Lucene的概述与应用场景(1)
文章目录
- 第1章 Lucene概述
- 1.1 搜索的实现方案
- 1.1.1 传统实现方案
- 1.1.2 Lucene实现方案
- 1.2 数据查询方法
- 1.1.1 顺序扫描法
- 1.1.2 倒排索引法
- 1.3 Lucene相关概念
- 1.3.1 文档对象
- 1.3.2 域对象
- 1)分词
- 2)索引
- 3)存储
- 1.3.3 常用的Field种类
- 1.4 分词器
第1章 Lucene概述
Lucene是apache软件基金会 jakarta项目组的一个子项目,是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。其作者是大名鼎鼎的大数据之父Doug-Cutting。Lucene通过使用倒排索引技术,能够快速地从大量的文档中检索出相关信息。对文本数据进行高效的索引和搜索,支持复杂的查询语法,包括布尔运算、短语搜索、模糊搜索等。
在Java开发环境里Lucene是一个成熟的免费开源工具。就其本身而言,Lucene是当前以及最近几年最受欢迎的免费Java信息检索[程序库。人们经常提到信息检索程序库,虽然与搜索引擎有关,但不应该将信息检索程序库与搜索引擎相混淆。Java中著名的搜索引擎ElasticSearch、Solr等都是采用Lucene作为内核进行开发;
- Lucene官网:https://lucene.apache.org/
Lucene的应用场景如下:
- 网站搜索:许多网站使用Lucene或其衍生产品(如Elasticsearch)来提供站内搜索功能。
- 企业级搜索:在企业内部,Lucene可用于构建文件、邮件、数据库记录等信息的搜索引擎。
- 日志分析:对于大规模的日志数据,可以通过Lucene快速定位到特定的错误或异常信息。
- 电子商务:在线购物平台经常利用Lucene来优化商品搜索体验,提高用户满意度。
1.1 搜索的实现方案
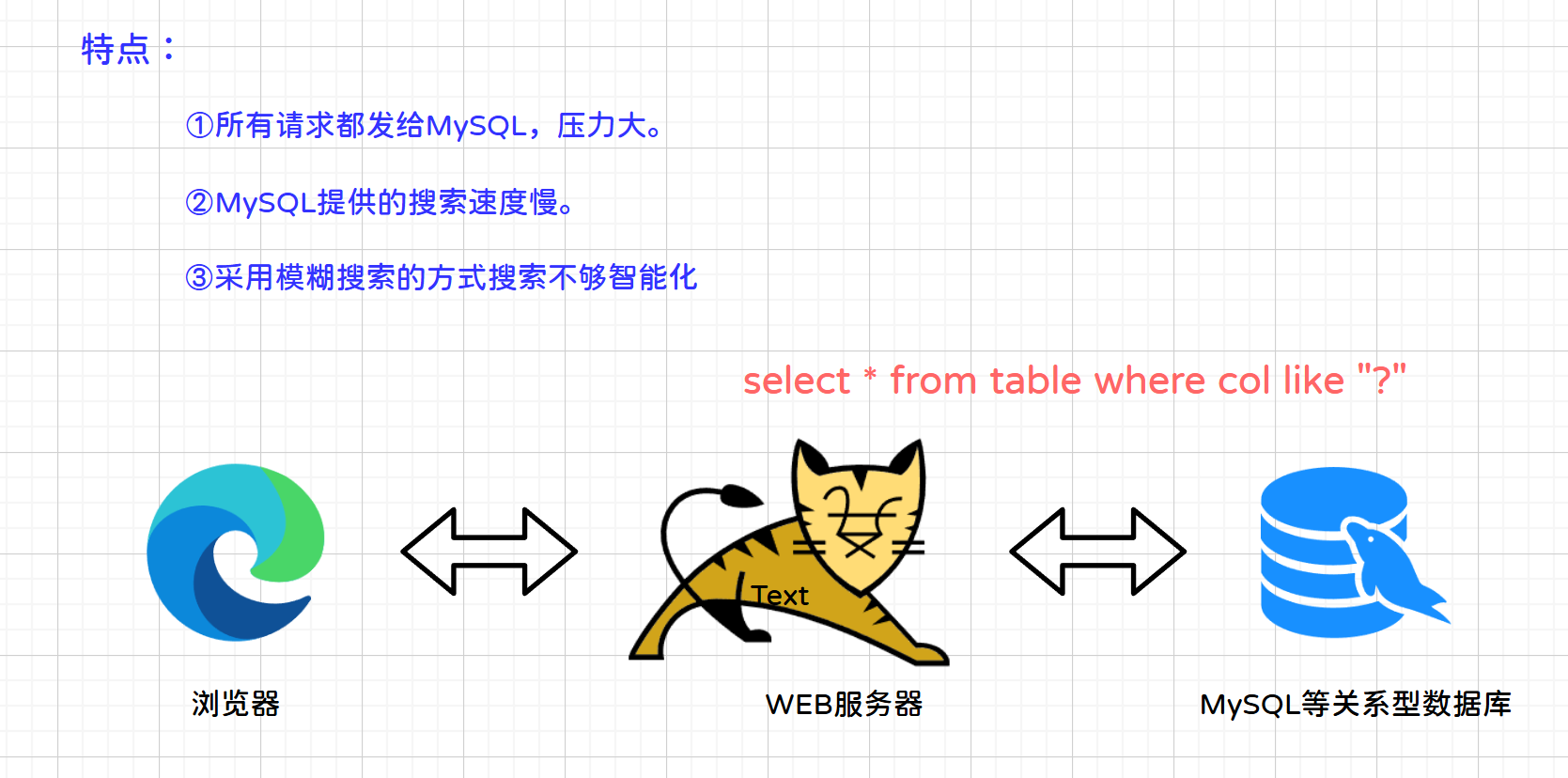
1.1.1 传统实现方案
用户发送请求查询到服务器,服务器通过SQL查询数据库将结果返回,最终将结果集响应到用户。
特点:数据库服务器压力大,查询速度慢,搜索不智能化。
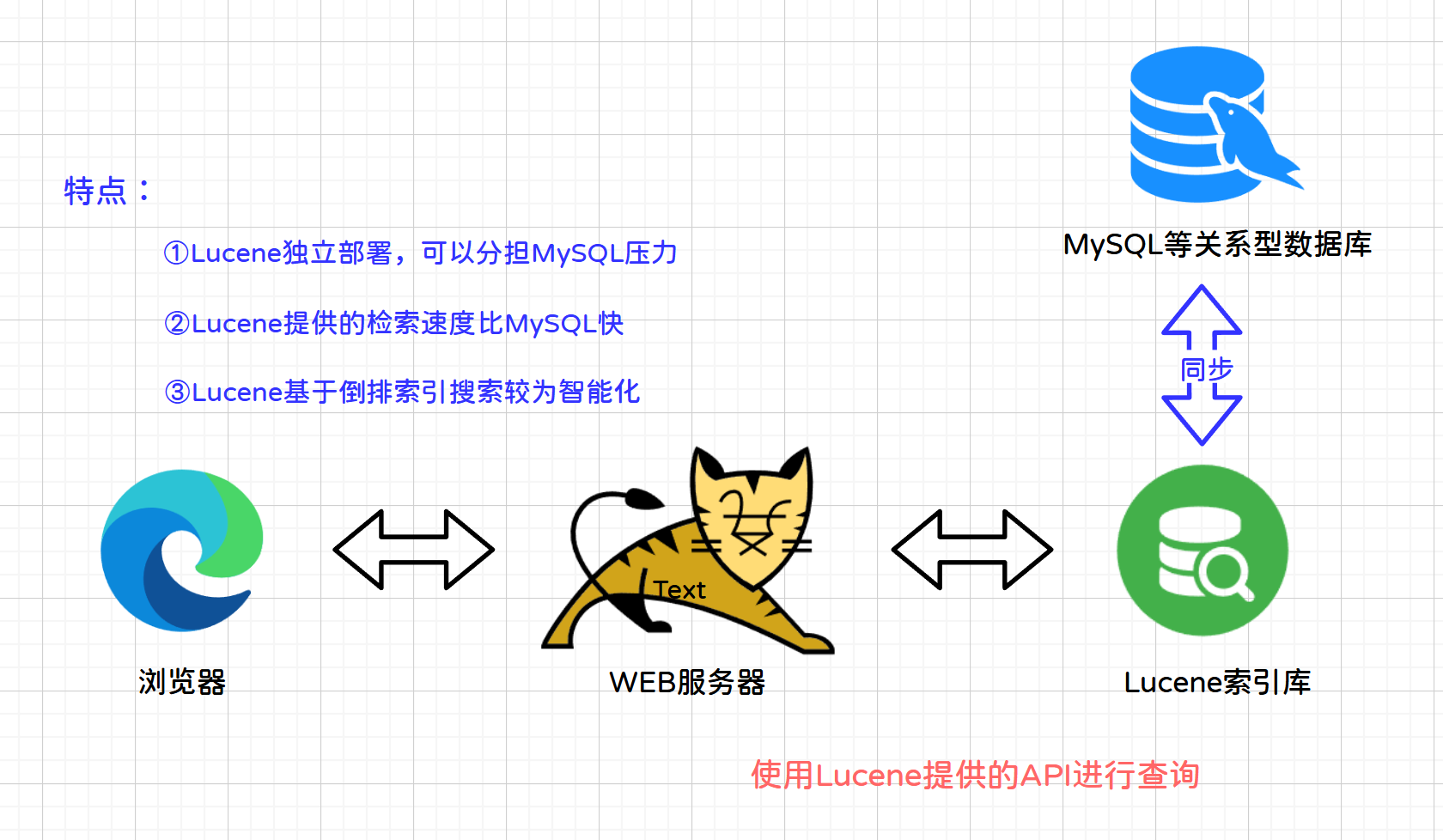
1.1.2 Lucene实现方案
说明:根据用户输入的搜索关键词(java),应用服务器通过lucene的API搜索索引库,索引库把搜索结果响应应用服务器,应用服务器再把搜索结果响应给用户。
特点:解决用户量大,数据量很大,系统对搜索速度要求高并且需要智能化搜索的业务需求。
1.2 数据查询方法
1.1.1 顺序扫描法
举个例子:比如我们有大量的文件,文件编号从A,B,C。。。。。。
需求:要找出文件内容中包含有java的所有文件
需求实现:从A文件开始查找,再找B文件,然后再找C文件,以此类推。。。。。
特点:如果文件数量很多,查找将会非常慢。
1.1.2 倒排索引法
举个例子:使用新华字典查找汉字,先找到汉字的偏旁部首,再根据偏旁部首对应的目录(索引)找到目标汉字。这个目录在计算机中被称为索引,是用来帮助程序快速查询数据用的。
索引的组织方式有很多,底层结构也不一样,但无论是那种索引都只有一个目标,那就是用于提高查询性能,快速定位到目标数据所在。
以Lucene为例建立倒排索引:
文件一(编号0):I am Chinese I am Chinese
文件二(编号1):I love China
| Term | (Doc,Freq) |
|---|---|
| Chinese | (0) (2) |
| love | (1)(1) |
| china | (1)(1) |
说明:
- 建立倒排索引,就是建立词语与文件的对应关系(词语在什么文件出现,出现了几次,在什么位置出现)
- 搜索的时候,直接根据搜索关键词(java),在倒排索引中找到目标内容。
1.3 Lucene相关概念
使用Lucene的第一步我们需要采集原始数据,数据的来源可以是传统的关系型数据库、文本文件、网络资源等;
- 保存在关系数据库中的业务数据MySQL:通过JDBC操作获取到关系数据库中的业务数据(mysql)
- 保存在文件中的数据:通过IO流获取文件上的数据
- 网络上的网页文件数据:通过爬虫(蜘蛛)程序获取网络上的网页数据
1.3.1 文档对象
文档对象(Document):一个文档对象包含有多个域(Field)。一个文档对象就相当于关系数据库表中的一条记录,一个域就相当于一个字段。

1.3.2 域对象
在Lucene中,一篇文档对应数据库的一行数据,一个域对象则对应一个字段,一个文档由多个域对象组成。在Lucene中不同的域对象具有不同的属性和功能
1)分词
分词(tokenized):对域中的文本内容进行根据要求进行分析,将一段文本分析成一个个符合逻辑的词组;
原始文档:
华为5G智能全面屏拍照游戏手机
分词后:
华为、5G、智能、全面屏、拍照、游戏、手机、游戏手机
- 需要分词的域(Field):商品名称,商品标题。这些内容用户需要输入关键词进行查询,由于内容格式大,内容多,需要进行分词处理建立索引。
- 不需要分词的域(Field):商品编号,身份证号。是一个整体,分词以后没有意义,不需要分词。
2)索引
索引(indexed):对分词后的数据(词组)建立索引关系(建立倒排索引表),索引的目的是为了搜索,最终实现的效果是只需要搜索分词后的词组就能找出对应的文档;
创建索引是对词组单元索引,通过词语找文档,这种索引的结构叫倒排索引结构。
原始文档:
doc-01: 华为5G智能全面屏手机
doc-02: vivo智能5G游戏手机
分词后的数据:
doc-01: 华为、5G、智能、全面屏、手机、全面屏手机
doc-02: vivo、智能、5G、游戏、手机、游戏手机
- 建立的索引(倒排索引表):
| Term | (Doc,Freq) |
|---|---|
| 华为 | (1) (1) |
| 5G | (1) (1) (2) (1) |
| 智能 | (1) (1) (2) (1) |
| 全面屏 | (1) (1) |
| 全面屏手机 | (1) (1) |
| 游戏 | (1) (1) |
| 手机 | (1) (1) (2) (1) |
| 游戏手机 | (2) (1) |
| vivo | (2) (1) |
建立索引其实就是建立词组与文档之间的关系,这个关系表就是倒排索引表,由于倒排索引表中也包含词组,因此索引建立的越多,占用的磁盘空间也会很大;
- 需要建立索引的域:商品名称,商品描述需要分词建立索引。商品编号,身份证号作为整体建立索引。只要将来要作为用户查询条件的词,都需要索引。
- 不需要建立索引的域:商品图片路径,不作为查询条件,不需要建立索引。
3)存储
存储(stored):由于索引库的数据都是从其他地方采集的(大多数是从关系型数据库中采集),因此其他地方已经存储一份原始数据,因此有些域我们是不需要存储到Lucenen的索引库的,只有那些需要搜索的域我们才存储到Lucene中;
- 需要存储的域:商品名称,商品价格。凡是将来在搜索结果页面展现给用户的内容,都需要存储。
- 不需要存储的域:商品描述。内容多格式大,不需要直接在搜索结果页面展现,不做存储。需要的时候可以从关系数据库取。
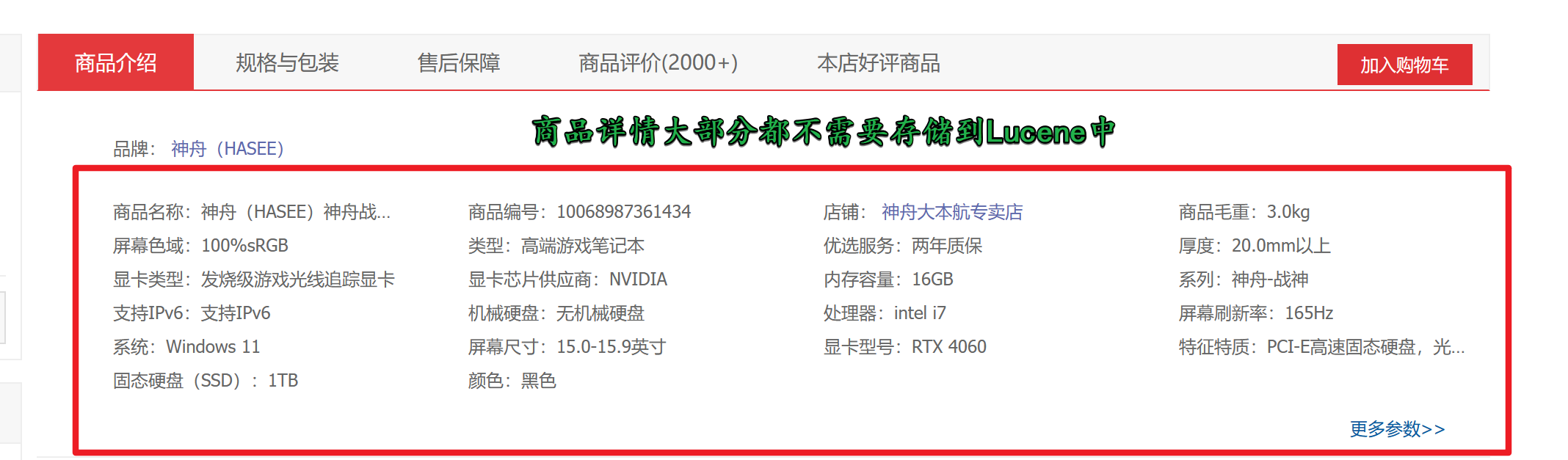
1.3.3 常用的Field种类
| Field种类 | 数据类型 | 是否分词 | 是否索引 | 是否存储 | 说明 |
|---|---|---|---|---|---|
| StringField(FieldName,FieldValue,Store.YES)) | 字符串 | N | Y | Y或N | 字符串类型Field,不分词,作为一个整体进行索引(比如:身份证号,商品编号),是否需要存储根据Store.YES或Store.NO决定 |
| DoublePoint(FieldName,FieldValue) | 数值型代表 | Y | Y | N | Double数值型Field代表,分词并且索引(比如:价格),不存储 |
| StoredField(FieldName,FieldValue) | 重载方法,支持多种类型 | N | N | Y | 构建不同类型的Field,不分词,不索引,只存储。(比如:商品图片路径) |
| TextField(FieldName,FieldValue,Store.NO) | 文本类型 | Y | Y | Y或N | 文本类型Field,分词并且索引,是否需要存储根据Store.YES或Store.NO决定 |
1.4 分词器
分词器,是将用户输入的一段文本,分析成符合逻辑的一种工具。到目前为止呢,分词器没有办法做到完全的符合人们的要求。和我们有关的分析器有英文的和中文的;
- 英文分词:
英文分词过程:输入文本-关键词切分-去停用词-形态还原-转为小写。
我们知道英文本身是以单词为单位,单词与单词之间,句子之间通常是空格、逗号、句号分隔。因此对于英文,可以简单的以空格来判断某个字符串是否是一个词,比如:I am Chinese,Chinese很容易被程序处理。
- 中文分词:
中文是以字为单位的,字与字再组成词,词再组成句子。中文:我是中国人,电脑不知道“是中”是一个词,还是“中国”是一个词?所以我们需要一定的规则来告诉电脑应该怎么切分,这就是中文分词器所要解决的问题。
- StandardAnalyzer分词器
一元切分法:一个字切分成一个词。
一元切分法“我是中国人”:我、是、中、国、人。扩展字库
- CJKAnalyzer分词器
二元切分法:把相邻的两个字,作为一个词。
二元切分法“我是中国人”:我是,是中、中国、国人。
- SmartChineseAnalyzer 词库分词器
通常一元切分法,二元切分法都不能满足我们的业务需求。SmartChineseAnalyzer,对中文支持较好,但是扩展性差,针对扩展词库、停用词均不好处理。
- IK-analyzer:IK分词器
最新版在 https://code.google.com/p/ik-analyzer/上,支持 Lucene 4.10 从 2006 年 12 月推出1.0 版开始, IKAnalyzer 已经推出了 4 个大版本。最初,它是以开源项目 Luence 为应用主体的,结合词典分词和文法分析算法的中文分词组件。从 3.0 版本开 始,IK 发展为面向 Java 的公用分词组件,独立 于 Lucene 项目,同时提供了对 Lucene 的默认优化实现。适合在项目中应用。
ik分词器本身就是对Lucene提供的分词器Analyzer扩展实现,使用方式与Lucene的分词器一致。
依赖:
<dependency><groupId>com.janeluo</groupId><artifactId>ikanalyzer</artifactId><version>2012_u6</version></dependency>但是IK分词器在2012年就不再更新了,在Lucene 5.4.0版本出现了部分兼容问题,因此我们本次使用的是:
<dependency><groupId>com.github.magese</groupId><artifactId>ik-analyzer</artifactId><version>8.5.0</version></dependency>相关文章:
Lucene的概述与应用场景(1)
文章目录 第1章 Lucene概述1.1 搜索的实现方案1.1.1 传统实现方案1.1.2 Lucene实现方案 1.2 数据查询方法1.1.1 顺序扫描法1.1.2 倒排索引法 1.3 Lucene相关概念1.3.1 文档对象1.3.2 域对象1)分词2)索引3)存储 1.3.3 常用的Field种类 1.4 分词…...

11.3笔记
在C#中,静态类和普通类(实例类)有一些关键的区别: 实例化: 普通类:可以被实例化,即创建对象。每个对象都有自己的状态和方法。静态类:不能被实例化,它们不包含构造函数&a…...
数据结构之线段树
线段树 线段树(Segment Tree)是一种高效的数据结构,广泛应用于计算机科学和算法中,特别是在处理区间查询和更新问题时表现出色。以下是对线段树的详细解释: 一、基本概念 线段树是一种二叉搜索树,是算法竞…...

vue 快速入门
文章目录 一、插值表达式 {{}}二、Vue 指令2.1 v-text 和 v-html:2.2 v-if 和 v-show:2.3 v-on:2.4 v-bind 和 v-model:2.5 v-for: 三、生命周期四、Vue 组件库 Element五、Vue 路由 本文章适用于后端人员,…...
iframe视频宽度高度自适应( pc+移动都可以用,jq写法 )
注意:要引入jquery 可以直接使用弹框播放iframe 一、创建 index.html <!DOCTYPE html> <html><head><meta charset"utf-8"><title></title><style>.modal {/* 默认隐藏 */display: none;position: fixed;z-i…...

Observability:OpenTelemetry Elastic 分发简介
作者:来自 Elastic Alexander Wert•Miguel Luna•Bahubali Shetti Elastic 自豪地推出了 Elastic Distributions of OpenTelemetry (EDOT),其中包含 Elastic 版本的 OpenTelemetry Collector 和多种语言 SDK,如 Python、Java、.NET 和 NodeJ…...

golang的RSA加密解密
参考:https://blog.csdn.net/lady_killer9/article/details/118026802 1.加密解密工具类PasswordUtil.go package utilimport ("crypto/rand""crypto/rsa""crypto/x509""encoding/pem""fmt""log"&qu…...

深度学习-梯度消失/爆炸产生的原因、解决方法
在深度学习模型中,梯度消失和梯度爆炸现象是限制深层神经网络有效训练的主要问题之一,这两个现象从本质上来说是由链式求导过程中梯度的缩小或增大引起的。特别是在深层网络中,若初始梯度在反向传播过程中逐层被放大或缩小,最后导…...
模式概述)
MVC(Model-View-Controller)模式概述
MVC(Model-View-Controller)是一种设计模式,最初由 Trygve Reenskaug 在 1970 年代提出,并在 Smalltalk 编程环境中得到了广泛应用。MVC 模式旨在实现用户界面和业务逻辑的分离,以增强应用程序的可维护性、可扩展性和复…...

数据结构 —— 红黑树
目录 1. 初识红黑树 1.1 红黑树的概念 1.2 红⿊树的规则 1.3 红黑树如何确保最长路径不超过最短路径的2倍 1.4 红黑树的效率:O(logN) 2. 红黑树的实现 2.1 红黑树的基础结构框架 2.2 红黑树的插⼊ 2.2.1 情况1:变色 2.2.2 情况2:单旋变色 2.2…...

《功能高分子学报》
《功能高分子学报》 中国标准连续出版物号:CN 31-1633/O6,国际标准连续出版物号:ISSN 1008-9357,邮发代号:4-629,刊期:双月刊。 《功能高分子学报》主要刊登功能高分子和其他高分子领域具有创新意义的学术…...

Linux特种文件系统--tmpfs文件系统
tmpfs类似于RamDisk(只能使用物理内存),使用虚拟内存(简称VM)子系统的页面存储文件。tmpfs完全依赖VM,遵循子系统的整体调度策略。说白了tmpfs跟普通进程差不多,使用的都是某种形式的虚拟内存&a…...
《基于STMF103的FreeRTOS内核移植》
目录 1.FreeRTOS资料下载与出处 1.1官网下载,网址:www.freertos.org 1.2在正点原子官网,任意STM32F1的开发板资料A盘里, 2.FreeRTOS移植重要文件讲解 2.1 FreeRTOS与FreeRTOS-Plus文件夹 2.2 Demo、Lincence、Source ●Demo文件…...

一七二、Vue3性能优化方式
Vue 3 的性能优化相较于 Vue 2 有了显著提升,利用新特性和改进方法可以更高效地构建和优化应用。以下是 Vue 3 的常见性能优化方法及示例。 1. 使用组合式 API (Composition API) Vue 3 引入的组合式 API,通过逻辑拆分和复用来实现更高效的代码组织和性…...

软件测试--BUG篇
博主主页: 码农派大星. 数据结构专栏:Java数据结构 数据库专栏:MySQL数据库 JavaEE专栏:JavaEE 软件测试专栏:软件测试 关注博主带你了解更多知识 目录 1. 软件测试的⽣命周期 2. BUG 1. BUG 的概念 2. 描述bug的要素 3.bug级别 4.bug的⽣命周期 5 与开发产⽣争执怎…...

Scikit-learn和Keras简介
一,Scikit-learn是一个开源的机器学习库,用于Python编程语言。它建立在NumPy、SciPy和matplotlib这些科学计算库之上,提供了简单有效的数据挖掘和数据分析工具。Scikit-learn库包含了许多用于分类、回归、聚类和降维的算法,包括支…...

python在word的页脚插入页码
1、插入简易页码 import win32com.client as win32 from win32com.client import constants import osdoc_app win32.gencache.EnsureDispatch(Word.Application)#打开word应用程序 doc_app.Visible Truedoc doc_app.Documents.Add() footer doc.Sections(1).Footers(cons…...

Java面试题十四
一、Java中的JNI(Java Native Interface)是什么?它有什么用途? Java中的JNI(Java Native Interface)是Java提供的一种编程框架,它允许Java代码与本地(Native)代码&#x…...

yarn : 无法加载文件,未对文件 进行数字签名。无法在当前系统上运行该脚本。
执行这个命令时报错:yarn --registryhttps://registry.npm.taobao.org yarn : 无法加载文件 C:\Users\Administrator\AppData\Roaming\npm\yarn.ps1。未对文件 C:\Users\Administ rator\AppData\Roaming\npm\yarn.ps1 进行数字签名。无法在当前系统上运行该脚本。有…...

Hadoop——HDFS
什么是HDFS HDFS(Hadoop Distributed File System)是Apache Hadoop的核心组件之一,是一个分布式文件系统,专门设计用于在大规模集群上存储和管理海量数据。它的设计目标是提供高吞吐量的数据访问和容错能力,以支持大数…...
)
ssm基于Java的试题库管理系统(10030)
有需要的同学,源代码和配套文档领取,加文章最下方的名片哦 一、项目演示 项目演示视频 二、资料介绍 完整源代码(前后端源代码SQL脚本)配套文档(LWPPT开题报告/任务书)远程调试控屏包运行一键启动项目&…...

泰米尔文TTS项目上线倒计时:ElevenLabs API v2.4.1强制启用新语音编码协议,旧集成方案将于2024年9月30日失效
更多请点击: https://intelliparadigm.com 第一章:泰米尔文TTS项目上线倒计时:ElevenLabs API v2.4.1强制启用新语音编码协议,旧集成方案将于2024年9月30日失效 ElevenLabs 已于 2024 年 7 月 15 日正式发布 API v2.4.1ÿ…...

免费Minecraft基岩版启动器终极指南:突破官方限制的完整解决方案
免费Minecraft基岩版启动器终极指南:突破官方限制的完整解决方案 【免费下载链接】BedrockLauncher 项目地址: https://gitcode.com/gh_mirrors/be/BedrockLauncher 还在为Minecraft基岩版官方启动器的功能限制而困扰吗?想要像Java版那样自由管理…...

3个技巧让FanControl风扇识别率提升90%:Windows 11用户的实战指南
3个技巧让FanControl风扇识别率提升90%:Windows 11用户的实战指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_…...
)
ElevenLabs泰米尔文TTS接入全链路详解:从API密钥配置、音色微调到低延迟流式响应(附3个避坑代码片段)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs泰米尔文TTS接入全链路详解:从API密钥配置、音色微调到低延迟流式响应(附3个避坑代码片段) ElevenLabs 自 2024 年起正式支持泰米尔语(ta-IN&a…...

3分钟搞定Figma中文界面:设计师必备的终极汉化方案
3分钟搞定Figma中文界面:设计师必备的终极汉化方案 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN 面对Figma满屏的英文界面感到困扰吗?专业术语看不懂、操作按钮…...

微软MOS认证-Word专家级|超全报考指南
不管是大学生还是职场人,Word 都是绕不开的工具。但多数人只会基础打字排版,面对长文档、规范报告时常常手忙脚乱。MOSWord 专家级认证,正是帮你把 “普通 Word” 变成 “高-效办公武器” 的实用路径。#微软mos认证 #大学生考证 #mos认证考试…...

别再只会用L298N了!用STM32高级定时器玩转H桥双极模式,精准控制直流电机转速与刹车
从L298N到STM32高级定时器:H桥双极模式下的直流电机精准控制实战 在嵌入式开发领域,直流电机控制一直是经久不衰的话题。许多开发者入门时都会选择L298N这类现成驱动模块,它们简单易用,却隐藏着响应迟滞、效率低下和功能局限等问题…...

tchMaterial-parser:5分钟快速上手,轻松获取国家中小学智慧教育平台电子课本的完整指南
tchMaterial-parser:5分钟快速上手,轻松获取国家中小学智慧教育平台电子课本的完整指南 【免费下载链接】tchMaterial-parser 国家中小学智慧教育平台 电子课本下载工具,帮助您从智慧教育平台中获取电子课本的 PDF 文件网址并进行下载&#x…...

AI自动化工具开发实战:从免费API整合到浏览器自动化
1. 项目概述与核心价值最近在GitHub上闲逛,发现了一个挺有意思的项目,叫ruwiss/ai-auto-free。光看名字,你可能会有点懵,“AI自动免费”?这到底是个啥玩意儿。我花了不少时间研究源码、测试功能,还把它部署…...