[DB] NSM
Database Workloads(数据库工作负载)
数据库工作负载指的是数据库在执行不同类型任务时所需的资源和计算方式,主要包括以下几种类型:
1. On-Line Transaction Processing (OLTP)
中文:联机事务处理
解释:
OLTP 是一种支持高频交易和快速数据操作的数据库工作负载,适用于日常事务处理。这种操作通常涉及读取和更新少量数据,典型的应用场景包括银行交易、库存系统和电子商务订单等。OLTP 数据库的设计目标是提供快速、可靠的事务处理,并确保数据的完整性。
特征:
- 高并发处理大量短小、快速的操作
- 操作一般只会影响少量记录
- 注重事务的完整性和一致性(ACID 特性)
- 例子:银行转账、实时库存更新
2. On-Line Analytical Processing (OLAP)
中文:联机分析处理
解释:
OLAP 是专门用于处理复杂查询的大量数据的工作负载,常用于决策支持系统或商业智能 (BI)。这种处理涉及从大量数据中进行复杂的查询和分析,以生成汇总报告或进行趋势分析。
特征:
- 执行复杂的查询,通常需要扫描大量数据
- 通常用于计算汇总或聚合结果(例如,计算平均值、总计等)
- 数据通常来自历史记录,读操作多,写操作少
- 例子:销售数据分析、市场趋势报告
3. Hybrid Transaction + Analytical Processing (HTAP)
中文:混合事务和分析处理
解释:
HTAP 是一种将 OLTP 和 OLAP 工作负载结合在同一个数据库实例上的模式。这种方式的目的是在同一系统中同时支持事务处理和分析操作,减少数据复制的复杂性和延迟。HTAP 适用于那些需要实时数据分析,同时又有大量事务操作的场景。
特征:
- 将 OLTP 和 OLAP 工作负载融合
- 支持实时数据分析
- 减少数据同步和延迟问题,适合实时决策
应用场景:电商平台实时推荐系统,金融系统的实时风险评估等。

轴说明:
- 左侧垂直轴(Operation Complexity,操作复杂性):从下方的简单操作(Simple)到上方的复杂操作(Complex)。OLTP 的操作通常较为简单,OLAP 则因为涉及复杂查询而复杂性较高。
- 底部水平轴(Workload Focus,工作负载重点):从左侧的写操作密集(Write-Heavy)到右侧的读操作密集(Read-Heavy)。OLTP 倾向于写操作,OLAP 倾向于读操作。
数据库工作负载分类:
-
OLTP(左下区域):
- 主要集中在简单操作且写操作密集(Write-Heavy)。OLTP 系统如电子商务平台、银行系统,操作简单且涉及大量数据写入,比如插入订单或更新库存。
-
OLAP(右上区域):
- 主要集中在复杂操作且读操作密集(Read-Heavy)。OLAP 系统如数据仓库或商业智能分析平台,执行复杂查询以读取大量数据并生成报告或分析。
-
HTAP(中间红色区域):
- 混合事务和分析处理,位于 OLTP 和 OLAP 之间,结合了这两者的特点。HTAP 系统既处理高频的写操作,也能应对复杂的读操作需求,适用于需要实时数据分析和事务处理的场景。
1. Relational Model and Tuple Storage
中文:关系模型与元组存储
解释:
关系模型并未规定数据库管理系统 (DBMS) 必须将一个元组(即一行)的所有属性(字段)一起存储在同一个页面(page)上。
- 元组:指的是关系数据库中的一行数据,每个元组包含多个属性,即列的数据。
- 页面:数据库中最小的存储单元之一,通常用于存放数据的物理存储块。
知识点:
在数据库设计中,是否将元组的所有属性集中存储在一个页面中可以影响性能。对于某些工作负载来说(如 OLTP),将相关数据集中存放可能更高效,但对于其他工作负载(如 OLAP),分离存储不同的属性可能带来更好的性能优化。不同工作负载的存储布局需求不同。

1. SELECT 语句:
SELECT P.*, R.*
FROM pages AS P
INNER JOIN revisions AS R
ON P.latest = R.revID
WHERE P.pageID = ?
- 解释:这是一个典型的 SQL 查询,使用了
INNER JOIN来联结两个表pages和revisions。P.*和R.*:选择pages表和revisions表中的所有字段。INNER JOIN revisions AS R ON P.latest = R.revID:将pages表和revisions表联结起来,条件是pages表的latest字段与revisions表的revID字段相匹配。WHERE P.pageID = ?:查询条件是pages表的pageID必须匹配给定的条件(用?表示占位符)。
用途:获取 pages 表中与某个 pageID 对应的页面信息,并获取该页面最新的修订版本信息。
2. UPDATE 语句:
UPDATE useracct
SET lastLogin = NOW(), hostname = ?
WHERE userID = ?
- 解释:这是一个更新语句,用于修改
useracct表中的某些字段。SET lastLogin = NOW(), hostname = ?:将lastLogin字段更新为当前时间,hostname字段更新为给定值(?是占位符)。WHERE userID = ?:只更新userID与给定值匹配的用户记录。
用途:更新用户的最后登录时间和主机名。
3. INSERT 语句:
INSERT INTO revisions VALUES (?, ?, ?)
- 解释:这是一个插入语句,用于向
revisions表中插入新数据。VALUES (?, ?, ?):插入的数据使用占位符,具体值在执行时提供。
用途:向 revisions 表中添加一条新记录,具体值将在插入时提供。
第二个图:

1. SELECT COUNT 和 EXTRACT 语句:
SELECT COUNT(U.lastLogin), EXTRACT(month FROM U.lastLogin) AS month
FROM useracct AS U
WHERE U.hostname LIKE '%.gov'
GROUP BY EXTRACT(month FROM U.lastLogin)
- 解释:这是一个带有聚合函数和日期提取函数的查询。
COUNT(U.lastLogin):统计useracct表中lastLogin字段非空的记录数。EXTRACT(month FROM U.lastLogin) AS month:从lastLogin字段中提取登录的月份。FROM useracct AS U WHERE U.hostname LIKE '%.gov':只选择hostname字段以.gov结尾的记录。GROUP BY EXTRACT(month FROM U.lastLogin):按登录月份分组,统计每个月的登录次数。
用途:统计所有使用 .gov 主机名的用户每个月的登录次数。
总结:
- 第一张图:展示了数据查询(
SELECT)、更新(UPDATE)和插入(INSERT)的基本操作。查询语句用于从两个相关表中获取信息,更新语句用于修改用户数据,插入语句则向表中添加新数据。 - 第二张图:展示了如何使用
GROUP BY和COUNT来统计特定条件下的数据(如登录时间按月统计),同时演示了如何使用EXTRACT函数从日期中提取特定的部分。
Storage Models(存储模型)
数据库管理系统 (DBMS) 的存储模型决定了它如何在磁盘和内存中物理组织元组(即数据库的行)。不同的存储模型对不同类型的工作负载(如 OLTP 和 OLAP)具有不同的性能特性。存储模型的选择还会影响数据库系统设计的其他部分。
1. N-ary Storage Model (NSM)
中文:N-元存储模型
解释:
NSM 又称为行存储模型,是传统的数据库存储模型,它将整个元组的所有属性(即一行的所有字段)存储在同一个连续的磁盘页面中。
- 优势:这种存储模型在处理OLTP 工作负载时非常高效,因为通常只需要访问或更新单行数据(如处理一笔银行交易)。
- 劣势:当查询只需要部分列时,NSM 模型可能会加载不必要的列,导致额外的 I/O 成本。
适用场景:OLTP(联机事务处理)系统,因为其通常只涉及单行或少量数据的频繁读写操作。
2. Decomposition Storage Model (DSM)
中文:分解存储模型
解释:
DSM 又称为列存储模型,将表的每一列单独存储为一个文件或一个页面。因此,每次访问时,只需要加载所需的列而不是整个元组(行)。
- 优势:DSM 在OLAP 工作负载下表现优异,特别是对于只查询少量列的复杂分析操作,能减少 I/O 成本并提高查询效率。
- 劣势:如果需要频繁更新多列数据,DSM 的性能可能不如 NSM,因为更新时需要在多个存储位置间进行操作。
适用场景:OLAP(联机分析处理)系统,尤其是在进行聚合查询或分析时,因为这些查询往往只涉及少数列,但会处理大量行。
3. Hybrid Storage Model (PAX)
中文:混合存储模型
解释:
PAX 是一种混合存储模型,结合了 NSM 和 DSM 的优势。PAX 模型将每一个磁盘页面分为多个区域,每个区域存储一个元组的一个属性。也就是说,元组的属性按列存储在同一个页面中,而不同页面之间则存储不同元组的列。
- 优势:PAX 同时优化了行存储和列存储的性能。它能减少 I/O 操作,并优化内存中的缓存性能,因为同一页面内的列存储布局能够有效利用 CPU 缓存。
- 劣势:与 NSM 和 DSM 相比,PAX 模型的实现更复杂。
适用场景:PAX 适用于既需要处理 OLTP 事务,又需要执行 OLAP 查询的混合工作负载系统(如 HTAP 系统)。这种模型提供了一种折中方案,适用于需要平衡行存储和列存储优势的场景。
1. N-ary Storage Model (NSM)
中文:N-元存储模型
解释:
在 NSM 模型中,数据库管理系统 (DBMS) 会将单个元组(即一行)的几乎所有属性连续存储在同一个磁盘页面上。这种模型也被称为行存储模型(row store),因为它将一整行的数据按顺序存储在一起。
2. 适用于 OLTP 工作负载
- 特点:NSM 模型非常适合 OLTP(联机事务处理)类型的工作负载,因为这些工作负载通常涉及对单个实体的频繁访问和大量的写操作。
- 优势:由于所有的元组属性都被连续存储在一个页面中,访问单个实体时可以减少磁盘 I/O 操作,从而提高效率。这样就可以快速读取或更新整个元组(即一行)的所有字段,这对于频繁的写操作来说尤其有用。
3. 页面大小与硬件相关
- NSM 数据库的页面大小通常是 4 KB 硬件页面的整数倍。数据库系统如 Oracle、PostgreSQL 和 MySQL 的页面大小各不相同:
- Oracle:4 KB
- PostgreSQL:8 KB
- MySQL:16 KB
1. Physical Organization of NSM (物理组织)
在磁盘导向的 N-元存储模型(NSM)中,DBMS 会将元组(tuple)的固定长度和可变长度属性连续存储在同一个**带插槽的页面(slotted page)**中。每个元组的属性,无论是定长还是变长,都会尽可能存储在同一页面中。
- 固定长度属性:如整数(INT)、浮点数(FLOAT),这些字段在数据库中占用的字节数是固定的。
- 可变长度属性:如字符串(VARCHAR),这些字段的长度是可变的,因此存储时需要额外的空间管理机制。
2. Slotted Page (带插槽的页面)
- Slotted page 是一种页面组织结构,页面内划分成若干插槽,每个插槽存储一个元组。页面的开始部分会有一个指针数组,记录每个插槽的位置。
- 这种方式使得在页面中插入、删除和更新元组更为灵活,因为插槽的指针可以调整。
3. Record ID (记录 ID)
- Record ID (page#, slot#):每个元组都有一个唯一的记录 ID,由页面编号 (page#) 和插槽编号 (slot#) 组成。这两个标识符共同标识了元组在磁盘中的物理位置。
- page#:代表元组所在的物理页面编号。
- slot#:代表元组在该页面中的插槽编号。
4. 用途
- DBMS 使用 Record ID (page#, slot#) 来唯一标识元组,并在需要时进行查找或更新。这种物理标识符与元组的存储位置直接相关,允许系统快速定位并处理数据。

1. SQL 查询与插入语句:
4. 磁盘与页面:
-
SELECT 语句:
SELECT * FROM useracct WHERE userName = ? AND userPass = ? -
- 这个查询从
useracct表中选取所有列(*),条件是userName和userPass必须与提供的值相匹配。这是一个典型的 OLTP 查询,用于验证用户的登录信息。
- 这个查询从
-
INSERT 语句:
INSERT INTO useracct VALUES (?, ?, …) -
- 这个插入语句向
useracct表中插入新的一行数据。占位符?用来表示在执行时插入的具体值。这是一个典型的写操作,常用于创建新用户账号等场景。
- 这个插入语句向
-
2. Index(索引):
- 图中显示了一个“Index(索引)”,虽然没有深入讲解(标记为“未来讲解”),但可以推测,这个索引用于加速查询。例如,
userName和userPass字段可能有索引支持,以便快速查找到匹配的行。这是 OLTP 系统中常见的优化方式,特别是在频繁查询的场景下,索引有助于提高查询效率。 -
3. NSM Disk Page(NSM 磁盘页面):
-
NSM 页面结构:
- 在 NSM 模型中,数据按照行的顺序存储。每行包含
userID、userName、userPass、hostname和lastLogin等字段。这些字段被连续存储在一个页面中,每行对应一条完整的用户记录。
- 在 NSM 模型中,数据按照行的顺序存储。每行包含
-
页面头部(header):
- 每个 NSM 页面都有一个页面头部(header),用于存储页面的元数据,如页面编号、插槽指针等信息。头部帮助管理页面中的数据。
- 图中显示了磁盘文件中 NSM 页面的存储方式。每个页面中包含了完整的元组(包括定长和可变长属性)。当系统执行 SQL 查询时,它会读取相关的页面,并利用索引查找数据,以提高查询的效率。
SELECT COUNT(U.lastLogin), EXTRACT(month FROM U.lastLogin) AS month
FROM useracct AS U
WHERE U.hostname LIKE '%.gov'
GROUP BY EXTRACT(month FROM U.lastLogin)
- 解释:
SELECT COUNT(U.lastLogin):统计lastLogin字段非空记录的数量。EXTRACT(month FROM U.lastLogin):从lastLogin字段中提取登录的月份,并将其作为month别名。FROM useracct AS U:从useracct表中查询数据。WHERE U.hostname LIKE '%.gov':条件筛选,查找hostname字段中以 “.gov” 结尾的记录(通常是政府机构)。GROUP BY EXTRACT(month FROM U.lastLogin):按登录的月份分组,统计每个月有多少次登录。
这个查询典型地属于 OLAP 工作负载,涉及复杂的聚合查询和大量数据处理。
2. NSM Disk Page(NSM 磁盘页面)
- 图中显示了 NSM 的磁盘页面存储布局,所有用户数据(
userID、userName、userPass、hostname、lastLogin等)都以行的形式紧密存储在同一个页面中。 - 在这个查询中,实际上只需要读取
lastLogin和hostname两列数据,但由于 NSM 是行存储模型,系统仍然需要加载整个行的数据,这可能会带来不必要的 I/O 操作。
3. OLAP 查询的局限性
- 由于 NSM 模型将每个元组的所有属性存储在一个页面上,因此当查询仅涉及某些列(如
lastLogin和hostname)时,系统仍然必须读取整个行的数据。这会增加磁盘 I/O 的负担,尤其是在需要处理大量行并且查询的列数较少时。 - 在 OLAP 场景下,这样的行存储模型可能不是最理想的,因为很多 OLAP 查询只需要少数几列,但 NSM 会迫使系统读取完整的行。
4. OLAP 工作负载下的挑战
- OLAP(联机分析处理) 工作负载通常需要处理大量数据并执行复杂的聚合查询(如统计、分组等)。在这种情况下,NSM 模型虽然可以执行这些查询,但它需要处理很多不必要的列,从而增加了 I/O 和处理时间。
- 例如,在这个查询中,系统需要分析
lastLogin和hostname字段,但是由于 NSM 是行存储模型,查询时系统必须加载整个用户记录的所有字段,而不仅仅是所需的几列。这种行为会影响查询的效率,尤其是当表中包含大量列时。
NSM (N-ary Storage Model) 总结
优点:
-
快速插入、更新和删除
- 解释:NSM 模型采用行存储,因此在处理插入、更新和删除操作时非常高效,尤其是在 OLTP 场景下,这种模型的操作粒度是行,能够快速地对单行进行操作。
-
适合需要整个元组的查询(OLTP)
- 解释:对于那些需要检索和操作整行数据的查询(如交易处理系统中的典型操作),NSM 模型表现出色,因为它将整行数据存储在同一个页面中,这可以减少读取和写入时的 I/O 次数。
-
可以使用面向索引的物理存储进行聚簇
- 解释:NSM 支持基于索引的物理存储方式,如聚簇索引。这可以通过将相关的元组存储在相邻的物理页面上来优化数据访问,从而减少磁盘查找时间,提高查询效率。
缺点:
-
不适合扫描大量表数据或子集属性
- 解释:在需要扫描大量行但只关心某些列的情况下(如 OLAP 场景中的分析查询),NSM 会导致不必要的 I/O 操作。因为 NSM 是按行存储的,即使只查询几个列,也必须加载整个行的所有数据,这会增加系统开销。
-
对于 OLAP 访问模式,内存局部性差
- 解释:OLAP 查询通常涉及读取大量数据并进行复杂的聚合操作。NSM 的行存储方式在这种场景下表现不佳,因为它会导致多个不相关的属性被加载到缓存中,降低缓存效率和内存局部性。
-
不适合压缩
- 解释:由于 NSM 在同一个页面内存储了不同数据类型的属性(即多个值域),这使得使用统一的压缩算法变得困难。相反,列存储模型(如 DSM)更容易进行压缩,因为同一列中的值通常具有相似的数据类型和分布特性。
总结:
- 适合场景:NSM 模型非常适合 OLTP 系统,尤其是需要频繁插入、更新和删除操作的场景。此外,它在需要访问整个元组时表现优异。
- 不适合场景:对于 OLAP 场景中需要处理大量数据、扫描部分列的查询,NSM 的性能表现欠佳,并且由于内存局部性差和压缩难度大,不能有效支持这种工作负载。
NSM 行存储模型的选择取决于系统的工作负载类型。如果你的数据库系统主要处理事务性操作(OLTP),NSM 是很好的选择,但如果你更多的是执行分析性查询(OLAP),那么列存储模型可能是更好的方案。
相关文章:
[DB] NSM
Database Workloads(数据库工作负载) 数据库工作负载指的是数据库在执行不同类型任务时所需的资源和计算方式,主要包括以下几种类型: 1. On-Line Transaction Processing (OLTP) 中文:联机事务处理解释:…...

Redis 高可用:从主从到集群的全面解析
目录 一、主从复制 (基础)1. 同步复制a. 全量数据同步b. 增量数据同步c. 可能带来的数据不一致 2. 环形缓冲区a. 动态调整槽位 3. runid4. 主从复制解决单点故障a. 单点故障b. 可用性问题 5. 注意事项a. Replica 主动向 Master 建立连接b. Replica 主动向 Master 拉取数据 二、…...

全能型选手视频播放器VLC 3.0.21 for Windows 64 bits支持Windows、Mac OS等供大家学习参考
全能型选手视频播放器,支持Windows、Mac OS、Linux、Android、iOS等系统,也支持播放几乎所有主流视频格式。 推荐指数: ★★★★★ 优点: ◆、界面干净简洁,播放流畅 ◆、支持打开绝大多数的文件格式,包…...

解决在Vue3中使用monaco-editor创建多个实例的导致页面卡死的问题
最近在项目中使用到了monaco-editor来实现相关的业务功能,按照官方使用方法进行了相关操作,但是在使用的时候,总是会导致创建多个编辑器实例,导致页面卡死的情况,下面来看看怎么处理这种情况吧,先说一下我使…...

【某农业大学计算机网络实验报告】实验二 交换机的自学习算法
实验目的: (1)理解交换机通过逆向自学习算法建立地址转发表的过程。 (2)理解交换机转发数据帧的规则。 (3)理解交换机的工作原理。 实验器材: 一台Windows操作系统的PC机。 实…...

燕山大学23级经济管理学院 10.18 C语言作业
燕山大学23级经济管理学院 10.18 C语言作业 文章目录 燕山大学23级经济管理学院 10.18 C语言作业1C语言的基本数据类型主要包括以下几种:为什么设计数据类型?数据类型与知识体系的对应使用数据类型时需要考虑的因素 21. 逻辑运算符2. 真值表3. 硬件实现4…...

【880线代】线性代数一刷错题整理
第一章 行列式 2024.8.20日 1. 2. 3. 第二章 矩阵 2024.8.23日 1. 2024.8.26日 1. 2. 3. 4. 5. 2024.8.28日 1. 2. 3. 4. 第四章 线性方程组 2024.9.13日 1. 2. 3. 4. 5. 2024.9.14日 1. 第五章 相似矩阵 2024.9.14日 1. 2024.9.15日 1. 2. 3. 4. 5. 6. 7. 2024.9.…...

【C++语言】精妙的哈希算法:原理、实现与优化
解锁Python编程的无限可能:《奇妙的Python》带你漫游代码世界 哈希算法是计算机科学中的一项基本技术,广泛应用于数据检索、加密、缓存等领域。本文将深入探讨C++中的哈希算法,详细讲解其原理、实现、优化以及在不同应用场景中的使用。通过丰富的代码示例和数学推导,本文旨…...

基于STM32的手势电视机遥控器设计
引言 本项目设计了一个基于STM32的手势电视机遥控器,利用红外线传输和加速度传感器(或陀螺仪)检测用户的手势动作,用于控制电视的音量、频道切换等操作。通过对手势的实时检测和分类,系统能够识别左右、上下、旋转等手…...

2、图像的特征
一、角点检测-Harris 1、cv2.cornerHarris角点检测函数 在 cv2.cornerHarris 函数中,Sobel 算子用于计算图像的梯度,这是 Harris 角点检测的第一步。 cv2.cornerHarris(src, blockSize, ksize, k, dstNone, borderTypeNone)下面是各个参数的详细解释&…...

URL、URN和URI的区别
目录 一:URI二:URN三:URL1. URL格式 一:URI URI 是(Uniform Resource Identifier)统一资源标识符的缩写。用于唯一标识互联网上的资源。URI包含了URN和URL 二:URN URN是(Uniform …...
深入理解Spring框架几个重要扩展接口
本文介绍Spring框架的几个日常开发重要扩展接口,方便日常项目中按需扩展使用。 一、Processor 系列接口 用途: Processor 系列接口包括 BeanPostProcessor 和 BeanFactoryPostProcessor,它们的设计目的是在 Spring 容器启动过程中对 Bean 和…...

使用dotnet-counters和dotnet-dump 分析.NET Core 项目内存占用问题
在.NET Core 项目部署后,我们往往会遇到内存占用越来越高的问题,但是由于项目部署在Linux上,因此无法使用VS的远程调试工具来排查内存占用问题。那么这篇文章我们大家一起来学习一下如何排查内存占用问题。 首先,我们来看一下应用…...
1282:最大子矩阵
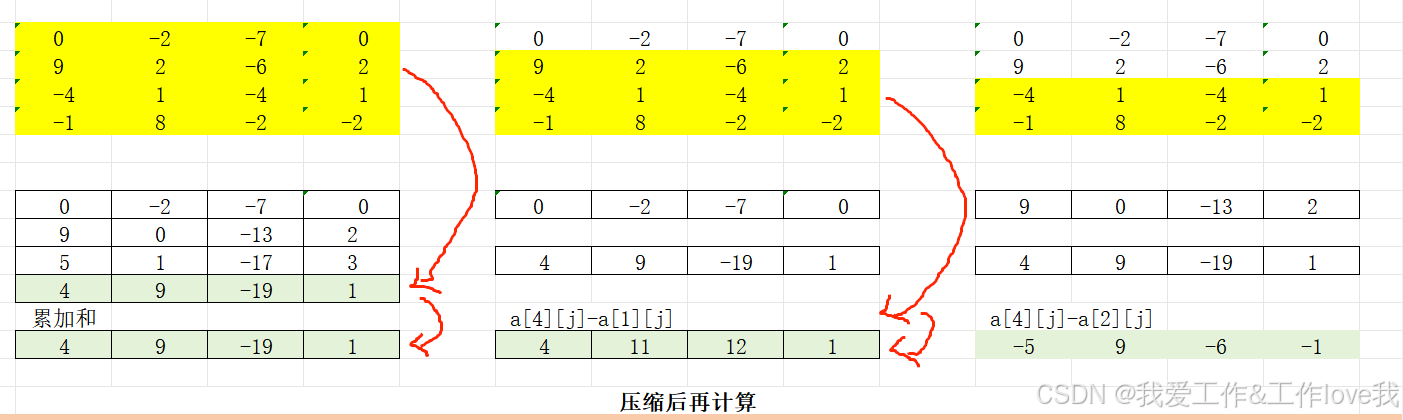
题目: 已知矩阵的大小定义为矩阵中所有元素的和。给定一个矩阵,你的任务是找到最大的非空(大小至少是1 1)子矩阵。 比如,如下4 4的矩阵 0 -2 -7 0 9 2 -6 2 -4 1 -4 1 -1 8 0 -2 的最大子矩阵是 9 2 -4 1 -1 8 这个子矩阵的大小是15。 …...
)
C++编程语言:抽象机制:特殊运算符(Bjarne Stroustrup)
第19章 特殊运算符(Special Operators) 目录 19.1 引言 19.2 特殊运算符(Special Operators) 19.2.1 下标运算符(Subscripting) 19.2.2 函数调用运算符(Function Call) 19.2.3 解引用(Dereferencing) 19.2.4 递增和递减(Increment and Decrement) 19…...
图片无损放大工具Topaz Gigapixel AI v7.4.4 绿色版
Topaz A.I. Gigapixel是这款功能齐全的图象无损变大运用,应用可将智能机拍摄的图象也可以有着专业相机的高质量大尺寸作用。你可以完美地放大你的小照片并大规模打印,它根本不会粘贴。它具有清晰的效果和完美的品质。 借助AIGigapixel,您可以…...
)
Vue中计算属性computed—(详解计算属性vs方法Methods,包括案例+代码)
文章目录 计算属性computed3.1 概述3.2 使用3.3 计算属性vs方法Methods3.4 计算属性的完整写法 计算属性computed 3.1 概述 基于现有的数据,计算出来的新属性。 依赖的数据变化,自动重新计算 语法: 声明在 computed 配置项中,…...
Python程序设计 内置函数 日志模块
logging(日志) 日志记录是程序员工具箱中非常有用的工具。它可以帮助您更好地理解程序的流程,并发现您在开发过程中可能没有想到的场景。 日志为开发人员提供了额外的一组眼睛,这些眼睛不断关注应用程序正在经历的流程。它们可以存储信息,例…...

中标麒麟v5安装qt512.12开发软件
注意 需要联网操作 遇到问题1:yum提示没有可用软件包问题 终端执行如下命令 CentOS7将yum源更换为国内源保姆级教程 中标麒麟V7-yum源的更换(阿里云源) wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Cento…...
)
每日算法一练:剑指offer——数组篇(3)
1.报数 实现一个十进制数字报数程序,请按照数字从小到大的顺序返回一个整数数列,该数列从数字 1 开始,到最大的正整数 cnt 位数字结束。 示例 1: 输入:cnt 2 输出:[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,1…...

如何构建现代搜索应用:ReactiveSearch与GraphQL的终极集成指南
如何构建现代搜索应用:ReactiveSearch与GraphQL的终极集成指南 【免费下载链接】reactivesearch Search UI components for React and Vue 项目地址: https://gitcode.com/gh_mirrors/re/reactivesearch ReactiveSearch是一个强大的React和Vue搜索UI组件库&a…...

Git子模块克隆总失败?试试这个国内镜像源+分步克隆的保姆级方案
Git子模块克隆失败?国内镜像源分步克隆的终极解决方案 每次看到终端里那个刺眼的"fatal: clone of https://github.com/xxx/yyy.git into submodule path failed"错误提示,我都忍不住想砸键盘。作为一个常年需要从GitHub拉取各种开源项目的开发…...

PP-DocLayoutV3入门指南:从零开始理解bbox坐标、label_id、score字段含义
PP-DocLayoutV3入门指南:从零开始理解bbox坐标、label_id、score字段含义 1. 前言:为什么你需要了解这些字段? 如果你刚开始接触文档布局分析,看到PP-DocLayoutV3输出的JSON数据,可能会对里面那些bbox、label_id、sc…...

Magisk系统权限架构深度解析:Android设备Root权限优雅解决方案
Magisk系统权限架构深度解析:Android设备Root权限优雅解决方案 【免费下载链接】Magisk The Magic Mask for Android 项目地址: https://gitcode.com/GitHub_Trending/ma/Magisk Magisk作为Android系统权限管理领域的革命性工具,通过独特的系统化…...

如何高效管理微信读书笔记:终极免费工具wereader完全指南
如何高效管理微信读书笔记:终极免费工具wereader完全指南 【免费下载链接】wereader 一个功能全面的微信读书笔记助手 wereader 项目地址: https://gitcode.com/gh_mirrors/we/wereader 微信读书助手wereader是一款专为微信读书用户设计的免费开源工具&#…...

告别VirtualBox默认20G!保姆级教程:从创建到动态扩容,打造你的专属开发环境
从零规划VirtualBox磁盘空间:开发环境搭建的黄金法则 刚接触VirtualBox的新手开发者们,是否曾在项目进行到一半时突然发现磁盘空间不足?那种被迫中断工作流程去处理存储问题的体验,足以毁掉一天的开发效率。本文将带你从源头规避这…...

cv_unet_image-colorization高保真上色案例:人脸肤色/服饰纹理自然还原实录
cv_unet_image-colorization高保真上色案例:人脸肤色/服饰纹理自然还原实录 你有没有翻看过家里的老相册?那些泛黄的黑白照片,记录着珍贵的瞬间,却总让人觉得少了点什么。色彩,是记忆的温度。过去,为黑白照…...

基于OpenCV的多条形码高效定位与识别实战
1. 为什么需要多条形码识别技术 在零售仓储和物流分拣场景中,我们经常需要同时处理多个条形码。比如快递站点的包裹分拣机,每秒钟要处理数十个包裹的条形码;超市收银台的商品堆里,经常叠放着五六件带条形码的商品。传统扫码枪需要…...

OpenClaw+Qwen3.5-4B-Claude:个人知识库自动化更新方案
OpenClawQwen3.5-4B-Claude:个人知识库自动化更新方案 1. 为什么需要自动化知识管理 作为一个每天需要处理大量技术资料的研究者,我发现自己陷入了一个困境:收藏的文章越来越多,但真正消化吸收的内容却越来越少。上周整理笔记时…...

解决语音合成难题:用QWEN-AUDIO实现高质量、带情绪的TTS
解决语音合成难题:用QWEN-AUDIO实现高质量、带情绪的TTS 1. 语音合成的痛点与突破 传统语音合成技术(TTS)长期面临三大难题:机械感强、缺乏情感表现力、定制成本高。许多开发者尝试过开源解决方案,但往往需要复杂的参数调整才能获得勉强可用…...