静态词向量预训练模型
1、神经网络语言模型
从语言模型的角度来看,N 元语言模型存在明显的缺点。
首先,模型容易受到数据稀疏的影响,一般需要对模型进行平滑处理;其次,无法对长度超过 N 的上下文依赖关系进行建模。
神经网络语言模型 (Neural Network Language Model ),在一定程度上克服了这些问题。一方面,通过引入词的分布式表示,也就是词向量,大大缓解了数据稀疏带来的影响;另一方面,利用更先进的神经网络模型结构(如循环神经网络、Transformer 等),可以对长距离上下文依赖进行有效的建模。 正因为这些优异的特性,加上语言模型任务本身无须人工标注数据的优势,神经网络语言模型几乎己经替代 N 元语言模型。
1.1、预训练任务
给定一段文本w1,w2...,wn,语言模型的基本任务是根据历史上下文对下一时刻的词进行预测,也就是计算条件概率 P(wt l w1,w2...,wt-1)。
为了构建语言模型,可以将其转化为以词表为类别标签集合的分类问题,其输人为历史词序列w1,w2...,wt-1,输出为目标词wt 。然后就可以从无标注的文本语料中构建训练数据集,并通过优化该数据集上的分类损失(如交叉熵损失或负对数似然损失)对模型进行训练。由于监督信号来自数据自身,因此这种学习方式也被称为自监督学习 (Self supervised Learning)。
在讨论模型的具体实现方式之前,首先面临的一个问题是:如何处理动态长度的历史词序列(模型输人)?
一个直观的想法是使用词袋表示,但是这种表示方式忽略了词的顺序信息,语义表达能力非常有限。
前馈神经网络语言模型 ( Feed-forward Neural Network Language Model)以及循环神经网络语言模型 (Recurrent Neural Network Language Model, RNNIM),分别从数据和模型的角度解决这一问题。
1.2、前馈神经网络语言模型 ( Feed-forward Neural Network Language Model)
前馈神经网络语言模型利用了传统N元语言模型中的马尔可夫假设( Markov Assumprion):对下一个词的预测只与历史中最近的n一1 个词相关。从形式上看:

因此,模型的输人变成了长度为n-1 的定长词序列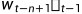 ,模型的任务也转化为对条件概率
,模型的任务也转化为对条件概率 进行估计。
进行估计。
前馈神经网络由输人层、词向量层、隐含层和输出层构成。在前馈神经网络语言模型中,词向量层首先对输人层长为n-1的历史词序列进行编码,将每个词表示为一个低维的实数向量,即词向量;然后,隐含层对词向量层进行线性变换,并使用激活函数实现非线性映射;最后,输出层通过线性变换将隐含层向量映射至词表空间,再通过 Softmax 函数得到在词表上的归一化的概率分布

(1)输入层。模型的输入层由当前时刻t的历史词序列构成,要为离散的符号表示。在具体实现中,既可以使用每个词的独热编码 ( One-Hot Encoding),也可以直接使用每个词在词表中的位置下标。
(2)词向量层。词向量层将输入层中的每个词分别映射至一个低维、稠密的实值特征向量。词向量层也可以理解为一个查找表 (Lookup Table),获取词量的过程,也就是根据词的素引从查找表中找出对应位置的向量的过程。
(3)隐含层。隐含对词向量层x进行线性变换与激活
(4)输出层。模型的输出层对h做线性变换,并利用 Softmax函数进行归一化,以而获得词表 V空间内的概率分布。
综上所述,前馈神经网络语言模型的自由参数包含词向量矩阵E,词向量层与隐含层之间的权值矩阵和偏置, 模型训练完成后,矩阵E则为预训练得到的静态词向量
模型实现
1、数据准备
使用 NLTK 中提供的 Reuters 语料库,该语料库被广泛用于文本分类任务,其中包含 10788 篇新闻类文档,每篇文档具有1个或至个类别。这里忽路数据中的文本类别信息,而只使用其中的文本数据进行词向量的训练。由于在语言模型的训练过程中需要 人一些预留的标记,例如句首标记、句尾标记,以及在构建批次(Batch)时用于补齐序列长度的标记(Padding token) 等,因此定义以下常量:
BOS_TOKEN = "<bos>"#句首标记
EOS_TOKEN = "<eos>"#包尾标记
PAD_TOKEN = "<pad>" # 补齐标记然后加载语料库,构建数据集,建立词表
from collections import defaultdict, Counterclass Vocab:def __init__(self, tokens=None):self.idx_to_token = list()self.token_to_idx = dict()if tokens is not None:if "<unk>" not in tokens:tokens = tokens + ["<unk>"]for token in tokens:self.idx_to_token.append(token)self.token_to_idx[token] = len(self.idx_to_token) - 1self.unk = self.token_to_idx['<unk>']@classmethoddef build(cls, text, min_freq=1, reserved_tokens=None):token_freqs = defaultdict(int)for sentence in text:for token in sentence:token_freqs[token] += 1uniq_tokens = ["<unk>"] + (reserved_tokens if reserved_tokens else [])uniq_tokens += [token for token, freq in token_freqs.items() \if freq >= min_freq and token != "<unk>"]return cls(uniq_tokens)def __len__(self):return len(self.idx_to_token)def __getitem__(self, token):return self.token_to_idx.get(token, self.unk)def convert_tokens_to_ids(self, tokens):return [self[token] for token in tokens]def convert_ids_to_tokens(self, indices):return [self.idx_to_token[index] for index in indices]def save_vocab(vocab, path):with open(path, 'w') as writer:writer.write("\n".join(vocab.idx_to_token))def read_vocab(path):with open(path, 'r') as f:tokens = f.read().split('\n')return Vocab(tokens)#加载语料库
def load_reuters():#从 nltk 导入reutersfrom nltk.corpus import reuters#获取所有句子text = reuters.sents()# lowercase (optional)text = [[word.lower() for word in sentence] for sentence in text]#构建词表,传入预留标记vocab = Vocab.build(text, reserved_tokens=[PAD_TOKEN, BOS_TOKEN, EOS_TOKEN])#利用词表将文本数据转换为idcorpus = [vocab.convert_tokens_to_ids(sentence) for sentence in text]return corpus, vocab#保存词向量
def save_pretrained(vocab, embeds, save_path):"""Save pretrained token vectors in a unified format, where the first linespecifies the `number_of_tokens` and `embedding_dim` followed with alltoken vectors, one token per line."""with open(save_path, "w") as writer:writer.write(f"{embeds.shape[0]} {embeds.shape[1]}\n")for idx, token in enumerate(vocab.idx_to_token):vec = " ".join(["{:.4f}".format(x) for x in embeds[idx]])writer.write(f"{token} {vec}\n")print(f"Pretrained embeddings saved to: {save_path}")2、数据
创建数据处理类,实现架前馈神经网络模型的训练数据构建与存取功能
#从dataset类中派生一个子类
class NGramDataset(Dataset):def __init__(self, corpus, vocab, context_size=2):self.data = []self.bos = vocab[BOS_TOKEN]#句首标记self.eos = vocab[EOS_TOKEN]#句尾标记for sentence in tqdm(corpus, desc="Dataset Construction"):# 插入句首句尾符号sentence = [self.bos] + sentence + [self.eos]#如果句子长度小于预定义的上下文大小,则跳过if len(sentence) < context_size:continuefor i in range(context_size, len(sentence)):# 模型输入:长为context_size的上文context = sentence[i-context_size:i]# 模型输出:当前词target = sentence[i]#每个训练样本由(context, target)构成self.data.append((context, target))def __len__(self):return len(self.data)def __getitem__(self, i):return self.data[i]def collate_fn(self, examples):# 从独立样本集合中构建batch输入输出inputs = torch.tensor([ex[0] for ex in examples], dtype=torch.long)targets = torch.tensor([ex[1] for ex in examples], dtype=torch.long)return (inputs, targets)3、模型
创建语言模型类,参数包含词向量层,由词向量层到隐含层,由隐含层到输出层的线性变换参数
class FeedForwardNNLM(nn.Module):def __init__(self, vocab_size, embedding_dim, context_size, hidden_dim):super(FeedForwardNNLM, self).__init__()# 词嵌入层self.embeddings = nn.Embedding(vocab_size, embedding_dim)# 线性变换:词嵌入层->隐含层self.linear1 = nn.Linear(context_size * embedding_dim, hidden_dim)# 线性变换:隐含层->输出层self.linear2 = nn.Linear(hidden_dim, vocab_size)# 使用ReLU激活函数self.activate = F.reluinit_weights(self)def forward(self, inputs):#将输入词序列映射为词向量,通过view函数对映射后的词向量序列组成的三维张量进行重构,完成词表的拼接embeds = self.embeddings(inputs).view((inputs.shape[0], -1))hidden = self.activate(self.linear1(embeds))output = self.linear2(hidden)# 根据输出层(logits)计算概率分布并取对数,以便于计算对数似然# 这里采用PyTorch库的log_softmax实现log_probs = F.log_softmax(output, dim=1)return log_probs4、训练
#超参数设置
embedding_dim = 64 #词向量维度
context_size = 2 #隐含层维度
hidden_dim = 128 #批次大小
batch_size = 1024 #输入上下文长度
num_epoch = 10 #训练迭代次数# 读取文本数据,构建FFNNLM训练数据集(n-grams)
corpus, vocab = load_reuters()
dataset = NGramDataset(corpus, vocab, context_size)
data_loader = get_loader(dataset, batch_size)# 负对数似然损失函数
nll_loss = nn.NLLLoss()
# 构建FFNNLM,并加载至device
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = FeedForwardNNLM(len(vocab), embedding_dim, context_size, hidden_dim)
model.to(device)
# 使用Adam优化器
optimizer = optim.Adam(model.parameters(), lr=0.001)model.train()
total_losses = []
for epoch in range(num_epoch):total_loss = 0for batch in tqdm(data_loader, desc=f"Training Epoch {epoch}"):inputs, targets = [x.to(device) for x in batch]optimizer.zero_grad()log_probs = model(inputs)loss = nll_loss(log_probs, targets)loss.backward()optimizer.step()total_loss += loss.item()print(f"Loss: {total_loss:.2f}")total_losses.append(total_loss)# 保存词向量(model.embeddings)
save_pretrained(vocab, model.embeddings.weight.data, "ffnnlm.vec")
1.3、循环神经网络语言模型 (Recurrent Neural Network Language Model, RNNIM)
在前馈神经网络语言模型中,对下—个词的预测需要回看多长的历史是由超参数n决定的。但是,不同的句子对历史长度的期望往往是变化的。例如,对于句子 “他 喜欢吃 苹果”,根据“吃” 容易推测出,下个词有很大概率 是一种食物。因此,只需要考虑较短的历史就足够了。而对于结构较为复杂的句子,如“他感冒了,于是下班 之后 去了 医院”,则需要看到较长的历史 (“感冒”)才能合理地预测出目标词 〝医院”。
循环神经网络语言模型正是为了处理这种不定长依赖而设计的一种语言模型。循环神经网络是用来处理序列数据的一种神经网络,而自然语言正好满足这种序列结构性质。循环神经网络语言模型中的每一时刻都维护一个隐含 状态,该状态蕴含了 当前词的所有历史信息,且与当新词一起被作为下一时刻的输入。这个随时刻变化而不断更新的隐含状态也被称作记忆(Merory)。
以上只是循环神经网络最基本的形式,当序列较长时,训练阶段会存在梯度弥散(Vanishing gradient )或者梯度爆炸(Exploding gradient) 的风险。为了应对这一问题,以前的做法是在梯度反向传播的过程中按长度进行截断 ( Truncated Backpropagation Through Time ),从而使得模型能够得到有效的训练,但是与此同时,也减弱了模型对于长距离依赖的建模能力。这种做法一直持续到2015 年左右,之后被含有门控机制的循环神经网络,如长短时记忆网络(LSTM)代替。
模型实现
1、数据准备
仍然使用 NLTK 中提供的 Reuters 语料库
2、数据
创建数据处理类,使用序列预测的方式构建训练样本,与前馈神经网络模型不同,RNNLM是输入长度是动态变化的,因此构建批次时,需要对批次内的样本补齐,时长度一致
class RnnlmDataset(Dataset):def __init__(self, corpus, vocab):self.data = []self.bos = vocab[BOS_TOKEN]self.eos = vocab[EOS_TOKEN]self.pad = vocab[PAD_TOKEN]for sentence in tqdm(corpus, desc="Dataset Construction"):# 模型输入:BOS_TOKEN, w_1, w_2, ..., w_ninput = [self.bos] + sentence# 模型输出:w_1, w_2, ..., w_n, EOS_TOKENtarget = sentence + [self.eos]self.data.append((input, target))def __len__(self):return len(self.data)def __getitem__(self, i):return self.data[i]def collate_fn(self, examples):# 从独立样本集合中构建batch输入输出inputs = [torch.tensor(ex[0]) for ex in examples]targets = [torch.tensor(ex[1]) for ex in examples]# 对batch内的样本进行padding,使其具有相同长度inputs = pad_sequence(inputs, batch_first=True, padding_value=self.pad)targets = pad_sequence(targets, batch_first=True, padding_value=self.pad)return (inputs, targets)3、模型
class RNNLM(nn.Module):def __init__(self, vocab_size, embedding_dim, hidden_dim):super(RNNLM, self).__init__()# 词嵌入层self.embeddings = nn.Embedding(vocab_size, embedding_dim)# 循环神经网络:这里使用LSTMself.rnn = nn.LSTM(embedding_dim, hidden_dim, batch_first=True)# 输出层self.output = nn.Linear(hidden_dim, vocab_size)def forward(self, inputs):embeds = self.embeddings(inputs)# 计算每一时刻的隐含层表示hidden, _ = self.rnn(embeds)output = self.output(hidden)log_probs = F.log_softmax(output, dim=2)return log_probs4、训练
embedding_dim = 64
context_size = 2
hidden_dim = 128
batch_size = 1024
num_epoch = 10# 读取文本数据,构建FFNNLM训练数据集(n-grams)
corpus, vocab = load_reuters()
dataset = RnnlmDataset(corpus, vocab)
data_loader = get_loader(dataset, batch_size)# 负对数似然损失函数,忽略pad_token处的损失
nll_loss = nn.NLLLoss(ignore_index=dataset.pad)
# 构建RNNLM,并加载至device
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = RNNLM(len(vocab), embedding_dim, hidden_dim)
model.to(device)
# 使用Adam优化器
optimizer = optim.Adam(model.parameters(), lr=0.001)model.train()
for epoch in range(num_epoch):total_loss = 0for batch in tqdm(data_loader, desc=f"Training Epoch {epoch}"):inputs, targets = [x.to(device) for x in batch]optimizer.zero_grad()log_probs = model(inputs)loss = nll_loss(log_probs.view(-1, log_probs.shape[-1]), targets.view(-1))loss.backward()optimizer.step()total_loss += loss.item()print(f"Loss: {total_loss:.2f}")save_pretrained(vocab, model.embeddings.weight.data, "rnnlm.vec")运行结果
2、Word2vec词向量
从词向量学习的角度来看,基于神经网络语言模型的预训练方法存在一个明显的缺点,即当对t时刻词进行预测时,模型只利用了历史词序列作为输人,而损失了与“未来”上下文之间的共现信息。
介绍一类训练效率更高、 表达能力更强的词向量预训练模型一-Word2vec ,其中包括 CBOW ( Continuous Bag-of Words)模型以及 Skip-grarn 模型。这两个模型由 Tomas Mikolov 等人于 2013年提出,它们不再是严格意义上的语言模型,完全基于词与词之间的共现信息实现词向量的学习
2.1、CBOW模型
给定一段文本,CBOW 模型的基本思想是根据上下文对目标词进行预测。 与神经网络语言模型不同,CBOW模型不考虑上下文中单词的位置或者顺序,因此模型的输人实际上是一个“词袋”而非序列,这也是模型取名为 “Coninuous Bag-of words”的原因。但是,这并不意味者位置信息毫无用处。相关研究表明,融入相对位置信息之后所得到的词向量在语法相关的自然语言处理任务(如词性标注、依存句法分析)上表现更好。
与一般的前馈神经 网络相比,CBOW 模型的隐含层只是执行对词向量层取平均的操作,而没有线性变换以及非线性激活的过程。所以,也可以认为 CBOW 模型是没有隐含层的,这也是CBOW 模型具有高训练效率的主要原因。
模型实现:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset
from torch.nn.utils.rnn import pad_sequence
from tqdm.auto import tqdm
from utils import BOS_TOKEN, EOS_TOKEN, PAD_TOKEN
from utils import load_reuters, save_pretrained, get_loader, init_weightsclass CbowDataset(Dataset):def __init__(self, corpus, vocab, context_size=2):self.data = []self.bos = vocab[BOS_TOKEN]self.eos = vocab[EOS_TOKEN]for sentence in tqdm(corpus, desc="Dataset Construction"):sentence = [self.bos] + sentence+ [self.eos]#如果句子长度不足以构建(上下文,目标词)训练样本,则跳过if len(sentence) < context_size * 2 + 1:continuefor i in range(context_size, len(sentence) - context_size):# 模型输入:左右分别取context_size长度的上下文context = sentence[i-context_size:i] + sentence[i+1:i+context_size+1]# 模型输出:当前词target = sentence[i]self.data.append((context, target))def __len__(self):return len(self.data)def __getitem__(self, i):return self.data[i]def collate_fn(self, examples):inputs = torch.tensor([ex[0] for ex in examples])targets = torch.tensor([ex[1] for ex in examples])return (inputs, targets)#与前馈神经网络较为接近,区别在于隐含层完全线性化,只需要对输入层向量取平均
class CbowModel(nn.Module):def __init__(self, vocab_size, embedding_dim):super(CbowModel, self).__init__()# 词嵌入层self.embeddings = nn.Embedding(vocab_size, embedding_dim)# 线性变换:隐含层->输出层self.output = nn.Linear(embedding_dim, vocab_size)init_weights(self)def forward(self, inputs):embeds = self.embeddings(inputs)# 计算隐含层:对上下文词向量求平均hidden = embeds.mean(dim=1)output = self.output(hidden)log_probs = F.log_softmax(output, dim=1)return log_probsembedding_dim = 64
context_size = 2
hidden_dim = 128
batch_size = 1024
num_epoch = 10# 读取文本数据,构建CBOW模型训练数据集
corpus, vocab = load_reuters()
dataset = CbowDataset(corpus, vocab, context_size=context_size)
data_loader = get_loader(dataset, batch_size)nll_loss = nn.NLLLoss()
# 构建CBOW模型,并加载至device
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = CbowModel(len(vocab), embedding_dim)
model.to(device)
optimizer = optim.Adam(model.parameters(), lr=0.001)model.train()
for epoch in range(num_epoch):total_loss = 0for batch in tqdm(data_loader, desc=f"Training Epoch {epoch}"):inputs, targets = [x.to(device) for x in batch]optimizer.zero_grad()log_probs = model(inputs)loss = nll_loss(log_probs, targets)loss.backward()optimizer.step()total_loss += loss.item()print(f"Loss: {total_loss:.2f}")# 保存词向量(model.embeddings)
save_pretrained(vocab, model.embeddings.weight.data, "cbow.vec")运行结果

2.2、 Skip-gram 模型
绝大多数词向量学习模型本质上都是在建立词与其上下文之间的联系。CBOW 模型使用上下文窗口中词的集合作为条件输人预测目标词, 。而Skip-gram 模型在此基础之上作了进一步的简化,使用Ct中的每个词作为独立的上下文对目标词进行预测。因此,Skip-gram 模型建立的是词与词之间的共现关系,即
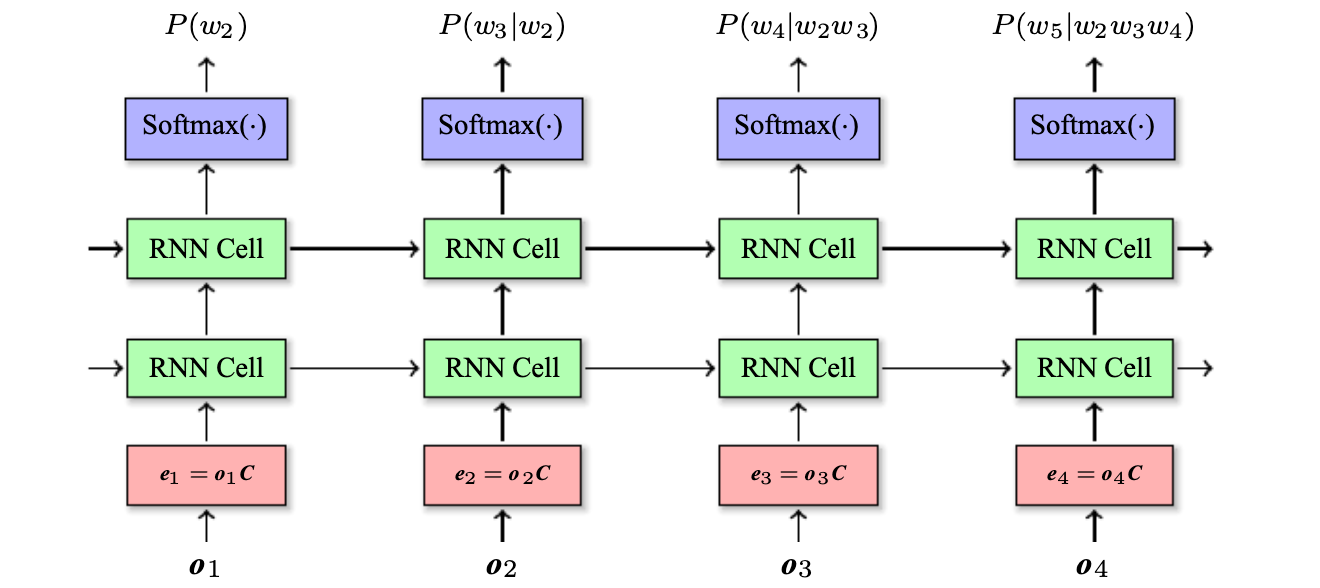
。而Skip-gram 模型在此基础之上作了进一步的简化,使用Ct中的每个词作为独立的上下文对目标词进行预测。因此,Skip-gram 模型建立的是词与词之间的共现关系,即 ,原文献口对于 Skip-gram 模型的描述是根据当前词wt 预测其上下文中的词wt+j,即
,原文献口对于 Skip-gram 模型的描述是根据当前词wt 预测其上下文中的词wt+j,即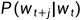 。这两种形式是等价的。
。这两种形式是等价的。
模型实现:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset
from torch.nn.utils.rnn import pad_sequence
from tqdm.auto import tqdm
from utils import BOS_TOKEN, EOS_TOKEN, PAD_TOKEN
from utils import load_reuters, save_pretrained, get_loader, init_weights#模型输入与CBOW接近,区别在于输入输出都是单个词,即在一定程度上下文窗口大小内共现的词对
class SkipGramDataset(Dataset):def __init__(self, corpus, vocab, context_size=2):self.data = []self.bos = vocab[BOS_TOKEN]self.eos = vocab[EOS_TOKEN]for sentence in tqdm(corpus, desc="Dataset Construction"):sentence = [self.bos] + sentence + [self.eos]for i in range(1, len(sentence)-1):# 模型输入:当前词w = sentence[i]# 模型输出:一定窗口大小内的上下文left_context_index = max(0, i - context_size)right_context_index = min(len(sentence), i + context_size)context = sentence[left_context_index:i] + sentence[i+1:right_context_index+1]self.data.extend([(w, c) for c in context])def __len__(self):return len(self.data)def __getitem__(self, i):return self.data[i]def collate_fn(self, examples):inputs = torch.tensor([ex[0] for ex in examples])targets = torch.tensor([ex[1] for ex in examples])return (inputs, targets)class SkipGramModel(nn.Module):def __init__(self, vocab_size, embedding_dim):super(SkipGramModel, self).__init__()self.embeddings = nn.Embedding(vocab_size, embedding_dim)self.output = nn.Linear(embedding_dim, vocab_size)init_weights(self)def forward(self, inputs):embeds = self.embeddings(inputs)#根据当前词的词向量,对上下文进行预测output = self.output(embeds)log_probs = F.log_softmax(output, dim=1)return log_probsembedding_dim = 64
context_size = 2
hidden_dim = 128
batch_size = 1024
num_epoch = 10# 读取文本数据,构建Skip-gram模型训练数据集
corpus, vocab = load_reuters()
dataset = SkipGramDataset(corpus, vocab, context_size=context_size)
data_loader = get_loader(dataset, batch_size)nll_loss = nn.NLLLoss()
# 构建Skip-gram模型,并加载至device
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = SkipGramModel(len(vocab), embedding_dim)
model.to(device)
optimizer = optim.Adam(model.parameters(), lr=0.001)model.train()
for epoch in range(num_epoch):total_loss = 0for batch in tqdm(data_loader, desc=f"Training Epoch {epoch}"):inputs, targets = [x.to(device) for x in batch]optimizer.zero_grad()log_probs = model(inputs)loss = nll_loss(log_probs, targets)loss.backward()optimizer.step()total_loss += loss.item()print(f"Loss: {total_loss:.2f}")# 保存词向量(model.embeddings)
save_pretrained(vocab, model.embeddings.weight.data, "skipgram.vec")输出

2.3、 负采样
目前介绍的词向量预训练模型可以归纳为对目标词的条件项测任务。如根据上下文预测当前词(CBOW 模型)或者根据当前词预测上下文(Skip-gram模型)。 当词表规模较大且计算资源有限时,这类模型的训练过程会受到输出层概率归一化 (Normalization)计算效率的影响。负采样方法则提供了一种新的任务视角:给定当前词与其上下文,最大化两者共现的概率。这样一来,问题就被简化为对于(w,c)的二元分类问题(共现或者非共现),从而规避了大词表上的归一化计算。
基于负采样的 Skip-gram 模型
1、数据
在基于负采样的 Skip-gram 模型中,对于每个训练(正)样本,需要根据某个负采样概率分布生成相应的负样本,同时需要保证负样本不包含当前上下文窗口内的词。一种实现方式是,在构建训练数据的过程中就完成负样本的生成,这样在训练时直接读取负样本即可。这样做的优点是训练过程无须再进行负采样,因而效率较高;缺点是每次迭代使用的是同样的负样本,缺乏多样性。 这里采用在训练过程中实时进行负采样的实现方式,
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset
from torch.nn.utils.rnn import pad_sequence
from tqdm.auto import tqdm
from utils import BOS_TOKEN, EOS_TOKEN, PAD_TOKEN
from utils import load_reuters, save_pretrained, get_loader, init_weightsclass SGNSDataset(Dataset):def __init__(self, corpus, vocab, context_size=2, n_negatives=5, ns_dist=None):self.data = []self.bos = vocab[BOS_TOKEN]self.eos = vocab[EOS_TOKEN]self.pad = vocab[PAD_TOKEN]for sentence in tqdm(corpus, desc="Dataset Construction"):sentence = [self.bos] + sentence + [self.eos]for i in range(1, len(sentence)-1):# 模型输入:(w, context) ;输出为0/1,表示context是否为负样本w = sentence[i]left_context_index = max(0, i - context_size)right_context_index = min(len(sentence), i + context_size)context = sentence[left_context_index:i] + sentence[i+1:right_context_index+1]context += [self.pad] * (2 * context_size - len(context))self.data.append((w, context))# 负样本数量self.n_negatives = n_negatives# 负采样分布:若参数ns_dist为None,则使用uniform分布self.ns_dist = ns_dist if ns_dist is not None else torch.ones(len(vocab))def __len__(self):return len(self.data)def __getitem__(self, i):return self.data[i]def collate_fn(self, examples):words = torch.tensor([ex[0] for ex in examples], dtype=torch.long)contexts = torch.tensor([ex[1] for ex in examples], dtype=torch.long)batch_size, context_size = contexts.shapeneg_contexts = []# 对batch内的样本分别进行负采样for i in range(batch_size):# 保证负样本不包含当前样本中的contextns_dist = self.ns_dist.index_fill(0, contexts[i], .0)neg_contexts.append(torch.multinomial(ns_dist, self.n_negatives * context_size, replacement=True))neg_contexts = torch.stack(neg_contexts, dim=0)return words, contexts, neg_contexts2、模型
class SGNSModel(nn.Module):def __init__(self, vocab_size, embedding_dim):super(SGNSModel, self).__init__()# 词嵌入self.w_embeddings = nn.Embedding(vocab_size, embedding_dim)# 上下文嵌入self.c_embeddings = nn.Embedding(vocab_size, embedding_dim)def forward_w(self, words):w_embeds = self.w_embeddings(words)return w_embedsdef forward_c(self, contexts):c_embeds = self.c_embeddings(contexts)return c_embeds3、训练
def get_unigram_distribution(corpus, vocab_size):# 从给定语料中统计unigram概率分布token_counts = torch.tensor([0] * vocab_size)total_count = 0for sentence in corpus:total_count += len(sentence)for token in sentence:token_counts[token] += 1unigram_dist = torch.div(token_counts.float(), total_count)return unigram_dist#超参数
embedding_dim = 64
context_size = 2
hidden_dim = 128
batch_size = 1024
num_epoch = 10
n_negatives = 10 #负样本数量# 读取文本数据
corpus, vocab = load_reuters()
# 计算unigram概率分布
unigram_dist = get_unigram_distribution(corpus, len(vocab))
# 根据unigram分布计算负采样分布: p(w)**0.75
negative_sampling_dist = unigram_dist ** 0.75
negative_sampling_dist /= negative_sampling_dist.sum()
# 构建SGNS训练数据集
dataset = SGNSDataset(corpus,vocab,context_size=context_size,n_negatives=n_negatives,ns_dist=negative_sampling_dist
)
data_loader = get_loader(dataset, batch_size)device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = SGNSModel(len(vocab), embedding_dim)
model.to(device)
optimizer = optim.Adam(model.parameters(), lr=0.001)model.train()
for epoch in range(num_epoch):total_loss = 0for batch in tqdm(data_loader, desc=f"Training Epoch {epoch}"):words, contexts, neg_contexts = [x.to(device) for x in batch]optimizer.zero_grad()batch_size = words.shape[0]# 提取batch内词、上下文以及负样本的向量表示word_embeds = model.forward_w(words).unsqueeze(dim=2)context_embeds = model.forward_c(contexts)neg_context_embeds = model.forward_c(neg_contexts)# 正样本的分类(对数)似然context_loss = F.logsigmoid(torch.bmm(context_embeds, word_embeds).squeeze(dim=2))context_loss = context_loss.mean(dim=1)# 负样本的分类(对数)似然neg_context_loss = F.logsigmoid(torch.bmm(neg_context_embeds, word_embeds).squeeze(dim=2).neg())neg_context_loss = neg_context_loss.view(batch_size, -1, n_negatives).sum(dim=2)neg_context_loss = neg_context_loss.mean(dim=1)# 损失:负对数似然loss = -(context_loss + neg_context_loss).mean()loss.backward()optimizer.step()total_loss += loss.item()print(f"Loss: {total_loss:.2f}")# 合并词嵌入矩阵与上下文嵌入矩阵,作为最终的预训练词向量
combined_embeds = model.w_embeddings.weight + model.c_embeddings.weight
save_pretrained(vocab, combined_embeds.data, "sgns.vec")输出

3、GloVe词向量
无论是基于神经网络语言模型还是 word2vec 的词向量预训练方法,本质上都是利用文本中词与词在局部上下文中的共现信息作为自监督学习信号。除此之外,另一类常用于估计词向量的方法是基于矩阵分解的方法,例如潜在语义分析等。这类方法首先对语料进行统计分析,并获得合有全局统计信息的“词-上下文”共现短阵,然后利用奇异值分解 (Singular Value Decomposition, SVD )对该矩阵进行降维,进而得到词的低维表示。然而,传统的矩阵分解方法得到的词 向量不具备良好的几何性质,因此,结合词向量以及矩阵分解的思想,提出Glove ( Global Vectors for Word Representation)模型。
3.1、模型实现
Glove模型的基本思想是利用词向量对 “词-上下文〞共现矩阵进行预测(或者回归),从而实现隐式的短阵分解。
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset
from torch.nn.utils.rnn import pad_sequence
from tqdm.auto import tqdm
from utils import BOS_TOKEN, EOS_TOKEN, PAD_TOKEN
from utils import load_reuters, save_pretrained, get_loader, init_weights
from collections import defaultdict#构建数据处理块,该模块需要完成共现矩阵的构建与存取
class GloveDataset(Dataset):def __init__(self, corpus, vocab, context_size=2):# 记录词与上下文在给定语料中的共现次数self.cooccur_counts = defaultdict(float)self.bos = vocab[BOS_TOKEN]self.eos = vocab[EOS_TOKEN]for sentence in tqdm(corpus, desc="Dataset Construction"):sentence = [self.bos] + sentence + [self.eos]for i in range(1, len(sentence)-1):w = sentence[i]left_contexts = sentence[max(0, i - context_size):i]right_contexts = sentence[i+1:min(len(sentence), i + context_size)+1]# 共现次数随距离衰减: 1/d(w, c)for k, c in enumerate(left_contexts[::-1]):self.cooccur_counts[(w, c)] += 1 / (k + 1)for k, c in enumerate(right_contexts):self.cooccur_counts[(w, c)] += 1 / (k + 1)self.data = [(w, c, count) for (w, c), count in self.cooccur_counts.items()]def __len__(self):return len(self.data)def __getitem__(self, i):return self.data[i]def collate_fn(self, examples):words = torch.tensor([ex[0] for ex in examples])contexts = torch.tensor([ex[1] for ex in examples])counts = torch.tensor([ex[2] for ex in examples])return (words, contexts, counts)class GloveModel(nn.Module):def __init__(self, vocab_size, embedding_dim):super(GloveModel, self).__init__()# 词嵌入及偏置向量self.w_embeddings = nn.Embedding(vocab_size, embedding_dim)self.w_biases = nn.Embedding(vocab_size, 1)# 上下文嵌入及偏置向量self.c_embeddings = nn.Embedding(vocab_size, embedding_dim)self.c_biases = nn.Embedding(vocab_size, 1)def forward_w(self, words):w_embeds = self.w_embeddings(words)w_biases = self.w_biases(words)return w_embeds, w_biasesdef forward_c(self, contexts):c_embeds = self.c_embeddings(contexts)c_biases = self.c_biases(contexts)return c_embeds, c_biases#超参数
embedding_dim = 64
context_size = 2
batch_size = 1024
num_epoch = 10# 用以控制样本权重的超参数
m_max = 100
alpha = 0.75
# 从文本数据中构建GloVe训练数据集
corpus, vocab = load_reuters()
dataset = GloveDataset(corpus,vocab,context_size=context_size
)
data_loader = get_loader(dataset, batch_size)device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = GloveModel(len(vocab), embedding_dim)
model.to(device)
optimizer = optim.Adam(model.parameters(), lr=0.001)model.train()
for epoch in range(num_epoch):total_loss = 0for batch in tqdm(data_loader, desc=f"Training Epoch {epoch}"):words, contexts, counts = [x.to(device) for x in batch]# 提取batch内词、上下文的向量表示及偏置word_embeds, word_biases = model.forward_w(words)context_embeds, context_biases = model.forward_c(contexts)# 回归目标值:必要时可以使用log(counts+1)进行平滑log_counts = torch.log(counts)# 样本权重weight_factor = torch.clamp(torch.pow(counts / m_max, alpha), max=1.0)optimizer.zero_grad()# 计算batch内每个样本的L2损失loss = (torch.sum(word_embeds * context_embeds, dim=1, keepdim=True) + word_biases + context_biases - log_counts) ** 2# 样本加权损失wavg_loss = (weight_factor * loss).mean()wavg_loss.backward()optimizer.step()total_loss += wavg_loss.item()print(f"Loss: {total_loss:.2f}")# 合并词嵌入矩阵与上下文嵌入矩阵,作为最终的预训练词向量
combined_embeds = model.w_embeddings.weight + model.c_embeddings.weight
save_pretrained(vocab, combined_embeds.data, "glove.vec")输出

相关文章:
静态词向量预训练模型
1、神经网络语言模型从语言模型的角度来看,N 元语言模型存在明显的缺点。首先,模型容易受到数据稀疏的影响,一般需要对模型进行平滑处理;其次,无法对长度超过 N 的上下文依赖关系进行建模。神经网络语言模型 (Neural N…...
永久免费CRM怎么选?有什么好用的功能?
在当今商业环境下,企业经营者们都希望能够找到一种方法来提高自己的生产力和盈利能力。一种非常有效的方法就是实现客户关系管理(CRM)。然而,由于很多传统的CRM解决方案价格昂贵,小企业和创业公司很难承担。那么&#…...
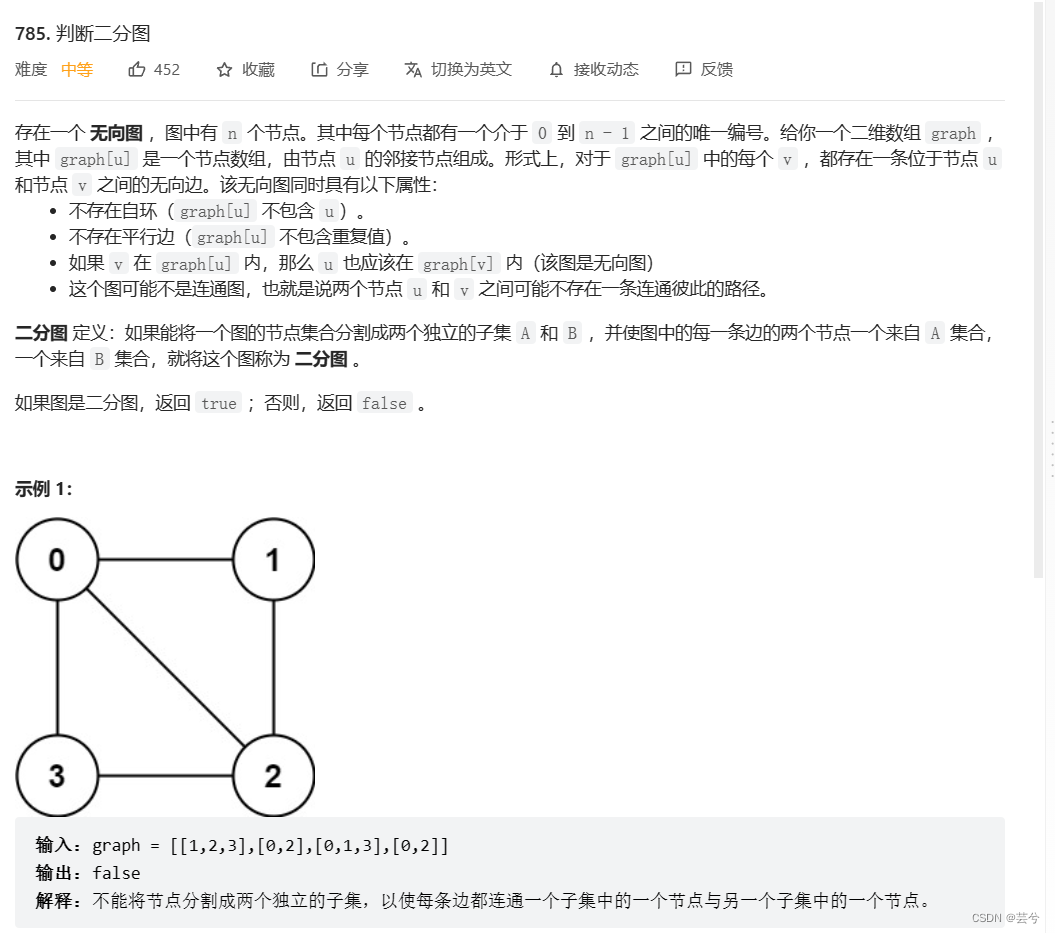
leetcode重点题目分类别记录(二)基本算法:二分,位图,回溯,动态规划,图论基础,拓扑排序
layout: post title: leetcode重点题目分类别记录(二)基本算法:二分,位图,回溯,动态规划,拓扑排序 description: leetcode重点题目分类别记录(二)基本算法:二…...

【JaveEE】多线程之定时器(Timer)
目录 1.定时器的定义 2.标准库中的定时器 2.1构造方法 2.2成员方法 3.模拟实现一个定时器 schedule()方法 构造方法 4.MyTimer完整代码 1.定时器的定义 定时器也是软件开发中的一个重要组件. 类似于一个 "闹钟". 达到一个设定的时间之后, 就执行某个指…...
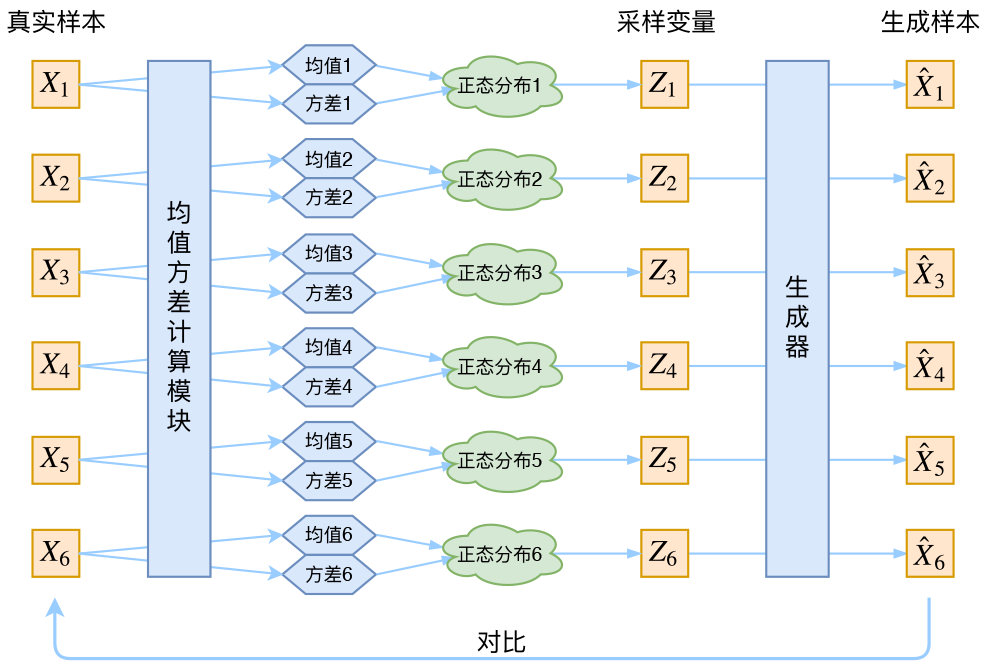
【理论推导】变分自动编码器 Variational AutoEncoder(VAE)
变分推断 (Variational Inference) 变分推断属于对隐变量模型 (Latent Variable Model) 处理的一种技巧,其概率图如下所示 我们将 X{x1,...xN}X\{ x_1,...x_N \}X{x1,...xN} 看作是每个样本可观测的一组数据,而将对应的 Z{z1,...,zN}Z\{z_1,...,z_N…...

【哈希表:哈希函数构造方法、哈希冲突的处理】
预测未来的最好方法就是创造它💦 目录 一、什么是Hash表 二、Hash冲突 三、Hash函数的构造方法 1. 直接定址法 2. 除余法 3. 基数转换法 4. 平方取中法 5. 折叠法 6. 移位法 7. 随机数法 四、处理冲突方法 1. 开放地址法 • 线性探测法 …...

HTML5 应用程序缓存
HTML5 应用程序缓存 使用 HTML5,通过创建 cache manifest 文件,可以轻松地创建 web 应用的离线版本。这意味着,你可以在没有网络连接的情况下进行访问。 什么是应用程序缓存(Application Cache)? HTML5 引…...

全国计算机等级考试三级网络技术选择题考点
目录 第一章 网络系统结构与设计的基本原则 第二章 中小型网络系统总体规划与设计方法 第三章 IP地址规划技术 第四章 路由设计基础 第五章 局域网技术基础应用 第六/七章 交换机/路由器及其配置 第八章 无线局域网技术 第九章 计算机网络信息服务系统的安装与…...

Python和VC代码实现希尔伯特变换(Hilbert transform)
文章目录前言一、希尔伯特变换是什么?二、VC中的实现原理及代码示例三、用Python代码实现总结前言 在数学和信号处理中,**希尔伯特变换(Hilbert transform)**是一个对函数产生定义域相同的函数的线性算子。 希尔伯特变换在信号处…...

嵌入式C语言语法概述
1.gcc概述 GCC全称是GUN C Compiler 随着时代的发展GCC支持的语言越来越多,它的名称变成了GNU Compiler Collection gcc的作用相当于翻译官,把程序设计语言翻译成计算机能理解的机器语言。 (1)gcc -o gcc -o (其…...
蓝桥杯第19天(Python)(疯狂刷题第3天)
题型: 1.思维题/杂题:数学公式,分析题意,找规律 2.BFS/DFS:广搜(递归实现),深搜(deque实现) 3.简单数论:模,素数(只需要…...
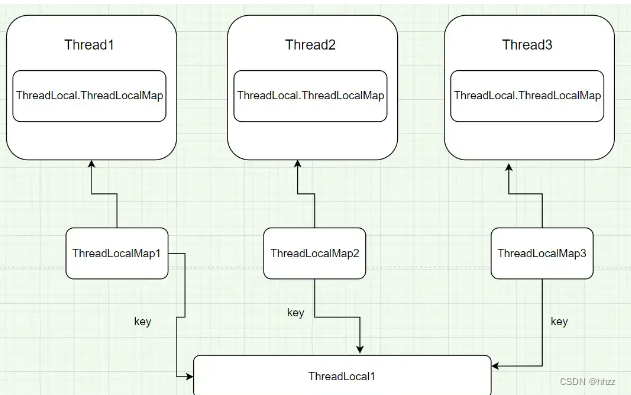
【数据库连接,线程,ThreadLocal三者之间的关系】
一、数据库连接与线程的关系 在实际项目中,数据库连接是很宝贵的资源,以MySQL为例,一台MySQL服务器最大连接数默认是100, 最大可以达到16384。但现实中最多是到200,再多MySQL服务器就承受不住了。因为mysql连接用的是tcp协议&…...
java 虚拟股票交易系统Myeclipse开发mysql数据库web结构jsp编程计算机网页项目
一、源码特点 JSP 虚拟股票交易系统是一套完善的java web信息管理系统,对理解JSP java编程开发语言有帮助,系统采用serlvetdaobean,系统具有完整的源代码和数据库,系统主要采用 B/S模式开发。 java 虚拟股票交易系统Myeclips…...

spring如何开启允许循环依赖
如何解决spring循环依赖 在Spring框架中,allowCircularReferences属性是用于控制Bean之间的循环依赖的。循环依赖是指两个或多个Bean之间相互依赖的情况,其中一个Bean依赖于另一个Bean,同时另一个Bean又依赖于第一个Bean。 allowCircularRe…...
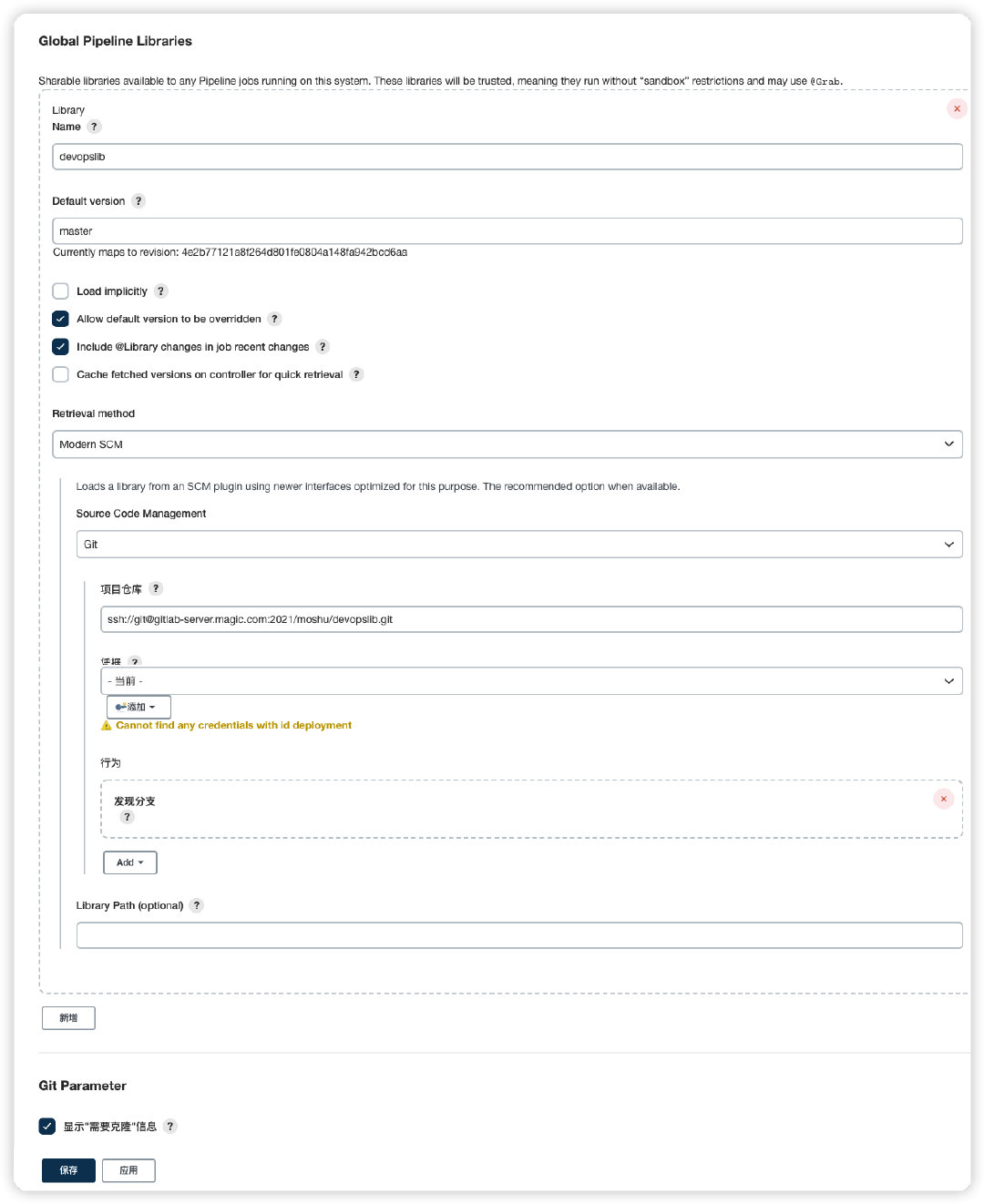
jenkins+sonarqube+自动部署服务
一、jenkins 配置Pipeline 二、新建共享库执行脚本 共享库可以是一个普通的gitlab项目,目录结构如下 三、添加到共享库 Jenkins Dashboard–>系统管理–>系统配置–>Global Pipeline Libraries Name: 共享库名称,自定义即可; Defa…...

【算法系列之动态规划III】背包问题
背包问题 01背包指的是物品只有1个,可以选也可以不选。完全背包是物品有无数个,可以选几个也可以不选。 二维数组01背包 有n件物品和一个最多能背重量为w 的背包。第i件物品的重量是weight[i],得到的价值是value[i] 。每件物品只能用一次&…...

MONAI-LayerFactory设计与实现
LayerFactory 用于创建图层的工厂对象,这使用给定的工厂函数来实际产生类型或构建可调用程序。这些函数是通过名称来参考的,可以在任何时候添加。 用到的关键技术点: 装饰器(Decorators), 例如:property装饰器,创建…...

Thinkphp 6.0路由的定义
本节课我们来了解一下路由方面的知识,然后简单的使用一下路由的功能。 一.路由简介 1. 路由的作用就是让 URL 地址更加的规范和优雅,或者说更加简洁; 2. 设置路由对 URL 的检测、验证等一系列操作提供了极大的便利性; …...

Kafka系列之:深入理解Kafka集群调优
Kafka系列之:深入理解Kafka集群调优 一、Kafka硬件配置选择二、Kafka内存选择三、CPU选择四、网络选择五、生产者调优六、broker调优七、消费者调优八、Kafka总体调优一、Kafka硬件配置选择 服务器台数选择: 2 * (生产者峰值生产速率 * 副本数 / 100) + 1磁盘选择: Kafka…...

creator-泄漏检测之资源篇
title: creator-泄漏检测之资源篇 categories: Cocos2dx tags: [creator, 优化, 泄漏, 内存] date: 2023-03-29 14:48:48 comments: false mathjax: true toc: true creator-泄漏检测之资源篇 前篇 资源释放 - https://docs.cocos.com/creator/manual/zh/asset/release-manager…...

大模型长对话记忆难题:LightMem轻量记忆系统原理与实战
1. 项目概述:当大模型遇上“记忆”瓶颈 最近在折腾大语言模型应用时,我遇到了一个挺典型的问题:想让模型记住更多、更长的对话历史,但无论是直接增加上下文窗口,还是用传统的向量数据库做检索增强,都感觉差…...

STC8H单片机低功耗实战:用掉电模式和外部中断,让电池续航翻倍
STC8H单片机低功耗实战:用掉电模式和外部中断,让电池续航翻倍 在电池供电的嵌入式设备开发中,功耗控制往往是决定产品成败的关键因素。想象一下,一款设计精良的便携式环境监测仪,如果因为功耗问题导致频繁更换电池&am…...
)
别只装AlexNet了!手把手教你在MATLAB里玩转更多预训练模型(VGG, ResNet, MobileNet安装指南)
别只装AlexNet了!手把手教你在MATLAB里玩转更多预训练模型(VGG, ResNet, MobileNet安装指南) 当你第一次在MATLAB中调用alexnet函数时,那种"开箱即用"的体验确实令人惊艳。但就像一位米其林大厨不会只满足于使用基础厨具…...

从省级技术中心认证,看嵌入式企业如何以系统工程能力赋能开发者
1. 从“省级企业技术中心”认定,看一家嵌入式企业的硬核实力最近,在河北省发改委公布的2023年省级企业技术中心认定名单里,我看到了一个熟悉的名字——保定飞凌嵌入式技术有限公司。对于圈内人来说,“飞凌嵌入式”这个名字并不陌生…...

终极免费解锁WeMod Pro会员功能:Wand-Enhancer完整使用指南
终极免费解锁WeMod Pro会员功能:Wand-Enhancer完整使用指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer Wand-Enhancer是一款强大的开源增…...
)
从原理到批量利用:深入剖析Apache Superset默认密钥漏洞(CVE-2023-27524)
1. Apache Superset安全漏洞背景 Apache Superset作为一款流行的开源数据可视化工具,在企业数据分析领域有着广泛应用。但正是这样一个看似无害的工具,却因为开发者的一个常见疏忽——使用默认密钥,导致了严重的身份验证绕过漏洞。这个编号为…...

框架式幕墙与单元式幕墙的价格差异
框架式幕墙与单元式幕墙的价格差异 框架式幕墙与单元式幕墙由于结构及安装方式的不同,在价格方面存着很大的差异。主要表现在以下几个方面: 铝型材的用量: 框架式幕墙铝型材用量一般在7—9 kg/平方米左右。 单元式幕墙铝型材用量一般在13—15kg/平方米左右。 两者每平方…...

跨越平台限制:如何用WorkshopDL免费获取Steam创意工坊模组
跨越平台限制:如何用WorkshopDL免费获取Steam创意工坊模组 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 还在为Epic Games或GOG平台无法访问Steam创意工坊而烦恼吗…...

深入解析go-containerregistry:无守护进程的容器镜像操作利器
1. 项目概述:容器镜像的“瑞士军刀”如果你在容器化这条路上已经走了一段时间,那么对“镜像”这个概念一定不会陌生。无论是 Docker Hub 上的nginx:latest,还是你公司私有仓库里的myapp:v1.2.3,这些镜像都是容器世界的基石。但你是…...

Vibe Coding Playbook:从环境到心流,打造高效愉悦的编程系统
1. 项目概述:一个关于“氛围感编程”的实践指南最近在GitHub上看到一个挺有意思的项目,叫“Vibe Coding Playbook”。乍一看这个标题,可能会有点摸不着头脑——“Vibe Coding”是什么?是某种新的编程范式吗?还是某种神…...