已解决:spark代码中sqlContext.createDataframe空指针异常
这段代码是使用local模式运行spark代码。但是在获取了spark.sqlContext之后,用sqlContext将rdd算子转换为Dataframe的时候报错空指针异常

Exception in thread "main" org.apache.spark.sql.AnalysisException: java.lang.RuntimeException: java.lang.NullPointerException;at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:106)at org.apache.spark.sql.hive.HiveExternalCatalog.databaseExists(HiveExternalCatalog.scala:194)at org.apache.spark.sql.internal.SharedState.externalCatalog$lzycompute(SharedState.scala:114)at org.apache.spark.sql.internal.SharedState.externalCatalog(SharedState.scala:102)at org.apache.spark.sql.hive.HiveSessionStateBuilder.externalCatalog(HiveSessionStateBuilder.scala:39)at org.apache.spark.sql.hive.HiveSessionStateBuilder.catalog$lzycompute(HiveSessionStateBuilder.scala:54)at org.apache.spark.sql.hive.HiveSessionStateBuilder.catalog(HiveSessionStateBuilder.scala:52)at org.apache.spark.sql.hive.HiveSessionStateBuilder$$anon$1.<init>(HiveSessionStateBuilder.scala:69)at org.apache.spark.sql.hive.HiveSessionStateBuilder.analyzer(HiveSessionStateBuilder.scala:69)at org.apache.spark.sql.internal.BaseSessionStateBuilder$$anonfun$build$2.apply(BaseSessionStateBuilder.scala:293)at org.apache.spark.sql.internal.BaseSessionStateBuilder$$anonfun$build$2.apply(BaseSessionStateBuilder.scala:293)at org.apache.spark.sql.internal.SessionState.analyzer$lzycompute(SessionState.scala:79)at org.apache.spark.sql.internal.SessionState.analyzer(SessionState.scala:79)at org.apache.spark.sql.execution.QueryExecution.analyzed$lzycompute(QueryExecution.scala:57)at org.apache.spark.sql.execution.QueryExecution.analyzed(QueryExecution.scala:55)at org.apache.spark.sql.execution.QueryExecution.assertAnalyzed(QueryExecution.scala:47)at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:74)at org.apache.spark.sql.SparkSession.createDataFrame(SparkSession.scala:300)at org.apache.spark.sql.SQLContext.createDataFrame(SQLContext.scala:272)at cn.itcast.xc.dimen.AreaDimInsert$.main(AreaDimInsert.scala:39)at cn.itcast.xc.dimen.AreaDimInsert.main(AreaDimInsert.scala)
Caused by: java.lang.RuntimeException: java.lang.NullPointerExceptionat org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:522)at org.apache.spark.sql.hive.client.HiveClientImpl.newState(HiveClientImpl.scala:180)at org.apache.spark.sql.hive.client.HiveClientImpl.<init>(HiveClientImpl.scala:114)at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)at java.lang.reflect.Constructor.newInstance(Constructor.java:423)at org.apache.spark.sql.hive.client.IsolatedClientLoader.createClient(IsolatedClientLoader.scala:264)at org.apache.spark.sql.hive.HiveUtils$.newClientForMetadata(HiveUtils.scala:385)at org.apache.spark.sql.hive.HiveUtils$.newClientForMetadata(HiveUtils.scala:287)at org.apache.spark.sql.hive.HiveExternalCatalog.client$lzycompute(HiveExternalCatalog.scala:66)at org.apache.spark.sql.hive.HiveExternalCatalog.client(HiveExternalCatalog.scala:65)at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$databaseExists$1.apply$mcZ$sp(HiveExternalCatalog.scala:195)at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$databaseExists$1.apply(HiveExternalCatalog.scala:195)at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$databaseExists$1.apply(HiveExternalCatalog.scala:195)at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:97)... 20 more
Caused by: java.lang.NullPointerExceptionat java.lang.ProcessBuilder.start(ProcessBuilder.java:1012)at org.apache.hadoop.util.Shell.runCommand(Shell.java:482)at org.apache.hadoop.util.Shell.run(Shell.java:455)at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:715)at org.apache.hadoop.util.Shell.execCommand(Shell.java:808)at org.apache.hadoop.util.Shell.execCommand(Shell.java:791)at org.apache.hadoop.fs.RawLocalFileSystem.setPermission(RawLocalFileSystem.java:656)at org.apache.hadoop.fs.RawLocalFileSystem.mkdirs(RawLocalFileSystem.java:444)at org.apache.hadoop.fs.FilterFileSystem.mkdirs(FilterFileSystem.java:293)at org.apache.hadoop.hive.ql.session.SessionState.createPath(SessionState.java:639)at org.apache.hadoop.hive.ql.session.SessionState.createSessionDirs(SessionState.java:567)at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:508)... 35 moresqlContext不为空指针,area也不为空指针,这个错的排查还是比较难的。
经发现,是本地模式下,如果在windows环境下运行该代码,并且windows没有配置HADOOP_HOME环境变量就会报这个错
这里直接给出解决方案
链接:https://pan.baidu.com/s/17Oy_CHoHBFYGk3-fCo8bJw
提取码:jco5

将这个路径配置成HADOOP_HOME的环境变量

重启idea,再次运行代码,即可解决上述问题
把winutils.exe复制到HADOOP_HOME⽬录内bin⽬录下, 如下图所示:


相关文章:
已解决:spark代码中sqlContext.createDataframe空指针异常
这段代码是使用local模式运行spark代码。但是在获取了spark.sqlContext之后,用sqlContext将rdd算子转换为Dataframe的时候报错空指针异常 Exception in thread "main" org.apache.spark.sql.AnalysisException: java.lang.RuntimeException: java.lang.Nu…...

flutter字体大小切换案例 小字体,标准字体,大字体,超大字体案例
flutter字体大小切换案例 小字体,标准字体,大字体,超大字体案例 Android iOS设备带有选择记录 我的flutter项目版本 environment: sdk: ‘>3.4.4 <4.0.0’ 图片案例 pubspec.yaml 添加依赖 # 屏幕尺寸适配 https://github.com/OpenF…...

智慧建造-运用Trimble技术将梦幻水族馆变为现实【上海沪敖3D】
项目概述 西雅图水族馆耗资1.6亿美元对海洋馆进行扩建。该项目包括建造三个大型栖息地,每个建筑物几乎都没有直边,其中一个主栖息地由520立方米混凝土和355吨钢筋组成。特纳建筑公司的混凝土团队通过强大的贸易合作伙伴和创新的数字制造技术,…...

【NOIP提高组】计算系数
【NOIP提高组】计算系数 C语言实现C实现Java实现Python实现 💐The Begin💐点点关注,收藏不迷路💐 给定一个多项式 (ax by)^k ,请求出多项式展开后 x^n y^m 项的系数。 输入 共一行,包含 5 个整数&#x…...

IDEA部署AI代写插件
前言 Hello大家好,当下是AI盛行的时代,好多好多东西在AI大模型的趋势下都变得非常的简单。 比如之前想画一幅风景画得先去采风,然后写实什么的,现在你只需描述出你想要的效果AI就能够根据你的描述在几分钟之内画出一幅你想要的风景…...

【阅读记录-章节1】Build a Large Language Model (From Scratch)
目录 1. Understanding large language models1.1 What is an LLM?补充介绍人工智能、机器学习和深度学习的关系机器学习 vs 深度学习传统机器学习 vs 深度学习(以垃圾邮件分类为例) 1.2 Applications of LLMs1.3 Stages of building and using LLMs1.4…...

微服务day08
Elasticsearch 需要安装elasticsearch和Kibana,应为Kibana中有一套控制台可以方便的进行操作。 安装elasticsearch 使用docker命令安装: docker run -d \ --name es \-e "ES_JAVA_OPTS-Xms512m -Xmx512m" \ //设置他的运行内存空间&#x…...

JAVA接入WebScoket行情接口
Java脚好用的库很多,开发效率一点不输Python。如果是日内策略,需要更实时的行情数据,不然策略滑点太大,容易跑偏结果。 之前爬行情网站提供的level1行情接口,实测平均更新延迟达到了6秒,超过10只股票并发请…...

使用Axios函数库进行网络请求的使用指南
目录 前言1. 什么是Axios2. Axios的引入方式2.1 通过CDN直接引入2.2 在模块化项目中引入 3. 使用Axios发送请求3.1 GET请求3.2 POST请求 4. Axios请求方式别名5. 使用Axios创建实例5.1 创建Axios实例5.2 使用实例发送请求 6. 使用async/await简化异步请求6.1 获取所有文章数据6…...

Vue2+ElementUI:用计算属性实现搜索框功能
前言: 本文代码使用vue2element UI。 输入框搜索的功能,可以在前端通过计算属性过滤实现,也可以调用后端写好的接口。本文介绍的是通过计算属性对表格数据实时过滤,后附完整代码,代码中提供的是死数据,可…...

抖音热门素材去哪找?优质抖音视频素材网站推荐!
是不是和我一样,刷抖音刷到停不下来?越来越多的朋友希望在抖音上创作出爆款视频,但苦于没有好素材。今天就来推荐几个超级实用的抖音视频素材网站,让你的视频内容立刻变得高大上!这篇满是干货,直接上重点&a…...

spring-cache concurrentHashMap 自定义过期时间
1.自定义实现缓存构建工厂 import java.util.concurrent.ConcurrentHashMap; import java.util.concurrent.ConcurrentMap;import lombok.Getter; import lombok.Setter; import org.springframework.beans.factory.BeanNameAware; import org.springframework.beans.factory.…...

解析传统及深度学习目标检测方法的原理与具体应用之道
深度学习目标检测算法 常用的深度学习的目标检测算法及其原理和具体应用方法: R-CNN(Region-based Convolutional Neural Networks)系列1: 原理: 候选区域生成:R-CNN 首先使用传统的方法(如 Se…...

shell数组
文章目录 🍊自我介绍🍊shell数组概述🍊Shell数组使用方法数组的定义直接定义单元素定义 元素的获取获取单个元素获取全部元素 获取数组长度获取整个数组长度获取单个元素的长度 操作数组增加删除 关联数组 🍊 你的点赞评论就是对博…...

高斯混合模型回归(Gaussian Mixture Model Regression,GMM回归)
高斯混合模型(GMM)是一种概率模型,它假设数据是由多个高斯分布的混合组成的。在高斯混合回归中,聚类与回归被结合成一个联合模型: 聚类部分 — 使用高斯混合模型进行聚类,识别数据的不同簇。回归部分 — 对…...

【3D Slicer】的小白入门使用指南八
3D Slicer DMRI(Diffusion MRI)-扩散磁共振认识和使用 0、简介 大脑解剖 ● 白质约占大脑的 45% ● 有髓神经纤维(大约10微米轴突直径) 白质探索 朱尔斯约瑟夫德杰林(Jules Joseph Dejerine,《神经中心解剖学》(巴黎,1890-1901):基于髓磷脂染色标本的神经解剖图谱)…...

【流量分析】常见webshell流量分析
免责声明:本文仅作分享! 对于常见的webshell工具,就要知攻善防;后门脚本的执行导致webshell的连接,对于默认的脚本要了解,才能更清晰,更方便应对。 (这里仅针对部分后门代码进行流量…...

基于树莓派的边缘端 AI 目标检测、目标跟踪、姿态估计 视频分析推理 加速方案:Hailo with ultralytics YOLOv8 YOLOv11
文件大纲 加速原理硬件安装软件安装基本设置系统升级docker 方案Demo 测试目标检测姿态估计视频分析参考文献前序树莓派文章hailo加速原理 Hailo 发布的 Raspberry Pi AI kit 加速原理,有几篇文章介绍的不错 https://ubuntu.com/blog/hackers-guide-to-the-raspberry-pi-ai-ki…...

Java在算法竞赛中的常用方法
在算法竞赛中,Java以其强大的标准库和高效的性能成为了众多参赛者的首选语言。本文将详细介绍Java在算法竞赛中的常用集合、字符串处理、进制转换、大数处理以及StringBuilder的使用技巧,帮助你在竞赛中更加得心应手。 常用集合 Java的集合框架提供了多…...
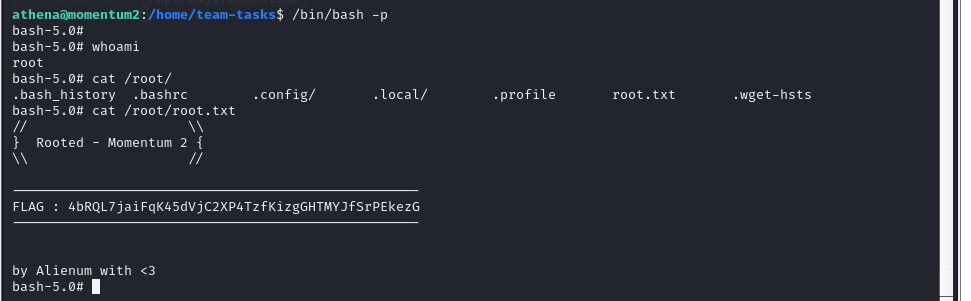
Vulnhub靶场案例渗透[10]- Momentum2
文章目录 一、靶场搭建1. 靶场描述2. 下载靶机环境3. 靶场搭建 二、渗透靶场1. 确定靶机IP2. 探测靶场开放端口及对应服务3. 扫描网络目录结构4. 代码审计5. 反弹shell6. 提权 一、靶场搭建 1. 靶场描述 - Difficulty : medium - Keywords : curl, bash, code reviewThis wor…...
)
ctfshow-web进阶-命令执行绕过技巧(web71-web74)
1. 命令执行漏洞基础与CTF常见场景 命令执行漏洞(Command Execution)是Web安全中一种高危漏洞,它允许攻击者在服务器上执行任意系统命令。在CTF比赛中,这类题目通常会模拟真实环境中开发者未对用户输入进行严格过滤的场景。 我刚开…...

GLM-OCR服务监控与运维指南:使用Prometheus与Grafana搭建看板
GLM-OCR服务监控与运维指南:使用Prometheus与Grafana搭建看板 想象一下,你负责的GLM-OCR服务正在线上稳定运行,突然接到业务方反馈,说图片识别接口响应变慢了。你第一反应是什么?是登录服务器看日志,还是去…...

ARM Cortex-M嵌入式通用头文件sarmfsw深度解析
1. sarmfsw项目概述sarmfsw(ARM-based Common Headers)是一个面向ARM Cortex-M系列微控制器的轻量级、跨平台通用头文件集合。它并非传统意义上的功能库,而是一套经过工程验证的类型定义(typedefs)、宏(mac…...
的跨模态融合应用)
Mirage Flow 与卷积神经网络(CNN)的跨模态融合应用
Mirage Flow 与卷积神经网络(CNN)的跨模态融合应用 你有没有想过,让机器不仅能“看见”图片,还能像人一样“理解”并“描述”图片里的故事?比如,给一张复杂的医学影像,它不仅能圈出病灶&#x…...
)
告别Swagger注解污染:用smart-doc + Maven插件5分钟生成整洁API文档(SpringBoot实战)
零侵入API文档革命:smart-doc在SpringBoot项目中的极致实践 如果你曾经被Swagger注解污染代码所困扰,或是厌倦了在业务逻辑中嵌入大量文档相关注解,那么smart-doc可能会成为你API文档管理的新选择。作为一款基于源码解析的文档生成工具&#…...

效率倍增:基于快马平台集成最新openclaw构建自动化采集工具
最近在做一个数据采集项目时,发现手动写爬虫实在太费时间了。每次都要重复处理请求头、代理设置、数据清洗这些基础工作,效率特别低。后来发现了openclaw这个工具包的新版本,正好结合InsCode(快马)平台快速搭建了一个自动化采集工具ÿ…...

ENet核心架构深度解析:从主机管理到对等通信
ENet核心架构深度解析:从主机管理到对等通信 【免费下载链接】enet ENet reliable UDP networking library 项目地址: https://gitcode.com/gh_mirrors/en/enet ENet是一款高性能的可靠UDP网络库,专为实时多人游戏和低延迟应用设计。它通过创新的…...

3步实现BERT模型轻量化部署与性能优化:基于Torch-Pruning的结构化剪枝指南
3步实现BERT模型轻量化部署与性能优化:基于Torch-Pruning的结构化剪枝指南 【免费下载链接】Torch-Pruning [CVPR 2023] Towards Any Structural Pruning; LLMs / Diffusion / Transformers / YOLOv8 / CNNs 项目地址: https://gitcode.com/gh_mirrors/to/Torch-P…...

交叉编译microcom
由于默认的busybox没有支持microcom工具,也没有提供源码,所以需要自己交叉编译microcom工具。 microcom工具 https://packages.ubuntu.com/zh-cn/plucky/microcom 下载ubuntu带的软件包microcom,下载microcom_2023.09.0.orig.tar.xz版本&…...

Graphormer图神经网络效果展示:含手性中心/立体异构体分子的预测能力验证
Graphormer图神经网络效果展示:含手性中心/立体异构体分子的预测能力验证 1. 模型概述 Graphormer是一种基于纯Transformer架构的图神经网络,专门为分子图(原子-键结构)的全局结构建模与属性预测而设计。该模型在OGB(…...