今日指数项目项目集成RabbitMQ与CaffienCatch
今日指数项目项目集成RabbitMQ与CaffienCatch
一. 为什么要集成RabbitMQ
首先CaffeineCatch 是作为一个本地缓存工具 使用CaffeineCatch 能够大大较少I/O开销
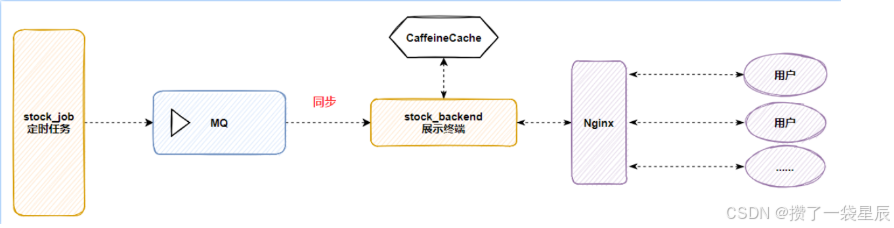
股票项目 主要分为两大工程 --> job工程(负责数据采集) , backend(负责业务处理)
由于股票的实时性也就是说 , 对于股票来说像大盘数据 , 个股数据等都是每分钟进行更新的
而使用传统的采集以及业务处理方式 , 也就是说 数据采集后将数据保存到数据库中 , 然后客户从数据库中反复获取数据
当用户数量增多 , 数据库的I/O开销也会随之增大 , 会导致时效性的降低
所以这里我采用MQ加CaffeineCatch , 在job工程中采集数据后 写入数据库 , 同时通过MQ发送消息给backend工程 重新加载缓存
将数据库中的数据读取到CaffeineCatch 中
二. job工程代码实现
1. 导入mq依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-amqp</artifactId></dependency>
2. 定义配置文件
spring:rabbitmq:host: 114.116.244.165 # rabbitMQ的ip地址port: 5672 # 端口username: jixupassword: 123321virtual-host: /
3. 编写服务端代码
package com.jixu.stock.config;import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.Queue;
import org.springframework.amqp.core.TopicExchange;
import org.springframework.amqp.support.converter.Jackson2JsonMessageConverter;
import org.springframework.amqp.support.converter.MessageConverter;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
public class MqConfig {// 定义大盘消息序列化方式@Beanpublic MessageConverter messageConverter(){return new Jackson2JsonMessageConverter();}// 定义主题交换机@Beanpublic TopicExchange topicExchange(){return new TopicExchange("stockExchange",true,false);}// 定义大盘队列@Beanpublic Queue stockMarketQueue(){return new Queue("marketQueue",true);}@Bean// 绑定大盘信息public Binding bindingStockeMarket(){// with( Routingkey 参数 --> 匹配的队列名称 )return BindingBuilder.bind(stockMarketQueue()).to(topicExchange()).with("inner.market");}
}
4. 定义客户端
package com.jixu.stock.config;import lombok.extern.slf4j.Slf4j;
import org.joda.time.DateTime;
import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.Queue;
import org.springframework.amqp.core.TopicExchange;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.amqp.support.converter.Jackson2JsonMessageConverter;
import org.springframework.amqp.support.converter.MessageConverter;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import java.util.Date;@Configuration
@Slf4j
public class MqConfig {// 定义大盘消息序列化方式@Beanpublic MessageConverter messageConverter(){return new Jackson2JsonMessageConverter();}// 客户端接受信息@RabbitListener(queues = "marketQueue")public void stockMarketListener(Date date){long diffTime= DateTime.now().getMillis()-new DateTime(date).getMillis();//超过一分钟告警if (diffTime>60000) {log.error("采集国内大盘时间点:{},同步超时:{}ms",new DateTime(date).toString("yyyy-MM-dd HH:mm:ss"),diffTime);}}
}
3. 修改业务层代码
在数据插入成功后发送消息给MQ
log.info("当前时间点{} , 数据插入成功", DateTime.now().toString("yyyy-MM-dd HH-mm-ss"));
rabbitTemplate.convertAndSend("stockExchange","inner.market",new Date());
三. backend工程代码实现
首先在实现业务逻辑之前需要导入相关依赖 , 以及配置MQ和CaffineCache
1. 配置MQ配置类
package com.jixu.stock.config;import lombok.extern.slf4j.Slf4j;
import org.joda.time.DateTime;
import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.Queue;
import org.springframework.amqp.core.TopicExchange;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.amqp.support.converter.Jackson2JsonMessageConverter;
import org.springframework.amqp.support.converter.MessageConverter;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import java.util.Date;@Configuration
@Slf4j
public class MqConfig {// 定义大盘消息序列化方式@Beanpublic MessageConverter messageConverter(){return new Jackson2JsonMessageConverter();}}
2. 配置CaffineCache配置类
/*** 配置CaffienCatch*/@Beanpublic Cache<String,Object> caffeineCache(){Cache<String, Object> cache = Caffeine.newBuilder().maximumSize(200)//设置缓存数量上限
// .expireAfterAccess(1, TimeUnit.SECONDS)//访问1秒后删除
// .expireAfterWrite(1,TimeUnit.SECONDS)//写入1秒后删除.initialCapacity(100)// 初始的缓存空间大小.recordStats()//开启统计.build();return cache;}
3. 创建客户端类接收信息
package com.jixu.stock.mq;import com.jixu.stock.service.StockService;
import lombok.extern.slf4j.Slf4j;
import org.joda.time.DateTime;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import com.github.benmanes.caffeine.cache.Cache;
import java.util.Date;/*** @program: stock_parent* @description:* @author: jixu* @create: 2024-10-01 12:45**/
@Component
@Slf4j
public class StockMarketMQ {@Autowiredprivate Cache caffeineCache;@Autowiredprivate StockService service;// 客户端接受信息@RabbitListener(queues = "marketQueue")public void stockMarketListener(Date date){long diffTime= DateTime.now().getMillis()-new DateTime(date).getMillis();//超过一分钟告警if (diffTime>60000) {log.error("采集国内大盘时间点:{},同步超时:{}ms",new DateTime(date).toString("yyyy-MM-dd HH:mm:ss"),diffTime);}}
}在信息接受之后需要对业务层代码进行修改 --> 实现CaffineCache缓存
这里我们使用CaffineCache.get的方法 , 其中会传入两个参数 , 分别是要从CaffineCache中查询的数据的key ,以及如果key不存在使用的补救方法(从数据库中查询)
4. 完善业务代码
/*** 实现股票大盘数据查询* @return*/@Overridepublic R<ArrayList<InnerMarketDomain>> getInnerMarketDomain() {R<ArrayList<InnerMarketDomain>> msg = (R<ArrayList<InnerMarketDomain>>) caffeineCache.get("stockMarketMsg" , key -> {// 1. 获取最新时间数据Date curTime = DateTimeUtil.getLastDate4Stock(DateTime.now()).toDate();// 创建mock数据curTime = DateTime.parse("2022-01-02 09:32:00", DateTimeFormat.forPattern("yyyy-MM-dd HH:mm:ss")).toDate();// 2. 获取股票代码ArrayList<String> marketInfo = stockInfoConfig.getInner();// 3. dao层查询数据ArrayList<InnerMarketDomain> data = stockMarketIndexInfoMapper.getMarketInfo(curTime , marketInfo);return R.ok(data);});return msg;}
5. 完善StockMarketMQ类刷新数据
// 清除caffeineCache中的缓存
caffeineCache.invalidate("stockMarketMsg");
// 调用service重新获取
service.getInnerMarketDomain();
相关文章:
今日指数项目项目集成RabbitMQ与CaffienCatch
今日指数项目项目集成RabbitMQ与CaffienCatch 一. 为什么要集成RabbitMQ 首先CaffeineCatch 是作为一个本地缓存工具 使用CaffeineCatch 能够大大较少I/O开销 股票项目 主要分为两大工程 --> job工程(负责数据采集) , backend(负责业务处理) 由于股票的实时性也就是说 ,…...

C0005.Clion中移动ui文件到新目录后,报错问题的解决
报错问题如下 AutoUic error ------------- "SRC:/confirmwizardpage.cpp" includes the uic file "ui_confirmwizardpage.h", but the user interface file "confirmwizardpage.ui" could not be found in the following directories"SRC…...
基于STM32的智能家居灯光控制系统设计
引言 本项目将使用STM32微控制器实现一个智能家居灯光控制系统,能够通过按键、遥控器或无线模块远程控制家庭照明。该项目展示了如何结合STM32的外设功能,实现对灯光的智能化控制,提升家居生活的便利性和节能效果。 环境准备 1. 硬件设备 …...

06.useEffect
在 React 开发中,正确使用 useEffect 钩子对于优化组件性能至关重要。一个常见但容易被忽视的性能问题是在依赖数组中使用对象作为依赖项。这可能导致不必要的效果重新执行,从而影响应用性能。通过优先使用原始值(如字符串、数字)作为依赖项,我们可以显著提高组件的效率。…...

【设计模式-中介者模式】
定义 中介者模式(Mediator Pattern)是一种行为设计模式,通过引入一个中介者对象,来降低多个对象之间的直接交互,从而减少它们之间的耦合度。中介者充当不同对象之间的协调者,使得对象之间的通信变得简单且…...

树和二叉树知识点大全及相关题目练习【数据结构】
树和二叉树 要注意树和二叉树是两个完全不同的结构、概念,它们之间不存在包含之类的关系 树的定义 树(Tree)是n(n≥0)个结点的有限集,它或为空树(n 0);或为非空树&a…...

ajax的原理,使用场景以及如何实现
AJAX 原理 AJAX(Asynchronous JavaScript and XML)是一种在网页中实现异步通信的技术,允许网页在不重新加载整个页面的情况下与服务器交换数据。这使得网页应用可以更加响应式和动态,提升用户体验。 AJAX 的核心原理是在后台通过…...

lock_guard和unique_lock学习总结
1.std::lock_guard std::lock_guard其实就是简单的RAII(Resource Acquisition Is Initialization)封装,资源获取即初始化。在构造函数中进行加锁,析构函数中进行解锁,这样可以保证函数退出时,锁一定被释放…...
数据挖掘-padans初步使用
目录标题 Jupyter Notebook安装启动 Pandas快速入门查看数据验证数据建立索引数据选取⚠️注意:排序分组聚合数据转换增加列绘图line 或 **(默认):绘制折线图。bar:绘制条形图。barh:绘制水平条形图。hist&…...
小阿轩yx-案例:项目发布基础
小阿轩yx-案例:项目发布基础 前言 随着软件开发需求及复杂度的不断提高,团队开发成员之间如何更好地协同工作以确保软件开发的质量已经慢慢成为开发过程中不可回避的问题。Jenkins 自动化部署可以解决集成、测试、部署等重复性的工作,工具集…...
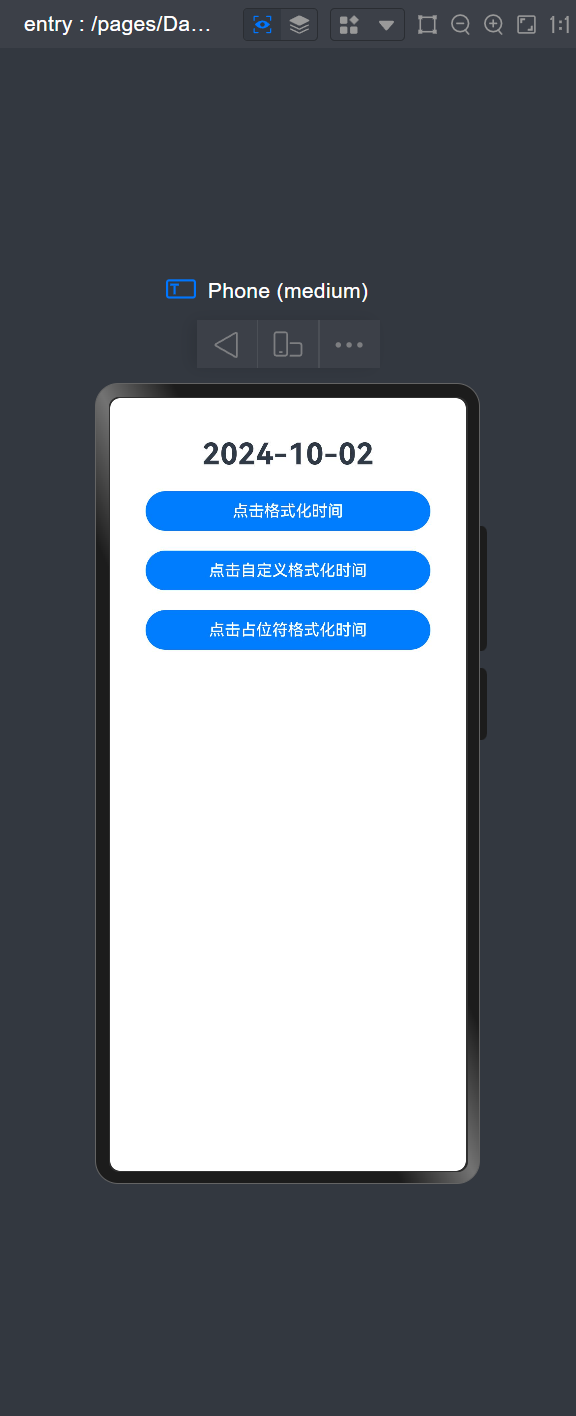
【HarmonyOS】时间处理Dayjs
背景 在项目中经常会使用要时间的格式转换,比如数据库返回一个Date数据,你需要转成2024-10-2的格式,鸿蒙的原生SDK中是没有办法实现的,因此,在这里介绍第三方封装好并且成熟使用的库Dayjs。 安装 切换到Entry文件夹下…...

论React Native 和 UniApp 的区别
1. 开发语言与框架 React Native: 使用 JavaScript 和 React 框架进行开发。采用了 React 的组件化开发模式,适合熟悉 React 生态的开发者。使用 JavaScript 编写的代码会通过 React Native 框架桥接到原生代码(如 iOS 的 Swift 或 Android 的 Java/Kotl…...
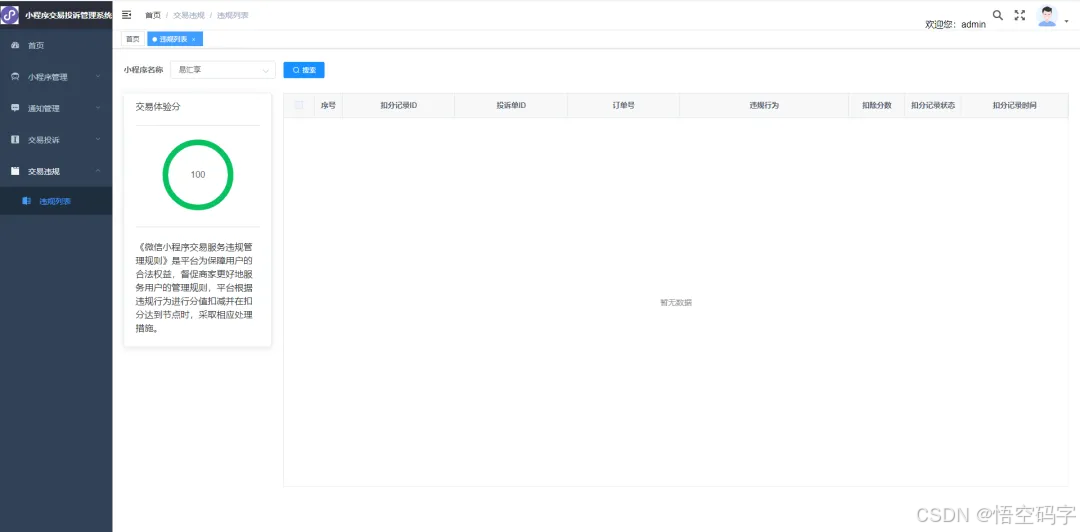
微信小程序处理交易投诉管理,支持多小程序
大家好,我是小悟 1、问题背景 玩过微信小程序生态的,或许就有这种感受,如果收到投诉单,不会及时通知到手机端,而是每天早上10:00向小程序的管理员及运营者推送通知。通知内容为截至前一天24时该小程序账号内待处理的交…...
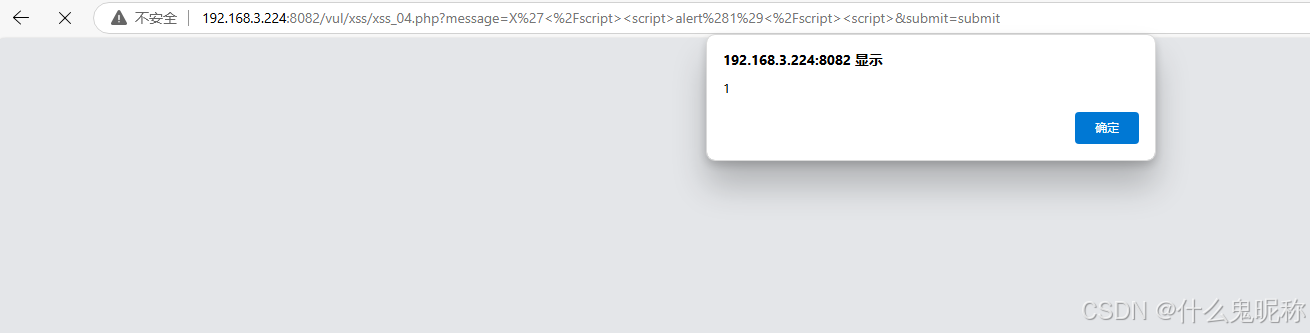
Pikachu-xss防范措施 - href输出 js输出
总体原则: 输入做过滤,输出做转义 过滤:根据业务需要进行过滤,如:输入点要求输入手机号,则只允许输入手机号格式的数字; 转义:所有输出到前端的数据,都根据输出点进行转…...
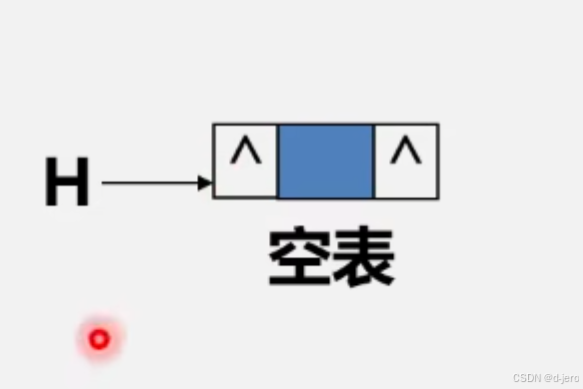
数据结构双向链表和循环链表
目录 一、循环链表二、双向链表三、循环双向链表 一、循环链表 循环链表就是首尾相接的的链表,就是尾节点的指针域指向头节点使整个链表形成一个循环,这就弥补了以前单链表无法在后面某个节点找到前面的节点,可以从任意一个节点找到目标节点…...

go基础面试题汇总第一弹
init函数是什么时候执行的? init的函数的作用是什么? 通常作为程序执行前包的初始化,例如mysql redis 等中间件的初始化 init函数的执行顺序是怎样的? 分不同情况来回答: 在同一个go文件里面如果有多个init方法,它们…...

Redis 实现分布式锁时需要考虑的问题
引言 分布式系统中的多个节点经常需要对共享资源进行并发访问,若没有有效的协调机制,可能会导致数据竞争、资源冲突等问题。分布式锁应运而生,它是一种保证在分布式环境中多个节点可以安全地访问共享资源的机制。而在Redis中,使用…...

百年极限论一直存在百年糊涂话:有正数小于所有正数
百年极限论一直存在百年糊涂话:有正数小于所有(任何、任意)正数。 “对于每个大于0的ε[ε>0],都有非0距离数小于ε”显然是病句:有正数小于每个(所有)正数ε。其中任意(任何&am…...
红日靶场1学习笔记
一、准备工作 1、靶场搭建 靶场地址 靶场描述 靶场拓扑图 其他相关靶场搭建详情见靶场地址相关说明 2、靶场相关主机信息 后续打靶场的过程中,如果不是短时间内完成,可能ip会有变化 主机ip密码角色win7192.168.122.131hongrisec2019!边界服务器win…...

【C++篇】揭开 C++ STL list 容器的神秘面纱:从底层设计到高效应用的全景解析(附源码)
文章目录 从零实现 list 容器:细粒度剖析与代码实现前言1. list 的核心数据结构1.1节点结构分析: 2. 迭代器设计与实现2.1 为什么 list 需要迭代器?2.2 实现一个简单的迭代器2.2.1 迭代器代码实现:2.2.2 解释: 2.3 测试…...

终于有人说清楚经营分析会怎么开了!一篇看懂经营分析会全流程
各位老板有没有想过,为什么你的经营分析会越开越多?有的企业月月开、周周开,甚至恨不得天天开。会一多,人就麻木了,翻来覆去讲同样的数据、追同样的问题,真正该花时间去解决的业务卡点,反而没人…...

Windows 环境 OpenClaw 2.7.5 一键安装避坑指南
OpenClaw 一键安装包|可视化部署,简化环境配置流程✨适配系统:Windows10/11 64 位当前版本:v2.7.5(虾壳云版)✨核心优势:全程可视化操作,不用命令行、不用手动配置 Python/Node.js&a…...

【Prometheus监控Linux系统】
提示:本文原创作品,良心制作,干货为主,简洁清晰,一看就会 文章目录前言一、环境介绍二、安装node_exporter2.1 安装docker2.2 安装docker-compose2.3 安装node_exporter三、修改prometheus配置3.1 修改prometheus.yml3…...

dy app抓包分析
声明 本文章中所有内容仅供学习交流使用,不用于其他任何目的,抓包内容、敏感网址、数据接口等均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关!抓包展示总结1.出于安全考虑,本章未提供…...

在 Hermes Agent 项目中集成 Taotoken 实现自定义模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在 Hermes Agent 项目中集成 Taotoken 实现自定义模型调用 对于正在使用 Hermes Agent 框架构建智能体应用的开发者而言࿰…...

固定翼无人机遥控器对频与天线摆放:一个细节没做好,你的飞机可能就‘失联’了
固定翼无人机遥控器对频与天线摆放:一个细节没做好,你的飞机可能就‘失联’了 第一次操控固定翼无人机升空的时刻总是令人兴奋的,但在这之前,确保遥控系统可靠工作是关键中的关键。许多新手飞手往往将注意力集中在机身组装和动力调…...

解锁SD-PPP:将AI绘画能力无缝融入Photoshop工作流
解锁SD-PPP:将AI绘画能力无缝融入Photoshop工作流 【免费下载链接】sd-ppp A Photoshop AI plugin 项目地址: https://gitcode.com/gh_mirrors/sd/sd-ppp 你是否曾经在Photoshop中创作时,突然需要一个AI生成的元素来完善设计,却不得不…...

CANN/asc-devkit SIMT fmodf函数
fmodf 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/cann…...

如何快速上手Orbit:新手入门10个技巧 [特殊字符]
如何快速上手Orbit:新手入门10个技巧 🚀 【免费下载链接】orbit Experimental spaced repetition platform for exploring ideas in memory augmentation and programmable attention 项目地址: https://gitcode.com/gh_mirrors/orbit1/orbit Orb…...

ncmdumpGUI终极指南:3步轻松解锁网易云音乐NCM加密文件
ncmdumpGUI终极指南:3步轻松解锁网易云音乐NCM加密文件 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经遇到过这样的烦恼?在…...