JavaEE-多线程基础知识
文章目录
- 前言与回顾
- 创建一个多线程
- 线程的创建以及运行机制简述
- step1: 继承Thread类
- step2: 实现Runable接口
- step3: 基于step1使用匿名内部类
- step4: 基于step2使用匿名内部类
- step5: 基于step4使用lambda表达式(推荐)
- Thread的常见方法
- 关于jconsole监视线程的工具
- 构造方法解析
- 获取 ID / 名称
- 查看 / 设置后台线程
- 查看线程的状态
- 获取 / 设置线程的优先级
- 查看线程存活
- 中断线程以及阻塞唤醒机制
- 使用自定义标志位终止线程
- lambda中的变量捕获
- 使用interrupt
- interrupt方法对于阻塞的打断
- 等待一个线程(join方法)
- join方法的基本说明
- join方法的使用及线程状态观察
- 线程休眠机制
- 如何获取线程的引用
- sleep方法
- sleep(0) 和 yield()
前言与回顾
基础的一些关于线程/进程的一些基础的概念, 已经在之前的帖子中有过解释
简单复习一下
- 线程是轻量级的进程(进程太重了, 创建销毁代价大)
- 进程包括线程
进程是操作系统资源分配的基本单位
线程是操作系统调度执行的基本单位 - 线程的调度是操作系统进行的, 在应用层无法进行干预, 也无法感知
- 线程是操作系统级别的概念, 操作系统内核实现了这种机制并封装提供用户一些API
Java中的Thread类可以视为是对操作系统的API的进一步封装和抽象
创建一个多线程
线程的创建以及运行机制简述
我们创建线程的最基本的方法其实是两种(后续还有)
- 通过定义一个类继承
Thread类重写run方法 - 通过定义一个类实现
Runnable接口重写run方法
run方法相当于主线程的main, 作为每一个线程的程序运行的入口, 我们通过start方法启动一个线程, 这时候操作系统的内部会真正的创建一个线程(源码层面是去调用的start0native修饰的本地方法, 自行调用cpp动态链接库), start0会调用run方法, 所以这相当于是一种回调函数的机制
但是我们提供了五种创建线程的方式, 其实本质都是基于上述两种(后续还要其他方法)
关于start的源码
public synchronized void start() {/*** This method is not invoked for the main method thread or "system"* group threads created/set up by the VM. Any new functionality added* to this method in the future may have to also be added to the VM.** A zero status value corresponds to state "NEW".*/if (threadStatus != 0)throw new IllegalThreadStateException();/* Notify the group that this thread is about to be started* so that it can be added to the group's list of threads* and the group's unstarted count can be decremented. */group.add(this);boolean started = false;try {start0();started = true;} finally {try {if (!started) {group.threadStartFailed(this);}} catch (Throwable ignore) {/* do nothing. If start0 threw a Throwable thenit will be passed up the call stack */}}}// 本地方法private native void start0();
也就是真正起作用的是start0, 如果好奇native修饰的方法的具体实现, 可以去JDK官网上自行查看JVM源码
step1: 继承Thread类
实现代码如下, 我们让每一个线程都睡眠1000ms便于观察
/*** 第一种创建线程的方式* 继承Thread类重写run方法*/class MyThread extends Thread{@Overridepublic void run() {while(true){System.out.println("hello thread!");// 睡眠一秒钟try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}}
}public class ThreadTest {public static void main(String[] args) {Thread t = new MyThread();// 开启一个线程t.start();// 主线程也执行while(true){System.out.println("hello main!");// 睡眠一秒钟try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}}
}
开始运行, 可以明显的看到线程t和线程main在交替的执行, 这也说明了是我们的底层的抢占式调度模型在起作用, 多个线程不断地抢夺cpu时间片

step2: 实现Runable接口
每一个逻辑加上一个sleep方法休眠便于观察
/*** 第二种创建线程的方式* 定义一个类实现Runnable接口*/
class MyRunnable implements Runnable{@Overridepublic void run() {while(true){System.out.println("hello thread!");try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}}
}
public class ThreadTest {public static void main(String[] args) throws InterruptedException {// 创建一个线程tThread t = new Thread(new MyRunnable());// 开启一个线程tt.start();// 主线程的逻辑while(true){System.out.println("hello main");Thread.sleep(1000);}}
}

step3: 基于step1使用匿名内部类
/*** 基于第一种方法使用匿名内部类*/
public class ThreadTest {public static void main(String[] args) throws InterruptedException {// 创建t线程Thread t = new Thread() {@Overridepublic void run() {while (true) {System.out.println("hello thread!");try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}}};// 开启t线程t.start();// 主线程的逻辑while (true) {System.out.println("hello main!");Thread.sleep(1000);}}
}step4: 基于step2使用匿名内部类
public class ThreadTest {public static void main(String[] args) throws InterruptedException {Thread t = new Thread(new Runnable() {@Overridepublic void run() {while(true){System.out.println("hello thread!");try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}}});// 开启线程 tt.start();// 主线程的逻辑如下while(true){System.out.println("hello main!");Thread.sleep(1000);}}
}step5: 基于step4使用lambda表达式(推荐)
lambda表达式本质上就是一个匿名的函数, 最主要的用途就是作为回调函数, 很多语言都有, 只不过叫法有差异而已
- 底层编译器会对
lambda表达式进行处理, 创建了一个匿名的函数式接口的子类, 并且创建了对应的实例并且重写里面的方法
代码实例
/*** 使用lambda表达式进行问题的描述*/
public class ThreadTest {public static void main(String[] args) throws InterruptedException {Thread t = new Thread(() -> {while(true){try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}System.out.println("hello t!!!");}}, "t");// 开启t线程t.start();// 主线程中的逻辑while(true){Thread.sleep(1000);System.out.println("hello main!!!");}}
}
这里可以看到, 我们的两个线程正在交替的执行逻辑
我们推荐这种方式进行平时的线程的测试, 因为比较的轻量级
Thread的常见方法
关于jconsole监视线程的工具
构造方法解析
是我们的JDK中自带的一个检测当前线程的工具, 在我们的JDK安装路径中的bin目录下, 可以在这个目录下找到这个检测的工具

我们开启一个多线程的逻辑, 我们这里的测试代码是上面的step5创建线程的方法, 可以先去看一下…
打开之后是下面的窗口

这里我们查看 t线程和main线程


这里我们可以看到线程的状态
比如现在的两个线程都位于TIMED_WAITING状态(sleep(1000))
还可以查看当前线程的堆栈跟踪状态是什么
这里其实还说明了一些问题, 我们的后台其实存在多个线程(本质上是后台线程, 比如跟网络通讯相关的线程, 还有跟垃圾回收 GC 相关的一些线程) 这些线程维持我们 Java 程序的正常执行

这张图是JDK的帮助文档的截图, 我们逐一解释一下里面的一些主要的方法(关于线程组创建线程的方法我们暂时略过, 后期回来继续说, 其实就是把线程进行分组)
| 方法签名 | 描述 |
|---|---|
| Thread() | 直接创建线程对象 |
| Thread(Runnable target) | 使用实现了Runnable接口的对象来创建线程 |
| Thread(String name) | 创建线程并传入一个名字(便于使用jconsole进行监视) |
| Thread(Runnable target, String name) | 前两种的结合 |
| Thread(ThreadGroup group, Runnable target) | 使用线程组来创建线程(现阶段了解) |
获取 ID / 名称
对于每一个线程来说, 都有一个独一无二的 ID (标识码, 类似PID)
对于每个线程来说, 程序开发者可以选择指定一个名字(或者系统自动分配)
getID: 获取当前线程的标识码getName: 获取当前线程的名称
public class ThreadTest {public static void main(String[] args) throws InterruptedException{// 创建一个t线程Thread t = new Thread(() -> {while(true){try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}System.out.println(Thread.currentThread().getId() + " " + Thread.currentThread().getName());}}, "t线程");// 开启t线程t.start();// 主线程中的逻辑while(true){Thread.sleep(1000);System.out.println(Thread.currentThread().getId() + " " + Thread.currentThread().getName());}}
}

可以观测到此时的随机调度的线程的 ID 以及 name
查看 / 设置后台线程
后台线程其实就是守护线程, 其实就是进程的"幕后人员"
setDaemon(boolean): 传入一个true把当前线程设置为守护线程(start前)isDaemon(): 查看当前线程是否是守护线程
守护线程是当所有的用户线程全部结束之后, 自动就结束了, 但是如果守护线程自己选择结束了, 那也算是结束了, 所以我们的守护线程一般用于链接网络, 维护数据库日志等等场景
class ThreadTest01 {public static void main(String[] args) throws InterruptedException {// 创建一个t线程Thread t = new Thread(() -> {while (true) {try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}System.out.println("守护线程执行ing");}}, "t线程");// 设置t线程为守护线程t.setDaemon(true);// 开启t线程t.start();while (true) {Thread.sleep(1000);System.out.println("main线程执行ing");}}
}

通过jconsole检测也可以发现两个线程的情况, 可以看到两个位置都是TIMED-WAITING状态
查看线程的状态
getState(): 查看当前线程的状态(有六种状态)
class ThreadTest01 {public static void main(String[] args) throws InterruptedException {// 创建一个t线程Thread t = new Thread(() -> {while (true) {try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}System.out.println("守护线程执行ing " + Thread.currentThread().getState());}}, "t线程");// 设置t线程为守护线程t.setDaemon(true);// 开启t线程t.start();while (true) {Thread.sleep(1000);System.out.println("main线程执行ing " + Thread.currentThread().getState());}}
}

实质上有多种状态描述, 我们此时的状态是可运行状态
获取 / 设置线程的优先级
class ThreadTest01 {public static void main(String[] args) throws InterruptedException {// 创建一个t线程Thread t = new Thread(() -> {try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}// 查看当前线程的优先级System.out.println("默认的优先级: " + Thread.currentThread().getPriority());}, "t线程");t.start();System.out.println("最低优先级: " + Thread.MIN_PRIORITY + " 最高优先级: " + Thread.MAX_PRIORITY);}
}

setPriority(): 设置线程的优先级(0 - 10)
这其实是一个概率问题, 定义一个线程抢占cpu时间片的概率, 但不是绝对的
查看线程存活
isAlive(): 判断当前线程是否存活
请注意, 线程的存活和线程对象的生命周期一般是不一样的
比如下面的代码
class ThreadTest02{public static void main(String[] args) throws InterruptedException {// 创建一个t线程Thread t = new Thread(() -> {System.out.println("...");}, "t线程");t.start();while(true){Thread.sleep(1000);System.out.println(t.isAlive());}}
}

此时线程以及结束了(run方法执行结束), 但是线程对象并没有销毁
中断线程以及阻塞唤醒机制
使用自定义标志位终止线程
定义一个static变量作为标志位然后打标记
public class ThreadTest {// 自定义一个标志位打标记private static boolean isFinished = false;public static void main(String[] args) throws InterruptedException {// 使用lambda机制创建一个线程Thread t = new Thread(() -> {while(!isFinished){try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}System.out.println(Thread.currentThread().getName());}}, "t线程");// 开启t线程t.start();// 三秒之后终止t线程Thread.sleep(3000);isFinished = true;}
}
可以看到 3s 之后终止 t 线程
lambda中的变量捕获
如果上面的代码的标志位是局部变量, 那么我们就触发了lambda表达式中的变量捕获语法

这个代码我们发现报错了
-
原因: 这其实就是lambda语法中的
变量捕获机制, 对于lambda表达式来说, 本质是一种回调函数, 执行时机很可能是很久之后了, 此时main函数存在与否都不好说, 假设main执行结束了, 此时isFinished变量其实也就销毁了, 那lambda中访问的isFinished变量又是什么呢 ? -
解决方案: 为了解决上述的问题, Java中采取的做法是, 在定义lambda的时候, 直接就把变量拷贝一份给lambda中的变量, 所以其实上述代码中, lambda中的
isFinished变量跟外部的isFinished的变量, 本质上是两个变量, 这样处理的好处就是, 此时外部的情况不管怎么变, 即使变量销毁了, 对lambda表达式内部也不会造成影响 -
不允许修改: 根据上面的解释, 如果一边改变, 另一边不变, 这样处理就会对程序员造成更对的困扰, 所以Java这边的做法是, 压根不允许我们对变量的值进行修改, 对于引用变量来说, 不允许指向修改, 但是内部的值是可以修改的…(C++对于这里的操作相对更复杂, 需要你自己定义变量的生命周期以及是否进行拷贝)
-
和定义外部变量的区别: 那为什么上面的定义一个外部变量就可以修改呢, 因为所属的语法机制不一样, 上面所属的语法体系是
内部类访问外部类变量, 当然可以修改
引用变量的场景


此时可以修改内部的值, 但是不可以修改引用
使用interrupt
关于终止线程, 我们上面给出了一种修改终止标志位的方案, 但其实Java中的Thread类天然的提供了一个标志位用来进行变量的修改
我们分析一下下面的代码
public class ThreadTest {public static void main(String[] args) throws InterruptedException {// 关于使用内部自带的标志位修改Thread t = new Thread(() -> {while(!Thread.currentThread().isInterrupted()){System.out.println("hello main!!!");;//Thread.sleep(1000);}});// 开启线程tt.start();// 三秒后终止线程tThread.sleep(3000);t.interrupt();}
}
上述代码是可以正常结束线程的, 因为3s之后, 我们把t线程的标志位设置为true, 然后跳出循环…


观察一下源码就可以发现, 其实跟我们自行定义标志位的做法是一致的
interrupt方法对于阻塞的打断
我们尝试分析一下下面的代码
public class ThreadTest {public static void main(String[] args) throws InterruptedException {// 关于使用内部自带的标志位修改Thread t = new Thread(() -> {while(!Thread.currentThread().isInterrupted()){System.out.println("hello main!!!");;try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}});// 开启线程tt.start();// 三秒后终止线程tThread.sleep(3000);t.interrupt();}
}我们运行的结果如下

我们尝试打断线程, 但是失败了, 只是在控制台打印了堆栈信息, 但是线程并没有被打断…
这里我们没办法查看sleep方法的源码(native修饰的本地方法)
- 原因: 其实就是我们在调用
interrupt方法的同时, 会唤醒sleep等等类似阻塞效果的方法, 并抛出异常InterruptedException后被唤醒(其实就是唤醒的机制), 并且把标志位interrupted重新设置为false, 所以下次循环还可以进入… - 处理逻辑: 那为什么要这样处理呢, 是不是毫无用处多此一举呢… 我认为, 这样处理的逻辑还是相对比较合理的, 因为留给了程序员更多的操作空间, 在被唤醒之后, 程序员可以选择下面三种处理方式
1 . 直接跳出执行逻辑(比如通过break)
2 . 执行操作逻辑后再跳出(先执行一段逻辑代码处理, 然后break)
3 . 忽视这个信号, 继续执行

上面是我们对于这个终止信号的三种处理态度
等待一个线程(join方法)
join方法的基本说明
由于多个线程之间都是随机调度执行的, 并发执行, 随机调度
所以站在程序员的角度, 我们不喜欢随机性, join方法可以要求多个线程之间的结束的先后顺序…
虽然可以通过sleep来设置等待的时间, 但是这种机制往往是不科学的, 比如我们现在有一个需求, 想要t线程执行结束后, main线程立即开始执行, 这时候使用sleep的合理性就很差了.

我们这里有三个常见的方法
join(): 无时间期限的等待join(long millis): 设置最长的等待时间为millis, 单位为毫秒join(long millis, int nanos): 设置最长的等待期限是毫秒+纳秒(不常用)
对于第三个方法的说明, 其实做不到那么精确, 除非使用实时操作系统…
第一个进入WAITING状态, 第二三个进入TIMED_WAITING状态
join方法的使用及线程状态观察
public class ThreadTest {public static void main(String[] args) throws InterruptedException {Thread t = new Thread(() -> {for(int i = 0; i < 5; i++){System.out.println("hello t ! ! !");try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}}, "t");// 启动t线程t.start();// t执行完毕再执行main线程t.join();System.out.println("hello main ! ! !");}
}
在t线程执行5s之后, main线程继续执行, 我们使用jconsole工具查看一下情况(修改上面t线程循环次数为50)

此时t线程处于TIMED_WAITING状态, 因为这个线程的大部分时间都处于sleep(1000)这里…

观察到main线程处于WAITING状态, 此时正在因为join()产生阻塞(无时间期限)
线程休眠机制
如何获取线程的引用
Thread.currentThread(): 静态方法, 返回一个当前线程对象的引用(相当于this关键字)
sleep方法
这个方法没什么可说的, 但是也有需要注意的一点
比如
Thread.sleep(1000);
这个真的是让当前线程休眠 1000ms 吗 ?
其实并没有那么精确, 实际上一般是要略大于 1000ms , 因为sleep(1000), 指的是1000ms之后
该线程再次拥有了抢夺 cpu 时间片的能力, 但是具体需要多长时间能够抢到, 这个其实是一个未知数, 所以一般是要比 1000ms 稍微大一些的…
sleep(0) 和 yield()

yield: 是一个静态方法, 使得当前调用该线程的方法立刻放弃抢夺到的cpu时间片进入就绪状态sleep(0): 和上面yield类似, 都是立刻放弃抢夺到的cpu时间片, 进入抢夺cpu时间片的就绪状态
相关文章:
JavaEE-多线程基础知识
文章目录 前言与回顾创建一个多线程线程的创建以及运行机制简述step1: 继承Thread类step2: 实现Runable接口step3: 基于step1使用匿名内部类step4: 基于step2使用匿名内部类step5: 基于step4使用lambda表达式(推荐) Thread的常见方法关于jconsole监视线程的工具构造方法解析获取…...

Pulid:pure and lightning id customization via contrastive alignment
1.introduction 基于微调的方案,对每个id进行定制需要花费数十分钟。另一项研究则放弃了对每个id进行微调,而是选择在一个庞大的肖像数据集上预训练一个id适配器。这些方法通常利用编码器例如clip来提取id特征,提取的特征随后以特定方式例如嵌入到cross attention集成到基础…...

什么是GraphQL,有什么特点
什么是GraphQL? GraphQL 是一种用于 API(应用程序编程接口)的查询语言,由 Facebook 在 2012 年开发,并于 2015 年开源。它提供了一种更高效、强大的方式来获取和操作数据,与传统的 RESTful API 相比&#…...
Java项目-基于SpringBoot+vue的租房网站设计与实现
博主介绍:✌程序员徐师兄、7年大厂程序员经历。全网粉丝12w、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专栏推荐订阅👇…...
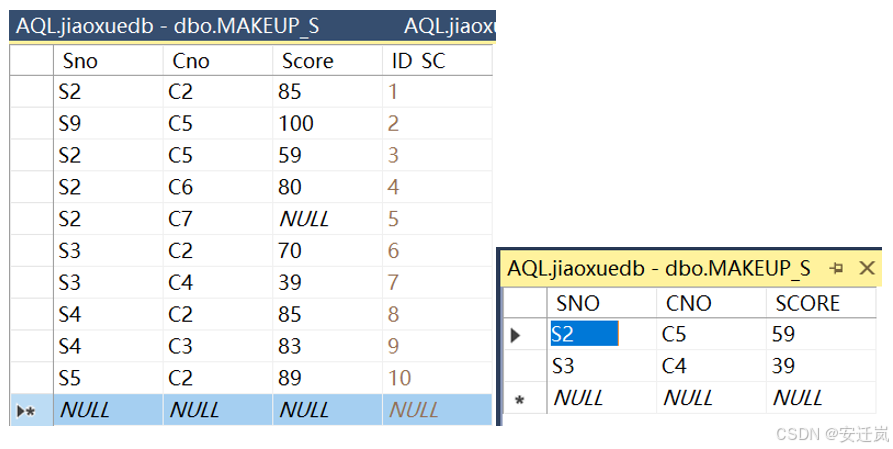
【SQL Server】华中农业大学空间数据库实验报告 实验三 数据操作
1.实验目的 熟悉了解掌握SQL Server软件的基本操作与使用方法,以及通过理论课学习与实验参考书的帮助,熟练掌握使用T-SQL语句和交互式方法对数据表进行插入数据、修改数据、删除数据等等的操作;作为后续实验的基础,根据实验要求重…...
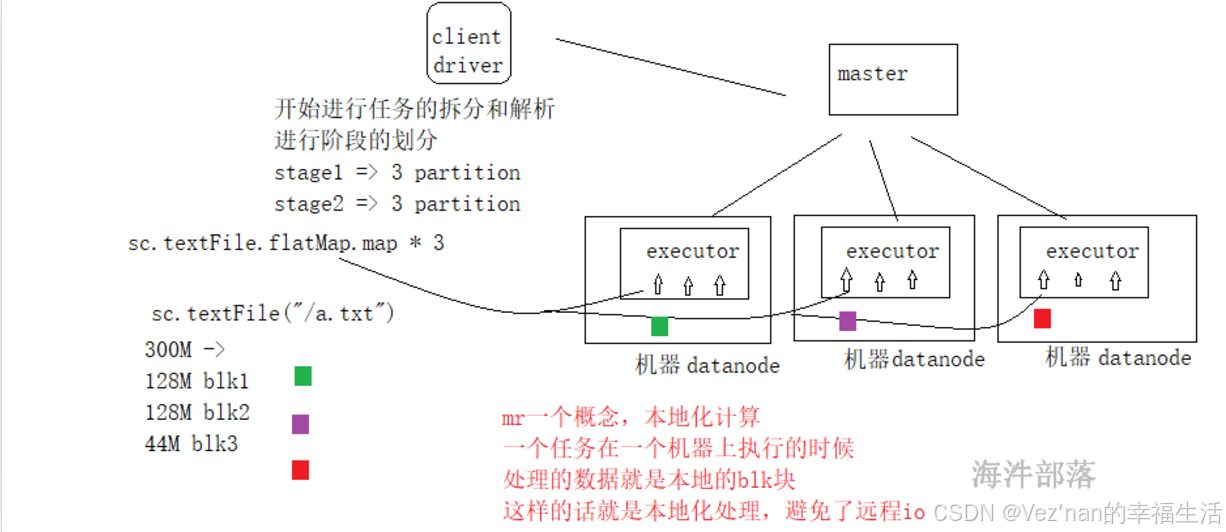
【大数据学习 | Spark】RDD的概念与Spark任务的执行流程
1. RDD的设计背景 在实际应用中,存在许多迭代式计算,这些应用场景的共同之处是,不同计算阶段之间会重用中间结果,即一个阶段的输出结果会作为下一个阶段的输入。但是,目前的MapReduce框架都是把中间结果写入到HDFS中&…...

ruoyi框架完成分库分表,按月自动建表功能
前提 这个分库分表功能,按月自动建表,做的比较久了,还没上线,是在ruoyi框架内做的,踩了不少坑,但是已经实现了,就分享一下代码吧 参考 先分享一些参考文章 【若依系列】集成ShardingSphere S…...

Antd中的布局组件
文章目录 一、Layout二、Menu三、Grid栅格 布局组件涉及项目框架的搭建,往往被忽略和低关注,毕竟不是经常用到,但是在调整项目结构的时候往往又需要重新设计布局,所以有必要提前归纳分析; 一、Layout Layout导出Sider,…...
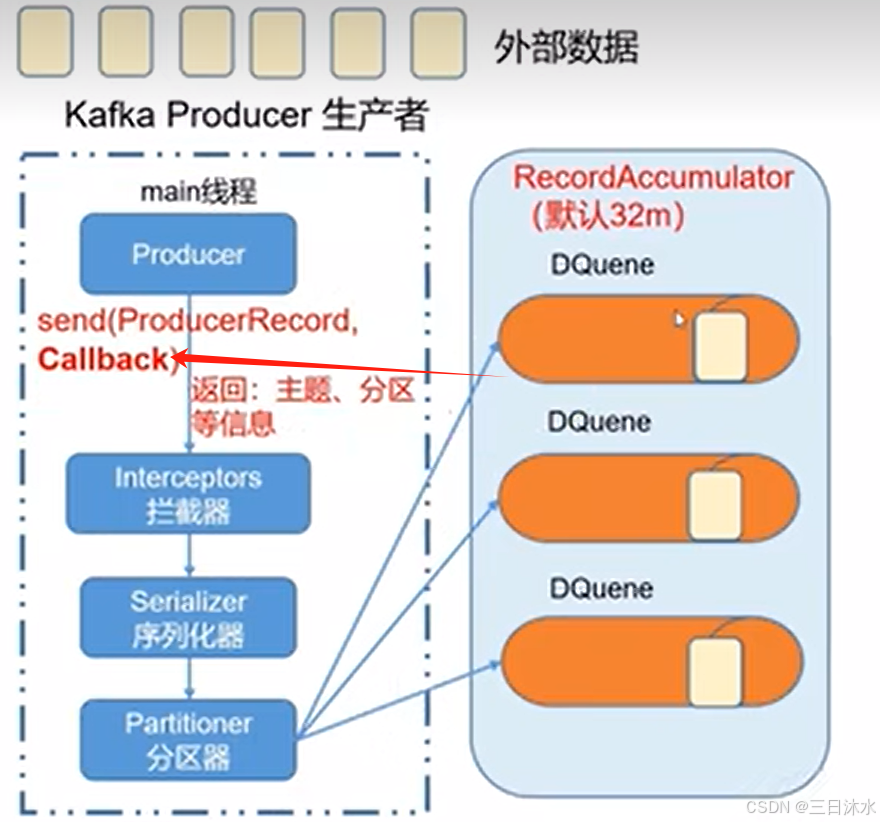
一文详解kafka知识点
目录 1、kafka定义 2、消息队列 2.1、产品选择 2.2、应用场景 2.3、消息队列的两种模式 3、kafka架构 4、kafka生产者 4.1、kafka生产者原理 4.2、kafka生产者异步发送 4.3、同步发送 4.4、分区 4.4.1、kafka分区好处 4.4.2、分区策略 4.4.3、自定义分区 4.5、生成吞…...

C语言基础学习:抽象数据类型(ADT)
基础概念 抽象数据类型(ADT)是一种数据类型,它定义了一组数据以及可以在这组数据上执行的操作,但隐藏了数据的具体存储方式和实现细节。在C语言中,抽象数据类型(ADT)是一种非常重要的概念&…...

提升性能测试效率与准确性:深入解析JMeter中的各类定时器
在软件性能测试领域,Apache JMeter是一款广泛使用的开源工具,它允许开发者模拟大量用户对应用程序进行并发访问,从而评估系统的性能和稳定性。在进行性能测试时,合理地设置请求之间的延迟时间对于模拟真实用户行为、避免服务器过载…...

施密特正交化与单位化的情形
在考研数学的线性代数部分,施密特正交化和单位化是两种不同的处理向量的方法,它们在特定的情况下被使用。以下是详细说明: 施密特正交化的应用场景 施密特正交化(Gram-Schmidt Orthogonalization)是一种从线性无关向…...
ROS机器视觉入门:从基础到人脸识别与目标检测
前言 从本文开始,我们将开始学习ROS机器视觉处理,刚开始先学习一部分外围的知识,为后续的人脸识别、目标跟踪和YOLOV5目标检测做准备工作。我采用的笔记本是联想拯救者游戏本,系统采用Ubuntu20.04,ROS采用noetic。 颜…...

2024 APMCM亚太数学建模C题 - 宠物行业及相关产业的发展分析和策略(详细解题思路)
在当下, 日益发展的时代,宠物的数量应该均为稳步上升,在美国出现了下降的趋势, 中国 2019-2020 年也下降,这部分变化可能与疫情相关。需要对该部分进行必要的解释说明。 问题 1: 基于附件 1 中的数据及您的团队收集的…...

C#里怎么样访问文件时间
C#里怎么样访问文件时间 文件时间也是一个关键信息, 因为很多数据处理需要时间来判断数据的有效性,比如股票中的股价, 它是的权重,是随着时间递减的。 一般来说,超过5年以上的数据,都是可以删除掉了。 或者说超过三年的数据,就需要压缩保存了,这样可以省掉很多磁盘空…...

Cesium教程01_认识View
Cesium 地图视图组件 目录 一、引言二、功能说明三、代码实现 1. 模板结构2. 脚本逻辑3. 样式设计 四、总结 一、引言 在三维地球可视化中,Cesium 是一个强大的开源 JavaScript 库,它能够展示精美的地球和地图应用。本示例展示了如何使用 Vue 组件化…...

【SQL Server】华中农业大学空间数据库实验报告 实验八 存储过程
1.实验目的 通过实验课程与理论课的学习深入理解掌握的存储过程的原理、创建、修改、删除、基本的使用方法、主要用途,并且可以在练习的基础上,熟练使用存储过程来进行数据库的应用程序的设计;深入学习深刻理解与存储过程相关的T-SQL语句的编…...

ArcMap 处理栅格数据的分辨率功能操作
ArcMap 处理栅格数据的分辨率功能操作 一、统一多分辨率栅格数据 1、查看两个栅格数据的分辨率 1)raster1 点击属性 2) raster2 2、统一像元大小 1)点击环境 展示和填写 处理范围 栅格分析 点击确定 3、重采样 让raster1和..2保持一致,即…...
 ae事件处理器(一))
redis7.x源码分析:(4) ae事件处理器(一)
ae模块是redis实现的Reactor模型的封装。它的主要代码实现集中在 ae.c 中,另外还提供了平台相关的io多路复用的封装,它们都实现了一套相同的poll接口,就类似于C中提供了一个接口基类,由针对不同平台的派生类去实现。 // 创建平台…...

【React】React Router:深入理解前端路由的工作原理
🌈个人主页: 鑫宝Code 🔥热门专栏: 闲话杂谈| 炫酷HTML | JavaScript基础 💫个人格言: "如无必要,勿增实体" 文章目录 React Router:深入理解前端路由的工作原理路由的演进历程传统多页面…...

rebar3最佳实践清单:避免常见陷阱的20个专业建议
rebar3最佳实践清单:避免常见陷阱的20个专业建议 【免费下载链接】rebar3 Erlang build tool that makes it easy to compile and test Erlang applications and releases. 项目地址: https://gitcode.com/gh_mirrors/re/rebar3 rebar3是Erlang生态系统中最流…...

通过Python快速调用Taotoken实现自动化文档生成
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Python快速调用Taotoken实现自动化文档生成 对于嵌入式或单片机开发者而言,为Keil5项目编写和维护技术文档是一项耗…...

Delft3D建模、水动力模拟方法及在地表水环境影响评价中的实践技术应用
一:Delft3D软件介绍及建模原理和步骤对常见的地表水数值模型进行介绍,学习Delft3D软件的构成、界面内容,了解地表水数值模型的建模步骤:1.1地表水数值模拟常用软件介绍EFDC_Explorer(商业) Delft3D…...

YOLO26 ONNX Runtime 部署实战:告别NMS后处理,边缘推理新标杆
🚀 YOLO26 ONNX Runtime 部署实战:告别NMS后处理,边缘推理新标杆 摘要: Ultralytics 重磅推出的 YOLO26 不仅在精度上实现了代际飞跃,更在架构层面进行了颠覆性革新——彻底移除了传统的 NMS(非极大值抑制)后处理环节。本文将带你深入了解 YOLO26 的核心优势,并基于 …...
2026)
郑州市科技局:科技成果汇编(第01册)2026
这份文档是郑州市科学技术局 2026 年发布的第 1 期科技成果汇编,共收录112 项优质科技成果,覆盖装备制造、环境治理、新材料、电子信息、新能源与节能、生物医药、粮油食品、其他八大核心领域,由郑州大学、华北水利水电大学、河南工业大学等高…...

别让格式毁了你的论文:一份给IEEE TII投稿者的Latex排版自查清单
IEEE TII投稿LaTeX排版终极自查指南:从格式合规到学术表达优化 第一次向IEEE Transactions on Industrial Informatics(TII)投稿的研究者,往往会在收到编辑的格式审查意见时感到措手不及。那些看似微不足道的标点空格、公式编号或…...

3个实战技巧:用GitHub社区徽章系统打造你的开发者影响力
3个实战技巧:用GitHub社区徽章系统打造你的开发者影响力 【免费下载链接】community Public feedback discussions for: GitHub Mobile, GitHub Discussions, GitHub Codespaces, GitHub Sponsors, GitHub Issues and more! 项目地址: https://gitcode.com/gh_mir…...

Apache APISIX Dashboard:现代化API网关管理的架构演进与实践方案
Apache APISIX Dashboard:现代化API网关管理的架构演进与实践方案 【免费下载链接】apisix-dashboard Dashboard for Apache APISIX 项目地址: https://gitcode.com/gh_mirrors/ap/apisix-dashboard 在微服务架构日益普及的今天,API网关已成为连接…...

Real-ESRGAN终极指南:5分钟掌握AI图像超分辨率技术,让模糊照片秒变高清
Real-ESRGAN终极指南:5分钟掌握AI图像超分辨率技术,让模糊照片秒变高清 【免费下载链接】Real-ESRGAN Real-ESRGAN aims at developing Practical Algorithms for General Image/Video Restoration. 项目地址: https://gitcode.com/gh_mirrors/re/Real…...

课堂教室学生行为识别分割数据集labelme格式1420张4类别
注意数据集中有增强图片主要是亮度对比度增强,此外图片并不是十分清晰,具体看图片数据集格式:labelme格式(不包含mask文件,仅仅包含jpg图片和对应的json文件)图片数量(jpg文件个数):1420标注数量(json文件个数)&#x…...