Spring AI Alibaba 快速入门
Spring AI Alibaba 实现了与阿里云通义模型的完整适配,接下来,我们将学习如何使用 spring ai alibaba 开发一个基于通义模型服务的智能聊天应用。
一、快速体验示例
注意:因为 Spring AI Alibaba 基于 Spring Boot 3.x 开发,因此本地 JDK 版本要求为 17 及以上。
-
下载项目 运行以下命令下载源码,进入 helloworld 示例目录:
git clone --depth=1 https://github.com/alibaba/spring-ai-alibaba.git cd spring-ai-alibaba/spring-ai-alibaba-examples/helloworld-example -
运行项目 首先,需要获取一个合法的 API-KEY 并设置
AI_DASHSCOPE_API_KEY环境变量,可跳转 阿里云百炼平台 了解如何获取 API-KEY。export AI_DASHSCOPE_API_KEY=${REPLACE-WITH-VALID-API-KEY}启动示例应用:
./mvnw compile exec:java -Dexec.mainClass="com.alibaba.cloud.ai.example.helloworld.HelloWorldExampleApplication"访问
http://localhost:8080/ai/chat?input=给我讲一个笑话吧,向通义模型提问并得到回答。
二、示例开发指南
以上示例本质上就是一个普通的 Spring Boot 应用,我们来通过源码解析看一下具体的开发流程。
-
添加依赖
首先,需要在项目中添加
spring-ai-alibaba-starter依赖,它将通过 Spring Boot 自动装配机制初始化与阿里云通义大模型通信的ChatClient、ChatModel相关实例。<dependency><groupId>com.alibaba.cloud.ai</groupId><artifactId>spring-ai-alibaba-starter</artifactId><version>1.0.0-M2.1</version></dependency>注意:由于 spring-ai 相关依赖包还没有发布到中央仓库,如出现 spring-ai-core 等相关依赖解析问题,请在您项目的 pom.xml 依赖中加入如下仓库配置。
<repositories><repository><id>spring-milestones</id><name>Spring Milestones</name><url>https://repo.spring.io/milestone</url><snapshots><enabled>false</enabled></snapshots></repository></repositories> -
注入 ChatClient
接下来,在普通 Controller Bean 中注入
ChatClient实例,这样你的 Bean 就具备与 AI 大模型智能对话的能力了。@RestController@RequestMapping("/ai")public class ChatController {private final ChatClient chatClient;public ChatController(ChatClient.Builder builder) {this.chatClient = builder.build();}@GetMapping("/chat")public String chat(String input) {return this.chatClient.prompt().user(input).call().content();}}以上示例中,ChatClient 调用大模型使用的是默认参数,Spring AI Alibaba 还支持通过
DashScopeChatOptions调整与模型对话时的参数,DashScopeChatOptions支持两种不同维度的配置方式:-
全局默认值,即
ChatClient实例初始化参数可以在
application.yaml文件中指定spring.ai.dashscope.chat.options.*或调用构造函数ChatClient.Builder.defaultOptions(options)、DashScopeChatModel(api, options)完成配置初始化。 -
每次 Prompt 调用前动态指定
ChatResponse response = chatModel.call(new Prompt("Generate the names of 5 famous pirates.",DashScopeChatOptions.builder().withModel("qwen-plus").withTemperature(0.4F).build()));关于
DashScopeChatOptions配置项的详细说明,请查看参考手册。
-
三、开发实例:RAG介绍
检索增强生成 (RAG) 是一种使用来自私有或专有数据源的信息来辅助文本生成的技术。它将检索模型(设计用于搜索大型数据集或知识库)和生成模型(例如大型语言模型 (LLM),此类模型会使用检索到的信息生成可供阅读的文本回复)结合在一起。
通过从更多数据源添加背景信息,以及通过训练来补充 LLM 的原始知识库,检索增强生成能够提高搜索体验的相关性。这能够改善大型语言模型的输出,但又无需重新训练模型。额外信息源的范围很广,从训练 LLM 时并未用到的互联网上的新信息,到专有商业背景信息,或者属于企业的机密内部文档,都会包含在内。
RAG 对于诸如回答问题和内容生成等任务,具有极大价值,因为它能支持生成式 AI 系统使用外部信息源生成更准确且更符合语境的回答。它会实施搜索检索方法(通常是语义搜索或混合搜索)来回应用户的意图并提供更相关的结果。
下图是一个RAG链路的两个阶段,包括Indexing pipeline阶段和RAG的阶段。

从上图可以看到, indexing pipeline的阶段主要是将结构化或者非结构化的数据或文档进行加载和解析、chunk切分、文本向量化并保存到向量数据库。 RAG的阶段主要包括将prompt文本内容转为向量、从向量数据库检索内容、对检索后的文档chunk进行重排和prompt重写、最后调用大模型进行结果的生成。
1、RAG调用
引入依赖:
<?xml version="1.0" encoding="UTF-8"?><!--Copyright 2023-2024 the original author or authors.Licensed under the Apache License, Version 2.0 (the "License");you may not use this file except in compliance with the License.You may obtain a copy of the License athttps://www.apache.org/licenses/LICENSE-2.0Unless required by applicable law or agreed to in writing, softwaredistributed under the License is distributed on an "AS IS" BASIS,WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.See the License for the specific language governing permissions andlimitations under the License.
--><project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.3.3</version><relativePath/> <!-- lookup parent from repository --></parent><groupId>com.alibaba.cloud.ai</groupId><artifactId>rag-example</artifactId><version>0.0.1-SNAPSHOT</version><name>rag-example</name><description>Demo project for Spring AI Alibaba</description><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding><maven.compiler.source>17</maven.compiler.source><maven.compiler.target>17</maven.compiler.target><maven-deploy-plugin.version>3.1.1</maven-deploy-plugin.version><!-- Spring AI --><spring-ai-alibaba.version>1.0.0-M3.2</spring-ai-alibaba.version><spring-ai.version>1.0.0-M3</spring-ai.version><!-- utils --><commons-lang3.version>3.14.0</commons-lang3.version></properties><dependencies><dependency><groupId>com.alibaba.cloud.ai</groupId><artifactId>spring-ai-alibaba-starter</artifactId><version>${spring-ai-alibaba.version}</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.apache.commons</groupId><artifactId>commons-lang3</artifactId></dependency><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-pdf-document-reader</artifactId><version>${spring-ai.version}</version></dependency><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-elasticsearch-store-spring-boot-starter</artifactId><version>${spring-ai.version}</version></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-deploy-plugin</artifactId><version>${maven-deploy-plugin.version}</version><configuration><skip>true</skip></configuration></plugin></plugins></build><repositories><repository><id>spring-milestones</id><name>Spring Milestones</name><url>https://repo.spring.io/milestone</url><snapshots><enabled>false</enabled></snapshots></repository></repositories></project>知识库内容导入
下边是将pdf文档导入到知识库的代码
DashScopeApi dashscopeApi = ...;// 1. 解析文档和chunk切分
String filePath = "新能源产业有哪些-36氪.pdf";
DashScopeDocumentCloudReader reader = new DashScopeDocumentCloudReader(filePath, dashscopeApi, null);
List<Document> documentList = reader.get();
DashScopeDocumentTransformer transformer = new DashScopeDocumentTransformer(dashscopeApi);
List<Document> transformerList = transformer.apply(documentList);
System.out.println(transformerList.size());// 2. 文档向量化
DashScopeEmbeddingModel embeddingModel = new DashScopeEmbeddingModel(dashscopeApi);
Document document = new Document("你好阿里云");
float[] vectorList = embeddingModel.embed(document);// 3. 导入文档内容到向量存储
DashScopeCloudStore cloudStore = new DashScopeCloudStore(dashscopeApi, new DashScopeStoreOptions("bailian-knowledge"));
cloudStore.add(Arrays.asList(document));// 4. 删除文档
cloudStore.delete(Arrays.asList(document.getId()));知识问答
下边代码将根据之前创建的知识库,进行知识问答的代码:
DocumentRetriever retriever = new DashScopeDocumentRetriever(dashscopeApi, DashScopeDocumentRetrieverOptions.builder().withIndexName("bailian-knowledge").build());ChatClient chatClient = ChatClient.builder(dashscopeChatModel).defaultAdvisors(new DocumentRetrievalAdvisor(retriever)).build();ChatResponse response = chatClient.prompt().user("如何快速开始百炼?").call().chatResponse();
String content = response.getResult().getOutput().getContent();
Assertions.assertNotNull(content);logger.info("content: {}", content);如果需要返回检索召回后,模型采纳和引用的文档内容, 可以通过以下代码实现:
DocumentRetriever retriever = new DashScopeDocumentRetriever(dashscopeApi,DashScopeDocumentRetrieverOptions.builder().withIndexName("spring-ai知识库").build());ChatClient chatClient = ChatClient.builder(dashscopeChatModel).defaultAdvisors(new DashScopeDocumentRetrievalAdvisor(retriever, true)).build();ChatResponse response = chatClient.prompt().user("如何快速开始百炼?").call().chatResponse();String content = response.getResult().getOutput().getContent();
Assertions.assertNotNull(content);
logger.info("content: {}", content);//获取引用的内容
List<Document> documents = (List<Document>) response.getMetadata().get(DashScopeDocumentRetrievalAdvisor.RETRIEVED_DOCUMENTS);
Assertions.assertNotNull(documents);for (Document document : documents) {logger.info("referenced doc name: {}, title: {}, score: {}", document.getMetadata().get("doc_name"),document.getMetadata().get("title"), document.getMetadata().get("_score"));}相关文章:
Spring AI Alibaba 快速入门
Spring AI Alibaba 实现了与阿里云通义模型的完整适配,接下来,我们将学习如何使用 spring ai alibaba 开发一个基于通义模型服务的智能聊天应用。 一、快速体验示例 注意:因为 Spring AI Alibaba 基于 Spring Boot 3.x 开发,因此…...
详解)
Docker Registry(镜像仓库)详解
Docker Registry(镜像仓库)详解 Docker Registry,即Docker镜像仓库,是Docker生态系统中一个至关重要的组件。它负责存储、管理和分发Docker镜像,为Docker容器提供镜像资源。本文将深入探讨Docker Registry的功能、结构…...

RTOS学习笔记---“二值信号量”和“互斥信号量”
在实时操作系统(RTOS)中,“二值信号量”和“互斥信号量”是两种常见的同步机制,用于线程之间的协调与资源管理。尽管它们有相似之处,都基于信号量概念,但它们的用途和行为存在重要区别。 1. 二值信号量&…...

Oracle-物化视图基本操作
-- 物化视图 -- 与普通视图的区别:真实存在数据的 普通视图的数据在基表 物化视图看成是, 一个定时运行的计算JOB一个存计算结果的表 创建时生成数据: 分为两种:build immediate 和 build deferred, build immediate是在创…...

(功能测试)测试报告
其中的统计分析和测试结果确认是必须要有的; 测试过程回顾:测试的时间和阶段,是否出现延期,与预期的任务计划是否匹配; !统计分析:统计写多少用例,用例覆盖情况如何(100%…...

【LeetCode每日一题】——746.使用最小花费爬楼梯
文章目录 一【题目类别】二【题目难度】三【题目编号】四【题目描述】五【题目示例】六【题目提示】七【解题思路】八【时空频度】九【代码实现】十【提交结果】 一【题目类别】 数组 二【题目难度】 简单 三【题目编号】 746.使用最小花费爬楼梯 四【题目描述】 给你一…...

程序里sendStringParametersAsUnicode=true的配置导致sql server cpu使用率高问题处理
一 问题描述 近期生产环境几台sql server从库cpu使用率总是打满,发现抓的带变量值的慢sql,手动代入变量值执行并不慢,秒级返回,不知道问题出在哪里。 二 问题排查 用扩展事件或者sql profiler抓慢sql,抓到了变量值&…...

Vue3 el-table 默认选中 传入的数组
一、效果: 二、官网是VUE2 现更改为Vue3写法 <template><el-table:data"tableData"border striperow-key"id"ref"tableRef":cell-style"{ text-align: center }":header-cell-style"{background: #b7babd…...

最后一个单词的长度
题目详情: 解题思路: 用两个变量分别存储当前值和上次值,就可保证当前移动时记录字符个数,当遇到空格时,这次值保存到上次值,并清空。 代码解析: /* 最后一个单词的长度 */ #include <st…...

2024-11-19 kron积
若A[a11 a12; a21 a22]; B[b11 b12; b21 b22]; 则C[a11*b11 a12*b11 a21*b11 a22*b11; a11*b12 a12*b12 a21*b12 a22*b12; a11*b21 a12*b21 a21*b21 a22*b21; a11*b22 a12*b22 a21*b22 a22*b22] 用MATLAB实现 方法1: A [a11 a12; a21 a22]; B [b11 b12; b21 b22]…...
Redis ⽀持哪⼏种数据类型?适⽤场景,底层结构
目录 Redis 数据类型 一、String(字符串) 二、Hash(哈希) 三、List(列表) 四、Set(集合) 五、ZSet(sorted set:有序集合) 六、BitMap 七、HyperLogLog 八、GEO …...

树莓派2 安装raspberry os 并修改成固定ip
安装 安装raspberry os 没啥说的,到树莓派官网,下载制作启动映像盘的软件: https://www.raspberrypi.com/software/ 下载后,直接安装该软件,然后运行,选择好开发板的型号和操作系统型号,按照…...

11月第3周AI资讯
阅读时间:3-4min 更新时间:2024.9.9-2024.9.13 目录 DIAMOND:扩散模型在世界构建中的应用 阿里云推出Qwen2.5-Turbo:高效长文本处理,性价比卓越 微软:AI已实现几乎无限的记忆 Comfyui_Object_Migration一致性换衣模型 DeepSeek发布R1-Lite-Preview:推理AI竞争愈发…...
一次封装,解放双手:Requests如何实现0入侵请求与响应的智能加解密
引言 之前写了 Requests 自动重试的文章,突然想到,之前还用到过 Requests 自动加解密请求的逻辑,分享一下。之前在做逆向的时候,发现一般医院的小程序请求会这么玩,请求数据可能加密也可能不加密,但是返回…...

Notepad++--在开头快速添加行号
原文网址:Notepad--在开头快速添加行号_IT利刃出鞘的博客-CSDN博客 简介 本文介绍Notepad怎样在开头快速添加行号。 需求 原文件 想要的效果 方法 1.添加点号 Alt鼠标左键,从首行选中首列下拉,选中需要添加序号的所有行的首列ÿ…...

Python和MATLAB示例临床因素分析
🌵Python片段 为了演示临床因素的分析,让我们模拟一个数据集并执行一些基本的统计和机器学习分析。我们将重点关注以下步骤: 模拟数据集:创建具有年龄、性别、BMI、吸烟状况和疾病结果等特征的临床数据。描述性统计:…...

嵌入式硬件实战基础篇(二)-稳定输出3.3V的太阳能电池-无限充放电
引言:本内容主要用作于学习巩固嵌入式硬件内容知识,用于想提升下述能力,针对学习稳压芯片和电容以及电池之间的运用,对于硬件PCB以及原理图的练习和前面硬件篇的实际运用;太阳能是一种清洁、可再生的能源,广…...

【数据结构】树——链式存储二叉树的基础
写在前面 书接上文:【数据结构】树——顺序存储二叉树 本篇笔记主要讲解链式存储二叉树的主要思想、如何访问每个结点、结点之间的关联、如何递归查找每个结点,为后续更高级的树形结构打下基础。不了解树的小伙伴可以查看上文 文章目录 写在前面 一、链…...

STM32-- keil常见报错与解决办法
调试问题 1. keil在线调试需要点击好几次运行才可以运行,要是直接下载程序直接就不运行。 解决:target里面的use microlib要勾选,因为使用了printf。 keil在线调试STM32,点三次运行才能跑到main的问题解决。 keil在线调试STM32…...
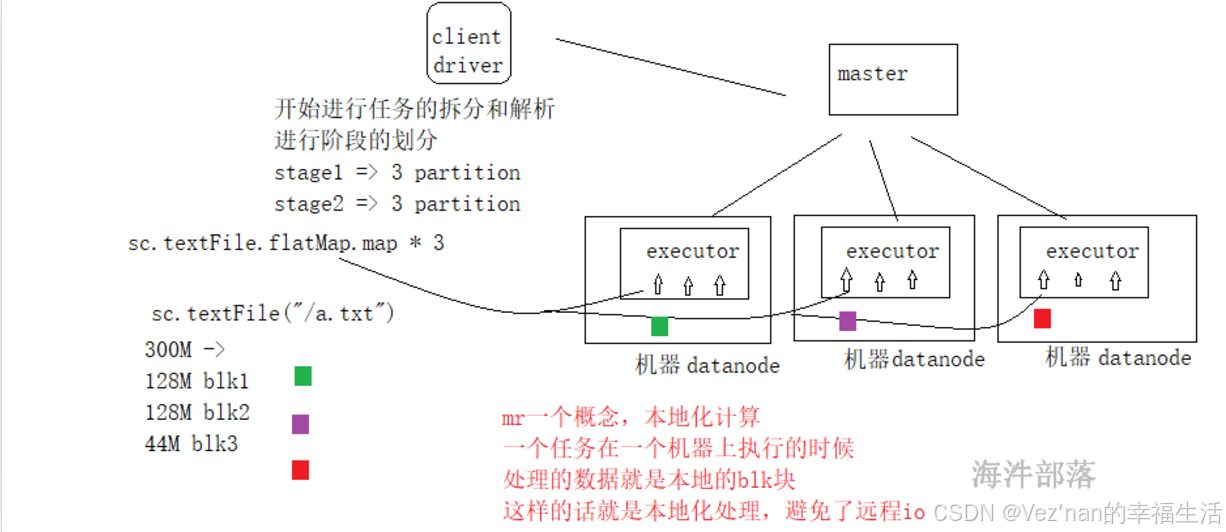
【大数据学习 | Spark-Core】RDD的概念与Spark任务的执行流程
1. RDD的设计背景 在实际应用中,存在许多迭代式计算,这些应用场景的共同之处是,不同计算阶段之间会重用中间结果,即一个阶段的输出结果会作为下一个阶段的输入。但是,目前的MapReduce框架都是把中间结果写入到HDFS中&…...

物理引导的机器学习工作流:气候建模的融合创新与实践
1. 项目概述:当气候建模遇见机器学习如果你像我一样,在气候模拟这个领域摸爬滚打超过十年,就会深刻体会到一种“甜蜜的负担”:我们构建的地球系统模型(ESM)越来越精细,物理过程越来越复杂&#…...

信息系统项目管理师核心知识点精讲
一、项目整合管理(重点:项目章程与项目管理计划) 知识点详解: 项目整体管理是项目管理知识体系的核心,它确保项目各要素协调统一。在考试中,特别要掌握项目章程和项目管理计划的区别与联系。 项目章程是项目的“出生证明”,由项目发起人发布。它正式授权项目,赋予项…...

HFSS仿真结果怎么看?以T型波导为例,读懂S参数与电场动态图
HFSS仿真结果深度解析:从S参数到电场动态图的实战指南当你第一次在HFSS中完成T型波导仿真后,面对满屏的曲线和彩色云图,是否感到既兴奋又困惑?那些起伏的S参数曲线究竟告诉你什么信息?电场图中跳跃的颜色又代表怎样的物…...

三十岁想从零转行现实吗?带你分辨真正有前景的好工作
我是29岁那年,完成从转行裸辞副业的职业转型。 如果你把职业生涯看成是从现在开始30岁,到你退休那年,中间这么漫长的30年,那么30岁转行完全来得及…...

Linux服务器被挖矿木马劫持的五步应急处置指南
1. 这不是“中病毒”,是服务器被劫持成了矿机——先别慌,但必须立刻断网“服务器被黑客攻击,用来挖矿!”——这句话在运维圈里一出,比收到OOM告警还让人头皮发紧。它不像网页被挂马、数据库被拖库那样有明显业务影响&a…...

别再死记硬背了!用5个生活化比喻彻底搞懂Linux进程的fork、exec和wait
别再死记硬背了!用5个生活化比喻彻底搞懂Linux进程的fork、exec和wait想象你正在厨房准备一顿大餐。菜谱上写着"切菜"、"炒菜"、"装盘"等步骤,但突然发现需要同时处理多道菜品——这时候,你会本能地让家人分工…...

基于ESP8266与MQTT的家庭水压自动控制系统设计与实现
1. 项目概述与核心需求解析家里水压不稳、供水时断时续,这大概是很多朋友都遇到过的烦心事。我所在的城市供水情况就很不理想,为了解决这个问题,我不得不自己动手,搭建了一套基于ESP8266微控制器的家庭水压增压与储水自动控制系统…...

如何快速上手DeepPurpose?5分钟完成你的第一个药物-靶点相互作用预测模型
如何快速上手DeepPurpose?5分钟完成你的第一个药物-靶点相互作用预测模型 【免费下载链接】DeepPurpose A Deep Learning Toolkit for DTI, Drug Property, PPI, DDI, Protein Function Prediction (Bioinformatics) 项目地址: https://gitcode.com/gh_mirrors/de…...

yolo视频识别 车辆速度估计识别 yolo11视频实时速度测量与测速估计
文章目录YOLOv11:视频实时速度测量与测速估计一、YOLOv11概述二、速度测量原理三、距离测量方法四、应用场景五、实践案例以下是关于使用YOLOv11进行视频实时速度测量与测速估计的介绍: YOLOv11:视频实时速度测量与测速估计 随着计算机视觉…...

Android Root检测绕过:从逆向分析到Frida分层Hook实战
1. 这不是“绕过root检测”,而是理解检测逻辑后的精准干预在安卓逆向工程的实际工作中,“过root检测”这个说法本身就容易引发误解——它听起来像某种黑箱魔法,仿佛只要套用某个脚本、加载某个插件,就能让App对设备状态“视而不见…...