Redis: 集群架构,优缺点和数据分区方式和算法
集群
- 集群指的就是一组计算机作为一个整体向用户提供一组网络资源
- 我就举一个简单的例子,比如百度,在北京和你在上海访问的百度是同一个服务器吗?
- 答案肯定是不是的,每一个应用可以部署在不同的地方,但是我们提供的服务是相同的
- 也就是说我每一个节点上跑的都是相同的业务,但是我对用户而言是透明的
- 我要保证我这个服务不出故障高可用,现在我全球分布了很多台机器
- 每一台机器上跑的都是百度的业务,对用户而言,你在北京
- 我就给你分发到离北京最近的一个服务器上,在上海就分发到离上海最近的一个服务器上
- 这其中的每一个计算服务器就是集群中的节点
- 集群还提供了以下关键的一些特性
- 1 )可扩展性
- 集群的性能,不限于单一的服务实体
- 新的服务实体可以动态的加入到集群,从而增强了集群的性能
- 2 )高可用性
- 把这些节点服务器发生故障的时候,这台服务器上所运行的应用程序
- 可以在另一台服务器上被自动接管,消除单点故障,增强了数据的可用性可达性可靠性
- 3 )负载均衡
- 负载均衡,能把这些任务比较均匀的分散到集群环境下的这些服务器上
- 在全球有很多服务器,但是我请求的时候,把这些请求全部都集中的分发到一个机器上
- 那我搭集群的意义何在呢?所以说它还有负载均衡的特性
- 4 )错误恢复
- 就是我们集群中的某一台服务器,由于故障或者说无法使用了
- 我们要把它的资源对应的这些应用程序要转移到一个可用的节点上
- 这个转移的过程,让它继续可用,就把它叫做错误恢复
- 1 )可扩展性
- 分布式和集群又有什么区别和联系呢?
- 1 )分布式指的就是把不同的业务分布在不同的地方去做,就是分开部署
- 2 )我们的集群,它是将几台服务器集中在一起,实现同一业务
- 这个集中在一起,不是说就部署在一个地方
- 比如说,我在北京,我在上海,无所谓的我布在哪都行
- 但是我们实现的是同一业务,这就是集群
- 3 )分布式的每一个节点都可以做集群,而集群并不一定就是分布式
- 比如我们有一个商城业务的网站,如果我把其中的每一个服务,因为用到微服务开发
- 其中的每一个服务都是可以单独部署,单独开发的
- 我把每一个服务分别部署在不同的服务器上,这就叫分布式
- 我们每一个服务都有自己的责任和职责
- 不同的服务部署在不同的服务器上,一起完成了一个大的功能
- 就是我们对外提供的是一个完整的功能,但是我们是要分开独立开发独立部署的
- 其实这个就是分布式
- 再比如,我们拿到其中的一个服务,比如说授权认证,它可以做集群
- 因为一开始它是单一的节点,如果你想要它高可用,那就来3,5, 7台
- 所以说,分布式的每一个节点都是可以做集群的,但集群不一定就是分布式
- 即使不用这种微服务的架构,我就用传统的单体应用都写在一个服务里面没有拆分
- 这样的单体应用想让其高可用,就来上多个机器,这个只能是集群,而非分布式
- 集群主要分为三大类
- HA: 高可用集群(High Availability Cluster),Redis Cluster 用的就是这种模式
- 高可用集群,其实指的是以减少服务中断时间为目的的服务器集群技术
- 通过保护用户的业务程序,对外不间断的提供服务
- 把因为一些软件、硬件人为造成的故障,对业务影响降到最低,这就是高可用性集群
- LBC:负载均衡集群/负载均衡系统 (Load Balance Cluster)
- 这种集群它所有的节点都是处于活动状态的, 它们分摊系统的工作负载
- 一般像我们的web服务器集群, 数据库集群和我们的应用服务器集群都属于这种LBC
- HPC: 科学计算集群 (High Performance computing Cluster) / 高性能计算集群 (High Performance Computing)
- 高性能计算集群, 它采用的是将计算任务分配到集群不同的计算节点上提高计算能力
- 主要应用在科学计算领域
- HA: 高可用集群(High Availability Cluster),Redis Cluster 用的就是这种模式
- 一般开发应用就是HA 和 LBC用的比较多。
- HA 就是提高它的一个高可用
- LBC 就是像我们的应用服务器, 我们倾向于 Nginx结合一些硬件来实现这种负载均算集群
Redis 集群架构
- 我们先来看下不同问题的应对策略
- 并发量大了:通过主从复制解决
- 主从稳定性:通过哨兵解决
- 单节点存储能力:通过集群Cluster解决
1 ) 并发量大了:通过主从复制解决
- 现在假设上千万,上亿的用户同时在访问 Redis, 其 QPS 达到了10w+
- 这些请求过来,单机 Redis 很快就会挂掉,现在系统的瓶颈出现在 Redis 单机的问题上
- 此时,通过主从复制解决这个问题,实现系统的高并发
- 这就是并发量大了,主从复制解决
- 主从模式中主节点宕机之后,从节点是可以作为主节点顶上来继续提供服务的
- 但是我们需要修改应用方的主节点地址,还需要命令所有的从节点去复制新的主节点
- 这一系列的过程都是需要要人工完成,比较复杂,于是在Redis@2.8版本开始引入了哨兵
2 ) 主从稳定性:通过哨兵解决
- 在主从复制的基础上,哨兵实现了自动化故障恢复
- 哨兵模式中单个节点的写能力,存储能力还是受到单机的限制的
- 而且动态扩容是相对而言,困难复杂,于是 Redis@3.0 版本推出 Redis Cluster 集群模式
3 ) 单节点存储能力:通过集群Cluster解决
- 集群有效解决 Redis 分布式方面的需求,
- Redis Cluster 模式还具有高可用高扩展性分布式容错等特性

- 通过上图,可以看到,Redis Cluster集群的架构采用的是无中心结构
- 就是我们经常所说的去中心化,每个节点都可以保存数据和整个集群的状态
- 而且每个节点都和其他的节连连接,这些虚线和其他的节点连接起来了
- 数据保存在主节点中,从节点只是主节点的一个复制,就是容灾备份使用的
- 集群一般是由多个节点组成,官方建议至少六个才能保证组成完整的高可用集群
- 其中三个是主节点,三个是从节点
- 三个主节点会分配插槽,它们分配插槽之后,每一个key,比如说 set username
- 这个key会经过哈希运算,之后,会对应到一个插槽的索引上,然后插到这个插槽里边
- 比如说,M1(0-3000), M2(3000-6000), M3(6000-9000),而实际上它的插槽是16384个
- 使用上面假设的例子,set username 运算完成后,他是 5000多,它会被插入到 M2
- 你的一个key的运算会对应到一个索引的插槽上
- 所如说,三个主节点会分配槽来存储数据处理客户端的命令请求
- 而从节点是主节点的一个复制,就是在主节点故障之后,顶替主节点的一个作用
- 如果按照一主两从的要求,最终是 9个节点(3主6从)
- 总结一下
- 读请求可以分配给所有节点写请求,可以分配给 master
- 数据同步再从master到slave节点
集群和主从模式
- 主从模式其实就是为了保证数据高可用性而存在的
- 而集群其实准确的讲,它没有上图的右边Slave节点,M1~M3 才是集群分片
- 但是我们要保证它的高可用性,就需要主从容灾备份
- Redis Cluster 为了保证数据的高可用性,加入了主从模式
- 一个主节点对应一个或多个从节点,主节点提供数据的存取,从节点复制主节点数据备份
- 当这个主节点挂掉后,就会通过主节点的从节点选取一个来充当新的主节点保证集群的高可用
- 在上图例子中,有3个主节点,若其中一个挂掉了,如果它还没有从节点,那整个环境就没法用了
- 因为每个主节点都提供这个中间槽的功能,比如上面的 username,对应主节点挂掉了,怎么去获取这个槽对应的值
- 所以说我们在创建集群的时候,一定要为每个主节点都添加对应的从节点
集群架构的优缺点
1 )优点
- 去中心化
- 可扩展性
- 是数据是按照槽存储分配在多个节点上的
- 节点间的数据共享,节点可以动态的添加或删除,可以动态的调整
- 高可用性
- 部分节点不能用的时候,集群仍然是可用的
- 因为我们可以通过增加slave从节点做备份来充当数据的副本
- 自动故障转移
- 然后它出了故障之后,从节点可以顶上来,就是自动故障转移
- 节点之间通过留言协议交换状态信息
- 再采用投票机制完成 slave从节点到master的角色的升级
2 )缺点
- 任何事物都是一把双刃剑
- 数据通过异步复制,没有办法保证数据强一致性,但保证最终一致性
- 集群环境的搭建复杂
- 在之前的版本要用ruby脚本去创建集群
- 目前最新的模式去创建集群就简单了很多
数据分区
- Redis 集群模式是把数据分别存储在多个节点上的
- 因为随着请求量和数据量的增加,一台机器满足不了我们的需求了
- 主从模式主节点仍然有写的压力问题和存储压力的问题,所以我们需要把数据和请求分散到多台机器
- 这时候需要引入分布式存储,那分布式存储有哪些特性
- 1 )增强可用性
- 如果数据库的某个节点出现了故障。
- 在其他节点的数据仍然是可用的,增强了可用性
- 不会说一个节点出了问题,可能就是其他节点全部都用不了
- 只是说当前这个节点数据可能暂时性的不可用了,其他节点的数据仍然可用
- 2 )维护方便
- 这个节点出现故障了,我们需要修复,那也只修复该节点即可
- 3 )均衡IO
- 可以把不同的请求映射到各节点以平衡IO
- 改善整个系统的性能
- 4 )改善了查询性能
- 对分区对象的查询,可以仅搜索自己关心的节点,提高检索速度
- 1 )增强可用性
- 分布式存储首先要解决的就是数据集是如何按照什么样的分区规则映射到多个节点上的
- 即把数据集划分到多个节点上,每个节点负责整体数据的一个子集
常见数据分区算法
1 )范围分区
- 范围分区在关系型数据库,用的比较多
- 它指的就是把数据基于范围映射到每一个分区
- 这个范围是你自己在创建分区时候指定的这个分区键决定的
- 分区键也经常会采用以日期的方式来做分区
- 它的优点就是同一范围内的范围查询,不需要跨节点提升了查询速度
- 应用场景就是 mysql oracle 关系数据库居多
2 )哈希分区
2.1 节点取余分区
- 根据 hash(object) % N
- object是 key, % 是取余,N是节点数
- 就是对一个key取余,比如说现在我们有三台机器,那么对这个key做一个哈希处理运算
- 然后对3取于取余的余数是多少?我们就放到一二三对应的那个节点上去
- 优点是实现起来非常简单:
- 你有几个节点,哈希运算完就对这个节点取余就行了。
- 然后把这个值就分配到这个节点上去了
- 缺点
- 如果扩容/收缩节点的时候,你做的这个数据迁移量会很大
- 大概得有百分之七八十这样子, 举一个最简单的例子
- 比如说, 这个key, 哈希运算完之后,它是10; 10取余三, 余数是1
- 我这里有三个节点,它就放到1那个节点上去了
- 现在我增加了一个节点,现在4个节点了,刚才10对3取余,余数是1
- 现在你增加一个节点之后,就相当于分配这个key
- 那 10 再对4 取余,它就变成2了, 这个key就要从第一个节点上转移到第二个节点上
- 类似这种,需要做的这个数据迁移量会非常的大
- 建议就是翻倍扩容相对减少迁移量,但仍旧很大,基本上在百分之四五十的迁移量
- 这种算法现在用的比较少了,它的出现就是因为一致性哈希、虚拟槽这种概念还没有提出来
- 就像我们的 Redis 一样,它随着发展它刚开始肯定是单节点嘛
2.2 一致性哈希分区

- 它的实现思路就是为系统中的每个节点分配一个token
- 这个 token 的范围是在就是 0 ~ 2 32 2^{32} 232 区间
- 这些token会构成一个哈希环,数据读写执行节点查询操作的时候
- 就是先根据key的计算,计算到一个哈希值,然后顺时针找到第一个大于等于该哈希的token节点
- 优点
- 这种方式相比我们刚才节点取余最大的好处,就是
- 在加入和删除节点的时候,它只会影响相邻的节点
- 缺点
- 你使用少量节点的时候,节点的变化还是大范围的影响
- 所以说它是不适合少量数据节点的分布式方案
- 它更多的是那种规模比较大的这种数据节点的一种分布式的缓存方案
- 应用场景就是 Memcached 居多,基本上就是用这个一致性哈希来分区的
2.3 虚拟槽分区
- 虚拟槽分区,你可以理解为就是在一致性哈希分区的基础上加入了虚拟槽的概念
- 它把这个分割的力度变得更小了,让每一个节点持有固定的槽
- 当你去添加一个节点的时候,它不会对这里边的每一个重新去分配
- 你只需要给它的分配指定的槽,这里边的这些槽,我们可以选择自动的分配,或者说手动的去分配
- 你可以自己去进行分配管理,影响可以说是非常非常的小,这就是Redis Cluster 用的虚拟槽分区
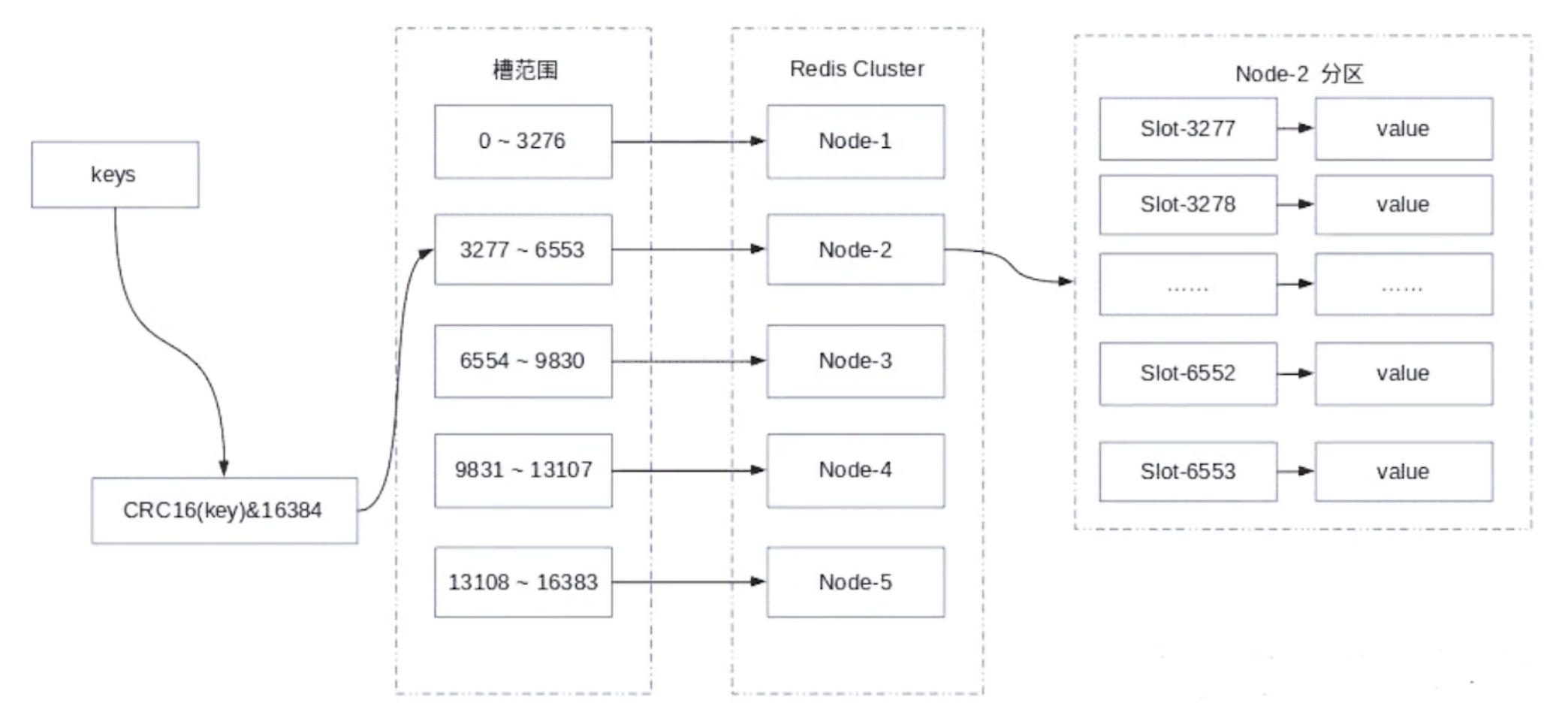
- 现在我们的一个key经过哈希运算之后,对 16384取余
- CRC16 这是它内部的一个执行的一个对key处理的一个源码里边的函数
- 取余以后,这里就会有我们的槽的范围,这里大概有5个节点如上图
- 我对这个key, 比如说username做完处理之后,它映射到这个区间了,比如节点2
- 上面是节点2的一个详细图,我现在,新增一个节点,我新增一个节点之后
- 可以把原先一个节点的部分范围取出来重新分配给另一个节点,它的影响极小
- 这是关于虚拟槽分区的一个方式,它也是 Redis Cluster 用的方式
- 它的缺点就是
- 我们的每一个节点都要去存储nodes和槽对应的信息
- 因为我们知道客户端来访问的时候,肯定是不是说指定访问到某一个节点上
- 假如说, 我访问到一号节点上,而访问的 key 实际上是在三号节点里边
- 它内部会给我们去做一些转向的处理, 它会存储节点和槽对应的信息
相关文章:
Redis: 集群架构,优缺点和数据分区方式和算法
集群 集群指的就是一组计算机作为一个整体向用户提供一组网络资源 我就举一个简单的例子,比如百度,在北京和你在上海访问的百度是同一个服务器吗?答案肯定是不是的,每一个应用可以部署在不同的地方,但是我们提供的服务…...

负载均衡可以在网络模型的哪一层?
一、网络模型概述 网络模型是用于描述网络通信过程和网络服务的抽象框架。最常见的网络模型有两种:OSI(开放式系统互联)模型和TCP/IP模型。 OSI模型 OSI(Open Systems Interconnection)模型是由国际标准化组织&…...

YOLOv11改进 | 上采样篇 | YOLOv11引入CARAFE上采样
1. DySample介绍 1.1 摘要:特征上采样是许多现代卷积网络体系结构(如特征金字塔)中的关键操作。它的设计对于密集预测任务(如对象检测和语义/实例分割)至关重要。在本文中,我们提出了一个通用、轻量级、高效的特征重组算子CARAFE来实现这一目标.CARAFE有几个吸引人的特性…...

【Linux运维】grep命令粗浅学习
文章目录 1 背景介绍1.1 为什么要学习grep?1.2 grep是什么?1.3 grep可以做什么? 2 grep基本语法2.1 命令格式2.2 “PATTERN”部分中的正则表达式语法学习2.3 grep命令参数学习 3 典型案例3.1 匹配非空行,过滤纯空行3.2 匹配IPv4地…...

【Godot4.3】匀速和匀变速直线运动粒子
概述 本篇论述,如何用加速度在Godot中控制粒子运动。 匀速和匀变速直线运动的统一 以下是匀变速运动的速度和位移公式: v t v 0 a t x t v 0 t 1 2 a t 2 v_tv_0 at \\ x_tv_0t \frac{1}{2}at^2 vtv0atxtv0t21at2 当a 0 时…...
基于Hive和Hadoop的用电量分析系统
本项目是一个基于大数据技术的用电量分析系统,旨在为用户提供全面的电力消耗信息和深入的用电量分析。系统采用 Hadoop 平台进行大规模数据存储和处理,利用 MapReduce 进行数据分析和处理,通过 Sqoop 实现数据的导入导出,以 Spark…...

一个简单的摄像头应用程序4
我们进一步完善了这个app01.py,我们优化了界面使其更人性化,下面介绍中包含了原有的功能及新增的功能: 创建和管理文件夹: create_folder 函数用于创建保存照片和视频的文件夹。 get_next_file_number 函数用于获取文件夹中下一个可用的文件编号。 图像处理: pil_to_cv 函…...

SpringBoot使用EasyPoi根据模板导出word or pdf
1、导出效果 1.1 wrod 1.2 pdf 2、依赖 <!--word--><dependency><groupId>cn.afterturn</groupId><artifactId>easypoi-base</artifactId><version>4.3.0</version></dependency><dependency><groupId>cn.…...
NVIDIA Hopper 架构深入
在 2022 年 NVIDIA GTC 主题演讲中,NVIDIA 首席执行官黄仁勋介绍了基于全新 NVIDIA Hopper GPU 架构的全新 NVIDIA H100 Tensor Core GPU。 文章目录 前言一、NVIDIA H100 Tensor Core GPU 简介二、NVIDIA H100 GPU 主要功能概述1. 新的流式多处理器 (SM) 具有许多性能和效率…...
AWS IoT Core for Amazon Sidewalk
目录 1 前言2 AWS IoT2.1 准备条件2.2 创建Credentials2.2.1 创建user2.2.2 配置User 2.3 本地CLI配置Credentials 3 小结 1 前言 在测试Sidewalk时,device发送数据,网关接收到,网关通过网络发送给NS,而此处用到的NS是AWS IoT&am…...
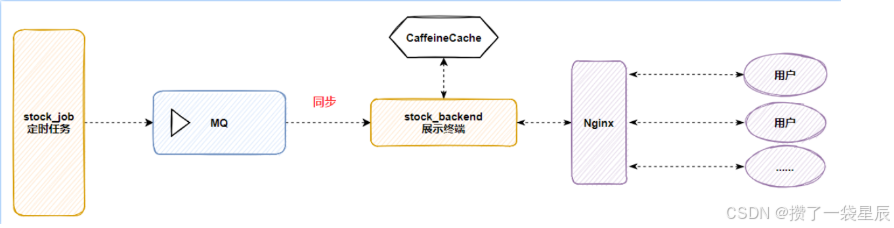
今日指数项目项目集成RabbitMQ与CaffienCatch
今日指数项目项目集成RabbitMQ与CaffienCatch 一. 为什么要集成RabbitMQ 首先CaffeineCatch 是作为一个本地缓存工具 使用CaffeineCatch 能够大大较少I/O开销 股票项目 主要分为两大工程 --> job工程(负责数据采集) , backend(负责业务处理) 由于股票的实时性也就是说 ,…...

C0005.Clion中移动ui文件到新目录后,报错问题的解决
报错问题如下 AutoUic error ------------- "SRC:/confirmwizardpage.cpp" includes the uic file "ui_confirmwizardpage.h", but the user interface file "confirmwizardpage.ui" could not be found in the following directories"SRC…...
基于STM32的智能家居灯光控制系统设计
引言 本项目将使用STM32微控制器实现一个智能家居灯光控制系统,能够通过按键、遥控器或无线模块远程控制家庭照明。该项目展示了如何结合STM32的外设功能,实现对灯光的智能化控制,提升家居生活的便利性和节能效果。 环境准备 1. 硬件设备 …...

06.useEffect
在 React 开发中,正确使用 useEffect 钩子对于优化组件性能至关重要。一个常见但容易被忽视的性能问题是在依赖数组中使用对象作为依赖项。这可能导致不必要的效果重新执行,从而影响应用性能。通过优先使用原始值(如字符串、数字)作为依赖项,我们可以显著提高组件的效率。…...

【设计模式-中介者模式】
定义 中介者模式(Mediator Pattern)是一种行为设计模式,通过引入一个中介者对象,来降低多个对象之间的直接交互,从而减少它们之间的耦合度。中介者充当不同对象之间的协调者,使得对象之间的通信变得简单且…...

树和二叉树知识点大全及相关题目练习【数据结构】
树和二叉树 要注意树和二叉树是两个完全不同的结构、概念,它们之间不存在包含之类的关系 树的定义 树(Tree)是n(n≥0)个结点的有限集,它或为空树(n 0);或为非空树&a…...

ajax的原理,使用场景以及如何实现
AJAX 原理 AJAX(Asynchronous JavaScript and XML)是一种在网页中实现异步通信的技术,允许网页在不重新加载整个页面的情况下与服务器交换数据。这使得网页应用可以更加响应式和动态,提升用户体验。 AJAX 的核心原理是在后台通过…...

lock_guard和unique_lock学习总结
1.std::lock_guard std::lock_guard其实就是简单的RAII(Resource Acquisition Is Initialization)封装,资源获取即初始化。在构造函数中进行加锁,析构函数中进行解锁,这样可以保证函数退出时,锁一定被释放…...
数据挖掘-padans初步使用
目录标题 Jupyter Notebook安装启动 Pandas快速入门查看数据验证数据建立索引数据选取⚠️注意:排序分组聚合数据转换增加列绘图line 或 **(默认):绘制折线图。bar:绘制条形图。barh:绘制水平条形图。hist&…...
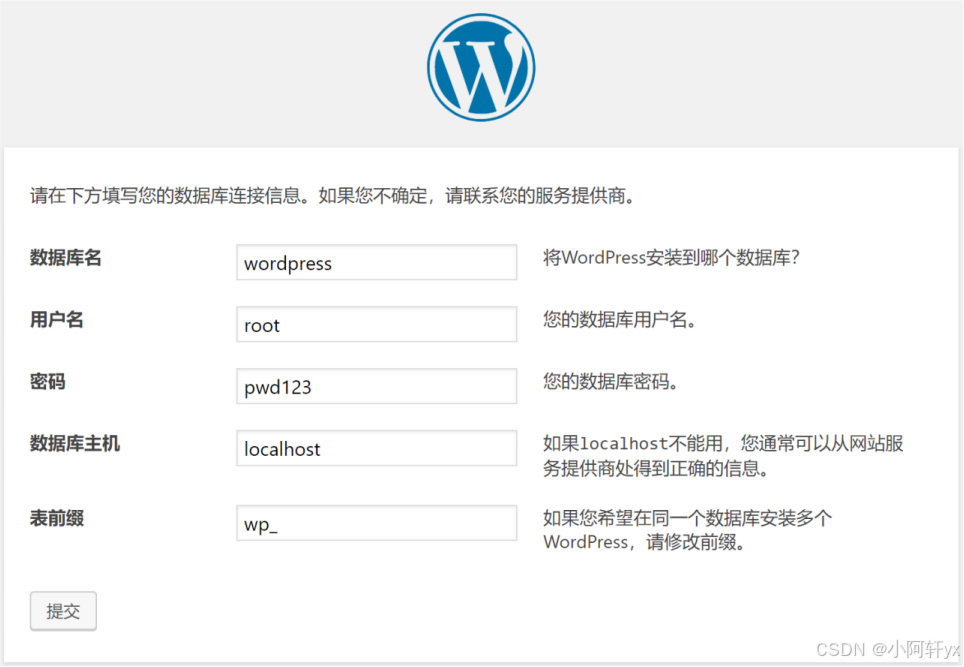
小阿轩yx-案例:项目发布基础
小阿轩yx-案例:项目发布基础 前言 随着软件开发需求及复杂度的不断提高,团队开发成员之间如何更好地协同工作以确保软件开发的质量已经慢慢成为开发过程中不可回避的问题。Jenkins 自动化部署可以解决集成、测试、部署等重复性的工作,工具集…...

百度文库文档免费下载终极指南:三步获取PDF完整教程
百度文库文档免费下载终极指南:三步获取PDF完整教程 【免费下载链接】baidu-wenku fetch the document for free 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wenku 你是否经常在百度文库找到心仪的文档,却因为需要下载券或付费而无法保存…...

波兰市场语音本地化迫在眉睫,ElevenLabs波兰语支持深度评测:WAV质量、时延、重音准确率98.7%实测数据曝光
更多请点击: https://kaifayun.com 第一章:波兰市场语音本地化战略紧迫性分析 波兰作为欧盟第六大经济体和中东欧数字化转型先锋,其语音技术采纳率正以年均23.7%的速度攀升。截至2024年Q2,波兰智能音箱渗透率达38%,而…...

AMD Ryzen SMU调试工具终极指南:3步掌握硬件级性能调优
AMD Ryzen SMU调试工具终极指南:3步掌握硬件级性能调优 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://g…...

开发 AI 应用时如何利用 Taotoken 实现模型的热切换与降级
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 开发 AI 应用时如何利用 Taotoken 实现模型的热切换与降级 在构建面向生产环境的 AI 应用时,服务的稳定性是核心考量之…...

台州华声汽车音响改装店推荐,资深玩家都去这几家
在汽车音响改装领域,选择一家靠谱的门店,往往比挑选器材本身更考验车主的眼光。对于追求极致听感的资深玩家而言,改装的成败不仅取决于喇叭、功放等硬件的参数,更在于安装工艺、声学调校与项目统筹能力。近期,笔者深度…...

欧姆龙G9SP安全控制系统中,如何通过NB触摸屏实现远程复位与状态监控?
欧姆龙G9SP安全控制系统与NB触摸屏的深度集成:远程复位与状态监控实战指南 在工业自动化领域,安全控制系统的可靠性与操作便捷性同样重要。欧姆龙G9SP作为专业的安全控制器,与NB系列触摸屏的协同工作,能够为生产线提供既安全又高…...

避开这些坑,你的蓝桥杯单片机程序也能拿高分:EEPROM存储与电压比较逻辑详解
蓝桥杯单片机高分秘籍:EEPROM存储与电压比较逻辑的深度优化 在蓝桥杯单片机竞赛中,能够完成基本功能只是及格线,真正决定成绩高低的是对细节的掌控和边界条件的处理。许多参赛者在EEPROM数据存储和复杂电压比较逻辑这两个关键环节频频失分&am…...
)
中药实验管理系统|基于springboot+vue的中药实验管理系统(源码+数据库+文档)
中药实验管理系统 目录 基于springbootvue的中药实验管理系统 一、前言 二、系统设计 三、系统功能设计 四、数据库设计 五、核心代码 六、论文参考 七、最新计算机毕设选题推荐 八、源码获取: 博主介绍:✌️大厂码农|毕设布道师,…...

终极指南:使用OpenHTMLtoPDF快速构建专业PDF生成器
终极指南:使用OpenHTMLtoPDF快速构建专业PDF生成器 【免费下载链接】openhtmltopdf An HTML to PDF library for the JVM. Based on Flying Saucer and Apache PDF-BOX 2. With SVG image support. Now also with accessible PDF support (WCAG, Section 508, PDF/U…...

抖音批量下载器终极指南:免费高效的视频采集解决方案
抖音批量下载器终极指南:免费高效的视频采集解决方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback suppor…...