【阅读记录-章节1】Build a Large Language Model (From Scratch)
目录
- 1. Understanding large language models
- 1.1 What is an LLM?
- 补充介绍
- 人工智能、机器学习和深度学习的关系
- 机器学习 vs 深度学习
- 传统机器学习 vs 深度学习(以垃圾邮件分类为例)
- 1.2 Applications of LLMs
- 1.3 Stages of building and using LLMs
- 1.4 Introducing the transformer architecture
- 1.5 Utilizing large datasets
- 1.6 A closer look at the GPT architecture
- 1.7 Building a large language model
- 总结:
1. Understanding large language models
大语言模型(LLMs) 如ChatGPT,依托深度学习和transformer架构,能够在多种自然语言处理(NLP)任务中表现出色,尤其是在理解、生成和处理复杂语言方面。
与传统的NLP模型不同,LLMs不仅能够完成如文本分类和翻译等特定任务,还能处理更具挑战性的任务,如解析复杂指令和生成连贯的原创文本。这些模型的成功得益于大规模文本数据的训练和transformer架构的应用,使它们能够捕捉语言中的深层次语境和细节。
正是这种技术进步,推动了NLP领域的变革,使得我们能够使用更强大的工具与人类语言进行互动。接下来的讨论将基于transformer架构,逐步实现一个类似ChatGPT的LLM,帮助理解LLMs的工作原理。
1.1 What is an LLM?
LLM(Large Language Model)是一种神经网络,旨在理解、生成和回应类人文本。这些模型通常是深度神经网络,经过大量文本数据的训练,数据量通常覆盖了互联网上的公共文本。
-
"Large"的含义:大语言模型中的“large”指的是两个方面:
- 模型大小:通常这些模型拥有数十亿甚至数百亿个参数。参数是模型在训练过程中需要优化的权重,用来预测文本中的下一个单词。
- 训练数据集的规模:这些模型训练所使用的数据集通常非常庞大,包括了互联网上的海量文本。
-
训练目标:大语言模型的核心任务之一是“下一个词预测”。这是因为语言本身具有序列性,模型通过学习上下文、结构和文本之间的关系来理解语言。因此,尽管“下一个词预测”看似是一个简单任务,但它却能生成非常强大的模型。
LLM通常使用Transformer架构,这是当前自然语言处理领域最流行的架构之一。Transformer的关键特点是它能够在生成文本时选择性地关注输入文本的不同部分,从而帮助模型更好地理解语言的细微差别。
- Transformer的优点是它能并行处理输入序列中的所有部分,而不是像传统的循环神经网络(RNN)那样逐步处理,从而加速训练和提高性能。
LLM常被视为 生成性人工智能(Generative AI, GenAI) 的一种形式。生成性AI指的是利用深度神经网络创造新的内容,比如文本、图像或其他媒体形式。LLM的目标是生成与人类语言相似的文本,因此它也属于生成性人工智能的范畴。

补充介绍
人工智能、机器学习和深度学习的关系
-
人工智能(AI):人工智能是一个广泛的领域,旨在让机器具备类似人类的智能。这包括理解语言、识别模式和做出决策等任务。
-
机器学习(Machine Learning, ML):机器学习是人工智能的一个子领域,致力于开发能够从数据中学习并基于数据做出预测或决策的算法。
-
深度学习(Deep Learning, DL):深度学习是机器学习的一个子领域,专注于使用多层神经网络(即深度神经网络)来建模复杂的数据模式。
机器学习 vs 深度学习
-
传统机器学习:在传统的机器学习方法中,特征提取是由人工完成的。例如,在垃圾邮件过滤任务中,专家会手动选择特征(如特定词汇的出现频率、感叹号的数量或邮件中的链接等)来训练模型。
-
深度学习:深度学习则不需要人工提取特征。深度学习算法能够自动从原始数据中学习和提取特征,并建模更复杂的模式和关系。因此,深度学习可以处理更为复杂和多样化的数据集,而无需依赖人工设计的特征。
传统机器学习 vs 深度学习(以垃圾邮件分类为例)
-
在传统的机器学习中,模型训练依赖于人工选择的特征。专家通过分析数据并挑选出重要的特征,来构建训练数据集。
-
在深度学习中,模型通过对数据进行训练,自动学习到哪些特征最为重要,从而提高预测的准确性,不需要人工干预。
1.2 Applications of LLMs
由于大语言模型(LLMs)具备解析和理解非结构化文本数据的强大能力,它们在多个领域中具有广泛的应用。以下是LLMs的一些主要应用:
- 机器翻译:LLMs被广泛应用于不同语言之间的翻译任务。
- 文本生成:LLMs能够生成新的文本,例如写作小说、文章,甚至计算机代码。
- 情感分析:分析文本中的情感倾向,例如判定评论或文章是正面、负面还是中立。
- 文本摘要:将长篇文章或内容进行总结,提取核心信息。
- 内容创作:LLMs在创作内容方面表现出色,如自动写作小说、文章等。
- 聊天机器人和虚拟助手:如OpenAI的ChatGPT和谷歌的Gemini(前身为Bard),这些应用可以回答用户问题并增强传统搜索引擎(如谷歌搜索或微软Bing)的功能。
- 知识检索:LLMs能够高效地从大量的专业领域文本中提取知识,例如医学和法律领域。这包括查阅文档、总结长篇段落,并回答技术性问题。
LLM的潜力与未来:LLMs能够自动化几乎所有涉及文本解析和生成的任务,其应用几乎是无限的。随着技术的不断创新和新的使用场景的探索,LLMs有可能重新定义我们与技术的关系,使其更加对话化、直观且易于访问。
1.3 Stages of building and using LLMs
从零开始编写一个大语言模型(LLM)是一个非常好的练习,它能帮助我们深入理解模型的工作原理和局限性。此外,构建自己的LLM还为我们提供了预训练或微调现有开源LLM架构的知识,使我们能够将模型应用于特定领域的数据集或任务。
PyTorch与LLM
目前,许多大语言模型是使用PyTorch深度学习库实现的,这也是我们将使用的工具。对于PyTorch的全面介绍,请参见附录A。
研究表明,定制的大语言模型(特别是为特定任务或领域量身定制的LLMs)在性能上往往优于通用的大语言模型(如ChatGPT),后者是为广泛的应用场景设计的。定制模型的例子包括BloombergGPT(专为金融领域设计)和专为医学问答设计的LLMs(有关更多细节,请见附录B)。
定制LLM的另一个显著优势是数据隐私。例如,企业可能不希望将敏感数据与第三方LLM提供商(如OpenAI)共享,因为存在保密性问题。此外,开发较小的定制LLM能够直接在客户设备(如笔记本电脑和智能手机)上部署,这是像苹果公司等公司正在探索的方向。这样做不仅可以大幅减少延迟,还能降低服务器相关的成本。
定制LLM还给予开发人员完全的控制权,使他们可以根据需要更新或修改模型。
创建LLM的流程
创建LLM的通用流程包括预训练和微调。
- 预训练阶段,指的是对模型进行初步训练,通常是在一个大型、多样化的数据集上训练,以开发模型对语言的广泛理解。此阶段的模型被称为预训练模型,例如GPT-3模型,它能够执行基本的文本补全任务,并具有有限的少量样本学习(few-shot learning)能力。
- 微调是对模型进行进一步训练,使其能够执行特定任务或应用。微调阶段,通常使用较小的标注数据集,来训练模型专注于某些领域或任务。

预训练和微调的具体步骤
-
预训练:首先,我们需要使用大规模的文本数据对LLM进行训练,这些数据通常是未标注的文本(即“原始文本”)。在这个阶段,模型使用自监督学习,通过预测文本中的下一个单词来“生成”标签,从而学习语言的结构和模式。
-
微调:当我们有了一个经过预训练的LLM后,可以使用标注数据进行微调。微调分为两类:
- 指令微调:使用包含问题和答案对的标注数据集(如翻译任务中的问题和正确翻译文本)。
- 分类微调:使用包含文本和相应类别标签的数据集(如垃圾邮件分类任务中的“垃圾邮件”和“非垃圾邮件”标签)。
微调后的LLM可以完成更多复杂的任务,如文本分类、翻译和问答等。
通过从头开始构建LLM,我们不仅能深入理解LLM的工作机制和局限性,还能获得定制和优化现有开源LLM模型的能力,特别是针对特定领域的任务。同时,定制LLM有助于解决数据隐私问题,并可部署在本地设备上,减少延迟和服务器成本。在LLM的开发过程中,预训练和微调是两个关键步骤,前者通过大量数据训练模型,后者则通过特定任务的标注数据进行精细化训练。
1.4 Introducing the transformer architecture
现代大型语言模型(LLMs)依赖于Transformer架构,它是一种深度神经网络架构,最初在2017年的论文《Attention Is All You Need》中提出。理解LLMs需要先理解原始的Transformer,它最初是为机器翻译任务设计的,旨在将英文文本翻译为德语或法语。
Transformer架构包括两个子模块:编码器(Encoder)和解码器(Decoder)。编码器处理输入的文本,并将其编码成一系列数字表示(向量),这些向量捕捉了输入文本的上下文信息。然后,解码器利用这些编码向量生成输出文本。在机器翻译任务中,编码器会将源语言的文本编码成向量,解码器则解码这些向量,生成目标语言的文本。

关键的组件是自注意力机制(Self-attention),它允许模型根据每个词或标记之间的相对重要性来加权它们。这使得模型能够捕捉到输入数据中的长程依赖关系和上下文关系,从而增强生成连贯且符合上下文的输出的能力。
之后,Transformer架构的变体,如BERT和GPT,在此基础上进行了改进,并被用于不同的任务。BERT专注于掩码词预测,它的训练方式与GPT不同,BERT通过预测句子中被遮蔽的词来训练,因此特别适合用于文本分类任务,如情感分析和文档分类。而GPT则主要关注生成任务,如文本生成、机器翻译和编写代码等。

GPT模型被设计为文本补全任务的生成模型,并具备显著的多功能性,能够进行零-shot学习和少-shot学习。零-shot学习指的是在没有任何具体示例的情况下完成任务,而少-shot学习则是在只提供少量示例的情况下进行学习。

最终,Transformer和LLMs通常是可以互换使用的术语,但并非所有Transformer模型都是LLMs,也并非所有LLMs都基于Transformer架构。虽然LLMs的计算效率可以通过其他架构(如循环神经网络或卷积神经网络)进行改进,但这些替代架构能否与基于Transformer的LLMs竞争,以及它们是否会被实际采用,还需要进一步观察。
1.5 Utilizing large datasets
大型语言模型(LLMs),如GPT-3,如何使用庞大的、多样化的训练数据集进行预训练。这些数据集涵盖了各种主题,包括自然语言和计算机语言。
例如,GPT-3的预训练数据集如下表所示:
| 数据集名称 | 数据集描述 | 令牌数量 | 数据在训练中的比例 |
|---|---|---|---|
| CommonCrawl(过滤) | 网络爬虫数据 | 4100亿 | 60% |
| WebText2 | 网络爬虫数据 | 190亿 | 22% |
| Books1 | 基于互联网的书籍语料 | 120亿 | 8% |
| Books2 | 基于互联网的书籍语料 | 550亿 | 8% |
| Wikipedia | 高质量文本 | 30亿 | 3% |
数据集中的“令牌”是模型读取的文本单位,令牌的数量大致等于文本中的单词和标点符号的数量。GPT-3模型的预训练数据集包含了大约3000亿个令牌,尽管其中有4990亿个令牌在数据集中。这些庞大的数据集使得模型能够在语言语法、语义和上下文等多种任务中表现良好。
进一步的GPT-3模型变体(如Meta的LLaMA)还扩展了训练数据源,加入了如Arxiv研究论文和StackExchange代码相关Q&A等数据。
GPT-3的预训练需要大量资源,估计成本为460万美元。然而,许多预训练模型作为开源工具提供,可以用于文本的写作、提取和编辑。LLMs还可以通过较小的数据集进行微调,从而提高在特定任务中的表现,并减少计算资源的需求。
我们将编写预训练代码来学习如何在消费级硬件上完成LLM预训练,并使用开源模型的权重来省去高成本的预训练步骤,实现微调。
1.6 A closer look at the GPT architecture
-
GPT的起源和发展:
- GPT(生成式预训练模型)最早由OpenAI在论文《通过生成式预训练改进语言理解》中提出。GPT-3是这个模型的扩展版本,拥有更多的参数,并在更大规模的数据集上进行训练。
- ChatGPT的原始版本是通过对GPT-3进行微调得到的,微调使用的是OpenAI在InstructGPT论文中提出的大规模指令数据集。
-
任务能力与训练方法:
- GPT模型的预训练任务非常简单——“预测下一个词”。这个任务属于一种“自监督学习”,即模型通过预测文本中的下一个词来自动生成训练标签,因此可以使用大规模的无标签文本进行训练。
- 通过这种方法,GPT不仅能完成文本补全,还能进行拼写检查、分类、翻译等多种任务。这种多任务能力很特别,因为GPT的训练目标只是预测下一个词,而并非专门针对特定任务。
-
自回归生成过程:
- GPT使用的“解码器”架构是原始Transformer架构的一部分,适用于自回归生成。每次生成一个词,该词会成为下一次预测的输入,这样一轮接一轮地生成完整的文本,使生成结果更加连贯。
-
模型规模的扩展:
- GPT-3具有96层Transformer层和1750亿参数,大大超越了最初的Transformer架构(编码器和解码器各6层)。这种规模的增加提升了模型的理解和生成能力。
-
突现行为(Emergent Behavior):
- 由于GPT在多语言和多样化的文本数据上训练,出现了“突现行为”——模型可以执行一些没有明确训练的任务,如翻译。这种能力表明,通过大规模数据的训练,模型可以自发地“学习”某些复杂的模式。

总结来说,GPT的架构虽然简单,但通过大量数据的预训练,实现了多种自然语言处理任务。这些任务并不是专门设计的,而是基于模型在多语言、多情境数据中的训练,自发地涌现出的能力。
1.7 Building a large language model
大型语言模型开发的三阶段:构建、预训练与微调
这张图展示了从头开始构建一个大型语言模型(LLM)的三个主要阶段:
Stage 1:LLM 的基础构建
- 数据准备和采样(Data preparation & sampling):这一步骤主要是收集和处理数据。因为大型语言模型需要大量的数据来进行训练,所以这里的数据准备包括采样、清洗和标注等过程。
- 注意力机制(Attention mechanism):实现并理解注意力机制是构建 LLM 的关键步骤。注意力机制允许模型更好地理解句子中的重要词汇及其关系。
- LLM 架构设计(LLM architecture):这一步是设计模型的整体架构,包括层数、维度、编码方式等。常见的架构有 Transformer、GPT、BERT 等。
- 预训练(Pretraining):在完成前几步之后,将模型在大量无标签数据上进行预训练。这是为了让模型学习到语言的基本结构和词汇关系。
在这个阶段结束后,得到了一个基础的 LLM,实现了数据采样、注意力机制和架构的基础。
Stage 2:构建基础模型(Foundation Model)
- 训练循环(Training loop):这一阶段的核心是建立训练循环。模型会在大量数据上进行训练,逐步优化参数,使其在语言任务上表现得更好。
- 模型评估(Model evaluation):训练过程中,需要定期评估模型性能,查看是否收敛或是否需要调整超参数。
- 加载预训练权重(Load pretrained weights):在一些情况下,可以加载已有的预训练权重进行微调,避免从头开始训练。
在这个阶段的末尾,得到了一个基础模型(Foundation Model),可以用作进一步任务的微调(fine-tuning)。
Stage 3:微调模型
- 微调分类器(Fine-tuning for classification):在一些任务中,基础模型会被微调以实现分类功能。这里需要一个有标签的数据集,通过训练让模型能够准确分类。
- 微调为助手模型(Fine-tuning for a personal assistant):在其他任务中,可以将基础模型微调成一个助手或对话模型,通过带有指令的数据集训练,让模型能够回答问题或提供交互支持。
最后,经过微调后,得到了特定任务的模型,例如分类器或个人助手(聊天模型)。
总结:
-
LLM对NLP的影响:LLM革新了自然语言处理(NLP)领域,从以往基于规则和简单统计方法转向深度学习方法,提升了机器对人类语言的理解、生成和翻译能力。
-
LLM的训练步骤:
- 预训练:在无标签的大规模文本数据上进行预训练,采用预测句子下一个词的方式。
- 微调:在较小的有标签数据集上微调,以执行指令或分类任务。
-
架构基础:LLM基于Transformer架构,其核心是注意力机制,使模型在逐词生成时可以选择性地访问输入序列的全部信息。
-
Transformer架构组成:原始架构包括用于解析文本的编码器和生成文本的解码器。GPT-3和ChatGPT等生成型LLM仅使用解码器模块,简化了架构。
-
大规模数据需求:LLM的预训练需要包含数十亿词的大规模数据集。
-
涌现能力:虽然LLM的预训练任务只是预测下一个词,但模型在分类、翻译和总结等任务上展现出涌现的能力。
-
微调效率:预训练后的LLM基础模型可通过微调更高效地执行下游任务,在特定任务上表现优于通用LLM。
相关文章:
【阅读记录-章节1】Build a Large Language Model (From Scratch)
目录 1. Understanding large language models1.1 What is an LLM?补充介绍人工智能、机器学习和深度学习的关系机器学习 vs 深度学习传统机器学习 vs 深度学习(以垃圾邮件分类为例) 1.2 Applications of LLMs1.3 Stages of building and using LLMs1.4…...

微服务day08
Elasticsearch 需要安装elasticsearch和Kibana,应为Kibana中有一套控制台可以方便的进行操作。 安装elasticsearch 使用docker命令安装: docker run -d \ --name es \-e "ES_JAVA_OPTS-Xms512m -Xmx512m" \ //设置他的运行内存空间&#x…...

JAVA接入WebScoket行情接口
Java脚好用的库很多,开发效率一点不输Python。如果是日内策略,需要更实时的行情数据,不然策略滑点太大,容易跑偏结果。 之前爬行情网站提供的level1行情接口,实测平均更新延迟达到了6秒,超过10只股票并发请…...

使用Axios函数库进行网络请求的使用指南
目录 前言1. 什么是Axios2. Axios的引入方式2.1 通过CDN直接引入2.2 在模块化项目中引入 3. 使用Axios发送请求3.1 GET请求3.2 POST请求 4. Axios请求方式别名5. 使用Axios创建实例5.1 创建Axios实例5.2 使用实例发送请求 6. 使用async/await简化异步请求6.1 获取所有文章数据6…...

Vue2+ElementUI:用计算属性实现搜索框功能
前言: 本文代码使用vue2element UI。 输入框搜索的功能,可以在前端通过计算属性过滤实现,也可以调用后端写好的接口。本文介绍的是通过计算属性对表格数据实时过滤,后附完整代码,代码中提供的是死数据,可…...

抖音热门素材去哪找?优质抖音视频素材网站推荐!
是不是和我一样,刷抖音刷到停不下来?越来越多的朋友希望在抖音上创作出爆款视频,但苦于没有好素材。今天就来推荐几个超级实用的抖音视频素材网站,让你的视频内容立刻变得高大上!这篇满是干货,直接上重点&a…...

spring-cache concurrentHashMap 自定义过期时间
1.自定义实现缓存构建工厂 import java.util.concurrent.ConcurrentHashMap; import java.util.concurrent.ConcurrentMap;import lombok.Getter; import lombok.Setter; import org.springframework.beans.factory.BeanNameAware; import org.springframework.beans.factory.…...

解析传统及深度学习目标检测方法的原理与具体应用之道
深度学习目标检测算法 常用的深度学习的目标检测算法及其原理和具体应用方法: R-CNN(Region-based Convolutional Neural Networks)系列1: 原理: 候选区域生成:R-CNN 首先使用传统的方法(如 Se…...

shell数组
文章目录 🍊自我介绍🍊shell数组概述🍊Shell数组使用方法数组的定义直接定义单元素定义 元素的获取获取单个元素获取全部元素 获取数组长度获取整个数组长度获取单个元素的长度 操作数组增加删除 关联数组 🍊 你的点赞评论就是对博…...

高斯混合模型回归(Gaussian Mixture Model Regression,GMM回归)
高斯混合模型(GMM)是一种概率模型,它假设数据是由多个高斯分布的混合组成的。在高斯混合回归中,聚类与回归被结合成一个联合模型: 聚类部分 — 使用高斯混合模型进行聚类,识别数据的不同簇。回归部分 — 对…...

【3D Slicer】的小白入门使用指南八
3D Slicer DMRI(Diffusion MRI)-扩散磁共振认识和使用 0、简介 大脑解剖 ● 白质约占大脑的 45% ● 有髓神经纤维(大约10微米轴突直径) 白质探索 朱尔斯约瑟夫德杰林(Jules Joseph Dejerine,《神经中心解剖学》(巴黎,1890-1901):基于髓磷脂染色标本的神经解剖图谱)…...

【流量分析】常见webshell流量分析
免责声明:本文仅作分享! 对于常见的webshell工具,就要知攻善防;后门脚本的执行导致webshell的连接,对于默认的脚本要了解,才能更清晰,更方便应对。 (这里仅针对部分后门代码进行流量…...

基于树莓派的边缘端 AI 目标检测、目标跟踪、姿态估计 视频分析推理 加速方案:Hailo with ultralytics YOLOv8 YOLOv11
文件大纲 加速原理硬件安装软件安装基本设置系统升级docker 方案Demo 测试目标检测姿态估计视频分析参考文献前序树莓派文章hailo加速原理 Hailo 发布的 Raspberry Pi AI kit 加速原理,有几篇文章介绍的不错 https://ubuntu.com/blog/hackers-guide-to-the-raspberry-pi-ai-ki…...

Java在算法竞赛中的常用方法
在算法竞赛中,Java以其强大的标准库和高效的性能成为了众多参赛者的首选语言。本文将详细介绍Java在算法竞赛中的常用集合、字符串处理、进制转换、大数处理以及StringBuilder的使用技巧,帮助你在竞赛中更加得心应手。 常用集合 Java的集合框架提供了多…...
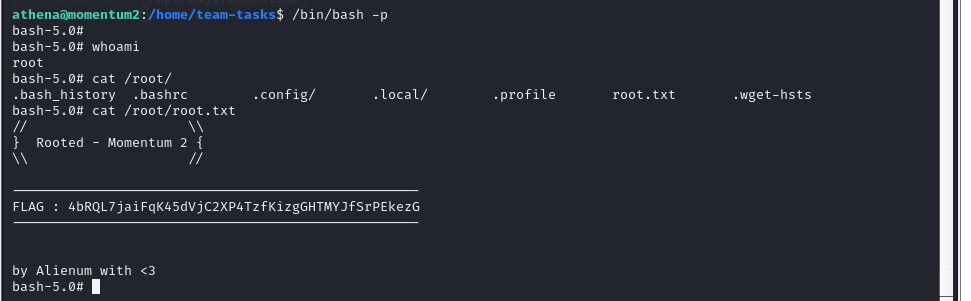
Vulnhub靶场案例渗透[10]- Momentum2
文章目录 一、靶场搭建1. 靶场描述2. 下载靶机环境3. 靶场搭建 二、渗透靶场1. 确定靶机IP2. 探测靶场开放端口及对应服务3. 扫描网络目录结构4. 代码审计5. 反弹shell6. 提权 一、靶场搭建 1. 靶场描述 - Difficulty : medium - Keywords : curl, bash, code reviewThis wor…...

Spark RDD中常用聚合算子源码层面的对比分析
在 Spark RDD 中,groupByKey、reduceByKey、foldByKey 和 aggregateByKey 是常用的聚合算子,适用于按键进行数据分组和聚合。它们的实现方式各不相同,涉及底层调用的函数也有区别。以下是对这些算子在源码层面的分析,以及每个算子…...

计算机网络 (6)物理层的基本概念
前言 计算机网络物理层是OSI模型(开放式系统互联模型)中的第一层,也是七层中的最底层,它涉及到计算机网络中数据的物理传输。 一、物理层的主要任务和功能 物理层的主要任务是处理物理传输介质上的原始比特流,确保数据…...
)
快速上手:Docker 安装详细教程(适用于 Windows、macOS、Linux)
### 快速上手:Docker 安装详细教程(适用于 Windows、macOS、Linux) --- Docker 是一款开源容器化平台,广泛应用于开发、测试和部署。本文将为您提供分步骤的 Docker 安装教程,涵盖 Windows、macOS 和 Linux 系统。 …...

kafka消费者出现频繁Rebalance
kafka消费者在正常使用过程中,突然出现了不消费消息的情况,项目里是使用了多个消费者消费不同数据,按理不会相互影响,看日志,发现消费者出现了频繁的Rebalance。 Rebalance的触发条件 组成员发生变更(新consumer加入组…...
rk3399开发环境使用Android 10初体验蓝牙功能
版本 日期 作者 变更表述 1.0 2024/11/10 于忠军 文档创建 零. 前言 由于Bluedroid的介绍文档有限,以及对Android的一些基本的知识需要了(Android 四大组件/AIDL/Framework/Binder机制/JNI/HIDL等),加上需要掌握的语言包括Java/C/C等࿰…...

3步打造你的专属AI角色扮演世界:SillyTavern终极指南
3步打造你的专属AI角色扮演世界:SillyTavern终极指南 【免费下载链接】SillyTavern LLM Frontend for Power Users. 项目地址: https://gitcode.com/GitHub_Trending/si/SillyTavern 你是否厌倦了千篇一律的AI对话?是否渴望创造真正有灵魂的虚拟角…...

仅剩最后3家银行未完成Java Istio全面替换——这份含12类Java Agent冲突检测脚本、4种Sidecar注入模式对比的适配手册即将下线
第一章:Java Istio适配现状与收官倒计时Istio 1.20 是最后一个官方支持 Java 客户端(istio-java-api)的版本,自 1.21 起,Istio 社区正式移除了对 Java SDK 的维护和 CI 验证。这一决策标志着 Java 生态在 Istio 原生控…...

QT:Tab Widget的进阶应用与实战技巧
1. Tab Widget的动态管理技巧 第一次用QT做带标签页的界面时,我习惯在设计器里把Tab页都固定好。直到接手一个需要动态加载配置文件的仪表盘项目,才发现动态增删Tab才是真实开发中的常态。比如用户点击"新建图表"按钮时,我们需要实…...

如何构建Min浏览器插件:从零开始的可扩展架构指南
如何构建Min浏览器插件:从零开始的可扩展架构指南 【免费下载链接】min A fast, minimal browser that protects your privacy 项目地址: https://gitcode.com/gh_mirrors/mi/min Min浏览器作为一款注重隐私保护的轻量级浏览器,其插件系统为开发者…...

自动缝纫机SolidWorks
在自动缝纫机的设计过程中,往往需要处理大量精密零件的协同工作,从送布机构、针杆组件到旋梭系统,每个部件的尺寸精度和装配关系都直接影响设备的运行稳定性和缝纫效果。而SolidWorks作为三维设计工具,在这一过程中扮演着关键角色…...

SGMICRO圣邦微 SGM8708YN8G/TR SOT-23 比较器
特性 低静态电流:在Vs1.8V时,典型值为2.2pA VOUT和VOUT双输出宽单电源电压范围:1.8V至5.5V 包含锁存功能 轨到轨输入和输出推挽输出电流驱动:在Vs5V时,典型值为18mA 内部1.2V参考电压工作温度范围:-40C至85C提供绿色S0T-23-8和S0IC-8封装...

【限时技术白皮书】:Istio 1.20正式版Java适配黄金72小时——我们已验证的6大兼容性断点及热修复方案
第一章:Istio 1.20正式版Java微服务适配全景概览Istio 1.20 正式版于2023年10月发布,针对Java生态的可观测性、安全通信与流量治理能力进行了系统性增强。该版本在Sidecar注入、Java应用兼容性、OpenTelemetry集成及JVM指标采集方面均实现关键演进&#…...

Fish-Speech 1.5应用案例:从播客配音到语音提醒,实战分享
Fish-Speech 1.5应用案例:从播客配音到语音提醒,实战分享 1. 项目概述与核心优势 Fish-Speech 1.5作为新一代文本转语音(TTS)系统,凭借其创新的DualAR架构在语音合成领域脱颖而出。这个开源项目通过双自回归Transformer设计,主T…...

OpenClaw+GLM-4.7-Flash:个人财务管理自动化实践
OpenClawGLM-4.7-Flash:个人财务管理自动化实践 1. 为什么需要自动化财务管理 每个月末,我都会面对一堆散乱的电子账单和银行流水。手动整理这些数据不仅耗时,还容易出错。直到我发现OpenClaw与GLM-4.7-Flash的组合,才真正实现了…...
)
InnoDB 事务 undo log 与 MVCC 可视化讲解(画流程图+伪代码)
InnoDB 事务 undo log 与 MVCC 可视化讲解(画流程图+伪代码) 前言 在MySQL的InnoDB存储引擎中,事务的四大特性(ACID)是其核心能力之一。其中,隔离性(Isolation)和一致性(Consistency)的实现离不开undo log与MVCC(多版本并发控制)的精妙设计。 本文将从底层原理出…...