT content, featrueFROM knowledge.vector_data_1ORDER BY featrue <-> {embedding_str}LIMIT %s"""cur.execute(retrieve_query, (k,))results = cur.fetchall()return [result[0] for result in results]
6. 构建 RAG 链并生成答案
我们使用LangChain的ChatOpenAI模型和Prompt链来完成生成答案的过程。
# 定义 RAG 链
prompt = hub.pull("rlm/rag-prompt")input_data = {"context": format_docs(retrieved_docs),"question": query
}# 构建 RAG 链
rag_chain = (prompt| ChatOpenAI(model="gpt-4o-mini")| StrOutputParser()
)# 生成答案
response = rag_chain.invoke(input_data)
print(response)
7. 关闭数据库连接
在程序结束时,别忘了关闭数据库连接。
cur.close()
conn.close()
完整代码实例
# 导入必要的库
import getpass
import os
import psycopg2
from psycopg2.extras import execute_values
import bs4
from langchain_community.document_loaders import WebBaseLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
import numpy as np
from langchain_openai import ChatOpenAI
from langchain import hub
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough# 设置 OpenAI API 密钥
os.environ["OPENAI_API_KEY"] = getpass.getpass("请输入你的 OpenAI API 密钥: ")# 1. 加载网页内容
loader = WebBaseLoader(web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),bs_kwargs=dict(parse_only=bs4.SoupStrainer(class_=("post-content", "post-title", "post-header"))),
)
docs = loader.load()# 2. 切分文本
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)# 3. 连接到 PostgreSQL 数据库
conn = psycopg2.connect(host="localhost", # 根据需要更改database="mydb", # 更改为你的数据库名user="root", # 更改为你的用户名password=getpass.getpass("请输入你的 PostgreSQL 密码: ")
)
cur = conn.cursor()# 4. 嵌入并将分割后的文本和向量数据存储到 PostgreSQL
embedding_model = OpenAIEmbeddings()def store_vectors_in_pg(splits):# 生成嵌入向量embeddings = embedding_model.embed_documents([doc.page_content for doc in splits])# 将 numpy.ndarray 转换为 Python 列表data = [(0, 0, doc.page_content, embedding) # 假设 user_id 和 file_id 为 0,实际可以调整for doc, embedding in zip(splits, embeddings)]# 插入数据到 PostgreSQL 表 knowledge.vector_data_1insert_query = """INSERT INTO knowledge.vector_data_1 (user_id, file_id, content, featrue)VALUES %s"""execute_values(cur, insert_query, data)conn.commit()store_vectors_in_pg(splits)# 5. 从 PostgreSQL 中检索数据并计算相似度
def retrieve_similar_docs(query, k=5):# 将查询嵌入为向量query_embedding = embedding_model.embed_query(query)# 将 query_embedding 转换为 PostgreSQL 可识别的向量字符串格式embedding_str = f"'{str(query_embedding)}'" # 将list转为vector字符串# SQL 查询:通过 HNSW 索引查找最相似的文档retrieve_query = f"""SELECT content, featrueFROM knowledge.vector_data_1ORDER BY featrue <-> {embedding_str} -- 使用转换后的字符串进行余弦相似度计算LIMIT %s"""cur.execute(retrieve_query, (k,))results = cur.fetchall()return [result[0] for result in results] # 返回相似的内容# 6. 检索并生成答案
query = "任务分解是什么?"
retrieved_docs = retrieve_similar_docs(query)def format_docs(docs):return "\n\n".join(docs)# 定义 RAG 链
prompt = hub.pull("rlm/rag-prompt")# 构建 dict 输入
input_data = {"context": format_docs(retrieved_docs),"question": query
}# 构建 RAG 链
rag_chain = (prompt # 提示模板| ChatOpenAI(model="gpt-4o-mini") # 使用 OpenAI 的 LLM 模型生成答案| StrOutputParser() # 将输出解析为字符串格式
)# 生成答案
response = rag_chain.invoke(input_data)print(response)# 7. 关闭连接
cur.close()
conn.close()
结论
通过本文,我们展示了如何使用PostgreSQL作为向量存储的数据库,配合OpenAI嵌入模型及LangChain库构建一个简单的RAG系统。这个系统能够高效检索文本片段,并基于检索结果生成回答。RAG 系统在知识问答、信息检索等领域具有广泛的应用前景,尤其是在处理大量结构化或非结构化数据时,结合自然语言处理模型的强大生成能力,可以显著提升用户体验。
希望这篇文章能为你构建自己的RAG系统提供参考!
相关文章:

利用 PostgreSQL 构建 RAG 系统实现智能问答
在现代信息检索和自然语言处理的场景中,检索增强生成 (Retrieval-Augmented Generation, RAG) 系统因其结合了知识库检索和生成模型的优势,成为了一种非常流行的智能问答方法。在这篇博文中,我将展示如何利用PostgreSQL作为向量存储数据库&am…...

Go 并发模式:扩展与聚合的高效并行
当你搭建好一个管道系统后,数据在各个阶段之间顺畅地流动,并根据你设定的操作逐步转换。这一切看起来像是一条美丽的溪流,然而,为什么有时候这个过程会如此缓慢呢? 在处理数据时,某些阶段可能会非常耗时,导致上游的阶段被阻塞,无法继续处理数据。这不仅影响了管道的整…...

【Transformers基础入门篇2】基础组件之Pipeline
文章目录 一、什么是Pipeline二、查看PipeLine支持的任务类型三、Pipeline的创建和使用3.1 根据任务类型,直接创建Pipeline,默认是英文模型3.2 指定任务类型,再指定模型,创建基于指定模型的Pipeline3.3 预先加载模型,再…...

java反射学习总结
最近在项目上有一个内部的CR,运用到了反射。想起之前面试的时候被面试官追问有没有在项目中用过反射,以及反射的原理和对反射的了解。 于是借此机会,学习回顾一下反射,以及在项目中可能会用到的场景。 Java 中的反射概述 反射&…...

探索C语言与Linux编程:获取当前用户ID与进程ID
探索C语言与Linux编程:获取当前用户ID与进程ID 一、Linux系统概述与用户、进程概念二、C语言与系统调用三、获取当前用户ID四、获取当前进程ID五、综合应用:同时获取用户ID和进程ID六、深入理解与扩展七、结语在操作系统与编程语言的交汇点,Linux作为开源操作系统的典范,为…...

1.4 边界值分析法
欢迎大家订阅【软件测试】 专栏,开启你的软件测试学习之旅! 文章目录 前言1 定义2 选取3 具体步骤4 案例分析 本篇文章参考黑马程序员 前言 边界值分析法是一种广泛应用于软件测试中的技术,旨在识别输入值范围内的潜在缺陷。本文将详细探讨…...

Spring IOC容器Bean对象管理-注解方式
目录 1、Bean对象常用注解介绍 2、注解示例说明 1、Bean对象常用注解介绍 Component 通用类组件注解,该类被注解,IOC容器启动时实例化此类对象Controller 注解控制器类Service 注解业务逻辑类Respository 注解和数据库操作的类,如DAO类Reso…...

OpenAI API: How to catch all 5xx errors in Python?
题意:OpenAI API:如何在 Python 中捕获所有 5xx 错误? 问题背景: I want to catch all 5xx errors (e.g., 500) that OpenAI API sends so that I can retry before giving up and reporting an exception. 我想捕获 OpenAI API…...

C++初阶学习——探索STL奥秘——标准库中的priority_queue与模拟实现
1.priority_queque的介绍 1.priority_queue中文叫优先级队列。优先队列是一种容器适配器,根据严格的弱排序标准,它的第一个元素总是它所包含的元素中最大的。 2. 此上下文类似于堆,在堆中可以随时插入元素,并且只能检索最大堆元…...

PyTorch经典模型
PyTorch 经典模型教程 1. PyTorch 库架构概述 PyTorch 是一个广泛使用的深度学习框架,具有高度的灵活性和动态计算图的特性。它支持自动求导功能,并且拥有强大的 GPU 加速能力,适用于各种神经网络模型的训练与部署。 PyTorch 的核心架构包…...

C++ STL容器(三) —— 迭代器底层剖析
本篇聚焦于STL中的迭代器,同样基于MSVC源码。 文章目录 迭代器模式应用场景实现方式优缺点 UML类图代码解析list 迭代器const 迭代器非 const 迭代器 vector 迭代器const 迭代器非const迭代器 反向迭代器 迭代器失效参考资料 迭代器模式 首先迭代器模式是设计模式中…...

力扣416周赛
举报垃圾信息 题目 3295. 举报垃圾信息 - 力扣(LeetCode) 思路 直接模拟就好了,这题居然是中等难度 代码 public boolean reportSpam(String[] message, String[] bannedWords) {Map<String,Integer> map new HashMap<>()…...

vue 页面常用图表框架
在 Vue.js 页面中,常见的用于制作图表的框架或库有以下几种: ECharts: 官方网站: EChartsECharts 是一个功能强大、可扩展的图表库,支持多种图表类型,如柱状图、折线图、饼图等。Vue 集成: 可以使用 vue-echarts 插件,…...

spring 注解 - @PostConstruct - 用于初始化工作
PostConstruct 是 Java EE 5 中引入的一个注解,用于标注在方法上,表示该方法应该在依赖注入完成之后执行。这个注解是 javax.annotation 包的一部分,通常用于初始化工作,比如初始化成员变量或者启动一些后台任务。 在 Spring 框架…...
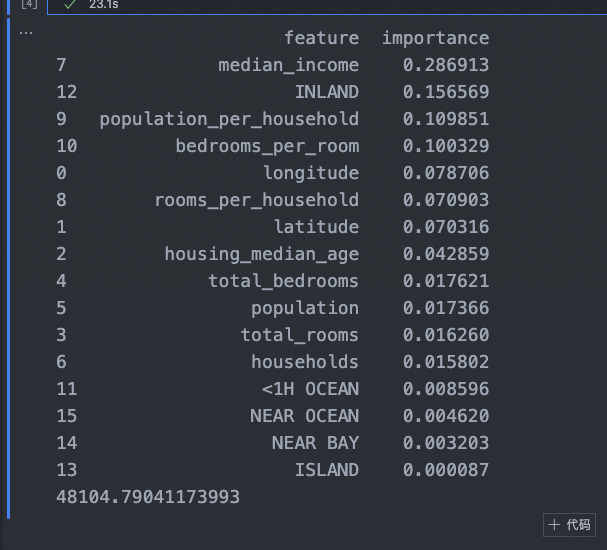
多机器学习模型学习
特征处理 import os import numpy as np import pandas as pd from sklearn.model_selection import train_test_split from sklearn.model_selection import StratifiedShuffleSplit from sklearn.impute import SimpleImputer from sklearn.pipeline import FeatureUnion fr…...

【网页设计】前言
本专栏主要记录 “网页设计” 这一课程的相关笔记。 参考资料: 黑马程序员:黑马程序员pink老师前端入门教程,零基础必看的h5(html5)css3移动端前端视频教程_哔哩哔哩_bilibili 教材:《Adobe创意大学 Dreamweaver CS6标准教材》《…...

STM32巡回研讨会总结(2024)
前言 本次ST公司可以说是推出了7大方面,几乎可以说是覆盖到了目前生活中的方方面面,下面总结下我的感受。无线类 支持多种调制模式(LoRa、(G)FSK、(G)MSK 和 BPSK)满足工业和消费物联网 (IoT) 中各种低功耗广域网 (LPWAN) 无线应…...

54 螺旋矩阵
解题思路: \qquad 这道题可以直接用模拟解决,顺时针螺旋可以分解为依次沿“右-下-左-上”四个方向的移动,每次碰到“边界”时改变方向,边界是不可到达或已经到达过的地方,会随着指针移动不断收缩。 vector<int>…...

基于STM32与OpenCV的物料搬运机械臂设计流程
一、项目概述 本文提出了一种新型的物流搬运机器人,旨在提高物流行业的物料搬运效率和准确性。该机器人结合了 PID 闭环控制算法与视觉识别技术,能够在复杂的环境中实现自主巡线与物料识别。 项目目标与用途 目标:设计一款能够自动搬运物流…...
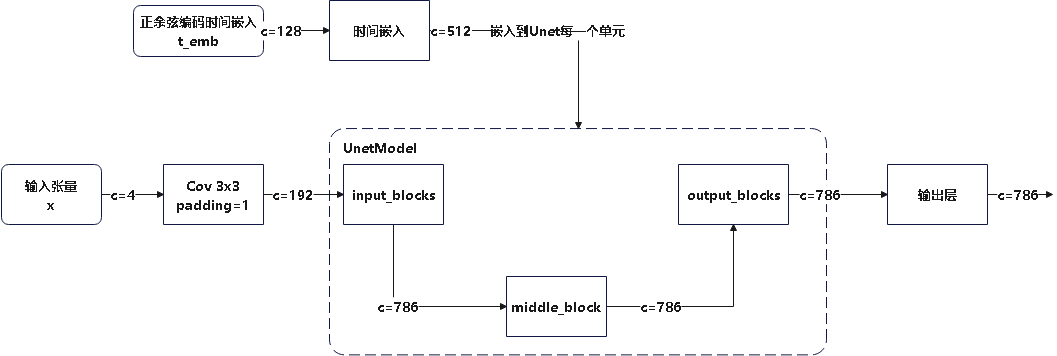
[万字长文]stable diffusion代码阅读笔记
stable diffusion代码阅读笔记 获得更好的阅读体验可以转到我的博客y0k1n0的小破站 本文参考的配置文件信息: AutoencoderKL:stable-diffusion\configs\autoencoder\autoencoder_kl_32x32x4.yaml latent-diffusion:stable-diffusion\configs\latent-diffusion\lsun_churches-ld…...
)
全域数学公理体系下Navier-Stokes方程本源证明(正式论文版)
全域数学公理体系下Navier-Stokes方程本源证明(正式论文版) 作者:乖乖数学 成文日期:2026年5月25日 体系归属:全域数学大典卷七数学物理应用层 核心立论:光速恒定公理、时空曲率公理、四维通量守恒公理格式…...

系统级开发中的夜间MVP构建与Boneyard归档实践
1. 项目概述:一个名为“Boneyard”的夜间MVP构建最近在开源社区里,我注意到一个挺有意思的项目,叫sys-fairy-eve/nightly-mvp-2026-04-05-boneyard。光看这个标题,信息量就很大,它像是一个系统构建流水线上的一个特定快…...

SISSO 终极指南:数据驱动建模的强大工具
SISSO 终极指南:数据驱动建模的强大工具 【免费下载链接】SISSO A data-driven method combining symbolic regression and compressed sensing for accurate & interpretable models. 项目地址: https://gitcode.com/gh_mirrors/si/SISSO SISSO…...

ThinkPad风扇控制终极指南:TPFanCtrl2如何让你的笔记本更安静、更凉爽?
ThinkPad风扇控制终极指南:TPFanCtrl2如何让你的笔记本更安静、更凉爽? 【免费下载链接】TPFanCtrl2 ThinkPad Fan Control 2 (Dual Fan) for Windows 10 and 11 项目地址: https://gitcode.com/gh_mirrors/tp/TPFanCtrl2 你是否厌倦了ThinkPad风…...

Claude Code提示词入门:CLAUDE.md编写完全指南
目录Claude Code提示词入门:CLAUDE.md编写完全指南 🎯📌 目录1. 什么是CLAUDE.md2. 为什么CLAUDE.md这么重要2.1 没有CLAUDE.md会怎样?2.2 有了CLAUDE.md会怎样?2.3 核心价值3. CLAUDE.md的加载机制3.1 加载优先级3.2 …...

面试题详解:检索链路设计全攻略——RAG 检索架构、查询理解、多路召回、混合检索、Rerank、上下文构造与评估闭环
1. 为什么说检索链路设计,是 RAG 项目的“生命线”?1.1 大模型回答质量,很多时候不是模型决定的,而是证据决定的在 RAG 系统里,大模型像一个会组织语言的“回答器”,但它能不能答准,取决于它面前…...

基于RT-Thread的AB32VG1开发板ADC采集与OLED显示实战
1. 项目概述与核心思路最近在折腾中科蓝讯的AB32VG1开发板,这块板子资源挺有意思,RISC-V内核加上丰富的外设,拿来练手嵌入式实时系统再合适不过。之前已经搞定了I2C接口的OLED屏幕显示,能让它乖乖地显示预设的字符串。但光显示静态…...

快速开发AI应用原型时Taotoken分钟级接入的价值
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 快速开发AI应用原型时Taotoken分钟级接入的价值 在黑客松、内部创新日或产品早期原型开发阶段,时间是最宝贵的资源。开…...

直播抠图技术100谈之25---调色中曲线是最优解
为什么曲线调色是最优解 蓝松抠图在即将发布的版本中特意重写了曲线调节,把达芬奇的二级曲线重新做了一遍,并模仿达芬奇的节点图做了自己的节点图。我们为什么要重新设计曲线,因为我们认为调色中曲线是最优解; 结论 在所有调色手段…...

论文降 AI 软件红黑榜!这 3 类是套壳 ChatGPT 改完 AI 率反涨 30% 别用
论文降 AI 软件红黑榜!这 3 类是套壳 ChatGPT 改完 AI 率反涨 30% 别用 每年毕业季都有同学跑来问我——「学姐我花了 200 块买的降 AI 工具,降完之后送知网检测 AI 率反而涨了 30 个点,怎么回事?」这不是段子,是 202…...