dolphinscheduler-3.1.4
1、相关环境
1.1、创建用户,配置免密
useradd hadoop;
echo "Hadoop#149" | passwd --stdin hadoop#配置sudo免密
sed -i '$ahadoop ALL=(ALL) NOPASSWD: NOPASSWD: ALL' /etc/sudoers
sed -i 's/Defaults requirett/#Defaults requirett/g' /etc/sudoers1.2、ssh免密配置
#切换到部署用户并配置ssh本机免密登录
su hadoop;ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys1.3、关闭防火墙 firewalld 和 Selinux
#关闭防火墙:
systemctl stop firewalld
systemctl status firewalld
systemctl disable firewalld#修改selinux的enforcing为disabled:
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config#查看selinux状态:
sestatus1.4、创建数据库
在MySQL数据库中:
set global validate_password_policy=0;
set global validate_password_length=1;CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
CREATE USER ds @'%' IDENTIFIED BY 'Changxin*8';GRANT ALL PRIVILEGES ON dolphinscheduler.* TO 'ds'@'%' IDENTIFIED BY 'Changxin*8';
GRANT ALL PRIVILEGES ON dolphinscheduler.* TO 'ds'@'localhost' IDENTIFIED BY 'Changxin*8';
flush privileges;2、下载
wget https://mirrors.tuna.tsinghua.edu.cn/apache/dolphinscheduler/3.1.4/apache-dolphinscheduler-3.1.4-bin.tar.gz --no-check-certificate 3、部署
3.1、创建目录并赋权
#创建目录
mkdir -p /opt/dolphin
#赋权
chown -R hadoop:hadoop /opt/dolphin
cd /opt/dolphin
tar -zxvf apache-dolphinscheduler-3.1.4-bin.tar.gz -C /opt/dolphin
#修改目录权限,使得部署用户对dolphin-backend目录有操作权限
chown -R hadoop:hadoop apache-dolphinscheduler-3.1.4-bin3.2、修改配置dolphinscheduler_env.sh
cd /opt/software/dolphinscheduler-3.1.4/bin/env
# JAVA_HOME, will use it to start DolphinScheduler server
export JAVA_HOME=/usr/java/jdk1.8.0_201# Database related configuration, set database type, username and password
export DATABASE=${DATABASE:-mysql}
export SPRING_PROFILES_ACTIVE=${DATABASE}
export SPRING_DATASOURCE_URL="jdbc:mysql://192.168.47.40:3306/ds?useUnicode=true&characterEncoding=UTF-8&useSSL=false"
export SPRING_DATASOURCE_USERNAME=dolphin
export SPRING_DATASOURCE_PASSWORD=Dolphin*020# DolphinScheduler server related configuration
export SPRING_CACHE_TYPE=${SPRING_CACHE_TYPE:-none}
export SPRING_JACKSON_TIME_ZONE=${SPRING_JACKSON_TIME_ZONE:-UTC}
export MASTER_FETCH_COMMAND_NUM=${MASTER_FETCH_COMMAND_NUM:-10}# Registry center configuration, determines the type and link of the registry center
export REGISTRY_TYPE=${REGISTRY_TYPE:-zookeeper}
export REGISTRY_ZOOKEEPER_CONNECT_STRING=${REGISTRY_ZOOKEEPER_CONNECT_STRING:-node-04:2181}# Tasks related configurations, need to change the configuration if you use the related tasks.
export HADOOP_HOME=${HADOOP_HOME:-/opt/soft/hadoop}
export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-/opt/soft/hadoop/etc/hadoop}
export SPARK_HOME1=${SPARK_HOME1:-/opt/soft/spark1}
export SPARK_HOME2=${SPARK_HOME2:-/opt/soft/spark2}
export PYTHON_HOME=${PYTHON_HOME:-/opt/soft/python}
export HIVE_HOME=${HIVE_HOME:-/opt/soft/hive}
export FLINK_HOME=${FLINK_HOME:-/opt/soft/flink}
export DATAX_HOME=${DATAX_HOME:-/opt/soft/datax}
export SEATUNNEL_HOME=${SEATUNNEL_HOME:-/opt/soft/seatunnel}
export CHUNJUN_HOME=${CHUNJUN_HOME:-/opt/soft/chunjun}export PATH=$HADOOP_HOME/bin:$SPARK_HOME1/bin:$SPARK_HOME2/bin:$PYTHON_HOME/bin:$JAVA_HOME/bin:$HIVE_HOME/bin:$FLINK_HOME/bin:$DATAX_HOME/bin:$SEATUNNEL_HOME/bin:$CHUNJUN_HOME/bin:$PATH3.3、修改 install_env.sh
cd /opt/software/dolphinscheduler-3.1.4/bin/env
# ---------------------------------------------------------
# INSTALL MACHINE
# ---------------------------------------------------------
# A comma separated list of machine hostname or IP would be installed DolphinScheduler,
# including master, worker, api, alert. If you want to deploy in pseudo-distributed
# mode, just write a pseudo-distributed hostname
# Example for hostnames: ips="ds1,ds2,ds3,ds4,ds5", Example for IPs: ips="192.168.8.1,192.168.8.2,192.168.8.3,192.168.8.4,192.168.8.5"
ips=${ips:-"node-04"}# Port of SSH protocol, default value is 22. For now we only support same port in all `ips` machine
# modify it if you use different ssh port
sshPort=${sshPort:-"22"}# A comma separated list of machine hostname or IP would be installed Master server, it
# must be a subset of configuration `ips`.
# Example for hostnames: masters="ds1,ds2", Example for IPs: masters="192.168.8.1,192.168.8.2"
masters=${masters:-"node-04"}# A comma separated list of machine <hostname>:<workerGroup> or <IP>:<workerGroup>.All hostname or IP must be a
# subset of configuration `ips`, And workerGroup have default value as `default`, but we recommend you declare behind the hosts
# Example for hostnames: workers="ds1:default,ds2:default,ds3:default", Example for IPs: workers="192.168.8.1:default,192.168.8.2:default,192.168.8.3:default"
workers=${workers:-"node-04:default"}# A comma separated list of machine hostname or IP would be installed Alert server, it
# must be a subset of configuration `ips`.
# Example for hostname: alertServer="ds3", Example for IP: alertServer="192.168.8.3"
alertServer=${alertServer:-"node-04"}# A comma separated list of machine hostname or IP would be installed API server, it
# must be a subset of configuration `ips`.
# Example for hostname: apiServers="ds1", Example for IP: apiServers="192.168.8.1"
apiServers=${apiServers:-"node-04"}# The directory to install DolphinScheduler for all machine we config above. It will automatically be created by `install.sh` script if not exists.
# Do not set this configuration same as the current path (pwd). Do not add quotes to it if you using related path.
installPath=${installPath:-"/opt/module/ds-3.1.4"}# The user to deploy DolphinScheduler for all machine we config above. For now user must create by yourself before running `install.sh`
# script. The user needs to have sudo privileges and permissions to operate hdfs. If hdfs is enabled than the root directory needs
# to be created by this user
deployUser=${deployUser:-"hadoop"}# The root of zookeeper, for now DolphinScheduler default registry server is zookeeper.
zkRoot=${zkRoot:-"/dolphinscheduler"}3.4、添加MySQL驱动
cp ../mysql-connector-j-8.0.32.jar master-server/libs/
cp ../mysql-connector-j-8.0.32.jar worker-server/libs/
cp ../mysql-connector-j-8.0.32.jar alert-server/libs/
cp ../mysql-connector-j-8.0.32.jar api-server/libs/
cp ../mysql-connector-j-8.0.32.jar tools/libs3.5、初始化数据库
bash tools/bin/upgrade-schema.sh
3.6、修改JVM参数
vi master-server/bin/start.sh
JAVA_OPTS=${JAVA_OPTS:-"-server -Duser.timezone=${SPRING_JACKSON_TIME_ZONE} -Xms1g -Xmx1g -Xmn512m -XX:+PrintGCDetails -Xloggc:gc.log -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=dump.hprof"}
3.7、一键安装&启动ds
bash ./bin/install.sh
4、登录操作
4.1、登录
http://localhost:12345/dolphinscheduler/ui默认的用户名和密码: admin/dolphinscheduler123
相关文章:

dolphinscheduler-3.1.4
1、相关环境 1.1、创建用户,配置免密 useradd hadoop; echo "Hadoop#149" | passwd --stdin hadoop#配置sudo免密 sed -i $ahadoop ALL(ALL) NOPASSWD: NOPASSWD: ALL /etc/sudoers sed -i s/Defaults requirett/#Defaults requirett/g /etc/su…...

大前端05-用vue轻量级第三方组件库快速创建个画板,可以支持画板、直线、圆形等输入,可以撤回,改变颜色
第三方组件介绍: 1. vue-whiteboard vue-whiteboard 是一个基于Vue.js的轻量级画板组件库。 GitHub仓库: https://github.com/craynic/vue-whiteboard 优势: 轻量级支持基本绘图功能,如画线、圆等支持橡皮擦功能支持清空画布 劣势&…...

ChatGPT使用案例之生成PPT
ChatGPT使用案例之生成PPT ChatGPT使用案例系列我们一直在寻找ChatGPT在哪些方面可以可以帮我们节省时间提高效率,越来越多的用户发掘出了ChatGPT更多实用性的功能,其中一项便是协助用户快速生成PPT。 作为一个基于大型语言处理模型的文字聊天工具,ChatGPT能够帮助用户围绕…...

ChatGPT基础知识系列之模型介绍
ChatGPT基础知识系列之模型介绍 前面我们已经介绍很多ChatGPT的使用案例了,更多案例可以参考我们下面的文章 ChatGPT使用案例之写代码 ChatGPT使用案例之画思维导图 ChatGPT使用案例之自然语言处理 ChatGPT使用案例之操作Excel ChatGPT使用案例之图像生成 ChatGPT使用案…...

ChatGPT助力软件开发
抛开Stack Overflow不谈,开发人员有了一个新的好朋友,它就是ChatGPT。ChatGPT是由人工智能驱动的语言模型,可以理解代码,还可以用自然语言回答问题。有了它,程序员再也不用在无尽的Stack Overflow页面和评论中搜索答案…...

这些关于高压放大器的常识,你知道多少?(二)
高压放大器是一种用于放大高压信号的电子测量仪器,具有高压输出,低噪声,高精度,高稳定性,高可靠性,低功耗,低成本等的优点。关于高压放大器的相关常识,相信还有不少新手工程师不太了…...

使用神经网络中的卷积核生成语谱图
主题思想: 正交基函数, sin,cos 是通过网络训练得到的参数。 使用一维卷积核直接对于原始音频,进行卷积生成语谱图; 使用一维卷积核生成语谱图特征, 不同于以往的方式,正是因为这些正交基函数是通过卷积…...

文章五:Python 网络爬虫实战:使用 Beautiful Soup 和 Requests 抓取网页数据
一、简介 本篇文章将介绍如何使用 Python 编写一个简单的网络爬虫,从网页中提取有用的数据。我们将通过以下几个部分展开本文的内容: 网络爬虫的基本概念Beautiful Soup 和 Requests 库简介选择一个目标网站使用 Requests 获取网页内容使用 Beautiful Soup 解析网页内容提取…...

【大数据之Hadoop】八、MapReduce之序列化
1 概述 序列化: 把内存中的对象,转换成字节序列(或其他数据传输协议),以便于存储到磁盘(持久化)和网络传输。 反序列化: 将收到字节序列(或其他数据传输协议)…...
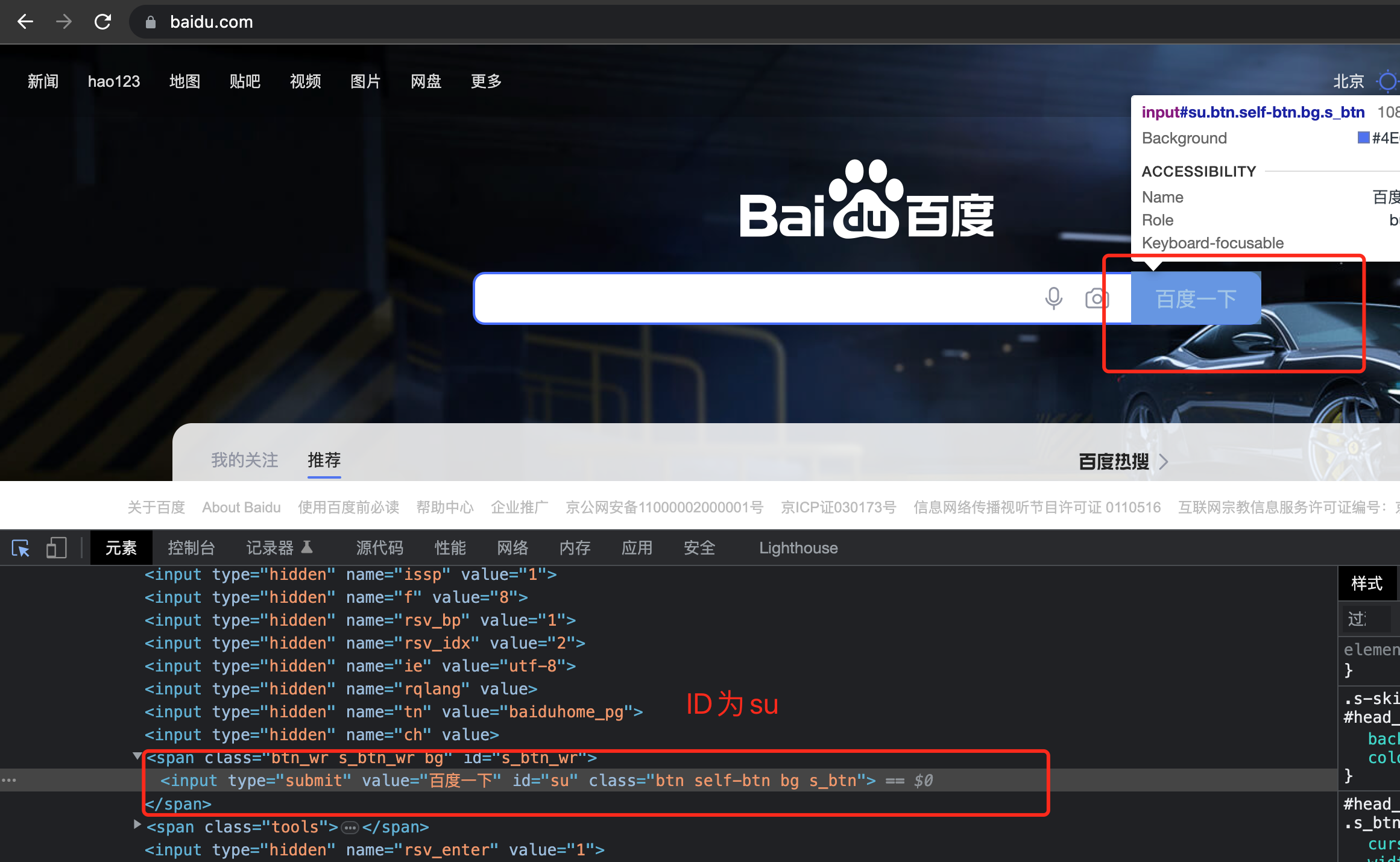
Python网络爬虫之Selenium详解
1、什么是selenium? Selenium是一个用于Web应用程序测试的工具。Selenium 测试直接运行在浏览器中,就像真正的用户在操作一样。支持通过各种driver(FirfoxDriver,IternetExplorerDriver,OperaDriver,ChromeDriver)驱动真实浏览器…...

中睿天下受邀出席电促会第五次会员代表大会
3月21日,中国电力发展促进会(以下简称“电促会”)第五次会员代表大会暨第五届理事会第一次会议在京召开,中睿天下作为网络安全专业委员会会员单位受邀出席。 会议表决通过了第五次会员代表大会工作报告、第四届理事会财务报告、《…...

Chat GPT:软件测试人员的危机?
Chat GPT,作为一个引起科技巨头“红色警报”的人工智能语言模型,短期内便席卷全球,上线仅两个月活跃用户破亿。比尔盖茨更是如此评价“这种AI技术出现的重大历史意义,不亚于互联网和个人电脑的诞生。” 在各个行业备受关注的Chat …...
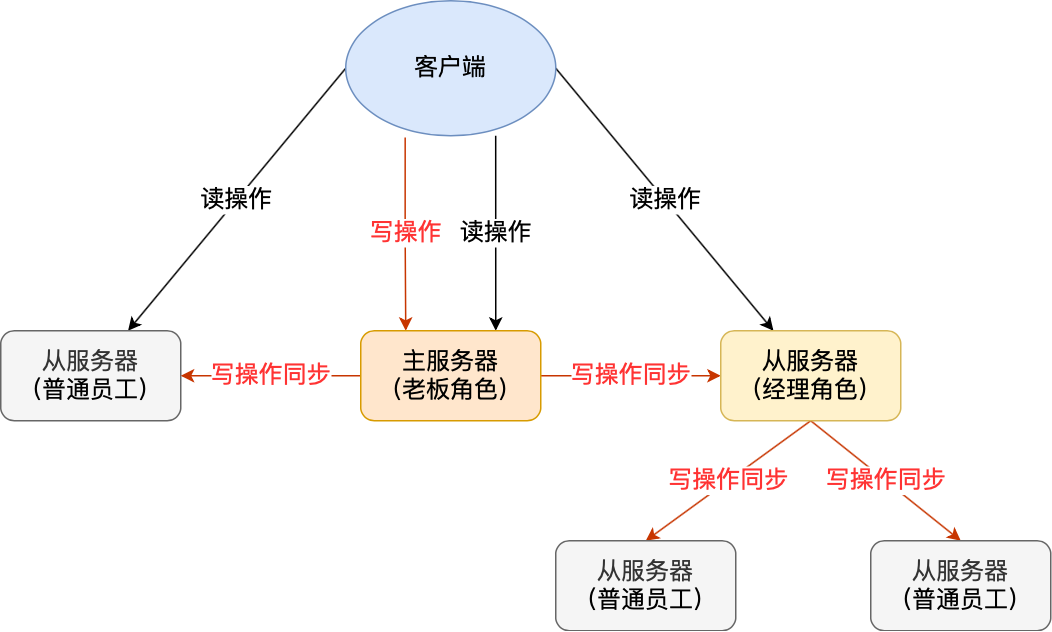
【Redis】高可用:Redis的主从复制是怎么实现的?
【Redis】高可用:主从复制详解 我们知道要避免单点故障,即保证高可用,便需要冗余(副本)方式提供集群服务。而Redis 提供了主从库模式,以保证数据副本的一致,主从库之间采用的是读写分离的方式。…...
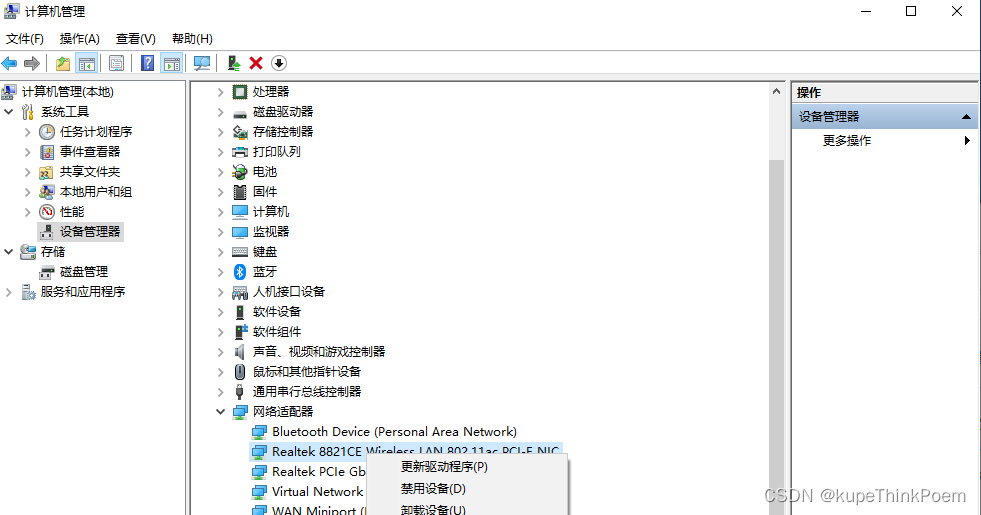
WLAN速度突然变慢
目录 一、问题 二、在设置中重置网络 1. 按下组合键“WinI”打开设置,在设置窗口中点击“网络和Internet”。 2、点击左侧的“状态”,在右侧选择“网络重置”。 3、然后会进入“网络重置”页面,点击“立即重置”后点击“是”等待完成即可…...
GDAL和 Pillow 的互操作)
GDAL python教程基础篇(12)GDAL和 Pillow 的互操作
GDAL和 Pillow GDAL和PIL处理和操作的对象都是栅格图像。 但它们又不一样。 GDAL主要重点放在地理或遥感数据的读写和数据建模以及地理定位和转换, 但是PIL的重点是放在图像本身处理上的。 至于在底层数据处理上,两者都可以用 numpy 转化的二进制作为数…...

快速学习java路线建议
还有2 ,3个月就要毕业了,啥都不会的你是不是很慌呢,是不是想知道怎么样快速学习java呢。嘿嘿!它来了。 首先是java的学习 ,推荐 【尚硅谷】7天搞定Java基础,Java零…...
【MySQL】深入浅出主从复制数据同步原理
【MySQL】深入浅出主从复制数据同步原理 参考资料: 全解MySQL之主从篇:死磕主从复制中数据同步原理与优化 MySQL 日志:undo log、redo log、binlog 有什么用? 文章目录【MySQL】深入浅出主从复制数据同步原理一、主从复制架构概述…...

Redis持久化和高可用
Redis持久化和高可用一、Redis持久化1、Redis持久化的功能2、Redis提供两种方式进行持久化二、RDB持久化1、触发条件2、bgsave执行流程3、启动时加载三、Redis高可用1、什么是高可用2、Redis高可用技术四、AOF持久化(支持秒级写入)1、开启AOF2、执行流程…...
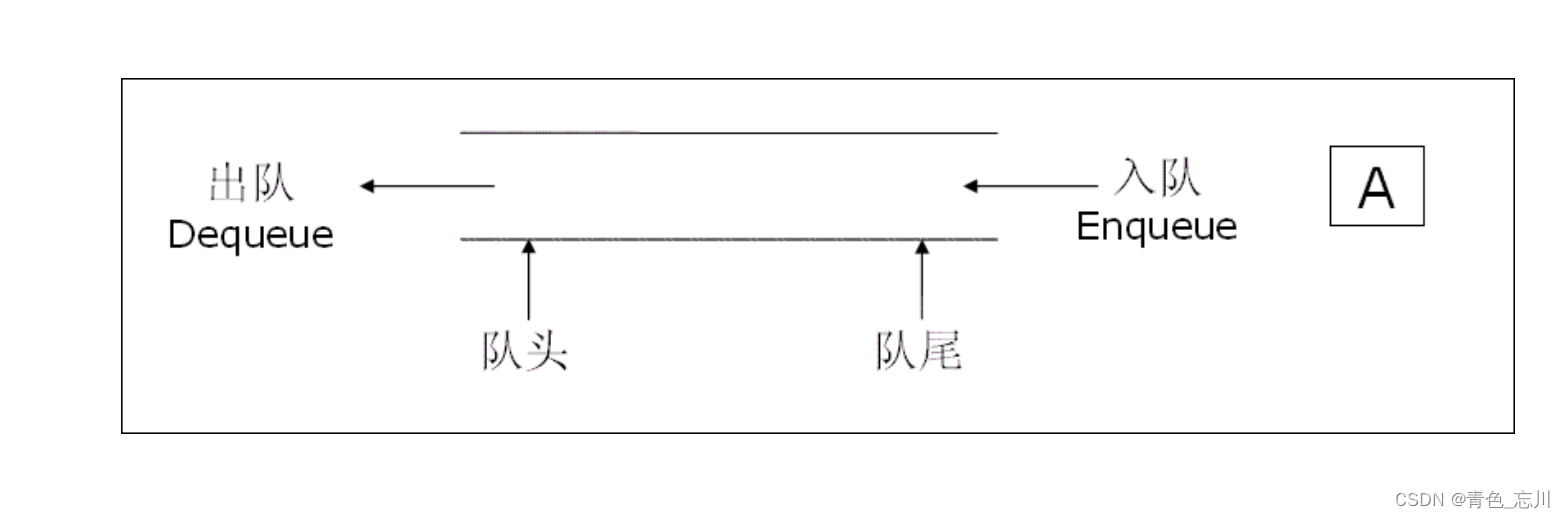
【数据结构】第六站:栈和队列
目录 一、栈 1.栈的概念和结构 2.栈的实现方案 3.栈的具体实现 4.栈的完整代码 5.有效的括号 二、队列 1.队列的概念及结构 2.队列的实现方案 3.队列的实现 4.队列实现的完整代码 一、栈 1.栈的概念和结构 栈:一种特殊的线性表,其只允许在固定…...
python matplotlib 绘制训练曲线 综合示例——平滑处理、图题设置、图例设置、字体大小、线条样式、颜色设置
文章目录1 导出曲线数据2 python简单的 绘制曲线3 Savitzky-Golay 滤波器--平滑曲线4 对y轴数值缩放处理5 设置图题、图例、字体、网格、保存曲线图6 补充6.1 python 曲线平滑处理——方法总结-详解6.2 Tensorboard可视化训练曲线导出数据用Python绘制6.3 PyTorch可视化工具-Te…...

多模态AI应用开发实战:GPT与图像生成的集成架构与优化
1. 项目概述与核心价值最近在折腾AI图像生成和智能对话的整合应用时,发现了一个挺有意思的仓库:bubblesslayyer-cmd/Awesome-GPT-Image-2-OpenAi。这个项目名字乍一看有点长,但拆解一下就能明白它的核心——“Awesome”系列通常代表精选资源集…...

西门子PLC通信必备:手把手教你用SCL编写Modbus RTU CRC校验功能块
西门子PLC通信实战:SCL实现Modbus RTU CRC校验的工程化解决方案 在工业自动化领域,可靠的数据通信如同设备的神经系统。当两台PLC需要通过RS485接口交换温度传感器读数时,Modbus RTU协议因其简洁高效成为首选。但许多工程师在调试阶段都会遇到…...

如何快速提升游戏帧率:OpenSpeedy游戏加速优化终极指南
如何快速提升游戏帧率:OpenSpeedy游戏加速优化终极指南 【免费下载链接】OpenSpeedy 🎮 An open-source game speed modifier. 项目地址: https://gitcode.com/gh_mirrors/op/OpenSpeedy 你是否厌倦了游戏卡顿和掉帧?OpenSpeedy是一款…...

Emacs AI编程助手:ai-code-interface.el深度集成指南
1. 项目概述:一个为Emacs注入AI灵魂的代码接口如果你是一位Emacs的深度用户,同时又对AI辅助编程抱有极大的热情,那么你很可能已经厌倦了在浏览器、终端和编辑器之间反复横跳的割裂体验。tninja/ai-code-interface.el这个项目,正是…...

Path of Building:3个步骤从Build小白到规划大师的完整指南
Path of Building:3个步骤从Build小白到规划大师的完整指南 【免费下载链接】PathOfBuilding Offline build planner for Path of Exile. 项目地址: https://gitcode.com/GitHub_Trending/pa/PathOfBuilding Path of Building作为流放之路玩家最信赖的Build规…...

飞书自动化开发实战:从脚本编写到事件驱动架构设计
1. 项目概述:飞书自动化,从“手动挡”到“自动驾驶”的进化 如果你每天的工作,有超过30%的时间是在飞书里重复着“点击-填写-发送”的枯燥操作,比如手动拉取数据生成日报、定时向群聊推送消息、或者根据特定条件审批流程…...

从零构建专属大语言模型:Self-LLM开源项目全流程实践指南
1. 项目概述与核心价值最近在开源社区里,一个名为datawhalechina/self-llm的项目引起了我的注意。乍一看,这像是一个关于大语言模型(LLM)的仓库,但“self”这个前缀又让人浮想联翩。经过一段时间的深入研究和实践&…...

基于CircuitPython与加速度计的魔法9号球:嵌入式交互项目实践
1. 项目概述:当硬件遇上玄学,用代码打造你的专属“决策神器”在嵌入式开发的世界里,我们常常与传感器、显示屏和逻辑代码打交道,构建着一个个解决实际问题的智能设备。但谁说硬件项目就一定要严肃刻板?今天,…...

基于xclaude-plugin框架的Claude自定义插件开发实战指南
1. 项目概述:Claude插件生态的“瑞士军刀”如果你最近在深度使用Claude,尤其是Claude Desktop应用,那你大概率已经感受到了插件生态的潜力与混乱。官方插件商店虽然方便,但总有些特定需求找不到现成的解决方案,或者找到…...
)
告别闪烁屏!瑞芯微RK3399开发板Debian系统烧写保姆级教程(含DriverAssistant v5.1.1 + AndroidTool v2.69)
RK3399开发板Debian系统烧写实战:从屏幕闪烁到完美显示的终极解决方案 当你在RK3399开发板上成功烧写Debian系统后,最期待的莫过于看到系统稳定运行的画面。然而,不少开发者却遭遇了屏幕闪烁的困扰——这个问题看似简单,背后却隐藏…...